안녕하세요, 58번째 x-review 입니다. 이번 논문은 RA-L 2025년도에 게재된 Monocular Thermal Depth Estimation에 대한 논문 입니다.
그럼 바로 리뷰 시작하겠습니다 !

1. Introduction
단안 RGB 이미지에서의 Monocular Depth Estimation(MDE)는 활발하게 연구가 진행되면서 정확하고 높은 zero shot 일반화 성능을 가지게 되었습니다. 이러한 추세는 아무래도 학습에 사용할 수 있는 라벨링된 depth를 가진 대규모의 RGB 데이터셋이 있었기 때문이죠. 예를 들어, UniDepth, Metric3D, 그리고 ZeroDepth와 같이 강한 일반화 성능을 가진 모델을은 각각 3M, 8M, 그리고 17M의 이미지와 라벨링 depth를 가지고 학습하였습니다. 그리고 Depth FM 중 대표적인 DepthAnything은 무려 62M의 이미지를 가지고 다양한 환경에서 정확한 depth를 예측할 수 있다고 알려져 있습니다. 그러나 많이 알고 계시듯이, RGB 이미지에서의 MDE는 저조도나 안개, 그리고 연기가 자욱한 상황에서 원래 가지고 있던 일반화 능력이 저하된다는 한계가 존재합니다. 이를 해결할 수 있는 방법으로 열화상 영상이 많이 언급되고 있지만 열화상 영상은 아직 RGB만큼 활발한 연구가 이루어지고 있진 못하는 상황 입니다. 그 이유는 열화상 이미지의 high signal-to-noise 특성과 RGB 이미지 대비 텍스처 및 색상 정보의 부족으로 인해 depth를 추정하는데 발생하는 난이도가 높아지기 때문입니다. 이 뿐만 아니라, RGB 이미지와 다르게 라벨링된 열화상 데이터셋이 부족하다는 것 또한 열화상 영상에서의 MDE를 수행하는데 어려움을 주고 있습니다.
그래서 본 논문에서는 대규모 RGB 이미지로 사전학습된 FM을 이용해서 열화상 MDE를 수행하고자 하였습니다. 이를 위해 confidence 기반으로 RGB MDE 모델을 열화상으로 distillation 할 수 있는 새로운 프레임워크를 제안하고 있습니다. 기존의 RGB와 Thermal을 같이 사용하는 연구들과 다르게, 해당 프레임워크는 완전히 align 맞지 않은 RGB-Thermal pair를 활용할 수 있도록 설계하였습니다. 이는 두 모달리티 간의 feature와 depth consistency에서 구하는 confidence를 distillation 과정에서 adaptive하게 가이드로 사용함으로써 가능할 수 있었다고 합니다.
이러한 본 논문의 main contribution을 정리하면 다음과 같습니다.
- RGB MDE 모델을 distillation하여 열화상 MDE 모델을 동작하는 새로운 semi-supervised distillation 프레임워크인 MonoTher-Depth를 제안
- feautre 공간과 depth 추정치의 spatial consistency를 기반으로 한 confidence-aware distillation을 제안하여 잘못된 가이드를 방지하고 정합을 맞춘 RGB-T pair의 필요성을 제거
- 제안한 confidence-aware distillation 방식은 zero shot 세팅에서 distillation이 없는 모델 대비 열화상 MDE의 abolute relative error를 22.88% 개선
2. Method
A. Problem Setup
정합을 맞춘 RGB-T 학습 데이터셋 부족 문제를 해결하기 위해 사전학습된 RGB MDE 모델을 열화상 MDE 모델로 distillation 하게 됩니다. 이때 FoV가 겹치는 pair 이미지와 calibration된 extrinsic 정보를 필요로 하긴 하지만, 완전히 정합을 맞추기 위한 과정은 필요로 하지 않는다고 합니다. 또한 Inference 시에는 RGB 이미지 없이 단안 열화상 이미지만으로 수행하게 되고요.
RGB MDE는 일반적으로 성능이 높지만, 이미지가 어떤 scene을 담고 있는지와 환경 조건에 따라 성능이 달라질 수 있습니다. 그런 경우에서의 RGB 모델 성능이 열화상 모델로 전이되는 것을 막기 위해 사용하는 것이 RGB 예측의 confidence이며 이 confidence는 학습 중에 열화상 모델을 adpative하게 조정하는데 사용할 수 있습니다. 여기서 말하는 confidence는 GT depth를 사용할 수 있는 때 학습되는 네트워크에 의해서 만들어지는 것이고, 만약 GT를 사용할 수 없어도 freeze된 RGB 모델과 confidence 네트워크를 사용해서 열화상 MDE 모델의 distillation loss를 조절할 수 있게 됩니다.
