오늘 리뷰할 논문은 이미지-텍스트 사전학습 모델인 CLIP을 비디오-텍스트 검색(Video-Text Retrieval)으로 확장한 모델인 CLIP4Clip에 관한 것입니다. 저자는 CLIP의 강력한 멀티모달 표현력을 활용하면서도, 비디오라는 시간 정보를 가진 입력에 맞게 구조를 개선하고, 영상-텍스트 검색에서의 성능을 높이는 방안을 제안하였습니다.

- Conference: Neurocomputing 2022
- Authors: Huaishao Luo, Lei Ji, Ming Zhong, Yang Chen, Wen Lei, Nan Duan, Tianrui Li
- Affiliation: 1Southwest Jiaotong University, Microsoft
- Title: CLIP4Clip: An empirical study of CLIP for end to end video clip retrieval and captioning
1. Introduction
비디오-텍스트 검색(Video-Text Retrieval)은 대표적인 멀티모달 태스크로, 실제 웹 서비스에서도 많이 활용되는 중요한 기술입니다. 사용자가 특정 문장을 입력했을 때, 그에 대응하는 영상을 검색해주는 것이죠. 기존 Video-Text Retrieval 모델은 대부분 고정된 영상 피처를 사용하는 feature-level 방식이었으며, 표현력에 한계가 있었습니다. 반면 raw video를 직접 학습에 사용하는 방식은 계산량이 크다는 단점이 있었죠. CLIP처럼 이미지-텍스트 간 표현력이 뛰어난 모델이 등장하면서, 이를 비디오 도메인에 전이하려는 시도가 본격화되었습니다.
하지만 CLIP은 이미지 기반 모델이기 때문에, 영상 내 프레임 간의 시간적 관계를 학습하지 못한다는 한계가 있었습니다. CLIP 모델을 기반으로 하되, 영상을 구성하는 여러 프레임 정보를 효과적으로 텍스트와 정렬할 수 있도록 설계된 CLIP4Clip을 제안하였습니다. CLIP을 비디오 검색에 활용하기 위해 제안된 방법으로 이해하시면 좋을 것 같습니다. 구체적으로, 비디오와 텍스트 간의 유사도를 계산하는 다양한 방식 (parameter-free, sequential, tight type)과, 대규모 영상-텍스트 데이터셋(HowTo100M)을 활용한 post-pretraining을 통해 성능을 향상시키는 방법도 함께 제안하였습니다.
2. Method
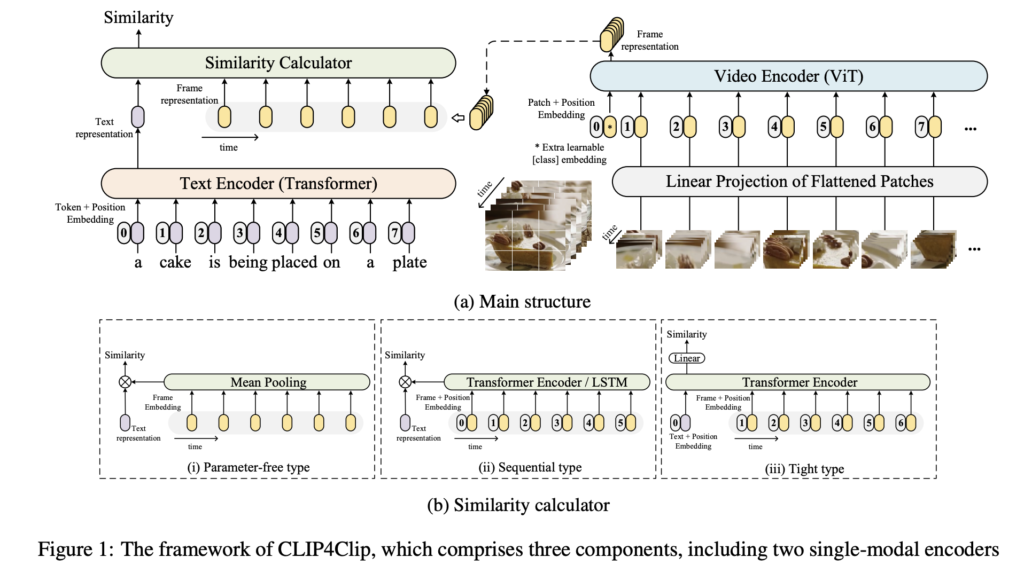
저자는 CLIP을 기반으로, 비디오-텍스트 사이 유사도를 계산할 수 있도록 확장한 CLIP4Clip을 제안하였습니다. CLIP4Clip은 크게 세 가지 구성 요소로 이루어져 있습니다: 텍스트 인코더, 비디오 인코더, 그리고 Similarity Calculator. 전체적인 구조는 상단 그림 1을 참고하면 이해가 쉬운데, 영상은 프레임 단위로 나눈 후 ViT 구조 기반 인코더를 통해 feature를 추출하고, 텍스트와의 유사도를 계산합니다.
2.1 Video Encoder
CLIP4Clip의 비디오 인코더는 CLIP에서 사용한 ViT-B/32 구조를 그대로 사용합니다. 영상은 여러 프레임으로 나뉘며, 각 프레임은 2D 패치 단위로 나뉘고, Linear Projection을 거쳐 Transformer에 입력됩니다. 이 과정을 통해 프레임마다 CLIP 스타일의 임베딩이 생성됩니다. 이 때, 저자는 시간 정보를 더 잘 반영하기 위해 두 가지 Linear Projection 방식을 실험하였습니다.

- 2D Linear: 각 프레임을 독립적으로 처리하는 방식 (CLIP 기본 구조)
- 3D Linear: 여러 프레임의 패치를 시간축을 따라 동시에 처리하여 temporal 정보를 반영하는 방식
결론을 정리하자면, 3D 방식은 시간 정보를 인코딩할 수 있다는 장점이 있지만, CLIP은 원래 2D 방식으로 학습되었기 때문에 성능 상 불리할 수도 있다고 합니다.
