안녕하세요, 이번주는 미니 챌린지 마지막 단계의 목표인 강화학습을 통한 복잡한 모션 수행을 위해 공부하던 중 발견 한 논문 리뷰입니다. 이 논문에서는 강화학습을 적용하여 카메라 영상만을 이용해 로봇 매니퓰레이터를 제어하는 방법을 제안했다고 합니다. 읽다보니 내용이나 17년 당시에 활용한 DQN이 현재와 조금 달라서 애매하긴 했는데, 발전 방향(?)을 살펴볼 수 있지 않을까 하고 이전 논문도 보려고 읽어봤습니다.
Introduction
기본적으로 강화학습은 어떤 특정한 정책에 따라 에이전트가 행동을 선택하고, 그로부터 얻은 보상들을 누적하여 최대화되는 방향으로 학습하는 알고리즘입니다. 그리고 매니퓰레이터를 강화학습으로 제어할 때는 로봇의 joint나 torque(토크)와 같은 값을 state로 사용해 왔다고 합니다. 최근에는 딥러닝의 발전으로 인해 고차원의 상태공간도 직접 다룰 수 있게 되었으며, 이에 따라 카메라로부터 얻은 raw image 자체를 상태로 사용하는 연구들이 등장했다고 합니다. 하지만 원시 이미지는 고차원이기 때문에 처리에 막대한 계산 자원이 필요하고, 저자는 비전 기반 방향 벡터(vision-based direction vector)를 사용해 타겟과 end effector 사이의 방향 벡터를 계산해서 효율적인 강화학습을 진행했다고 합니다. direction vector를 강화학습의 state로 활용했기 때문에 컴퓨팅 코스트를 많이 낮출 수 있었다고 하네요. 또 학습하는 동안 타겟의 position을 모른다는 전제로 진행해서 더 일반화 됐다고 합니다. 학습에는 model-free 방식인 DDPG를 활용했다고 합니다.
Method
전체 시스템 구조는 아래 figure와 같습니다. 학습된 정책 pi는 로우레벨 제어와 물리 기반 시뮬레이션으로 전달될 행동을 생성하며, 이를 ROS 환경을 통해 Gazebo 시뮬레이터에서 구현했다고 합니다. 로봇으로는 UR3 매니퓰레이터를 사용하며, 총 6개의 자유도(degree of freedom)를 가집니다. 구성은 base, shoulder, 엘보, wrist1, wrist2, wrist3로 이루어져 있으나, Wrist3에는 카메라가 부착되어 있어 제어를 하지 않고 제외했다고 합니다.

각 time step마다 매니퓰레이터의 개별 관절들은 encoder 정보를 기반으로 로우레벨 제어 구조에 의해 제어된다고 합니다.(사실 이 말이 정확히 어떤 말인지 좀 더 찾아봐야 할 것 같습니다.) 정책은 DDPG를 활용하는 만큼 actor-critic 구조로 구성되며, 각각 DNN으로 구현된다고 합니다. actor 네트워크 μ(s)는 현재 상태 s를 받아 해당 상태에서의 행동을 출력하고, critic 네트워크 Q(s)는 주어진 상태에서 특정 행동의 가치를 추정합니다. 시뮬레이션 과정에서는 각 time step의 시작 시점마다 크리틱 네트워크가 현재 상태에 대한 Q값을 추정하고, 그중 가장 높은 값을 가지는 액터의 출력을 선택하여 그 값을 통해 로봇을 제어하는 구조라고 합니다.
Vision based policy representation
정책(Pi)는 state space (S)에서 action(A)로의 매핑으로 정의되며, 강화학습의 핵심 목적은 누적 보상을 최대화 하는 pi를 찾는 것입니다. 이 논문에서 정의한 A는 UR3 매니퓰레이터의 관절 각도의 변화량(delta joint angles)을 연속적으로 표현한 것 입니다. S는 시각 정보를 바탕으로 구성되며, input 이미지에서 얻은 x, y, z 방향에 대한 discrete한 방향 벡터들로 이루어져 있습니다. 여기에 더해, base joint의 각도를 상태에 포함시켜 좌우 대칭 구조로 인한 모호성을 제거했다고 합니다. (좌우 대칭 구조로 인해 생기는 모호성이 어떤건지에 대해 조금 더 생각해봐야 할 것 같습니다.
