안녕하세요, 57번째 x-review 입니다. 이번 논문은 CoRL 2024년도에 게재된 논문 입니다.
그럼 바로 리뷰 시작하겠습니다 !

1. Introduction
스테레오 카메라를 통해 구해지는 depth map은 노이즈와 정확도 측면에서의 한계로 인해 로봇 분야에서 잘 만들어진 인지 및 조작 알고리즘을 활용하는데 어려움을 주고 있습니다. 전통적인 SGM과 같은 stereo-to-depth 알고리즘에는 근본적인 문제가 존재하는데요, 먼저 non-Lambertian 표면 (바라보는 방향에 따라 밝기가 달라지는 표면)을 처리할 수 없다는 것 입니다. 두번째는 occlusion 및 시야각 외부 영역에 대한 픽셀 매칭은 계산할 수 없죠.
최근에는 learning 기반으로 위의 두 문제를 어느 정도 해결하고 있지만, RGB를 기준으로 봤을 때 모호한 픽셀 매칭으로 인해 depth를 추정하기에 어려움이 존재하는 투명하거나 반사되는 물체의 depth를 예측하는 것은 여전히 해결되지 못하고 있습니다.
본 논문에서 제안하는 D3RoMA는 이전의 대부분의 연구처럼 cost volume으로 네트워크를 설계하는 대신에 Diffusion을 사용해서 disaprity 맵을 예측하여 dense 매칭 문제를 이미지 간의 translation으로 정의하고 있습니다. 이는 low 레벨의 feature 매칭에 의존하는게 아니라 생성 모델을 사용해서 두 프레임을 목표하는 disparity 이미지로 변환하는 것이죠. 이러한 방식은 diffusion 모델을 통해 투명하거나 반사되는 표면에 대해서도 depth 분포를 생성할 수 있다고 합니다. 또한 inference 할 때는 왼쪽/오른쪽 프레임에 대한 consistency loss를 추가하여 기존의 스테레오 비전에서 사용하는 기하학적인 제약을 추가하였다고 합니다. 전체적으로 보면, diffusion 모델의 score function에서 gradient를 간단하게 합치친 학습 기반의 예측과 기존의 기하학적인 모델링을 통합하게 되는 것이죠.
추가적으로 학습을 위해 투명하고 반사되는 물체를 포함한 합성 데이터셋 HSSD-IsaacSim-STD(HISS)을 구축하였다고 합니다. 합성 데이터로 학습하고 real scene에 대해서 적용해봤을 때 반사, 투명, diffusive (통틀어서 STD) 물체를 대상으로 한 데이터셋에서까지 SOTA를 달성하였다고 합니다. 또한 로봇 조작에 대해서 검증하기 위해 tabletop 세팅부터 indoor 환경에서의 모바일 grasping을 수행하여 시뮬레이션 환경과 real 환경 모두에서 실험을 진행하였습니다. 결과적으로 높은 퀄리티의 depth map과 포인트 클라우드를 만들 수 있기 때문에 이를 사용해서 다양한 환경에서의 로봇 조작 성공률을 향상시킬 수 있었다고 합니다.
여기서 본 논문의 main contribution을 정리하면 다음과 같습니다.
- 투명 및 반사 표면에 대해 노이즈가 존재하는 depth map을 추정할 수 있는 diffusion 기반 스테레오 depth estimation 프레임워크 제안
- guided diffusion을 통해 학습에 스트레오 방식의 기하학적인 제약 조건 통합
- 실제 depth 센서의 IR 패턴과 렌더링을 시뮬레이션하여 STD 합성 데이터셋 구축
- depth map과 포인트 클라우드를 이용하여 로봇 조작 작업 성공률 개선
2. Method
2.1. Preliminaries
Denoising Diffusion Probabilistic Model
Diffusion 모델에 대한 논문에서는 이렇게 매번 Preliminaries를 구성하여 기본적인 수식을 설명해주는 것 같은데요, 마지막으로 한번 살펴보도록 하겠습니다.
먼저 forward 과정에서 주어지는 disparity map x_0가 있으면, 이 데이터에 노이즈를 추가하면서 변형하였다가 결국에는 완전히 노이즈만 존재하는 x_T를 만들게 됩니다.
