안녕하세요 류지연입니다.
계속해서 6 DoF (Degree of Freedom) Pose Estimation 관련된 논문을 보고 있습니다. 오늘은 PVNet (PVNet리뷰) 에 이어서 두번째로 PVN3D 논문을 가져왔습니다. 그럼 바로 리뷰 시작하겠습니다.
Introduction
본 연구도 PVNet과 동일하게 6자유도를 갖는 3차원 물체의 자세(방향과 위치)를 추정하는 것을 task를 다루고 있습니다. 해당 물체의 자세 추정은 로보틱스 분야에서의 인지 작업이나 증강현실에서 실제 물체와 상호작용하기 위해 중요하게 적용되는 기술입니다.
그렇다면 PVNet과 다른 게 무엇인가 싶을텐데요.. 계속해서 얘기를 하겠지만 본 연구는 2차원에서 물체의 키포인트를 예측해서 자세를 추정하는 방법의 문제를 지적하며 2차원 이미지를 3차원으로 재구성해 키포인트를 3차원 상에서 예측할 것을 제안합니다. 저자는 2차원에서의 오류를 3차원으로 가져오게 되면 그 차이가 훨씬 크다고 설명합니다.
Related Works
PVNet 뿐만 아니라 앞선 기존 연구에서는 어떤 방법으로 해당 문제를 다뤘는지에 대한 얘기를 하겠습니다. RGB 이미지에서 직접 자세를 추정하는 방법이 초기에 있었습니다. 이 방법은 정확도가 낮았고 일반화하기 어려웠습니다. 방향을 이산화해 분류의 문제로 접근한 방법도 있었고요. RGB 이미지에서 특징을 추출해 키포인트를 예측하고 이를 가지고 자세를 추정하는 방법도 있었습니다. 앞서 작성했던 PVNet도 그런 방법 중에 하나입니다. 이 방법에서도 어떻게 RGB 이미지에서 특징을 추출하는지에 따라 방법이 나뉘었었습니다. 딥러닝 네트워크를 추가해 regression의 방법으로 키포인트를 추출하는 방법, heatmap을 생성해 키포인트를 추출하는 방법이 있었습니다. 하지만 해당 방법은 occlusion, truncation 상황에서 추정을 잘 하지 못했습니다. 이를 보완한 게 PVNet이었습니다. pixel-wise voting network라는 키포인트 검출 방식을 제안해 좋은 성능을 보였었습니다. 하지만 앞서 처음에도 언급했던 것 처럼 키포인트를 2차원 이미지에서 검출하고 3차원 상의 모델의 키포인트와 비교해 그 변환 관계를 추정하다 보니 2차원 상에서의 조그마한 오차에도 자세 추정 정확도가 크게 떨어졌습니다.
그리고 RGBD 센서를 저렴하게 사용할 수 있게 되면서 자연스럽게 자세 추정 문제에 이런 센서를 사용해 이미지를 촬영하고 3차원으로 구성하는 연구가 제안됐습니다. 3차원으로 재구성한 포인트 클라우드의 한 포인트를 키포인트로 예측하고 자세를 추정하는 방식이 제안됐습니다.
본 연구가 제안하는 방법인 3D Keypoints Hough Voting Network도 이런 방향의 연구입니다. PVNet의 keypoint voting 알고리즘을 3차원 상으로 가져와 진행한다고 생각하시면 됩니다.
간단하게 방법론을 설명하자면 같은 장면에 대해 촬영한 RGB 이미지, Depth 이미지를 입력으로 받은 모델이 각 이미지로부터 특징을 추출한 다음 추출한 특징을 가지고 키포인트를 찾습니다. (아래의 이미지를 참고해주세요) 3차원 상에서 그려지는 각 포인트는 추출된 특징을 기반으로 하나의 키포인트 후보를 가리키게 되는데 voting을 진행하며 물체의 키포인트를 특정짓습니다. (d)가 voting을 거치고 나서 최종적으로 결정된 키포인트들인 것입니다. (e)에서 mesh model의 (RGB 이미지와 함께 학습 때 제공되는 데이터) 키포인트와 변환 관계를 나타내는 R, t 행렬을 계산합니다. 학습된 모델은 예측된 자세 (R, t)를 가지고 mesh model을 입력이미지에서 처럼 포개어지게 변환할 수 있게 됩니다. 이렇게 해서 2차원 영상 속 물체를 Positioning 할 수 있게 됩니다.
