안녕하세요. 박성준 연구원입니다. 오늘 리뷰할 논문은 CVRP2025에 게재된 Vision-Language 분야에서 Compositionality를 다룬 논문입니다. 논문의 제목에서 알 수 있듯이 저자는 Synthetic Data를 통해 Compositionality를 다뤘고 최근에 CVPR 2025 accepted 논문 리스트를 서베이하다가 Vision-Language task에서 어떻게 Compositionality를 해결할 수 있을 지에 관심이 있었기에 해당 논문을 읽어보게 되었습니다.
Introduction
Vision-Language 연구가 많이 진행되며 Vision-Language 모델의 한계에 대한 분석도 많아지고 있습니다. 최근 연구들은 특히, Vision-Language 분야에서 Compositional Understanding에 대해 주목하고 있습니다. Compositional Understanding은 이미 알고 있는 정보들을 새로운 방식으로 조합했을 때의 정보를 이해하는 능력을 말합니다. 이러한 Compositional Understanding 능력에 대한 관심이 늘어나는 이유는 당연하게도 Vision Language Model(VLM)의 Compositional Understanding 능력이 부족하기 때문이고 이는 미세한 변화를 포함한 샘플에 대한 학습이 적기 때문입니다. 즉, 서로 다른 이미지와 텍스트 페어에 대해서는 학습을 진행하지만, 비슷하지만 서로 다른 의미를 갖는 샘플을 통한 학습은 비교적 적게 이루어지기 때문입니다. 따라서 서로 다른 의미는 잘 파악하지만, 비슷한 의미를 갖는 문장 사이의 구별력이 떨어지게 됩니다.
위 문제를 해결하기 위한 방법 중에 하나는 바로 Synthetic Data를 활용하는 것입니다. Synthetic Data란, 합성 데이터를 의미하는데 일반적으로 실제 데이터가 아니라 생성한 데이터를 의미하게 됩니다. Synthetic Data를 통한 학습은 실제 데이터는 비슷한 의미를 갖는 문장에 대한 학습이 어렵기 때문에 비슷한 의미지만 서로 다른 의미를 갖는 데이터를 생성함으로 Compositional Understanding 능력을 향상시키는 방법입니다. 하지만, Synthetic Data를 통한 학습에는 두가지 문제점이 있습니다. 하나는 정확한 데이터의 생성에 어려움이 있다는 점이고 하나는 Cross-modal alignment 품질의 불안정성입니다. 정확한 데이터의 생성에 어려움이 있다는 것은 결국 생성형 데이터는 사전학습된 생성형 모델을 통해 생성되는데, 이때 사전학습된 생성형 모델의 품질에 크게 영향을 받기 때문입니다. 두번째 문제 또한 비슷하게 사전학습된 생성형 모델의 품질에 영향을 받기 때문에 생기는 문제입니다.

위 Figure 1.은 합성 데이터의 생성 및 학습 과정에서 발생하는 문제를 정성적으로 보여주는 figure입니다. (a)는 원본 이미지를 바탕으로 변형을 가한 데이터에서 문제를 보여주며, Synthetic 데이터를 생성하는 생성형 모델이 텍스트와 정확하게 정렬되지 않는 결과를 보이는 예시와 시각적 품질을 유지하지 못하는 것을 보여줍니다. (b)는 positive와 negative caption을 적용했을 때의 문제점으로 미세한 차이가 있는 positive 샘플은 모델이 차이를 구별하기 어렵게하며, 과도하게 변형하는 negative 샘플은 학습 효과가 떨어지게 됩니다. 가장 큰 문제는 역시 맨 오른쪽 caption이며, 부정확한 caption을 생성함으로 학습에 오히려 방해를 할 가능성이 높습니다.
저자는 위 두가지(정확한 데이터의 생성에 어려움, Cross-modal alignment 품질의 불안정성)를 해결하기 위한 방법으로 Subtle Variation Data Generation and Training(SVD-GT)를 제안하는데 이 방법은 Image Feature Injection(이미지 특징 주입)과 Adaptive Margin Loss(적응형 마진 손실)를 사용합니다. 이는 이미지 특징 주입을 통해 생성형 데이터의 품질을 향상시키고, 적응형 마진 손실을 구별이 어려운 샘플들을 명확하게 학습할 수 있도록 도와줍니다.
