안녕하세요, 쉰 다섯번째 X-Review입니다. 이번 논문은 2024년도 ArXiv에 올라온 CLII: Visual-Text Inpainting via Cross-Modal Predictive Interaction논문입니다. 바로 시작하도록 하겠습니다. ??
1. Introduction
도시 거리에는 광고판이나, 벽, 간판, 표지판 등등 다양한 텍스트가 많이 존재합니다. 이는 홍모 목적이거나 혹은 정보를 제공하는 목적을 갖고 있죠. 이 거리를 촬영한 영상에 대한 텍스트를 정확하게 인식하는 낯선 언어를 사용하는 도시를 방문하는 여행객들에게 유용합니다. 하지만, 현실에서는 텍스트가 가려지거나 훼손되어 있을 가능성이 큽니다.
이런 훼손된 텍스트를 인식하는 해결책으로는 먼저 이 훼손된 영상 내의 텍스트를 검출한 후 누락되어 있는 문자를 보완하는 방법이 존재합니다. 하지만, 이 방식에는 두 가지의 한계점이 존재합니다.
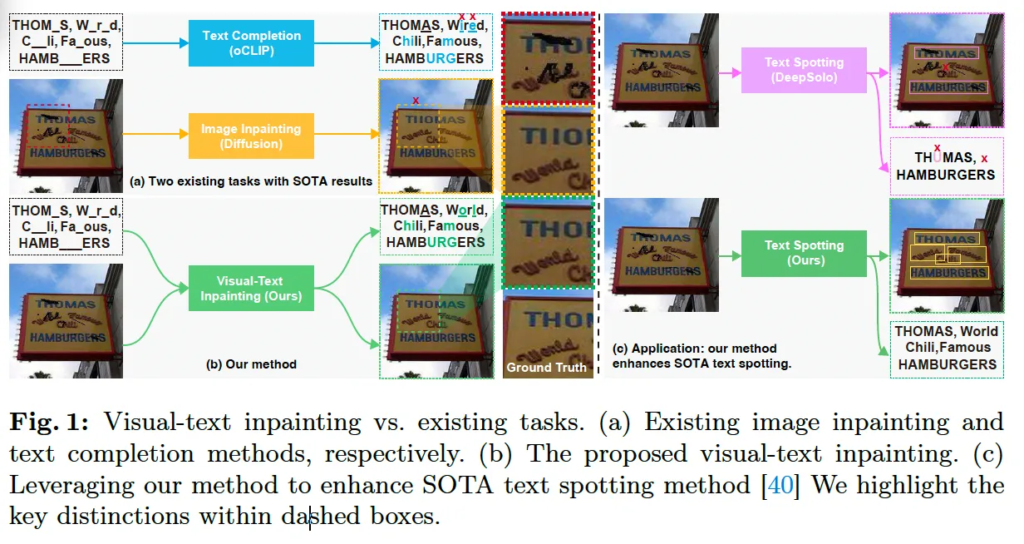
(1) 첫 번째로 훼손된 영상에서 텍스트 content를 추출하는 것이 어렵다는 점입니다. 위 Fig1의 우측에 있는 (c)는 상단을 보면 SOTA text spotter를 통해 훼손된 영상에 대한 spotting 결과를 보여줍니다. 보시면, 훼손된 텍스트 영역을 검출하지 못하는 부분도 있으며, 검출한 텍스트에 대해서도 단어를 제대로 인식하지 못하는 모습을 보이고 있습니다.
(2) 두 번째로, 누락된 문자를 보완하는 text completion 과정에서 error prediction이 발생할 수 있다는 점입니다. Fig1(a)를 보시면 현존하는 SOTA text completion 방법론인 oCLIP을 사용하여 훼손된 문자를 competion하도록 할 때 ‘World’라는 단어를 ‘Wired’라고 잘못 예측하는 결과를 보입니다.
또 다른 completion 방식으로는 image inpainting 방식을 사용해볼 수 있겠는데요. 근데, 이 scene text의 completion을 목표로 하는 image inpainting 기법은 아직 잘 연구되지 않을 뿐더러, 기존 image inpainting 방식을 바로 적용하기 어려운 scene text의 고유한 문제도 갖고 있습니다. 그 문제라고 함은, scene text 이미지에서는 배경과 text content를 동시에 복원해야 하는데, 이 복원 자체가 language priors와 연결되어 있기 때문이라는 점입니다. 즉, text는 단어를 바꿈으로써 무한한 조합을 생성할수도 있으며, 다양한 글꼴이나 스타일을 포함하기 때문에 어렵다는 점입니다. 예를 들어 fig1(a)의 노란색 박스 Diffusion based image inpainting 기법을 적용한 경우를 봐보시면 누락되어 있는 pixel을 채워서 자연스러운 영상을 생성해낼 수는 있지만, 실제로 text를 정확하게 복원하지는 못하고 있습니다. 실제 단어는 THOAS이지만, H가 아닌 I I로 복원해버린 것처럼 말이죠.
