
안녕하세요. 이번 주 x-review도 태스크별 대규모 로봇-액션 데이터를 이용한 학습이나, 환경 모델에 기반한 강화학습없이, 파운데이션 비전-언어 모델인 VLM(GPT4V)을 활용하여 instruction이 들어왔을 때 prompt engineering과 python action code generation 기반의 Robot Manipulation을 보이기 위한 연구입니다. 기본적으로 저희 팀에서 수행하고 있는 미니챌린지의 베이스라인인 VoxPoser[CoRL23, 23년 11월]를 해당 논문에서도 베이스라인으로 삼았단 점에서 좀 관심있게 살펴보게 되었습니다. 리뷰시작하겠습니다.
1. Introduction
일반화된 작업을 수행하기 위한 로봇 개발에는 중요한 점을 크게 두 가지로 나뉘어 설명해볼 수 있습니다. 먼저 로봇이 어떤 작업을 수행할 때 큰 레벨에서 작업을 분해하고 단계별로 뭘 해야할 지 생각하는 “high-level task planning”, 그리고 분해된 각각의 sub-task들에서 로봇 joint 및 gripper 운동에 의한 정밀한 action에 초점을 맞춘 “low-level robotic control”이 되겠습니다. 이 일반화된 매니퓰레이션 관련 연구들이 대개 이런 굵직한 흐름을 따라가고 있는 추세인데, 이것들의 기반은 사실 거대한 웹규모 데이터셋으로 사전학습된 Foundation model 및 LLM의 등장으로 이루어졌다고 해도 과언이 아니겠습니다. 이것들을 로봇연구에 적용하고자 하는 시도가 많이 늘어났고 실제로 능력이 좋으니 이를 기반으로한 연구들(SayCan, InnerMonologue 등)이 속속들이 생겨났는데요. 근데 이런 방법론들은 “high-level”의 측면만을 강조해서 다루는 경향이 있었습니다. 또 이와는 반대로, Imitation Learning이나 Reinforcement Learning를 접목한 연구같은 경우는 “low-level”에 집중한 경우로, 작업별로 정책을 각각 설계하는 데 집중되어 있습니다. 그러다보니 이전에 경험하지 못한 작업 시나리오가 등장하면 실패하기 쉬웠죠. 심지어는 Rt-1, Rt-2와 같은 대규모 로봇-action 데이터로 사전학습된 VLA 모델들의 경우에도 이전에 접하지 못한 환경에서는 어려움을 겪어왔습니다.
이를 좀 정리해서 다시 생각해보면, 일반화 가능한 low-level 로봇 제어가 어렵다는 것인데, 본 연구는 해당 문제와 관련해서 인간의 물체 조작 관점의 이해부터 다시 생각해보게 됩니다. 예를 들어 망치질을 하려면 사람은 특정 망치에 대한 익숙함이나 이런 건 상관없이 망치를 보면 직관적으로 1. 손잡이를 잡고, 2. 타격면(망치머리)가 못과 정렬되도록 방향을 조정, 3. 타격. 이 순서로 행동을 할 수 있는데, 사실 이 과정은 작업에 필요한 물체 자체가 가지고 있는 물리적인 속성, 세상에 대한 광범위한 상식이 전제가 되어야 됩니다.
이런 사람의 사고흐름과 직관에 기반해서, Code as Policies와 VoxPoser의 경우 LLM의 풍부한 의미론적 사전 지식을 활용해서 low-level의 일반화된 제어까지 가능하도록 primitive control code policies, action code generation, CoT Prompt Engineering 기반의 방법론을 제안했었습니다. 하지만 예시로 입력되는 Prompt 자체에 크게 의존하게 되는 수밖에 없으며, 장면에 대한 피상적인 이해라는 근본적인 한계로 인해 정밀한 물리적 이해를 필요로 하는 작업에서는 실패하는 경우가 많았습니다. 실제로 저희 로보틱스 팀이 구현한 VoxPoser 베이스라인의 경우에도 RLBench 시뮬레이터 상에서는 꽤나 괜찮은 작업 성공을 보이지만, real-world로 작업 시도를 해보니 일단 Visual Grounding 능력이 떨어지고 복잡한 Instruction에 대해서는 Prompt 예시에서 본적이 없었기에 적절한 action code를 generation해내지 못하는 경우가 많았습니다.
본 연구는 이런 문제에 기반해서, 로봇에 보다 정밀한 물리적 이해를 부여하기 위해 GPT-4V를 잘 활용하여 로봇 매니퓰레이션을 수행하는 CoPa(Robotic Manipulation through Spatial Constraints of Parts)를 제안했습니다. 명칭에서 엿볼 수 있다시피, 대부분의 매니퓰레이션 작업은 물체의 부분에 집중하는 물리적 이해가 중요하다는 점에서, Coarse-to-Fine Grounding 모듈을 설계하여 활용합니다. 또한 GPT-4V의 물리적 이해와 해당 Grounding을 잘 연결해주기 위한 연결다리 기법(marking based visual prompting)을 활용하고, 공간 제약을 생성하여 low-level의 작업에서는 solver를 통해 로봇의 자세를 결정하게끔 합니다. 이 때 pose-to-pose 간의 전환에서는 기존 motion planning을 활용했다고 합니다.
