제가 이번에 리뷰할 논문은 MASt3R로, 네이버랩스 유럽에서 공개한 논문입니다. 실제로 데모를 실행해보았는데, 카메라에 대한 내부/외부 파라미터를 모르고 사용한 데이터 수가 굉장히 적은 상황에도 3D Reconstruction이 상당히 잘 되는 것 같습니다.

Abstract
3D Vision에서 이미지 매칭은 중요한 알고리즘으로, 근본적으로 카메라 pose와 기하학적 정보가 연관된 3차원 문제임에도 일반적으로 2차원 문제로 다뤄집니다. 이는 매칭의 목표가 2D 픽셀 사이의 대응을 설정하는 것이기 때문으로, 이에 대해 저자들은 잠재적인 위험이 있으며, 이를 위해 새로운 관점을 제안합니다. 저자들은 3D recunstruction(영상을 활용하여 3차원 장면을 재구성하는 연구) 프레임워크인 DUSt3R을 사용하여 3D 작업으로 매칭을 적용하는 방식을 제안합니다. pointmap regression을 기반으로 하는 해당 방식은 viewpoint가 변하는 경우의 매칭에 강인성을 보였으나, 정확도는 제한적이었고, 저자들은 이러한 강인성은 확보하면서도, 매칭 정확도를 개선하는 것을 목표로 하였습니다. 따라서 저자들은 dense한 local feature를 출력하는 새로운 head를 추가하여 DUSt3R 네트워크를 보완하는 것을 제안합니다.(DUst3R도 네이버랩스 유럽의 논문입니다) 또한, dense matching의 경우 복잡도가 증가한다는 문제를 해결하고자 fast reciprocal matching 방식을 제안합니다. 다양한 실험을 통해 해당 논문이 제안한 MASt3R이 기존 매칭 연구들의 성능을 능가함을 보였으며, 어려운 Map-free localization 데이터 셋인 VCRE AUC에서 기존 연구대비 크게 개선된 성능을 보였습니다.
Introduction
동일 장면에서 여러 시점에서 촬영된 이미지 사이의 픽셀간 대응을 구하는 이미지 매칭은 localization, navigaition 등 다양한 3D 비전 어플리케이션에서 중요한 알고리즘으로, 해당 논문은 이를 위해 두 이미지가 주어졌을 때 필셀간의 대응 쌍을 생성하는 것을 목표로 합니다. 특히, real-world로의 응용을 위해 시점과 조명 변화로 인한 어려움에도 강인하게 밀도 높고 정확한 매칭을 수행하고자합니다.
과거의 매칭 방식은 sparse한 keypoint를 추출한 뒤, 이에 대해 locally invariant한 feature인 descriptor를 생성하여 feature 수준에서 유사한 feature를 매칭하는 3단계 방식으로 이루어지는 것이 일반적이었습니다.(SIFT 생각하시면 됩니다.) 이러한 파이프라인은 계산 효율성과 조도 및 시점 변화에 강인하게 작동하여 COLMAP과 같은 3D Reconstuction에서 오랜시간 사용되어왔습니다. 그러나, 이러한 keypoint 기반의 매칭 방식은 매칭을 keypoint로 축소하므로써, 전체적인 기하학적 정보를 활용하지 못한다는 단점이 있습니다.
이러한 이유로 반복적이거나 texture가 부족한 경우에는 오류가 쉽게 발생하였으며, 이를 해결하기 위해 SuperGlue와 같은 연구들이 매칭 단계에서 사전학습된 지식을 활용하여 global optimzation을 활용하였으나, 이러한 방식은 keypoint와 descriptor가 충분한 정보를 가지고 있어야 한다는 선행 조건이 필요합니다. 따라서 이미지 전체에 대한 dense holistic matching을 수행하는 LoFTR과 같은 연구들이 제안되었으며, 이미지 전체의 대응점을 고려하기 때문에 반복적인 패턴이나 low texture에도 더 강인하게 작동하였습니다.
그러나, 이러한 방식 또한 Map-free localization 벤치마크 데이터 셋인 VCRE AUC에서 34%라는 저조한 성능을 보였으며, 이에 대해서 저자들은 매칭을 2D 이미지 매칭 문제로 접근하였기 때문이라고 주장합니다. 이미지 매칭 문제는 근본적으로는 3차원 문제이며, 서로 다른 두 이미지에서 대응되는 픽셀은 동일한 3D 포인트를 관찰하는 것이므로, DUSt3R과 같은 3D reconstruction 접근법을 활용할 것을 제안합니다. 이에 추가로, DUSt3R은 3D reconstruction을 위해 고안된 알고리즘이지만 Map-free localization 벤치마크에서 기존 keypoint 방법론들보다 뛰어난 성능을 보였음을 근거로 제시합니다.
