
안녕하세요, 허재연입니다. 이번 리뷰에서 다룰 논문은 CVPR 2023에 게재된 CORA: Adapting CLIP for Open-Vocabulary Detection with Region Prompting and Anchor Pre-Matching 라는 논문으로, 기존 VLM을 OVOD에 활용하면서 생기는 task 간 mismatch를 완화하고자 시도한 논문입니다. 함께 살펴보겠습니다.
Introduction
기존 전통적인 Object Detection은 사전에 정의 및 학습된 closed set category에 속하는 객체에 대해 그 위치를 찾고 클래스를 분류하는 문제였습니다. 하지만 라벨링이 되어 있는 물체만을 검출할 수 있다는 것은 실생활 적용에 있어 큰 걸림돌이었고, 추가적인 라벨링만으로 이러한 한계를 극복하기 어려워 대규모 사전학습된 VLM을 활용하여 학습되지 않은 범주의 객체(novel class)에도 localization 및 classficiation 할 수 있는 open-vocabulary object detection이 주목 받았습니다.
대표적으로 웹에서 수집된 대규모 image-text pair로 joint embedding space에서 contrastive learning으로 학습하여 image 및 간단한 text caption에 대한 표현력을 확보한 CLIP은 사전에 보지 못한 클래스를 인식하는 zero-shot task에서 상당히 좋은 성능을 보여주었기에, 이러한 CLIP을 활용하여 많은 OVOD 방법론들이 제안되었습니다. CLIP을 OVOD에 적용하는 이들의 일반적인 접근법은 CLIP을 OVD의 분류기로 하용하는 것이었습니다. 하지만 저자들은 CLIP을 OVD에 효과적으로 적용하는데 다음과 같은 두 가지 문제가 있다고 지적합니다.
How to adapt CLIP for region-level tasks?
CLIP은 기본적으로 학습 과정에서 영상 인스턴스 단위로 학습하기 때문에 detection이나 segmentation과 같은 region-level task에 적용시키기 위해서 어떻게 적용해야 효율적일지 고민이 필요합니다. 가장 나이브한 방법은 영상에서 인식하고자 하는 영역만 crop해서 이들 각각을 독립적인 이미지로 취급하는 것이긴 하지만, crop된 region image를 처리하는 것과 전체 이미지를 처리하는 데에는 distribution gap이 있기 때문에 이렇게 활용하는 것은 분류 정확도에 부정적인 영향을 줄 수 있습니다. MEDet이라는 방법론이 image feature와 text feature를 augment하는 방법으로 이를 해소하려고 시도한 적이 있는데, 해당 방법론은 학습 과정에서 보았던 base class에 오버피팅되는 문제를 방지하기 위해 추가적인 image-text pair를 필요로 한다는 한계가 있었다고 합니다. RegionCLIP은 RoIAlign을 활용해 바로 regional feature를 얻는, 보다 효율적인 방법론을 제안하였지만 finetuning없이 novel class에 일반화 하는 데 한계가 있었다고 합니다. 특히 더 큰 CLIP 모델을 사용할 경우에는 finetuning에 너무 많은 비용이 소요됩니다.
How to learn generalizable object proposals?
ViLD, OV-DETR, Object-Centric-OVD, RegionCLIP과 같은 방법론들은 novel class object의 가능성이 있는 영역을 제안하기 위해 RPN과 같은 class-agnostic object detector를 필요로 합니다. 하지만 RPN같은 네트워크들은 이들이 학습된 base class에 강하게 편향되어 있어 novel class에 대한 성능이 떨어지는 문제가 있습니다. MEDet과 VL-PLM은 이러한 문제를 인식하고, 품질이 낮은 박스를 제거하거나 병합하는 몇 가지 handcrafted rule을 설계하였지만, 여전히 frozen RPN의 성능 한계의 영향을 피할 수 없었습니다.