이러한 방향 벡터를 계산하기 위해 먼저 카메라 이미지 상에서 목표 물체를 인식해야 합니다. 논문에서는 이를 위해 color-based detection방식을 채택하며, 노란색 공을 목표로 설정했습니다. 노란색을 인식하기 위해 HSV(Hue, Saturation, Value) 색 공간을 활용했다고 합니다. 아래와 같이 추출된 결과의 노이즈를 없애기 위해서 dilation과 erosion을 통해 노이즈를 제거하고, 분리된 요소들을 하나의 객체로 연결해주는 과정도 진행했다고 합니다.
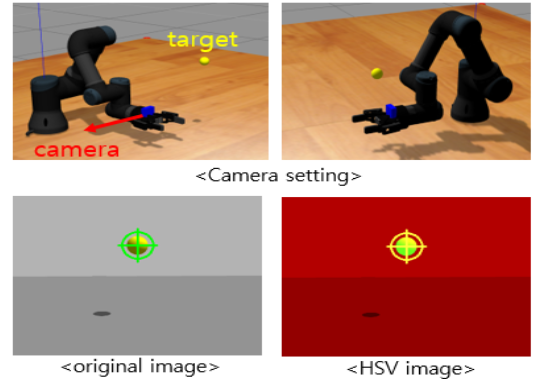
이러한 vision을 기반으로 state, action, reward, policy를 구성했다고 합니다. 더 살펴보도록 하겠습니다.
State
state는 엔드이펙터로부터 목표물까지의 방향 정보를 기반으로 구성됩니다. 구체적으로는, x, y, z 세 좌표축을 기준으로workspace를 나누고, 각 축마다 + 와 − 방향을 고려해 아래 figure와 같이 전체 8가지 방향을 정의했습니다. 즉, 로봇이 목표를 향해 접근할 수 있는 8개의 상대적 방향이 존재하며, 이들을 하나의 벡터로 표현합니다.
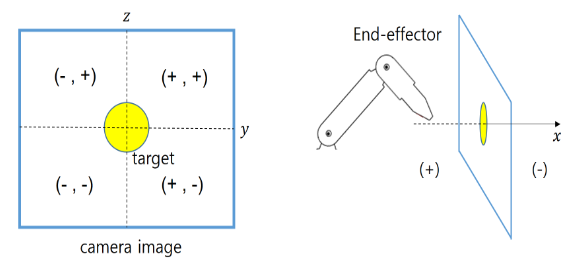
앞서 설명한 목표 탐지 과정을 통해, 이미지 상에서 목표 물체의 중심 좌표를 계산할 수 있다고 합니다. 카메라는 엔드이펙터 끝부분에 장착되어 있으므로, 엔드이펙터의 위치는 이미지의 중심이라고 가정할 수 있습니다. 따라서 방향 벡터는 엔드 이펙터와 타겟의 x,y,z 좌표 차이로 구할 수 있습니다. 여기서 x_e, y_e, z_e는 엔드이펙터의 위치이고, x_t, y_t, z_t는 타겟의 위치이며, 두 좌표 모두 이미지 상의 픽셀 기준으로 표현됩니다. 이 차이 벡터의 각 성분에 대해 부호를 취하면, -1, 0, +1 중 하나가 됩니다. 이렇게 부호화된 값들이 상태를 구성하게 됩니다. 결과적으로 로봇은 현재 자신이 목표물에 대해 어느 방향에 위치해 있는지를 상대 좌표계 기준으로 인식하게 됩니다. 이러한 상태 표현 방식은 계산적으로 간단하면서도, 로봇이 어떤 방향으로 이동해야 하는지에 대한 명확한 정보를 제공한다고 합니다. 그냥 좌표 차이를 방향벡터라고 말한 것 같습니다.
Action, Reward
로봇을 제어하기 위해 이 논문에서는 joint 각도의 변화량(delta joint angles)을 action으로 정의합니다. 즉, policy는 목표에 도달하기 위해 각 joint가 얼마나 움직여야 하는지를 출력합니다. 따라서 총 5차원의 연속적인 행동 공간을 갖게 됩니다.
reward function의 설계는 강화학습 성능에 결정적인 영향을 미치기 때문에 신중하게 정의했다고 합니다. 이 논문에서는 이미지 내에서 목표 영역이 차지하는 비율 α와, 카메라 중심과 목표 중심 간의 픽셀 차이 β를 함께 고려하여 보상을 설계합니다. 엔드이펙터가 목표에 가까워질수록 이미지 내에서 목표가 더 크게 보이고, 중심에 위치하기 때문에 α는 클수록 좋고, β는 작을수록 좋다는 방향으로 reward를 아래와 같이 설계했다고 합니다.