본 연구의 기여는 다음과 같이 요약할 수 있습니다.
- VLM의 상식 지식을 활용하여 저수준 로봇 제어를 위한 새로운 프레임워크인 CoPa를 제안하며, 이는 최소한의 프롬프트 엔지니어링과 추가적인 학습 없이 open-set instruction과 object를 처리할 수 있음.
- real-world 실험을 통해 CoPa는 작업 관련 객체의 물리적 속성에 대한 정밀한 이해를 필요로 하는 조작 작업 능력을 갖추고 있으며, 베이스라인(Voxposer)을 크게 능가함.
- CoPa가 고수준 계획 방법과 원활하게 통합되어 복잡하고 장기적인 작업(예: pour over 커피 만들기 및 로맨틱 테이블 세팅)을 수행할 수 있음.
2. Methods
본 논문의 Methods에서는 A절에서 조작 작업의 정식화를 소개하고, B절의 작업 지향적 파지, C절의 작업 인지적 모션 계획과 같이 제안하는 프레임워크의 핵심 요소 두 가지를 상세히 설명합니다.
A. Promblem Formulation
대부분의 매니퓰레이션 작업은 크게 두 단계, 물체의 초기 파지와 작업을 완료하는 데 필요한 후속 동작으로 나눌 수 있습니다. 예를 들어, 서랍을 여는 작업은 손잡이를 잡고 직선으로 당기는 동작을 포함하며, 물컵을 집는 작업은 먼저 컵을 잡은 다음 들어 올리는 동작을 필요로 하게 됩니다. 여기서 영감을 얻은 본 연구는 Task-Oriented Grasping과 Task-Aware Motion Planning이라는 두 가지 모듈로 접근 방식을 구성합니다. 또한, 로봇 작업의 실행은 본질적으로 로봇 엔드 이펙터에 대한 일련의 goal pose를 생성하는 과정이라고 가정하기에, 인접한 goal pose 간의 전환은 모션 계획을 통해 달성될 수 있습니다.
언어 명령 l과 초기 장면 관측 O_0 (RGB-D 이미지)가 주어졌을 때, Task-Oriented Grasping 모듈의 목표는 지정된 관심 객체에 대한 적절한 파지 자세를 생성하는 것입니다. 이 과정은 P_0 = f(l, O_0)로 표현됩니다. 