안녕하세요. 지난 주 논문 제출을 마치고 약 2달 만의 리뷰입니다. 금일 리뷰 하는 논문은 ACL (Association for Computational Linguistics) 학회로 아마 연구원 분들은 익숙하진 않으실 학회이겠지만, 자연어처리 분야의 CVPR 급의 Top-Tier 학회입니다. 왜 이번 논문을 읽게 되었는지, 사담과 함께 시작해보겠습니다.
제가 이전에 한 연구인 Multispectral Pedestrian Detection, Domain Learning에 이어 이번 주에는 추후 연구 주제를 고민하였습니다. 현실적으로 석사 졸업 이후 취업을 위한 연구와 해보고 싶은 연구 중에 고민이 되었는데, 이 둘을 충분히 충족할 수 있는 연구에 대해 생각하다 결정한 길이 VLM 모델의 경량화 또는 최적화입니다. 하지만 이들을 위한 양자화와 같은 연구는 그 연구의 가치가 높지만 남은 시간과 제 역량을 고려할 때 힘든 길이였고, 그렇기에 딥러닝 측면의 방식에서 어떤 갈래의 연구들이 성행하고 있는 지에 대해 살펴보고 있습니다. 앞으로 한 달 정도는 해당 연구에 대한 다양한 갈래의 논문을 읽으며 흐름을 살펴보고 아이디어를 정립한 이후, 4월 중순 이후에는 다시 논문 작업을 천천히 시도해보려 합니다. 저희 연구실에서도 아직 해당 분야에 대해서는 많이 탐구 되지 않았는데, 이번 기회로 관심을 가져봄도 좋지 않을까 싶습니다.
Introduction
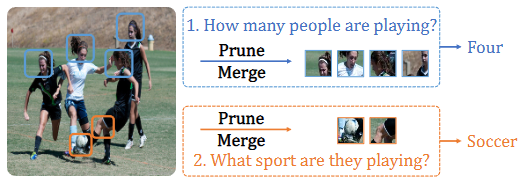
최근 Vision 관련 대부분의 태스크는 VLM을 빼놓고 말할 수 없습니다. Recognition, VQA, Visual Reasoning 등의 다양한 태스크에서 우수한 제로샷 성능으로 그 효과를 보이지만 VLM 논문이나 VLM이 사용된 논문을 보면 알 수 있듯, 일반적인 모든 VLM 모델들에서 필수적인 요소는 이미지와 텍스트 간 Align을 위해 Attention이 종종 사용되어 모델이 무겁습니다. 모델이 무겁다는 의미는 메모리 소비나 연산량 (Latency)이 높아진다는 의미입니다. 모델 경량화 연구가 유의미한 이유는 이런 좋은 성능을 보이는 모델들이 무겁기 때문에, 클라우드 배포나 스마트폰에서 사용하기 어렵습니다. 본 논문에서 저자의 직관은 “입력 이미지는 중복되는 정보를 포함하며 특정 태스크를 위해 이미지의 특정 부분만 필요하다.”입니다. 이 때 말하는 이미지의 특정 부분이라 함은 Salient Region 또는 텍스트에서 언급되는 영역으로, 위 Fig 1을 예시로 봅시다. 두 질문, “1. How many people are playing?”과 “2. What sport are they playing”에 대해, 2번째 질문의 경우 대부분의 사람이나 필드와 같은 영역은 굳이 필요하지 않습니다.
이전의 Vision-only 또는 Text-only 연구에서 Image/Text token을 줄이며 모델의 연산량을 줄이고자 pruning으로 태스크에 대한 non-salient token을 제거하는 방식을 학습하거나, 또는 merging으로 유사한 의미의 token을 묶습니다. 저자는 이들의 방식을 따로 활용함은 VL 문제에서 두 문제가 존재합니다: 1. salient image token은 텍스트 입력에 따라 다릅니다. 즉, 위 Fig. 1에서 1번째 질문에서는 사람이, 2번째 질문에서는 축구공이 salient image token에 해당합니다. 2. 모달리티 (이미지, 텍스트)에 관계없이 token을 merging하면 VLM에 혼동을 주는데, 이는 텍스트와 이미지 token의 representation이 동일한 semantic space에서 완벽히 align되지 않기 때문입니다.