해당 논문은 3D reconstruction에서 시점 변화에 강인한 성능을 보인 DUSt3R을 베이스로 활용하며, DUSt3R의 부정확성을 보완하기 위해 밀도 높은 local feature map에 대한 regression을 수행하는 head르 추가하고 InfoNCE loss로 학습하는 MASt3R를 제안합니다. 픽셀 수준의 정확한 매칭을 위해 다중 스케일에서 매칭을 수행하는 coarse-to-fine matching 방식을 제안하며, 각 매칭 과정에는 dense feature map에서 상호 일치하는 항목을 추출하는 작업이 포함됩니다. 이에 대해 저자들은 기존의 픽셀 수준의 매칭 방식보다 2배 정도 빠르고 정확한 알고리즘을 제안하였다고 합니다.
해당 논문의 contribution을 정리해보면
- 최신 3D Reconstruction 알고리즘인 DUSt3R 프레임워크를 기반으로 기반으로, 정확하고 시점 변화에 강인한 3D-aware maching 방식인 MASt3R 제안
- coarse-to-fine maching 방식을 제안하여 고해상도 이미지에 대한 빠른 매칭 작업 가능
- MASt3R는 여러 절대 및 상대 pose를 추정하는 localization 벤치마크에서 기존 성능을 크게 능가함
Method
카메라 파라미터가 알려지지 않은 두 카메라로 촬영된 2개의 이미지 I^1, I^2가 주어졌을 때, 픽셀의 대응관계 \{(i,j)\}, i=(u_i,v_i),j=(u_j,v_j)를 복구하는 것을 목표로 하며, 이때 일반화를 위해 두 이미지가 동일 해상도를 가지고 있다고 가정합니다. 이후 최종 네트워크는 종횡비를 고려하게 됩니다. 이에 대한 전체적인 프레임워는 아래의 Figure 2에서 확인할 수 있으며, 베이스라인으로 삼은 DUSt3R에 대해 먼저 설명한 뒤, 이미지 매칭을 위해 추가된 matching head와 이를 학습하기 위한 loss를 살펴보고, dense featuer map을 처리하기 위해 제안된 매칭 방식을 설명한 뒤(빠르게 매칭 작업 가능), 마지막으로 coarse-to-fine 매칭에 대한 설명합니다.
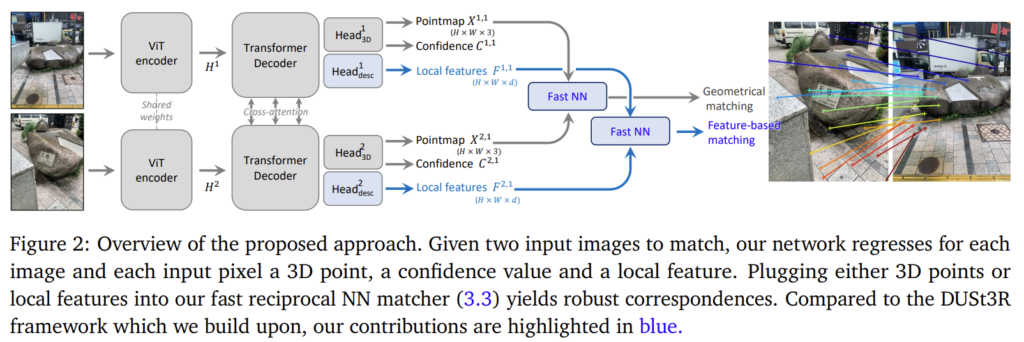
1. DUSt3R framework
DUSt3R은 서로 다른 두 이미지 I^1, I^2가 주어졌을 때 calibration과 3D reconstruction 문제를 함께 풀고자 하였으며, output으로는 2개의 dense한 pointmap X^{1,1}, X^{1,2}를 예측합니다. 여기서 pointmap X^{a,b}\in \mathbb{R}^{H×W×3}은 2D-3D 대응 관계로, I^a의 각 픽셀 i=(u,v)에 대응되는 카메라좌표계 C^b에서 표현된 3D Point X^{a,b}_{u,v} \in \mathbb{R}^3를 의미합니다. 즉, DUSt3R은 동일한 카메라 좌표계 C^1에 대한 두개의 pointmap X^{1,1}, X^{1,2}를 regression 으로 구하는 방식을 통해 calibration과 3D reconstruction을 해결하게 됩니다. 2개 이상의 이미지가 주어질 경우에는 global alignment 과정을 통해 모든 pointmap을 동일한 좌표계로 병합하게되며, 해당 논문에서는 2장의 매칭으로 한정하게 됩니다. (n개의 이미지가 주어지면 n*(n-1)번 pointmap을 만드는 과정을 수행하는 것 입니다.)