2.2 Text Encoder
텍스트 인코더는 CLIP의 텍스트 인코더를 그대로 사용하며, 마지막 [EOS] 토큰의 출력값을 텍스트 임베딩으로 사용합니다. 구조는 Transformer 기반이며, 총 12 layer, 8-head의 self-attention으로 구성됩니다.
2.3 Similarity Calculator
텍스트와 비디오 프레임 간의 유사도를 계산하기 위해, 저자는 세 가지 방식의 Similarity Calculator를 제안하였습니다.
Parameter-free type (Mean Pooling):
프레임별 임베딩을 단순 평균 내어 하나의 ‘평균 프레임 표현’을 만들고, 텍스트 임베딩과 코사인 유사도를 계산합니다. 새로운 학습 파라미터가 없기 때문에 작은 데이터셋에서도 안정적인 성능을 보일 수 있다는 장점이 있습니다. 수식은 아래와 같습니다.

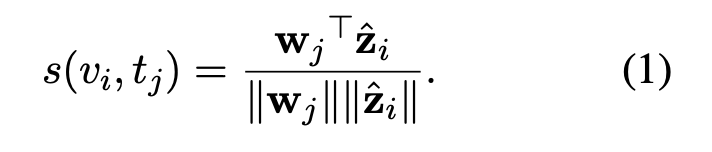
Sequential type (LSTM / Transformer):
프레임 간의 순서를 반영하기 위해 LSTM 또는 Transformer Encoder를 사용해 시간 정보를 인코딩합니다. position embedding을 추가하여 프레임 시퀀스를 순차적으로 학습한 뒤, 평균 풀링을 적용해 유사도를 계산합니다. 이후 계산은 Mean Pooling 방식과 동일합니다.
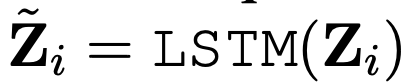
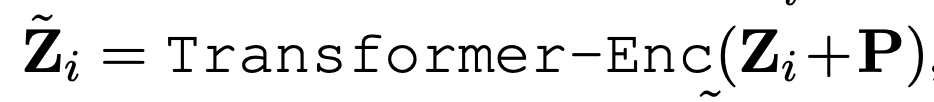
Tight type (Cross-modal Transformer):
영상과 텍스트 임베딩을 하나의 시퀀스로 concat한 후, 멀티모달 Transformer를 통해 유사도를 직접 학습합니다. 가장 많은 파라미터가 추가되며, cross-attention 과 같은 형태가 되죠. 아래 수식에서 U_i가 바로 concat 입력이되고, 이후 Transformer Encoder를 통과시켜 얻은 첫 번째 토큰 \tilde{U}_i[0]을 기반으로 유사도를 계산합니다.
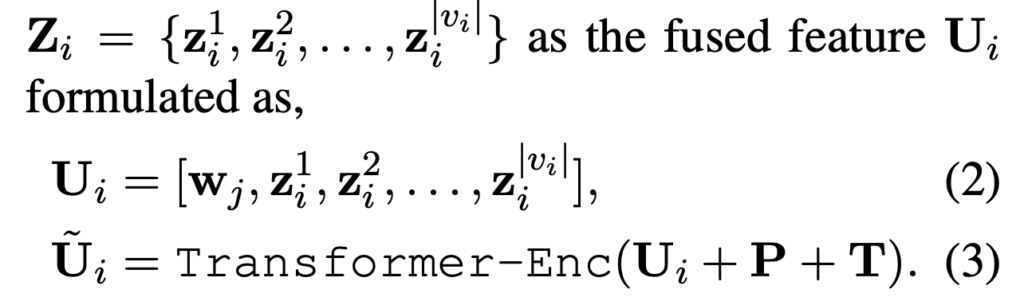
다만 저자는 이 방식은 학습 파라미터가 많기 때문에, 데이터셋이 작을 경우 성능 저하가 발생할 수 있다고 합니다.
2.4 Training Strategy
CLIP4Clip은 비디오과 텍스트 간의 유사도를 학습하기 위해, 기존 CLIP 구조를 유지하면서도 비디오 입력에 맞춘 학습 전략을 적용하였습니다. 주요 학습 구성 요소는 크게 세 가지입니다: Loss Function, Frame Sampling, Pre-training.
2.4.1 Loss Function
학습은 Text-to-Video Video-to-Text 양방향 유사도를 동시에 고려하는 cross-entropy loss 기반으로 이루어집니다. 아래 수식에서 (4) 비디오→텍스트 유사도 기반 Loss (5) 텍스트→비디오 유사도 기반 Loss (6) 최종 Loss는 두 방향을 더한 형태

이처럼 양방향 유사도 정렬을 동시에 학습함으로써, 모델이 영상-텍스트 간의 정렬 관계를 더 안정적으로 학습할 수 있도록 설계하였습니다.
2.4.2 Frame Sampling
비디오는 여러 프레임으로 구성되어 있기 때문에, 전체 프레임을 모두 사용하기에는 계산 비용이 큽니다. 이에 따라 저자는 효율적인 학습을 위해 일정 수의 프레임만 추출하는 sampling 전략을 사용하였습니다.
- Head sampling: 영상 앞부분 프레임을 순서대로 선택
- Tail sampling: 영상 뒷부분 프레임을 선택
- Uniform sampling: 전체 영상 길이를 기준으로 균등한 간격으로 프레임 선택
실험 결과, 대부분의 데이터셋에서 Uniform 방식이 가장 안정적인 성능을 보였으며, Tail sampling은 성능이 가장 낮게 나타났다고 합니다. 이는 영상의 중요한 정보가 전체에 걸쳐 분포한다는 점에서, Uniform sampling이 더 나은 시각 정보를 담을 수 있음 나타낸다고 하네요.
