안녕하세요, 이번주엔 3D Gaussian Splatting을 활용해서 로봇이 새로운 환경에서 효율적으로 물체를 조작할 수 있는 접근방식을 제안한 논문을 리뷰해보도록 하겠습니다. 1분 이내에 고품질로 장면을 재구성하고 여러 세팅의 태스크에서 현존하는 다른 방법론들 대비 훨씬 뛰어난 성능을 보인다고 합니다. 리뷰 시작하겠습니다. https://graspsplats.github.io/에서 작동 영상도 확인해볼 수 있습니다.
Introduction
저자는 로봇이 다양한 downstream appllication에서 zero-shot manipulation 을 원활하게 수행하기 위해서는 part-level grasp affordance를 dynamic 하게 이해하는 것이 중요하다고 주장합니다. 또한 정밀한 조작이 가능하려면, 로봇은 단순히 장면의 geometry뿐 아니라 semantic한 정보 까지도 잘 이해하고 있어야 한다고 합니다. 이러한 이해를 2D 영상 피처만으로는 얻기 어렵기 때문에, 2D와 3D 사이의 간극을 메우기 위한 최적화 과정이 필요합니다. 이 때의 대부분 모델들은 NeRF에 CLIP과같은 비전모델의 feature들을 임베딩해서 scene을 이해시키거나, point based method를 사용해 2D feature를 역투영해서 feature construction을 진행했지만, 각각 정적인 장면만을 이해할 수 있다는 점과 occlusion 문제를 가지고 있었습니다. NeRF 기반 방식들은 본질적으로 implicit하기 때문에 장면이 바뀔 때마다 유연하게 수정하기 어렵다고 합니다. 그 결과, 장면을 static한 상황으로 가정하게 되는 제한이 생깁니다. 3D Gaussian Splatting을 활용하는 다른 여러 연구들을 봤을 때 이렇게 모델을 학습시켜서 나타내는 방식이 아닌 점이 굉장한 이점인 것 같습니다.
이러한 문제들을 해결하기 위해 저자들은 GraspSplats라는 새로운 방식을 제안합니다. GraspSplats은 보정된 카메라로부터 촬영된 RGBD를 입력으로 받아, 3D Gaussian Splatting(3DGS라고 쓰겠습니다) 기법을 통해 장면을 고해상도로 재구성합니다. (이전에 리뷰했던 Feature Splatting을 기반으로 사용했다고 합니다.)이 때 GraspSplats 방식은 30초 이내에 장면을 재구성할 수 있다고 합니다.(앞에선 60초 이내라고 했던거 같은데 직접 해봐야 알 것 같습니다..) 이 덕분에 빠르고 정밀하게 part-level object tracking을 수행할 수 있다고 합니다. GraspSplats는 explicit Gaussian primitives을 직접 이용해 몇 밀리초 단위의 짧은 시간 안에 그립 제안을 만들어낸다고 합니다. 이 때 antipodal grasp generator를 사용했다고 합니다. (antipodal grasp generator는 추후에 찾아보도록 하겠습니다..)
3DGS는 명시적인 표현 방식을 가지고 있어 물체가 움직이는 상황에서도 고품질의 장면 표현을 유지할 수 있고, 이를 위해 point tracker를 활용해 rigid transformation을 반영한 장면 편집을 수행하고 scene을 일부분만 재구성 하는 방식으로도 최적화를 진행했다고 합니다. 결과적으로 기존 방식들보다 10배 이상 빠르게 작동하며, 이 덕분에 로봇 팔이 장면을 스캔하는 동시에 GraspSplats의 표현을 실시간으로 생성하는 것도 가능했다고 합니다. 이럼에도 불구하고 기존 NeRF나 Point기반 방법들보다 우수한 성능을 보였다고 합니다.
