Abstraction
Affordance를 인식하고 pose를 추정하는 것은 로봇의 조작에 중요하며, 이 둘을 융합하므로써 작업과 연관된 affordance를 잡기 위한 pose를 생성해내므로써 로봇의 조작 능력이 개선될 수 있습니다. 기존 연구들은 사전에 정의된 affordance로 제한된다는 한계로 실제 적용에 어려움이 있었고, 해당 논문의 저자들은 3D 포인트 클라우드에 대하여 새로운 language-conditioned affordance-pose joint learning 방식을 제안합니다. 물체의 3D point cloud가 주어졌을 때, 이에 대하여 open-vocabulary affordance detection을 수행하고, 임의의 affordance 영역에 대하여 language-guided diffusion 모델을 적용하여 6D Pose를 생성하게 됩니다. 또한, 저자들은 해당 모델 학습을 위한 새로운 데이터 셋을 제안합니다. 실험을 통해 제안한 방식이 open-vocabulary에서 효과적으로 작동하며, 다른 방법론보다 성능이 크게 개선되었음을 확인하였으며, 실제 로봇에도 효과적임을 보였습니다.
- 사이트: https://3dapnet.github.io/
- 코드: https://github.com/Fsoft-AIC/Language-Conditioned-Affordance-Pose-Detection-in-3D-Point-Clouds
Introduction
로봇의 응용 관점에서 affordance를 찾고 pose를 추정하는 것은 중요합니다. 먼저 물체의 affordance를 이해한다는 것은 로봇이 주어진 환경에서 물체가 제공하는 기능적 가능석을 파악하는 것으로, “컵”의 경우 손잡이는 “잡다”, 통 부분은 “담다”와 같이 물체이 특정 부분이 가진 기능적인 가능성을 이해한다는 것 입니다. 또한, pose 추정은 물체의 정확한 위치와 자세를 인식하는 것으로, 물체를 조작하고 상호작용 하기 위해 필수적인 정보입니다. 따라서 affordance detection과 pose estimation을 융합하면 로봇의 환경에 대하여 포괄적으로 이해하고 조작할 수 있습니다. 그러나 affordance에 대한 정보는 정해져 있지 않기 때문에 텍스트와 같은 추가적인 정보가 필요하므로 최신 연구들은 대부분 이 두가지 task를 분리하여 연구하였습니다.
depth 카메라의 사용이 확대되며 3D point cloud에서 affordance detection이 가능해졌으나, supervised 방식으로 접근하여 사전에 정의된 affordance label에 한정된다는 한계가 존재합니다. 이러한 문제를 해결하고자 최근 language 모델을 사용하여 open-vocabulary로 확장한 연구가 나왔으나, affordance 대응 영역에 대한 6D pose를 고려하고 있지는 않습니다. 일부 연구들은 affordance와 6D pose를 함께 고려하지만, 여전히 사전 정의된 affordance로 한정되어있습니다.
해당 논문은 affordance detection과 6D pose estimation을 함께 고려하는 방식을 제안합니다. 사전에 정의되지 않은 affordance가 텍스트 쿼리가 주어졌을 때, 이에 해당하는 영역을 인식하고, pose를 생성하는 것을 목표로합니다. 이를 위해 먼저, 3D Affordance-Pose 를 함께 학습할 수 있는 데이터 셋, 3DAP dataset을 제안합니다. 데이터 셋은 3D 포인트클라우드와 자연어 형태의 affordance label, 6D Pose 집합이 함께 주어집니다. 그 다음, language-driven affordance detection 브랜치와 pose estimation 브랜치로 이루어져 두 가지를 함께 학습하는 프레임워크를 제안합니다. pose estimation 브랜치는 3D 포인트크라우드와 affordance text가 condition으로 주어졌을 때 diffusion 모델을 이용하여 6D Pose를 생성하게 됩니다. 저자들은 diffusion 모델을 사용한 이유에 대해 다양한 모달리티의 데이터에 대하여 좋은 성능을 보였으며, 6D Pose Estimation에서는 아직 제한적으로 적용되었기 때문이라고 이야기합니다. 저자들이 제안한 프레임워크는 end-to-end로 학습됩니다.
해당 논문의 contribution을 정리해보면
- affordance와 6D Pose를 함께 학습하기 위한 3DAP datset 제안
- affordance와 6D Pose를 함께 학습할 수 있는 3DAPNet 제안
- 다양한 실험을 통해 3DAPNet를 검증하고, real-world에서 효용을 입증
3DAP Dataset
저자들은 affordance detection과 6d pose estimation을 함께 수행하기 위해 3DAP(3D Affordance-Pose) dataset을 데이터 셋 구축하였으며, 이를 위해 반자동 파이프라인을 제안합니다.