로봇이 P_0에 도달한 후의 관측을 O_1으로 표기합니다. Task-Aware Motion Planning 모듈의 목표는 파지 후 자세의 시퀀스를 도출하는 것이며, 이는 g(l, O_1) \longrightarrow {P_1, P_2, ..., P_N}으로 표현됩니다. 여기서 N은 작업을 완료하는 데 필요한 총 자세의 수입니다. 목표 자세를 획득한 후, 로봇 엔드 이펙터는 \text{RRT}^* 및 \text{PRM}^* 과 같은 motion planning 알고리즘을 활용하여 해당 자세에 도달할 수 있습니다.
B. Task-Oriented Grasping
Task-Oriented Grasping 자세를 생성하기 위해 본 연구에서는 먼저 파지 모델을 사용하여 파지 자세 후보를 생성하고, 새롭게 제안하는 파지 부분 Grounding 모듈을 통해 가장 실현 가능한 자세를 필터링합니다. 전체 과정은 아래 그림 3을 참고하시면 됩니다.
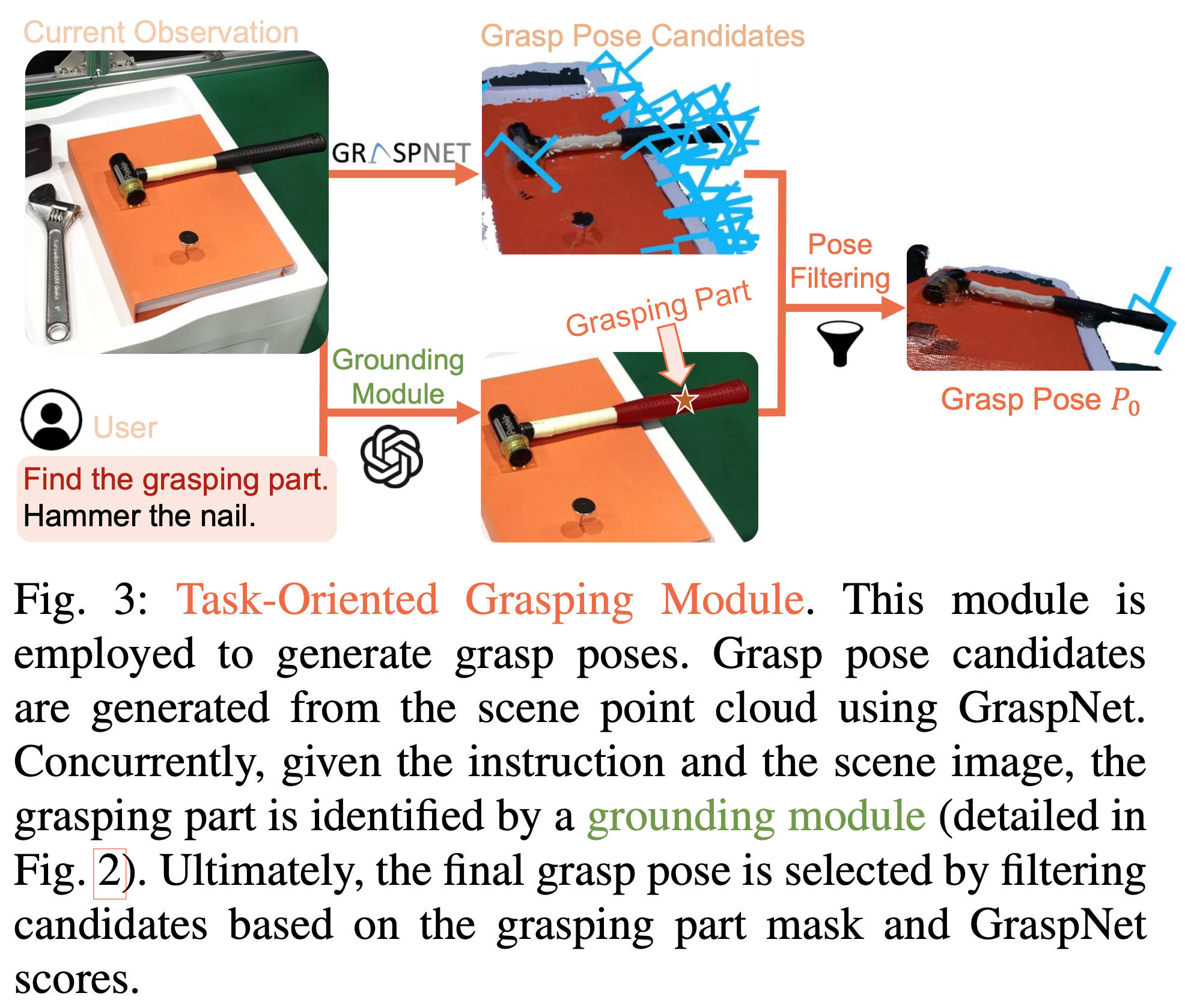
[Grasp Pose Proposals]
사전 훈련된 파지 모델을 활용하여 파지 자세 후보를 생성합니다. 이를 위해 먼저 RGB-D 이미지를 3D 공간으로 역투영하여 포인트 클라우드로 변환합니다. 변환된 포인트 클라우드는 사전학습된 GraspNet에 입력되고, GraspNet은 파지 점, 폭, 높이, 깊이, 파지 가능성을 나타내는 “grasping score”에 대한 정보를 포함하여 6DoF grasping proposal을 출력합니다. 하지만 GraspNet은 장면 내의 모든 잠재적 파지를 제공하므로 언어 명령에 명시된 특정 작업에 따라 최적의 파지를 선택하는 필터링 메커니즘을 사용하는 것이 필수적이게 됩니다.
[Grasping Part Grounding]
절단을 위해 칼을 잡을 때 칼날이 아닌 손잡이를 잡고, 컵을 집을 때 렌즈 대신 프레임을 잡는 것처럼, 인간은 의도된 용도에 해당하는 물체의 특정 부분을 파지합니다. 승현님이 자주 리뷰하시는 Affordance 개념이 이와 같다고 볼 수 있는데, 이 과정은 본질적으로 인간의 상식 지식의 적용을 나타냅니다. 이 상식을 모방하기 위해 본 방법론은 방대한 양의 상식 지식을 가진 GPT-4V와 같은 비전-언어 모델(VLMs)을 활용하여 파지할 물체의 적절한 부분을 식별합니다.