이를 봤을 때 scene text inpainting을 할 때 language model의 language priors를 활용해 단어 내에서 누락된 문자를 복원하면 될 것 같습니다. 즉, 다시말해 이 text completion과 image inpainting을 따로 하는 것이 아니라 같이 활용하는 것이 더 효과적일 수 있다는 것이죠. 이런 아이디어에 착안하여 이 두 방식 text completion과 image inpainting을 통합해 활용하는 방식을 제안합니다. 즉, image 정보와 language 정보를 결합했을 때 더 정확하게 text를 복원할 수 있다는 것이죠. 이렇게 제안된 모델의 결과는 Fig1-(b)에서 확인할 수 있는데, 단순 텍스트 내의 누락되어 있는 문자를 복원한느 것뿐만 아니라, 영상 내의 손상되어 있는 문자의 복원된 영상을 생성하는 것을 볼 수 있습니다. 또한, Fig1(c)를 보았을 때 이 모델을 sota spotting 모델에 합쳐 누락되거나 손상된 text에 대해 강인하게 동작하는 것을 확인할 수 있습니다. 아래 Method 파트에서 본 논문에서 제안된 CLII에 대해 자세히 살펴보도록 하겠습니다.
2. Visual-Text Inpainting
2.1. Problem Formulation
먼저 visual-text inpainting 문제에 대해 정의하고 그 다음에 제안된 CLII에 대해 디테일한 부분을 설명드리도록 하겠습니다.
본 논문에서 정의하고 있는 visual-text inpainting에서 가정하는 상황은 scene text image I와 text string S는 동일한 텍스트 정보를 갖고 있지만 이미지 I에는 일부 픽셀이 손실되어 있고, String S에도 일부 문자가 손실되어 있습니다. 이때 visual-text inpainting의 목표는 두 모달리티 모두에서 손실된 정보를 복원하는 것이겠죠.
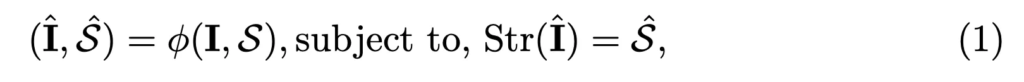
이를 수식으로 나타내면 위 식1과 같습니다. 복원된 이미지 내의 text와 복원된 문자열이 같아야 하기 때문에 제약조건으로 Str(\hat{I})=\{S}가 성립되어야 하겠죠.
따라서 본 테스크를 풀고자 한다면 두 모달리티의 상호 보완적인 정보를 효과적으로 활용해야 할 것입니다. 예를 들어 손상된 영상 내에서 특정 문자가 가려져 있더라도, 손상된 text 문자열에서 일부 그 문자가 손상되지 않고 남아있다면 이를 참고해 이미지를 inpainting할 수 있겠죠. 또 반대로 영상 내에서는 완전히 보이는 문자들이 있다면 손상된 text 문자열을 completion하는 데 활용할 수 있을 것입니다. 즉, visual-text inpainting은 단순 이미지 복원이 아니라, 텍스트와 이미지의 상호작용을 고려한 복원 문제로 볼 수 있습니다.