< Point Cloud Collection >
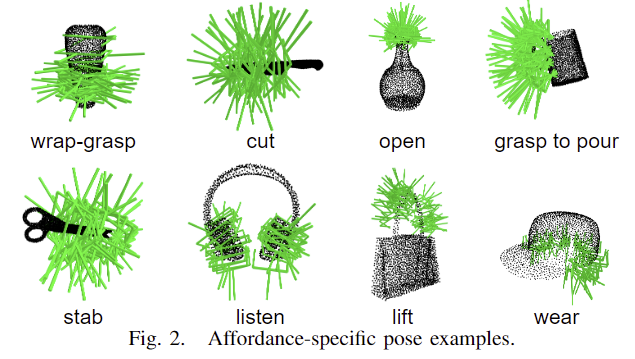
먼저, affordance 정보가 annotation 되어있는 3D AffordanceNet 데이터 셋(아래의 그림으로 예시 확인 가능)에서 3D 포인트클라우드 object를 수집합니다. 각 object는 단일 객체이며, 2048개의 점들로 구성되며, 좌표들은 0~1 사이로 정규화되어있습니다. 저자들은 실제 물체를 표현하기 위해 객체에 대한 3D bounding box에서 가장 긴 변이 5~30 cm가 되도록 배율을 조정하였다고 합니다. 물체들은 칼, 가위와 같이 일상생활에서 접하기 쉬운 물체들입니다. affordance label에 대해서 자연어 설명을 적용하여 open-vocabulary affordance detection이 가능하도록 하였다고 합니다.

해당 논문에서는 어떻게에 해당하는 내용이 명시되어있지 않아, 데이터를 확인해보았습니다. 결론적으로, affordance label을 모두 자연어로 확장한 것이 아니라 일부 추가하거나 변형을 준 것으로 보입니다. (아래의 예시 중, 170번 인덱스에 해당하는 Mug는 “grasp to pour”라는 식으로 자연어로 변화가 되었지만, 바로 아래 110번 인덱스는 단순히 “grasp”라 되어있는 것을 확인하실 수 있습니다. 각각의 원래 affordance 정보는 위의 그림에서 확인하실 수 있습니다.)

< Pose Collection >
수집된 포인트클라우드에 대하여 가능한 pose 후보를 생성하기 위해 6D GraspNet을 활용합니다. 모델을 통해 예측을 수행한 뒤, score가 높은 1000개의 pose를 선정하였으며, 그후, 각 aoffordance에 대응되는 pose들만을 수동으로 선택하였다고 합니다. 예를 들어 “open”이라는 affordance가 주어질 경우, 병뚜껑에 접촉이 되도록 하는 pose들을 선택하는 방식이며, 이렇게 하여 28,000개의 pose를 포함하였다고 합니다. 아래의 그림은 이에 대한 예시입니다.
Affordance-Pose Joint Learning
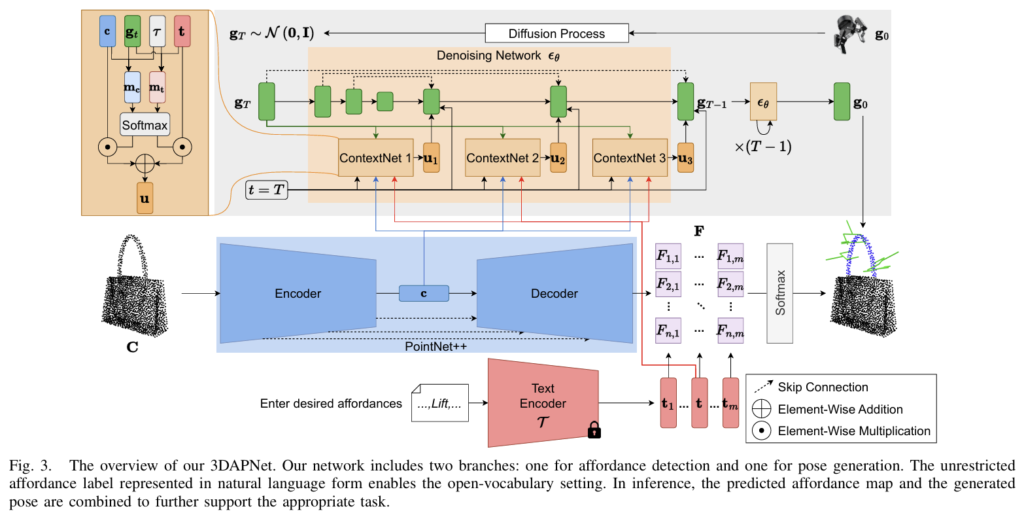
<Problem Formulation>
해당 논문은 affordance와 pose를 함께 학습할 수 있도록 3DAPNet을 제안합니다. 3DAPNet은 3D 포인트클라우드 \mathbf{C}=\{p_1,p_2,…,p_n\}와 자연어 텍스트로 된 m개의 임의의 affordance labels을 입력으로 받습니다. 이후 3DAPNet을 통해 affordance map \mathbf{A}=\{a_1,a_2,…,a_n\}과 해당 영역에서 그리퍼의 pose 집합 m개를 생성합니다. 6D Pose [\mathbf{g_{qu}}, \mathbf{g_{tr}}]로 이루어지며, 이는 각각 rotation을 쿼터니안으로 표현한 단위벡터와 translation 벡터를 의미합니다. 3DAPNet의 전체적인 파이프라인은 위의 그림으로 확인하실 수 있습니다.
