안녕하세요 이번주에는 3D reconstruction과 neural rendering을 활용한 엄청나게 현실적인 real-to-sim 시스템에 대해서 리뷰해보도록 하겠습니다.
Introduction
실제 환경에서 전문가의 Teleoperation을 통한 데이터 수집은 뛰어난 일반화 능력이 있지만 시간과 비용이 정말 많이 발생합니다. 반면 시뮬레이션 데이터는 기하급수적으로 데이터를 확장할 수 있기 때문에 로봇 정책 학습을 위한 데이터를 만들 때 지속가능한 대안이 될 수 있습니다. 문제는 시뮬레이션으로 현실을 옮길때의 gap이 크다는 점입니다. 미리 만들어진 CAD 모델은 이상적인 구조를 가정하고 만들었기 때문에 이러한 모델을 합성해서 만든 데이터는 sim-to-real gap이 클 수 밖에 없습니다. 구조적인 문제 뿐 만 아니라 센서의 노이즈나 부정확한 렌더링은 시각적으로도 gap을 유발합니다. 이런 sim-to-real gap을 줄이기 위해 저자들은 3D-photorealistic real-to-sim-to-real system인 RE3SIM을 제안했습니다. MVS와 Gaussian rasterization 기법을 사용해 기하학적인 구조와 시각적인 렌더링을 실제와 유사하게 복제할 수 있다고 합니다. 나아가 시뮬레이션 환경에서의 물리엔진을 통해 역학적인 요소들도 구현하고, hybrid rendering 엔진을 통해 실시간으로 렌더링을 할 수도 있다고 합니다.

real-to-sim의 전반적인 파이프라인은 위 figure의 (b)와 같으며 장면 및 객체의 기하학적 구조를 재구성하는 mesh recovery, 전경과 배경을 합성하는 hybrid visual rendering, 실제 환경과 시뮬레이션 환경 간의 좌표를 동기화하는 real-world alignment로 구성됩니다. 이 과정에서 인간의 개입은 장면의 영상 촬영과 ArUco 마커를 배치해 로봇 베이스 정렬을 위한 추가적인 사진을 통해 real-world alignment를 수행만 필요합니다. 3분 이내에 새로운 장면을 재구성하고 두 개의 카메라를 통해 24FPS의 렌더링을 할 수 있다고 하네요. (c)의 결과를 보면 정말 실제와 유사한 모습을 볼 수 있습니다.이를 활용해 설계한 real-to-sim-to-real 프로세스는 위 figure의 (a)와 같은 zero shot 작업에서 58%의 작업성공률을 보여주면서 향후 일반화 가능한 로봇 정책의 기반이 될 것으로 기대한다고 합니다. 마지막 (d)를 보시면 시뮬레이션과 real world간의 격차가 거의 없는 것을 볼 수 있습니다.
Method
사실 Isaac Sim, Gazebo와 같은 physics 기반의 시뮬레이터들은 물리엔진을 물리적으로는 높은 정확도의 시뮬레이션 결과를 제공합니다. 하지만 현실의 3D 환경을 직접 취득하는것, 그리고 그 데이터를 고품질로 렌더링 하는 것에 한계가 있었습니다. 가장 직관적인 방법은 객체와 배경을 전체적으로 함께 재구성 하는 것이지만 Multi View Stereo와 같은 기법들을 사용해 배경을 재구성하면 돌출된 부분들이나 패여있는 부분들이 생길 수 있고, 현실감을 저하시킵니다. 또, 객체를 분리하는데도 많은 노력이 필요합니다. 최근 NeRF나 3D Gaussian Splatting과 같은 고품질 렌더링 모델들이 등장해 이러한 문제를 어느정도 해결해 줄 수 있게 되었다고 합니다. 저자들은 충돌 감지를 위한 배경 메쉬를 개별적으로 reconstruction 하고 3D Gaussian Splatting을 활용해 렌더링을 하되, 객체 렌더링이 로봇의 시각적 관찰에서 차지하는 비율이 작기 때문에, 객체 렌더링에는 3DGS를 사용하지 않기로 결정했다고 합니다. 결론적으로 기존의 mvs의 품질 문제를 해결하기 위해 3D Gaussian Splatting을 통해 배경과 객체를 분리해서 렌더링하는 전략을 택했씁니다. 다만 로봇은 포함하지 안흔ㄴ다고 합니다.
