안녕하세요, 쉰 세번째 X-Review입니다. 이번 논문은 2024년도 ArXiv에 올라온 InstructOCR: Instruction Boosting Scene Text Spotting논문입니다. 바로 시작하도록 하겠습니다. ?
1. Introduction
최근 vision과 text를 함께 사용하는 vision-language task에서 사람의 지시 instruction을 함께 사용함으로써 모델이 영상 내용을 더 잘 이해하도록 하는 연구가 있어왔습니다. 본 논문은 이런 연구에서 인사이트를 얻어 다음과 같은 질문을 던지게 됩니다.
For scene text images, which inherently involve visual text, wouldn’t the incorporation of human language instructions be more beneficial?
해석하자면, Visual text를 포함하고 있는 scene text 영상에서 사람의 자연어 지시를 사용하면 더 유익하지 않을까? 라는 것입니다.
OCR tasks에서는 oCLIP이나 ODM이라고 하는 text 정보를 사용함으로써 image encoder를 효과적으로 사전학습하는 사전학습 기법을 제안하는 논문들이 최근에 나오고 있습니다. 사전학습한 image encoder를 real scene text image에 대해 fine-tuning할 때 가져와 사용하는 방식이라고 보면 됩니다. 하지만 이런 방법론들은 사전학습과정에서 학습한 image와 text encoder를 모두 text spotting 단에서 사용하는 것이 아니라 오직 image encoder만 가져와서 사용하고 있습니다. 그 외에 TCM, FastTCM이라고 하는 모델들은 CLIP을 가져와 사용하여 visual prompt learning과 cross attention을 통해 이미지와 텍스트 기반의 prior knowledge를 추출해 사용하는 방식을 제안하였는데, 이 TCM과 FastTCM에서 사용된 text encoder는 CLIP 모델의 text encoder를 그대로 가져와 사용한 거구, 학습 과정에서 freeze되어 업데이트 되지 않습니다.
본 논문 저자가 말하고자 하는 것은, scene text spotting task에서 사람의 자연어 지시와 visual text이 align되도록 학습하면 좋을 것이다는 것입니다. 이런 주장을 입증하고자 InstructOCR이라는 instruction 기반의 scene text spotting 모델을 제안합니다. 또, 앞서 언급한 연구들이 text encoder를 freeze해서 사용한다던지 등의 한계를 해결하고자 text image 인코더를 학습 때와 추론 때 둘다 사용하고자 하였습니다.

위 그림은 다양한 Instruction, 지시어를 사용했을 경우에 대응하고 있는 recognition 결과입니다. 위쪽 그림의 instruction을 보면 문자가 3개인 text로 구성된 text를 인식하라고 적혀있고 이에 대해 모델이 지시어를 잘 이해하여 3글자 텍스트인 New와 Job을 인식하고 있습니다. 밑에는 A 문자로 시작하는 text를 인식하라는 지시어인데 이에 대해 “Ahead”라는 텍스트만이 잘 인식되고 있습니다.
이렇게 모델을 학습하고 추론할 때 필요해보이는 Instruction은 기존 데이터셋에 그냥 주어지지는 않고 데이터셋 annotation을 기반으로 생성해서 사용을 해야겠지요. 텍스트의 속성 중 길이 같은 것들이 모델 성능을 향상하는데 중요하다는 기존 연구를 기반으로 아래 표에 적힌 것과 같이 10개의 템플릿을 설계하였습니다.

몇 개만 살펴보자면, 모든 text를 인식해라, N 글자 이상인 text를 인식해라, {word}를 포함한 텍스트를 인식해라 등이 있습니다. 이렇게 다양한 지시어를 통해 모델이 사람의 의도에 맞는 작업을 수행하도록 학습하고자 하였습니다. 또, 이렇게 설계한 지시어는 기존 어노테이션 정보만으로 설계할 수 있어 추가적인 cost가 들지 않는다는 장점도 있습니다. 이제 Method단에서 설계된 프레임워크를 구체적으로 살펴보도록 하겠습니다.