B. Metric MDE Network
본 논문에서는 두 모달리티의 MDE 모델로 DepthAnything 메트릭 버전을 사용하였다고 합니다. DepthAnything은 많은 분들이 아시는 것처럼, feature를 추출하기 위해 DinoV2를 사용하고 relative depth를 예측하기 위해 DPT 디코더, 그리고 마지막으로 metric depth를 예측하기 위해 metric bin 모듈을 사용하고 있습니다.
DepthAnything을 기반으로 한 RGB teacher 모델과 동일하게 열화상 MDE 모델도 동일한 구조를 사용하고 있지만, 다른 점은 raw 16비트 열화상 이미지를 정규화하는 추가적인 전처리를 필요로 합니다. 또한 여러 열화상 활용 연구에서 CLAHE를 사용하곤 하는데요, 본 논문에서는 MDE의 목적과 CLAHE 사이의 적합한 사용 필요성을 찾지 못하여 CLAHE는 사용하지 않았다고 합니다.
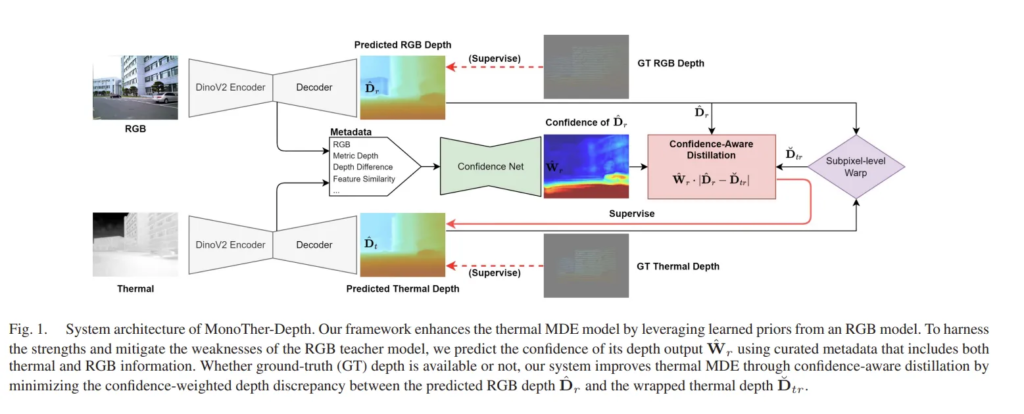
C. Sub-Pixel Warp of Thermal-RGB Depth
RGB MDE 모델의 지식을 열화상 MDE 모델로 전달하기 위해서는 공간적인 매핑을 필요로 하는데요, 이를 위해 Fig.1에서 보이는 것과 같이, SubPixel-level Warp 모듈에서는 예측된 depth map과 카메라 내부/외부 파라미터를 사용해서 두 모달리티 데이터 픽셀 간의 대응 관계를 계산하고 있습니다.
먼저 RGB MDE 모델이 예측한 depth map \hat{D}_r을 열화상 이미지로 변환하는 과정을 식(1)과 같이 정의하였습니다.
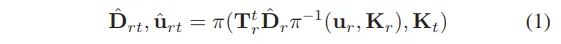
- \pi(x,K) : 카메라 projection → 점 x를 내부 파라미터 K를 통해 이미지 평면으로 변환
- \pi^{-1}(u,K) : reprojection → 이미지 픽셀 u를 3D 평면으로 변환
- T^t_r : RGB 카메라 → 열화상 카메라로의 6 자유도 변환 행렬
결과적으로, \hat{D}_{rt}는 열화상 좌표계로 변환된 RGB depth를 의미합니다. 식(1)을 통해서 RGB 이미지에서의 픽셀 u_r에 대해 대응하는 열화상 이미지 픽셀 \hat{u}_{rt}를 찾을 수 있습니다.
그 다음엔 반대로 열화상 이미지에서의 예측 depth \hat{D}_t를 RGB 이미지 평면으로의 변환을 식(2)를 통해 수행할 수 있습니다.