2.2. Cross-Modal Predictive Interaction
Framework overview
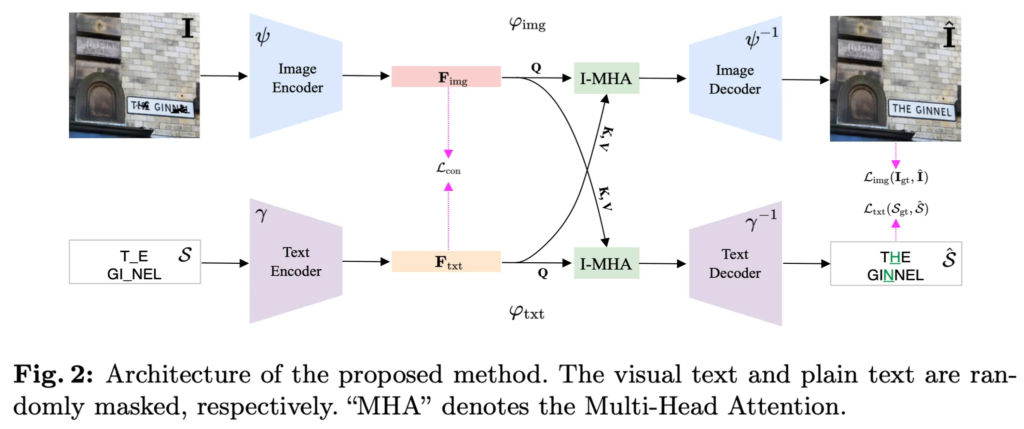
이제 본 CLII를 디테일하게 살펴보도록 하겠습니다. 먼저 위 Fig2에 도식화되어 있는 framework를 살펴보자면 CLII는 scene text image의 reconstruction과 text completion을 동시에 수행하는 모델로, 두 주요 branch인 ImgBranch와 TxtBranch로 구성이 되어 있습니다. 학습 할때 이 두 Branch간의 상호 정보를 교한함으로써 reconstruction 성능을 향상시키는 것이죠. 이를 가능하게 하기 위해 두 branch 간 latent embedding을 주고 받는 Interactive Multi-Head Attention (이하 I-MHA) layer를 도입하였습니다.
CLII의 전체적인 과정을 아래와 같이 표현될 수 있습니다.
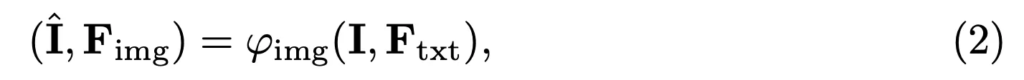
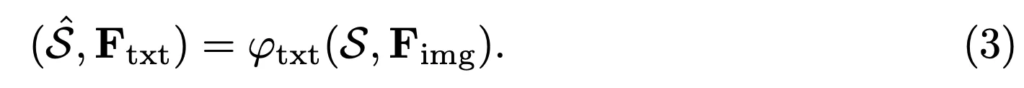
정리하자면, ImgBranch는 text의 feature를 활용해 이미지를 reconstruction하는 것이고, TxtBranch는 image의 latent feature를 활용해 text를 reconstruction하는 구조인 것이죠.
각각에 대해 살펴보도록 하겠습니다.
ImgBranch
ImgBranch는 입력으로 scene text image I를 받게 되고 이로부터 feature embedding F_{img}를 추출한 후 text branch로부터 나온 embedding F_{txt}를 활용해 최종 reconstruction된 영상 \hat{I}를 생성합니다.
수식으로 살펴보자면 아래와 같습니다.

식4처럼 encoder \psi에 입력 영상을 태워 이미지 feature F_{img}를 추출하게 되구요.
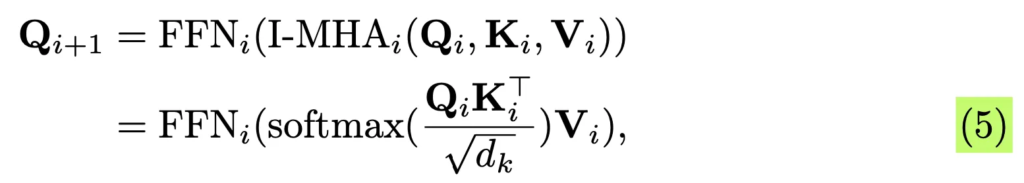
이후, 위 식5처럼 TxtBranch에서 얻은 F_{txt}와 상호작용하기 위해 I-MHA(Interactive Multi-head Attention) layer를 적용해 image feature를 보완하게 됩니다. 식에서 Q_i가 이미지 feature이구요, key, value가 text embedding입니다. 즉, 이미지 feature를 text 정보로 보완해 손실된 영역을 복원하는 과정입니다.

최종적으로 앞선 과정을 통해 얻은 image featureF_{img}< - _{txt}를 decoder를 태워 reconstruction된 영상을 생성합니다.
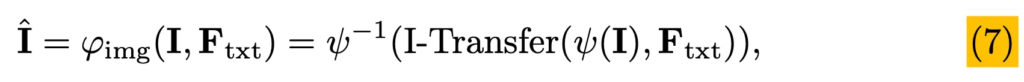
전체 과정을 한번에 정리하자면 위 식7이 되겠네요. 이 식에서 I-Transfer는 I-MHA를 통해 text 정보를 image feature에 반영하는 과정을 의미합니다.