이에 따른 저자의 Contribution은 다음과 같습니다.
- 저자는 Image Feature Injection 방법을 제안하여 합성 샘플의 변형 품질을 향상시킵니다.
- 저자는 Adaptive Margin Loss를 활용하여 positive 샘플과 negative 샘플을 효과적으로 구분할 수 있도록 도와줍니다.
- 마지막으로 저자는 실험결과를 통해 위 두가지 방법을 적용한 Synthetic Data를 통한 학습이 VLM의 Compositionality를 개선한다는 사실을 증명합니다.
Method
SVD-GT는 Compositional Understanding을 향상시키기 위해 subtle variations(미세한 변형)을 포함한 합성 멀티모달 샘플을 생성합니다. 생성시킨 후 미세한 변형을 통해 비슷한 의미를 갖는 데이터 사이의 차이를 학습합니다.
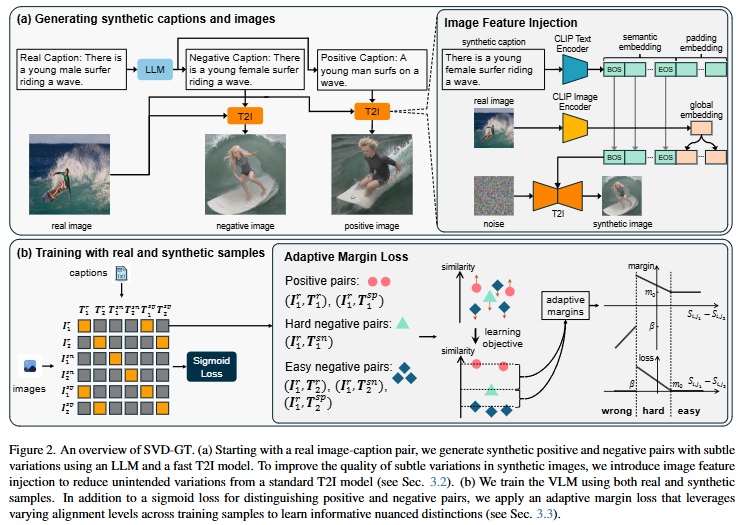
Figure 2.는 저자가 제안하는 프레임워크를 보여주는 figure입니다. 저자가 제안하는 두가지 방법을 어떻게 적용하는지를 설명하고 있으며, (a)는 Generating Synthetic captions and images로 LLM과 T2I(text-to-image) 모델을 사용하여 positive, negative 샘플을 생성하는 과정입니다. LLM을 이용한 캡션 변형은 크게 특별한 내용은 없습니다. LLM을 통해서 positive caption과 negative caption을 생성합니다. 예를 들어 원래 caption이 “젊은 남성 서퍼가 파도를 타고 있다”라고 한다면, negative sample은 “젊은 여성 서퍼가 파도를 타고 있다”, positive sample은 “젊은 남성이 파도를 탄다”와 같이 negative sample은 비슷하지만 다른 의미를 갖는 문장이고, positive sample은 같은 의미를 갖는 문장입니다. caption을 생성한 이후에는 생성한 caption과 T2I 모델을 통해 새로운 이미지를 생성합니다. 생성된 이미지는실제 이미지와 비교했을 때 미세한 차이를 갖지고 일관성을 유지해야합니다. 여기서 일관성을 유지한다는 것은 T2I 모델이 같은 caption을 통해 생성하는 이미지가 비슷해야한다는 것을 의미합니다. 즉, 같은 프롬프트(caption)을 입력했을 때의 생성된 이미지가 너무 다르지 않아야 한다는 것을 의미하고 다르게 된다면 저자가 초기에 문제 삼은 정확한 데이터의 생성에 어려움이 생길 수 있습니다.