2.4.3 Pre-training
기본적으로 CLIP은 이미지-텍스트 페어를 기반으로 사전학습되었기 때문에, 시간 정보를 포함한 비디오-텍스트 도메인에 바로 적용하기엔 한계가 있습니다. 이를 보완하기 위해, 저자는 비디오-텍스트 대규모 데이터셋인 HowTo100M 중 약 38만 개의 샘플을 활용하여 post-pretraining을 수행하였습니다.
이 때 사용된 학습 방식은 MIL-NCE Loss 기반의 contrastive learning입니다.
MIL-NCE는 Multiple Instance Learning Noise-Contrastive Estimation의 약자로, 하나의 문장이 여러 개의 프레임(또는 클립) 중 어떤 부분과 정확히 대응되는지를 모를 때, 이를 포괄적으로 학습할 수 있도록 설계된 loss입니다.
예를 들어, 긴 영상에 대한 캡션 하나가 있을 경우, 캡션과 정확히 어떤 클립이 정렬되는지는 불확실하죠. 이럴 때 MIL-NCE는 영상 내 여러 클립을 모두 candidate로 두고, 그 중 최소 하나는 positive pair일 것이라는 전제 하에 학습을 진행합니다. 즉, “이 문장은 이 영상의 일부 구간과 반드시 관련이 있을 것이다”라는 가정을 기반으로, 영상 전체를 구성하는 클립 중 가장 유사한 것을 정답으로 간주해 contrastive loss를 계산한다고 합니다.
이 방식은 긴 영상과 짧은 문장 간의 정렬이 불완전한 경우에도 학습이 가능하다는 장점이 있으며, 저자는 이를 통해 CLIP4Clip의 비디오 인코더가 영상 내 핵심 정보에 집중할 수 있도록 설계하였습니다. Post-pretraining은 주로 parameter-free 구조(mean pooling)에 적용되었으며, 실험 결과 zero-shot 및 fine-tuning 상황 모두에서 성능이 향상되는 것으로 나타났습니다.
3. Experiments
저자는 제안한 CLIP4Clip의 성능을 검증하기 위해 총 다섯 개의 영상-텍스트 검색 벤치마크에서 실험을 수행하였습니다: MSR-VTT, MSVD, LSMDC, ActivityNet, DiDeMo. 실험은 Text-to-Video Retrieval 기준으로 수행되었으며, 평가 지표로는 Recall@1, 5, 10, Median Rank(MdR), Mean Rank(MnR)를 사용하였습니다.
3.1 Dataset
저자가 데이터셋을 정리해줬기도 했고, Video-Text Retrieval 리뷰는 처음이기에 한번 데이터셋도 간략하게 다뤄보겠습니다.

- MSR-VTT: 가장 널리 사용되는 영상-텍스트 검색 벤치마크 중 하나. 총 10,000개의 영상 클립과 20만 개의 캡션으로 구성되어 있으며, 평균 20초 길이의 영상과 하나당 20개의 캡션이 제공. 학습에 9,000개, 테스트에 1,000개 영상.

- MSVD (Youtube2Text): 비교적 작은 규모의 데이터셋으로, 1,970개의 영상과 약 8만 개의 문장으로 구성. 각 영상에는 평균 40개 이상의 캡션이 존재하며, 짧은 문장들이 중심이라 zero-shot 또는 소규모 fine-tuning 성능을 확인하는데 많이 사용.

- LSMDC: 영화 장면 기반으로 수집된 대규모 데이터셋. 총 118,081개의 비디오-문장 쌍으로 구성되어 있으며, 비디오당 하나의 문장만 제공. 문장이 상대적으로 길고 복잡한 구조를 가지고 있어, 단순한 영상 설명을 넘어 구성적 의미 이해가 필요한 태스크.
- ActivityNet Captions: 한 영상 내 여러 segment와 각 구간에 해당하는 문장이 주어지는 paragraph-level 영상 설명 데이터셋. 총 20,000개 이상의 비디오 segment와 100,000개 이상의 문장으로 구성되어 있으며, 영상 하나가 여러 문장과 연결되기 때문에 Fine-grained retrieval 성능 평가 가능.

- DiDeMo: 모바일 환경에서 촬영된 짧은 영상으로 구성된 데이터셋. 각 영상은 6개의 temporal segment로 나뉘며, 각 구간마다 사용자 주석 기반의 문장이 포함. 다른 데이터셋과는 달리 구간 단위의 정렬 능력을 요구하기 때문에, Temporal Localization이 중요한 실험 환경.
3.2 Experimental Details
영상과 텍스트 모두 기존 CLIP의 사전학습된 인코더를 그대로 사용하며, 학습 시 두 인코더는 함께 fine-tuning되었다고 합니다. 학습 초기에는 CLIP의 표현력을 보존하는 것이 중요하다고 판단하여, 처음 몇 epoch 동안은 일부 layer만 학습하도록 하고 이후 모든 layer를 fine-tuning하는 방식으로 안정적인 학습을 진행하였다고 합니다.
3.3 Comparison to the State of the Art
저자는 제안한 CLIP4Clip이 기존 영상-텍스트 검색 관련 SOTA(State of the Art) 모델들과 비교해 얼마나 경쟁력 있는 성능을 가지는지를 평가하였습니다. 총 다섯 개의 벤치마크 데이터셋(MSR-VTT, MSVD, LSMDC, ActivityNet, DiDeMo)을 기준으로 실험을 수행하였습니다.