2. Method
다시 한 번 정리해보자면 본 논문에서는 InstructOCR이라고 하는 scene text spotting 방법론을 제안하고 있습니다. 이 InstructOCR은 사람의 지시어를 모델이 어떻게 출력해야 하는지 가이드로 사용하였습니다. 이렇게 지시어에 맞는 모델의 인식 결과를 생성하도록 함으로써 텍스트에 대한 이해를 높이고자 한 것이죠.
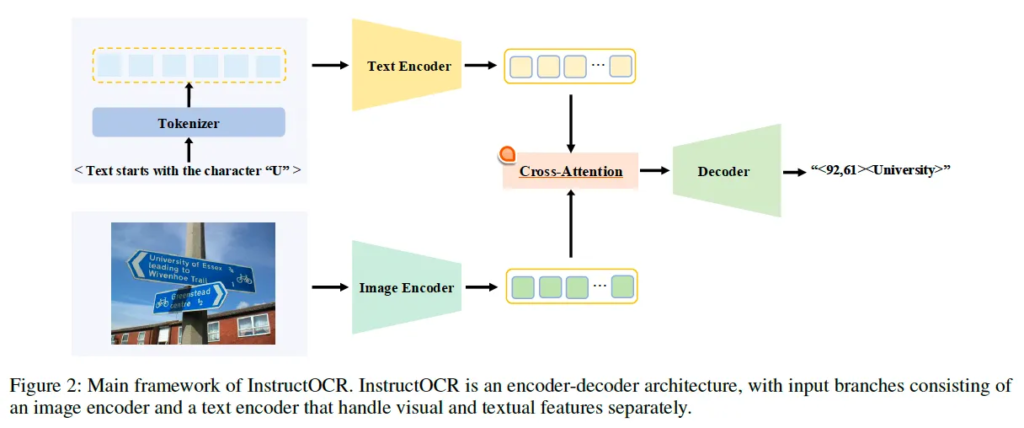
전체적인 프레임워크는 위 fig2에 모사되어 있습니다. 살펴보자면 처음에 입력 영상과 함께 instruction이 동시에 입력되고 있으며 각각의 encoder를 통해 타고 나온 feature를 cross-attention을 거치고 decoder를 통해 최종적으로 instruction에 해당하는 text만을 recognition하는 식으로 동작합니다. 구조를 좀 더 자세히 살펴보도록 하겠습니다.
InstructOCR Architecture
Image Encoder & Text Encoder.
입력 영상에 대한 feature를 추출하는 이미지 인코더는 ResNet50을 사용하였으며, text encoder로는 BERT를 사용하여 지시어에 대한 feature를 추출하도록 하였습니다.
Decoder.
InstructOCR의 decoder는 SPTS라고 하는 single point 기반으로 spotting을 수행하는 기존 방법론의 decoder를 사용하였습니다. 이 SPTS의 decoder는 auto regressive방식으로 영상 내 존재하는 모든 text instance에 대한 sequence를 생성하는 식으로 동작합니다. 각 text instance에 대한 sequence는 [x, y, t]라는 세 파트로 구성이 됩니다. 이 중 (x, y)가 text의 센터 점 좌표에 해당을 하고 t가 text의 transcription(진짜 text)에 해당합니다.

위 fig3에 방금 설명드린 부분이 나와있습니다. output sequence라고 되어 있는 것들 중 scene text spotting 부분을 보면 맨 앞에 text의 센터 좌표가 나오게 되고 그 다음 text가 나오구요, 이게 다음 text에 대해 계속 이어져 나오는 식입니다.
본 InstructOCR은 VQA task에도 적용할 수 있는 모델인데요, 그림처럼 *what number is on the top sign?*이라는 질의가 들어오게 되면 이 질문을 마찬가지로 text encoder를 통해 인코딩한 후 그에 대한 답을 sequence로 생성하게 됩니다.
Instructions Generation
모델 설명은 이쯤 하고 학습에 필요한 instruction 생성에 대해 살펴보도록 하겠습니다. 현존하는 OCR 어노테이션은 location과 recognition 정보로 구성이 되어있습니다. 본 논문에서는 Instruction을 구성할 때 드는 cost를 줄이고자 이 annotation을 사용하여 automated processing 방식을 사용하여 instruction을 생성하도록 하였습니다.
