안녕하세요, 이번주는 텍스트를 통해 3D asset을 생성할 수 있는 기술인 Text-to-3D 변환 기술에 3D Gaussian Splatting을 활용한 논문을 리뷰 해보도록 하겠습니다. 아래 이미지는 이번에 리뷰하려는 논문에서 제안한 GSGEN이라는 모델을 통해 텍스트를 통해 생성한 3D Asset인데요, 3D Gaussian Splatting의 명확한 장면 묘사의 특징을 활용해기존의 Text-to-3D텍스트 기술들이 가진 부정확한 기하 구조 문제를 해결하고, 3D prior를 효과적으로 통합하여 더욱 현실적이고 세밀한 3D 모델을 생성할 수 있었다고 합니다.

Introduction
Diffusion 모델을 베이스로 하는 text-to-image 생성 모델들은 2D 이미지에서는 좋은 성능을 보였으나 3D를 만들어 내는것에 있어서는 현실의 3D 세계의 복잡한 모습을 재현하는데 있어서 한계가 있다고 합니다. DreamFusion에서는 score distillation sampling을 사전 학습된 diffusion prior와 함께 활용해 3D scene 제작을 할 수 있었다고 합니다. 이후 많은 방법들이 속도를 올리거나 품질을 향상시켰으나, 기존의 text to 3D 방법들이 NeRF와 같은 implicit한 방법에 의존하기 때문에 3D 표현을 직접 명시적으로 하지 않고 신경망을 활용해 모델링 해야하는 점에서 근본적으로 3D prior를 조작하는데 한계가 있었고, 이로 인해 fidelity에 한계가 있고, collapse된 모습들을 많이 보여주었다고 합니다.
저자가 제안한 방법은 기존의 NeRF를 3D Gaussian으로 바꾸면서 3D pointcloud diffusion prior를 추가해 기하학적 구조의 일관성을 향상시켰다고 합니다. 저자는 먼저 3D 형태를 기하학적으로 최적화해서 초기 결과값을 만들고, 이 때 3D pointcloud diffusion prior 구조를 추가해 기하학적 구조를 일관되게 이해하는 능력을 키우고 이를 통해 같은 입력에 대해 복수의 다양한 외형을 만들어내서 결과적으로 비현실적인 3D 구조를 나타내는 Janus Problem을 해결했다고 합니다. 이어서 기하학적 바탕이 되는 모델의 외관을 디테일을 추가해 바꿔주는 appearance refinement 단계를 통해 현실적이고 안정적인 기하구조를 갖는 3D asset을 얻을 수 있었다고 합니다.
Related Work
Text-to-3D Generation
초기 Text-to-3D 생성 연구에서는 CLIP guidance를 활용하여 3D 에셋을 생성했었다고 합니다. 그러다 더 강력한 diffusion prior를 활용하기 위해 DreamFusion은 렌더링된 이미지와 diffusion prior 간의 차이를 최소화하여 3D 콘텐츠를 최적화하는 score distillation sampling을 도입했습니다. 이후 Magic3D는 낮은 해상도의 diffusion prior로 NeRF를 최적화한 다음 coarse NeRF로 초기화된 DMTET를 사용하여 latent diffusion prior에서 텍스처를 향상시키는 coarse-to-fine 전략을 사용했다고 합니다. ProlificDreamer는 SDS를 개선하고 다양한 3D asset 생성을 용이하게 하기 위해 variational score distillation을 도입했다고 합니다. 기존의 방법들은 NeRF 기반의 방법을 어떻게 더 발전시킬까? 에 대한 연구들이 진행됐던 것 같습니다. 이를 explicit한 특성을 가지는 3D Gaussian Splatting을 통해 획기적으로 개선했다는 것 같습니다. 지난번에 리뷰한 feature splatting도 3D Gaussian Splatting의 explicit한 특성을 언급했는데요, 모델을 통해 표현하지 않고 직접 표현하는 점이 3D Gaussian Splatting의 엄청난 장점인 것 같습니다. 이를 활용해 저자는 가능한 디테일 하게 표현하는 것을 목표로 하지만, 동일한 시점에 DreamGaussian이라는 논문에서는 3D Gaussian을 속도 향상에 집중시켜서 활용했다고 합니다.
Preliminary
Preliminary 섹션도 존재합니다. 논문을 읽기 위해 필요한 사전지식들인 것 같습니다. 자세히 살펴보도록 하겠습니다.