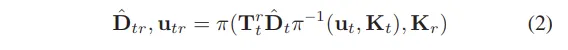
RGB 모델을 사용해서 열화상 모델을 효과적으로 학습하려면 이렇게 변환된 depth map을 서브 픽셀 레벨에서 더욱 디테일하게 샘플링 할 수 있어야 합니다. RGB와 열화상 카메라는 서로 다른 위치에서 같은 장면을 찍은 것이기 때문에 동일한 물체라도 두 이미지에서 픽셀 위치가 다를 수 있겠죠. 그래서 각 픽셀의 정확한 대응 관계를 파악하기 위해 서브 픽셀 레벨에서 두 depth를 일치시키는 warping 방법을 선택한 것 입니다.
그래서 \hat{D}_{tr}을 서브픽셀 위치 \hat{u}_{tr}에서 bilinear interpolation을 통해서 식(3)과 같이 샘플링하게 됩니다.
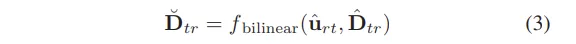
- \breve{D}_{tr} : RGB 이미지 좌표게에서 변환된 열화상 depth 값
이렇게 하면 RGB 이미지에 대응하는 열화상 depth 값을 얻을 수 있는데, 결국 interpolation을 통해 서브픽셀에서의 depth 값을 얻음으로써 연속적인 depth 정보를 계산할 수 있습니다.
D. Confidence-Aware Model Distillation
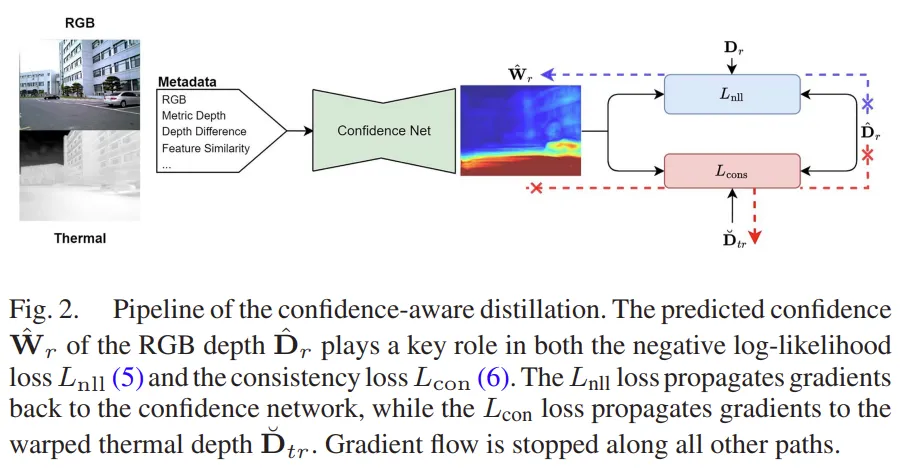
본 논문에서 RGB MDE 모델을 사용한다곤 했지만, RGB MDE 모델이 모든 픽셀에서 정확하게 depth를 예측할 수 있는 것은 아니죠. 가령 그림자가 있거나, 반사하는 표면과 같은 영역에서는 depth의 오차가 크게 발생할 수 있습니다. 이렇게 RGB에서 잘못된 depth 값을 예측한 정보가 그대로 열화상 모델로 전달이 되면 학습에 좋지 않은 영향을 미치게 됩니다. 이를 해결하기 위해, RGB MDE 모델의 depth 예측값 \hat{D}_r을 얼마나 신뢰할 수 있는지를 학습하여서 열화상 모델이 신뢰할 수 있는 픽셀 정보만을 학습할 수 있도록 유도하는 방법을 사용하였습니다.