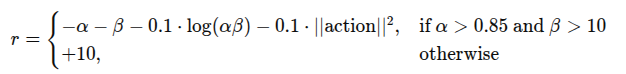
alpha는 카메라 프레임에서 목표 영역의 비율을 나타내며, 이 비율이 높을수록 더 가까이 있기 때문에 보상이 증가하게 됩니다. 반면, beta는 카메라 중심과 목표 간의 픽셀 거리 차이를 의미하며, 이 값이 작을수록 보상이 높아집니다. (둘 다 결국 카메라와 목표가 가까워 지면 좋아지는 방향입니다. 마지막으로, ||action||^2은 취한 행동의 크기를 제곱한 값으로, 큰 행동을 취할 경우 보상이 감소하도록 설계되어 로봇이 미세하고 정확하게 작동하는 것을 가능하게 해준다고 합니다.
이 수식은 alpha > 0.85 , beta > 10 을 만족하는 경우에만 계산되고, 그렇지 않은 경우 기본 보상으로 +10이 주어지는 방식으로 이루어져 있어서 목표지점에 일정 수준만큼 도달하기 전 까지는 기본 10인 보상을 준다고 합니다. 이렇게 정의된 보상을 통해 아래와 같이 전체 누적 보상도 정의됩니다. 이 때 감마값은 discount factor인데, 0과 1 사이의 값으로, 전체적으로 보상을 수렴시키고 현재에 가중치를 두기 위해서 미래의 보상일수록 저 작다고 합니다.
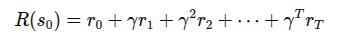
Policy
policy는 앞서 말했듯 DDPG(Deep Deterministic Policy Gradient) 알고리즘을 기반으로 구현됩니다. state로 표현된 특징들을 입력으로 받아, actor critic 신경망을 통해 학습이 이루어집니다. critic 네트워크는 주어진 state-action 쌍에 대해 Q-value, 즉 누적 보상의 기대값을 예측합니다. 반면, actor 네트워크는 해당 state에서 취해야 할 행동을 제안합니다. 학습 중에는 여러 actor가 제안한 행동들 중, 가장 높은 Q-value를 출력하는 actor의 행동이 선택됩니다.
액터 네트워크의 구조는 두 개의 fully connected layer로 이루어져 있으며, 각각의 은닉층은 32개의 유닛을 가진다고 합니다. 크리틱 네트워크도 동일한 두 개의 은닉층으로 구성되지만, 각 층은 128개의 유닛을 사용하여 보다 높은 표현력을 확보했다고 합니다. 이와 같은 구조를 통해, 주어진 상태 S에 대해 가장 높은 Q-value를 가지는 policy를 취합니다.
Deep Reinforcement Learning (DDPG)
저자가 활용한 DDPG라는 방식은 매니퓰레이터와 같은 continuous action space를 가지는 환경에 적합한 알고리즘으로, 로봇 제어와 같은 물리 기반 시스템에서 활용됐다고 합니다. Policy와 Value의 장점을 결합한 Actor Critic 네트워크 입니다. Actor와 Critic이 각각 policy와 value를 학습하고, 이 때 target netowrk를 함께 사용해 학습을 더 안정적으로 진행하는 방식입니다. Actor 네트워크는 state를 입력으로 받아 어떤 action을 취할지 결정합니다. 논문에서는 방향 벡터와 베이스 조인트 각도를 상태로 사용하며, 이를 기반으로 각 관절의 목표 각도를 연속적인 값으로 출력합니다. Critic 네트워크는 상태와 행동을 모두 입력으로 받아, 해당 행동의 Q-value를 평가합니다. 즉, 그 행동이 얼마나 좋은지를 판단합니다.