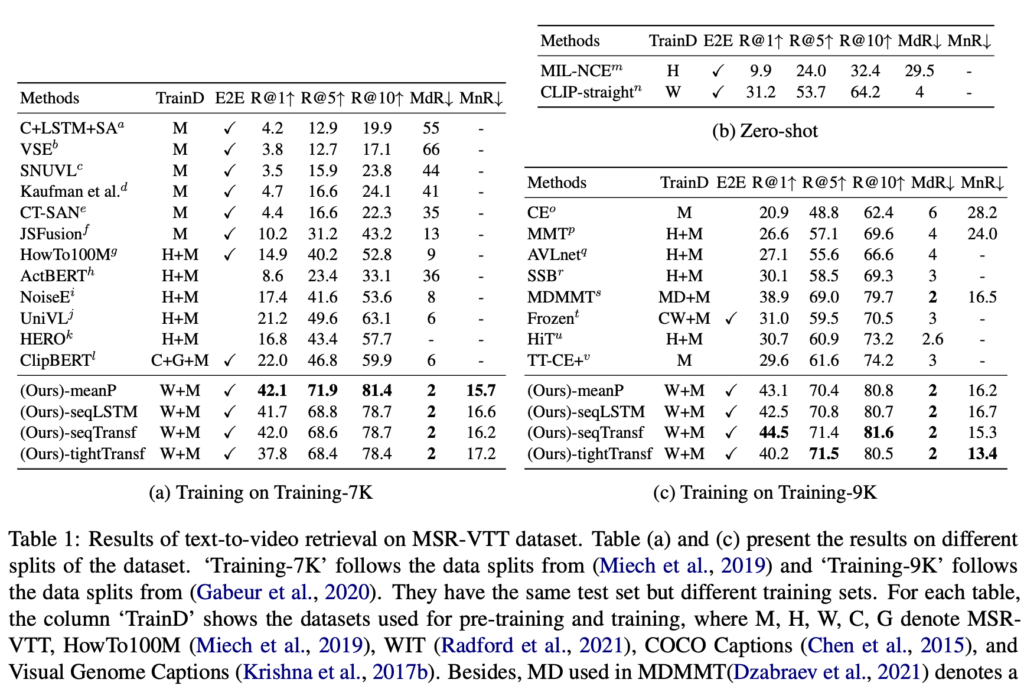
(상단 테이블 1) CLIP4Clip은 기존 모델들인 MMT, SupportSet, Frozen, ClipBERT 등을 모두 능가하는 성능을 보였습니다. 특히 seqTransf 구조는 R@1 기준 44.5를 기록하여, Frozen(30.9), SupportSet(30.1)을 큰 차이로 넘겼습니다. 저자는 이는 CLIP의 강력한 표현력과 시계열 정보를 반영한 구조 설계가 결합된 결과라고 설명하였습니다.
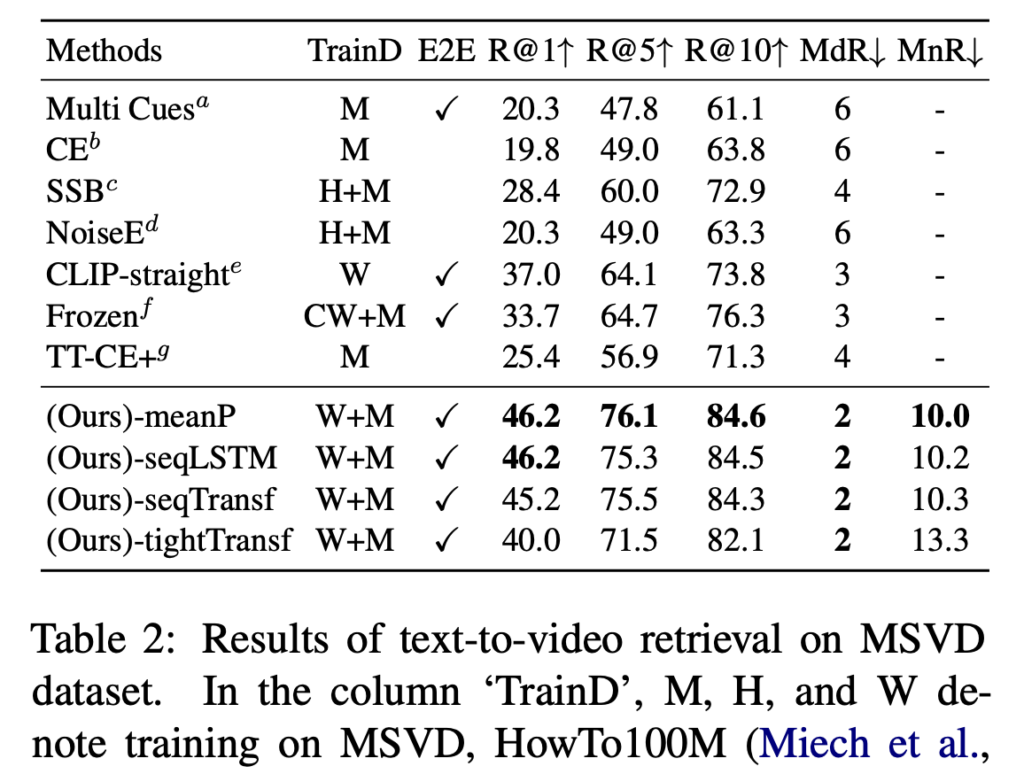
(상단 테이블 2) MSVD 데이터셋에서는 meanP 구조가 가장 높은 성능(R@1 46.2, R@5 76.1)을 보였으며, 기존 ClipBERT(22.0), SupportSet(30.1) 대비 큰 차이를 보였습니다. 소규모 데이터셋에서는 파라미터가 적은 구조가 더 효과적이라는 점이 실험을 통해 확인되었습니다.