Score Distillation Sampling
DreamFusion에서 사용했던 방법 샘플링 방식이라고만 나와있어서 정보가 부족했었는데, Score Distillation Sampling(SDS)은 3D 모델을 직접 생성하는 것이 아니라, 2D 이미지 기반의 사전 학습된 확산 모델을 활용하여 3D 표현을 최적화하는 방법이라고 합니다. 3D 장면을 DIP 방식을 사용하여 3D 공간을 매개변수 θ로 표현하고, 이를 주어진 카메라 위치에서 2D 이미지로 변환하는 함수 g(θ)를 통해 최적화한다고 합니다. 핵심 아이디어는 3D 모델을 평가하는 방식으로 3D 모델을 통해 2D로 렌더링된 이미지가 사전 학습된 diffusion 모델이 생성하는 이미지와 최대한 비슷하도록 만드는 것이라고 합니다. diffusion 모델중 하나인 Imagen 모델을 활용하여 스코어를 추정하고, 이를 바탕으로 DIP 매개변수를 조정해 3D 표현을 점진적으로 개선한다고 합니다. 저자들은 이 과정을 3D Gaussian Splatting을 활용한 3D 모델에게 2D와 3D 레벨에서 각각 다른 diffusion 모델을 통해 기하학적으로 일관된 형상을 유지할 수 있다고 합니다. (3D 레벨에서는 어떻게 적용한다는건지 모르겠는데 SDS에 대한 이해가 살짝 부족한 것 같스빈다..)
3D Gaussian Splatting
이 방법론의 핵심인 3D Gaussian Splatting에 대한 설명도 있었습니다. 3D Gaussian Splatting은 3D 장면을 엄청나게 많은 3D 가우시안들로 표현하여 빠르고 효율적으로 렌더링하는 기법입니다. Gaussian Splatting은 장면을 여러 개의 3D 가우시안 분포 (위치, 색상, 불투명도, 공분산(가우시안의 형태와 방향을 나타냅니다.))으로 나타내고, 이를 2D 화면에 투영하여 이미지로 렌더링합니다. 저자의 GSGEN도 3D Gaussian Splatting을 Text-to-3D 생성 과정에 적용하여 텍스트 입력을 기반으로 3D 가우시안들을 배치하고 최적화하는 방법을 제안했습니다.
Method
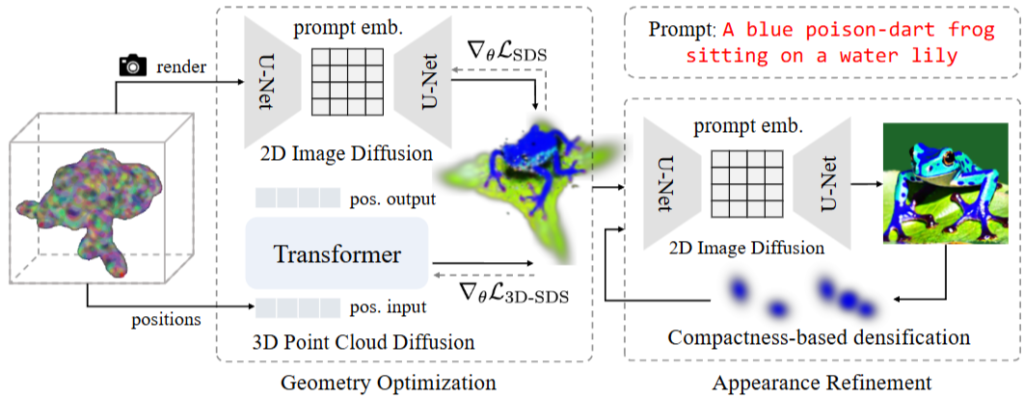
앞서 언급했던것 처럼 3D 모델을 최대한 현실적이고 정교하게 구성하는 것이 GSGEN의 목표이고, 이를 기하학적인 prior를 통합할 수 있고 유연하게 사용할 수 있는 3D Gaussian을 통해서 달성하려고 했습니다. GSGEN은 크게 두 단계로 이루어져 있습니다. Geometry Optimization과 Appearance Refinement 단계로 이루어져 있고, Geometry Optimization 단계에서는 3D pointcloud Diffusion인 Point-E의 prior를 사용해 가우시안의 위치와 크기를 조정해 예시의 개구리의 기하학적인 베이스를 만들어 줍니다. 이때 2D Image Diffuion의 prior와 함께 SDS를 사용해 일관성을 확보합니다. 위치 정보는 트랜스포머를 활용해 처리한다고 합니다. 이어서 Appearance Refinement 단계를 거칩니다. 이 때는 diffusion을 통한 2D 이미지 prior만을 활용해 가우시안을 계속 업데이트 하고, Compactness-based densification을 통해 풍부한 디테일을 완성한다고 합니다. 각 단계별로 좀 더 자세히 알아보도록 하겠습니다.