본 논문에서 저자는 PuMer, VLM 모델에서 Pruning과 Merging을 연계하여 활용하는 방식을 소개하며, 텍스트에 관계없는 이미지 token을 제거하는 방식 (pruning)과 각 모달리티 별로 이미지와 텍스트 토큰을 합치는 방식 (merging)을 활용합니다. 이에 따른 (1) text-informed image token pruning과 (2) modality-aware token merging을 소개하며, 뒤에서 소개하겠지만 특히 pruning에서 파라미터가 없는 token reducer를 활용하여 학습 시에도 메모리 소비가 늘어나지 않는다는 추가적인 장점도 있습니다. 그럼, 방법론에서 다시 자세히 살펴보겠습니다.
Background and Overview
본 논문에선 친절히 Preliminaries에 대해 안내해주네요. 아마도 자연어처리 학회이다 보니, VLM에 대한 이해가 CV 학회에 비해서는 부족하여 이러한 점을 추가하지 않았을까 합니다. 신입 연구원 분들도 이 글을 읽을 수 있다 보니, 간단히 짚고 넘어가겠습니다.
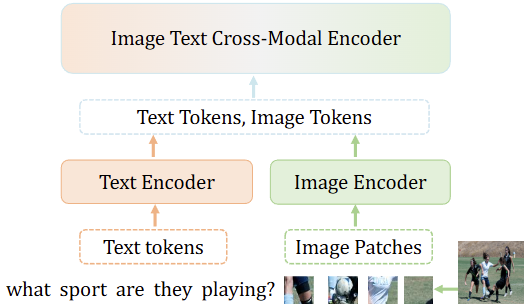
위의 Fig. 2는 Text Encoder와 Image Encoder, 그리고 이들에 대한 Cross-Modal Encoder로 구성된 일반적인 VLM 구성을 보여줍니다. Text Encoder와 Image Encoder는 각각의 Backbone도 있고, FPN과 같은 Feature Representation을 높이기 위한 모듈들도 있겠죠. 이들은 입력에 대해 텍스트는 Text tokens로, 이미지는 Image Patches로 토크나이징합니다 (이 토크나이징에서 얼만큼 좋은 품질의 token으로 만드는지는 이번 논문에서는 중요하지 않습니다). 이후 Cross-Modal Encoder에 이들의 토큰이 쉽게 생각하면 막 섞이게 됩니다. 이 섞이는 과정은 텍스트와 이미지라는 각기 다른 모달리티의 입력에 대해 정보를 교류하며 서로에 대해 이해하는 과정이라 생각하면 쉽습니다. 이렇게 정보를 교류하는데에는 Transformer 방식 (Cross-attention)만한게 없습니다. 일반적으로 VLM에서 텍스트 입력에 대한 token은 기껏해야 몇 개에서 몇 십개이지만 (위 Fig. 1의 예시에서는 4개의 단어로 구성되어 있습니다), 이미지의 경우 입력 해상도를 384×384에 patch의 크기를 16으로 둔다면, 토큰의 수는 (384/16)^2 = 576으로 몇 백개, 해상도에 따라 몇 천개의 patch (token)를 가질 수도 있습니다.
PuMer: Text-Informed Token Reduction Framework
위의 예시로 든 VLM 모델에 이전의 연구에서 흔히 사용되는, token을 줄이는 방식을 활용한다고 생각해봅시다. 그 전에, 당연히 왜 줄이는지에 대해 잊지 않아야겠죠. 다시 마지막으로 리마인드하자면 연산 효율성을 위함입니다. 그럼 연산 효율성을 높이고자 선택할 수 있는 하나의 방식은 단순히 많은 퍼센트의 Image token을 지우면 되겠지만 (앞서 설명하였듯 Text token은 기껏해야 몇 십 수준이기에), 당연히도 정보 손실이 오게 됩니다. 연산 효율성이 최우선 순위인 것은 맞지만, 동시에 최우선 순위는 그 때의 성능이 너무 떨어져서는 안됩니다*. 만약 Fig. 2에서 축구공에 해당하는 token을 지운다면, 뭐 모델 입장에서는 당연히 알 수 없겠죠. 저자는 위의 문제점에서 다음의 방법을 제안합니다.