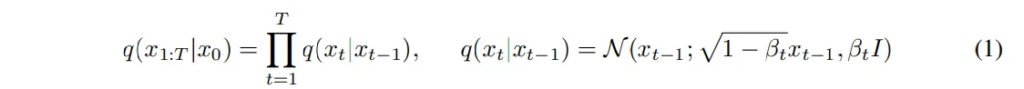
- B_t : 각 단계에서 추가되는 노이즈의 크기
식(1)의 왼쪽 식을 보면 알 수 있는데요, 초기 데이터에서 노이즈를 추가함으로써 최종적으로 노이즈로 채워진 x_T를 생성하는 것 입니다. 이때 각 단계에서의 노이즈 추가는 특정한 공식으로 계산되는데, 간단하게 말하면 랜덤 노이즈 \epsilon ~ \mathcal{N}(0,I)를 x_t를 만들며 시간이 지날수록 점점 더 많은 노이즈를 추가하게 됩니다.
반대로 reverse 과정은 식(2)와 같이 완전한 노이즈 x_T를 시작으로 점점 깨끗한 데이터 x_0로 되돌아갑니다.
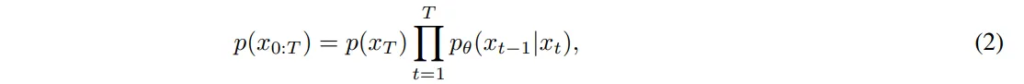
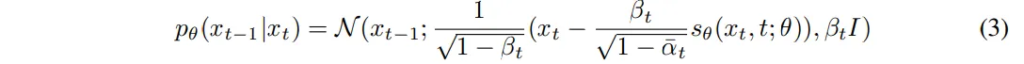
- x_t : 현재 단계의 노이자
- x_{t-1} : 한 단계 더 노이즈가 제거된 상태
- p_{/theta}(x_{t-1}|x_t) : 현재 상테에서 이전 상태로 가는 확률 분포
식(3)은 x_t에서 노이즈를 조금씩 제거해서 x_0으로 복원하는 과정을 나타내는데, 현재 상태에서 모델이 예측한 노이즈 s_{\theta}를 빼면서 더 깨끗한 상태 x_{t-1}로 이동하는 과정을 의미합니다.
모델은 노이즈를 얼마나 잘 예측할지를 학습하게 되는데요, 예측한 노이즈와 실제 노이즈 사이의 차이를 최소화하는 loss가 식(4)와 같이 정의할 수 있습니다.
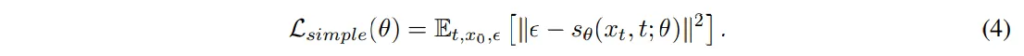
- s_{\theta}(x_t,t;\theta) : 모델이 예측한 노이즈
- \epsilon : 실제 랜덤 노이즈
모델이 노이즈를 잘 제거하기 위해서는 결국 노이즈 자체를 정확하게 예측할 수 있는 것이 먼저이기 때문에 노이즈의 예측 오차를 줄이는 방향으로 학습을 하게 됩니다. 잘 학습을 하면 노이즈가 포함된 데이터에서 원래의 disparity map을 복원할 수 있는 것이죠.
모델이 충분히 학습을 하고나면, 노이즈의 확률 분포 gradient를 예측할 수 있게 됩니다. 학습이 완료되면 모델은 x_t에서 여기는 노이즈다라는 걸 예측하는 패턴을 학습하게 되겠죠. 그래서 모델이 예측한 노이즈 s_{\theta} 가 바로 얼마나 노이즈가 포함되어있는지를 나타내는 값이 됩니다. 그래서 x_t에서 노이즈를 얼마나 빼야하는지, 즉 노이즈 분포의 gradient를 식(5)와 같이 score function으로 정의하여 알 수 있습니다.
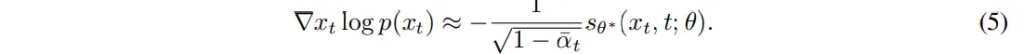
inference 단계에서는 학습된 모델을 이용해서 depth map을 식(6)과 같이 복원합니다.
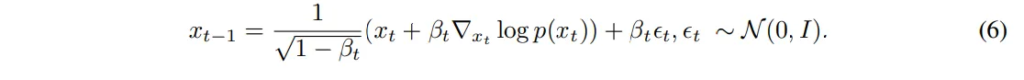
학습했던 모델이 노이즈라고 예측한 만큼 조금씩 노이즈를 빼면서 깨끗한 depth map을 만들어가는데, 여기서 너무 큰 차이를 가지고 노이즈를 제거하면 부자연스러운 결과가 나올 수 잇어서 조금씩 제거해야 한다고 하네요.