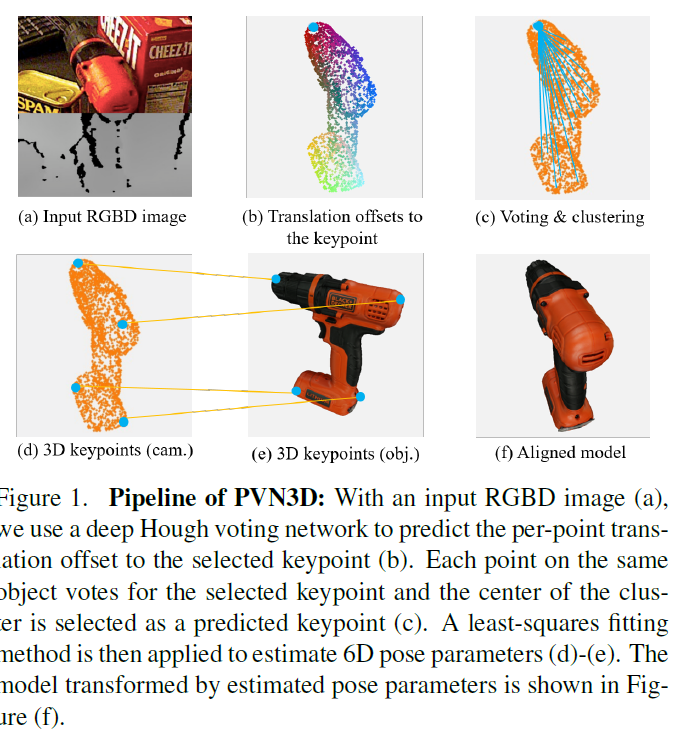
Proposed Method
이번 단락에서는 논문에서 제안하는 방법론에 대해 더 자세하게 다뤄보겠습니다. 앞서 얘기했지만 한번 더 본 연구의 컨셉을 얘기하자면 6DoF에서 자세추정이란 것은 모델 좌표계에서의 물체를 카메라 좌표계에서의 물체로 변환하는 3변환 행렬을 구하는 것입니다 (얼마나 회전했고 얼마나 이동했는지를 알아내는 것입니다). PVNet과 동일하게 영상에서 키포인트를 예측하는 것과 키포인트로 최종적인 자세를 추정하는 two-stage 방법을 똑같이 사용합니다.
다만 본 연구에서는 3D Keypoint Hough voting network라는 새로운 제안을 합니다. 저자는 키포인트를 검출하는 과정에서 Instance Semantic Segmenation 과정의 중요성을 강조하고 별개의 모듈로 분리해 설명합니다.
아래의 이미지는 제안된 방법론의 네트워크를 그린 것으로 각 단계가 순차적으로 나눠 그려져 있습니다. 해당 방법론이 어떤 방식으로 동작하는지에 대한 전반적인 흐름을 파악하기에 좋은 그림인 것 같습니다.
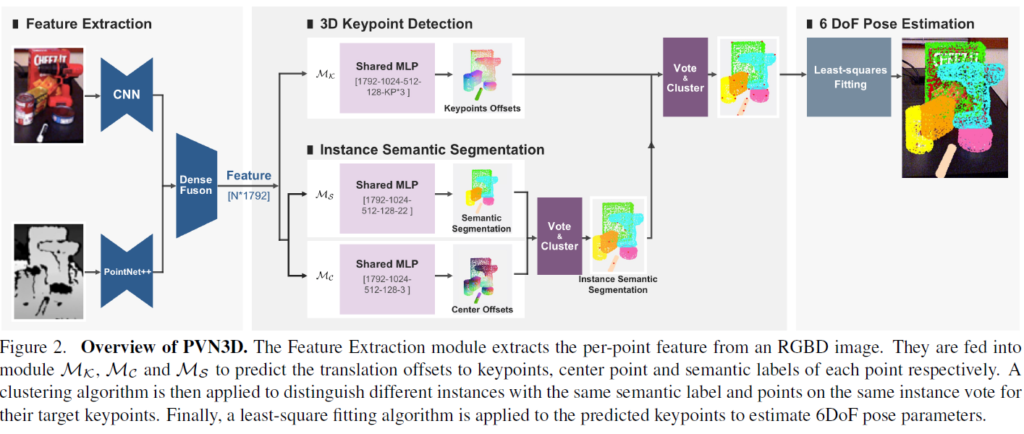
1. Feature Extraction Module
RGBD 이미지를 입력으로 받습니다. RGB 이미지, Depth 이미지에 대해서 각각 따로 Feature Extraction이 진행된 다음 퓨전이 됩니다. 추출한 특징은 Keypoint Detection module로 전달 돼 이어서 키포인트 예측을 합니다.