각 단어는 첫 문자가 대문자인지 혹은 어떤 특성 문자를 포함하고 있는지 등등의 여러 속성으로 나눠볼 수 있습니다. 여기서는 10가지 타입의 템플릿을 구성했는데

{N}, {C}, {Word}에 들어갈 적당한 단어 숫자 문자를 랜덤으로 구성하여 최종 instruction이 완성되는 식입니다. 이때 언급하고 싶은 부분이 Instruction을 사용할 때 사람 자연어를 사용했다는 점입니다. 이런 연유는 다음의 3가지 이유 때문입니다. 먼저, (1) 여기서의 instruction에는 랜덤 숫자나 문자가 포함되어 있기 때문에 다른 연구에서처럼 고정된 indicator나 특정 task에 적합한 prmopt를 사용하기보다는 필요에 따라 새로운 조건으로 만들 수 있기 때문입니다. (2) 두 번째로는 사람 자연어를 사용하게 됨녀 대규모의 corpora에서 사전 학습된 BERT의 가중치를 사용함으로써 모델이 instruction 의미를 이해하는데 도움이 될 수 있기 때문입니다. (3) 마지막으로는 사람 자연어 instruction 기반의 pre-training을 하게 되면 spotting이외에도 Visual Question Answering(VQA)와 같은 다른 다운스트림 task로 확장하기 용이하기 때문입니다.
모델 학습을 할 때 들어가는 instruction이 어떻게 생성되는지 살펴봐야겠죠. 우선 10개의 템플릿 중 하나로 instruction이 랜덤하게 선택이 되게 되며, 이에 따라 각 데이터 x_i는 {c_i, s_i, t_i}로 표현이 됩니다. 여기서 c_i는 OCR 모델이 수행하게 될 instruction, s_i는 원본 영상, t_i는 instruction에 따른 정답 text sequence입니다.
원본 영상에는 원래 여러 text instance t’ = {t’_0, t’_1, t’_2, … , t’_{n-1}}이 존재하게 되겠죠. 이때 여러 instruction에 따라 어노테이션을 필터링하여 t={t_0, t_1, …, t_{m-1}}을 구성하게 됩니다. 예를 들어 길이가 3인 단어만 찾아라는 instruction이라면 원본 영상에 있는 모든 text들 중 길이가 3인 것들만 선택하여 정답 text를 구성하는 것이죠. 이를 통해 정리하자면 모델의 목표는 입력 영상 s_i와 instruction c_i를 기반으로 instruction에 맞는 text t_i를 생성하는 것입니다. 학습이 끝난 후 실제 inference 단에서는 모든 text를 인식하는 것이 원래 spotting의 목적이기 때문에 instruction을 “Recognize all text”로 하여 사용하게 됩니다.
Loss Function
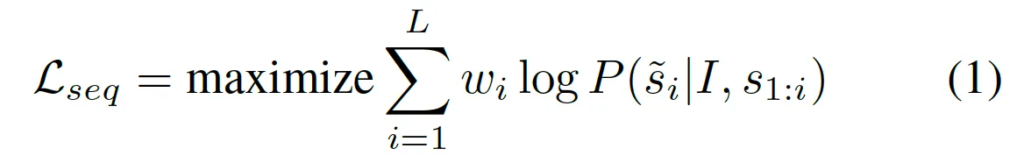
마지막으로 loss function에 대한 설명입니다. 이 InstructOCR은 학습 목표가 token을 prediction하는 것이기에 cross entropy loss를 사용하였습니다. 위 식1에서 I는 입력 영상이구요, s는 입력 sequence, \tilde{s}는 output sequence이고 L은 sequence 길이에 해당합니다.
3. Experiments
실험은 크게 Scene Text Spotting 태스크와 Scene Text에 대한 VQA로 구성됩니다.
3.1. Comparison with Scene Text Spotting Methods
기존 spotting 방법론은 Bounding box 기반과 point 기반 방법론으로 나뉩니다. 이 중 InstructOCR은 SPTS라고 하는 point 기반의 방법론의 decoder를 가져와 사용했으므로 point 기반 방식에 해당을 합니다.