이를 위해 \hat{D}_r 값의 confidence \hat{W}_r을 예측하는 U-Net 모델을 사용하는데요, 입력으로는 RGB 메타 데이터들이 들어가게 됩니다. Fig.2에서 볼 수 있듯이, 입력으로 들어가는 메타 데이터는 여러 가지가 있는데,
(1) RGB와 열화상 feature map의 코사인 거리 : RGB/열화상 feature가 얼마나 유사한지를 측정
(2) (1)번과 반대로 열화상과 RGB feature map의 코사인 거리 : (1)번과 반대 방향의 유사도를 측정
(3) RGB-열화상 depth map의 차이 |\hat{D}_r - \breve{D}_tr|
(4) 와핑된 열화상 depth \hat{D}_tr
(5) RGB depth \hat{D}_r
(6) RGB 이미지 I_r
이렇게 6개의 메타 데이터를 활용해서 각 픽셀의 RGB depth 값이 얼마나 신뢰할 수 있는지를 학습하게 됩니다. 특히나 이런 메타 데이터의 구성 요소들은 RGB 이미지에 맞추워 서브 픽셀 레벨로 align이 맞춰져 있기 때문에 정확한 confidence map 예측을 하는데 유용하다고 합니다.
(3)-(5)번의 메타 데이터를 얻는 것은 비교적 간단하지만, (1)번을 조금 설명이 필요한데요, 우성 코사인 거리는 두 feature map 간의 방향적인 유사도를 측정하는 방식 입니다. 이를 측정하기 위해서 먼저 RGB와 열화상 feature 벡터 F_r, F_t를 추출합니다. 그 다음에 식(4)와 같이 두 feature map 사이의 코사인 거리를 계산하는 것이죠.
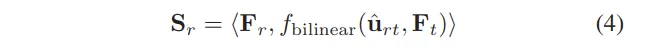
- <A,B> : 두 벡터 사이의 cosine similarity
- f_{bilinear}(\hat{u}_{rt}, F_t) : 열화상 featuer를 RGB 좌표게에 맞게 bilinear interpolation 적용
이렇게 계산하면, RGB feature와 열화상 feature 간의 유사도를 계산할 수 있습니다. 반대로 (2)번은 열화상 feature와 RGB feature 간의 유사도는 계산하여 S_t를 알 수 있습니다.
이러한 6개의 메타 데이터를 U-Net 구조의 입력으로 넣는다고 했는데, 여기서 인코더는 4개의 다운 샘플링 레이어를 사용하여 high level의 feature를 추출하고자 하였습니다. 그리고 디코더는 4개의 업샘플링 레이어를 사용해서 feature map을 다시 원본 이미지 크기로 복원하고자 하죠. 최종 출력으로는 각 픽셀의 confidence 값 \hat{W}_r을 0-1 사이의 값으로 출력하게 됩니다.
아까도 말씀드렸다시피, 이 confidence 예측을 위한 학습은 GT RGB depth D_r을 사용할 수 있는 경우에만 수행할 수 있습니다. 이를 위해, 식(5)로 정의된 라플라스 분포의 Negative log-likelihood(NLL) 함수를 사용하였다고 합니다.
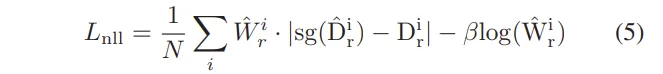
식(5)에서 첫번째 항은 confidence가 높은 픽셀일수록 실제 depth 값과의 차이가 작아지도록 학습을 하고, 반대로 두번째 항은 confidence 값이 너무 작아지는 것을 방지하기 위한 정규화 역할을 하고 있습니다. 너무 작은 confidence 값을 가지는 픽셀이 많아지게 되면, 학습이 제대로 진행되지 않을 수 있기 때문에 두번째 항을 추가한 것이죠. 결국 confidence가 높은 픽셀은 실제 GT depth 값과의 차이가 작아야 하고, confidence가 낮은 픽셀은 학습에서 덜 중요하도록 조정함으로써 잘못된 RGB depth 값이 열화상 모델에 전달되지 않도록 할 수 있게 됩니다.
다만 여기서 confidence 네트워크는 RGB GT가 있을 때만 학습할 수 있는데, 이 말은 즉 라이다 데이터가 있는 경우에만 학습을 할 수 있다는 뜻 입니다. 그러나 실제로는 모든 픽셀에서 라이다 데이터를 얻을 수 없어서 일부 픽셀에서만 학습하게 되죠. 특히 outdoor 환경에서는 라이다가 매우 sparse하게 존재해서 학습할 수 있는 픽셀의 개수가 제한적이기 때문에 본 논문에서는 학습 가능한 픽셀에 대해서만 해당 loss 함수를 적용하고, 이후에 학습된 confidence 네트워크를 이용해서 모든 픽셀의 confidence를 예측하도록 설계하였다고 합니다.