* 제 사견에서, 이러한 Trade-off는 특히 최신 연구에서는 다양한 원인으로 인해 어쩔 수 없는 요소입니다. 잠시 그 이야기를 해보자면, 과거의 CNN-only 방식만 살펴본다면 오히려 Pruning과 같은 방식이 Overfitting을 방지한다거나, 또는 이미지의 Background가 아닌 Object에 더욱 집중하여 모델의 Representation을 높이기도 하는, 꼭 Trade-off가 아니더라도 그 방식들이 효율성 뿐만 아니라 더 좋은 성능을 보이기도 하였습니다. 그런데 데이터의 양이 많아지며 동시에 Transformer 이후 모델의 크기가 기하급수적으로 커져감에 따라 규모의 경제가 되어가는 느낌입니다. 쉬운 예시로 COCO, Pascal VOC와 같이 아주 예쁜 데이터가 아니더라도, 다소 Noise한 데이터도 수 많은 데이터라면 그들을 활용함이 더 좋은 성능을 보이는 것처럼 앞서 설명한 관점 (모델의 Representation을 높이기도 한다는 측면)에서는 이제 “아니, 그래도 그냥 더 많은 데이터로 학습하면 그 배경을 학습하거나 아니면 쓸모 없다고 여겨질 수 있는 토큰을 학습함도 크게 보면 더 좋아”라고 생각하게 됩니다.
Token Reducers
방식은 비교적 간단합니다. cross-modal encoder내 n개의 layer에 대해, 첫 번 째 f번째 레이어 이후, 특정 layer에서 k%의 토큰을 지웁니다 (pruning). 단순히 지우지는 않고, 텍스트 정보에 가이드 받아 지우며 이 토큰들은 이후의 layer에서 사용되지 않습니다. 그 이후 token reducer는 r%의 이미지 token과 t%의 텍스트 token을 합칩니다 (merging). 위 방식의 token reducer는 f와 n 사이의 레이어 몇몇에 걸쳐 사용됩니다. 직관적으로 지워진 토큰들이 이후의 layer에서 사용되지 않는다는 점에서, 앞 쪽의 layer에서 token을 줄인다면 더 높은 연산 효율성을 보일테지만, 반대로 그만큼 해당 token이 충분히 필요한지/하지 않은지에 대해 명확하지 않는 지점일 수 있기에 성능 저하가 심해질 수도 있습니다. 이후의 과정을 포함하여 저자는 다음의 알고리즘에서 전체 과정을 요약하나, 의사 코드는 아니기에 다소 복잡해보입니다. 고로, 계속 문장으로 설명하도록 하겠습니다.

각 token reducer는 저자가 제안하는 두 가지의 non-parameteric module을 포함합니다. 우선 non-parameteric이라는 용어에서 알 수 있듯, 학습 대상의 모듈은 아닙니다. 첫 번째는 Text-Informed Pruner (TIP)로, 텍스트와 연관되지 않은 Image token을 지웁니다. 두 번째는 Modality-Aware Merger (MAM)으로, 이미지와 텍스트 각각 이내에서 유사한 토큰을 병합합니다. 이들에 대해서는 아래에서 다시 다룰테며, 중요한 점은 이들이 각각 쓰인다면: 예를 들어 MAM이 없이 TIP만 쓰인다면 유사한 효율성 향상을 위해서는 높은 퍼센트의 pruning을 진행해야 하므로 정보 손실이 심해질 것이며, 반대로 MAM만 단독으로 쓰인다면 그 자체만으로 정보 손실 정도를 줄이면서도 효율성 향상에 어느 정도 기여할테지만, 실질적인 효율성 향상에 큰 기대를 하기에는 어렵습니다 (축구공이 중요하다면, 축구공에 대한 이미지 토큰을 잘 병합하더라도 남은 99%의 이미지 영역은 여전히 그대로 사용될 것이기 때문입니다). 이제 각 모듈에 대해 살펴보겠습니다.