최종적으로 저자들이 제안한 contribution은 크게 세가지 입니다. 정확하고 효율적인 part 단위의 grasp affordance, 편집 가능한 고성능 scene 표현, 더 나아가 real robot에서의 zero shot 실험들입니다. 이 때 기존의 시간이 오래걸리던 NeRF기반이나 다른 point 기반 방법론들보다 우수한 성능을 보였다고 하네요. 좀 더 살펴보도록 하겠습니다.

Methods
우선 이 논문에서는 평행 그리퍼를 사용하는 로봇과, 손목에 장착된 RGBD 카메라. 제3자의 시점에서 장면을 볼 수 있는 외부 카메라를 가지고 있는 환경을 가정합니다. 로봇의 목표는 이러한 장면 내에서 다양한 물체들이 존재할 때 language query를 바탕으로 특정 물체를 집고 들어 올리는 것입니다. 예를 들어, 사용자가 ‘주방용 칼’이라는 쿼리를 주면, 로봇은 해당 물체를 인식하고 들어 올립니다. 추가적으로, 손잡이처럼 특정 부위를 명시한 part query도 함께 제공될 수 있습니다. 이런 식의 파트 지정은 특히task-oriented manipulation에서 중요하게 작용한다고 합니다.
여기서 주목할 점은, GraspSplats는 기존의 많은 방식들과 달리 장면이 정적(static)일 것이라는 가정을 하지 않는다는 점입니다. 기존 방식들은 물체가 움직이지 않을 것이라는 전제를 바탕으로 설계되었기 때문에, 실제 환경처럼 물체가 이동하거나 회전하는 경우엔 적용이 어려웠습니다. 반면, GraspSplats는 더 일반화된 알고리즘을 지향한다고 합니다. 즉, 물체가 움직이는 상황에서도 파트 수준의 grasping affordance와 그립 sampling이 지속적으로 이루어질 수 있도록 설계되어 있습니다. 이를 통해 실제 환경에서도 유연하게 작동할 수 있다고 합니다.
Feature Enhanced 3D Gaussians
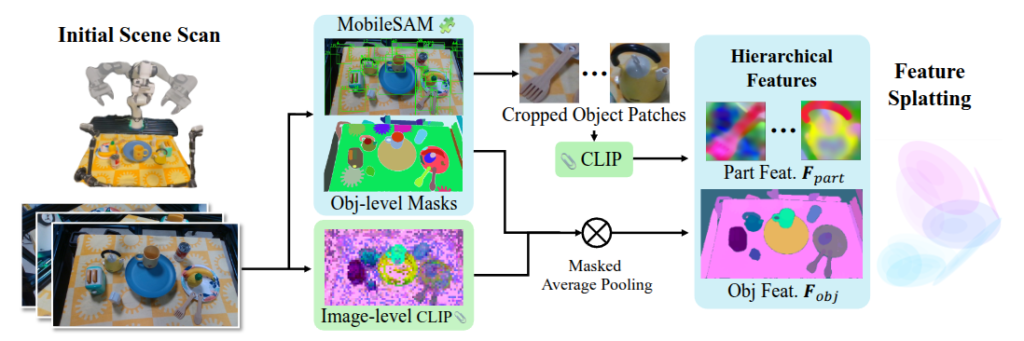
2D를 3D로 표현할 때 미분가능한 rasterization기법을 사용한다고 합니다. 이 과정에서 기존의 3DGS들 방법들과 차별화된 접근이 있다고 합니다. 기존의 3DGS관련 접근들은 cost가 높은 reference feature 계산과 SfM을 기반으로 하는 Gaussian을 고밀도로 바꾸는 과정이 존재했는데, GraspSplat에서 이 두가지 문제를 모두 해결했다고 합니다.