이제는 예측한 confidence를 활용해서 RGB 모델에서 열화상 모델로 distillation을 수행해야 합니다. 이 때는 confidence를 가중치로 사용하는 식(6)과 같은 L_1 loss를 사용해서 더 신뢰할 수 있는 픽셀에 대해서만 학습에 반영하도록 하였습니다.
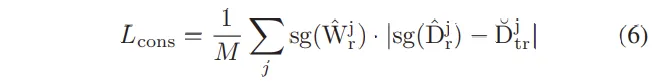
- j : RGB 이미지 좌표 내 픽셀 인덱스
- M : 학습 가능한 픽셀 개수
L_{cons}는 \hat{D}_r과 \breve{D}_{tr}간의 차이를 줄이도록 학습하는데, 다만 RGB 모델이 잘못된 depth를 예측한 경우에도 이를 무조건 학습 시키는 것을 막아야겠죠. 따라서 앞서 예측한 RGB depth의 confidence \hat{W}_r를 여기서 가중치로 사용하여 신뢰할 수 있을만한 픽셀만 학습하도록 유도하게 됩니다. 추가로 여기서 sg(\hat{W}^j_r)와 sg(\hat{D}^j_r)이 필요한 이유는 각각 RGB 모델의 depth 예측값이 역전파에 영향을 받지 않고, RGB confidence 값이 학습될 때 열화상 모델이 영향을 주지 않도록 하기 위함입니다. RGB 모델과 열화상 모델이 각각 독립적으로 학습할 수 있도록 하기 위해 설계된 것으로, \hat{D}^j_r가 역전파 과정을 거치면 RGB 모델이 계속 업데이트 되면서 바뀌어버릴 수 있기 때문 입니다. 하지만 여기서는 이미 사전학습된 RGB 모델을 활용하는 것이기 때문에 RGB 모델은 freeze된 상태로 열화상 모델만 학습할 수 있도록 loss를 설계하게 된 것 입니다.
여기서 추가적으로 학습에 고려해야되는 것은 우선 occlusion 영역 입니다. occlusion 영역에 대해서는 대응되는 픽셀이 없을 수 있기 때문에 이러한 픽셀까지 그대로 학습하면 오히려 모델의 성능이 떨어질 수 있겠죠. 그래서 depth 차이가 가장 큰 상위 20%의 픽셀은 학습에서 제외함으로써 loss 값이 큰 픽셀을 제거하여 더 신뢰할 수 있는 나머지 데이터만을 학습에 사용하였다고 합니다.
그 다음엔 RGB와 열화상 이미지가 동일한 정보를 담고 있는 것이 아니기 때문에, RGB 모델이 잘 예측하는 영역과 열화상 모델이 학습하기 좋은 영역이 다를 수 있습니다. 즉, RGB와 열화상 간의 feautre가 너무 다른 픽셀이 존재할 수 있기 때문에 그러한 픽셀은 학습에서 제외할 필요성이 있다는 것 입니다. 그래서 두 feature map 간의 코사인 유사도 S_r을 사용해서 유사도가 상위 80%인 픽셀만 학습에 사용하였다고 합니다. 결국 RGB와 열화상 feaeture가 유사한 부분만 사용해서 열화상 모델을 학습하게 되는데, 이 부분이 두 이미지가 align이 맞지 않더라도 학습이 가능할 수 있도록 하는 중요한 설정이 됩니다.
E. Implementation Details
여기서는 전체 distillation 프레임워크에서 사용하는 loss 함수에 대해서 설명하고 있습니다.
우선 본 논문의 프레임워크는 다양한 MDE 모델에서 사용할 수 있도록 설계하였다고 합니다. RGB/열화상 MDE 모델을 학습할 때, 기본적으로는 DepthAnything 모델을 사용하지만 다른 MDE 모델로 바꾸더라도 confidence 네트워크를 그대로 사용할 수 있도록 한 것이죠. 모델을 학습할 때, RGB/열화상 MDE 모델에 모두 동일한 loss 함수인 SILOG loss를 사용한다고 합니다. 식(7)의 SILOG loss는 large scale의 데이터셋에서 depth estimation을 학습할 때 효과적으로 사용해오던 방식이라고 하네요.