DUSt3R의 파이프라인은 다음과 같습니다. 두 이미지는 파라미터를 공유하는 ViT를 이용하여 H^1, H^2로 인코딩된 뒤, 시점과 장면에 대한 global 3D geometgry의 공간적 관계를 이해하기 위해 cross-attention으로 정보를 교환하는 두 개의 decoder를 통해 개선된 representation H'^1, H'^2를 생성합니다. 마지막으로, 두 개의 Head에 인코더로 추출한 feature와 개선되 representation을 함께 입력하여 최종 pointmap X^{1,1}, X^{2,1}과 confidence map C^1, C^2를 예측합니다. DUSt3R을 fully-supservised 방식으로 학습이 진행되었으며, 예측된 3D Point와 GT 3D Point 사이의 평균 거리로 오차를 계산하였으며 아래의 식으로 정의됩니다.
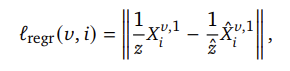
- v \in {1,2}: 시점
- \hat{} : GT
- z, \hat{z}: normlaization factor
이때, DUSt3R 저자들은 map-free localization과 같이 실제 크기 정보가 필요할 수 있으므로 scale invariance가 부적절할 수 있다고 보고, GT 3D Point가 실제 크기일 경우에는 z:=\hat{z}로 설정하여 아래와 같은 식이 되도록 합니다.
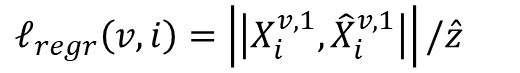
DUSt3R의 최종적인 loss는 confidence를 고려하여 아래의 식으로 정의가 됩니다.
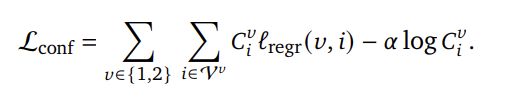
2. Matching Prediction Head and Loss
<Matching Head>
신뢰할만한 픽셀의 대응 관계를 얻기 위해 일반적인 방식은 scale invarient한 특징에 대하여 일치하는 것을 찾는 방식(descriptor에 대한 매칭)으로, DUSt3R에서 극단적인 시점변화가 있는 경우에도 잘 작동하지만 정확도가 제한적입니다. 이에 대해 저자들은 regression이 노이즈에 영향을 받고, DUSt3R이 매칭에 대하여 명시적으로 학습하지 않았기 때문으로 보았습니다. 저자들은 이러한 이유로 2개의 dense feature maps D^1, D^2 \in \mathbb{R}^{H×W×d}을 출력하도록 2개의 MLP 레이어로 구성된 matching head를 추가하였습니다.
<Matching Objective>
각 local descriptor가 장면상에서 동일한 3D 포인트를 나타내는 다른 local descriptor와 일치하도록 학습하기 위해 GT 대응 관계 \hat{\mathcal{M}} = \{ (i,j)|\hat{X}^{1,1}_i = \hat{X}^{2,1}_j \}를 InfoNCE loss에 활용합니다.
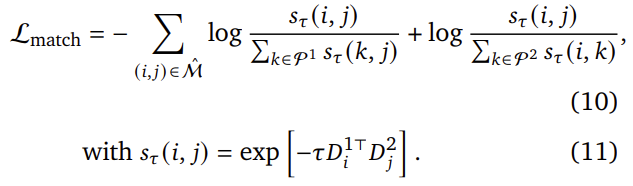
- \mathcal{P}^1=\{ i|(i,j) \in \hat{\mathcal{M}} \}, \mathcal{P}^2=\{ j|(i,j) \in \hat{\mathcal{M}} \}: 각 이미지에 대한 픽셀의 하위 집합
- \tau: temperature 하이퍼파라미터로, 스케일 조절
Matching loss를 통해 가까운 픽셀이 아닌 정확한 픽셀일 경우에만 보상을 받도록 하며, 이를 통해 dense matching의 정확도를 높입니다. 최종적인 loss는 pointmap에 대한 regression loss와 matching loss를 가중합하여 구하게 됩니다.
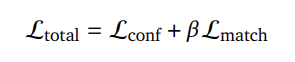
3. Fast Reciprocal Matching
앞서 추가한 matching head로 예측된 dense feature map D^1, D^2이 주어졌을 때, 신뢰할만한 대응 관계를 추출하는 것이 목표입니다.
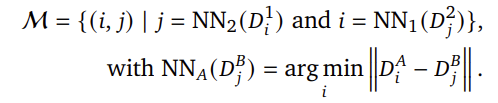
상호 매칭을 단순히 구현하면 모든 픽셀과 비교해야하므로 O(W^2H^2)의 계산 복잡도를 갖게 되고, 이는 dense feature map에 적용하기에는 너무 비효율적입니다. 따라서 저자들은 빠르게 상호 매칭을 수행하는 방식을 제안합니다.