TxtBranch
TxtBranch는 입력으로 들어오는 text string S에서 feature를 추출하고 마찬가지로 ImgBranch에서 추출된 image feature를 사용해 손실된(누락된) 문자를 복원하게 됩니다. 과정을 자세히 살펴보자면,
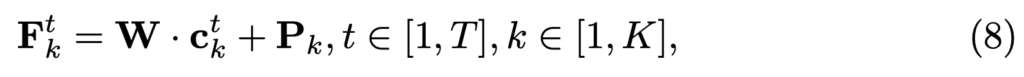
먼저 위 식8에 나와있는 것처럼 character-level text encoder를 사용해 각 문자 c^t_k를 vector로 변환하게 됩니다. W가 character embedding matrix리구요 P_k는 positional encoding입니다.
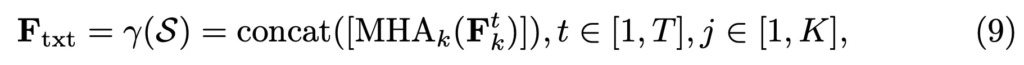
이후에는 Multi-head attention(MHA) 를 태워 각 문자 embedding을 통합해 전체 text embedding F_{txt}를 얻게 됩니다.
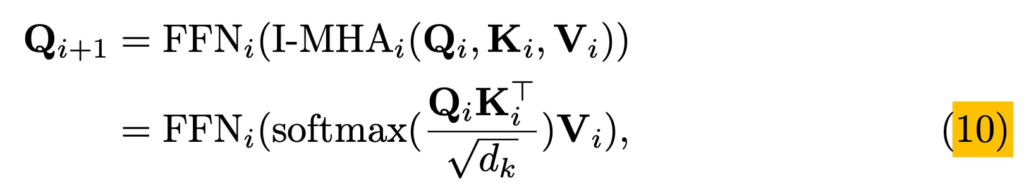
이후에 ImgBranch때와 마찬가지로 ImgBranch에서 생성된 image embedding F_{img}와 상호작용하기 위해 I-MHA layer를 태우게 됩니다. 이때 여기서 Query는 text embedding이 되겠고, key, value가 image embedding이 되겠죠.

이후에 decoder를 태워 최종적으로 reconstruction된 text \hat{S}가 나오게 됩니다.
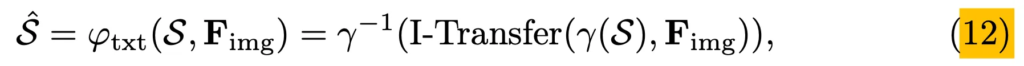
이 TxtBranch를 한줄로 나타내자면 식12와 같이 표현됩니다. 여기서 I-Transfer는 I-MHA를 통해 영상 정보를 text feature에 반영하는 과정입니다.
2.3. Network Training
Loss functions.
다음은 loss function에 대해 설명드리도록 하겠습니다.
먼저 text completion을 위한 loss 함수로는 Cross-Entropy Loss를 사용합니다.
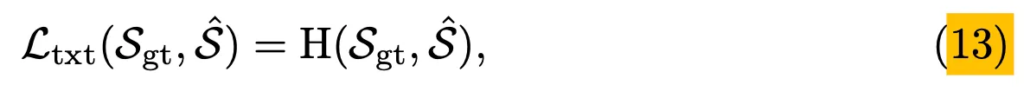
식으로 보자면 L_{txt}는 prediction text \hat{S}와 gt S_{gt} 간의 cross-entropy loss를 계산하는 식입니다.
또, image inpainting loss로는 L1 loss를 사용하였습니다.
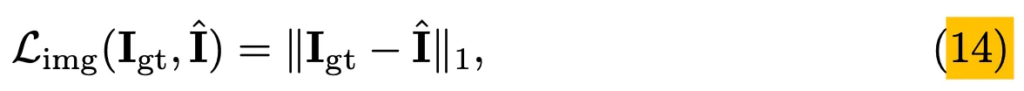
마지막으로 Image와 text가 서로 matching되도록 하기 위한 contrastive loss를 추가하였는데. Image와 text간의 유사도를 학습하는 역할로 넣은 만큼 동일한 내용을 담고 있는 영상과 text pair가 높은 similarity를 갖도록 학습됩니다. 수식으로 살펴보자면 먼저, 특성 batch 내에서 B개의 text와 image pair가 있다고 할 때 동일한 내용을 가진 (S_i, I_j) pair가 positive pair가 되겠고 그 외 나머지는 negative pari가 됩니다.