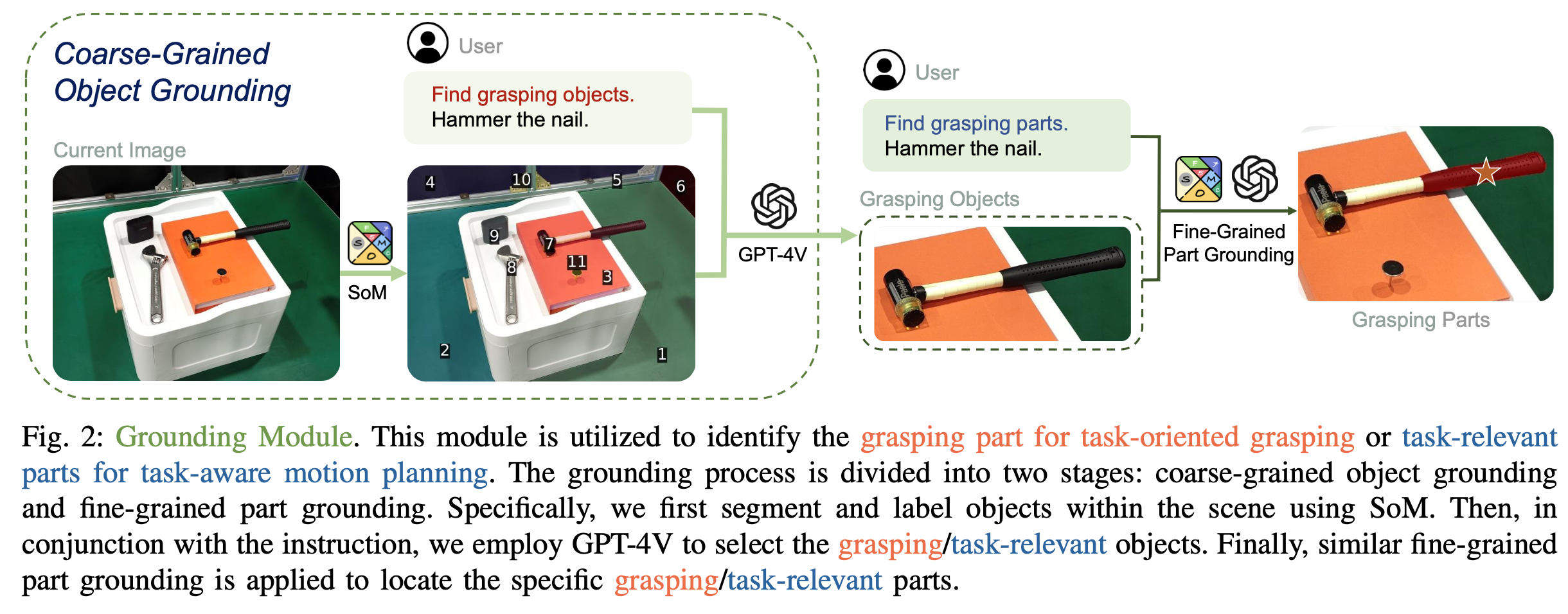
언어 명령을 파지에 적합한 물체의 특정 부분에 접지하기 위해 2단계 과정을 거치는데, 이는 coarse-grained object grounding과 fine-grained part grounding으로 이루어집니다. 위 그림 2.를 같이 보시면 되는데, 두 단계 모두에서 최근 visual prompting 메커니즘인 Set-of-Mark (SoM)을 활용합니다. SoM은 segmentation 모델(주로 SAM)을 활용하여 이미지를 개별 영역으로 분할하고 각 영역에 숫자 마커를 할당하여 VLMs에서 부족한 visual grounding 능력을 크게 향상시킵니다. coarse-grained object grounding 단계에서는 SoM을 객체 수준에서 활용하여 장면 내의 모든 객체를 감지하고 레이블을 지정합니다. 이후 VLMs는 사용자의 지시에 따라 파지할 목표 객체 (예: 망치)를 정확히 찾아내는 작업을 수행한다. 선택된 객체는 이미지에서 crop하고, 그 위에 fine-grained part grounding을 적용하여 파지할 객체의 특정 부분 (예: 망치의 손잡이)을 결정합니다.해당 coarse-to-fine 설계는 점진적인 미세한 물리적 이해 능력을 부여하여 복잡한 시나리오 전반에 걸쳐 일반화할 수 있도록 의도했다고 합니다. 마지막으로는, 파지 자세 후보를 필터링하고 모든 파지 점을 이미지에 반영하여 파지 부분 마스크 내에 있는 자세만 유지하도록 합니다. 그런 다음 이 중에서 GraspNet이 가장 높은 신뢰도로 뽑은 자세를 실행을 위한 최종 파지 자세 P0로써 선택하게 됩니다.
C. Task-Aware Motion Planning
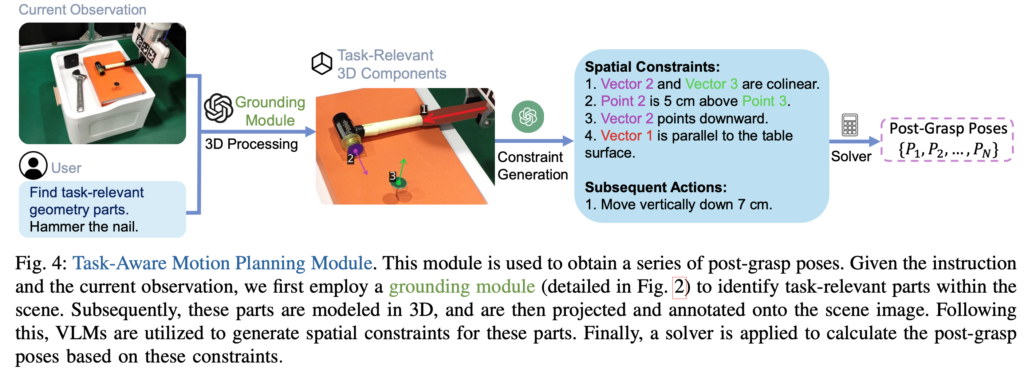
Task-Oriented Grasping를 성공적으로 실행한 후, 이제 파지 후 자세의 시퀀스를 획득하는 것을 목표로 하는 단계입니다. 해당 단계는 또 세부적으로 Task-Relevant Part Grounding, Manipulation Constraints Generation 및 Target Pose Planning의 세 가지 모듈로 나뉩니다. 전체 과정은 위의 그림 4에 나와 있습니다.