Text-Informed Image Pruning
TIP의 핵심은 텍스트와 연관되지 않은 Image token을 찾아내는 과정 (반대로 말하면, 텍스트와 연관된 Image token을 찾아내는)입니다. 이전의 연구는 어떤 Image token을 pruning해야하는지에 대해 학습 가능한 파라미터를 활용하였지만, 저자는 이러한 파라미터가 결국 연산 효율성 측면에서는 좋지 않다는 관점에서 파라미터가 없는 방식을 활용하고자 합니다. 그렇다면 다시 말해, 이전 연구에서와 같이 어떤 Image token을 pruning해야하는지를 알아내어야 하는데, 이 모듈의 전제가 텍스트와의 연관성이다 보니 Cross-attention 과정에서 계산되는 Score를 활용합니다. 이미 쓰이는 것을 다른 관점에서 바라보아 우리가 원하는 용도로 활용하면서 그 이점을 발견하는, 개인적으로 제가 흥미로워하는 방향성의 연구입니다 (이번 제출 논문에서 Depth Map이라는 요소를 쓴 것이 이러한 직관에서 출발하였습니다). 이러한 TIP는 학습 시에도 활용될 수 있기에, 더 빠른 학습을 보장한다는 장점도 존재합니다. 수식적으로 살펴보자면 각각의 l번째 Cross-modal layer에서 Token reduer가 적용될 때, Text token vector를 T, Image token vector를 V, Text-to-image cross-attention score를 A로 두면 다음의 수식으로 모든 Image token에 대한 Text-saliency score를 정의할 수 있습니다.
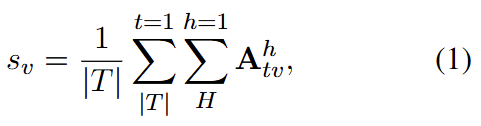
|T| 는 Text token의 수, H 는 Cross-attention head의 수, t와 v는 각각 text와 image token을 의미합니다. 이 Text-saliency score는 곧즉 더 높은 score를 가질 수록, 이미지와 텍스트가 그만큼 연관성이 깊다는 측도이니, 이후 우리는 이 score를 기반으로 top-k개의 Image token만 남기면 됩니다. 어렵지 않고 굉장히 단순한 방식입니다.
Modality-Aware Merging
위에서 소개한 TIP가 적용되고 나면, Image token은 텍스트와 연관된 토큰들만 남을 것이 기대되지만, 여전히 중복된 정보들을 포함할 수 있습니다. 다시 Fig. 1의 예시를 보면 축구공에 관련된 토큰은 뭐, 영역 자체가 많지 않아 몇 개 정도겠지만 질문 1의 사람과 관련된다면 수십개의 토큰이 될 수 있습니다. 텍스트에서는 이전 연구에서 밝혀낸 바에 따르면 Self-attention 연산이 문맥적으로 유사한 정보를 점진적으로 생성해내기에, 여기서 다시 정보의 중복이 발생한다고 봅니다. Self-attention 연산이 유사한 정보를 생성해낸다기에는 제가 그 이전 연구까진 읽어보지 않아 정확한 느낌이 오지 않지만, 또 다르게 보면 Text encoder에는 보통 입력 문장의 길이를 맞추기 위해 Padding이 들어가는데, 이로 인한 중복도 발생합니다.