본 논문에서, 저자들은 추가적인 image-text pair 데이터를 사용하지 않고 open vocabulary object detection을 수행할 수 있는 새로운 CLIP, DETR 기반의 프레임워크를 제안합니다. 해당 프레임워크는 class-aware object localization을 수행하기 위해 DETR스타일의 object localizer를 활용하며, 예측된 바운딩 박스를 CLIP image encoder의 중간 feature map을 pooling하여 인코딩합니다. 하지만, CLIP의 본래 visual encoder에서 나온 전체 이미지 feature와, 새롭게 풀링된 region feature 간에는 distribution gap이 생기기에 성능이 저하될 수 있습니다. 이를 해결하기 위해 저자들은 Region Prompting 기법을 제안하여 CLIP image encoder를 적용시켜 이를 활용해 분류 성능을 향상시킴과 동시에 기존 방법론들보다 뛰어난 일반화 성능을 보입니다. localizaer로는 DAB-DETR을 활용하였습니다. box regression 이전에 dynamic anchor box와 input category들을 prematching하는 Anchor Pre-Matching 기법을 도입하여 반복적인 클래스 별 inference 없이 class-aware regrion을 수행할 수 있도록 하였습니다.
제안한 방법론을 COCO 및 LVIS1.0 OVD 벤치마크에서 검층하여, 다양한 규모의 CLIP 모델에 대해서 기존 SOTA 방법론들을 능가하는 좋은 결과를 보였다고 합니다.
저자들이 주장하는 contribution을 정리하면 다음과 같습니다 :
(1) 제안하는 region prompting 방법은 효과적으로 영상의 전체 특징과 영상의 영역 특징 간 분포 차이를 완화하며, open-vocabulary setting에 잘 일반화된다.
(2) 제안하는 Anchor Pre-Matching은 DETR이 효과적으로 일반화된 object localization을 수행할 수 있도록 한다.
(3) 제안하는 방법론을 통해 COCO 및 LVIS OVD 벤치마크에서 state-of-the-art를 달성했다
Method
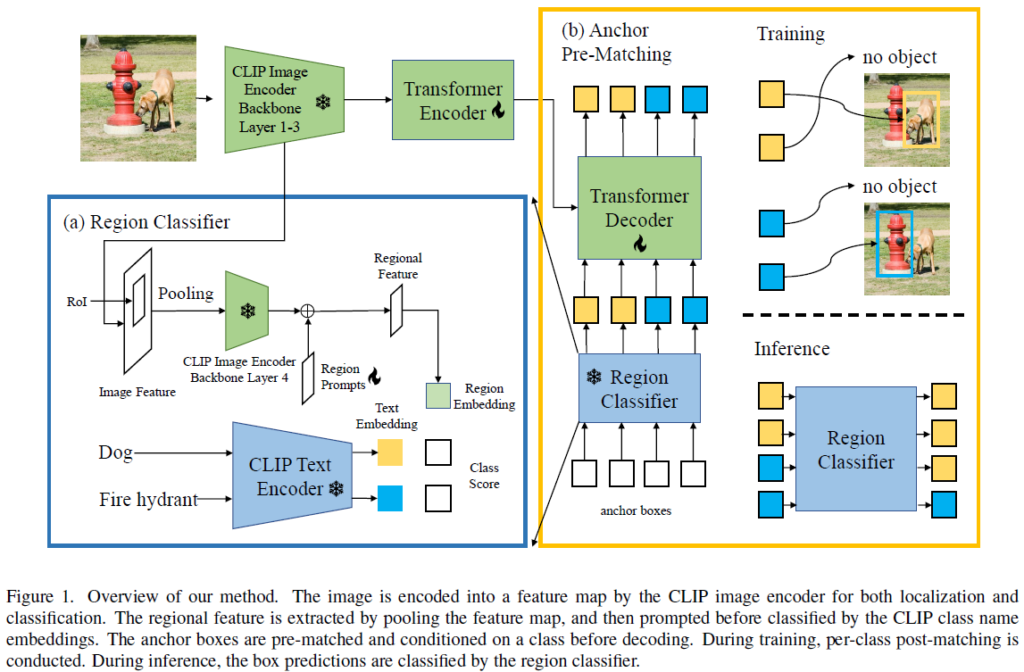
Overview
전반적인 CORA 프레임워크 구조는 Figure 1에서 확인할 수 있습니다. 주어진 입력 이미지는 사전학습된 CLIP의 이미지 인코더인 ResNet backbone을 거쳐 spatial feature map을 얻게 되는데, 이를 region classification 및 object localization branch에서 모두 사용합니다. 전통적인 detector와 달리, 해당 프레임워크에는 localization과 classification을 분리하여 순차적으로 수행해 보다 OVD 문제의 특성에 적합하도록 설계하였습니다. 해당 방법론은 object query set과 연관된 anchor box를 지속적으로 정제(refine)하여 객체 위치를 탐지(localize)하는 DETR 스타일의 detector를 학습시키게 되며, 이후 CLIP을 활용한 region classififer에 의해 분류됩니다.