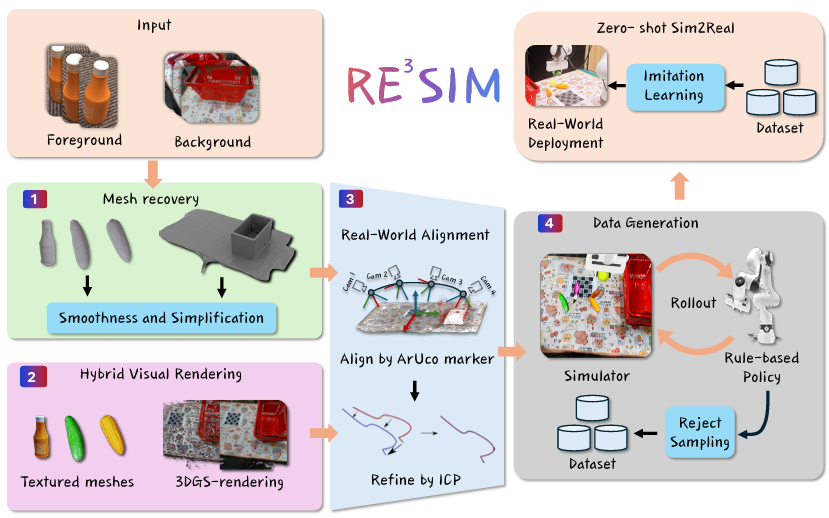
RE3SIM은 다음과 같이 Mesh recover, Hybrid Visual Rendering, Real-World Alignment, Data Generation의 4가지 주요 컴포넌트로 이루어져 있습니다. 각각 객체의 충돌정보, 3DGS와 mesh의 결합, 재현에 포함되지 않은 로봇의 좌표계 정렬, manipulation을 위한 데이터 생성을 담당합니다. 하나씩 살펴보도록 하겠습니다/
Mesh Reconstruction
이 단계의 핵심은 전경과 배경을 따로, 정밀하게 재구성해서 USD형식으로 표현하는 것입니다. 먼저 COLMAP을 사용해 이미지에서 카메라 포즈를 추정하고, sparse point cloud를 생성합니다. 이후 OpenMVS를 활용해서 정밀한 mesh를 생성합니다. 이렇게 생성된 mesh는 polycam을 활용해 생성한 mesh보다 훨씬 더 매끄러운 품질을 제공한다고 합니다. 또한 전경과 배경을 따로 구분해서 처리하는 것 또한 품질을 향상시킵니다. 이 때 전경과 배경은 ARCode를 활용해서 구분하는데, ARCode가 조작 대상 객체를 자동으로 분할해서 사용자가 마스킹하는 작업을 생략할 수 있습니다. 이렇게 따로 구분된 객체에 대한 COLMAP + OpenMVS 조합으로 메쉬를 생성하면 시뮬레이션에서 훨씬 더 정돈된 기하적 구조를 가질 수 있게 됩니다. 이후 생성된 mesh들에 대해 빈 공간을 채워주거나 표면을 평평하게 하는 작업을 통해 더 안정된 시뮬레이션을 노리고, 물리량 같은 경우는 질량, 마찰계수 등등 전부 default value를 사용하고, 그렇게 해도 시뮬레이션 상에 문제가 없다고 합니다. 이 부분에 대해서는 조금 더 찾아봐야 할 것 같습니다. RialTo의 경우 sim-to-real 과정에서 현실의 물리량을 잘 옮기는 것도 중요하다고 했던 것 같은데 default value를 활용해 과정이 단순화 되었는데도 성능적인 희생이 없다고 합니다. 질량에는 어떻게 default value가 있는건지도 모르겠습니다..