MAM에서의 핵심은 “의미적(Semantic)으로 유사한 Token을 이미지와 텍스트 각각에서 발견해내고, 이들을 하나의 Token으로 병합함”에 있습니다. 결국 중요한건 의미적으로 유사한 Token을 어떻게 찾는지에 달렸는데,이 과정이 파라미터에 따라 결정되거나 또는 그 과정에서 과도한 연산량이 들어간다면, 다시 본래의 목적인 연산 효율성을 방해하게 됩니다. 아주 쉬운 예시로 K-means clustering과 같은 방식은 결국 모든 Token 과의 연산이 포함되어야 하기에 비효율적입니다. 그렇기에 저자는 Bipartite soft matching 알고리즘을 활용합니다. 이 알고리즘과 MAM의 전체 과정은 Fig. 3와 함께 보겠습니다.
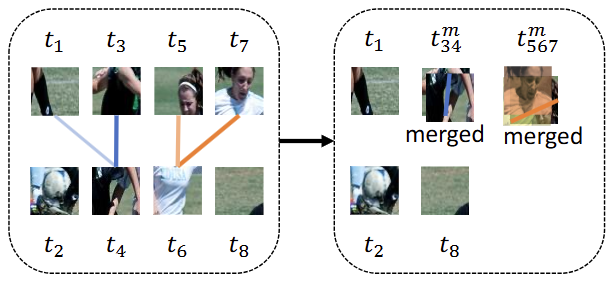
위 Fig. 3은 t1, t2, …, t8의 Image token이 존재합니다 (Text token에도 동일하게 사용되지만, 시각적 이해를 위해 Image token을 예시로 설명합니다). Bipartite soft matching에서는 우선 입력 Image token은 홀수끼리/짝수끼리의 두 집합으로 묶습니다. 홀수끼리 묶인 Token 집합(t1, t3, t5, t7)을 E, 짝수끼리 묶인 Token 집합(t2, t4, t6, t8)을 O로 명시하겠습니다. 이제 O의 각 Token을 E의 Token들과 비교하여, 유사성을 계산합니다. 이 때의 유사성은 Self-attention에서 Key와 Value 사이 그들의 유사성을 측정한다는 점에서 본 따, 토큰의 Key들의 값을 곱하여 사용합니다 ( S_p^{t_1 t_2} = K_{t_1}K_{t_2} ). 이후 top-r개의 유사성을 토대로, 묶습니다. 저자는 이 유사성을 토대로 top-r개의 연관된 Token을 찾아내며, 매칭되지 않은 E와 O에서의 나머지의 Token은 그대로 둡니다. 이 과정으로 Fig. 3의 오른쪽 그림에서와 같이 총 8개의 Token이 묶인 이후 5개가 남게 됩니다 (계산해보면 37.5%만큼 줄이는 효과를 보입니다). 왜 이 방식이 이전의 연구 (대표적인 예시로 K-means clustering)에 비해 효율적인지를 쉽게 생각해보면, 물론 위 그림에서 동일 집합 내의 t5와 t7, t4와 t6가 묶이는게 좋아보일 수도 있겠죠. 하지만 그렇게 하기 위해선 모든 Token과 1:1, 즉 다시 말해 K개의 Token에 대해 K*(K-1) 번의 연산이 필요합니다. 반면 이 방식으로는, t5와 t7 사이 교량 역할인 t6가 이들을 묶어주는 효과도 불러오면서 연산량은 그 절반으로 낮출 수 있게 됩니다.
이후 저자는 Trade-off에서 성능 저하를 줄이고자 Knowledge distillation loss를 추가로 활용하는데, 뭐 사실 이렇게 특정 목적을 위해 기존의 방식을 차용한 것 자체는 본 논문의 핵심은 아니라고 보기에, 길게 설명하진 않겠습니다 (아래 Ablation 표에서 나오기에 짚고만 넘어갑니다). 제가 위 TIP와 MAM 모듈을 통해 하고자 하는 말은, 하고자 하는 일 (연산 효율성 증대)을 위해 어떻게 할 수 있을까를 고민하다가, 기존에 이미 사용되고 있던 것을 다른 시각으로 바라보아 활용한다는 점에서 높은 점수를 주고 싶습니다. 이제 실험을 보고 마치도록 하겠습니다.