1. Open-Vocabulary Affordance Detection
open-vacabulary affordance detection을 위해 입력 포인트클라우드 \mathbf{C}를 PointNet++모델에 입력하여 n개의 포인트에대한 feature vector \mathbf{P}_1, \mathbf{P}_2, …,\mathbf{P}_n 를 추출합니다. m개의 affordance labels는 text encoder를 통과시켜 text embeddings \mathbf{t}_1, \mathbf{t}_2, …,\mathbf{t}_n 를 생성합니다.
open-vocabulary affordance detection을 위해 저자들은 코사인 similarity 함수를 이용하여 text embeddings와 포인트클라우드에 대한 feature vector 에 적용하여 두 데이터 사이의 의미론적 관계를 계산합니다. 이렇게 구한 유사도 F_{i,j} \in i=1,…,n , j=1,…,n는 학습을 통해 특정 affordance label과 의미론적으로 관련된 포인트의 feature를 생성하도록 PointNet++을 학습시키며, 이후 각 포인트들에 대한 출력은 아래의 식(2)으로 계산됩니다.
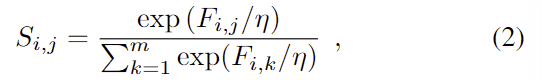
- \eta: 학습된 파라미터
또한, 학습에 사용되는 loss fuction은 다음과 같습니다.
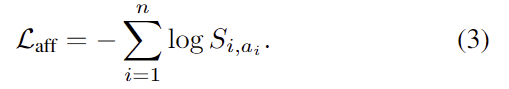
2. Language-Conditioned Pose Generation
저자들은 diffusion 모델에 affordance에 해당하는 pose를 생성하도록 적용하였다는 점에서 컨트리뷰션이 있음을 강조하며, 포인트클라우드 뿐만 아니라 affordance에 대한 text도 함께 입력으로 사용하였습니다.
<Forward Process>
데이터셋으로부터 pose \mathbf{g}_0가 주어졌을 때, 점진적으로 가우시안 노이즈를 T번 추가하여 sequence \mathbf{g}_1, \mathbf{g}_2, …, \mathbf{g}_T를 만들어냅니다. 각 단계의 노이즈 적용은 q(\mathbf{g}t | \mathbf{g}{t-1})=\mathcal{N}(\sqrt{1-\Beta_t}\mathbf{g}_{t-1}, \Beta_t\mathbf{I})로 정의됩니다.
<Reverse Process>
reverse process는 forward process에서 추가된 가우시안 노이즈를 점진적으로 denoise하여 원본 데이터를 복원하는 과정입니다. 이때, 포인트클라우드의 feature \mathbf{c}와 affordandce label의 text embedding \mathbf{t}를 condition으로 사용합니다. 가우시안 노이즈에서 시작하여 T step에 걸쳐 데이터를 복원하며, 해당 과정에 역확률 분포 q(\mathbf{g}_{t-1} | \mathbf{g}_t, \mathbf{c}, \mathbf{t})를 신경망 \mathbf{\epsilon\theta} ( \mathbf{g}_t, \mathbf{c}, \mathbf{t}, t)로 계산합니다. \mathbf{\epsilon}은 학습을 통해 real과 noise 사이의 오차를 최소화 하는 방식으로 학습이 되며 loss function은 아래와 같이 정의됩니다.
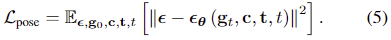
pose 생성에 대한 다양성과 품질 사이의 균형을 맞추기 위해 랜덤하게 condition \mathbf{c}와 \mathbf{t}를 drop 하여 unconditioinal에 대한 확률도 동일 네트워크로 함께 학습합니다.
denoising 네트워크 \mathbf{\epsilon}_\theta는 U-Net 구조를 가지고 있으며, t 시점의 노이즈가 포함된 pose \mathbf{g}_t를 3개의 연속적인 donwscaling MLPs에 입력합니다. 이후 3개의 up-scaling MLPs를 적용하여 원본 데이터를 복원하며, 이전 단계의 출력을 포함하는 skip-connection 구조를 가지고 있습니다. 또한, t 시점에서 계산된 time embedding \tau와 포인트클라우드 정보 및 affordance label 정보를 모두 통합하여 ContextNet 모듈을 통과시켜 컨텍스트 \mathbf{u}를 구합니다. ContextNet은 포인트 클라우드와 affordance label 텍스트로부터 MLPs와 softmax를 통과시켜 point cloud influence mask \mathbf{m_c}와 text influence mask \mathbf{m_t} 동일한 크기의 influence mask를 구한 뒤, 포인트와 text에 각각 요소곱을 적용하여 구합니다.