Region Classification
주어진 영역(anchor box 또는 box prediction)을 분류하기 위해, RoIAlign을 활용하여 해당 영역의 특징을 추출한 후, CLIP의 어텐션 풀링(attention pooling) 모듈을 적용하여 영역 임베딩(region embedding)을 생성하게 됩니다. 이후, CLIP 텍스트 인코더에서 얻은 클래스 임베딩(class embedding)과 비교하여 분류를 수행합니다. 해당 과정은 CLIP 기반 영역 분류기(CLIP-based region classifier) module에서 수행됩니다 (Figure. 1-(a))
Object Localization
visual feature map은 먼저 DETR-style의 인코더를 통해 정제되고 이후 DETR-style의 디코더에 입력됩니다. 앵커 박스의 query는 먼저 CLIP 기반 region classifier로 분류되며, 그 다음 DETR 유사 디코더에 의해 반복적으로 정제되어 더 나은 localization을 수행하게 됩니다. 디코더는 쿼리와 이전에 예측된 레이블이 매칭되는지 여부(matchability)를 추정하게 됩니다. 훈련 중에 예측된 박스는 동일 레이블을 가진 GT box와 일대일로 매칭되며,(Figure 1-(b)), DETR과 같이 훈련되게 됩니다. 추론 단계에서는 CLIP 기반 region classifier에 의해 box의 class label이 조정됩니다.
앞에서 언급했듯, OVD에는 두 가지 장애물이 있습니다. (1) CLIP 모델은 전체 이미지로 학습되었는데 object detection은 이미지의 국소적 영역에 대해 수행되기에 분류를 수행함에 있어 distribution gap이 부정적인 영향을 미친다는 것이고, (2) 검출기의 localizer가 base class에서만 학습되었기 때문에 novel class에 대한 localization 능력이 떨어진다는 것입니다. (1)번의 문제를 해결하기 위해 저자들은 더 일반화 가능한 영역 임베딩을 생성할 수 있도록 region feature를 module하도록 유도하는 region prompting을 제안하였고, (2)번의 문제를 해결하기 위해 추론 중에 novel class로 일반화 할 수 있는 class-aware object localization을 수행하도록 anchor pre-matchning을 제안하였습니다.
Region Prompting
Region Classifier는 기존의 타 OVD와 유사하게 CLIP을 활용한 Region Classification을 수행합니다. CLIP image encoder의 regional embdding와, CLIP text encoder의 class name ebdding과의 유사도를 비교하여 region classification을 을 수행하게 됩니다.
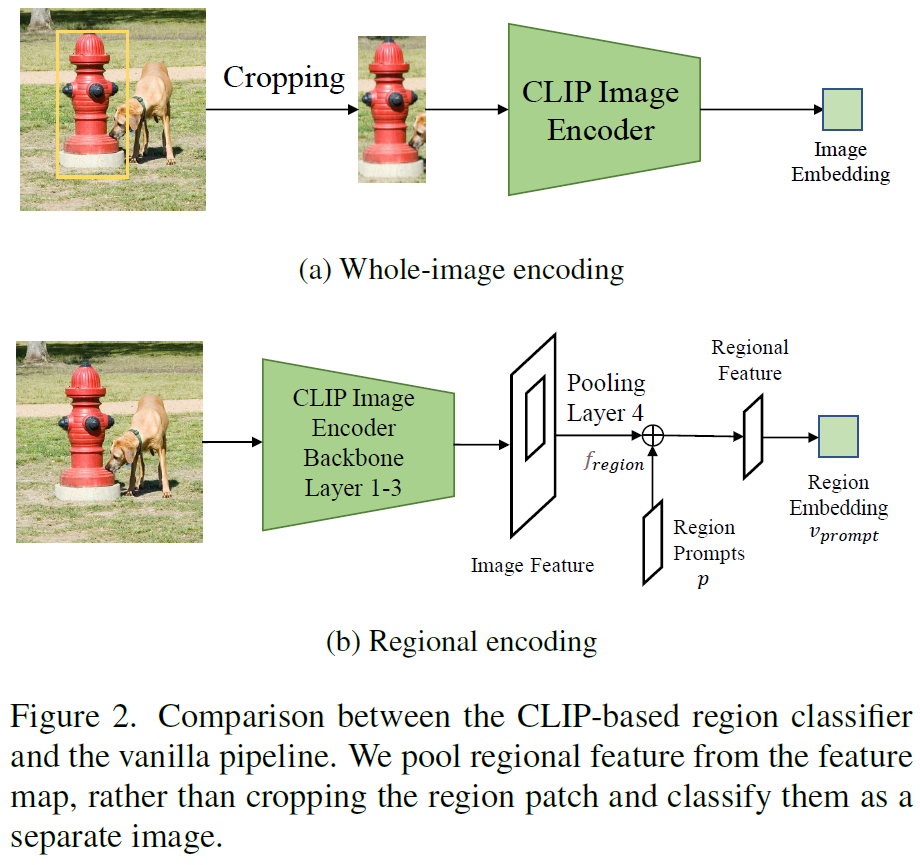
Region Prompting.