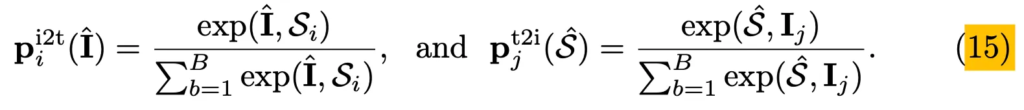
이떄 각 inpainting된 영상 \hat{I}와 text S_i간의 유사도, 그리고 completion된 text \hat{S}와 각 영상 I_j간의 similarity는 위 식15와 같이 계산될 수 있겠죠.
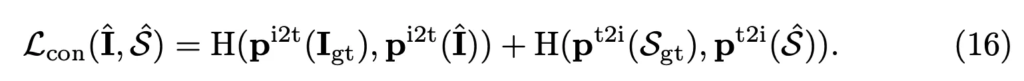
이를 기반으로 contrastive loss는 식 16과 같이 정의됩니다. 즉, gt와 reconstruction된 영상, 텍스트 간의 유사도를 최대한 맞추는 방식으로 학습하게 되고 최종적으로 모델의 전체 loss는 이 세 loss를 가중합하여 계산됩니다.
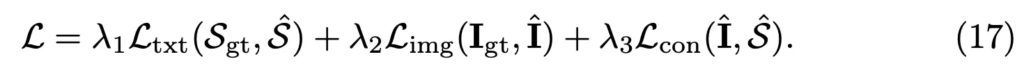
3. Leveraging CLII for Robust Scene-Text Spotting
이 CLII는 단순 text completion 및 image inpainting을 수행하고자 설계된 것이 아니라 결국 현실 세계에서 spotting을 하기 위해 설계된 것이었죠. 이를 검증하기 위해 본 논문에서는 CLII를 기존 spotting 모델인 DeepSolo에 적용하여 성능이 향상되는지 확인하는 실험을 수행하였습니다.
이를 위해 먼저 손상되어 있는 image I가 주어졌을 때 DeepSolo를 사용해 text recognition 결과를 뽑아냅니다.
수식으로 나타내면 아래 식18과 같습니다.
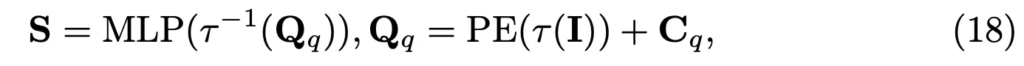
식에서 보이는 \tau(I)[/latex]는 DeepSolo의 transformer 기반의 encoder를 통해 추출한 image embedding을 나타내며, 이 image feature를 기반으로 text location과 content(S)를 prediction하게 됩니다.
따라서, 그 다음에 제안된 CLII 모델을 사용해 다시 손상된 영상 I와 누락된(손실된) 문자열 S를 입력으로 넣어 inpainting된 영상 \hat{I}와 completion된 text \hat{S}를 생성하게 됩니다. 이렇게 복원한 영상을 가지고 다시 DeepSolo에 넣어 최종 text recognition 결과를 뽑아내도록 하였습니다.