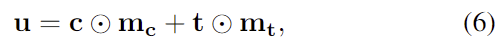
<Pose Sampling>
모델 학습이 끝난 뒤, 가우시안 노이즈에 reverse process를 적용하여 pose를 샘플링합니다. 이 과정은 T에서 0 시점까지 진행하며, 아래의 식을 적용합니다.
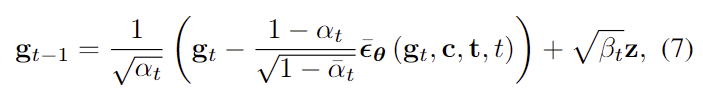
- t>1 일 경우 \mathbf{z}~\mathcal{N}(\mathbf{0,I}), t≤1일 경우 \mathbf{z}=\mathbf{0}: t가 1보다 클 경우 정규분포에서 샘플링된 노이즈, 나머지는 0
\mathbf{\bar{\epsilon}_\theta}(\mathbf{g}_t,\mathbf{c,t},t)는 아래의 식으로 계산됩니다.
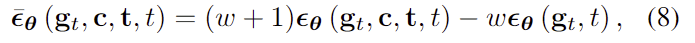
- w: 가중치(해당 논문에서는 0.2로 설정)
- \mathbf{ \epsilon_\theta}(\mathbf{g}_t,t): 포인트클라우드와 affordance label이 condition으로 사용되지 않았을 때 예측된 노이즈
<Training and Inference>
전체 loss function은 \mathcal{L}=\mathcal{L}{aff}+\mathcal{L}{pose}로 정의되며, 학습 과정에는 CLIP의 text 인코더를 freeze하여 사용하였다고 합니다. diffusion 모델은 T=1000으로 설정하고, forward process에서 상수 \Beta는 \Beta_1=10^{-4}에서 \Beta_T=0.02까지 선형적으로 증가하도록 설정하였다고 합니다. 저자들이 제안한 3DAPNet은 affordance detection과 2000개의 pose를 생성하는 과정에 180ms가 소요된다고 합니다.
Experiments
3DAP dataset에서 학습된 3DAPNet의 효과를 입증하기 위한 실험을 진행합니다. 먼저 기존 연구들과 비교한 뒤, 정성적 결과를 통해 연구에 대한 일반화 가능성을 검토합니다. 이후 ablation study를 수행한 뒤, 실제 로봇에 적용하여 제안한 프레임워크에 대한 검증을 수행합니다.
1. Comparison with other baselines
- Baseline
- 3DAPNet을 기존 연구인 6D-TGD, OpenAD, 6D-GraspNet와 비교합니다. 이때, OpenAD는 pose를 추정하지 않는 방식이며, 6D-GraspNet은 affordance를 고려하지 않는 방식입니다. 6D-GraspNet은 open-vocabulary 설정에 맞도록 조정하여 재학습을 수행한 것으로 보입니다.
- Metrics
- affordance detection 평가에는 mIoU와 Acc(모든 포인트에 대한 accuracy), mAcc(모든 affordance에 대한 accuracy)를 적용합니다.
- pose generation에 대한 평가에는 mESM(생성된 poses와 GT poses의 유사도로, 코드를 보니 가장 작은 l2 distance들의 평균을 구합니다)와 mCR(생성된 pose가 ground truth pose 공간을 얼마나 잘 커버하는지 평가하는 지표로, 코드를 보니 GT poses에 대해 최소 하나의 pose라도 distance가 0.2 이내인지를 확인하여 비율을 계산합니다. )를 적용합니다.
<Comparison with baseline>
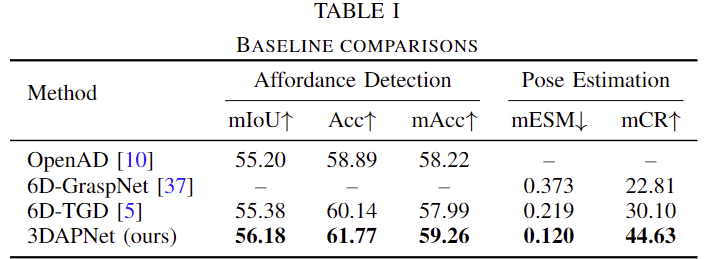
Table 1은 다른 방법론들과 비교한 결과로, 다른 방법론들과 비교했을 때, 저자들이 제안한 3DAPNet이 모든 지표에서 가장 좋은 성능을 보였습니다. 이를 통해 affordance detection과 pose estimation 모두 성능이 크게 개선되었음을 검증하였습니다.