먼저 Initial scene scan 단계에서 초기 장면을 스캔합니다. 이 때 로봇에 부착된 RGBD 센서를 사용해 여러 시점에서 RGBD 이미지를 취득합니다. 이후 2D 이미지에서 MobileSAMV2를 통해 클래스에 의존적이지 않은 Bbox와 Mask를 생성합니다. 이후 Crop된 object patch들을 중심으로 Mask CLIP을 통해 이미지 전체에서 추출된 CLIP feature에 Masked Average Pooling 방식으로 정규화된 CLIP이 masking된 이미지를 얻을 수 있습니다. 이 때 Mask CLIP을 batch로 실행해서 효율적으로 추론할 수 있다고 합니다. 이 때 object 수준과 더 나아가 part 수준의 Hierarchial Feature들을 만들어내게 됩니다. 이러한 방식으로 계층적인 언어 기반의 grasping을 이해할 수 있는 빠른 3D Gaussian이 생성됩니다.
Static Scene : Part Level Object Localization and Grasp Sampling
GraspSplats는 제로샷으로 파트 단위 물체를 집기 위해 아래 그림과 같이 물체식별, 잡을 위치 식별, grasping의 세 가지 주요 단계를 거칩니다. 먼저, open vocabulary 상황에서 사용자의 쿼리를 입력받고 식별합니다. 예를 들어, 사용자가 “머그컵”이라고 입력하면, GraspSplats는 CLIP 기반의 피처를 활용해 장면 안의 3D Gaussian 중 해당 텍스트와 가장 유사도가 높은 Gaussian들을 식별합니다. 경우에 따라 “병은 아닌”과 같은 부정문 쿼리를 통해 제외할 대상을 지정할 수도 있다고 합니다. 기존의 NeRF 기반 접근법은 이러한 feature extraction과 질의에 많은 렌더링 비용이 들지만, GraspSplats는 명시적인 Gaussian 표현 위에서 직접 연산하므로 훨씬 빠르게 동작한다는 점을 또 어필합니다.
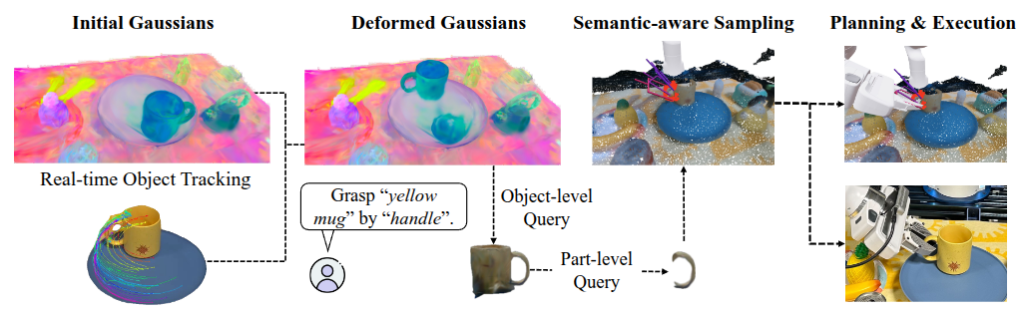
이후에는 Open-Vocaulary상황에서 Conditional part level querying이 진행됩니다. 예를 들어, “머그컵의 손잡이”와 같이 더 구체적인 부위를 집고 싶을 때 CLIP 모델은 여러 단어가 섞인 표현에 대해 각 단어의 의미를 혼합해서 반응하는 특성이 있기 때문에, 단순히 “mug handle”이라고 질의하는 것만으로는 정확한 부위 식별이 어렵습니다. 그래서 GraspSplats는 먼저 전체 물체(머그컵의 손잡이인 경우 머그컵)를 식별한 뒤, 해당 물체에 속한 Gaussian들만 대상으로 파트 쿼리를 다시 적용합니다. Gaussian을 crop하고 그 안에서 찾으면 더 잘 찾을 수 있기 때문에 이렇게 진행하는 것 같습니다.