<Fast Matching>
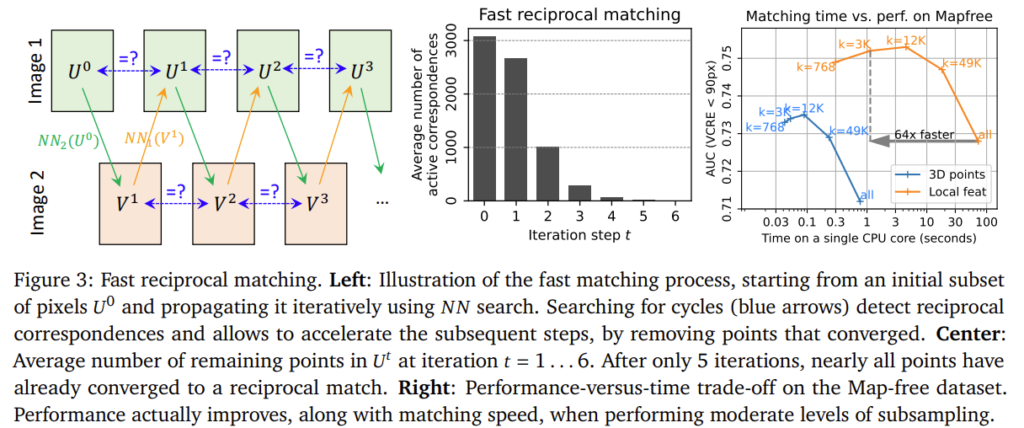
저자들은 sub-sampling을 기반으로 하는 빠른 매칭 방식을 제안합니다. 이는 k픽셀의 초기 sparse set U^0 =\{U^0_n\}^k_{n=1}로부터 시작하여 반복적으로 업데이트하는 방식입니다. 이미지 I^1의 그리드에서 균일하게 샘플링 된 후 각 픽셀을 이미지 I^2에서 Nearest Neighbor에 매핑하여 V^1을 구하고, 해당 픽셀을 동일한 방식으로 이미지 I^1에 매핑합니다.
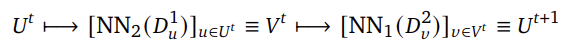
해당 과정을 통해 U^t=U^{t+1}인 상호 매칭 집합을 찾아낸 뒤, U^t에서 매칭이 되지 않은 픽셀들만을 이용하여 다시 해당 과정을 반복하고, V^t, V^{t+1}에 대해서도 동일하게 적용합니다. Figure 3의 왼쪽 이미지가 이에 대한 설명에 해당합니다. 또한, 중간의 그래프는 반복 횟수에 따른 U^t의 개수를 나타낸 것으로, 몇 번 반복으로도 빠르게 매칭이 이루어지는 것을 확인할 수 있습니다. 최종적으로 output은 모든 상호 매칭 쌍 집합이 됩니다.
이와같이 Fast Reciprocal Matching은 O(kWH)의 복잡도를 가지며, WH≫k 이므로 dense feature에 대하여 단순하게 모든 매칭을 고려하는 방식에 비해 속도가 크게 향상됩니다.
4. Coarse-to-Fine matching
ViT 계열의 모델은 attention 연산의 복잡도로 인해, 픽셀 이미지에 대해 O(N^2)로 연산 복잡도가 증가하게 되어, MASt3R는 최대 512 픽셀의 이미지만을 처리하게 됩니다. 이보다 더 고해상도인 경우에는 down-scale 후 연산을 수행한 뒤 다시 up-scale 하게 됩니다. 이러한 이유로 성능 저하가 발생할 수 있으며, 저자들은 저해상도로 대략적인 매칭을 찾고주변 영역을 고해상도로 바꿔 매칭하는 Coarse-to-Fine matchig 방식을 통해 정밀도를 높이고자 하였습니다.
먼저 두 원본 이미지를 k배 축소하고 매칭을 수행하여 coarse correspondences 집합 \mathcal{M}_k^0을 생성합니다. 원본 이미지에 50%의 겹침이 발생하도록 일정한 크기의 overlapping window crops W^1, W^2 \in \mathbb{R}^{w×4}를 만들고 두 이미지의 window들의 coarse correspondences가 90% 이상인 window 쌍 (w_1,w_2) \in W^1 × W^2을 찾습니다. 이후 선별된 window 쌍에 대하여 fast reciprocal Matching을 수행한 뒤, 매칭 결과를 원본 이미지 좌표계로 되돌려 병합하는 방식을 통해 효율적으로 고해상도에 대한 dense matching을 진행합니다.