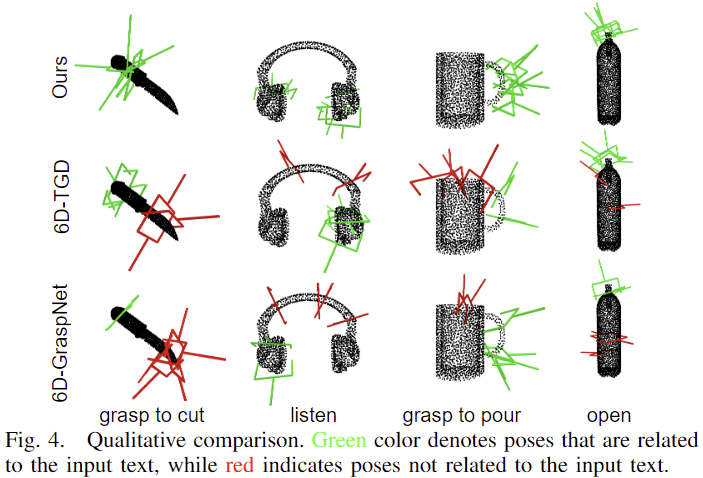
3DAPNet이 생성한 pose에 대한 정성적 결과입니다. 빨간색은 affordance에 대응되지 않는 pose들을 나타내는 것 으로, 저자들의 방식은 affordance 정보를 고려한 pose를 생성하는 데 반해 기존 연구들은 전체적인 영역에서 pose를 생성하고 있습니다.
<Generalization to Unseen Affordances>
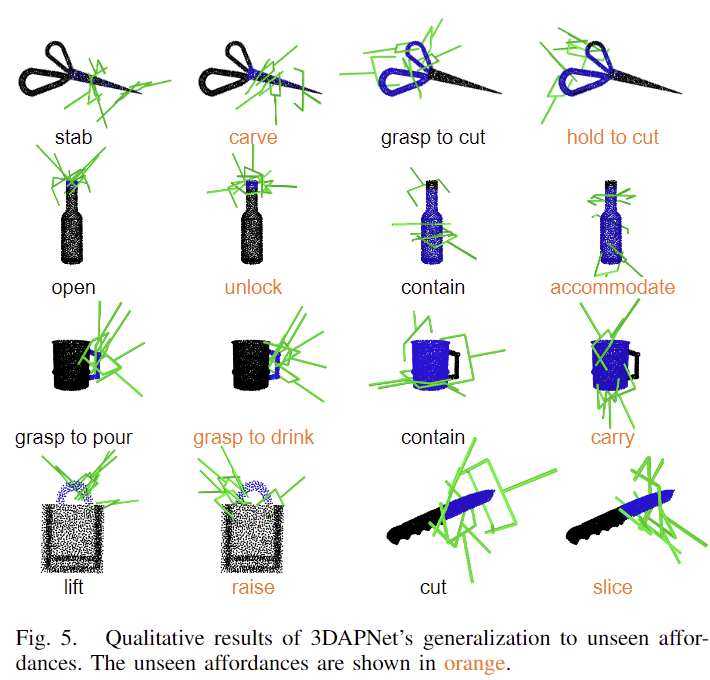
3DAPNet이 Unseen Affordance에 대하여 일반화가 가능한지를 확인하는 실험 결과입니다. 주황색에 해당하는 affordance 정보는 학습에 사용되지 않은 affordance label로 유의미한 영역에 활성화가 된 것을 확인할 수 있습니다. 해당 실험 결과를 보며 “cut”과 “slice”와 같은 영역이 잘 활성화가 되어있지만 해당 affordance는 그리퍼 pose가 생성되는 것이 유의미한지에 대한 의문이 생기긴 합니다. 물론 “grasp to drink”와 “hold to cut”과 같은 영역은 잘 활성화가 되었지만, cut이 주어졌을 때도 grasp to cut에 해당하는 영역이 활성화가 되어야하지 않을까 하는 생각이 들었습니다.
<Generalization to Unseen Objects>
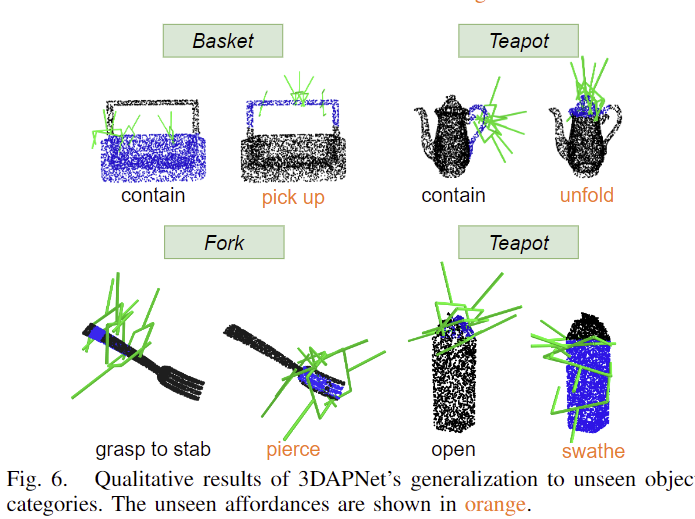
저자들은 unseen object로 확장 실험을 진행하였습니다. 해당 물체들은 학습에 사용하지 않았던 물체들로, 학습에 사용한 affordance label과 새로운 affordance label에 모두 유의미한 영역이 활성화되고 이에 대응되는 pose가 잘 생성된 것을 확인할 수 있습니다.