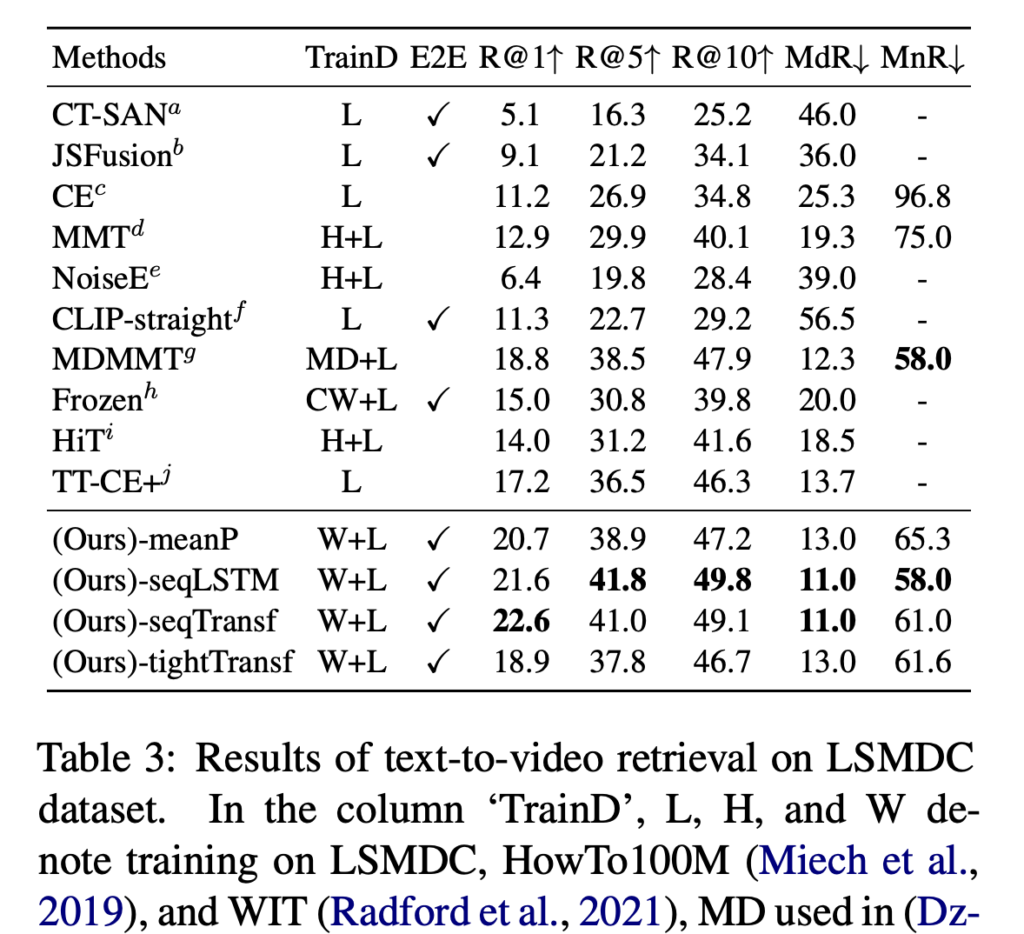
(상단 테이블 3) 기존 MDMMT, HiT 모델들보다 높은 R@1을 기록하였으며, seqTransf 구조가 22.6을 달성하여 가장 좋은 결과를 보였습니다. 단일 문장만 제공되는 데이터셋 특성상, 문장과 클립 간의 정밀한 정렬 능력이 중요하다는 점에서 CLIP4Clip의 구조적 강점이 드러났다고 볼 수 있습니다.
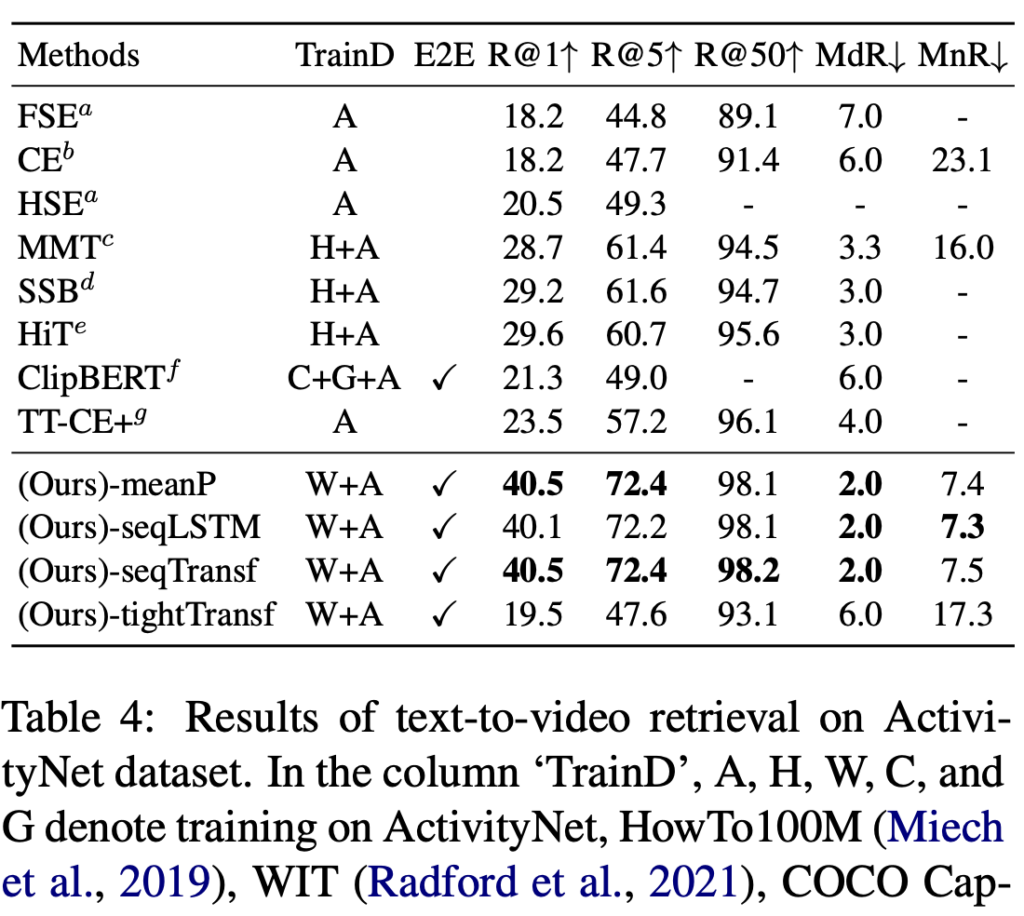
(상단 테이블 4) CLIP4Clip은 R@1 기준 40.5, R@5 기준 76.6, R@50 기준 98.2를 기록하였으며, SupportSet 및 W2VV++을 크게 앞섰습니다. 긴 영상과 복잡한 문장 구성에서도 안정적인 검색 성능을 보인 점이 인상적이었다고 합니다.