2.2. Disparity Diffusion for Depth Estimation
본 논문에서는 depth estimation을 이미지 간의 translation 문제로 본다고 했는데요, 스테레오 이미지를 입력으로 넣어서 깨끗한 disaprity map을 만들고자 합니다.
제가 이전에 리뷰했던 논문들이 그러했듯 본 논문에서도 랜덤의 이미지를 생성하는게 아니라 추가적인 조건으로서 raw disparity map인 \tilde{D}를 사용하였습니다. 이렇게 조건으로 raw disparity map을 추가했을 때 OOD 환경에서도 더 안정적인 결과를 낼 수 있었다고 하네요.
여기서 disparity map은 두 가지 방식으로 얻을 수 있는데, 전통적인 방식(SGM)이나 realsense와 같은 실제 depth 센서에서 얻는 방식이 있습니다. 이렇게 raw한 disparity map은 쉽게 얻을 수 있는 것이기 때문에 학습에 활용하고자 한 것이죠. 특히 realsense와 같은 stereo depth sensor는 일반 RGB 카메라가 아니라 IR 카메라를 사용해서 패턴을 project하여 depth 정보를 얻기 때문에 보다 더 정확한 정보를 얻을 수가 있습니다.
기본 diffusion 모델 식에서 조건을 부여하면 식(7) 같습니다.

y=\{I_l, I_r, \tilde{D}\}로, 왼쪽/오른쪽 이미지와 raw한 disparity map을 입력으로 사용한다는 의미 입니다. 모델은 기존 연구와 다르게 직접 disparity map을 예측하는게 아니라 확률 분포를 학습해서 샘플링하는 방식으로 사용한다는 것 입니다. 학습이 끝나면 샘플링을 통해 disparity map을 생성할 수 있는데, 샘플링 과정에서 확률적인 요소가 들어가 있기 때문에 더 자연스러운 결과를 도출하는 것이 가능하다고 합니다.
2.3. Reverse Sampling Guided by Stereo Geometry
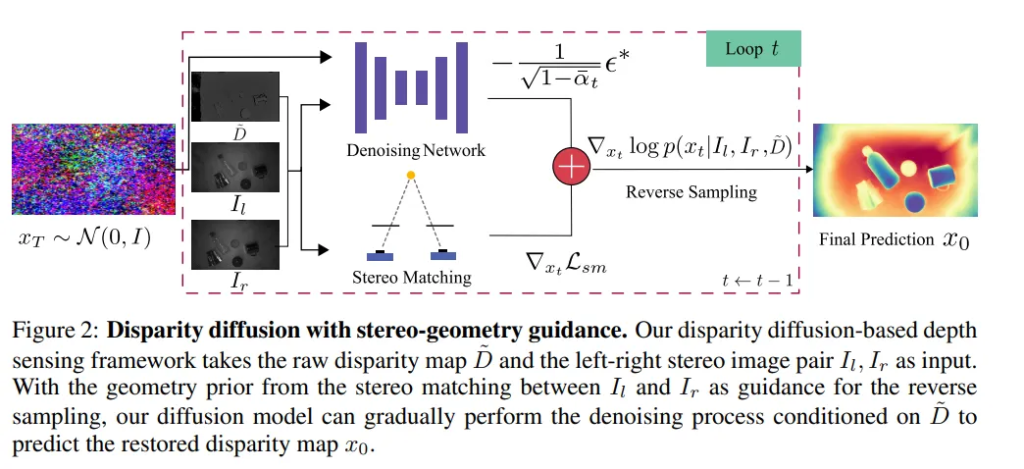
앞선 diffusion 모델에서 더 나아가 정확한 disparity map을 생성할 수 있도록 기하학적인 정보(gradient)를 추가하였습니다. 원래는 노이즈를 제거하면서 disparity map을 복원하였다면, 여기에 추가적으로 스테레오 매칭을 기반으로 한 기하학적인 정보를 활용해서 더 일관된 결과를 만들 수 있도록 유도하고자 한 것 입니다.
그 과정은 Fig.2에서 나타내고 있으며 reverse 과정에서 스테레오 매칭을 기반으로 한 항을 추가하여 식(9)과 같이 정의할 수 있습니다.