RBG 이미지로부터 특징 추출을 할 땐 PSPNet, ResNet34 모델이 사용되고요 PointNet++ 로 포인트 클라우드의 특징이 추출됩니다. 두 이미지에서 추출된 특징들은 DenseFusion의 방법으로 퓨전됩니다.
2.1. 3D Keypoint Detection Module
물체의 각 포인트에서 추출된 특징에 따라 하나의 키포인트를 가리키게 됩니다. 그러면 그 포인트와 그 포인트가 가리키는 키포인트 간의 거리차이가 생기겠지요. (이를 오프셋이라고 설명합니다. 이 오프셋만큼 포인트를 translation을 시킨다면 키포인트가 된다고 기대하며 예측 오프셋이 GT 오프셋으로 근사하도록 학습됩니다.) PVNet에서 각 픽셀이 키포인트를 향하는 방향을 가리키던 것과 같이 같은 물체에 대해서 모든 포인트가 가리키는 키포인트에 대해서 voting 해 키포인트를 결정합니다. (같은 물체에서 두개의 포인트의 벡터의 교점을 하나의 가설로 두고 각 가설이 같은 물체에 있는 다른 포인트와도 얼마나 잘 부합하는가를 점수화하고 이를 바탕으로 키포인트의 분포를 계산한다) 학습 시 예측된 오프셋과 GT오프셋으로 L1 loss이 정의되고 그 간극을 줄이도록 학습됩니다.
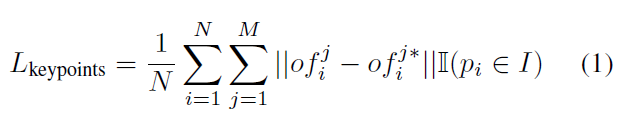
N은 I 인스턴스에 포함되는 모든 seed point (point cloud의 point들)의 개수입니다. M은 해당 인스턴스에서의 키포인트의 개수입니다. GT 오프셋과 예측 오프셋간의 차이에 대해 L1 loss를 정의한 식입니다. \mathbb{I}는 Indicator function으로 해당 포인트가 I 인스턴스에 포함돼 있는 경우 1을 아닌 경우에는 0을 반환하는 함수입니다. 그래서 loss는 같은 물체내의 포인트의 오프셋을 가지고 계산됩니다.
2.2 Instance Semantic Segmentation Module
키포인트 검출과 함께 추가적으로 해당 단계에서 3차원 영상에서 키포인트 검출의 정확성을 높이기 위해 물체의 중앙 지점을 검출하고 각 seed point 마다 semantic 레이블도 구합니다. semantic 정보를 가지고 각 포인트가 어떤 클래스에 속하는지 구하고 이를 가지고 각 포인트에서 키포인트를 voting 통해 구합니다.
본 연구에서는 Keypoint Detection 과 Semantic Segmentation이 함께 이뤄질 때 서로 보완이 된다고 설명합니다. Segmentation과정에서 global, local feature로 각 물체를 구분을 하는데, 이 과정에서 각 물체의 포인트를 검출하고 따라서 키포인트와의 오프셋을 구하는데도 도움이 되고 반대로 Keypoint Detection 시 각 포인트가 키포인트와 갖는 오프셋을 알 수 있는데 이를 가지고 물체의 크기를 대충 짐작할 수 있게돼서 segementation 과정에서 물체의 크기에 대한 정보를 가지고 더 정확하게 진행 할 수 있다고 합니다. Semantic Segmentation Module에서는 focal loss를 줄이도록 학습됩니다.
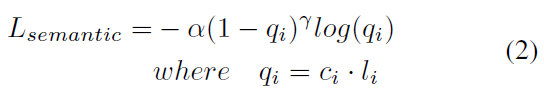
c_i는 i번째 point에서 각 클래스마다의 (라벨마다의) 신뢰도를 나타냅니다. l_i는 GT 라벨에 대한 one-hot 형태의 값으로 해당 loss에서는 GT인 라벨에 대한 class 신뢰도만이 계산될 것 입니다.
여기서 또 물체의 중앙 점을 예측하는 모듈 Center Voting Module이 있어 각 포인트와 중앙점간의 오프셋이 예측됩니다. 각 물체의 중앙 점의 위치를 알 수 있을 때 우리는 서로 다른 물체를 구분하기 쉽습니다. 이 모듈에서의 학습과정은 앞선 Keypoint Detection Module 과정과 동일하다.