Geometry Optimization
기존 text-to-3D 기법에서 자주 발생하던 문제인 Janus Problem은 여러 시점에 오버피팅 돼서 3D 모델이 구겨지거나 비현실적인 구조를 갖는 현상이라고 합니다. 모델이 앞에서 본 것과 뒤에서 본 것이 다르다면, 각 view에 맞게 오버피팅 됐을때는 앞뒤로 구겨진 모델이 나오거나 얼굴 뒤에 다른 얼굴이 붙어있는 등 기하구조가 붕괴됩니다. 2D diffusion만을 사용해서는 이 문제를 해결하기 힘듭니다. 하지만 NeRF와 달리 3D Gaussian은 3D pointcloud를 직접 활용할 수 있기 때문에 가우시안들의 위치를 직접 조정하는 방식으로 3D 구조를 보정한다고 합니다. 3D point들을 직접 조정할 수 있기 때문에, 2D에서 사용했던 SDS 기법의 개념을 그대로 3D에 적용시키는 방법이라고 하네요. Point-E라는 사전 학습된 text-to-pointcloud diffusion 모델을 기반으로 구조를 보정하되, 이를 그대로 적용시키면 마찬가지로 왜곡이 발생할 수 있기 때문에 아래 수식을 Loss로 하는 SDS를 적용해 pointcloud를 참조하면서 올바른, 현실적인 기하 구조를 형성합니다. Loss는 2D 이미지 기반 SDS loss와 Point-E 기반 3D SDS를 조합해서 사용합니다.
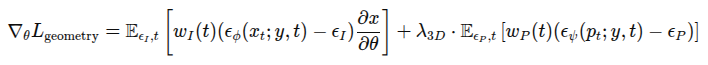
첫째 항은 기존의 SDS loss를 기반으로 2D 이미지 측면에서 최적화하는 과정이고, 두 번째 항은 3D 공간에서 Gaussian 위치를 최적화하는 과정입니다. 3D 가우시안 기반으로 렌더링된 2D 이미지 x_t가 주어지면, 이 이미지가 2D diffusion이 생성한 이미지와 비슷하도록 Gaussian의 매개변수들을 업데이트 한다고 합니다. 이를 여러 view에서 동시에 반복해 Gaussian을 통해 렌더링 된 2D 이미지들이 일관되게 각 view를 2D diffusion이 생성한 이미지와 비슷하게 업데이트를 해줍니다. 이 때 유사도를 비교하는 score로 Imagen 모델의 노이즈와 렌더링 된 이미지의 노이즈를 비교한다고 합니다.
두 번째 항은 3D pointcloud 들의 위치 정보를 포함한 노이즈가 추가된 Gaussian의 3D 좌표 p_t 기반의 loss입니다. Point-E에서 생성되는 diffusion의 노이즈는 Gaussian의 현재 3D 상에서 제거해야 할 노이즈의 방향의 기준을 잡아준다고 합니다. 이 노이즈 예측값과 실제 노이즈의 차이를 계산해 3D Gaussian들이 Point-E가 생성하는 포인트 클라우드의 자연스러운 형상과 일치하도록 위치를 수정하는 방향으로 최적화합니다.
이렇게 3D 형상을 최적화 하되, 여러 view에서 렌더링 했을 때도 정상적인 모습을 보일 수 있도록 2D와 3D를 동시에 최적화합니다. Gaussian을 pointcloud에 맞춰서 최적화 한다는 것이 살짝 와닿지 않긴 했지만 pointcloud를 기준으로 Gaussian들의 올바른 위치를 유도하는것을 목표로 한다고 합니다. 공분산은 2D로 렌더링 했을 때 어떻게 보이는지를 통해 최적화하는 것 같습니다.