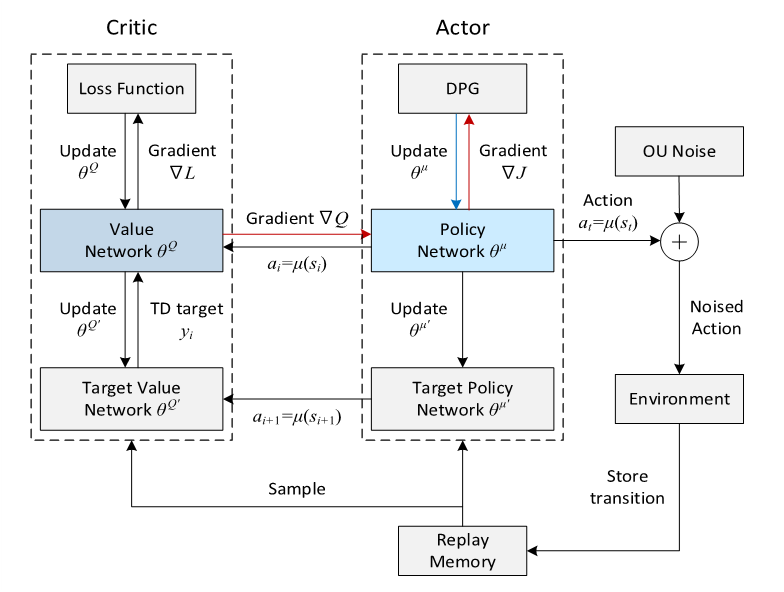
Policy를 학습 할 때는 기본적으로 off-policy 방식으로 진행됩니다. 이는 두 개의 주요 신경망, actor와 critic 네트워크를 통해 구현됩니다. Actor는 최대 Q 값을 출력하는 행동을 확률적으오 선택한다고 합니다. 이를 위해 softmax 함수를 사용하며, 각 행동의 확률을 기반으로 가장 가능성이 높은 행동을 선택하도록 구성됩니다. 또 연속적인 행동 공간에서 강화학습을 수행할 때 가장 큰 어려움 중 하나는 exploration이었다고 합니다. DDPG는 off policy 방식이기 때문에, 탐색 전략을 학습 과정과 독립적으로 설계할 수 있고,(다른 최신 연구들도 탐색 과정을 효과적으로 진행하기 위해 imitation learning등을 사용하는 것 같습니다.) 이를 위해 정책 μ에 노이즈를 더한 확장된 policy μ′(st)를 사용했습니다.
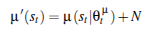
노이즈 N은 환경 특성을 반영하여 설계되며, 저자는 시간적으로 상관된 탐색을 위해 Ornstein-Uhlenbeck 프로세스를 적용했다고 합니다. 설정된 파라미터는 θ=0.15, σ는 초기 1.0에서 시작하여 시간 단계마다 0.2까지 점차 감소한다고 합니다. 학습 과정에서 매 time-step은 다음과 같은 형태의 경험 튜플(tuple)로 요약돼서 저장된다고 합니다. (st , at , rt , st+1, success). 각각 현재 상태, 현재 액션, 현재 보상, 다음 state와 성공 유무에 대한 Bool값입니다. 이러한 튜플들은 replay memory에 저장되며, 총 10,000개의 최근 경험을 유지하고 활용한다고 합니다. 이후 매 학습 스텝마다 32개의 요약본을 batch로 샘플링하여 actor, critic 네트워크를 각각 업데이트합니다. 초기 단계에서는 정책이 학습되지 않았기 때문에 랜덤한 정책을 통해 수집된 경험 10,000개로 액터와 크리틱 버퍼를 초기화 해준다고 합니다. 초기 튜플이 저장될 때, 각 경험에 대응되는 액터는 랜덤하게 선택되어 지정됩니다.
Simulation
시뮬레이션에서는 강화 학습을 통해 임의의 위치에 있는 목표물에 접근하는 제어 작업을 수행합니다. 학습 중에는 목표의 정확한 위치를 알 수 없으며, 목표는 카메라 프레임보다 약간 넓은 범위 내에 무작위로 생성됐다고 합니다. 성공 여부는 두 가지 기준으로 결정했습니다. 첫 번째는 카메라 프레임 내에서 목표가 차지하는 면적이 0.35 이상일 때, 두 번째는 카메라 중심과 목표 중심 사이의 픽셀 거리가 10픽셀 이하일 경우입니다. 카메라 해상도(320×240)를 고려했을 때, 그리퍼가 물체를 안정적으로 잡을 수 있을 정도로 충분히 가까워 졌다고 판단할 수 있을 때 성공으로 정의했다고 합니다.