[Task-Relevant Part Grounding]
이전 Grasping part grounding 모듈과 유사하게 coarse-grained object grounding과 fine-grained part grounding을 사용하여 작업 관련 부분을 찾게 됩니다. 여기서는 여러 작업 관련 부분 (예: 망치의 타격 표면, 손잡이 및 못의 표면)을 식별해야 하고, 특히 로봇 팔에 대한 visual-marking 표시가 VLMs의 grounding에 영향을 미칠 수 있다는 점을 고려하여 로봇 팔의 마스크를 필터링하는 과정이 필요하다고 합니다.
[Manipulation Constraints Generation]
작업을 실행하는 동안 작업 관련 객체는 종종 다양한 공간 기하학적 제약 조건을 받습니다. 예를 들어, 휴대폰을 충전할 때 충전기의 커넥터는 충전 포트와 정렬되어야 하며, 병을 닫을 때 뚜껑은 병 입구 바로 위에 위치해야 합니다. 이러한 제약 조건은 본질적으로 객체의 물리적 속성에 대한 심오한 이해를 포함하는 상식 지식을 필요로 합니다. 그래서 VLMs를 활용하여 로봇이 조작하는 객체에 대한 공간 기하학적 제약 조건을 생성하는 것을 목표로 하게 됩니다.
먼저 식별된 작업 관련 부분을 간단한 기하학적 요소로 모델링합니다. 구체적으로, 가느다란 부분 (예: 망치 손잡이)은 벡터로 표현하고, 다른 부분은 표면으로 모델링합니다. 벡터로 모델링된 부분의 경우 scene 이미지에 직접 그려 넣습니다(SoM처럼). 표면으로 모델링된 부분의 경우는 중심점과 법선 벡터를 확인하고 2D 장면 이미지에 투영하여 표시합니다. 이렇게 주석처럼 기하학적 정보가 삽입된 이미지는 VLMs의 prompting 입력으로써 사용되며, 결과적으로 기하학적 요소에 대한 공간 제약 조건에 대한 description 정보(벡터와 표면 간의 수직성 등)를 얻습니다. VLMs에게 첫 번째 목표 자세에 필요한 제약 조건을 먼저 생성하도록 지시한 다음, 해당 자세에 도달한 후에는 필요한 후속 작업을 순차적으로 생성하도록 지시합니다.
[Target Pose Planning]
위에서 조작 제약 조건을 획득한 후에는, 이젠 파지 후 자세의 시퀀스를 도출해야 합니다. 이는 로봇 팔에 의해 조작되는 객체의 부분에 적용될 때 이러한 부분이 공간 기하학적 제약 조건을 충족하도록 SE(3) 행렬의 시퀀스를 계산하는 것과 같습니다. 조작 중인 객체 부분과 로봇 엔드 이펙터가 함께 강체를 구성한다고 가정하면 계산된 SE(3) 변환을 로봇 엔드 이펙터에 직접 적용할 수 있게 됩니다. SE(3) 행렬의 계산을 제약 조건이 있는 최적화 문제로 공식화하게 됩니다. 구체적으로는 각 제약 조건에 대한 손실을 계산한 다음 비선형 제약 조건 해결사를 사용하여 이러한 손실의 합을 최소화하는 SE(3) 행렬을 찾으며, 그림 4의 “벡터 2가 아래쪽을 가리킨다”는 제약 조건을 예로 들면, 손실은 SE(3) 변환 후 정규화된 벡터 2와 벡터 (0, 0, -1)의 음의 내적으로 정의할 수 있습니다. 첫 번째 목표 자세를 획득한 후 VLMs에서 지정한 작업에 따라 후속 자세를 해결하게 됩니다. 구체적으로는 각 후속 작업에 해당하는 새로운 자세를 순차적으로 계산하고 예를 들어, “수직으로 7cm 아래로 이동” 작업의 경우 단순히 현재 자세에서 z축에서 7cm를 빼게 됩니다. 이 과정을 통해 완전한 파지 후 자세 세트 {P1, P2, …, PN }이 생성되며, 인접한 자세 간의 전환은 motion planning 알고리즘에 의해 동작하게 됩니다.
3. Experiments
A. Experimental Setup
[하드웨어]
실제 탁상 환경을 구축하였습니다. Franka Emika Panda 로봇(7-DoF 암)과 1-DoF 평행 조(parallel jaw) 그리퍼를 사용하고, 테이블 양쪽 끝에 RGB-D 카메라(Intel RealSense D435) 2대를 장착하고 각각 calibration을 수행했다고 합니다.
[작업 및 평가]
물체의 물리적 속성에 대한 종합적인 이해를 요구하는 10가지 real-world 조작 작업을 설계하였다. 작업에 대한 그림은 아래 그림입니다. 각 작업에 대해서는 물체 유형 및 배열의 변경을 포함하는 10가지 다른 환경 변화에 걸쳐 모든 방법을 평가합니다.

