이번 리뷰 논문은 3D Language Feature Splatting 기법에 대해서 다루고자 합니다. 제목 중 Occam이라는 용어가 보일 겁니다. 저 용어는 Occam’s Razor (오컴의 면도날)라는 단순의 미학을 의미하는 격언?에서 따온 말입니다. 즉, 기존 3DLF가 너무 복잡하게 수행되어져 왔다. 그냥 단순하게 해보자 라는 의미입니다. 실제로 저자는 시각-언어 특징에 대해 별도의 학습 없이 그대로 올리는 것 만으로도 충분한 성능을 보장 할 수 있음을 실험적으로 보입니다.

Intro
3D Language Field (3DLF)는 3차원 공간을 이해하기 위한 기법 중 하나로, CLIP과 SAM과 같은 시각-언어 기본 모델의 지식과 3차원 공간에 대한 정밀한 표현력을 보이고 있는 Novel View Synthesis (NVS)를 결합한 기법입니다. 특히나, 로보틱스 분야에서는 일반화된 객체 인지를 위해서 3DLF를 활용하는 움직임을 보이고 있습니다.
로보틱스와 같이 인지-판단-제어를 실시간으로 수행해야하는 분야에서는 추론 속도가 굉장히 중요합니다. 이러한 필요성으로 인해서 로보틱스 분야에서는 3DLF에 활용되는 NVS 중 빠른 추론 속도를 보이는 3D Gaussian Splatting (3DGS)를 활용한 기법들을 활용해 연구를 진행하고 있습니다.
그럼에도 불구하고 사실 3DGS를 이용한 3DLF들은 높은 추론 속도를 가지고 있지만… 새로운 장면 마다 데이터 전처리부터 새로 학습이 필요한 NVS의 한계로 인해 실제 로봇에 적용하기에 부적합한 프로세스를 갖추고 있습니다. 전반적인 학습 프로세스는 다음과 같습니다.
1. 로봇이 관측하는 장면에 여러 시점에서의 N 장의 시퀀스 영상 취득
2. 시퀀스 영상으로부터 재구성 수행 (e.g. COLMAP)
3. 재구성된 영상으로부터 NVS 학습
4. 시퀀스 영상으로부터 시각-언어 특징 추출
(SAM->NxM => CLIP->NxMx786, M은 장면 당 추출된 mask의 수)
5. 높은 차원을 가진 시각-언어 특징에 대한 전처리
6. 장면에 대해 학습된 NVS에 전처리된 시각-언어 특징을 학습
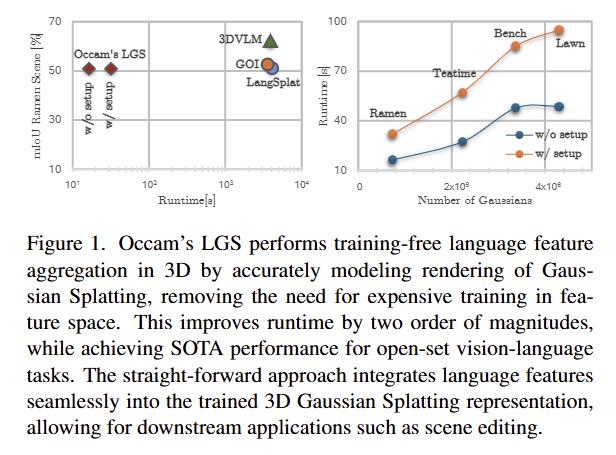
+ 저자는 fig 1에서 보이는 바와 같이 LangSplat은 67min이 소요된다고 작성했습니다.
추론 단계에서는 0. 객체에 대한 쿼리를 전달 받아 해당 쿼리를 CLIP의 text encoder에 입력, 1. 입력된 쿼리를 시각-언어 특징이 임베딩된 NVS과 유사도 검사를 통해 해당하는 영역을 추출합니다. 해당 과정은 일반적으로 ms 단위의 추론이 가능합니다.
즉, 쿼리에 대한 추론 시간은 ms의 단위로 추출이 가능하기 때문에 어느 정도 적절한 성능을 가지고 있다고 볼 수 있습니다. 허나, 학습 프로세스가 매 장면마다 진행이 되어야 하기 때문에 실질적인 추론 시간은 학습 프로세스의 총 시간 67min + @ms의 시간이 포함되어야 하는 거죠….