이때 T2I 모델이 생성하는 이미지의 품질을 향상시키기 위해서 실제 이미지를 참고 하지 않는다면 실제 이미지와 유사한 이미지를 생성하지 않은 가능성이 높습니다. 만약에 “젊은 남자 서퍼가 파도를 타고 있다”의 이미지를 생성한다고 했을 때, 남자의 생김새 혹은 뒷 바다의 배경이 원래 이미지와 다르게 된다면, 이는 Compositionality를 향상시키는 데에 도움을 주는 것이 아니라 그냥 서로 다른 이미지를 통해 학습하는 것과 같은 의미를 갖게 됩니다. 따라서 저자는 실제 이미지와 유사한 이미지 생성을 위해서 실제 이미지의 특징을 주입하는 과정을 거치게 됩니다. 이를 위해서 저자는 CLIP 인코더를 통해서 실제 이미지의 임베딩을 추출하고 이 임베딩을 T2I 모델의 입력에 포함하는 것으로 실제 이미지와 비슷한 결과를 생성하게 됩니다. 이때 저자는 추가적으로 Style Transfer를 적용해 실제 이미지와 생성한 이미지 사이의 도메인 차이를 최소화합니다. 수식적으로는 다음과 같습니다.
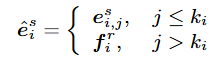
이때, e^s_{i,j}는 기존 T2I 모델에서 사용하는 텍스트 임베딩을 의미하고 f^r_{i,j}는 실제 이미지에서 추출한 특징 임베딩을 의미합니다. 즉, 기존 텍스트 임베딩 중 일부를 실제 이미지 특징으로 대체하는 것으로 합성 이미지가 실제 이미지와 유사한 스타일을 유지할 수 있습니다. Style Transfer에는 AdaIN(Adaptive Instance Normalization)을 활용합니다.
(b) 과정은 Adaptive Margin Loss로 일반적으로 합성 이미지를 생성할 때에 positive sample과 원래 데이터의 거리를 가까이, negative sample과의 거리를 멀어지게 학습을 하게됩니다. 저자는 이 방법은 negative sample이 실제 이미지와 얼마나 다른지, positive sample이 실제 이미지와 얼마나 비슷한 지를 정확하게 반영할 수 없다고 지적합니다. negative 중에도 더 구별하기 어려운 Hard Negative와 구별하기 쉬운 Easy Negative가 존재하기 때문입니다. 따라서 저자는 쉽게 구별되는 negative 샘플에는 더 작은 margin을 제공하고 구별이 어려운 negative 샘플에는 더 큰 마진을 적용하는 것으로 모델이 더 유의미한 샘플에 집중할 수 있도록 도와줍니다.
실제 이미지 샘플 (I^r_i, T^r_i)에 대해서 생성한 Synthetic Negative 샘플과 Synthetic Positive 샘플은 각각 (I^{sn}_i, T^{sn}_i), (I^{sp}_i, T^{sp}_i)이고 3개의 이미지, 텍스트 쌍이 학습 샘플에 포함되게 됩니다. 그 후 저자는 학습을 위해 각 이미지와 텍스트의 유사도와 어떤 이미지-텍스트 쌍이 positive인 지를 나타내는 GT 행렬 M를 정의합니다. 유사도는 코사인 유사도를 사용하고 GT 행렬은 다음과 같습니다.
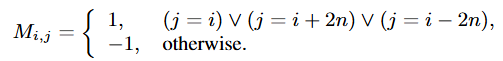
1은 positive, -1은 negative를 의미합니다. 이에 따른 손실 함수는 다음과 같습니다. positive의 유사도를 높게, negative의 유사도를 낮게 학습합니다.
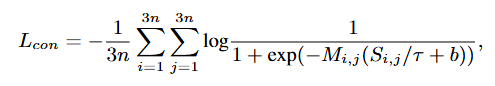
정리하면 저자는 T2I 모델을 활용하여 positive와 negative 샘플을 생성하고 원래 이미지-텍스트 쌍을 포함하는 3개의 샘플을 하나로 엮어 학습에 사용합니다. 그 후 유사도를 계산하고 GT 행렬을 통해 Contrastive Learning을 수행합니다.