<Ablation Study>
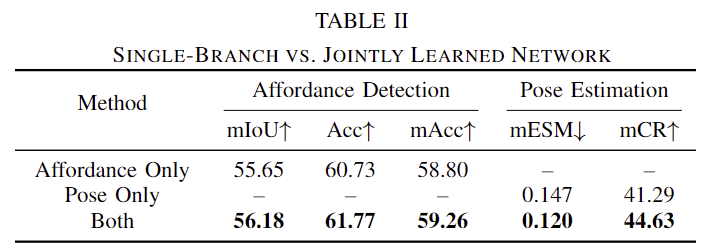
Table 2는 3DAPNet의 두 브랜치를 각각 실험한 결과를 함께 리포팅한 것입니다. 두 브랜치를 함께 학습하는 것에 성능 개선에효과가 있음을 실험적으로 확인하였습니다.
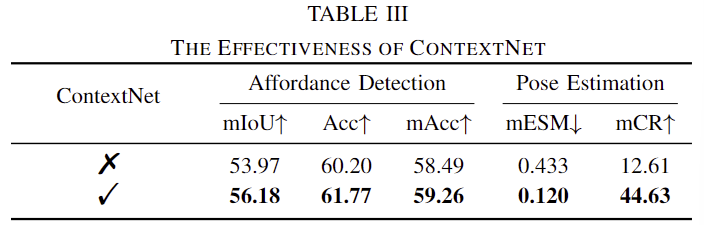
Table3은 ContextNet에 대한 ablation study를 수행한 결과입니다. ContextNet을 통해 성능이 개선되었다는 것도 실험적으로 보였습니다.
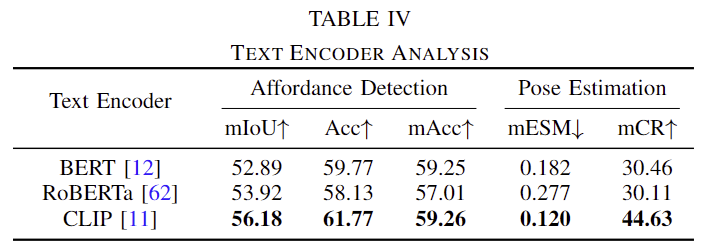
Table 4는 text encoder에 대한 변경 실험을 수행한 결과입니다. CLIP을 사용하는 것이 가장 좋다는 것을 확인할 수 있씁니다. 이에 대해 저자들은 CLIP이 language-vision에 대한 이해가 뛰어나기 때문인 것으로 분석합니다.
<Robotic Demonstration>
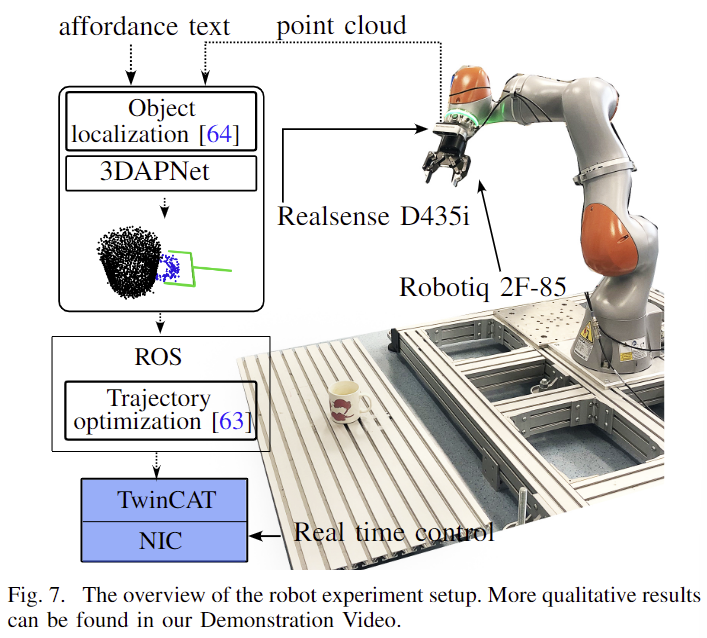
마지막으로 실제 로봇을 이용한 검증 실험 결과입니다. 센서로는 Realsense D435i를 사용하였으며, 3DAPNet을 통해 affordance pose를 생성하여 ROS 모듈로 넘겨 경로를 생성한 뒤 실제 로봇을 통해 조작을 수행합니다. 이에 대한 데모 영상은 함께 첨부해두었습니다.