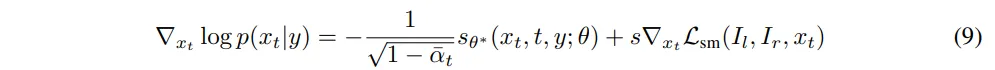
- s : 스테레오 매칭의 기하학적인 정보에 대한 정도를 조절하는 하이퍼파라미터
원래는 모델이 학습한 s_{\theta^*}만 가지고 depth map을 만들었다면, 추가적으로 스테레오 매칭을 이용한 gradient \triangledown_{x_t}L_{sm}을 사용한 것이죠. 여기서 L_{sm}은 왼쪽,오른쪽 이미지를 비교하는 loss 함수 입니다.
그럼 이 함수는 어떻게 계산되는 것이냐하면, 먼저 오른쪽 이미지 I_r을 x_t를 이용해서 와핑한 후에 그 와핑된 이미지를 I_l과 비교합니다. 즉, 왼쪽 이미지와 비슷한 모습이 되도록 오른쪽 이미지를 변형하는 과정을 통해 두 이미지 간의 차이를 줄이는 방향을 학습할 수가 있습니다. 그리고 graidnet를 계산할 때 여러 해상도를 사용하였는데요, 일반적인 스테레오 매칭이 되게 로컬한 영역에 대해서만 gradient를 계산해서 전체적인 구조를 반영하지 못한다는 문제가 있었기 때문입니다. 그래서 낮은 이미지의 해상도를 통해 더 넓은 범위에서 gradient 정보를 계산할 수 있도록 하였습니다. 이러한 L_{sm}을 정의하면 식(10)과 같습니다.
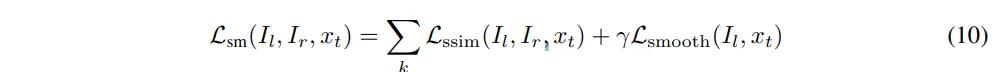
- k : 다른 해상도에 대한 index
크게 구조적인 유사도를 계산하는 L_{ssim}과 disparity map의 smooth함을 유지할 수 있는 L_{smoot}로 구성되어 있습니다.
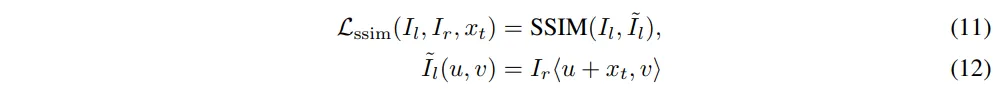
그 중 L_{ssim}은 I_l과 와핑하여 변형한 \tilde{I}_l을 비교하여 식(11)과 같이 유사도를 계산합니다.
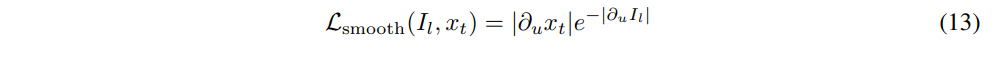
L_{smooth}는 disparity map을 smooth하게 유지하면서 엣지를 보존할 수 있도록 설계한 loss 함수 입니다. 이미지의 변화가 크면, 즉 엣지 부분이면 스무딩을 약하게 적용하고 이미지의 변화가 크지 않고 평탄한 부분에서는 더 부드럽게 보정될 수 있도록 하는 것이죠. 결국 depth map이 부드럽게 이어지면서도 중요한 경계 영역은 유지될 수 있도록 합니다.
식(9)에서 정의한 gradient를 사용해서 최종적인 disaprity map x_0을 복원할 수 있고 이 disparity map을 depth map으로 변환할 수 있겠죠. 이는 카메라 파라미터를 안다면 변환할 수 있으며, 이 과정까지 거치게 되면 결과적으로 얻고자 했던 depth map을 얻을 수 있게 됩니다.
2.4. HSS synthetic Dataset
구축한 HSS 합성 데이터셋은 기존의 HSSD라는 데이터셋을 기반으로 만들어졌습니다. 다양한 scene으로 확장하고 물체는 컵, 유리, 병과 같이 투명하거나 반사되는 물체를 포함하여 추가하였다고 합니다. NVIDIA Isaac Sim을 이용한 렌더링 방식을 사용하는데요, 첫번째 렌더링으로는 물체를 diffuse 재질로 설정해서 일반적인 RGB와 depth map을 생성합니다. 실제적인 조명을 이용해서 리얼한 이미지를 만들어냅니다. 그 다음 두번째 렌더링에서는 조명을 끄고 Realsense 415의 IR 패턴을 모방해서 그림자 패턴을 적용한 다음에, 내부 파라미터를 사용해서 만개 이상의 스테레오 이미지를 생성하였다고 합니다.