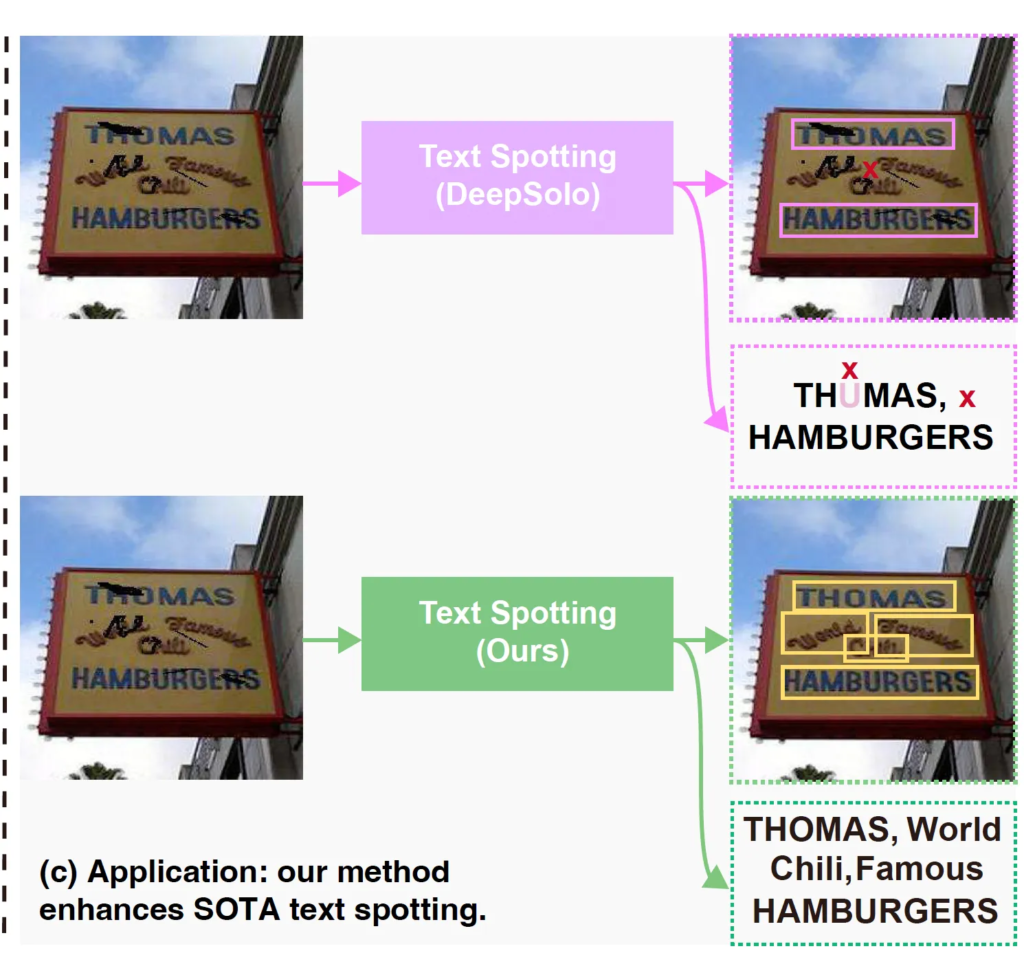
Fig1(c)에 나와있는 그림이 이 내용을 담고 있습니다. 제안된 CLII를 함께 사용한다면 손상되어 있는 text가 포함된 이미지에서도 DeepSolo의 recognition 성능을 크게 향상할 수 있음을 보여주고 있습니다.
4. Experiments
이제 실험 부분을 설명드리도록 하겠습니다.
모델 성능을 평가하기 위한 metric으로는 PSNR, SSIM, Precision을 사용하였습니다. PSNR과 SSIM은 image inpainting 퀄리티를 측정하기 위한 평가지표로 PSNR이 높을수록 좋은 것이며 SSIM은 inpainting된 영상이 gt 영상과 얼마나 유사한지 정량적으로 평가하는 지표입니다. Precision은 text completion의 정확도를 측정하기 위해 사용되었습니다.
4.1. Comparison Results
Quantitative comparison
먼저 CLII의 정량적으로 평가하기 위해 Total-Text, ICDAR2015, TextSeg 세 데이터셋에서 실험을 수행하였습니다. 실험에서는 image 손실 비율 즉 마스킹 된 비율은 20%로 고정하였고 text 손실 비율도 마찬가지로 20%로 설정하였습니다.
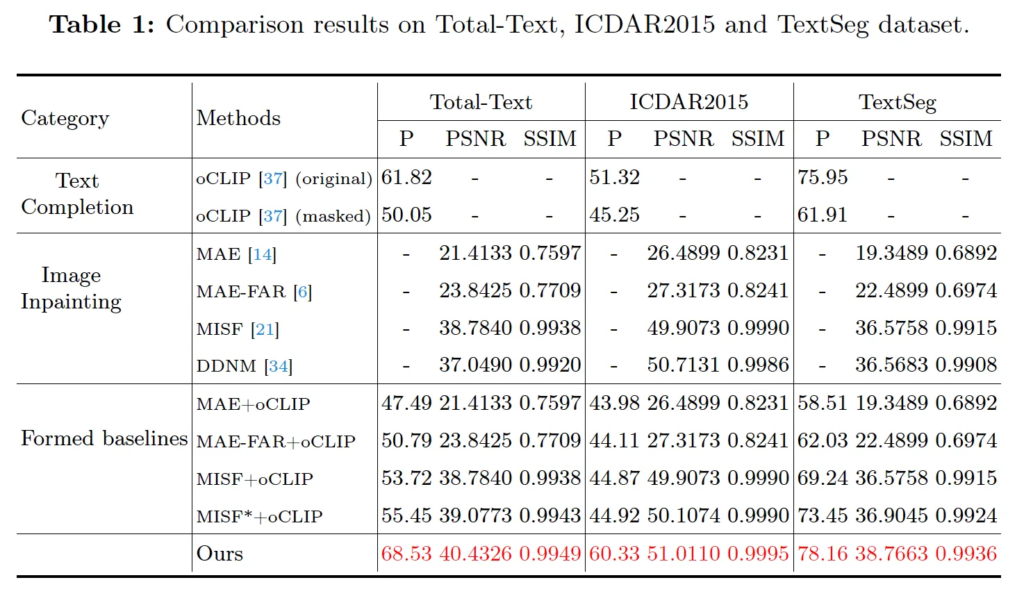
그 결과가 위 표1에 나와 있습니다. 보시면 제안된 CLII가 모든 데이터셋에서 SOTA를 달성하였습니다. P라고 적힌 것이 Precision으로 text completion 성능을 측정한 것인데 CLII는 oCLIP 대비 25~37% 정도의 성능 향상을 보이고 있습니다. 특히, oCLIP이 original 데이터셋을 사용했을 때보다 masked 영상을 사용했을 때 text completion 성능이 크게는 14%정도로 많이 떨어지는 모습을 보이는데, CLII는 image 정보를 활용해 text를 completion함으로써 성능 저하를 막았을 뿐더러 original data를 사용한 oCLIP보다 오히려 좋은 성능을 보입니다.