마지막으로 실제로 로봇이 집을 위치를 제안하는 grasp sampling을 진행합니다. 여기서 GraspSplats는 GPG(Grasp Proposal Generator) 알고리즘을 활용해, Gaussian 표현 기반의 샘플링 방식으로 그립을 제안합니다. 먼저, 사용자가 지정한 물체의 특정 부위를 중심으로 작업 공간 R_obj를 정의합니다. 이 공간은 해당 Gaussian의 크기와 그리퍼가 충돌하지 않을 정도의 여유를 고려하여 설정됩니다. 이후 이 영역에서 N개의 포인트를 샘플링하고, 각 포인트 주변의 Gaussian들로부터 표면 법선 벡터들을 수집합니다. 이 법선 벡터들을 바탕으로 로컬 좌표계를 계산하고, 그리퍼가 어느 방향과 위치에서 접근하면 적절한 접촉이 가능한지를 평가합니다. 이때 단순히 겉보기 형상만을 고려하는 것이 아니라, Gaussian 표현이 제공하는 부드럽고 세밀한 표면 정보를 활용해, 손가락이 실제로 물체에 닿는 위치를 정밀하게 탐색한다고 합니다.
Dynamic Scene: Real-time Tracking and Optimization
GraspSplats는 장면의 semantic과 geometric 정보를 모두 학습한 표현을 사용하고 NeRF 기반과 달리 explicit하기 때문에, 이를 바탕으로 물체가 이동하는 상황에서도 실시간으로 3D 표현을 수정하고 추적하는 기능까지 자연스럽게 확장할 수 있었다고 합니다.저자는 multi-view 카메라 추적을 통해 추적하는 기능을 확장할 수 있었다고 합니다. 여기서 중요한 가정은, 카메라들이 고정되어 있어야(회전, 흔들림이 없음) 한다는 점입니다. 사용자가 “머그컵”이라는 언어 쿼리를 입력하면, GraspSplats는 해당 물체를 구성하는 3D Gaussian들을 식별하고, 이를 이용해 카메라 뷰에서 2D 마스크를 생성합니다. 이 마스크를 픽셀 단위로 나눠 point set으로 만든 후, 포인트 트래커에 입력하여 계속해서 2D 상에서 움직임을 추적합니다.
이렇게 추적된 2D 좌표들은 depth와 결합하여 3D 좌표로 변환됩니다. 이 과정에서 잡음이 섞인 포인트들도 생기기 때문에, GraspSplats는 DBSCAN 이라는 클러스터링 알고리즘을 이용해 outlier들을 제거하고, 신뢰도 높은 점들만 남긴다고 합니다. 그런 다음 남은 점들을 기반으로 Kabsch 알고리즘을 적용하여 물체의 이동을 계산합니다. Kabsch 알고리즘을 통해 3D 상에서 물체가 어떻게 회전하고 이동했는지를 표현하는 SE(3) 변환 행렬을 얻고, 이를 원래의 Gaussian 표현에 적용하여 물체의 새로운 위치를 반영한다고 합니다.
만약 여러 대의 카메라가 사용되는 경우라면, 각 카메라에서 얻은 3D 대응점들을 모두 결합해 Kabsch 계산에 반영하여 더욱 정확한 변환을 얻을 수 있다고 합니다. 이 과정은 반드시 로봇 팔이 물체를 움직였을 때만 작동하는 것이 아니라, 사람이나 외부 요인에 의해 물체가 이동했을 때도 문제없이 작동할 수 있습니다. (그냥 사람이 손으로 물체를 이리저리 움직여도 따라서 반영되는 모습을 볼 수 있습니다.) 이는 기존 시스템들이 자주 가정하던 “로봇이 직접 움직일 때만 물체 위치가 바뀐다”는 제약을 넘어서기 위한 큰 발전이라고 저자들은 주장합니다.