Hybrid Visual Rendering
컬러 이미지는 시뮬레이션에서 중요한 인식 신호이지만, 현실과 비교했을 때 시각적 차이가 크다고 합니다. (아직 정확하게 어떤 의미에서 이런 말을 했는지는 잘 이해가 안 됩니다..) 이를 해결하기 위해, RE3SIM은 hybrid visual 렌더링 기법을 적용하여 전경 객체와 배경을 다르게 렌더링합니다. 전경 객체는 메쉬 기반 렌더링을 수행하며 ray tracing 기법을 지원하여 보다 정교한 조명을 반영할 수 있도록 합니다. 반면, 배경은 장면의 대부분을 차지하기 때문에 3D Gaussian Splatting 을 활용한 photorealistic 렌더링을 적용하여 현실감 있는 환경을 구현합니다. 또한, 객체들을 보다 자연스럽게 합성하기 위해 Z-buffer 렌더링을 적용하여 실제ground-truth depth정보에 맞춰 객체들을 정렬합니다. 이와 함께, 다중 시점에 따른 multi-view rendering을 지원하여 다양한 시점에서도 일관된 렌더링 품질을 유지할 수 있도록 합니다. 결론적으로, RE3SIM은 hybrid visual rendering 기법을 통해 전경과 배경을 다르게 처리하여 렌더링 품질을 높이며, Z-buffer를 활용한 자연스러운 객체 합성과 multi-view 지원을 통해 보다 현실적인 시뮬레이션 환경을 제공합니다.
Real-World Alignment
렌더링과 메쉬 간의 정렬이 이미 이루어졌음에도 불구하고, 현실적인 시나리오와의 정렬, 특히 배경과 전경 객체가 로봇과 상대적으로 일치하는 위치를 보장하는 과정이 추가적으로 필요합니다. 전경 객체의 경우, 시뮬레이션에서 배치될 수 있는 가능한 위치 범위를 정의하여 객체가 적절한 위치에 놓이도록 합니다. 배경과 관련해서는 테이블 위에 ArUco 마커를 배치하여, 3DGS 좌표를 마커 좌표와 정렬합니다. 이를 통해 배경 메쉬가 실제 환경과 최대한 일치하도록 보정합니다. 추가적으로, ICP (Iterative Closest Point) 후처리 기법을 적용하여 좌표 정렬 과정에서 발생하는 오차를 최적화합니다. ICP는 depth camera에서 얻은 partial point cloud와, 재구성된 메쉬에서 샘플링한 complete point cloud 간의 상대적 변환을 최적화하는 방식으로 동작한다고 합니다. 이를 통해 시뮬레이션 환경과 실제 환경 간의 정렬 정확도를 더욱 높일 수 있습니다.
Expert Data Collection
저자들은 RE3SIM의 효과를 검증하기 위해 Pick-and-Place와 같은 사전 설계된 작업 시나리오를 기반으로 대규모 시연 데이터를 수집했다고 합니다. 이를 위해 스크립트 기반 정책을 활용하여 데이터를 생성하며, 각 rollout에서 domain randomization을 적용합니다. 도메인 랜덤화는 소스 및 타겟 객체의 위치를 무작위로 변경하거나, 로봇 팔의 베이스 위치를 다르게 설정하는 방식으로 이루어 진다고 합니다. 이를 통해 정책이 다양한 환경에서도 일반화될 수 있도록 합니다. 전문가 정책은 특권 정보를 기반으로 정의됩니다. 여기서 특권 정보란 타겟 객체의 정확한 pose나 물리량 같은 시뮬레이션에서만 접근 가능한 정보를 의미합니다. 전문가 정책을 활용하여 시뮬레이터와 상호작용하면서 observation과 action 쌍 (ot, at)을 생성합니다. 관측 데이터(ot)는 실제 환경에서 접근할 수 있는 정보로, 이미지 및 로봇의 상태(proprioception data) 등을 포함합니다. 또한, 특정 단계에서 그리퍼의 6D pose를 계산하고, RRTConnect 알고리즘을 기반으로 경로를 계획하여 (key steps 간의 이동 경로를 joint space에서 계획하는 방식으로 진행합니다.) 조작 작업을 수행합니다. 또한 데이터 생성 과정에서 Reject Sampling을 적용하여 실패한 rollout을 필터링 함으로써 데이터셋의 품질과 신뢰성을 향상 한다고 합니다. 이러한 방식으로 필요한 양만큼 시뮬레이션 데이터를 지속적으로 생성할 수 있으며, 이를 통해 최종적으로 시뮬레이션 데이터셋 D를 확보하게 됩니다. 이를 통해 manipulation을 위한 large scale dataset을 확보할 수 있습니다.