해당 데이터셋을 통해 투명하거나 반사하는 물체의 depth 추정을 더 정확하게 학습할 수 있고 real wold의 일반화 성능을 향상하는데 도움이 되었다고 합니다.
3. Experiments
3.1. Depth estimation in Robotic Scenarios
먼저 투명하고 반사되는 물체에 대한 합성 데이터와 라벨링이 된 real 데이터가 모두 포함되어 있는 테이블 레벨의 데이터셋인 DREDS에서 본 논문의 방법론을 평가하였다고 합니다.
총 4개의 SOTA 베이스라인 (1) NLSPN (2) LIDF (3) SwinDR (4) ASGrasp와 비교하였으며, 스테레오 depth SOTA 방식인 (1) RAFT-Streo (2) IGEV-Stereo (3) CroCoStereo와도 비교하였다고 합니다.
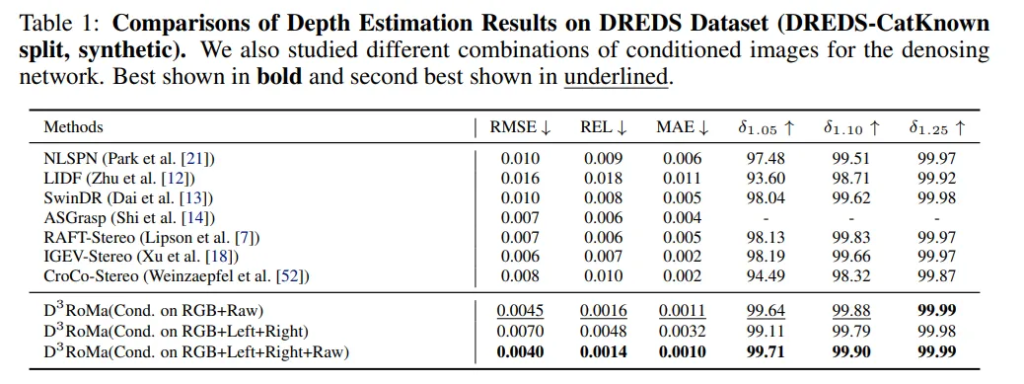
Tab.1을 보면, 모든 성능 지표에서 베이스라인 모델들 대비 SOTA를 달성한 것을 확인할 수 있습니다. 특히 제공되는 정보에 따라 성능 차이가 발생하는데 더 많은 정보를 제공할 수록 성능이 단계적으로 향상되고 있음을 확인할 수 있습니다.

그 다음은 투명하고 반사된 물체의 depth estimation을 위한 데이터셋의 효율성을 추가로 평가하였다고 합니다. Fig.13을 보면, 스테레오 매칭을 위해서 large-scale의 데이터셋에 대해 학습된 RAFT-Stereo와 비교했을 때 특히나 투명한 병에 대해서 더 잘 depth를 예측하는 것을 확인할 수 있습니다. Fair comparison을 위해 40만 에포크로 HISS에 대해서 RAFT-Stereo를 fine-tuning해서 투명한 물체에 대해서 depth를 좀 더 잘 추정하고 있긴 하지만 여전히 물체 모양에 대해서 부정확하게 나타내고 있는 것을 알 수 있습니다. 그 다음으로 ASGGrasp는 물체 경계가 흐릿하게 나타나는 것을 볼 수 있죠. 이러한 결과를 통해서 본 논문의 방법론이 모든 STD 물체에 대해 가장 최적의 depth를 제공할 수 있고, 물체의 경계가 더 명확하게 표현할 수 있다고 분석하고 있습니다.