[VLM 및 프롬프트]
OpenAI API의 GPT-4V를 VLM으로 사용합니다. 최소한의 퓨샷(few-shot) 프롬프트를 사용하려고 노력했으며 VLM의 장면 이해를 돕기 위해 CoT기법을 활용합니다.
[베이스라인]
foundational model을 활용하여 추가 학습 없이 폐루프 로봇 궤적(closed-loop robot trajectory)을 합성할 수 있는 방법인 Voxposer와 비교합니다. OpenAI API의 GPT-4를 LLM으로 사용하고, perception으로는 OVD인 Owl-ViT와 SAM을 활용했습니다.
B-1. CoPa for Real-World Manipulation
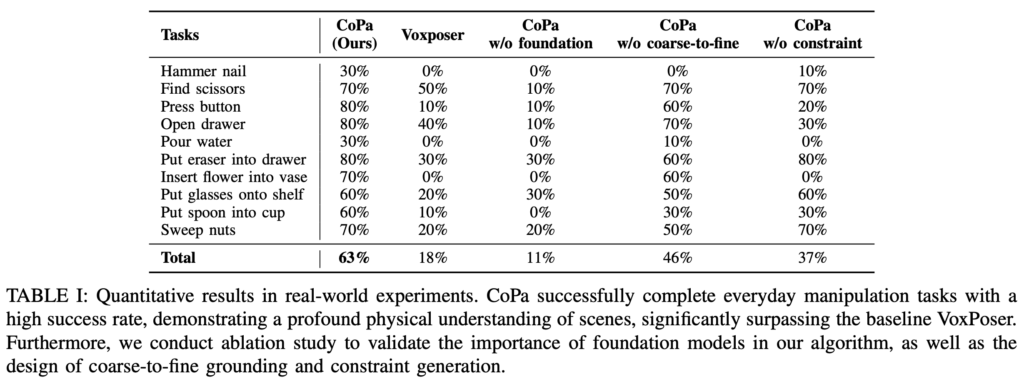
CoPa가 실제 조작 작업을 위한 로봇 궤적을 생성할 수 있는지 여부에 대한 정량적 결과입니다. CoPa는 10가지 작업에서 63% 작업성공률을 달성하여, VoxPoser 베이스라인 대비 매우 높은 성능 향상을 보였습니다. CoPa가 뛰어난 성능을 보인 핵심 요인은 part grounding과 constraints 조건 생성 단계 모두에서 물체의 물리적 속성에 대한 이해를 위해 VLM의 상식을 잘 활용할 수 있도록 연결고리로써 visual-prompting을 잘 줬기 때문이라고 저는 생각합니다. 예를 들어, 부분 접지 단계에서 CoPa는 “지우개를 선반에 놓기” 작업에서 지우개의 껍데기를 잡아야 한다는 점을 정확히 식별하고, “꽃을 꽃병에 꽂기” 작업에서는 꽃의 줄기와 꽃병의 림이 핵심적인 부분임을 인식했습니다. 또한 제약 조건 생성 단계에서는 “숟가락을 컵에 넣기” 작업에서 숟가락을 컵에 수직으로 넣어야 한다거나, “버튼 누르기” 작업에서 나무 막대를 버튼과 정확히 정렬해야 한다는 점을 이해했습니다.
B-2. Quantitative Result



C. Understanding Properties of CoPa

CoPa는 다음 세 가지 측면에서 중요한 이점을 보였습니다.
첫째, 세밀한 물리적 이해 측면입니다. 많은 로봇 조작 작업에서는 장면에 대한 미묘한 물리적 이해가 필요한데, 이는 물체의 부분을 세밀하게 구분할 뿐만 아니라 복잡한 물리적 속성까지 이해해야 합니다. CoPa는 이러한 측면에서 탁월한 성능을 나타냈으며, 물체의 큰 부분부터 미세한 부분까지 정확히 식별할 수 있는 모듈을 통해 잡기 및 작업 수행과 관련된 물체 부분을 선택했습니다. 또한 VLM을 통해 공간 기하학적 제약 조건도 효과적으로 설정했습니다. 반면 Voxposer는 장면 내 물체를 전체로만 인식하는 한계가 있었습니다. 이렇게 조잡한 수준의 이해는 정밀한 조작 작업에서 자주 실패로 이어졌습니다. 예를 들어, “꽃을 꽃병에 꽂기” 작업(그림 5 왼쪽)에서 CoPa는 꽃의 줄기를 잡는 반면 Voxposer는 꽃잎을 잡았습니다. 또한 “망치로 못 박기” 작업(그림 5 중간)에서는 CoPa가 망치를 못과 정확히 정렬했지만, Voxposer는 세밀한 물리적 제약 조건을 무시하고 망치를 단순히 단일 강체로 취급했습니다.