Experiment
저자들은 RE3SIM의 성능을 평가하기 위해 다음과 같이 4가지 질문을 던지고 (RE3SIM은 고품질의 정확하게 정렬된 재구성 결과를 생성할 수 있는가? RE3SIM이 생성한 시뮬레이션 데이터는 3D sim-to-real gap이 작으며, 실제 로봇 조작 문제 해결에 유용한가?, 대규모 시뮬레이션 데이터가 보다 복잡한 실제 환경에서 조작 성능을 향상시키는가?, RE3SIM은 전체 장면을 시뮬레이션에서 효율적으로 구축하고, 저비용으로 데이터를 합성할 수 있는가?) , 이에 대한 답을 구하기 위해 실험을 진행했다고 합니다. 로봇은 Franka Research3를 사용하고, depth sensor로는 그리퍼에 부착된 한 대, 환경 전체를 찍는 한 대로 총 두 대의 D435i를 사용했다고 합니다.
먼저 RE3SIM이 고품질의 데이터를 정확하게 생성할 수 있는지에 대한 배경 렌더링 평가와 비교를 진행했습니다. 시뮬레이션 데이터셋에서 특정 trajectory를 선택해 로봇이 수행한 trajectory 그대로 실제 환경에서 gt를 구해 그 과정에서 촬영된 이미지간의 시각적 유사도를 측정했다고 합니다. 결과는 Polycam 방식을 사용했을 때 보다 3DGS를 활용했을 때 더 높은 유사도를 가졌습니다. 직접 촬영된 이미지를 눈으로 비교해보면 정말 우수한 성능이 체감됩니다.


ㄷㅏ음으로는 두 번째 질문인 작은 3D sim-to-real gap을 유지하며, RE3SIM이 실제 로봇 조작 문제를 해결하는 데 도움이 되는가?에 대한 답을 얻기 위해 table top환경의 manipulation task를 설계해서 평가했습니다. 25cm × 35cm 영역 내에서 무작위로 배치된 오렌지색 병을 집어 바구니에 넣어야 하는 task, 35cm × 50cm 영역 내에 무작위로 배치된 오이를 무작위로 배치된 도마에 올리는 task, 무작위로 배치된 큐브를 쌓는 task로 실험을 진행했습니다. RE3SIM을 통해 수집된 정책의 비교대상은 RialTo였습니다. 아래 표에 제시된 수치 결과를 분석한 결과, RE3SIM을 통해 생성된 데이터는 정책이 Zero-Shot Sim-to-Real 전이를 달성하는 데 중요한 역할을 하는 것으로 나타났다고 합니다. 기존 real-to-sim grasping 방법과 비교했을 때도 RE3SIM 기반의 학습된 정책이 강력한 성능을 보였습니다. 특히, RE3SIM을 이용하여 구축한 대규모 합성 데이터셋에서 학습한 정책은 실제 환경에서 수집한 데이터만으로 학습한 정책과 비교했을 때 오히려 더 높은 성능을 기록하였다고 합니다. 단순하게 시뮬레이션 데이터를 사용하는 것이 아니라, 고품질의 시뮬레이션 환경이 실제 환경에서의 조작 성능을 크게 향상시킬 수 있다는 것을 아 ㄹ 수 있었습니다.