Evaluation Setup
저자는 당시의 SotA VLM인 ViLT와 METER를 기반으로 실험합니다. ViLT는 110 million parameter를, METER는 330 million parameter를 가지는 모델로, 각각 PuMer-ViLT와 PuMer-METER로 명명됩니다. 두 VLM 모두 12개의 Transformer Encoder (위에서 설명한 Cross-modal Encoder)를 가지는데, 저자는 Image-Text Retrieval, VQA, Visual Entailment, Visual Reasoning의 4가지 태스크에서 이들의 성능과 효율성을 비교합니다.
VLM 외에, 연산 효율성의 비교를 위한 이전 연구의 방법론은 3가지입니다. 첫 번째는 DynamicViT로, 앞서 말한 학습 가능한 파라미터 (MLP) 기반의 pruning 방식입니다. 두 번째는 ToMe로, ViT의 Token merging 방식입니다. 세 번째는 Smaller Resolution으로, 연구의 방법론은 아니지만 단순히 입력 이미지의 해상도를 줄이는 직관적인 방식입니다.
Trade-off를 모두 고려해야 하다보니, 평가 방식은 단순히 Accuracy가 중요함은 아닙니다. 저자는 PuMer 방식의 적용 이전/이후의 Accuracy 비교 (3번의 평균)와 동시에 Throughput (examples per second)의 증가 (Throughput Increase)를 리포팅하며, 동시에 Memory 하락 (Memory Reduction)을 리포팅합니다. 저자의 말에 따르면, 이 방식(Throughput과 Memory)은 FLOPs에 빕해 더 정확한 비교 방식이라고 합니다. 또한 해당 연구에서는 Batch와 GPU도 동일한 환경에서 구현/구동됨이 중요한데, Inference Throughput 측정을 위해 저자는 GPU memory가 OOD될때까지 Batch를 늘린 이후 한 GPU에서 30초 동안 최대 Throughput을 측정합니다. 반면 Memory 측정을 위해서는 동일한 Batch에서 측정을 하며, Peak memory를 보고합니다.
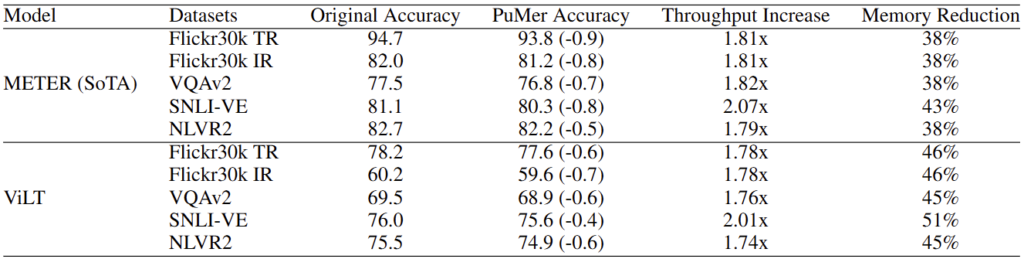
Tab. 1의 PuMer 적용에 따른 Accuracy, Throughput, Memory 비교를 살펴보면 성능은 기존에 비해 1% 미만으로 하락하는 모습을 보입니다. 반면, 1.7x-2x의 speedup과 35-51%의 메모리 소비가 감소한 모습을 보입니다. 성능 하락이 1%가 안된다는 말은 3번의 구동에 따른 평균을 고려할 때 랜덤성의 수준이 아닐까 생각이 들지만, 추론 속도의 측면과 메모리 소비량을 생각할 때 굉장히 큰 폭으로 좋아짐을 확인할 수 있습니다.