Contrastive Learning에 추가로 저자는 Adaptive Margin Loss를 사용하게 되는데 이는 positive에는 높은 유사도를, Hard Negative에는 높은 마진, Easy Negative에는 낮은 마진을 주는 것으로 학습하는 방법입니다. 이는 Hard Negative를 더 효과적으로 구분할 수 있도록 하는 동시에 Easy Negative의 학습 부담을 줄이는 효과를 갖습니다. 저자는 이를 위해서 배치 내에 4가지 그룹으로 분류하여 학습하고, 순서대로 positive(P), Hard Negative(N_h), Easy Negative(N_e), Real Negative(N_r)입니다. Real Negative는 실제 데이터와는 무관한 샘플을 의미합니다.
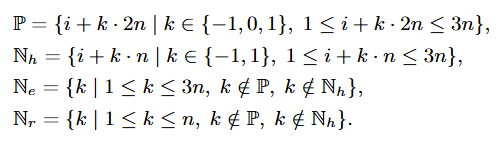
그 후 그룹 별로 서로다른 마진을 부여합니다.
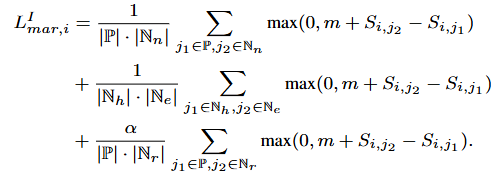
S는 유사도를 의미합니다. 마진 m는 Adaptive하게 적용되는데 다음과 같이 정의됩니다.
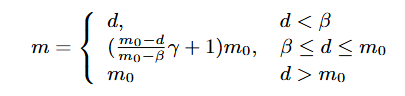
이때 d는 d = S_{i,j_1} - S_{i,j_2}로 두 유사도 사이의 차이를 의미합니다. 이러한 마진은 negative 샘플의 유사도가 너무 높다면(d<\beta) 잘못된 샘플일 가능성이 있으므로 마진을 낮게하는 역할을 수행하고 샘플이 충분히 구분된다면(d>m_0), 마진을 m_0 고정하는 것으로 손실을 감소시키는 역할을 수행합니다. 이때 m_0, \beta는 순서대로 기본 마진값과 임계값을 의미합니다.
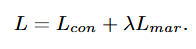
최종 손실함수는 Contrastive Loss와 Adaptive Margin Loss를 합한 형태입니다.
Experiments
저자가 학습에 사용한 데이터셋은 COCO 데이터셋입니다. 평가에 사용하는 데이터셋은 ARO 데이터셋과 VL-Checklist 데이터셋, SugarCrepe, SugarCrepe++ 데이터셋입니다. 4데이터셋은 모두 Compositionality를 평가할 수 있는 데이터셋으로 관계 이해, 속성 이해, 구성 이해 등을 포함하고 있는 데이터셋입니다.
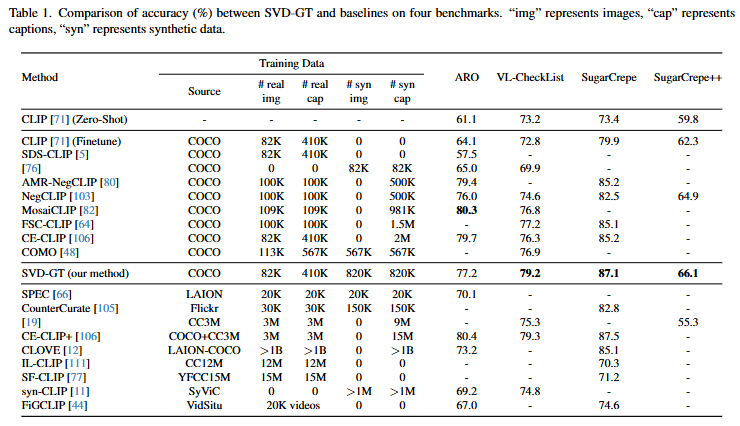
Table 1.은 저자가 제안하는 SVD-GT의 성능을 보여줍니다. ARO를 제외한 모든 COCO 학습 방법론 중에 SOTA를 달성했으며, 저자는 이를 통해 저자가 제안하는 SVD-GT가 Compositionality에 효과적인 방법임을 주장합니다. 저자는 ARO 데이터셋에서의 성능이 낮은 이유로 ARO 데이터셋 자체가 문법적으로 오류가 많은 데이터셋이기 때문이라고 주장하고 있습니다. SVD-GT는 정제된 데이터 학습에 초점을 맞춘 방법론으로 문법적으로 오류가 많은 데이터셋에서는 성능이 하락할 수 있음을 말하고 있습니다. 개인적으로 저자의 설명이 맞다고 하더라도 일반화 능력이 떨어지는 것은 아닐까 생각되긴하지만, 다른 데이터셋에서는 SOTA를 달성했음에 좀 더 주목하고 ARO 데이터셋에서의 성능이 낮은 이유 분석은 짧게 언급만 하고 넘어갑니다.