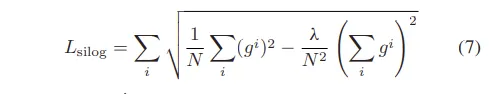
- g_i : depth 차이의 로그 값
- N : GT depth가 존재하는 픽셀 수
L_{silog}를 사용하면 로그 계산을 통해 상대적인 depth 차이를 균형 있게 학습할 수 있는데, 가령 1m→2m depth 차이와 10m→20m 차이는 동일한 2배라는 비율 차이가 나기 때문에 동일한 중요도로 학습할 수 있다는 것 입니다. 또한 이미지 전체의 depth 관계를 고려하여 정규화할 수 있기 때문에 depth의 절대적인 값 뿐만 아니라 상대적인 비율까지 고려하여 학습할 수 있다는 장점이 있어 본 논문에서는 L_{silog}를 선택하여 사용하였다고 합니다.
추가로 depth 예측의 smooth함을 보장하기 위해서 smoothness loss를 사용하였는데요, 이 smooth함을 위한 loss는 제가 읽은 depth estimation 논문에서 공통적으로 포함되는 것 같습니다.
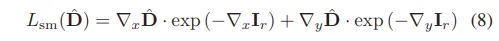
depth map이 너무 불연속적일 경우에 노이즈가 발생할 수 있는데, 만약 같은 물체라면 그 안에서 depth가 급격하게 변하지 않는, 즉 smooth함을 유지할 필요가 있습니다. 이를 위해 RGB 이미지의 엣지와 일치하는 방식으로 depth 값을 부드럽게 조정하는 식(8)과 같은 L_{sm}을 사용하였습니다. 엣지가 존재하는 부분에서는 depth 변화가 있더라도 허용하고, 엣지가 없는 부분에서는 depth 변화를 최소화하여 부드럽게 만들 수 있도록 설계되었습니다. 그런데 L_{sm}은 RGB depth에만 적용을 하는데요, 그 이유는 열화상 이미지는 애초에 엣지와 텍스처 정보가 부족하여 RGB 이미지보다 더 노이즈가 많을 가능성이 높습니다. 따라서 열화상 depth에 동일하게 smooth loss를 적용하면 필요한 depth 변화까지 허용하지 못할 수 있어서 비교적 텍스처와 엣지가 명확한 RGB 이미지에만 smooth loss를 적용함으로써 효과적으로 학습할 수 있도록 하였다고 합니다.
그래서 최종적인 loss 함수는 식(9)와 같이 정의할 수 있습니다.
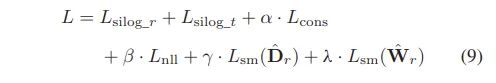
그런데 위에까지의 전제 조건은 GT depth가 있는 경우에 해당했는데요, 항상 GT depth 데이터가 있다면 좋겠지만 그렇지 않은 경우도 많겠죠. 이럴 때는 RGB 모델의 knowledge를 사용해서 열화상 모델을 학습해야 한다고 합니다. 구체적으로, RGB 모델은 freeeze하고 오로지 consistency loss로만 학습을 하는 것이죠. 사전학습된 RGB MDE 모델과 confidence 네트워크의 가중치는 freeze하고, RGB 모델이 예측한 depth 값을 가이드로 해서 L_{cons}만으로 열화상 모델을 학습합니다. 즉, GT가 없더라도 RGB 모델을 teacher 모델 삼아 열화상 모델을 학습할 수 있기 때문에 GT가 있을 때와 없을 때 모두 사용할 수 있는 프레임워크임을 강조하고 있습니다.
3. Experiments
실험에는 MS2 자율주행 데이터셋과 ViViD++ 데이터셋 중에 outdoor scene을 선택하여 진행하였다고 합니다.