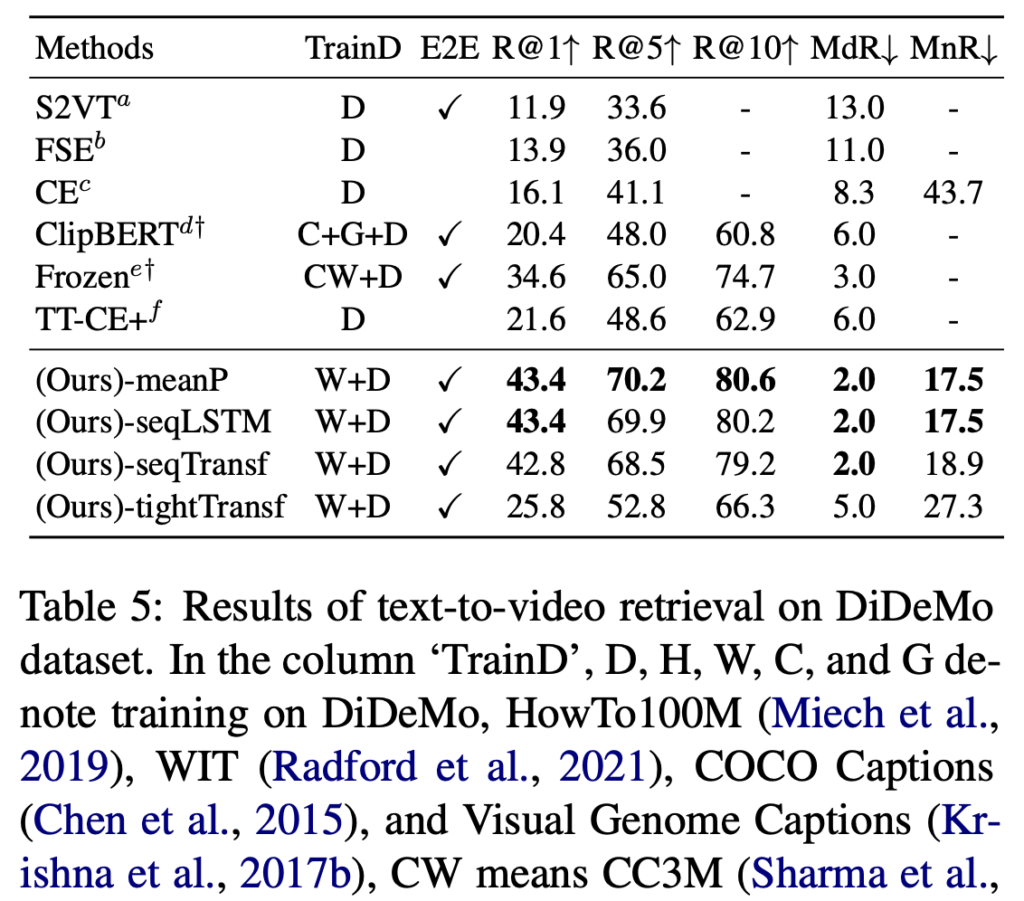
(상단 테이블 5) 기존 Frozen 모델은 R@1 기준 16.5였던 반면, CLIP4Clip의 meanP 구조는 25.0을 기록하며 큰 향상을 보였습니다.영상 내 temporal segment와 문장 간의 정밀한 매칭이 필요한 데이터셋에서도 효과적이라는 점을 보여주었습니다.
3.4 Post-pretraining on Video Dataset
CLIP은 이미지-텍스트 기반으로 사전학습되었기 때문에, 영상 내 시간 정보를 효과적으로 학습하기 위해서는 추가적인 pretraining이 필요합니다. 이를 위해 저자는 HowTo100M 데이터셋에서 38만 개의 영상-문장 쌍을 사용하여 post-pretraining을 수행하였습니다.