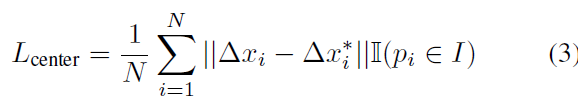
p_i는 포인트 클라우드에서 각 seed point입니다. \Delta x_i는 p_i에서 물체 중심점간의 거리차이를 나타냅니다. 중심점에 대한 loss 도 키포인트에서와 마찬가지로 L1 loss로 구해집니다.
각 module들의 결과를 clustering 해 최종적인 키포인트가 결정되는데요 앞선 세 모듈을 하나의 큰 Module로 보고 각 단계에서의 loss를 더해 Multi-task Loss를 정의합니다. 각 loss항 마다 가중치를 달리 줄 수 있는데 저자는 동일하게 1로 설정했다고 합니다.
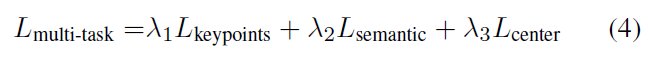
Pose Estimation
모델 좌표계와 카메라 좌표계간의 회전, 이동 변환 관계를 추정하기 위해서는 각 좌표계에서의 대응점을 각각 알아야 합니다. Keypoint Selection 단계에서는 3차원 mesh model의 키포인트를 구하는 과정을 거칩니다. PVNet에서 동일하게 FPS의 방법을 채택해 총 M개의 키포인트를 학습 이전에 결정해둡니다.
3차원 영상 키포인트와 모델의 키포인트를 가지고 Least-Squares Fitting 방법으로 Least-Squares을 최소화하는 회전, 이동 변환 행렬을 구합니다.
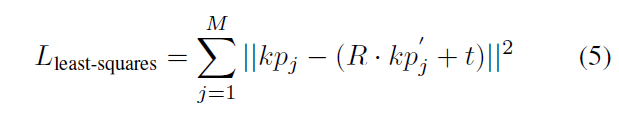
Experiments & Ablation Studies
본 연구에서는 두가지 데이터셋에 YCB-V, LineMOD에 대해서 실험을 진행해 성능을 평가합니다. 간단히 각 데이터셋에 대한 설명을 드리자면..
YCB-V 데이터셋은 이미지마다 조도 환경이 다르고 노이즈도 정도도 다르고 다른 물체로 가려진 경우가 있어 자세 추정이 쉽지 않다는 게 특징인 데이터셋입니다. 총 21개의 물체를 촬영한 영상으로 구성돼 있습니다.
LineMOD는 텍스처 정보가 거의 없는 물체들로 조명 환경도 다른 이미지로 구성됩니다. occlusion는 일어난지 않아 occlusion 상황에서 물체를 정확하게 검출하도록 학습시키기에는 한계가 있습니다.
다음으로 평가 지표로 사용되는 것들에 대해 얘기하겠습니다. 6DoF 태스크에서 평가지표로 사용되는 것은 다 비슷한 것 같습니다. PVNet에서의 평가지표도 다음과 동일하게 사용됐었습니다.
모델 물체를 예측한 자세를 가지고 변환한 것과 GT 자세로 변환 한 것간의 포인트 간의 거리 차이를 가지고 자세 추정이 정확한지를 평가합니다. 이때 매칭점들 간의 평균 거리를 나타내는 ADD(-S)라는 지표를 사용한다. YCB-V 데이터셋에 대한 지표로는 ADD(-S)에 대해서 정답을 인정하는 거리의 임계값을 달리하며 구한 AUC를 계산해 평가 비교합니다.
다음으로는 각 실험 결과를 살펴보며 저자가 제안하는 방법이 효과를 검증하도록 하겠습니다.