Figure 2와 같이, 이미지와 RoI set이 주어지면 우선 이미지 전체를 CLIP encoder의 처음 3개 block에 통과시켜 feature map을 얻게 되고, 여기에 anchor box나 예측된 박스 정보로 RoIAlign을 수행하여 region feature를 추출한 뒤 마지막 CLIP image encoder backbone의 마지막 블록을 거쳐 인코딩됩니다. CLIP image encoder의 전체 이미지 featuremap과 pooled regional feature 간에는 distribution gap이 있기에, region feature를 learnable prompt로 증강시켜 misalignment를 해소하는 region prompting을 활용합니다. learnable prompt p는 SxSxC차원인데, S는 regional feature의 spatial size이고, C는 regional feature의 차원이 됩니다. 주어진 입력 regional feature {f}_{region}에 대해, region prompting은 다음과 같이 얻어집니다.
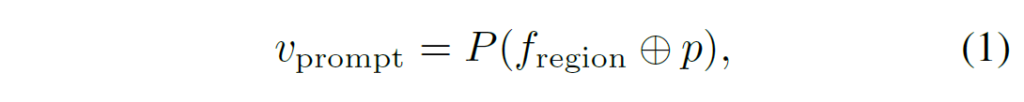
수식 (1)에서 ⊕는 element-wise addition 연산이고, P는 CLIP visual encoder의 attention pooling module을 의미합니다.
Optimizing Region Prompts.
region prompt들은 detection dataset에 있는 base-class anootation들을 활용하여 학습하게 되는데, class name embedding들은 CLIP text encoder에 의해 미리 연산되어 이후 분류기 가중치에 사용됩니다. 프롬프트는 크로스 엔트로피로 학습되어 GT box와 이들의 pooled regional feature {f}_{region}를 분류하게 됩니다. region prompt를 최적화할 때, 다른 모델 가중치는 freeze한 상태로 유지하고, region prompt만만 학습하도록 합니다.
Anchor Pre-Matching
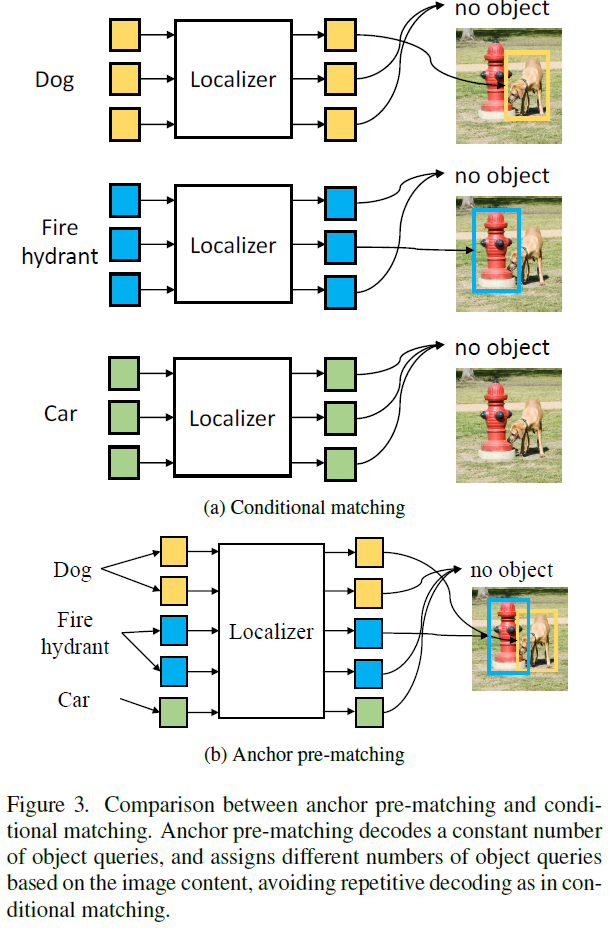
detection을 수행하기 위해서는 region classification뿐만 아니라 object localization도 잘 되어야겠죠. 사전학습된 RPN이 novel class에서 잘 동작하지 못하는 것을 고려하여, 저자들은 unseen sclass에서 더 나은 일반화 능력을 보여주는 class-aware query-based object localizer를 도입합니다. 앞에서 보았던 Figure 1와 같이, frozen CLIP image encoder에서 추출한 visual feature map이 주어지면 object query는 CLIP text encoder에서 출력된 class name embedding에 pre-matching됩니다.