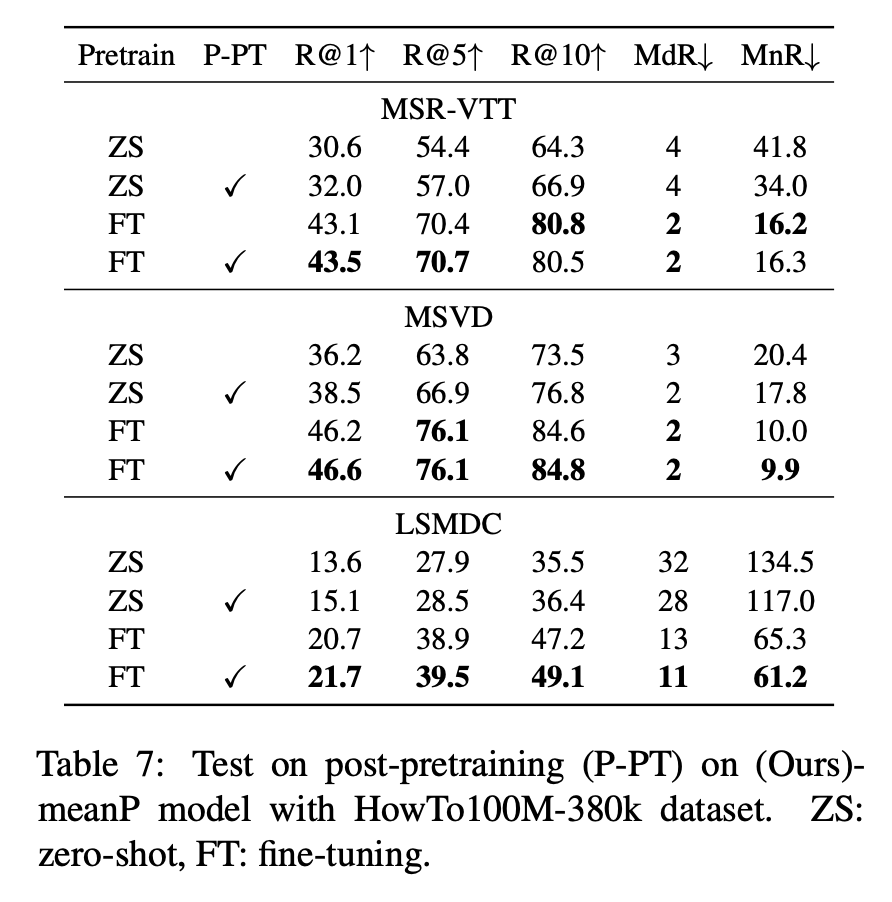
실험 결과, post-pretraining은 특히 zero-shot setting에서 큰 성능 향상을 가져왔습니다. MSVD ZS R@1 36.2 → 38.5 / LSMDC ZS R@1 13.6 → 15.1 Fine-tuning 후에도 소폭 향상되었으며, 기존 표현력 손실 없이 시간 정보 학습이 가능하다는 점을 보여주었습니다.
3.5 2D/3D Patch Linear
영상 입력을 Transformer에 넣기 전, 각 프레임의 시각 정보를 어떤 방식으로 패치화하고 투영할 것인지를 결정하는 것도 중요한 요소입니다. 저자는 두 가지 방식을 비교하였습니다:
- 2D Patch Linear: 각 프레임을 독립적으로 처리 (CLIP 원 구조)
- 3D Patch Linear: 시간축을 포함하여 여러 프레임을 동시에 처리해 temporal 정보를 반영
3D 방식은 시간 정보를 직접 인코딩할 수 있는 장점이 있지만, CLIP은 원래 2D 구조로 학습된 모델이기 때문에 새로운 방식이 오히려 표현력을 저해할 수 있는데, 이는 실험을 통해 확인할 수 있었습니다.
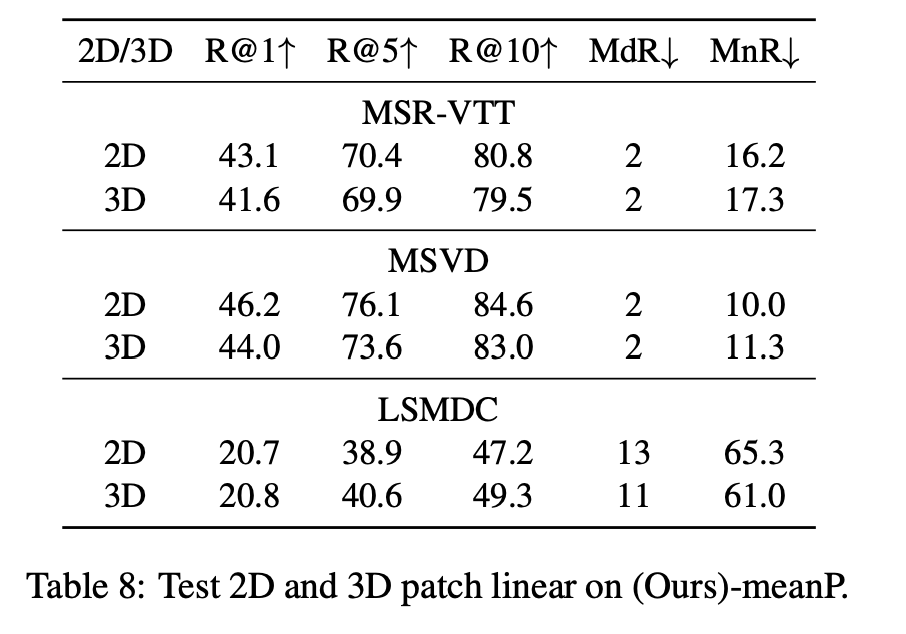
MSR-VTT 기준, 2D 방식이 R@1 43.1을 기록한 반면, 3D 방식은 41.6으로 성능이 하락하였고, 다른 데이터셋에서도 비슷한 경향이 나타났습니다. 저자는 이 결과를 통해, CLIP의 사전학습된 표현력을 활용하려면 2D 구조를 유지하는 것이 현재로서는 더 효과적이라는 결론을 내렸습니다.
4. Conclusion
본 논문은 이미지-텍스트 사전학습 모델인 CLIP을 기반으로 하여, 영상-텍스트 검색(Video-Text Retrieval) 태스크에 효과적으로 확장한 CLIP4Clip을 제안하였습니다. 저자는 CLIP의 강력한 표현력을 그대로 유지하면서, 시간 정보를 포함하는 영상 입력에 적합한 구조로 조정하고, 다양한 유사도 계산 방식(parameter-free, sequential, tight)을 실험적으로 비교하였습니다. 실험 결과, CLIP4Clip은 MSR-VTT, MSVD, LSMDC, ActivityNet, DiDeMo 등 다양한 벤치마크에서 기존 SOTA 모델들을 능가하는 성능을 보여주었으며, 구조 선택에 따라 데이터셋 특성에 맞는 성능 최적화가 가능함을 확인하였습니다.