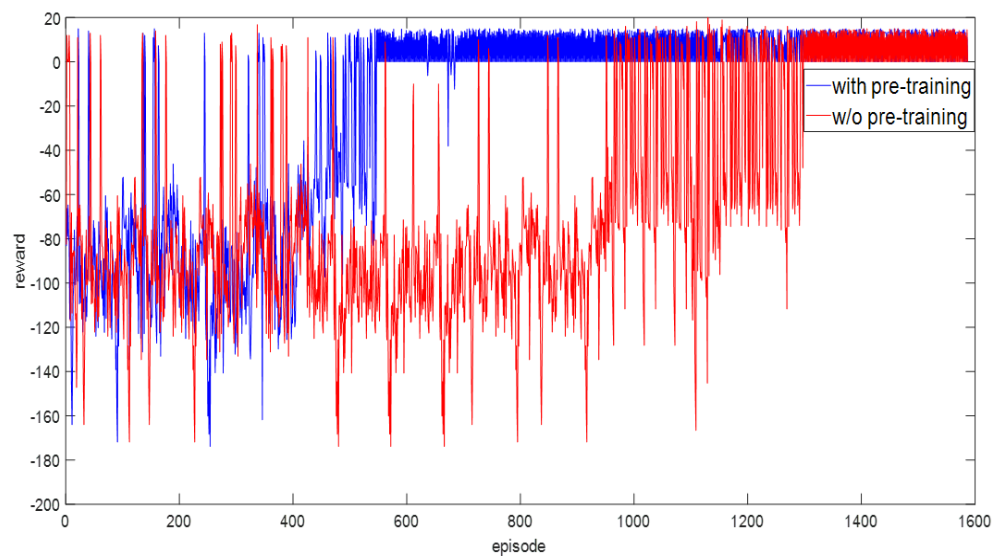
본격적인 카메라 영상 기반 학습에 앞서, 저자는 사전 학습(pre-training) 단계를 수행합니다. 이 과정에서는 카메라 이미지 대신, 목표와 엔드이펙터의 실제 좌표 정보를 활용하여 방향 벡터를 계산해서 진행했다고 합니다. 아래 figure와 같이 같은 에피소드 수 내에서 관절 각도를 상태로 사용할 경우에는 학습이 수렴하지 않는 반면, 방향 벡터를 사용할 경우 학습이 성공적으로 진행됨을 확인할 수 있었다고 합니다. 횟수가 많아 지면 결국 수렴하는 것 같은데 의미가 있는지는 잘 모르겠습니다.
Conclusion
원래는 강화학습 보상을 어떤 기준으로 설계해서 적용시키는지, 그 구조는 어떻게 되는지를 vision based 기반의 학습이라는 제목을 보고 궁금해서 알아보려고 했는데 생각보다 원하는 것을 얻을 수는 없는 논문이었던 것 같습니다.. 공부가 아직 부족한 것 같기도 합니다.
어려운 논문을 읽기 시작하여 힘들었을 텐데 고생하셨습니다.
해당 논문에 관련하여 몇 가지 질문을 남기고 가겠습니다.
Q1. 해당 논문을 읽게된 계기가 궁금합니다. 해당 방법론은 IK를 강화학습으로 변경하기 위한 기법으로 카메라 내 노란색 타겟을 목적으로 IK를 풀어내는 것 같습니다. 저희가 하고자 하는 태스크가 IK가 반드시 필요하기는 하나… 서랍을 여는 행위와 같이 복잡한 움직임 대비 움직임이 단순할 것으로 예상됩니다.
Q2. off-policy에 대해서 설명 부탁드립니다.
Q3. “Wrist3에는 카메라가 부착되어 있어 제어를 하지 않고 제외했다고 합니다.” 라는 이야기는 초기 자세 이후 제어를 아예 안한다는 이야기일까요???
Q4. 학습 프로세스에 대해서 이해가 안갑니다.
Q4-2. 방향 벡터라는 것이 무엇에 대한 방향 벡터인가요?
Q4-1. Deep Reinforcement Learning (DDPG) 섹션에서의 그림이 아키텍쳐 같은데…. 작성하신 글과 맵핑이 되지 않는 부분들이 있어 이해하기가 어려운 것 같습니다.
안녕하세요 영규님, 좋은 리뷰 감사합니다.
저희 팀이 이제 RL 태스크에 집중하기 시작했고 다들 처음이고 어려워하는지라 고군분투하고 있는데, 영규님 리뷰를 읽고 나니 어느정도 그림이 그려지는 부분도 생기네요. 특히 매니퓰레이션 작업에 있어서의 state와 action, reward의 값 자체가 어떤 요소들로 구성되는 지 잘 그려지지 않았었는데, 해당 논문의 방식을 통해 좀 엿볼 수 있었던 것 같습니다.