Anchor Pre-Matching
object localizer는 트랜스포머 encoder-decoder를 활용하여 DETR 구조로 구현되어, encoder는 특징 맵을 뽑고 decoder는 object query set을 디코딩하여 box prediction을 수행하게 됩니다. 저자들은 각 object query에 anchor box 정보를 추가한 DAB-DETR을 활용하였습니다(기존 DETR의 object query가 단순히 랜덤 초기화를 하였다면, DAB-DETR은 이 object query에 anchor box 정보를 연관시켜 성능 개선을 시도한 방법론이었습니다). 각 GT box는 동일한 라벨의 쿼리 셋에 pre-match됩니다(Figure 3 참고). object query의 라벨 \hat{c}_{i}은 연관된 anchor box {b}_{i}를 분류하면서 할당됩니다.
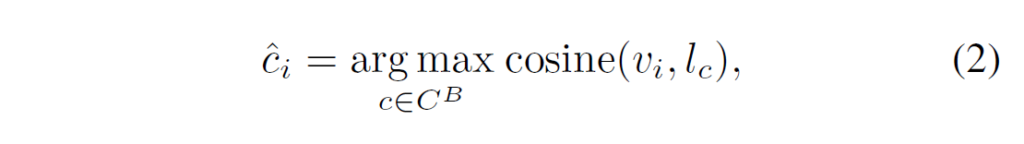
수식 (2)에서 {v}_{i}는 anchor box {b}_{i}의 region feature이고,, {l}_{c}는 class c에 대한 class name embedding입니다. pre-matching 이후, 각 object query는 예측된 클래스 임베딩에 조건화(condition)되어 class-aware box regression을 수행하게 합니다. conditioned object query는 다음과 같이 주어집니다.
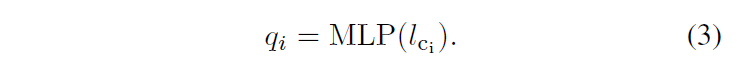
DETR구조의 디코더는 반복적으로 각 object query와 anchor box 정보 ({q}_{i}, {b}_{i}) 를 처리하여 (\hat{q}_{i}, \hat{b}_{i}) 의 예측을 수행합니다.
모델 예측이 수행되면, 각 클래스마다 익숙하게 GT box와 예측 값 간 DETR의 bipartite matching이 수행됩니다. 여기서 저자들은 디코더가 conditioned text embedding을 인식하도록 강제하기 위해 각 GT box가 동일한 pre-matched label로 예측된 GT box에 할당하도록 하였습니다. \hat{y}
구체적으로, 클래스 c의 경우, 클래스 c에 pre-match된 {N}^{c} box prediction {\hat{y}^{c} = {\hat{y}_{i} | \hat{c}_{i} = c}와 클래스 c 의 GT box set인 {y}^{c}가 주어졌을 때 {N}^{c}개 element를 다음의 cost function으로 최적화합니다.
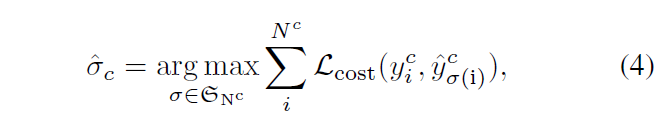
matching cost는 다음과 같습니다.
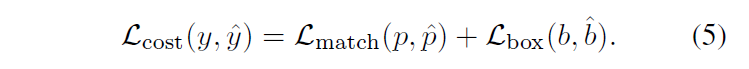
{L}_{match}(y, \hat{y})는 binary classification loss이고, {L}_{box}(b, \hat{b})는 localization error를 나타닙니다. localization error의 경우이전 DETR계열들과 동일하게 L1 loss와 GIoU의 weighted sum을 사용했다고 합니다.