CLIP4Clip은 Video-Text Retrieval의 토대가 되는 백본으로 활용되고 있는 것 같아 리뷰하게 되었습니다. 이미지 중심의 CLIP 모델이 시간 정보를 포함한 비디오-텍스트로 자연스럽게 활용되기 위한 간단한 변형을 잘 보여준 것 같습니다.
좋은 리뷰 감사합니다. 리뷰 읽다 궁금한 점이 두 가지 생겨 질문 드립니다.
CLIP의 구조를 거의 그대로 활용해서 video-text 간 유사도를 계산할 수 있다는 점이 흥미롭네요. 여기서 궁금한 점이 있는데, frame sampling을 했다고 하더라도 동영상이기에 temporal 축으로 영상이 많아져 유사도를 계산하기 위한 feature의 차원이 너무 커지지 않을까 하는 생각이 드는데요, 보통 샘플링을 몇 프레임 정도 하게 되나요? 이 값은 고정된 하이퍼파라미터 값인가요 아니면 동영상 길이에 따라 가변적인 것인가요?
또, video retrieval 쪽 논문을 살펴보신 이유도 궁금합니다. 향후 해당 분야의 연구를 수행하실 계획이신건가요?
감사합니다.
1. 샘플링 시 Uniform sampling 방식을 기본으로 사용하며, 이는 비디오 전체 길이에 걸쳐 균등하게 프레임을 추출하는 방식입니다. 실험에서는 대부분 초당 1프레임 비율로 샘플링하며, 총 12프레임을 고정적으로 사용했다고 합니다. 따라서 이 프레임 수는 학습 시 고정된 하이퍼파라미터로 사용되며, 영상 길이에 따라 가변적으로 달라지는 구조는 아닙니다.
2. 네 올해는 해당 분야로 연구를 수행할 계획입니다. 당분간 계속 Video-Language 관련 멀티모달 연구를 계속해서 리뷰할 것 같구요
안녕하세요, 좋은리뷰 감사합니다.
제가 전반적인 흐름을 이해하지 못했을 수 있습니다만, transformer 의 input으로 들어갈 2D 및 3D path 임베딩 벡터들중에서 clip 의 구조에 맞는 2D 패치 임베딩이 현재로서는 더 효과적이라고 논문 결과가 보여주는 것 같습니다. 다만 3D 패치가 만들 수 있는 시간적 정보가 아무래도 video-text 의 관점에서 미래에는 쓰일 수 있다고 생각하시는지 궁금합니다. 단지 모델의 구조적 한계인지? 궁금합니다.
감사합니다.
우선 배경부터 설명드리면 3D patch는 2D 이미지에 추가적인 차원으로 시간축을 고려할 수 있다는 측면에서, 시간적인 연속성을 더 잘 포착할 수 있을 거란 가정에서 연구가 많이 수행되었습니다.
그러나 해당 논문에서는 실험 결과 기존에 많이 사용하던 3D patch보다는 오히려 2D patch 방식이 더 나은 성능을 보였습니다. 저자들은 그 이유를 CLIP이 2D 이미지 기반으로 사전 학습되었기 때문에, 3D 방식의 초기화가 충분히 안정적이지 않아서 학습이 어렵다고 분석하였습니다.
다만 저 결과를 기반으로 3D 방식이 무의미하다고 결론 내리기엔 비약이 크다 생각합니다. CLIP 기반 모델이 2D 중심으로 설계되어 있어 현재 구조에서 3D 정보를 효과적으로 다루기엔 한계가 있었던 것이고, 3D patch 기반의 사전 학습 모델이나 보다 강건한 3D 초기화 방법이 나온다면 해당 연구가 다시 주류가 될 가능성이 있겠죠. 특히, 비디오가 가진 연속적인 움직임이나 행동 정보는 시간 축 없이는 포착이 어려우므로… 최근 연구에서도 이런 시간에 대한 움직임을 잘 포착하려는 시도가 지속적으로 나오고 있는 것 같습니다.
안녕하세요 홍주영 연구원님! 좋은 리뷰 잘 읽었습니다.
CLIP이 이미지와 텍스트간의 관계를 잘 학습했던 것을 이용해 video-text retrieval에 적용했다는 점이 흥미롭습니다.
저도 궁금한 게 있는데요 시간 순서를 고려하기 위해서 2D 패치를 시간축으로 연결되는 패치들을 하나로 묶어 비디오 인코더에 전달한다고 이해했습니다. 이렇게 3D 패치로 들어가서 인코더 안에서 시간 순서가 고려되면서 패치간의 관계가 학습되는지가 궁금합니다. 또한 평가지표로 사용하는 Recall 뒤에 붙는 숫자 1, 5, 10이 무엇을 의미하는지도 궁금합니다.
감사합니다.
1. CLIP4Clip에서 시간 정보를 반영하기 위해 사용하는 방식 중 하나가 바로 프레임을 순차적으로 Transformer Encoder나 LSTM에 넣는 구조입니다. 이를 통해 각 프레임 간의 시간적 관계를 고려하며, 이를 Sequential Type Similarity Module이라 부릅니다. 입력된 프레임은 시간 순서대로 처리되며, positional embedding을 추가하여 시간축에서의 위치 정보를 반영합니다. 이 과정을 통해 Transformer 내부에서 시간 순서에 따른 패치 간 관계가 학습됩니다.
2. Recall@K (R@1, R@5, R@10*는 텍스트-비디오 retrieval task의 성능을 평가하는 지표로, 주어진 텍스트에 대해 정답 비디오가 Top-K 결과 안에 존재하는 비율을 의미합니다. 예를 들어 R@1이 43%라는 것은 100개의 텍스트 쿼리 중 43개는 정답 비디오가 가장 첫 번째로 검색되었다는 뜻입니다. R@5는 Top 5 안에, R@10은 Top 10 안에 포함되었는지를 나타냅니다. 정확도와 비슷하게 숫자가 클수록 더 좋은 성능을 의미합니다.