실시간으로 인지-제어-판단이 필요한 실제 어플리케이션에서는 매우 부적합한 구조를 가지고 있다고 볼 수 있습니다. 저자는 이러한 기존 연구들의 문제점을 불필요한 프로세스에 있다고 주장합니다. 또한, 기존 연구에서는 높은 차원을 가진 시각-언어 특징 정보를 효율적으로 NVS에 임베딩 시키기 위해서 Table 1과 같이 압축을 시키거나, 별도의 lookup table을 만들어 효율적인 학습이 가능하도록 하였습니다. 이러한 연산들은 학습 효율성을 높일 수 있겠지만, 실질적인 시간 소요가 높아질 뿐더러 특징 정보의 소실이 이뤄질 수 있다고 이야기합니다.
이러한 문제점을 해소하기 위해서 저자는 시각-언어 특징 정보를 그대로 사용하면서, 불필요하게 3DGS에 시각-언어 특징 정보를 학습을 시키지 않고, forward rendering에 시각-언어 특징 정보들을 활용하는 방법을 제시합니다. 해당 기법은 총 프로세스 시간 16.35~31.93s를 달성했으며, 성능 측면에서도 SOTA를 달성한 결과를 보여줍니다.
쉽게 설명하면, 학습 안 시키고 원래 3DGS가 가진 값 (투명도) 고려해서 시각-언어 특징 붙이니깐 되던데? 라고 보시면 됩니다.
+ 속도가 너무 차이가 많이 난다고 볼 수 있습니다. LangSplat 대비 전체적으로 최적화를 목적으로 기법들을 변경하였기에 제안한 모듈만 두고 비교하기에는 부족하긴 합니다. 허나, 기존 기법들이 속도에 고려하지 못한 부분들이 해당 기법을 통해 해소되었다고 점에서 이득이라고 생각합니다 하하…
Method
해당 기법에 대해서 이해하기 위해서는 3DGS와 LangSplat에 대한 전반적인 지식이 필요합니다. 이번 리뷰에서는 이미 안다고 알고 있다는 가정 하에서 진행하도록 하겠습니다.
전반적인 프로세스를 설명 드리자면 우선 rgb 기반의 기존 3DGS의 학습이 끝났다고 가정합니다. 그 다음 LangSplat에서는 시각-언어 특징 정보를 압축 시키기 위해 auto-encoder를 학습 시키고 압축된 특징 정보를 3DGS에 다시 학습 합니다.
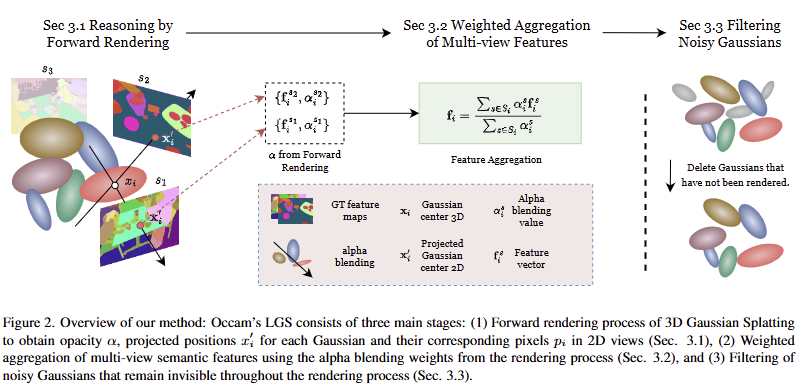
해당 기법에서는 LangSplat이 수행하는 방법이 아예 생략되었고 더 간단한 방법으로 대체 됩니다. 저자가 제안하는 요소를 정리하면 fig 2와 같이 Reasoning by Rendering, Weighted Feature Aggregation 그리고 Filtering에 해당합니다.
+ 핵심적인 부분만 설명을 하는 것이 좋을 것 같아 추가합니다.