으델은 다음의 최종 loss로 계산됩니다 :
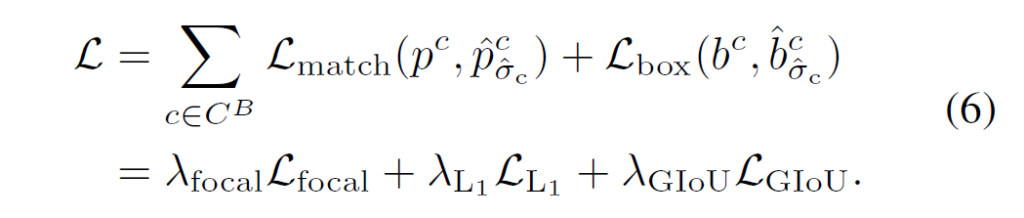
inference 과정에서는, 앞의 region prompting에서 살펴봤던 region classifier를 사용하여 예측된 박스의 분류를 수행합니다. 박스의 품질을 고려하여 class score는 pre-matching score와 곱해집니다.
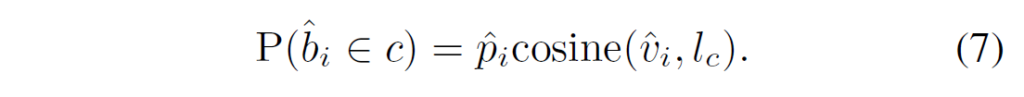
Experiment
주요 실험은 COCO OVD에서 수행되었습니다. OVD라는 task가 사전학습 모델에 굉장히 의존적이기 때문에, baseline 방법론들과 동일한 CLIP 모델을 사용하였습니다.
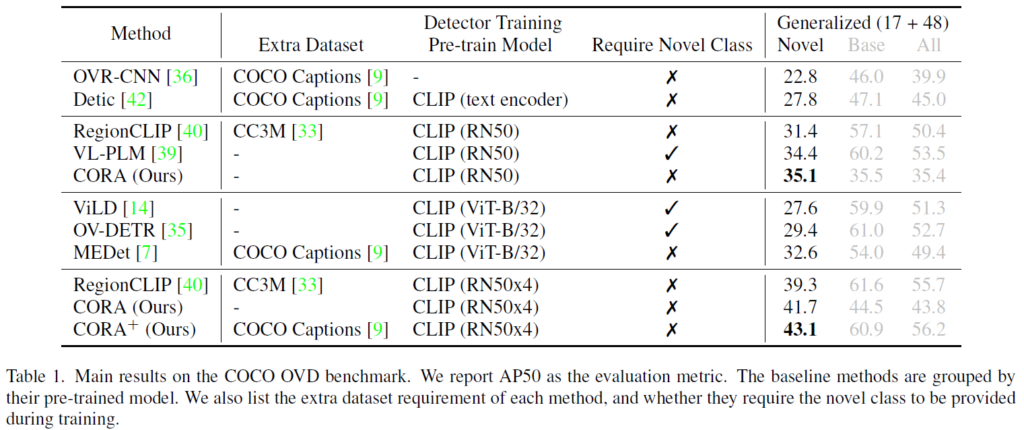
CLIP RN50 에서는 CORA가 VL-PLM보다 novel class 검출을 더 잘 수행했고, 그보다 큰 사전학습 모델에서도 RegionCLIP보다 좋은 결과를 보여주었습니다. 비교군 중 VL-PLM, ViLD, OV-DETR은 학습 과정에서 potential novel object를 식별하거나 pseudo label을 부여하기 위해 novel class를 사용하였다는 점을 강조하고 있네요.