둘째, 간단한 프롬프트 엔지니어링 측면입니다. CoPa는 최소한의 프롬프트 엔지니어링만으로도 다양한 시나리오에서 뛰어난 일반화 가능성을 보였습니다. 실제 실험에서도 VLM이 정확히 역할을 이해하도록 하는 데 단 3개의 예제만 사용했습니다. 반면 Voxposer는 수작업으로 작성한 85개의 예제가 포함된 매우 복잡한 프롬프트에 의존했습니다. Voxposer의 추론 능력은 프롬프트에 크게 의존하여, 새로운 시나리오에 대한 일반화가 제한적이었습니다. 실제로 Voxposer의 프롬프트를 간소화하여 예제 수를 CoPa와 동일하게 3개로 줄이면 시스템 성능이 급격히 떨어져 평가된 모든 작업에서 거의 완전한 실패로 이어졌습니다.
마지막으로, 회전 자유도(DoF) 처리 측면입니다. 로봇의 조작 작업은 엔드 이펙터의 위치뿐 아니라 회전까지 정밀히 제어하는 능력을 요구합니다. 예를 들어, “물 따르기” 작업에서 주전자를 특정 각도로 회전시켜 물이 주둥이에서 잘 흘러나오도록 해야 합니다. CoPa는 장면 속 주요 물체 부분의 공간 기하학적 제약 조건을 고려하여 엔드 이펙터의 6-DoF 자세(pose)를 계산하고, 회전 자유도를 정확히 제어할 수 있었습니다. 그러나 Voxposer는 프롬프트 내 간단한 예제를 기반으로 LLM이 회전 자유도를 직접 지정하게 하였고, 출력 가능한 회전 값도 제한된 이산 옵션 중에서 선택하게끔 했습니다. 이러한 방식은 물체 간 동적 상호작용과 공간적 제약 조건을 제대로 반영하지 못했습니다. 실제 “숟가락을 컵에 넣기” 작업(그림 5 오른쪽)에서도 CoPa는 숟가락을 수직 방향으로 정확히 회전시켰으나, Voxposer는 로봇의 엔드 이펙터를 컵을 향해 잘못 배치하여 숟가락과 컵의 충돌을 유발했습니다.
D. Ablation Study
첫 번째로, CoPa w/o foundation에서는 기초가 되는 시각-언어 모델(VLM, GPT-4V)의 사용을 제거했습니다. 특히, 잡기 및 작업과 관련된 부분 접지 모듈을 개방 어휘 검출기인 Owl-ViT로 대체했으며, 제약 조건 생성 단계도 삭제하고 대신 사전 정의된 규칙 기반 방식으로 포스트-그랩(post-grasp) 자세를 계산했습니다(자세한 내용은 부록 참조). 표 I에서 확인할 수 있듯이, 이 접근법은 모든 작업에서 평균 11%의 성공률로 현저히 낮은 성능을 보였습니다. 이는 VLM 내에 내장된 상식적 지식이 매우 중요함을 강조하는 결과입니다. 예컨대 “견과류 쓸기” 작업에서는 VLM의 도움 없이 장면에서 어떤 도구가 쓸기에 가장 적합한지 판단하는 것이 매우 어려웠습니다.
두 번째로, CoPa w/o coarse-to-fine에서는 접지 모듈의 조잡한 부분부터 세밀한 부분까지의 설계를 제거하고, 대신 곧바로 세밀한 SoM과 GPT-4V를 사용해 장면 내에서 물체 부분을 직접 선택하도록 했습니다. 실험 결과, 조잡한 부분부터 세밀한 부분까지의 설계를 없애자 특히 중요한 부분을 정확히 식별해야 하는 작업에서 성능 저하가 크게 나타났습니다. 예를 들어 “망치로 못 박기” 작업에서는 이 설계가 없으면 망치의 타격면을 정확하게 찾지 못하여 성공률이 0%로 떨어졌습니다.
마지막으로, CoPa w/o constraint에서는 조작 작업의 제약 조건을 VLM이 생성하는 대신, 엔드 이펙터의 포스트-그랩 자세에 대한 숫자 값을 VLM이 직접 출력하도록 했습니다. 실험 결과에 따르면 대부분의 조작 작업에서 장면의 이미지로부터 정확한 자세 값을 직접 얻는 것은 매우 어려웠습니다. 예를 들어 “물 따르기” 작업에서 주전자를 올바른 자세로 기울이기 위한 정확한 값을 VLM이 직접 예측하는 것은 거의 불가능했습니다. 반대로, VLM이 제약 조건을 제시하고 이를 기반으로 포스트-그랩 자세를 계산하는 방식이 훨씬 더 실현 가능한 것으로 나타났습니다.
E. Integration with High-Level Planning

고수준 계획과 저수준 제어는 로봇 작업을 실행하는 데 있어 두 가지 중요한 별개의 측면입니다. 저수준 제어 프레임워크는 고수준 계획 방법과 원활히 결합될 때 복잡하고 장기적인 작업 수행이 가능합니다. 이러한 결합의 효과를 검증하기 위해 본 연구에서는 “푸어 오버 커피 만들기”와 “로맨틱 테이블 세팅”이라는 두 가지 장기 작업을 설계했습니다. 이 두 작업은 합리적이고 실행 가능한 단계로 정확히 분해되어야 할 뿐 아니라, 각 단계의 실행 시에도 작업과 관련된 물체의 물리적 특성을 깊이 이해해야 합니다.