Experimental results
<Traning>
학습에는 indoor및 outdoor, 합성 및 실제 데이터 등 다양한 14개의 데이터 셋(Habitat, ARKitScenes, BlendedMVS, MegaDepth, Static Scenes 3D, ScanNet++, CO3D-v2, Waymo, Map-free, WildRgb, VirtualKitti, Unreal4K, TartanAir, internal dataset)을 이용합니다. 이중 10개의 데이터 셋이 metric GT가 존재합니다.
(1) Map-free localization
Map-free relocalization benchmark는 map 없이 단일 reference 이미지가 주어졌을 때, 실제 공간에서 카메라의 위치를 파악하는 것을 목표로 하는 데이터 셋 입니다. 460개, 65개, 130개의 장면으로 구성된 train, validataion, test 셋으로 나누어져있으며, 각가 2개의 비디오 시퀀스로 구성됩니다. 또한 해당 데이터는 720×540의 저해상도라 (해당 논문은 512×384로 downscale함) 판단하여 coarse-to-fine을 수행하지는 않았다고 합니다. 또한 평가에 사용되는 VCRE(Virtual Correspondence Reprojection Error) 지표는 추정한 카메라의 3D 좌표와 GT 카메라 좌표로 point cloud를 투영시켰을 때 픽셀의 오차를 측정하는 방식입니다.
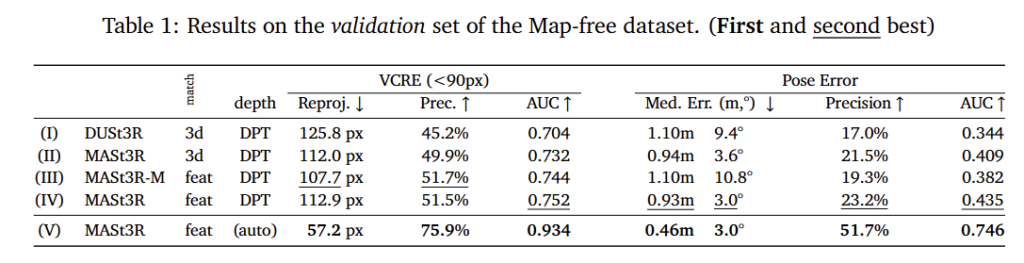
- Table1은 ablation study 결과로, 각 요소에 대한 효과를 리포팅하였습니다. 전체적으로 베이스라인으로 삼은 DUSt3R과 비교했을 때, MASt3R이 좋은 성능을 보이는 것을 확인할 수 있습니다. 이에 대해 저자들은 MASt3R이 더 많은 데이터로 학습되었기 때문이라고 설명하며, 2행과 4행의 결과를 통해 descriptor를 매칭하는 방식 보다 3D point에 대한 매칭이 더 좋은 성능을 보인다는 것을 어필하였습니다.
- 또한 3행은 matching loss \mathcal{L}_{match} 만을 사용하였을 때의 실험 결과로, DUSt3R에서 제안한 3D Point에 대한 loss \mathcal{L}_{conf} 를 고려하지 않음으로써 성능이 저하된다는 것을 보였습니다. 이를 통해 3D Reconstruction을 함께 학습하는 것이 매칭을 개선하는 데 효과가 있음을 이야기합니다.
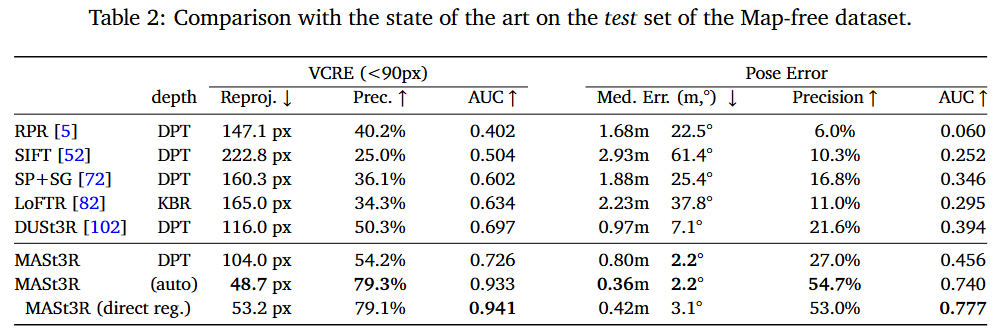
- Table2는 Map-free 데이터 셋에 대한 실험결과로, VCRE AUC에서 70% 이하의 성능을 보였던 SOTA 방법론인 DUSt3R에서 크게 개선된 93.3%의 성능을 달성하였습니다.

- 위의 Figure 4는 정성적 결과로, 시점 변화가 최대 180°로 큰 영상들에 대한 매칭 결과를 나타낸 것 입니다. 외관이 크게 달라졌음에도 MASt3R이 일치하는 영역들을 잘 찾고있다는 것을 어필하며, 기존의 2D 기반의 매칭을 적용하는 것으로는 이러한 상관관계를 유추하기 어렵다는 것을 어필합니다.