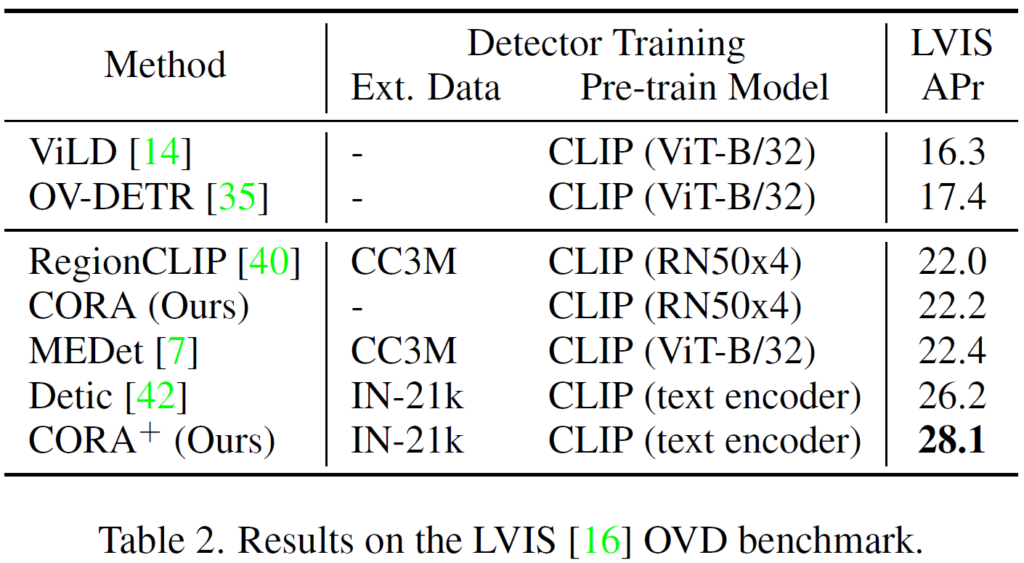
Table 2는 대규모 OD 데이터셋인 LVIS에서의 결과입니다. 역시 다양한 pretrain model에 대해 CORA가 좋은 성능을 보여주고 있습니다. CORA+는 기존의 방법론들과 동일한 비교 평가를 하기 위해 CORA 구조를 비교하는 방법론과 동일한 구조로 수정한 것입니다.
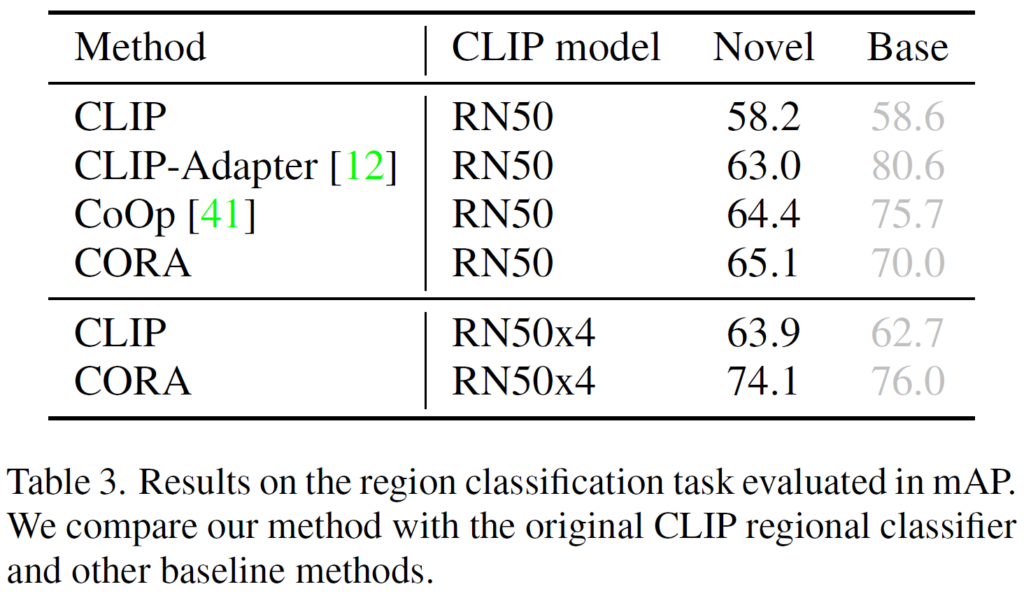
Table 3에서는 region prompting의 효과를 보기 위해 region classification에서 비교 실험을 수행한 것입니다. COCO데이터셋에서 base class로 학습한 뒤, validation set의 base 및 novel class에서 region classification으로 평가를 진행하였습니다. 평가 metric은 mAP입니다. 실험 결과, 추가적인 학습을 진행하기 않은 CLIP또한 58.2mAP로 novel class 에서 좋은 결과를 경쟁력을 보여주는데, 저자들의 CORA는 다른 방법론들보다 비교해 좋은 결과를 보여주고 있습니다. CoOP은 지난 주 세미나에서 다루었듯 CLIP에 prompt learning을 도입한 방법론입니다.