Appearance Refinement
Geometry Optimization을 통해 3D 구조는 초ㅣ적화 했지만, 아직 외형 디테일이 부족한 상황이기 때문에 외형을 개선하고 Gaussian의 밀도를 높여주어야 합니다. view space에서 spatial gradient가 큰 Gaussian을 분할하여 밀도를 높여준다고 합니다. 하지만 SDS loss는 확률적으로 변화하는 특성을 가지고 있기 때문에, 이 방법을 그대로 적용하지 않는다고 합니다. 기존의 SDS를 Gaussian에 그대로 적용하게 되면 너무 작은 임계값은 불필요하게 많은 과도한 Gaussian들을 생성하는 문제를 가지고, 임계값이 크다면 Gaussian이 부족해 흐릿한 형상을 얻게 됩니다. 따라서 아래 그림과 같이 Compactness-based Densification을 제안했습니다. 먼저 KD-Tree를 이용해 각 Gaussian의 KNN을 찾고, 특정 Gaussian과 이웃 Gaussian 간의 거리가 서로의 반지름(radius) 합보다 작다면, 두 Gaussian 사이에 새로운 Gaussian을 추가하는 방식으로 사이사이에 잘 껴넣는 느낌으로 진행하는 것 같습니다. 이렇게 자연스럽게 빈 공간들을 채울 수 있다고 합니다.
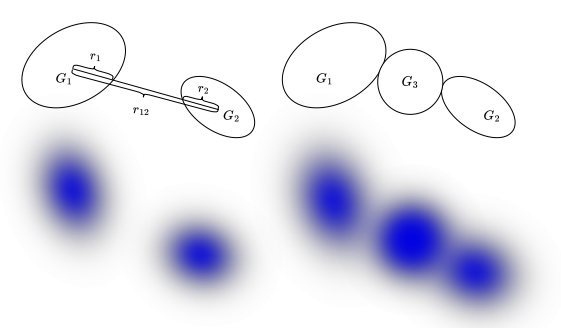
Gaussian은 잘 채워넣는 것도 중요하지만 불필요한 Gaussian들은 제거해주어야 하는데요, 이를 통해 투명도 기반 필터링을 수행합니다. 중심에서 멀어질수록 불투명도를 줄인 후 임계값 보다 낮은 불투명도를 갖는 Gaussian들을 제거해준다고 합니다. 하지만 이를 가지고만 pruning을 진행할 경우 일관성을 유지하기 힘들 수 도 있기 때문에 기존 geometry 최적화에서 얻은 Gaussian 위치와 너무 많이 벗어나는 Gaussian에 패널티를 주는 항을 추가했다고 합니다. 정리하자면 아래와 같습니다.
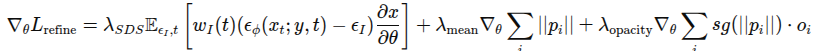
Initialization with Geometry Prior
3D Gaussian Splatting을 활용한 text-to-3D 모델에서는 초기 3D 형상을 어떻게 설정하느냐가 최종 결과에 큰 영향을 미친다고 합니다. 이전 연구에서도 단순한 초기 패턴으로 시작하면 최적화 과정에서 3D 모델이 비정상적인 형상으로 수렴할 위험이 크다는 점이 확인되었고, 이를 해결하기 위해 Gaussian들의 초기 위치를 기존의 3D 형상을 기반으로 설정하는 방식을 채택했다고 합니다.
초기화 방식은 크게 두 가지로 나뉩니다. Point-E 모델을 활용하여 텍스트 프롬프트로부터 초기 포인트 클라우드를 생성하는 방식과 사용자가 직접 제공한 3D 모델을 활용하는 방식입니다. Point-E는 텍스트 기반으로 대략적인 3D 포인트 클라우드를 생성할 수 있고, 사용자가 직접 3D 형상을 제공하는 경우에는 이를 Gaussian 초기화에 활용할 수 있도록 mesh인 경우 데이터를 포인트 클라우드로 변환하여 적용한다고 합니다.