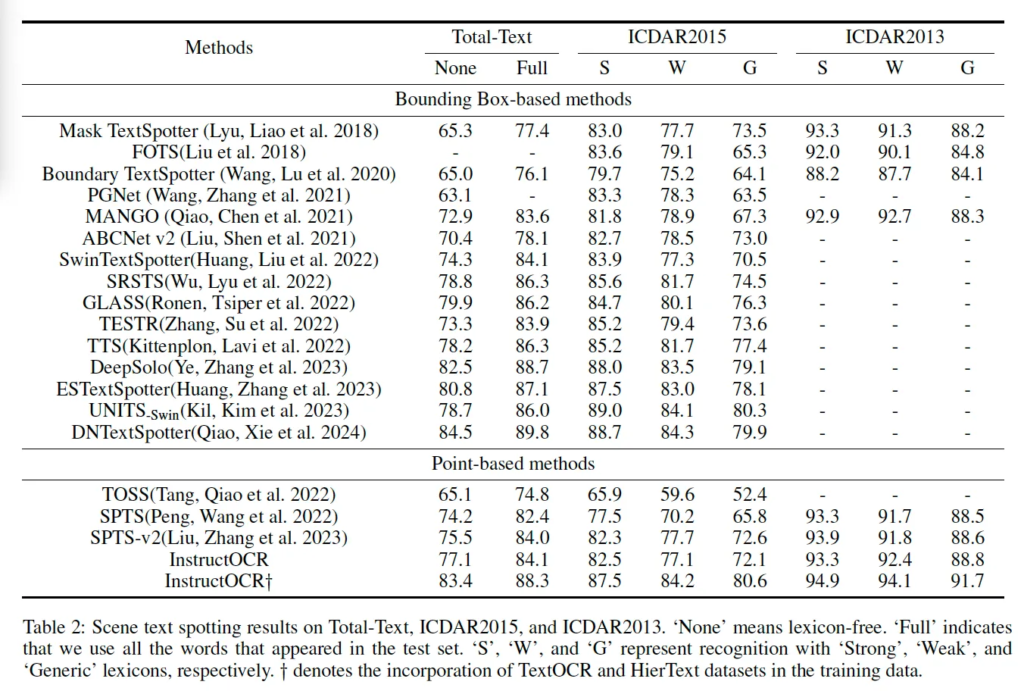
위 table에서 구분선이 그어져 있는데 위쪽이 bounding box 기반의 방법론들이고 아래쪽이 point 기반 방법론들인데 보시면 point 기반 방법론은 TOSS, SPTS, SPTSv2 정도만 존재합니다. 본 논문에서 제안된 InstructOCR과 다른 poitn 기반 방법론들과 비교해보면 SPTSv2와 유사하거나 약간 더 좋은 성능을 보입니다. 이는 사람 자연어 instruction을 사용하여 text 이해도를 높이는 것이 spotting에 도움이 된다는 것을 시사합니다. 또, bounding box 기반 방법론들과 비교해보면 InstructOCR은 이 방법론들과 비슷한 성능이거나,, 혹은 몇보다는 더 좋은 성능을 보이기는 하지만 그래도 약간 떨어지기는 합니다..
3.2. Applicability to Scene-Text VQA
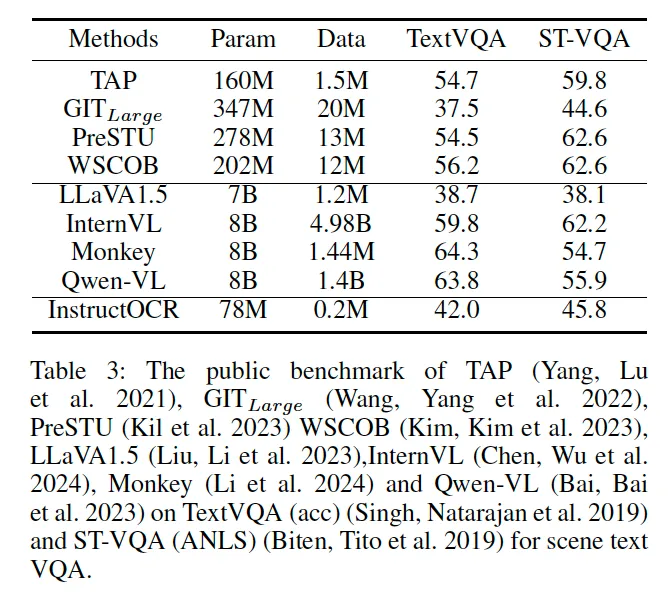
이 부분에서는 InstructOCR이 scene text spotting 뿐만 아니라 scene text VQA에도 적용될 수 있음을 보여주는 실험입니다. 기존 scene text VQA 모델들은 OCR을 별도로 수행한 후에 그 결과를 VQA 모델에 입력하는 방식으로 동작하는데, InstructOCR은 OCR과 VQA를 한번에 통합할 수 있다는 구조를 가진다는 점에서 차별적이라고 보면 되겠습니다.