A. Evaluation of Metric Monocular Depth Estimation
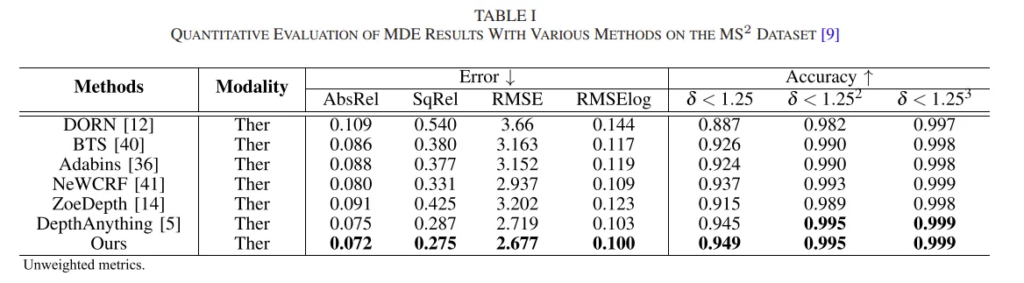
우선 Tab.1은 MS2 데이터셋에서의 monocular depth estimation 결과를 보여주고 있습니다. 비교하는 모든 타 방법론은 MS2 열화상 학습 데이터로 학습하거나, fine-tuning한 모델 입니다. 결과적으로 본 논문의 방법론인 Mono Ther-Depth가 SOTA를 달성한 것을 확인할 수 있습니다. 이러한 결과는 학습 과정에서 RGB MDE 모델에서 효과적으로 knowledge를 distillation 할 수 있었기 때문에 가능하였다고 이야기하고 있습니다.

MS2 데이터셋은 낮/밤 데이터 뿐만 아니라 우천/안개와 같은 이상 환경에 대해서도 담고 있는데, Fig.3은 이상 환경에서 열화상 이미지의 장점을 강조하고 있습니다. 비가 오고나서 도로가 반사되거나 어두운 환경에서 빨간색 박스 표시된 영역과 같이 열화상으로 예측한 depth map이 각 나무에 대한 디테일한 구조를 잘 파악하고 물체의 형상을 더 정확하게 표현하고 있는 것을 확인할 수 있습니다.
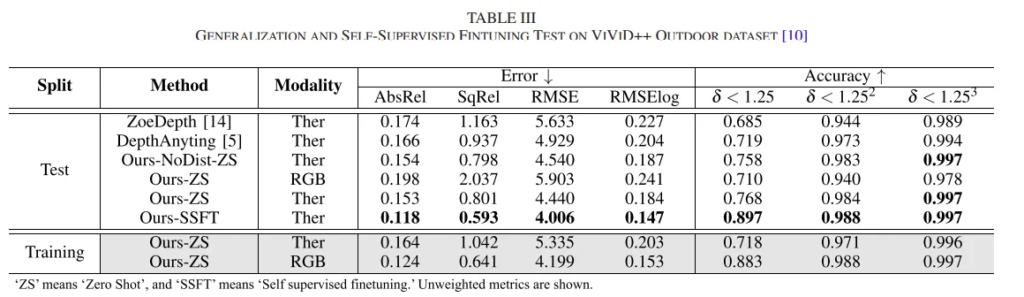
Tab.3은 zero shot 일반화를 평가하기 위해 ViViD++ 데이터셋에서 outdoor scene에 대해 평가한 결과 입니다. 모든 네트워크는 MS2 데이터셋에서 학습된 가중치로 평가하였으며 Ours-ZS에서 모달리티에 따라 RGB MDE 모델과 열화상 MDE 모델의 zero shot 성능을 보여주고 있습니다.
평가한 테스트 데이터가 야간에 취득된 것이기 때문에 RMSE가 열화상 4.440, RGB 5.903으로, 열화상이 더 좋은 성능을 달성한 것을 확인할 수 있습니다. 또한 RGB-열화상 distillation 없이 학습된 방법이 Ours-NoDistZS로 표시되어 있는데, distillation을 했을 때 더 나은 일반화 성능을 보여줌으로써 distillation 방식이 RGB 정보를 활용하여 열화상 DE에 도움을 주고 있다는 것을 보여주고 있습니다.
B. Ablation Study
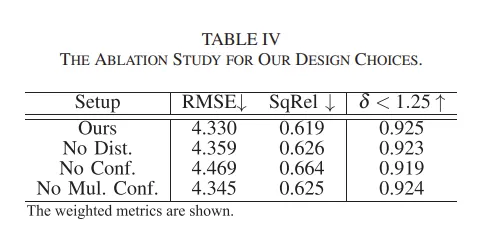
마지막은 MS2 데이터셋에서 제안한 방식에 대한 ablation study 입니다.
먼저 distillation 없이 각각의 GT depth을 사용해서 RGB/MDE 모델을 함께 학습하는 것이 No Dist로 표시되어 있으며, No Conf는 confidence를 가중치로 사용하여 통합하지 않고 RGB 모델에서 열화상 모델로 단순 distillation하는 것을 의미합니다. No Mul. Conf.는 confidence 네트워크에서 RGB 관련 메타데이터만 사용해서 RGB MDE confidence를 예측할 때 열화상과 관련된 모든 입력 요소를 제거한 버전을 나타냅니다.