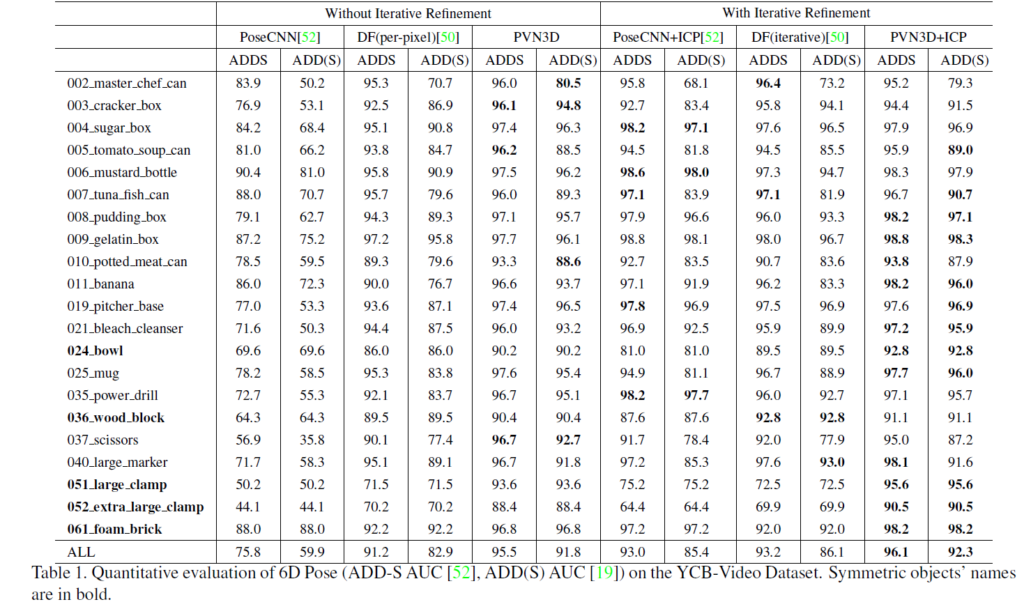
위 테이블은 YCB-V에 대해 실험한 결과인데요 RGB이미지만을 가지고 자세를 추정하는 이전 모델과 비교했을 때 더 높은 성능을 낸 것을 확인할 수 있고 PVN3D에 추가적으로 자세를 조정하는 단계를 추가한 것이 제일 높은 성능을 보인다는 것을 확인할 수 있습니다.
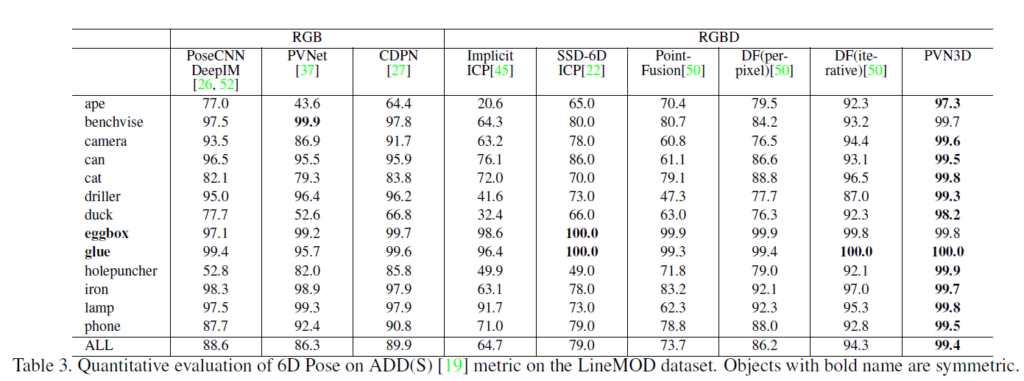
LineMOD에 대한 실험결과를 보면 본 연구에서 제안하는 방법론이 (PVNet을 포함하는) RGB 이미지만을 가지고 추정하는 모델, RGBD에서의 이전 모델들보다 성능이 좋다는 것을 알 수 있습니다.
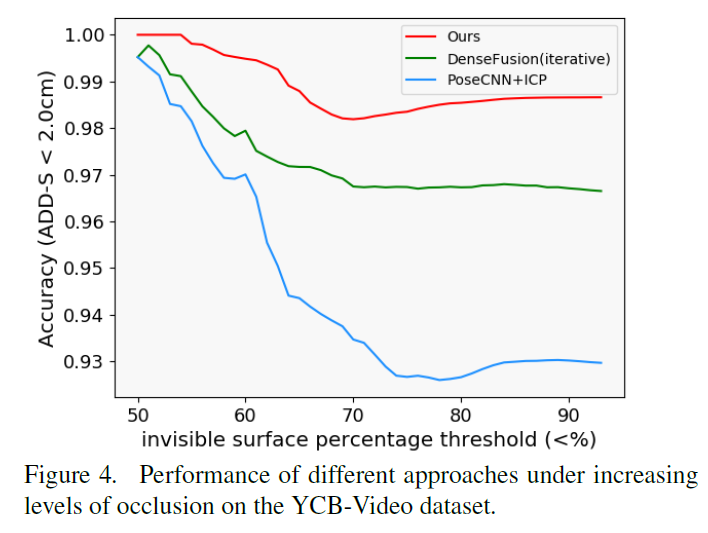
YCB-V에 대해서 추정된 자세정보로 변환한 것과 GT간의 거리차가 2cm 보다 작은 것만을 정답으로 인정하고 occlusion 정도에 따라 정확도가 어떻게 변하는지를 비교한 실험인데. 추가적으로 자세 조정을 해주는 PoseCNN, DenseFusion 모델의 경우 물체가 많이 가려질 수록 정확도가 떨어졌고 그 폭이 컸으나 본 연구에서 제안하는 PVN3 는 물체의 상당 부분이 가려짐에도 불구하고 비교적 작은 폭으로만 떨어진다는 것을 확인할 수 있습니다. 따라서 실험 결과, 제안한 모델이 occlusion에도 다른 모델보다 강인함을 확인할 수 있는 실험 결과였다
다음은 본 연구에서 제안하는 방법 두 가지 (1. 추출된 특징을 가지고 각 이미지를 3차원에서 재구성하고 키포인트를 예측한다 2. 3D Keypoint Detection Module을 키포인트 검출 모듈과 세그멘테이션 모듈, 그리고 중심점 검출 모듈로 구성한다)가 성능 향상에 기여했는지 여부와 그 정도를 확인하는 Ablation Study에 대한 실험 결과입니다.