구체적으로, 본 실험에서는 VILA라는 고수준 계획 방법으로 활용하여 전체적인 명령을 일련의 저수준 제어 작업으로 나누었으며, 이를 CoPa를 통해 순차적으로 실행했습니다. 일부 환경 롤아웃(rollout)의 예시는 그림 6에서 확인할 수 있습니다. 실험 결과, CoPa는 고수준 계획 방법과 성공적으로 결합하여 장기적인 작업을 효과적으로 수행할 수 있었고, 이를 통해 실제 로봇 응용 분야에서 이러한 조합이 가지는 잠재력을 입증했습니다.
4. Conclusions
본 연구에서는 로봇 조작 작업을 위한 포즈 시퀀스를 생성하기 위해 파운데이션 비전-언어 모델의 상식적 지식을 활용하는 새로운 프레임워크인 CoPa를 제안했습니다. CoPa는 별도의 학습 과정 없이 간단한 프롬프트 엔지니어링만으로도 효과적으로 작동할 수 있음을 보였습니다. 또한, 장면에 대한 정교한 물리적 이해를 바탕으로 CoPa가 오픈 월드 시나리오로 일반화되어 개방형 지시 및 객체를 처리할 수 있음을 확인했습니다. 더 나아가, CoPa는 복잡하고 장기적인 작업을 수행하기 위해 고수준 계획 알고리즘과 자연스럽게 결합될 수 있음을 제시했습니다.
Limitation으로는 먼저 CoPa의 복잡한 객체 처리 능력은 표면 및 벡터와 같은 단순한 기하학적 요소에 의존하고 있어 제약이 있습니다. 이는 모델링 과정에서 보다 다양한 기하학적 요소를 추가하면 개선될 여지가 있어보인다고 하며, 둘째, 현재 사용 중인 VLM이 대규모 2D 이미지에 대해서만 사전학습되어, 3D 물리 세계에 대한 실제적인 기반이 부족하다는 점이 있었습니다. 이러한 한계는 정확한 공간 추론을 저해하므로, 포인트 클라우드와 같은 3D 입력 데이터를 VLM의 학습 단계에 추가적으로 통합하는 방안을 통해 해결할 수 있을 것이라고 저자들은 말합니다. 마지막으로, 기존 VLM은 이산적인 텍스트 출력만을 생성하는 반면, 본 연구의 프레임워크는 객체의 좌표와 같은 연속적인 출력값을 필수적으로 요구한다는 점이 한계라고 합니다. 이러한 연속적인 출력 기능이 통합된 파운데이션 모델의 개발이 향후 매우 중요한 발전 과제가 될 것으로 기대했습니다.
안녕하세요 재찬님, 좋은 리뷰 감사합니다.
Task-Aware Motion Planning 에서 궁금한 점이 있는데요, 로봇 팔의 마스크를 필터링하는 과정은 어떤 식으로 처리를 하게 되는 건가요? 미리 정의된 gt 마스크가 있을까요?
또한 Target Pose Planning에 있어서 SE(3) 행렬에 대한 제약조건 최적화가 어떤 식으로 이루어지는 지에 대한 추가 설명부탁드립니다!!
안녕하세요 영규님, 좋은 질문 감사합니다.
1. 논문의 본문에는 없었고, appendix에 있었던 내용인데, Task-Aware Motion Planning에서 로봇 팔의 마스크를 얻는 과정은 일반적인 segmentation이나 학습 기반 방법이 아니라, 렌더링을 활용한 기하학적 방식으로 처리됩니다.
구체적으로는, 카메라 Extrinsic 파라미터(즉, 카메라의 위치와 방향)를 기반으로, 시뮬레이터나 렌더러에서 로봇의 URDF 모델을 해당 시점에서 카메라 뷰로 렌더링하고 이 과정에서 로봇이 현재 이미지에서 어떻게 보이는지를 얻어 낸 다음 이 렌더링 결과로부터 로봇 팔이 차지하는 마스크를 구한다고 합니다. 즉, 따로 ground-truth 마스크를 수작업으로 만들 필요 없이, 렌더링을 통해 자동으로 GT 수준의 마스크를 생성할 수 있는 구조라고 하네요.
2. 제가 appendix에 있던 descriptions of Constraints 와 그것과 상응하는 loss calculation식이 정해져있는 테이블을 같이 첨부하지 못해 생긴 질문같네요. 우선 Target Pose Planning에서의 SE(3) 행렬 제약조건 최적화는 좀 풀어서 설명하면, 로봇의 작업 수행 시 공간적 제약조건(예, 물체 표면 상의 벡터 A가 테이블 표면과 평행해야한다.)이 있다면 이를 만족하도록 로봇의 포즈인 SE(3)를 찾아야 하는데, 이 찾는 과정을 최적화 문제로 정의한다는 뜻이었습니다. 해당 최적화에 대한 알고리즘은 BFGS, Trust-Region 등을 사용했다고 하며, 최적화를 위해 공간적 제약조건에 상응하는 특정 Loss식을 정의했다고 합니다!