3DGS는 장면을 표현하기 위한 anisotropic Gaussians G들을 학습하는 것을 목표로 합니다. G는 position x, covariance Σ, color c, opacity o로 표현됩니다. G들로부터 효율적으로 영상의 pixel을 표현하기 위해서 16×16 tile-based rasterization을 수행합니다. 이때, 카메라 센터를 기반으로 pixel에 해당하는 ray 내 가우시안들을 깊이에 따라 정렬을 합니다. 카메라와 가장 가까이에 있는 가우시안의 정보가 픽셀 정보에 가장 큰 영향을 주는 것이 맞지만 동일 ray에 소속된 가우시안의 컬러들도 영향을 줄 수 있습니다. (예를 들어 투명한 페트병의 색상은 뒤 배경의 색상의 영향을 맞는 것처럼 말이죠) 저자는 이를 모델링하기 위해서 정렬된 가우시안에 대해서 기여도에 따른 alpha α에 대한 alpha blending을 수행합니다. 이는 아래와 같습니다.
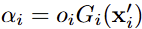
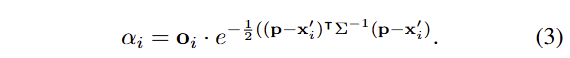
+ 수식 3은 ocupancy o와 3D gaussian을 픽셀 영역에 사영한 2D gaussian의 연산으로 보시면 됩니다.
최종적으로 컬러 값들은 아래 수식을 통해 기여도에 따른 alpha α에 대한 alpha blending을 통해 얻어 집니다.
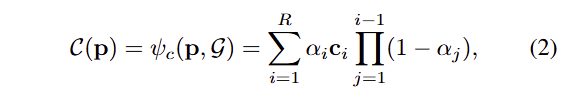
기존 3DLF에서는 시각-언어 특징 정보 f를 3DGS에 임베딩하기 위해서 식 2에서 c를 대치하여 활용합니다. 이는 아래와 같이 정의됩니다.
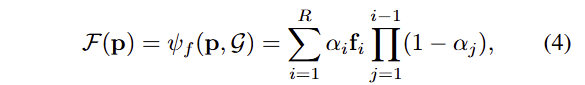
수식 4와 같이 시각-언어 특징 f를 3차원 공간에 back-projection을 수행하여 재 학습을 진행합니다. 이러한 구조는 시각-언어 특징 f의 dim이 커질 수록 필요한 연산량이 급수적으로 높아지게 됩니다.
Reasoning by Rendering
기존 기법들은 시각-언어 2D 특징을 3D 공간에 올리는 방법(uplifting)으로 보통 back-projection에 의존하는 반면 저자는 forward rendeting에서 2D 특징을 3D 공간에 lifting하는 방법을 제시합니다.
먼저, rgb 영상만을 이용하여 학습한 Gaussian model이 주어져 있고, Gaussians G 중에서 view frustum 내의 Gaussian set S_i에 해당하는 픽셀 p_i가 있을 때, 픽셀 p_i에 해당하는 시각-언어 특징 f_i를 구하는 것을 목표로 합니다. 이는 아래와 같습니다.
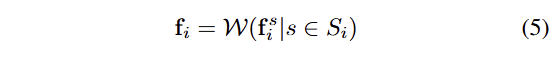
여기서 W는 아래 섹션에서 다시 다룹니다. 보다 효율적으로 계산하기 위해서 tile-based rasterization을 수행하면서 사영된 2D gaussians의 위치 x’를 픽셀에 할당하기 위해서 아래와 같이 픽셀 위치를 할당합니다.
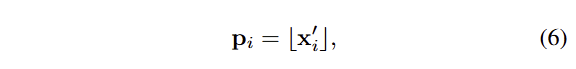
그냥 float 형태의 위치 값을 내림하여 정수화 시켜 픽셀에 할당 시켰다고 생각하시면 됩니다.
저자가 주장하길 위와 같이 forward rendering만 수행했을 때, 장점은 다음과 같다고 합니다.
첫째, feature uplifting이 단 한 번의 forward pass만 요구되어 계산 효율성이 매우 높습니다.
둘째, view frustum culling과 tile-based sorting을 통해 occluded Gaussian들을 자연스럽게 처리함으로써, 실제로 보이는 특징들만을 처리할 수 있습니다.