물체가 이동한 후에 장면 일부 (예를 들어 머그컵이 있던 자리에 가려져 있던 식탁의 경우에 컵을 없애면 구멍이 남아있을 수 있습니다)에는 시각적인 왜곡이나 결손이 생길 수 있습니다. 이럴 때 GraspSplats는 partial fine-tuning 을 실행한다고 합니다. 물체가 이동하기 전과 후에 생성된 마스크 정보를 이용해 전체 장면을 다시 학습하지 않고도, 변경된 일부 영역만 빠르게 다시 최적화할 수 있는 방식이라고 합니다. 덕분에 GraspSplats는 효율성을 유지하면서도, 동적인 환경에서 매우 유연하게 대응할 수 있습니다. 전체적으로 3D Gaussian의 장점을 잘 살리는 방향인 것 같습니다. 이후 grasping은 정적인 환경과 유사하게 작동합니다.
Experiments
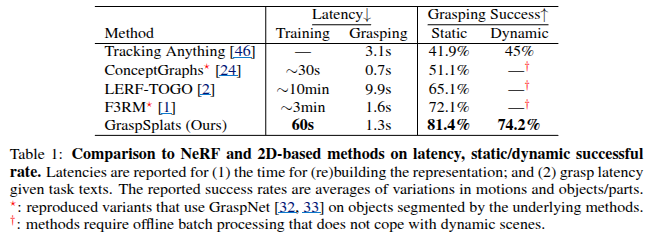
Main Results
저자들은 GraspSplats가 실제 로봇 조작 환경에서 얼마나 효과적으로 작동하는지를 입증하기 위한 실험을 진행했습니다. 특히 이번 실험은 두 가지 주요 질문에 답하는 것을 목표로 했다고 합니다.
첫째, GraspSplats는 왜 기존의 NeRF 기반 방법이나 포인트 기반 방법보다 더 우수한가? 둘째, GraspSplats 내부의 다양한 설계 요소들 중 어떤 부분이 실제 성능에 영향을 미치는가?
실험에 앞서 모든 제3자 시점의 카메라는 Colmap과 Aruco 마커를 활용해 calibration을 진행했고, 장면의 초기 스캔은 로봇 팔이 사전에 정의된 웨이포인트를 따라 했다고 합니다. 모든 실험은 실제 로봇을 통해 수행되었으며, 각 실험마다 로봇에게 텍스트 형태의 Object-Part 쿼리를 제공하여 특정 물체의 특정 부위를 잡도록 했습니다. GraspSplats는 개념적으로 멀티 카메라 기반의 물체 추적을 지원하지만, 실험에서는 단일 RGB-D 카메라만을 사용하여 그 추적 성능을 평가했다고 합니다. 조작 성공의 기준은 로봇이 지정된 물체 또는 그 부위를 집고 들어 올린 후, 재시도 없이 최소 3초 이상 안정적으로 유지했을 때 성공으로 간주하고, static과 dynamic한 상황을 나누어서 실험을 진행했습니다.
Static한 상황에서는 총 24개의 다양한 물체를 활용해 8가지 방식으로 장면을 재구성했으며, 이 중 절반은 의도적으로 복잡하게 배치하여 Hard한 scene을 구성했다고 합니다. 총 43회의 실험이 이루어졌으며, 물체는 주방용품, 식기류, 장난감, 공구 등 일상에서 자주 볼 수 있는 항목들로 구성되었습니다. 특히 일부 실험에서는 물체 전체가 아니라 손잡이나 팁처럼 특정 부위만을 지정해 조작하도록 하여, GraspSplats의 파트 수준 인식 및 제로샷 조작 능력을 집중적으로 테스트했다고 합니다.