실험 테이블을 보면 InstructOCR은 TextVQA에서 42%, ST-VQA에서 45.8%의 성능을 보였습니다. 사실 다른 모델들 TAP이나 GITLarge, PreSTU, WSCOB 등과 비교하면 성능이 무척 떨어지기는 합니다만 저자는 InstructOCR이 78M이라는 비교적 작은 모델 크기와 0.2M 정도의 데이터셋만을 사용했다는 점에서 효율성이 뛰어나다는 점을 어필하고 있습니다.
결론적으로 InstructOCR은 단순 scene text spotting 모델이 아니라, scene text VQA와 같은 복합적인 language-vision task에도 적용 가능하다는 점을 증명한 부분이라고 보면 되겠습니다.
3.3. Ablation Studies
마지막으로 ablation study 살펴보고 마무리하도록 하겠습니다.
Impact of Module Integration
먼저 제안된 여러 모듈의 효과를 분석하는 실험입니다.
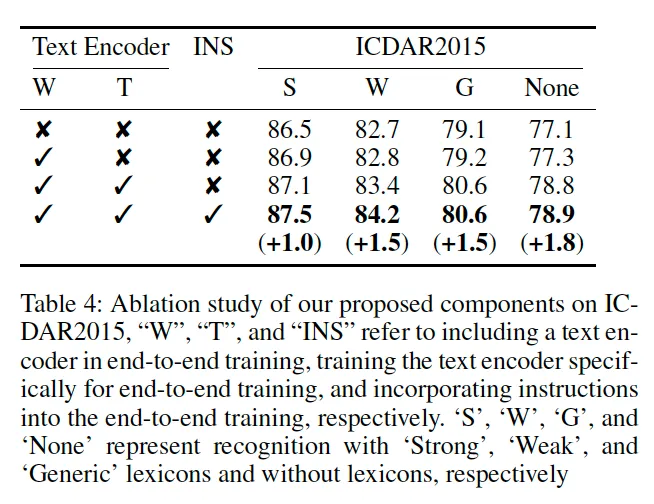
먼저 모델에 있는 text encoder의 영향을 분석합니다. 구체적으로 Text encoder 없이 학습한 모델과, 텍스트 인코더를 포함하되 froze된 상태로 둔 모델의 성능을 비교합니다. 표를 보시면 text encoder가 없을 때보다 있는 경우, 이를 training했을 때 freeze했을 때보다 더 성능이 좋아짐을 확인할 수 있습니다. 또, Ins라고 하여 최종적으로 instruction이 추가됐을 경우 최종적으로 성능이 더욱 개선됨을 보입니다.
Figure 5에서는 human language instruction을 추가했을 때 recognition 결과과 정확애진 예시들을 보여줍니다.

안녕하세요! 좋은 리뷰 감사합니다.
Instruction을 어떻게 설계하느냐에 따라 성능이 많이 달라질 것으로 보이는데, 이 저자가 설계한 10가지의 템플릿 중 일부만 사용한다던가, 구성을 다르게 한다던가 했을 때의 성능 변화를 보는 실험은 없었나요? 또 사람의 자연어 지시를 사용한 이유를 본문에 나열해주셨는데 고정된 indicator나 특정 prompt를 사용하는 경우는 어떤 경우인지 궁금합니다.
감사합니다.
댓글 감사합니다.
1. 10가지 템플릿 중에 일부만 사용하거나, 구성을 다르게 한 경우에 따른 성능 변화를 다룬 ablation study는 없습니다.