(2) Relative pose estimation
상대 Pose를 추정하는 작업은 CO3Dv2 데이터와 RealEstate10K 데이터 셋에 대하여 평가를 수행하였습니다. CO3Dv2는 37만개의 비디오에서 600만개의 프레임을 추출하였으며, 51개의 MS-COCO 카테고리로 구서되고, GT 카메라 pose는 COLMAP을 적용하여 얻습니다. RealEstate10k는 10000만 프레임의 유튜브 비디오 80만개의 클립으로 구성된 실내/실외 데이터셋으로, Bundle adjustment가 적영된 SLAM을 통해 GT 카메라 Pose를 얻습니다. 41개의 카테고리에 대하여 평가를 수행하며, 각 sequenece는 10프레임 길이로, 가능한 45쌍의 프레임 사이의 카메라 상대 Pose를 평가합니다. 평가에는 rotation과 translation에 대한 상대 오차가 임계치 이하인지를 판단하여 Accuracy (RRA/RRT)를 측정합니다.
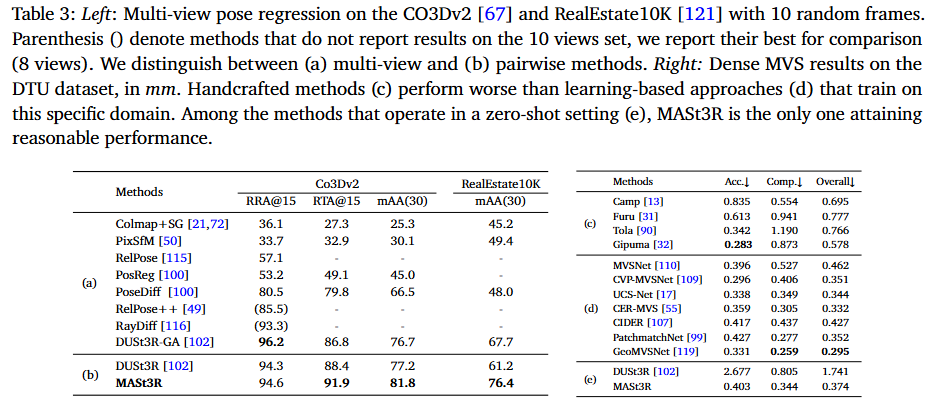
- Table 3은 상대 Pose에 대한 실험 결과로, SfM 기반의 방식들은 시각적 정보에 의존하여 view 변화가 큰 해당 실험에서 성능이 낮은 경향을 보이며, 3D 기반의 방식인 DUSt3R과 MASt3R은 높은 성능을 보입니다.
(3) Visual localization
Absolute Pose Estimation 성능을 Aachen Day-Night 데이터셋과 InLoc 데이터셋을 통해 평가합니다. Aachen Day-Night 데이터셋은 hand-held 카메라로 촬영된 4,328장의 reference 이미지와, 스마트폰으로 촬영된 824장의 주간(Day) 및 98장의 야간(Night) 쿼리 이미지로 구성되어 있습니다. InLoc 데이터셋은 viewpoint 변화가 큰 환경에서 아이폰7로 촬영한 329장의 쿼리 이미지로 이루어져 있으며, 9,972장의 RGB-D 이미지와 각 이미지에 대한 6D 포즈 정보가 포함되어 있습니다. 평가지표는 translation에 대한 임계치의 m 와 rotation에 대한 임계치의 °가 주어졌을 때, 임계치 이하의 오차가 발생한 경우를 정답으로 평가하여 localization의 성공 여부를 판단합니다. ( Aachen: (0.25m, 2°), (0.5m, 5°), (5m, 10°) / InLoc: (0.25m, 10°), (0.5m, 10°), (1m, 10°) )
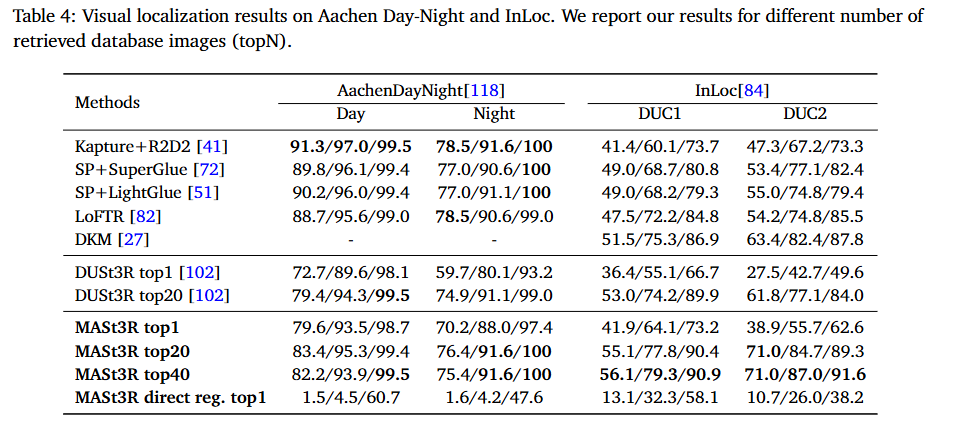
- Table4는 localization에 대한 실험 결과로, 기존 방법론과 비교했을 때 경쟁력 있는 성능을 보입니다. 항상 좋은 성능을 보이는 것은 아니지만, Top-1에 대해서도 성능 저하가 크지 않다는 것을 통해 신뢰할 수 있는 pose 추정이 가능하다고 어필합니다.