초기 Gaussian의 색상은 Point-E가 생성하는 컬러 정보를 그대로 사용할 수도 있지만, 실험 결과 이를 직접 적용하면 오히려 최적화 과정에서 문제가 발생할 수 있다는 점이 확인되었고, Gaussian에 랜덤한 색상을 부여하고, 이후 Appearance Refinement 단계에서 점진적으로 색상을 최적화하는 방법을 택했다고 합니다. 또한, Gaussian의 크기와 불투명도는 초기에는 고정된 값으로 설정한 뒤, 학습 과정에서 점진적으로 업데이트 합니다. Gaussian의 회전 행렬도 초기에 Identity Matrix로 설정하여, 처음에는 특정 방향성을 갖지 않도록 하고 최적화 과정에서 방향이 자동으로 조정되도록 합니다. 마지막으로 pointcloud에서 Gaussian의 개수를 적절하게 맞춰서 시작한다고 합니다. 너무 많은 갯수를 가지고 시작하면 계산량이 급격히 증가할 수 있기 때문에, 샘플링 기법을 활용하여 적절한 개수만 선택한다고 합니다. 이를 위해, 포인트 클라우드에서는 Farthest Point Sampling을 적용하여 공간적으로 균형 잡힌 점들을 선택하고, 메시 데이터에서는 Uniform Surface Sampling을 통해 표면에서 고르게 점을 추출하는 방식을 사용했다고 합니다.
Experiments
GSGEN을 stable Diffusion 기반으로 구현해 기존 SOTA 모델들과 동일하게 Guidance Scale = 100을 사용해서 실험을 진행했고, Stable Diffusion 체크포인트는 runwayml/stable-diffusion-v1-5 버전을 사용했다고 합니다. 또 기존의 DreamFusion과 동일한 focal length, 고도, 방위각을 사용했다고 합니다. 또 카메라 위치를 더 균등하게 샘플링 하기 위해 방위각에 Stratified Sampling을 적용했다고 합니다.
실험결과 기존 SDS 기반 방법들은 동일한 가이드 모델과 프롬프트를 사용했음에도 불구하고 3D 기하 구조가 붕괴되는 문제를 보였고, 특히 DreamFusion, Magic3D, Fantasia3D와 같은 기존 모델들은 Janus Problem 으로 인해 형상이 왜곡되는 경향이 있었다고 합니다. 반면, GSGEN은 3D Gaussian Splatting을 기반으로 안정적인 기하 구조를 유지하면서도 SDS 손실을 활용하여 디테일한 요소를 잘 표현할 수 있었습니다. 세부적인 디테일 보존 측면에서도 GSGEN은 다른 모델들 대비 뛰어난 성능을 보여주었습니다. 예를 들어 스시 위의 무늬나 공작새 깃털의 세밀한 패턴, 초가 지붕의 질감과 같은 디테일들이 다른 모델보다 더욱 선명하게 표현되었다고 합니다. Magic3D와 Fantasia3D는 메시 기반 방법의 한계로 인해 Over-smoothed한 기하 구조를 생성하는 경향이 있었으며, ProlificDreamer는 Janus 문제로 인해 비현실적인 여러개의 얼굴이 나타나는 모습을 보 ㄹ수 있습니다.


Ablation 실험 결과, Point-E 기반 initialization은 기존보다 형상 자체가 조금 더 현실적인 3D 구조를 형성하는 것을 볼 수 있고, 3D Prior를 활용하면 Janus 문제를 해결할 수 있으며, Compactness 기반 밀도 증가 방식은 Gaussian을 dense하게 만들어 세부적인 디테일을 만드는 데 효과적인 것을 볼 수 있습니다.

Conclusion
GSGEN은 텍스트 프롬프트가 지나치게 복잡하거나 논리적으로 어려운 경우에는 원하는 3D 모델을 정확하게 생성하지 못하는 한계를 가진다고 합니다. 뭔가 어떻게 보면 당연한 말이지만 Point-E와 Stable Diffusion의 언어 이해 능력이 제한적이고 diffusion 자체의 성능에도 복원해내는 것에 있어서 한계가 있지 않나 싶습니다. 또, 3D Prior를 활용하더라도 Janus Problem을 완전히 해결하는 것은 어렵고, 특정한 프롬프트에서는 여전히 기하 구조가 붕괴될 가능성이 있다고 하는데, 개선 방법이 무엇일지는 고민을 해봐야 알 것 같습니다. 이러한 한계에도 불구하고, Gaussian Splatting을 활용한 text-to-3D 생성 기법을 제안하여 새로운 파이프라인을 통해 기존보다 훨씬 그럴싸한 3D 모델을 만들어 낼 수 있는 모델인 것 같습니다.