Ablation Study

Table 2. 는 Ablation Study입니다. Synthetic Caption이 Synthetic Image보다 성능 향상에 도움을 많이 준다는 것을 확인할 수 있고 두 데이터를 모두 활용할 때가 제일 좋은 효과를 보인다는 것을 확인할 수 있습니다. Image Feature Injection도 상당히 효과적임을 표에서 확인할 수 있습니다. #10의 성능을 확인하면, Easy Negative 샘플에 높은 마진을 적용하는 방식은 오히려 성능을 낮추는 방법이라고 설명하고 있습니다. 그렇다고 Hard Negative만을 활용하는 것보다는 Adaptive Margin Loss를 적용하는 것이 효과적이며 Hard Negative의 효과가 효율적임을 보이고 있습니다. 또한, positive sample을 같이 활용하는 것이 가장 성능에 도움이 되는 것임을 보여주고 있습니다.
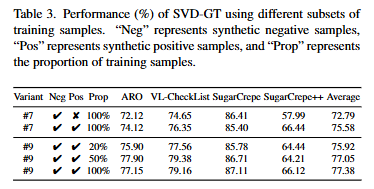
추가로 저자는 50%의 데이터만을 사용했을 때에도 대부분의 모델보다 높은 성능을 달성했다고 말하고 있습니다. 20% -> 50% -> 100% 로 데이터의 양을 증가시킬때마다 성능이 향상되었으며, 20%에서 50%로 데이터를 늘릴 때 가장 효율적임을 보이고 있습니다.
감사합니다.
안녕하세요! 좋은 리뷰 감사합니다.
Synthetic data를 통해 compositional understanding 능력을 향상시키고자 한 논문으로 이해했는데요, Real과 synthetic sample을 함께 사용해 VLM을 학습하는 과정(b)에서 sigmoid기반의 contrastive loss를 쓴 것으로 보입니다. 기존에 익숙한 softmax 기반이 아닌 sigmoid 기반의 cl loss를 사용한 이유가 있을까요 ? 이렇게 했을 때 어떤 이점이 있는지도 궁금합니다.
감사합니다 !
안녕하세요 정윤서 연구원님 좋은 댓글 감사합니다.
일반적으로 softmax 기반의 contrastive learning은 hard negative에 민감하게 반응한다는 단점이 있습니다. 그 이유는 확률분포의 형태로 클래스 간 확률을 나눠갖게 되는데 이는 positive의 유사도가 낮아지고 hard negative의 유사도가 올라갈 수 있기 때문입니다. 이는 compositional generalization의 관점에서는 바람직하지 않습니다. 반면 sigmoid는 각각이 독립적으로 시행되기 때문에 클래스간 불균형에 강건하고 hard negative에도 강건하기에 본 논문에서 저자는 sigmoid 기반의 contrastive learning을 사용했습니다.
감사합니다.
안녕하세요 성준님 리뷰 감사합니다.
“ARO 데이터셋에서의 성능이 낮은 이유로 ARO 데이터셋 자체가 문법적으로 오류가 많은 데이터셋이기 때문이라고 주장하고 있습니다. SVD-GT는 정제된 데이터 학습에 초점을 맞춘 방법론으로 문법적으로 오류가 많은 데이터셋에서는 성능이 하락할 수 있음을 말하고 있습니다. ” 라는 표현을 하셨는데 정제된 데이터로 학습한것과 문법적인 오류가 많은 데이터셋에는 어떤 상관관계가 있는건가요? 또 일반화 능력과 관련해서 성준님 의견이 궁금합니다!!