<Discussion>
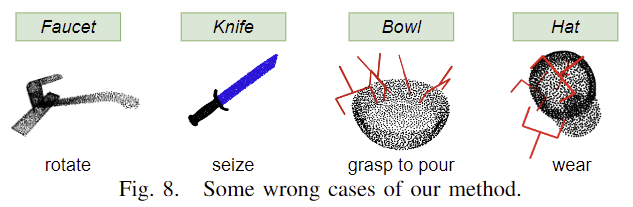
저자들은 3DAPNet의 한계를 이야기합니다. 왼쪽의 2개 예시는 unseen affordance에 대한 실패 케이스, 오른쪽 2개는 잘못된 pose를 생성한 경우입니다. 이러한 예시를 통해 모든 경우에 잘 작동하는 게 아님을 이야기하며, 추가로 데이터셋이 하나의 물체를 대상으로 하고 있어 여러 물체가 존재하는 경우에는 성능을 보장할 수 없다는 한계를 이야기합니다.
승현님 좋은 논문 리뷰 감사합니다.
해당 기법은 생성형 AI인 Diffusion model을 통해 범용성을 꾀하고자 했던 것 같습니다.
허나, 리뷰 마지막에 작성해주신 바와 같이 보지 못한 객체에 대해서는 잘 작동하지 못하는 결과를 보여줍니다.
이러한 결과를 토대로… 해당 연구도 6D pose estimation과 동일한 흐름으로 발전하지 않을까란 생각이 듭니다.
즉, 학습 데이터에 의존 없이 ~ 3D 모델에 의존하지 않는 연구로요.
승현님도 아시겠지만… multi-modal LLM이 주어진 쿼리를 토대로 필요한 작업으로 해석 가능할테고 이를 기반으로 2차원 영역에서 affordance를 구할 수 있다고 생각이 듭니다. 전 해당 영역을 occam’s LGS이 수행한 것과 같이 3D 영역에 여러 뷰를 기반으로 uplifting 수행해 해당 영역에 대한 3차원 모델을 추출하고 이를 기반으로 해당 3차원 영역을 super-quadric으로 단순화시켜 이를 기반으로 파지 위치를 찾는 것도 좋은 방법이라고 생각합니다.
어떻게 생각하시나요…?
질문 감사합니다.
affordance grounding에서 3D point cloud를 이용하는 연구와 2D 데이터에 대하여 인식을 진행한 뒤, 이를 3D 로 넘기는 두가지 흐름이 존재하는 것으로 알고있습니다. 저도 태주님이 이야기하신대로 굳이 3차원 point cloud로부터 affordance를 인식해야하나?하는 의문이 있고, 2D에서 먼저 유의미한 영역을 찾고 이를 3차원으로 올리는 것도 좋은 해결이 될 것 같습니다. 그러나 제가 이전에 리뷰했던 AffordanceLLM은 이미지로부터 생성한 pseudo depth map을 함께 이용하는 것이 affordance 인식 성능을 개선하는 데 효과가 있음을 보였고, 이러한 이유로 3D 정보 활용의 효과를 검증해보아야할 것 같다는 생각이 듭니다.
즉, 3D point cloud로 부터 affordance를 인식하고 garsping의 pose를 추정하는 방식과, 2D 이미지로부터 affordance를 인식한 뒤, 이를 3D로 올려 pose를 추정하는 것 중 어떤게 더 효과적인지에 대한 실험이 필요할 것 같습니다. 또한, super-qudric과 pose estimation 방식 중 어떤 게 더 잘 작동할지도 실험적으로 확인해볼 내용인 것 같습니다.
안녕하세요 이승현 연구원님. 좋은 리뷰 감사합니다.
본 논문을 기존에는 affordance만 고려하던 방법론을 pose까지 확장한 방법론으로 이해하였습니다. 물체의 영역 뿐만 아니라, 물체의 쓰임새(일종의 concept label로 이해했습니다)까지 예측해야하는 affordance task 자체로도 난이도가 높은데, pose까지 확장을 하는 방법이라니 신기합니다.
유사한 task 이더라도 task를 확장하는게 일반적으로 항상 성능 개선에 도움이 되지 않는것으로 알고있습니다. 또한, open-vocabulary detection이라면 사전에 정의된 3D Mask 등과 대조해야하는 일이 없으므로 6D pose와 같은 디테일한 이동 성질까지는 고려하지 않아도 되지 않는가 라는 의문도 듭니다.
위와 같은 task 확장에 대한 부정적 관점이 혹시 완전히 틀린 관점인지 승현님의 의견이 궁금합니다.
질문 감사합니다.
우선 저도 서로 다른 두가지 task를 함께 하는 것에 대해 우려가 있지만, 해당 논문은 각각의 task를 나누어 실행하는 기존 연구보다 개선된 성능을 보이며 실험적으로 입증하였으므로 문제가 없다고 생각하였습니다. 해당 테스크는 결국 real-world에서 로봇을 이용한 파지까지 수행하는 것이 목적이기 때문에 파지를 위한 그리퍼의 6D Pose를 추정하였고, 이러한 목적을 고려하였을 때 두 task를 함께 학습해 수 있지 않을까 합니다. 어찌보면 지능의 3요소인 인식, 추론/결정, 행동에서, 인지에 집중하던 연구흐름이 판단 및 행동으로 넘어가는 것에 아닐까 합니다.