또, PSNR과 SSIM을 통해 image inpainting 성능을 확인해 보면 tt 데이터셋에서 CLII는 MAE 대비 30% 정도의 성능 향상을 보이고 있구요, sota 방법론인 DDNM과 비교해봤을 때도 더 좋은 성능을 보이고 있습니다. 맨 아래칸에 있는 Formed baselines이라고 하는 건 기존 image inpainting과 text completion을 결합한 방식인데요 이와 비교해보았을 때도 가장 좋은 성능을 보입니다. 이는 단순 image inpainting 후 text를 completion하는 방식보다 image와 text 정보를 동시에 활용해 복원하는 CLII의 접근 방식이 효과적이라는 점을 시사합니다.
Qualitative comparison

위 Fig3은 정성적 결과를 보이고 있습니다. 그림이 작아 잘 안보일 것 같은데 맨 마지막 행이나, 바로 그 윗 행을 보시면 비교가 쉬울 것 같습니다. 보시면 MAE나 MAE-FAR의 경우 masking되어 있는 영역을 채우긴 하지만 text의 shape을 유지하지 못하고 있으며, MISF는 이 두 방법론보다는 글자를 잘 reconstruction하는 것으로 보이지만 디테일이 조금씩 부족해보입니다. CLII는 앞선 방법론보다 선명하게 text를 복구하고 있음을 확인할 수 있습니다.
4.2. Discussion
Effectiveness of image cues for text completion.
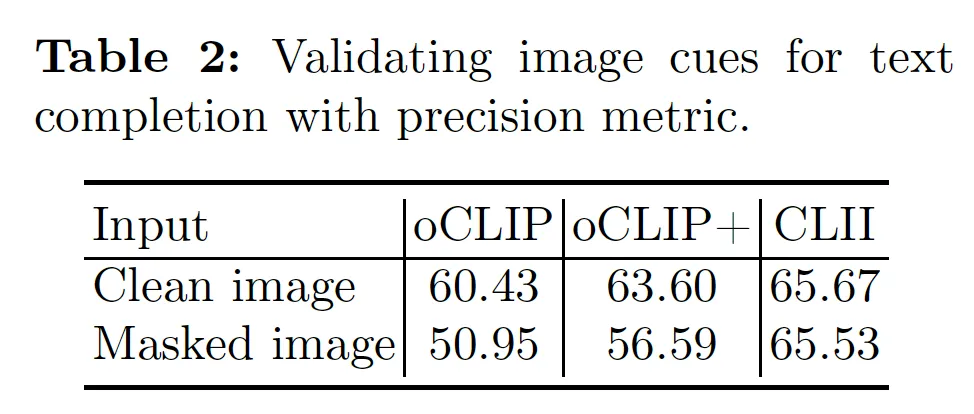
본 실험은 CLII가 image 정보를 활용해 text completion 성능을 향상시키는지 검증하기 위해 기존 text completion model인 oCLIP과 비교하는 실험을 수행한 부분입니다. 위 Table2에서 확인할 수 있듯이 실험은 oCLIP, oCLIP+, 제안된 모델 CLII를 비교하고 있습니다.
첫번째 oCLIP은 깨끗한 영상과 masking된 text를 입력으로 받아 학습 및 test를 수행한 것이구요. 두번째 oCLIP+는 masking된 영상과 masking 된 text를 사용해 학습 및 테스트하도록 하여 image의 손상 여부가 text completion 성능에 미치는 영향을 확인하고자 한 실험입니다.