안녕하세요 김영규 연구원님 좋은 댓글 감사합니다.
compositional generalization의 관점에서 노이즈가 많은 데이터를 사용하는 것은 리스크가 큽니다. 그 이유는 문장 내 맥락을 잘 파악해야하는데 gt가 제대로 주어지지 않는 다면 제대로 학습한다고 보기가 어렵기 때문입니다. 또한 본 논문의 방법론은 생성 데이터에 크게 의존하기에 노이즈를 줄이는 것이 중요하다고 볼 수 있습니다. 일반화 능력에 관해서는 생성 데이터를 사용하는 것 자체가 학습 데이터의 볼륨을 늘리는 것이기에 도움이 될 것 같습니다. 노이즈가 있더라도 많은 데이터를 사용하는 것은 다른 거대 사전학습 모델들처럼 굉장히 많은 데이터를 사용하는 경우에는 또 다른 결과가 나올 수 있지만, 본 논문에서의 결과만을 봤을 때는 볼륨이 커지더라도 잘못된 라벨로 학습을 할 가능성이 높기에 크게 도움은 되지 않을 것 같다고 생각합니다.
감사합니다.
안녕하세요 성준님 좋은 리뷰 감사합니다.
본문의 Method에서 질문이 있습니다. 그림 2에서 T2I 모델이 이미지를 생성할 때, Text Encoder에서 나온 임베딩 값과 Image Encoder에서 나온 값이 함께 입력으로 들어가는 것 같은데, 이때 Padding Embedding 자리에 단순히 Image Embedding 값을 채우는 방식인가요?
추가적으로 Synthetic Negative 샘플과 Synthetic Positive 샘플을 생성하는 과정에서, 이 샘플들이 실제 이미지와 유사한지를 어떻게 보장하나요? 단순히 T2I 모델이 생성한 이미지를 사용하나요, 아니면 추가적인 평가 과정이 있는지 궁금합니다.
감사합니다.
안녕하세요 정의철 연구원님 좋은 댓글 감사합니다.
코드가 아직 공개되지 않아 정확하지 않을 수 있지만, 논문의 내용에 따르면 padding embedding자리에 단순히 Image Enbedding 값을 채우는 방식이 맞습니다. 그리고 실제 이미지와 유사한지에 대한 평가는 진행하지 않습니다. 다만 저자가 정성적인 결과를 통해 저자의 방식이 유효하다는 것을 입증하는 데에 사용합니다. off-the-shelf T2I 모델을 사용하는 것으로 보아 생성형 이미지의 퀄리티는 기존 연구의 성능에 의존하는 것 같습니다.
감사합니다.
안녕하세요 성준님 좋은 리뷰 정말 감사드립니다.
아직 저에게는 이해하기에는 어려운 논문이었지만 설명을 잘 해주신 덕분에 조금이나마 이해할 수 있었던 것 같습니다.
리뷰를 읽다가 궁금한 부분이 생겨서 답글 드립니다.
Hard Negative와 Easy Negative를 구분해서 마진을 다르게 준다고 이해를 하였는데, 제가 놓쳤을 수도 있지만 Hard Negative와 Easy Negative 구분 자체는 어떻게 이뤄지는지 궁금합니다. 예를 들어 모델이 학습 도중에 구분을 하는지 혹은 특정 threshold를 두고 사전 정의된 방식으로 나누는지가 궁금합니다!
감사합니다.
안녕하세요 안우현 연구원님 좋은 댓글 감사합니다.
hard negative와 easy negative를 구분하는 방식은 명시적인 thresholding을 통해 구분하지는 않습니다. 다만 문장 내 특정 단어에 변주를 얼마나 가하는 지에 따라 hard와 easy를 구분하고 있습니다. 즉, 문장이 의미론적으로 얼마나 원래 문장에 비해 달라지는가를 기준으로 생각합니다. 예를 들어 ‘남자 청년이 서핑을 하고 있다’라는 문장이 주어질 때에 ‘남자가 서핑을 하고 있다’는 hard negative, ‘여자가 서핑을 하고 있다’는 easy negative로 사용하는 것입니다. 이때 생성되는 이미지의 의미론적 정보가 원래 이미지와의 차이가 큰지 적은지를 통해 구분됩니다.
감사합니다.