(4) Multiview 3D reconstruction
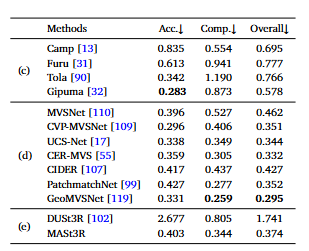
마지막으로 matching 쌍을 이용한 삼각측량으로 Multi-View Stereo Reconstruction을 수행합니다. 카메라에 대한 정보가 없이 영상만을 이용하며, DTU 데이터 셋으로 평가를 수행합니다. 다른 방법론들과 다르게 zero-shot 세팅으로 DTU 데이터에 대한 fine-tuning을 수행하지 않았으며, 이에 대한 실험 결과는 아래의 표와 같습니다.
안녕하세요, 좋은 리뷰 감사합니다.
DUSt3R에서 3D Point와 GT 3D 포인트 사이의 오차를 계산하는 식에서 z와 \hat{z}가 normalization factor라고 말씀해주셨는데, GT 포인트가 실제 크기가 아니라면 normalization을 해준다고 해도 scale invariance를 만족하지 못한다고 생각합니다. GT 포인트가 실제 크기가 아닐 경우에 이를 만족하기 위해서는 추가적인 처리를 해주진 않나요 ?
감사합니다.
질문 감사합니다.
GT 3D Point가 실제 크기일 경우에만 normalization을 수행하고,
아닐 경우에는 normalization factor를 적용하지 않은 위의 식을 이용하여 loss를 구하게 됩니다.
안녕하세요 승현님 리뷰 감사합니다.
dense feature map을 사용해서 matching head를 구성하면서 DUST3R와의 차이가 생기는걸로 이해했는데 이 과정에서 dense matching을 진행할 때 가까운 픽셀이 아닌 정확한 픽셀인 경우에만 보상을 받는다고 하셨는데 “정확한 위치일 때”만 보상을 받는것의 의미가 무엇인가요? pointmap의 regression loss를 보정하는데 사용되는걸까요??
질문 감사합니다.
우선 MASt3R은 두 이미지 A,B가 있을 때, A를 기준으로 pointmap \hat{X^}{1,1}과 B를 기준으로 pointmap \hat{X^}{2,1}을 만들어내게 됩니다. 이때, 두 pointmap이 일치하는 point에 대해서 loss가 줄어들도록 설계하였다는 점에서 정확한 위치일 경우 loss가 줄어들도록 설계된 것으로 이해하시면 될 것 같습니다.
좋은 논문 리뷰 감사합니다.
몇 가지 질문 남기고 가겠습니다.
Q1. Fast Reciprocal Matching에 대해서 이해가 잘 안갑니다… 아마 “sub-sampling 기반” 여기부터 이해를 못해서 인 것 같아요. sparse set U는 어떻게 구하는 걸까요?
Q2. 정략적 결과를 보면 (auto)부터 성능이 크게 향상되는 결과를 보여주고 있습니다. (auto)에 대해 추가 설명 부탁합니다.
Q3. 정략적 결과 중 direct reg의 성능이 극단적인 것 같아요. 특히나, visual localization에서 가장 낮은 경우, 1.5%… 이 정도면 feature matching에 실패한건데… 저자가 별 다른 설명이 없었나요? (아마 scale invariant 이야기 하지 않았을까 싶습니다)
Q3-1. direct reg가 실제 크기를 학습하는 것이 목표라고 했습니다… 사실 로봇 환경에서는 metric depth가 굉장히 중요하죠. 이를 쓸려면 direct reg를 써야하는 상황인지.. 아님 다른 전략이 있을지 궁금합니다.
질문 감사합니다.