위 테이블 4.에 대해서 결과 일부를 설명하겠습니다. 키포인트를 3차원 공간상에서 예측하는 것의 효과를 보기 위해 본 연구에서 사용한 모델에서 vote 통해 선택된 키포인트를 2차원 이미지에 다시 사영시키고 PnP 솔버로 자세를 추정하는 방식 (Ours(Corr)) 으로 진행 해 성능을 비교한 결과 3차원 키포인트를 사용했을 때 (Ours(3D KP)) 정확도가 더 높았습니다. 이는 물체의 중심점을 가지고 이해해볼 수 있는데요 서로 가려진 물체의 경우 물체의 포인트들을 (중심점을 포함해서) 2차원으로 사영시키고 나면 중심점 간이 구분이 쉽지 않습니다. 두 가직 실험을 통해 물체를 3차원 상의 공간에서 다루고 키포인트를 예측하고 자세를 추정하는 것이 훨씬 정확하다는 것을 알 수 있습니다.
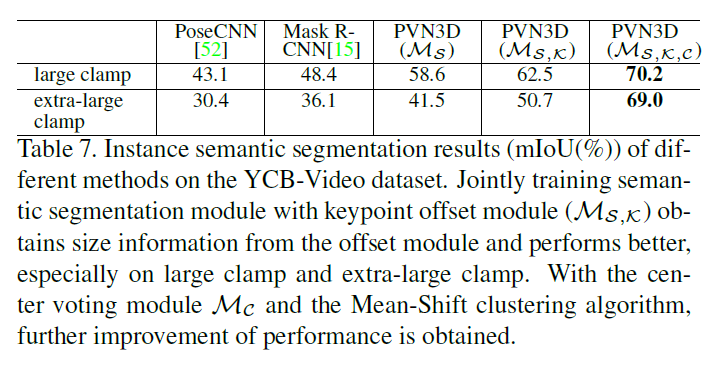
제안하는 방법론인 PVN3D에서 keypoint detection 모듈만을 가지고 키포인트를 검출할 때 보다 Segmentation을 함께 진행할 때 성능이 더 좋습니다. Semantic 정보를 가지면 각 포인트가 포함되는 인스턴스의 구분히 확실해 지기 때문에 같은 물체에 있는 키포인트를 예측하는 과정이 더 정확하게 이뤄진다고 설명합니다.
Conclusion
본 연구를 정리하자면 2차원에서 키포인트를 voting 하던 것을 3차원 상에서 진행하는 3D keypoints voting network를 제안한 것입니다. 이런 방법을 제안해 자세 추정의 정확성을 높이고자 하였습니다. 그리고 실제로 실험을 통해서 저자가 제안한 방법들이 모두 유의미있게 성능 향상에 기여했음을 확인할 수 있었습니다.
PVN3D의 후속 연구로는 FFB6D가 있습니다. 이 논문을 지금 다 읽어가고 있는 중인데 이 논문도 3차원 포인트 클라우드에서 키포인트를 예측하는 것을 그대로 가져갑니다. 이 연구를 통해 2차원 상에서 키포인트를 찾아 모델의 키포인트와 매칭시키는 것 보다 3차원의 카메라 좌표계에서 점과 매칭시키는 것이 정확한 추정을 하는데 중요하다는 것이 제대로 증명된 것이라고도 볼 수 있을 것 같습니다. 그럼 저는 다음에는 FFB6D 논문으로 다시 돌아오겠습니다. 감사합니다.
지연님 좋은 리뷰 감사합니다.