Table 4는 제안하는 방법론과, region 영역을 whole-image로 취급하여 분류하였을 때 성능을 나타낸 것입니다. 결과에서 확인할 수 있듯, region 영역을 whole-image로 취급하여 분류하면 그 성능이 저하될 수 있습니다.

마지막으로, Anchor Pre-Matching에 대한 ablation입니다. anchor pre-matching은 query conditioning과 per-class post-matching이라는 두 요소로 구성되는데, 그 효과를 table 5에 나타내었습니다. 결론은 당연하게도, 저자가 제안한 조합이 가장 좋다는 것을 보이면서 프레임워크 설계의 정당성을 나타내고 있습니다.
conclusion
OVD에서 어떻게 하면 base class의 knowledge를 unseen 객체인 novel class에 잘 적용할 수 있을까 라는 과정에서, whole image-local region 간 distribution gap과, anchor pre matching이라는 방법을 활용해 기존 RPN이 novel class를 잘 localize하지 못하는 점을 다룬 논문이었습니다. 문제 정의부터 해결해가는 과정까지 논리 흐름이 좋고 뒷받침하는 실험도 탄탄해 배울 점이 있는 논문이었습니다.
감사합니다.
안녕하세요 허재연 연구원님 리뷰 감사합니다.
논문에서는 region image와 whole image 간의 distribution gap이 OVD에서 분류 성능 저하의 원인이라고 설명하고 있고, Table 4는 CORA 내부 실험을 통해 이를 보여주는 것 같습니다. 그런데 이러한 분포 차이에 따른 성능 저하가 기존 방법들(CLIP, RegionCLIP 등)에서도 발생한다는 점을 직접적으로 정량 검증한 실험 결과가 있는지 궁금합니다. 즉, distribution gap 자체가 OVD 전반에서 보편적인 문제인지, 아니면 CORA에서만 관찰된 현상인지 확인하고 싶습니다.
whole image – region image에 따른 distribution gap은 본 논문에서 처음 제기한 문제는 아닌 듯 합니다. 기존 다른 연구에서도 언급됐던 문제이며, 본문에서도 MEDet등의 방법론이 이를 해결하기 위한 연구라고 언급되어 있습니다. 이로 미루어보아, distribution gap은 CORA뿐만이 아닌 일반적으로 OVOD에서 발생할 수 있는 문제로 보여집니다.
이는 비단 OVOD뿐만이 아닌 CLIP을 활용하는 다양한 task에서 발생할 수 있는 문제로 생각되는데요, 영상의 global한 특징을 추출하도록 학습이 진행된 CLIP을 활용하기에 어쩌면 당연한 문제로 생각됩니다(contrastive learning계열 SSL에서도 SimCLR, MoCo등에서 local 정보가 부족하니 이를 개선하기 위해 DenseCL, DetCo, SoCo 등의 방법론이 제안된 것과 비슷한 맥락이 아닐까 싶습니다). dense prediction task를 위해서 denseCLIP과 같은 추가적인 연구가 수행된 것으로 알고 있습니다.
하지만 아쉽게도, 본문에 다른 방법론들에 대해 distribution gap을 명시적으로 보이는 실험은 없습니다.
안녕하세요. 좋은 리뷰 감사합니다.
Object Localization 파트에서, decoder를 통해 query와 이전에 예측한 라벨이 매칭되는지 여부를 추정한다고 하였는데 이 부분에 대해 더 자세히 설명해주실 수 있을까요 ? 디코더가 matchability를 추정한다는 건 단순히 bipartite matching을 위한 것인가요 ?
또, object query가 예측된 class embedding에 조건화..?! 된다는 것이 무슨 말인지 궁금합니다.
감사합니다.
쿼리는 디코더에 입력되기 이전에 region classifier에서 class embedding의 정보를 얻게 됩니다. 이후 디코더에서 예측된 라벨 정보와 쿼리와의 matachability를 추정합니다. 예측된 박스는 GT값과 DETR의 학습방식(헝가리안 알고리즘을 활용한 bipartite matching이겠죠)과 동일하게 1대1로 매칭됩니다(Figure1.b).
object query가 예측된 class embedding에 조건화(conditioned)된다는것은, clip 기반 region classifier에서 분류된 뒤 class 정보를 갖고 디코더에 입력된다는 뜻입니다. 조건부확률 P(A|B)를 생각해보면 B에 대한 정보가 주어진 다음 사전 A가 일어나는 것처럼 class 정보를 가지고 입력되므로 이런 맥락에서 condition이라는 단어를 사용한것으로 보입니다.