마지막으로, 렌더링 과정에서 투영 위치를 명시적으로 기록함으로써 시각-언어 2D 특징과 3D Gaussian 간의 직접적이고 정밀한 대응 관계를 구축할 수 있어, 복잡한 back-projection과 같은 학습이 필요하지 않게 됩니다.
Weighted Aggregation of Multi-View Features
단순하게 다중 뷰에서 얻어진 특징 정보들 aggregation하게 되면 생성된 특징 정보에 노이즈가 발생할 수 있습니다. 어떤 뷰에서는 한 Gaussian이 거의 보이지 않거나 심하게 가려져 있어 그 기여도가 신뢰할 만하지 않을 수 있습니다. 이를 해결하기 위해, 우리는 feature aggregation process에서 각 뷰에서의 Gaussian 기여도를 고려합니다. 각 Gaussian G_i에 대해, view s에서 직접 투영된 pixel position p^s_i에서의 기여도 α^s_i를 가중치로 활용합니다. 그러면 가중치가 적용된 feature aggregation function 는 다음과 같이 표현할 수 있습니다.
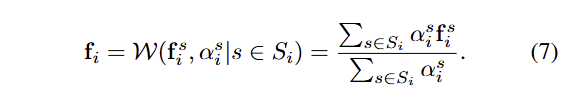
위 방식을 통해서 영향력이 큰 뷰들이 실질적인 특징에 더 큰 기여를 하도록하며, 이를 통해 더 강건하고 일관된 3D feature를 형성하도록 한다고 합니다.
Filtering Noisy Gaussians
저자는 forward rendering pass를 진행하고 나서, 확인해보니 기여가 없는 가우시안들이 굉장히 많고 이들을 필터링하니 노이즈를 크게 감소시킬 수 있었다고 합니다.
+ 구체적인 방법에 대해서는 적혀져 있지 않아서… 확인해봐야 할 것 같습니다.

전반적인 흐름은 alg 1에 작성되어 있습니다. 진짜 단순하게 rgb에 학습된 gaussian model에 정해진 alpha에 따라 feature f를 가중합하고 나중에 합산된 alpha a_i를 나눠줘서 feature naormaization을 수행합니다. 이게 끝입니다… 하하…
Experiment
실험은 LERF와 같이 3D-OVS와 LERF 데이터 셋에서 진행됩니다.
Implementation Details. GSplat 라이브러리를 활용하여 기존 3DGS 세팅에 따라 장면에 대해서 30,000 iter를 진행해 사전 학습합니다. 이를 통해 2,500,000 Gaussians을 생성합니다. 2D language feature는 LangSplat과 동일하게 OpenCLIP ViT-B/16과 SAM ViT-H를 이용해 추출합니다. 모든 실험은 A6000에서 진행했다고 합니다.
평가는는 query text에 따른 relevancy socre > 0.5를 기반으로 생성된 mask에 대한 평가를 진행합니다. (object stability threshold = 0.4)
Open Vocabulary Semantic Segmentation

LERF에서의 정성적 결과 입니다.