PNV3D는 keypoint에 대한 offeset과 물체의 중앙점에 대한 offset을 모두 구하는 것으로 이해하였는데, 맞을까요? 맞다면 이 둘 중 어떤 게 더 유의미한지에 대한 실험이 따로 없는 지 궁금합니다.
또한, 중앙점을 통해 물체를 구분하는 데 사용되는 것으로 이해하였는데 맞을까요? 그렇다면, 해당 논문은 occlussion이 발생한 물체에 대해서도 예측을 함께 수행하는 것으로 보이는데, 물체의 중앙점이 다른 물체 위에 표시될 경우가 발생하는 것에 대한 보완도 함께 고려되었는지, 혹은 한계로 언급하는 지 궁금합니다.
안녕하세요 승현님!
1. 네 두가지 오프셋이 모두 구해지고 이를 줄이는 방향으로 학습됩니다.
본 연구에서는 둘을 가지고 어떤 게 더 유의미한지에 대한 실험은 없었고요. 키포인트 오프셋을 가지고 학습하는 모델에 추가적으로 center point 오프셋을 추가했을 때 성능 향상을 보인 연구가 있었습니다. 이로써 center point의 오프셋을 함께 고려하는 게 자세 추정의 정확도를 높이는 방법이라는 결론을 냈었습니다.
2. 승현님께서 얘기해주신 상황을(물체의 중앙점이 다른 물체 위에 표시되는 경우) occlusion의 상황으로 이해했는데요 해당 경우에 대한 구체적인 언급은 논문에서는 없었던 것으로 압니다. 제 생각에는요 논문에서 center point 추정에 대해서도 voting 방법이 동일하게 적용되기 때문에 해당 occlusion이 발생해도 보완이 될 것 같습니다.
감사합니다.
안녕하세요 지연님, 좋은 리뷰 감사합니다.
3D Keypoint Detection Module에서는 gt offset과 예측된 offset간의 L1 Loss를 통해 학습을 하는 것으로 이해했습니다. 이 때 gt offset은 데이터셋에서부터 point cloud에 annotation되어 주어지는 건가요?
Segmentation과정에서 global, local feature 는 각각 어떤 기준으로 정의된 feature인가요?
안녕하세요!
질문 감사합니다.
GT 오프셋을 준다기보다는 GT 자세 정보 (R, t)가 주어져 이를 가지고 mesh model의 키포인트를 회전, 이동 시키게 되면 point cloud 상에서의 GT 키포인트를 알 수 있게 되어 GT 오프셋을 알 수 있게 되는 것이라고 저는 이해했습니다.
global feature과 local feature를 나누는 기준에 대해서는 조금 더 찾아보고 답변 드리겠습니다.
감사합니다.
안녕하세요 지연님 좋은 리뷰 감사합니다.
혹시 ADD(-S)라는 지표에 대해서 조금만 설명해주실 수 있으신가요? 정확하게 이해가 되지 않았습니다..
또 YCB-V 데이터셋에 대한 지표로 ADD(-S)에 대해서 정답을 인정하는 거리의 임계값을 달리하며 구한 AUC를 계산해 평가 비교한다고 하셨는데, 왜 이런식으로 비교하는지도 궁금합니다!!
영규님 안녕하세요! 질문 감사합니다.
우선 ADD(-S)란 지표에 대해서 설명을 드리자면..
모델이 예측한 자세 정보 (R, t)와 GT 자세 각각을 가지고 mesh model에 변환을 수행하고 그 차이를 보고 성능을 평가합니다. 이때 예측된 자세로 변환한 mesh model이 GT의 것과 완전히 일치하지 않게 되는데 두 변환된 model에서의 대응 점간의 거리 차이를 가지고 그 정도를 확인할 수 있습니다. 거리 차이가 설정한 임계값보다 차이가 작게 날수록 ADD(-S)는 더 큰 값을 갖게됩니다.
또한 symmetric한 물체에 대해서는 가장 짧은 거리에 있는 두 대응점에 대해서 거리를 계산하고 평가합니다. (ADDS 사용)
YCB-V에 대해서 다른 평가지표를 사용하는 이유에 대해서는 다시 알아보고 답변드리겠습니다.
감사합니다.
기존 연구들이 YCB-V 데이터셋에 대한 실험에서 평가지표로 ADD(-S)의 AUC를 사용했기 때문에 본 연구에서도 동일한 지표를 사용해 비교하고 있다고 압니다.
안녕하세요, 좋은 리뷰 감사합니다.