3.2. Comparisons with SOTA Stereo Matching Methods in General Scenarios
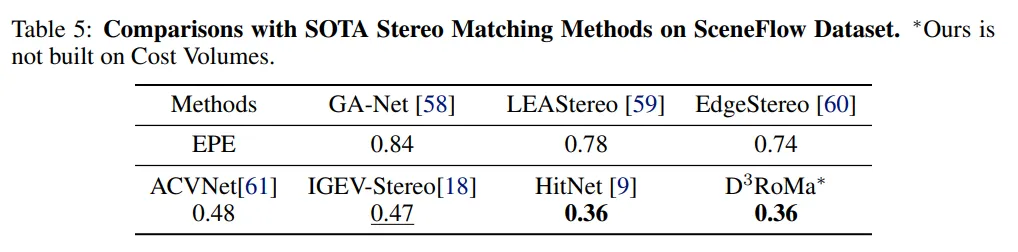
Tab.5는 일반적인 시나리오에서 스테레오 매칭에 대한 실험 결과 입니다. 합성 데이터셋인 SceneFlow 데이터셋에서 SOTA 스테레오 매칭 베이스라인과 비교하였다고 하네요. 별다른 분석이 적혀있진 않고 Tab.5에서 보이듯이 SOTA 대비 더 개선된 성능을 보이고 있다고만 이야기하고 있습니다.
3.3. Robotic Manipulation
인트로에서 이야기하였듯 본 논문에서는 만들어낸 depth map으로 포인트 클라우드까지 형성하여 실제 로봇 조작에서의 성공률까지 평가를 진행하였습니다.
Environment Setup

먼저 Fig.5와 같이 real 환경에서 Table-top grasping이나, 물체 조작, 그리고 모바일 grasping 환경을 설정하였다고 합니다. 물체는 유리나 도자기와 같이 non-diffusive한 표면을 가진 물체로 구성하였습니다.
Result and Analysis
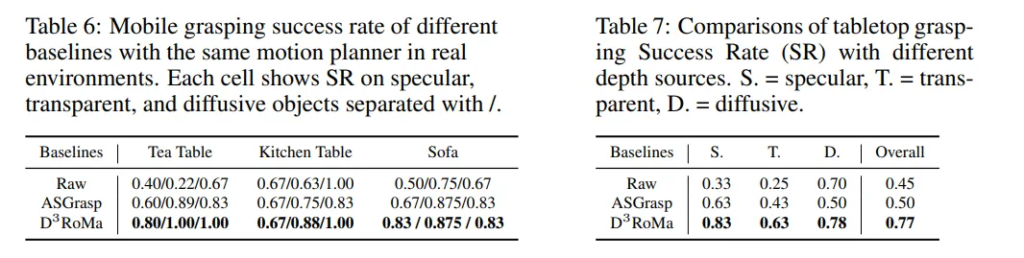
모든 베이스라인은 동일한 모션 플래너 CuRobo을 사용하지만 depth 센싱 방식은 다르다고 합니다. Tab.6은 서로 다른 모바일 grasp scene에 대한 정량적인 결과 입니다. STD 물체에 대한 Table-top grasping은 ASGrasp와 비교하였고, Tab 7은 각각 다른 STD 물체에 대한 결과와 전체 성공률을 나타내고 있습니다.
베이스 모델과 본 논문의 방법론은 모두 raw한 센서 출력에 비해서는 개선되었지만, 본 논문의 방법론인 ASGrasp보다도 더 개선된 성능을 보이며 생성한 depth map의 퀄리티가 향상되면서 실제 로봇 조작으로 확장하여서도 활용할 수 있다는 것을 실험적으로 증명하고 있습니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
본 논문에서 제안하는 contribution 중 하나가 HSS 합성 데이터셋을 구축한 것이라고 이해했는데, 해당 데이터셋에 대한 실험 결과는 없는 것일까요 ? 타 데이터셋에 대한 실험 결과만 리포팅되어 있어서 혹시 논문에 추가적으로 있는지가 궁금합니다.
그리고 L_{ssim}은 왼쪽 이미지와 와핑된 이미지를 대상으로만 이루어지는 것인가요 ?? 왼쪽 이미지를 기준으로 하는 이유가 있을까요 .. ?
감사합니다.
안녕하세요, 리뷰 읽어주셔서 감사합니다.
말씀하신 것처럼 논문의 실험 파트에는 HSS 데이터셋에 대한 내용은 없고 appendix를 찾아보니 리포팅 돼있었습니다. 그런데 벤치마킹한 방법론도 본 논문 방법론 포함 두개밖에 없고, 별다른 분석은 없더라구요.
L_{ssim}은 왼쪽 이미지와 와핑된 왼쪽 이미지 간의 구조적인 유사도를 측정하는 것이 맞고, 왼쪽 이미지를 기준으로 비교하는 이유는 스트레오에서 보통 왼쪽 이미지가 기준 프레임으로 사용되며 와핑된 이미지는 그 기준 프ꂌ임에 맞춰져야 의미있는 유사도 비교가 가능하기 때문입니다.
감사합니다.