2. 고정된 indicator를 사용하는 방식으로는, 모델이 어떤 task를 수행할 지 미리 정의한 숫자나 토큰으로 알려주는 방식을 예로 들 수 있겠으며, 특정 prompt를 사용하는 경우는 자연어로 된 indicator를 고정해서 사용하는, 예를 들어 ‘Read the text in the image’ 와 같은 하나의 고정된 prompt만을 사용하는 경우입니다.
안녕하세요 윤서님, 좋은 리뷰 감사합니다.
text spotting 이라는 태스크 자체에 대한 이해도가 조금 떨어져서,, 혹시 평가지표가 어떻게 되는 건가요? 실험 테이블의 Lexicon이라는 것도 궁금합니다!
또한 Instruction 초기 구성 자체가 모두 Recognize, 혹은 Text 라는 단어로 설명이 정의되는 것으로 보아 pre-training 후 편향되는 문제도 있을 것 같다는 생각이 듭니다. 그래서 VQA 다운스트림 태스크로 넘어갔을 때도 확장성이 좋다는 3.2절의 말에 조금은 의문점이 생기는데요. 사실 Param수와 Data수가 적어졌다고 하나 성능이 다른 방법론에 비해 꽤나 낮은 것이 이 bias 때문이 아닌가 싶긴합니다. 이것에 대한 저자들의 고찰이 있는지, 혹은 윤서님의 생각이 궁금합니다.
감사합니다.
댓글 감사합니다.
1. Text spotting의 평가 지표는 f-measure을 사용합니다. 실험 테이블에서 언급되는 lexicon의 경우에는 쉽게 생각하면 단어 사전이라고 볼 수 있는데요. 모델이 최종 recognition까지 했을 때 예측한 text가 나올텐데, 이 text에 대해서 바로 평가하는 것이 table에 적혀 있는 None(lexicon 사용 X)이며, lexicon(단어 사전) 내에서 예측과 유사한 단어를 하나 뽑아 정답 라벨과 비교를 통해 성능을 측정하는 것이 Full에 해당합니다. 또 ICDAR13, 15의 경우에는 S, W, G라고 적혀져 있는데 이들 각각은 strong, weak, generic이라고 하여 lexicon에 어디까지의 단어를 포함할 것인지 정도 차이라고 보시면 됩니다.
2. 저자의 고찰은 딱히 담겨있지 않구요. 재찬님이 언급해주신 것처럼 instruction 템플릿이 전부 recognizer, ~ text ~ 로 시작하기 때문에 모델이 학습하면서 그냥 텍스트를 읽는 task라고 학습하게 될 것이고. 결국 spotting쪽으로 좀 bias된 모델이 나오기에 VQA에서 낮은 성능을 보인게 아닌가 싶습니다. 물론, 본 논문에서는 어느정도 VQA task도 수행 가능하다는 점을 어필하고 싶은 것으로 보입니다.
안녕하세요 윤서님 좋은 리뷰 감사드립니다.
리뷰를 읽는 과정에서 궁금했던 부분에 대해서 질문을 드리고자 답글드립니다!
학습 단계에서는 다양한 instruction 템플릿을 활용해서 모델이 여러 조건에 따라 텍스트를 인식하도록 학습했다고 이해했습니다.
그리고 리뷰에서 “학습이 끝난 후 실제 inference 단에서는 모든 text를 인식하는 것이 원래 spotting의 목적이기 때문에 instruction을 “Recognize all text”로 하여 사용하게 됩니다.” 라고 말씀 하셨는데,
학습 단계에서는 다양한 instruction을 사용하고 실사용할 땐 Recognize all text”만 사용하는 것인지 궁급합니다! 만약 맞다면 학습 땐 다양한 instruction을 사용했는데, 실사용할 땐 결국 “Recognize all text”만 쓰는 거라면 학습의 다양성이 inference에도 도움이 되는 건지 궁금합니다.
댓글 감사합니다.
다양한 instruction만을 사용하면서 모델의 representation을 향상시켜 결국 일반화 능력을 키우기 위함이지 않을까 싶습니다. 물론, table4의 ablation study를 보면 이 instruction을 추가했을 때의 성능 향상은 엄청 드라마틱한 건 아니기도 합니다.