RGB/Depth map이 입력으로 들어가서 그 중 Depth map은 백본으로 PointNet++을 통과하고 있는데, 제가 알기로는 PointNet++의 원래 입력 데이터는 raw한 포인트 클라우드 인 것으로 알고 있습니다. depth map 형태로 들어갔을 때 PointNet++을 통과하기 위해서 추가적인 전처치를 어떻게 해주게 되나요 ??
감사합니다.
안녕하세요 건화 연구원님!
네 맞습니다. depth map 형태로 전달된 입력 이미지는 PointNet++에 통과하기 위해 point clound의 형태로 변환하는 과정이 필요합니다. depth map의 픽셀값으로 depth 정보 즉 카메라와 그 물체간의 거리에 대한 정보가 저장돼 있습니다. 카메라 내부 파라미터 (focal length, priciple point의 좌표)를 알고 있다는 전제하에 해당 depth 정보로 각 픽셀의 3차원 좌표를 구할 수 있게 되고 이를 바탕으로 point cloud를 구성할 수 있게 되는 것입니다.
감사합니다.
안녕하세요, 좋은리뷰 감사합니다.
2D voting 방식에서는 키포인트를 예측하고 3D로 변환하는 과정에서 오차가 더 크게 발생해서
3D voting 방식으로 포인트 클라우드에서 예측을 시작해서 오차가 적어지는거로 보이는데, 너무 간단한 질문이지만 궁금한점은 3D 허프 보팅을 할때 입력으로 들어가는 3차원 정보가 그럼 x,y,z, 좌표값인건가요? 그리고 최종 keyponit는 개수를 정해놓는 것 같은데 적절한 개수를 정하는 방법이 있는지 궁금합니다
안녕하세요 인택 연구원님 질문 감사합니다!
1. 네, 각 seed point마다(포인트 클라우드상의 점을 가리킵니다) 3차원 좌표값과 오프셋을 가집니다. 오프셋을 가지고 키포인트가 예측되고 여러 예측된 후보 키포인트들을 군집화해 최종적으로 하나의 키포인트를 설정합니다.
2. 적절한 개수를 정하는 방법이란 건 없는데요 키포인트를 결정하는 방법으로 FPS(Farthest Point Sampling)이 사용됩니다. mesh model의 표면상에 위치하는 점들 중 키포인트 집합내의 점들과 제일 먼 점을 추가하면서 키포인트의 개수를 늘려가며 정하는 방법입니다. 처음에는 키포인트 집합내의 키포인트가 없기 때문에 model의 center point를 기준으로 제일 먼 점을 골라 추가합니다. 사실 키포인트 개수를 어떤 것으로 정하는지는 자유로운데요 이전 PVNet 논문에서 해당 방법을 제안했고 키포인트 개수를 달리하며 최적의 개수를 확인하는 실험을 진행했었습니다. 실험은 4, 8, 12개로 설정해서 비교가 되었는데 키포인트 개수가 많을수록 (4개일 때 보다 8, 12개일 때가 더 정확했음) 정확했지만 8개일 때와 12개일 때의 차이가 크지 않아서 해당 연구에서는 8개를 최적으로 결정했습니다. 이후 연구들도 같은 이유로 키포인트를 8개로 두고 실험을 진행했다고 보시면 되겠습니다.
안녕하세요 류지연 연구원님!
좋은 리뷰 감사합니다.
궁금한것이 있습니다 global feature와 local feature 를 모두 학습가능하다고 하셨는데 어떤 과정으로 인해서 그게 가능한지 궁금합니다! 추가적으로 투표할때 중간점에서 가장 먼점을 선택한다고 위에 질문에 답을 해주셨는데 voting이 총 2번 일어나게되는데 처음 voting할때는 중심점을 voting 할거같은데 어떻게 하는건가요? 궁금하네요
질문 주셔서 감사합니다 손우진 연구원님.
1. 추출된 feature map에 대해서 각 포인트가 어떤 인스턴스에 해당하는 포인트인지 예측하도록 하는 semantic segmentation을 도입함으로써 해당 모듈이 포인트간 구분을 하기 위해 두가지 feature를 잘 추출하도록 학습이 이뤄진다고 합니다.
2. FPS에 대해서 질문을 주신 건가요? 우선 FPS의 방법으로 정하는 키포인트는 mesh model (어떤 물체를 3D로 구현한 것)의 점으로 학습 과정에서 GT로 적용되는 것으로 voting을 통해 정해지는 건 아닙니다. mesh model의 경우 해당 물체를 이루는 점들의 좌표를 알고 GT 키포인트를 정하는 방법론이라고 이해해주시면 되겠습니다.
답변이 되었으면 좋겠네요