안녕하세요, 좋은 리뷰 감사합니다.
데이터셋 수집에서 실제 물체를 표한하기 위해 객체에 대한 바운딩 박스에서 가장 긴 변을 최디 30cm가 되도록 배율을 조정하였다고 말씀해주셨는데, 침대와 문 같이 큰 물체들을 이렇게 임의로 배율을 조정하게 되면 pose를 추정하거나 후에 할 작업들을 생각해봤을 때 스케일에 대한 이슈가 발생하진 않을지 의문이 듭니다. 이에 대한 추가적인 언급이나 후처리는 없었을까요 ??
감사합니다.
좋은 질문 감사합니다.
침대와 같은 가구를 임의로 크기를 조정하게 되면 문제가 발생하지 않을 까 하였는데, 이에 대해 저자들은 따로 언급하고 있지 않습니다. 또한, 별도의 후처리 작업도 없습니다. 저자들은 동일한 네트워크를 이용하여 3D point cloud에서 자연어 설명애 대응되는 영역을 식별하기 위해 물체의 크기를 맞춘 것으로 보입니다. 하지만 건화님이 이야기하신 것 처럼 이를 이용한 후속 작업을 위해서는 별도의 후처리가 필요할 것 같으며, 추가로 물체 사이의 상대적 정보가 하나의 단서가 될 수 있을 지 확인해보는 것도 필요할 것 같습니다.
안녕하세요 승현님 리뷰 감사합니다.
Open vocabulary에서 Affordance 와 6D pose estimation을 동시에 수행하는 프레임워크 인 것 같은데요, affordance와 6d pose의 특성상? Diffusion 모델을 활용해서 진행한다고 생각하는데요, 제 지식 선에서는 diffusion이 정답에 맞게 복원해나가는 과정(?)이라고 알고있는데 가능한 여러 다양한 6d pose들을 생성하는 이유가 복원하는 과정에서 여러 경우가 생기는 것인지, 아니면 diffusion을 통해 복원된 경우가 여러 세트인 것인지 궁금합니다!!
질문 감사합니다.
pose를 예측한느 것을 diffusion 모델로 하고, affordance에 대해서는 3D 작업에 사용되는 PointNet++을 이용합니다. 또한, Fig 3는 데이터 셋의 pose 예시로, 하나의 물체와 affordance에 대해 많은 pose들이 포함되어있습니다. 또한, 복원 과정에서도 여러 6D Pose 예측값이 생기게 됩니다.
승현 연구원님 꼼꼼한 리뷰 감사합니다.
unseen affordance label에 대해서도 정확하게 affordance point를 찾고 로봇이 작업할 수 있는 그 지점에 대한 pose 추정까지 해서 실제로 구현된 것까지 모두 흥미롭게 읽었습니다.
아래는 읽으면서 궁금했던 부분들입니다.
Figure 5에 대한 설명으로 승현님께서 cut과 slice라는 label에 대해서 모델이 추정한 pose들이 과연 유의미한지와 grasp to cut에서와 같은 pose가 추정되어야 하지 않을까란 의문을 적어주셨는데요 해당 내용일 잘 이해가 되지 않았습니다. 한번 더 설명 부탁드려도 될까요?
그리고 해당 연구는 open vocabulary affordance detection도 가능하다고 하셨는데요 데이터셋에 나와있지 않은 shake같은 affordance label에 대해서도 수행이 가능 한 건가요?
감사합니다.
질문 감사합니다.
먼저, Figure 5에 대해 모델이 추정한 pose가 유의미한지에 대한 의문은, 예측된 그리퍼 pose로 물건을 파지한다고 했을 때, 물체의 무게 중심이나 표면 등의 영향으로 실제 물건을 파지할 수 있는 지에 대한 의문이였습니다. 또한, cut이 주어졌을 때도 grasp to cut와 동일한 영역의 pose가 적절하지 않을까라 생각한 이유는, cut이라는 행동을 물체 도구 관점에서 봤을 대, 칼 날 부분은 다른 물체와 작용이 이뤄져야 하는 부분이기 때문에, cut에 해당하는 영역에 활성화되는 것은 적절하지만, 이에 대한 pose는 손잡이 부분이 되어야하지 않을까 하는 의문이였습니다. 혹은 cut이라는 표현을 다 grasp to cut으로 바꾸는 것이 어떨까하는 것 입니다.
마지막으로, open vocabulary affordance detection가 가능하다는 것은 데이터 셋에 없는 shake도 affordance를 추정할 수 있다는 것이 맞습니다. 그러나, 해당 논문의 방법론의 일반화 성능이 뛰어나다고 하기는 어려운 상황이라, “shake”에 대해 정확히 인지가 가능하다고 확언할수는 없습니다. 연구가 더 필요하며, 데이터 셋에 없는 일부 affordance 라벨로도 확장이 가능함을 확인한 상황이라고 이해해주시면 될 것 같습니다.