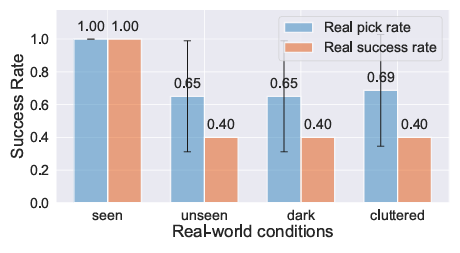
더 나아가서 저자들은 세번째 질문인 대규모 시뮬레이션 데이터가 보다 복잡한 실제 조작 작업에서 도움이 되는가?에 대한 실험도 진행했습니다. 이를 위해서 무작위로 배치된 모든 물건들을 바구니에 넣는 long horizon task를 통해서 실험을 진행했습니다. 이 때 이 task를 진행하면서 로봇이 본 적 없는 물체들도 조작할 수 있는지 평가했다고 합니다. 충분한 평가를 위해 seen, unseen, cluttered(seen unseen 혼합), darkness(조도 변화)로 설정하고 진행했습니다. 10번 반복해서 진행했고, grasping에 실패했을 경우 두 번의 추가 기회를 주었다고 합니다.
실험 결과, 훈련 시 다섯 개의 물체만을 사용했음에도 불구하고, 정책은 새로운 물체의 형태 및 색상이 다름에도 불구하고 유사한 크기를 가진 물체를 효과적으로 잡을 수 있었다고 합니다. 이러한 결과가 나온 이유로, 연구진은 로봇이 고정된 scene을 인식하고, 배경과의 색상 차이를 이용하여 물체를 식별할 수 있기 때문이라고 가설을 세웠습니다. 또한, 형태가 다른 물체라 하더라도 grasping point가 유사한 경우가 많아, 로봇이 일관된 정책을 실행할 수 있었던 것으로 분석되었다고 합니다. (이건 뭔가 맞는 말인지 잘 모르겠습니다..). 추가적으로 큰 데이터셋을 사용하여 다양한 물체를 학습한 정책은 상대적으로 높은 성공률을 유지하는 반면, 작은 데이터셋에서 학습한 정책은 일반화 능력이 제한되는 경향이 있었다고 합니다. darkness 상황에서도 잘 작동하는 모습을 보였습니다.
마지막 질문이었던 RE3SIM의 효율성을 검증하기 위해, 저자들은 배경 및 객체 재구성 속도와 시뮬레이션 데이터 생성 속도를 측정했습니다. 배경을 재구성하기 위해서는 배경의 이미지 집합 또는 짧은 동영상과 더불어 깊이 정보를 포함한 정렬용 추가 이미지가 필요하고, 이 때는 어쩔 수 엇이 배경과 전경 객체를 재구성하는 작업은 일정 부분 사람의 개입이 요구되므로, 실험에서는 해당 작업에 소요되는 시간을 추정했다고 합니다.