실험 결과, 모든 제안한 구성을 포함한 Ours가 가장 좋은 성능을 보이고 있는데, 그 중에서 No Conf.는 열화상 MDE 성능에 안 좋은 영향을 미치며 심지어는 distillation을 하지 않은 것보다 더 낮은 성능을 보이고 있습니다. 이를 통해 distillation 자체도 중요하지만 그 과정에서 confidence를 계산하여 정확하지 않은 정보는 억제하면서 RGB가 잘 예측한 정보를 제대로 전달하는 것이 중요하다는 것을 다시 한 번 강조하고 있습니다.
안녕하세요! 좋은 리뷰 감사합니다.
confidence를 구할 때 메타 데이터로 들어가는 데이터가 RGB를 기준으로 한 메타 데이터라고 말씀해주셨는데요, 그럼 이미지는 RGB-Thermal이 모두 들어가고 메타 데이터는 RGB를 기준으로 들어가게 되면 결과로 나오는 W는 RGB 이미지에 대해서만 나오게 되는건가요 ?? 사실 그럼 열화상 이미지 자체가 입력으로 들어가게 되는 필요성을 잘 모르겠는데, 열화상 depth map이 아닌 열화상 이미지까지 사용해야 하는 이유가 있을까요 ?
감사합니다 ! !
안녕하세요, 리뷰 읽어주셔서 감사합니다.
사용되는 메타 데이터는 단순히 RGB 정보만 포함하는게 아니라 열화상 이미지와의 cross-modal 관계까지 반영해야 하는 구조 입니다.
confidence는 RGB depth 결과의 신뢰 정도를 추정하는 건 맞지만, 그 추정하는 과정에서 RGB만을 기준으로 하는건 아니고 열화상 정보를 같이 사용하고 있습니다.
thermal 이미지 자체를 입력으로 사용하는건 RGB-MDE와 thermal-MDE 간의 신뢰도 차이를 반영해야 하고, thermal MDE가 학습할 때 정확하게 distillation 가중치를 주기 위함이라고 이해해주시면 될 것 같습니다.
감사합니다.
안녕하세요!, 좋은 리뷰 잘 읽었습니다.
Confidence-aware distillation을 통해 RGB MDE 모델로부터 효과적인 지식 전이를 수행하고, thermal 단안 깊이 추정의 정확도를 향상시킨 점이 인상 깊었습니다.
한 가지 궁금한 점이 있어 댓글 드립니다.
제안하신 프레임워크에서는 RGB 기반 모델의 confidence map을 활용하여 thermal 모델의 학습을 조절하고 있는데, 저조도, 안개, 야간 환경과 같이 RGB 자체의 품질이 떨어지는 상황에서는 confidence 역시 낮게 예측될 가능성이 높다고 생각됩니다.
그렇다면 오히려 thermal 이미지가 갖는 강점을 살려야 할 환경에서, RGB 기반 confidence에 따라 학습 신호가 약화되어 thermal 모델이 충분히 학습되지 못하는 것이 한계인지 궁금합니다
안녕하세요, 리뷰 읽어주셔서 감사합니다.
말씀하신 것처럼 이상 환경에서 RGB의 성능이 낮아 depth 예측이 부정확할 수 있고 그 결과로 confidence가 낮게 예측될 수 있는데요, 다만 해당 논문에서 그걸 반영하기 위해 제안한 것이 confidence-aware distillation 방식 입니다.
RGB 기반의 예측이 만약 신뢰도가 낮다라고 판단이 된다면 해당하는 영역에 대한 가중치를 줄이고, 만약 정상 상황에서 RGB 결과의 신뢰도가 높다면 강하게 distillation 신호를 줌으로써 thermal 모델이 잘못된 RGB에서의 결과에 대한 신호에 영향을 덜 받을 수 있겠죠. 즉 말씀하신 것처럼 RGB 기반의 confidence에 따라 학습 신호가 약해진다고 해서 열화상 모델이 마냥 학습을 잘 못하는게 아닌, 선택적으로 adaptive하게 신뢰할만한 신호를 받아서 학습할 수 있게 됩니다.
감사합니다.