실험 결과를 보시면 oCLIP 과 oCLIP+은 이미지에 손상이 있는가 여부 차이인데 masking 처리를 한 영상을 넣은 oCLIP+가 성능이 oCLIP보다 높은 것을 볼 수 있습니다. 즉, 이미지가 masking 처리가 되더라도 text completion할 때 더 도움이 된다고 볼 수 있는 것이죠. 그런데 CLII는 oCLIP+보다 더 좋은 성능을 보이는데 이는 그냥 masking된 영상을 참고하는 것만으로 충분하지 않고 image와 text 정보를 상호작용하는 방식으로 학습하는 것이 더 효과적이라는 점을 시사합니다.
또, 볼만한 점이 maskiing된 image를 사용했을 때 oCLIP과 oCLIP+은 clean image를 사용했을 떄와 비교하여 성능이 약 10%, 7% 정도 하락한 반면 CLII는 거의 차이가 없이 일관된 성능을 보이고 있습니다.
Applications in scene text spotting.
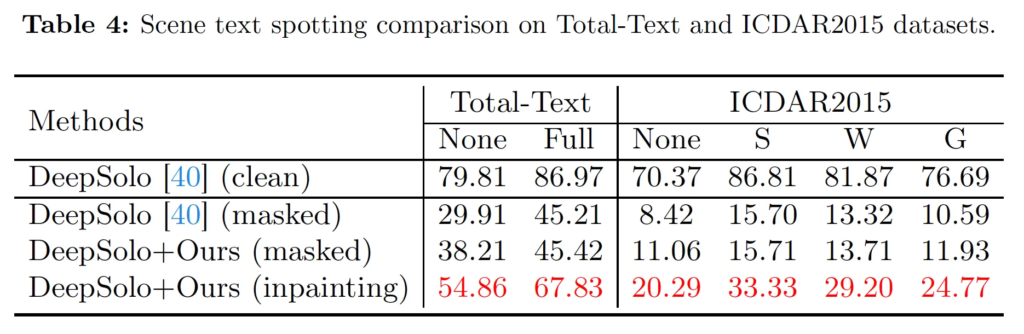
마지막으로 CLII가 실제 spotting task에 적용했을 때의 실험입니다.
Base 모델로 DeeoSolo를 사용했는데, 표를 보시면 clean과 masked간의 성능 차이가 엄청난 것을 확인할 수 있습니다. ICDAR2015에서 한 실험을 보면 None일 때 70.37이었던 성능이 8.42로 하락해버리는,, 문제가 있죠. 이를 해결하기 위해 저자는 CLII를 두가지 방식으로 적용해 실험을 수행하였습니다.
먼저 첫 번째는 DeepSolo+Ours(masked)라고 DeepSolo가 masking처리된 영상을 처리하도록 하고 CLII의 text completion을 적용하는 방식이며, 두번째 방식 DeepSolo + Ours(inpainting)은 CLII가 먼저 image를 inpainting한 후 DeepSolo가 이렇게 복원한 영상을 입력으로 받아 text recognition을 수행하는 방식입니다.
표를 보시면 첫번째 방식을 적용하면 이전 그냥 DeepSolo 성능보다 약간의 성능 향상을 보이며, 두번째 방식인 inpainting을 적용한 결과 8.42 → 20.29로 성능이 두 배 가까이 향상되었습니다. 그래도 그냥 clean일떄의 성능과 비교해보면 많이 아쉬운 성능이긴 합니다.
안녕하세요, 좋은 리뷰 감사합니다.
한가지 궁금한 점이 있는데, CLII이 image 정보를 활용해 text completion 성능을 향상시키는지 검증하는 실험에서 oCLIP과 oCLIP+의 차이가 이미지에 손상이 있는가 여부 차이라고 하였고 또 이에 대해 clean image와 masked image가 나뉘는 것으로 보았는데 이때 손상이 있는가 여부라고 함은 masking이 아닌 다른 손상을 의미하는 것인가요? 그렇다면 왜 손상이 있는 oCLIP+이 더 좋은 성능을 보이는지 궁금합니다.
감사합니다.
댓글 감사합니다.
1. oCLIP과 oCLIP+ 차이는 마스킹 여부가 맞습니다.
2. 아마 구조적인 차이가 원인일 수 있는데 oCLIP의 경우에는 텍스트만 보고 마스킹된 부분을 채워 넣는다고 하면 oCLIP+의 경우에는 이미지도 같이 보고 학습한 버전입니다. 이때 image와 text간의 cross-attn이 들어가 있는데 이 차이로 인해 더 좋은 성능을 보이는 것으로 생각해볼 수 있습니다.