A1. 우선 이미지에 대한 feature에서 매칭이 이루어집니다. sparse set U는 이미지의 feature를 균일하게 샘플링한 후 샘플링된 feature와 유사한 feature를 Nearest Neighbor를 통해 찾게 됩니다. 즉, 200×200의 이미지라면 이를 10픽셀간격으로 셈플링하여 20×20개의 feature에 대한 NN을 찾는 것으로 이해하시면 됩니다.
A2. 우선 depth가 DPT라 되어있는 결과가 DPT를 이용하여 metric scene scale 정보를 추론한 방식이고, auto라 되어있는 방식이 저자들이 제안한 방식입니다. 즉, 해당 논문에서 제안한 방식이 크게 성능 개선을 이룰 수 있었다는 것을 보였습니다.
A3. PnP를 사용하여 매칭 없이 MASt3R로 직접 regression을 수행한 결과로, 매칭 과정이 따로 이루어지지 않습니다. 해당 논문에서는 metric depth를 위해 direct regression뿐만 아니라 DPT 등의 모델을 이용하는 방식도 있는 것으로 이해하였습니다.
안녕하세요 승현님, 좋은 리뷰 감사합니다.
승현님이 옆자리에서 MASt3R demo 돌려보시면서 인터넷에서 가져온 에펠탑 사진 3장으로 3d reconstruction이 잘 되는 모습을 보여주셔서 충격먹었던 기억이 나네요. 질문이 몇가지 있습니다.
1. 해당 논문은 카메라 파라미터 없이도 인풋으로 이미지만 주어져도 dense feature matching을 이뤄낸 논문인데, DUSt3R framework에서 transformer decoder를 타고 나온 다음 head_3d 를 통해 pointmap이 예측되는 과정이 잘 이해가 되지 않았습니다. 인풋으로는 rgb밖에 없었는데 어떻게 3d pointmap을 예측할 수 있었던 것인가요?
2. DUSt3R의 framework 에서의 설명과 Fast Reciprocal Matching 부분 내용을 합쳐서 생각해 봤을 때 궁금한 점이 하나 생겼습니다. 2개 이상의 이미지가 주어질 경우엔 global alignment 과정을 통해 모든 pointmap을 동일한 좌표계로 병합하는 과정이 있어서, n*(n-1)번의 pointmap 병합과정이 필요한 것으로 이해했습니다. 그러면 인풋으로 들어오는 이미지가 많아질수록 연산속도 문제가 생길 것 같은데요. Fast Reciprocal Matching의 내용과 Fig3을 통해 이해한 바로는 sub-sampling 기반의 빠른 매칭방식으로 대략 6회 미만의 matching iteration으로도 2장의 인풋이면 매칭이 모두 이루어진다고 이해했는데, 인풋 이미지가 n개면 이게 어떻게 수행되는 건가요.. n*(n-1) 번의 매칭이 이루어지려나요..? 혹시 이 부분에 대해서 저자들의 언급은 없는지 궁금합니다!
3. Fast Reciprocal Matching으로 인한 속도개선이 contribution으로 생각되는데, 해당 sub-sampling 매칭 방법론은 gpu에서 이루어지는 연산이 아닌건가요? Fig3에 3번째 그림에서 CPU core라고 되어 있길래 여쭤봅니다!
감사합니다.
질문 감사합니다.
1. transformer decoder를 이용하여 각 픽셀이 3차원 point cloud 정보를 예측하도록 supervised 방식으로 학습을 진행하였기 때문에 예측이 가능하다고 이해하였습니다.
2. 우선 방법론 측면에서 조금 정리를 해드리자면, DUSt3R에는 global alignment 과정이 있고 MASt3R은 두 이미지 사이의 pointmap을 예측하여 global alignment 과정이 따로 없습니다. 두 이미지 사이의 pointmap을 예측하는 과정 자체가 n*(n-1)번 이루어진다는 것으로 이해하시면 됩니다. 이후, Fast Reciprocal Matching 과정은 pointmap을 예측하기 위해 두 이미지 사이의 대응되는 point들을 찾는 과정으로, sub-sampling 방식을 통해 속도를 개선하고자 한 것 입니다. 즉, n개의 인풋 이미지가 있으면, n*(n-1) 번 이미지들 사이의 대응 관계를 구하고, 두 이미지 사이의 대응 관계를 구하기 위해 매칭되지 않은 픽셀이 없도록 충분한(6번 이하) matching iteration 반복됩니다. matching iteration의 수는 이미지 마다 달라지는 것으로 5번 이후부터는 0에 해당한다고 실험적으로 확인한 것으로 보입니다.
3. 찾아보니 CPU core 단위의 시간은 특정 하드웨어(GPU 등)에 종속되지 않고, 성능을 상대적으로 공정하게 비교할 수 있게 해준다는 점에서 사용한 것으로 보입니다. 코드에서는 GPU로 돌아간 것으로 기억합니다..