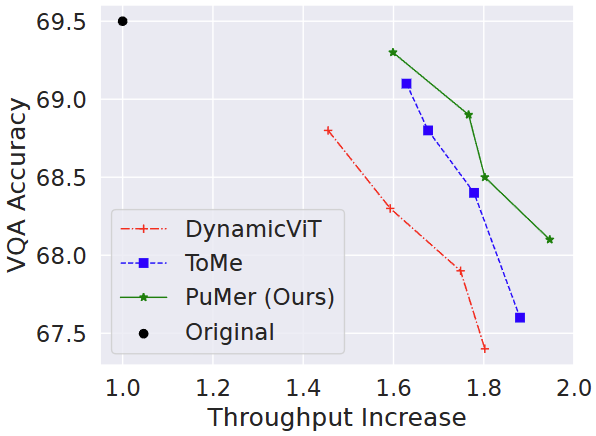
반면 동일한 하나의 모델에서 위에서 언급한 이전 연구인 DynamicViT, ToMe, PuMer 방법과의 비교에서 Throughput Increase 1.8x에서 비교하면 PuMer는 가장 높은 성능을 보입니다 (논문에선 이렇게만 표현하지만, 1.6x 이상의 모든 지점에서 PuMer 방식이 높은 성능을 보입니다. 반면 Accuracy가 1% 정도 하락한 시점에서, PuMer는 가장 높은 Throughput Increase를 보입니다.
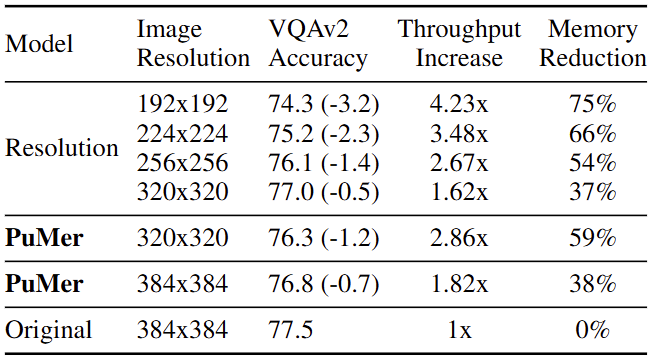
Tab. 2에서는 Resolution에 따른 성능 및 효율성 비교를 보입니다. Resolution을 줄이는 방식은 가장 직관적으로 연산 효율성을 높일 수 있으면서도, 동시에 가장 직관적으로 성능이 낮아지는 방식입니다. Original의 384×384도 사실은 일반적인 이미지를 고려할 때, 굉장히 낮은 해상도입니다. 이미지의 크기를 1/2인 192×192로 낮추면, Throughput Increase는 4.23x, Memory Reduction은 75% 향상된 모습을 보이지만, 성능이 3.2% 하락합니다. Throughput Increase만 고려하면 확실히, 이미지의 크기가 작다는 의미가 곧 Image token 자체가 작다는 의미 (384×384에서 Patch size 16일 때의 Image token 개수는 576인 반면, 192×192에서는 144입니다)이므로, 가장 효과적이기는 합니다. 유사한 비교를 위해 PuMer를 320×320, Resolution을 320×320으로 줄였을 때, PuMer는 단순히 Resolution을 줄이는 것에 비해 약 1.5배 정도의 연산 효율성을 보입니다 (신기하게도 성능은 더 하락하기는 합니다).
Efficient AI와 관련해서 처음 보는 분야이다보니 논문을 꽤 자세하게 읽어보았습니다. 다행히도 첫 논문은 직관적인 요소가 많아 이해하기에 좋았지만, 앞으로는 어떨지 또 궁금하네요. 그럼 리뷰 마치겠습니다.
안녕하세요 상인님 좋은 리뷰 감사합니다.
리뷰에서 설명해주신대로 Modality-Aware Merging은 의미적으로 유사한 토큰을 병합하여 연산 효율성을 높이는 방식으로 동작하는 것으로 이해했습니다. 하지만 여기서 생긴 의문은, VQA에서 “이 이미지에 있는 사람은 몇 명인가요?”와 같은 개수(counting) 관련 질문을 처리할 때, 유사한 패치들이 하나의 토큰으로 병합되면서 개체 수 정보가 손실될 가능성이 있을 것 같다는 의문이 생겼습니다.