근데,, 제가 고봉밥 질문을 좀 들고왔는데,, 죄송합니다.
1. “각 time step마다 매니퓰레이터 개별 joint들이 encoder 정보 기반으로 low-level로 제어?”
–> 해당 부분에서 encoder 언급이 있길래 본 리뷰에서 encoder 설명이 나타나는 부분이 어디있을까 쭈욱 읽어봤는데 따로 찾을 수 없었습니다..ㅜ 해당 encoder는 어떤 부분에 구조적으로 포함된 것이며 이것이 어떤 인풋을 가지고, 어떤 아웃풋을 내뱉길래 개별 joint들에 대한 low-level 제어가 가능한지 추가 설명 부탁드립니다!
2-1. vision-based policy representation 부분 설명에서, RGB -> HSV 방식이 나오는데, 그 이유가 노란색을 인식하기 위해서라는 점이 잘 납득이 되지 않았습니다. RGB 말고 HSV space를 사용한 이유에 대해 추가 설명 부탁드립니다!
2-2. vision-based policy representation 부분 설명에서, 결과 이미지에서 노이즈를 없애기 위해 dilation, erosion 같은 morphological한 방식을 사용했다고 하는데, 그것이 해당 부분과 분리된 요소들을 하나의 객체로 어떻게 연결해준 것인지에 대해서도 궁금합니다!
3-1. State 부분 설명에서, 타겟과 ee 사이의 방향 벡터를 계산한 vision-based direction vector 가 결국 x,y,z에 대한 3차원 공간에서 8가지 공간으로 쪼개진 binary하게 이산화된 벡터라고 이해했습니다. 근데 workspace가 8가지 방향으로 나뉘어진 것이 마치, target 물체의 중심좌표를 기준으로 x,y,z축이 정의된 것으로 보이는데 제가 이해한 게 맞나요? 원래대로라면 x,y,z 라는 좌표계는 어떤 한 world혹은 base 좌표계로 고정되어 있어야하는 게 아닌가 해서요!
3-2. State 부분 설명에서, 목표탐지를 통해 target 물체의 중심좌표를 계산할 수 있다고 했는데, 목표탐지는 어떤 과정으로 이루어지게 되나요? 시뮬레이터면 gt처럼 주어지고, real-world라면 일반적인 object detection 후 bbox중심점 계산인가요?
4. action 부분 설명에서, state랑 action이랑 두 부류에 모두 joint의 각도변화량 내지는 각도값 자체가 들어가는 방식이 결국에 ee의 pose는 forward kinematics로 정의될 수 있기 때문인가요?
5. reward 부분 설명에서, reward 중에는 α,β 두 종류로 분류하여 구성한 것을 확인했는데, β 에 관해 한 가지 의견이 생각났습니다!(물론 17년도 논문인 점은 인지하고 있어서 추후 더 좋은 태스크들이 분명 나왔을 것이라고 생각합니다만) 저희 로보틱스팀은 realsense 등의 rgbd sensor를 사용해 카메라 셋을 구성했는데, 본 논문에서 언급하는 방식인 단순 카메라 중심과 목표 중심 간의 픽셀 차이, 즉 어떤 2d 정보보다는 , depth를 고려한 3d 정보가 맞지 않을까 생각합니다. 예를 들면 | ‘ee의 position(x,y,z)’ – ‘목표 중심의 position(x,y,z)’ | 로 설계하는 셈인거죠. 왜냐면 픽셀레벨의 2d정보로만 고려하면, ee가 목표중심과 x축 방향으로 충분히 멀리떨어진 상태일 땐, y혹은 z 축으로 아주 크게 움직여도 원근법에 의해 β값은 큰 변화가 없을 수 있고, 반대로 ee와 목표중심이 충분히 가까우면, 아주 조금만 움직여도 β값은 큰 변화가 생길 수 있을 것 같고, 이렇게 되면 누적기대보상의 분산도 커지면서, 최종적으로 학습 시 불안정한 경향성을 보일 것 같다는 생각이 들었습니다.
그런 이유에서 저는 본 논문에서 reward를 구성한 것이 굉장히 의미있고 중요한 과정이라고 생각되는데, 영규님은 state, action, policy, reward, DDPG network 중 어떤 부분의 구성이 가장 핵심 contribution이라고 생각하시나요?
고봉밥 질문 죄송합니다.. 나중에 저도 강화학습 리뷰쓰면 질문 왕창 달아주세요… 답변드릴게요. 감사합니다.