Dynamic한 환경에서는 정적 실험과 동일한 물체들을 활용하되, 장면 스캔 이후 사람이 직접 물체를 재배치함으로써 더 복잡한 시나리오를 구성했다고 합니다. 총 40회의 실험이 이루어졌으며, 이 과정에서 GraspSplats가 실제로 물체의 위치 변화를 추적하고, 여전히 파트 단위 조작을 성공적으로 수행할 수 있는지를 평가했습니다. 이 실험은 세 가지 난이도로 구분되었는데, Easy 단계에서는 단순히 물체를 이동만 시키며 회전은 하지 않고, Medium 단계에서는 물체를 180도 회전시키면서 회전 중 손으로 occlusion이 나타나게 했고, ‘Hard’ 단계에서는 물체를 동시에 이동시키고 회전시키며 occlusion이 일어나도록 설정했다고 합니다. 이러한 실험을 통해서 GraspSplat의 낮은 Grasping Latency와 Grasping 성공률을 보여주었습니다.
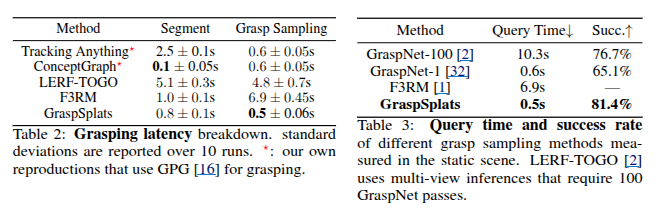
Ablation Study
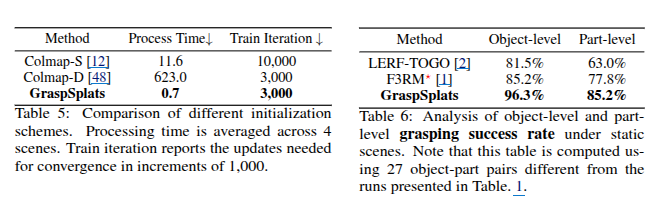
다음으로는 GraspSplats의 그립 제안(grasp proposal) 방식에 대한 분석이 이루어졌다. 기존의 GraspNet 방식은 여러 시점에서 GraspNet을 반복 실행하고 결과를 누적하는 방식인데, GraspSplats는 이러한 접근과 비교했을 때 훨씬 안정적이고 빠른 성능을 보여줬습니다. 세그멘테이션과 그립 제안에 소요되는 시간도 줄어들었습니다. 텍스트 쿼리를 기반으로 객체나 파트를 식별하는 데 걸리는 시간과, 그에 기반해 실제 그립 위치를 샘플링하는 데 걸리는 시간을 각각 측정한 결과, GraspSplats는 이 두 단계 모두에서 매우 짧은 시간 안에 처리를 마쳐, 전반적으로 매우 효율적인 시스템임을 입증했습니다. 초기화 방식에 대한 비교도 함께 진행됐습니다. 기존 Gaussian Splatting 논문에서는 Colmap을 통해 RGB 이미지 기반의 희소 초기화(Colmap-S)를 사용했고, 일부 최근 연구에서는 더 고밀도 초기화(Colmap-D)를 적용해 학습 수렴 속도를 높이려 했습니다. 이에 비해 GraspSplats는 깊이 영상에서 직접 Gaussian 중심점을 초기화하고, 기하학적 정규화를 함께 수행함으로써 훨씬 더 빠르고 효율적인 학습을 가능하게 했다고 합니다. 실제로 평균 처리 시간은 GraspSplats가 0.7초에 불과했던 반면, Colmap-S는 11.6초, Colmap-D는 623초가 소요됐습니다. 이러한 실험 결과는 GraspSplats가 단순히 빠르고 효율적인 시스템이라는 것을 넘어서, 그 구조적 설계가 실제 조작 성능에도 직접적으로 긍정적인 영향을 준다는 사실을 명확하게 보여줍니다.
안녕하세요 영규님, 리뷰 감사합니다.
grasp sampling을 진행한다고 할 때, part 단위로도 구분해서 집는다고 했는데 이 때 affordance는 따로 예측이 되는것이 아니고 SAM을 통해 구분된 part중 사용자의 query만 part 단위로 이해할 수 있는건가요?
또 dynamic 하고 static 한 scene에서 grasping이 유사하게 작동한다고 했는데 다른 부분이 있는건가요?