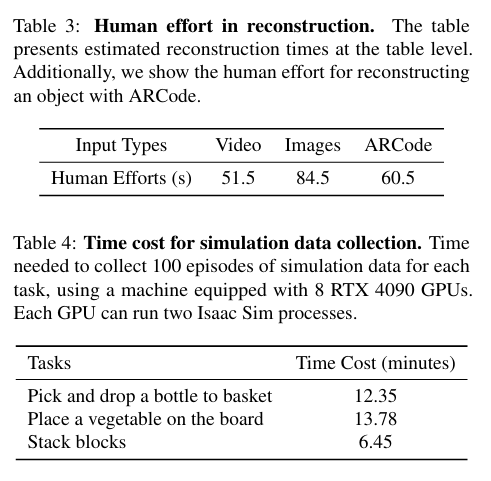
Table 3에서는 입력 데이터 유형에 따른 처리 속도를 비교했고, 비디오를 입력으로 사용할 경우 모션 블러로 인해 품질이 약간 저하될 수 있지만 처리 시간이 단축되는 반면, 이미지를 활용하면 품질이 향상되지만 처리 시간이 조금 더 소요됐다고 합니다. 또한, ARCode를 활용하여 단일 객체를 재구성하는 데 걸리는 시간을 측정하고, 이를 바탕으로 장면 전체를 재구성하는 데 소요되는 총 시간을 계산했습니다. 시뮬레이션 데이터 수집 속도를 평가를 위해서는 zero shot 평가를 위해 만든 작업별로 100개의 시뮬레이션 에피소드를 생성하는 데 걸리는 시간을 측정하였습니다. 실험에는 8개의 RTX 4090 GPU를 사용하여 병렬 연산을 수행하였으며, 시뮬레이션을 활용한 데이터 수집이 실제 환경에서 teleoperation 방식으로 데이터를 수집하는 것보다 훨씬 빠르고 비용 효율적인 방법임을 확인했다고 합니다. 100개의 에피소드를 위해 10분 남짓의 시간이 필요한 것을 보면 굉장히 빠른 것 같습니다.
안녕하세요 영규님 좋은 리뷰 감사합니다.
렌더링 얘기가 중간중간 많이 나오는데, hybrid visual 렌더링, Z-buffer 렌더링 등이 무엇인가요?
재찬님 댓글 감사합니다.
hybrid visual 렌더링은 하이브리드로 배경은 빠르고 사실적인 3DGS를 사용해 렌더링하고, 상호작용 해야하는 전경 객체는 mesh를 활용한 렌더링을 섞어서 최적화된 렌더링을 진행하는 것이라고 보시면 될 것 같습니다.
추가적으로 Z-buffer 렌더링은 배경과 전경을 따로 렌더링해서 표현하기 때문에, Z값 (깊이)를 저장하는 버퍼를 도입한 렌더링을 통해 겹치는 부분이 생기는 경우 더 가까이 있는 렌더링만을 표현하는 방법입니다.
좋은 리뷰 감사합니다.
Intro에 작성된 내용 중에서
“저자들은 충돌 감지를 위한 배경 메쉬를 개별적으로 reconstruction 하고 3D Gaussian Splatting을 활용해 렌더링을 하되, 객체 렌더링이 로봇의 시각적 관찰에서 차지하는 비율이 작기 때문에, 객체 렌더링에는 3DGS를 사용하지 않기로 결정했다고 합니다. 결론적으로 기존의 mvs의 품질 문제를 해결하기 위해 3D Gaussian Splatting을 통해 배경과 객체를 분리해서 렌더링하는 전략을 택했씁니다.”
라는 말이 저한테 중요한 말인 것 같습니다.
로봇이 상호작용하는 대상은 객체인데 객체 렌더링이 로봇의 시각적 관찰에서 차지하는 비율이 적다는 말은 틀린 말 같습니다… 오히려 더 크지 않을까요??
해당 부분에 대해서 추가적인 설명 부탁합니다…
태주님 댓글 감사합니다. 제가 이해를 잘못했었습니다.
우선 저자들의 프레임워크는 전경과 배경을 분리해서 렌더링하고, 배경은 3DGS, 전경은 mesh 기반의 ray tracing 렌더링으로 표현합니다. 이유는 말씀하신대로 로봇이 실제로 상호작용 하는 대상이 전경 객체이기 때문입니다. 시뮬레이터 상에서 6D Pose를 구하거나 실제 물리 엔진을 적용해서 상호작용 하기 위해서는 mesh 구조가 필수적입니다. 하지만 배경의 경우 시뮬레이터 상의 카메라로 보여지는 부분이기 때문에 (보고 피해야 하기 때문에) 현실적인 렌더링이 중요하고, 이를 더 깔끔하고 빠르게 할 수 있는 렌더링이 3DGS입니다. 만약 테이블이나 벽과 같은 로봇이 실제로 상호작용해야 하는 배경이라면 그 부분에도 대략적인 mesh를 통한 collision을 설정해준다고 합니다.