그런데 Fig. 1을 보면, counting 문제에도 강인함을 보이는 것 같은데, 유사한 패치들을 병합했음에도 개체 수 정보를 보존할 수 있는 이유가 무엇인지 궁금합니다.
감사합니다.
음, 좋은 질문 감사합니다.
저도 고민해보았습니다. Counting 시에는 문제가 발생할 수도 있겠다고 처음 생각하였는데,
Fig.1은 What sport they are playing? 시에 적합한 Tokening/Mergining 방식이라고 생각해야할 것 같습니다. 그러니 즉, Counting이 필요한 질문 (How many people are playing?)에서는 서로 다른 사람에 대해서는 다른 개체로, 즉 유사한 패치로 인식되지 않을 것이라는 것이 저의 생각입니다. 왜냐하면 Mergining과정에서는 단순히 Mergining하는게 아닌 Image와 Text 정보가 교류되기 때문에, 영향을 받지 않을까 싶습니다.
안녕하세요 상인님 리뷰 감사합니다.
세미나 때도 흥미롭게 들었던 주제였던 것 같습니다. Pruning이나 Merging 둘 다 결국 cross attention 과정에서 계산되는 score를 활용하는 것 같은데, 그렇다면 혹시 어느정도 복잡한 쿼리까지 커버할 수 있을까요? 뭔가 reasoning이 필요한 수준까지 갔을때도 문제가 없을까요? 단순 쿼리 text 자체만 기반으로 하는건지 궁금합니다!!
안녕하세요. 리뷰 읽어주셔서 감사합니다.
입력 텍스트가 충분히 길어졌을 때 (Reasoning이 필요한) 쿼리가 Pruning/Mergining 되었을 때 문제에 대해 질문 주신 것으로 이해하였습니다.
우선, 이 논문에서 중요한건 그래서 성능이 올랐는 지가 아닙니다. 내부적으로 텍스트 토큰도 물론 Pruning되고 Mergining되면서 이전보다 가지는 지식이 더 적어졌을 순 있다고 생각합니다. 그렇지만 성능 하락 대비 효율성 향상에 주목을 두어야하고, 그렇다고해서 성능이 말도 안되게 낮아졌느냐?하면 그것은 아니기에, 실험적인 증명 결과로 미루어보아 위 Reasoning이 필요한 수준의 긴 텍스트에서도 그 때의 필요한 토큰들은 여전히 남아있기에, 이런 성능을 유지할 수 있지 않았을까 생각합니다.
안녕하세요, 이상인 연구원님. 좋은 리뷰 감사합니다.
저도 대규모 모델의 경량화에 관심이 있습니다. 해당 연구는 불필요한 token을 pruning하고 merging하며 의미적으로 중요한 token만을 남겨 경량화 하는 논문으로 이해했습니다.
질문이 있는데요, 이렇게 경량화를 하지 않은 VLM 모델은 실제 서비스에 응용하기에 얼마나 큰지 감이 잘 오지 않아서 혹시 경량화 된 모델과 그렇지 않은 모델이 어느 정도의 자원(연구실 서버와 같은 워크스테이션, 일반 pc, edge device)에서 실시간 사용이 가능한지 혹시 알고 계시다면 알려주시면 감사하겠습니다..
안녕하세요. 리뷰 읽어주셔서 감사합니다.
음, 사실 VLM 모델이 실제 서비스에서 응용하기에는 아직 얼만큼 커서 힘든지 / 또는 자원이 얼만큼 필요한지 그 때의 실시간성은 어떤지에 대해서는 제가 알기엔 어렵습니다. 그 수치는 제품마다 / 기업마다 너무 천차만별일테고, 사실 그것과 무관하게 해당 연구가 시사하는 바는 더 적게 쓸수록 회사와 제품 입장에서는 더 좋을 수 밖에 없다는 점이라고 생각합니다. 만약 현재 서비스를 위해 VLM 모델을 그대로 쓸 수 있다 하더라도, 더 적은 메모리가 들고 더 적은 연료를 소비할 수 있다면 그만큼 제품 가격을 낮출 수 있기 때문이죠