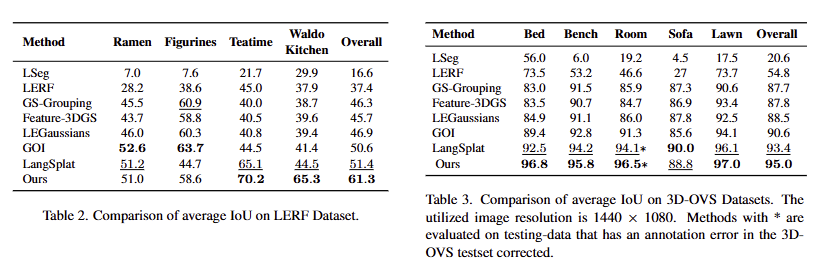
LERF와 3D-OVS에서의 정량적 결과, 기존 기법들을 뛰어넘는 결과를 보여주고 있음. LERF의 경우, LangSplat 대비 약 10%의 성능 향상을 보여줌
Localization

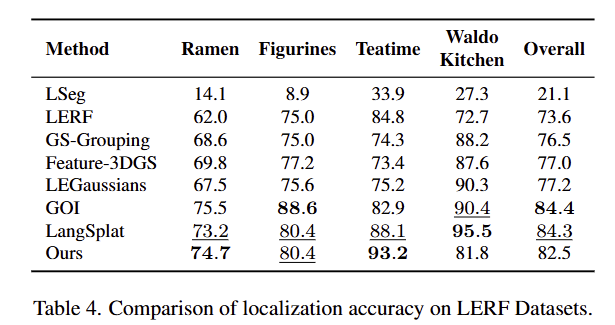
3D 공간에서의 쿼리에 따른 relevancy socre에 따른 localization을 평가함. SOTA는 달성하지 못했지만 단순함 대비, 비교 가능한 성능이 나왔다고 주장…
Computational Efficiency
계산 효율성에 대한 실험. fig 1에서도 확인 가능함. LangSplat과 GOI는 저자와 동일하게 사전 학습된 3DGS를 활용함. 두 기법은 uplifting만 시간을 측정했을 때, LangSplat은 67min, GOI는 60min이 소요됨. 3DVLM은 reconstruntion이 결합된 기법으로 이를 반영해서 65min을 소요함.
이에 반해 저자가 제안한 기법은 16.35s를 소요함. 여기서 setup (including checkpoint, saving)을 고려하면 31.93s를 소요함.
Ablation Study
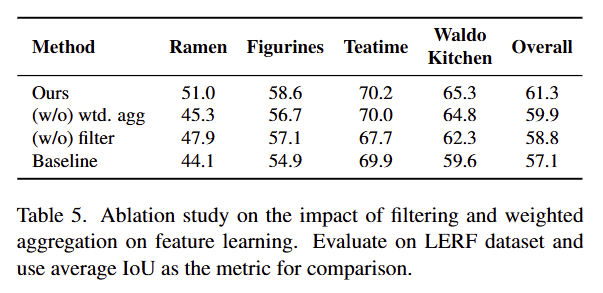

tab 5에서는 저자가 제안한 weighted aggregation과 filtering을 제거하고 수행한 실험 결과.
baseline은 기존 back-propagation을 수행한 결과라고 함??????
+ baseline부터 LangSplat을 넘겼음… 뭐지??????
+ 추가로 weighted aggregation 없어도 어떻게 되는 거지?
위에서 서술한 바와 같이 3DLF를 로봇에 적용하기 위해서는 모든 프로세스의 시간이 크게 감소되어야 합니다. 해당 연구는 이를 위한 기본 틀을 제시했고, 이제… 3DGS 자체 프로세스의 시간을 줄이면 됩니다. 이를 수행하기 위한 기법도 찾아두었으니 관심 있으신 분들은 다음 편을 기대하시길 바랍니다. 하하…
좋은 리뷰 감사합니다.
단순한 방법이지만 성능과 소요 시간이 크게 개선되었다는 점이 흥미롭습니다.
Figure 4의 빨간색 글자가 입력으로 들어가는 것으로 이해하였습니다. 특정 물체에 대하여 활성화 되는 것 뿐만 아니라, “three cookies”에서 3개의 쿠키가 활성화 되는 것이 흥미롭습니다. 단순히 cookies를 입력해도 비슷한 결과가 나오지 않을까 하는데 이에 대한 의견이 궁금합니다. CLIP feature를 가우시안에 올린 것으로 이해하였는데, three를 이해할 수 있는 이유에 대해 생각하시는 이유가 있는 지 궁금합니다.
Q1. 단순히 cookies를 입력해도 비슷한 결과가 나오지 않을까 하는데 이에 대한 의견이 궁금합니다.
A1. 제 생각에도 cookies를 입력해도 비슷한 결과가 나올거라고 생각합니다. 셀링하려고 three를 붙인 거라고 생각합니다.
Q2. CLIP feature를 가우시안에 올린 것으로 이해하였는데, three를 이해할 수 있는 이유에 대해 생각하시는 이유가 있는 지 궁금합니다.
A2. CLIP feature를 사용하기 때문에 three를 이해하는 능력은 떨어질 것이라고 판단됩니다.