안녕하세요. 박성준 연구원입니다. 오늘 리뷰할 논문은 CVPR2023에 게재된 논문으로 Vision-Language task에서 Compositional Generalization 능력에 대한 논문입니다.
Introduction
Compositionality는 인간의 인지 능력에서 중요한 능력 중에 하나로 Vision-Language(V&L) 분야에서 Compositional Generalization 능력은 최근에 주목 받고 있는 연구 분야 중에 하나입니다. Compositional Generalization 능력은 이전에 알고 있는(학습한) 단어들을 새로운 방식으로 조합하여 새로운 조합의 문장의 의미를 파악하고 일반화 능력을 의미합니다. 이는 자연어를 이해하는 데에 있어 중요한 능력으로 평가됩니다.
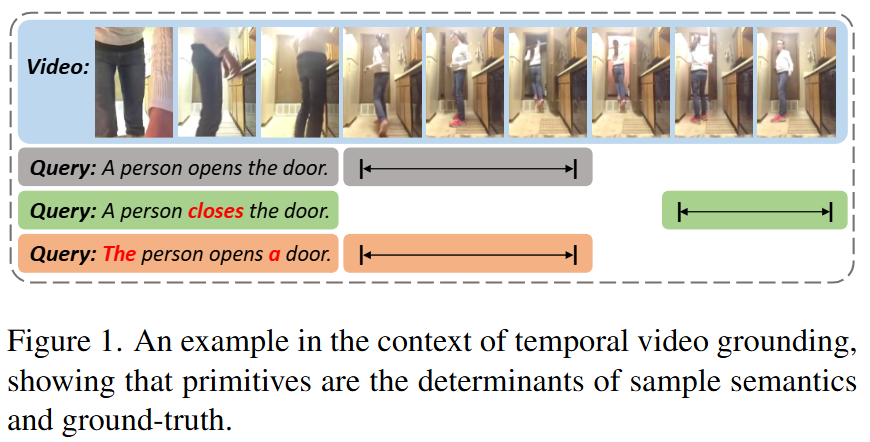
저자는 이러한 Compositional Generalization 능력을 위해서 Primitives(원시 요소; 문장의 단어, 비디오의 프레임 등을 의미함)가 미치는 영향에 집중합니다. 이러한 Primitives는 샘플의 의미를 구성하는 굉장히 중요한 요소로 Figure 1.에서 “A person opens the door”라는 문장에서 “opens”를 “closes”로 변경하면 문장의 의미가 완전히 변하게 됩니다. 반면에, “The”가 “A”로 변경된다고해서 문장의 의미가 변하지는 않습니다. 저자는 이러한 관찰을 바탕으로 Primitives의 중요성을 파악했으며, 이전 연구의 V&L 연구들은 이러한 차이점에 주목하지 않았음을 지적하고 있습니다.
저자는 이러한 Compositional Generalization 능력을 위해 두가지 측면에서의 Primitives의 영향력을 탐구합니다. 첫 번째는 Semantic Equivariance(의미적 동변성)으로 primitives가 변경되었을 때 모델의 예측 또한 변화해야한다는 것을 의미합니다. 두 번째로 Semantic Invariance(의미적 불변성)으로 primitives가 변경되었을 때 모델의 예측이 변하지 않는 것을 의미합니다. 저자는 이러한 두가지 특성은 Compositional Generalization을 모델이 가지고 있어야하는 필수적인 특성이며 이를 학습시키는 방법을 탐구합니다.

위 아이디어를 바탕으로 저자는 Figure 2.에서 설명하는 4가지 마스킹 기법을 통해 모델의 Semantic Equivariance 능력과 Semantic Invariance 특성을 학습하고자 했고 이를 통해 모델의 Compositional Generalization 능력을 향상시키고자했습니다. 위의 4가지 마스킹 방법은 순서대로 문장의 중요한(의미가 문장 전체의 의미에 영향을 주는) primitives를 마스킹, 비디오의 중요한 primitives(GT 구간)를 마스킹, 문장의 중요하지 않은(의미가 문장 전체의 의미에 영향을 주지 않는) primitives를 마스킹, 비디오의 중요하지 않은 primitives(GT가 아닌 구간)를 마스킹하는 방법입니다. 각각의 마스킹 방법은 negative, negative, positive, positive 샘플이 되어 모델의 Semantic Equivariance, Semantic Invariance 특성을 모델링합니다.
저자는 위 4가지 마스킹 방법을 Self-Supervised 학습 기반의 Plug-in 프레임워크로 기존 모델에 추가하는 것으로 기존 모델이 부족한 Compositional Generalization 능력을 향상시키고자 합니다. 이에 따른 저자의 Contribution은 다음과 같습니다.
- 저자는 Primitives가 기존 V&L 기법의 Compositional Generalization 능력에 미치는 영향을 탐구하였으며 Primitives의 변화에 따른 의미적 변화의 차이에 주목했습니다.
- 저자는 Self-Supervised 학습 기반 프레임워크를 제안하는 것으로 다양한 마스킹 방식을 통해 기존 V&L 모델이 Semantic Equivariance와 Semantic Invariance를 학습할 수 있도록 하였습니다.
Method
저자는 두가지 V&L task에서 저자의 방법론을 평가합니다. Temporal Video Grounding(TVG)와 Visual Question Answering(VQA)입니다. TVG는 untrimmed video에서 language query에 해당하는 구간을 검색하는 task이고 VQA는 이미지 또는 video에 대한 자연어 질문에 대한 답변을 생성하는 task입니다.
이후 수식에서 V, Q는 각각 video, language query를 의미하고, 구체적으로는 Q = {q_i}^M_{i=1}, V = {v_i}^N_{i=1}로 표현됩니다. M, N은 전체 단어 수, 전체 프레임의 개수를 의미합니다.
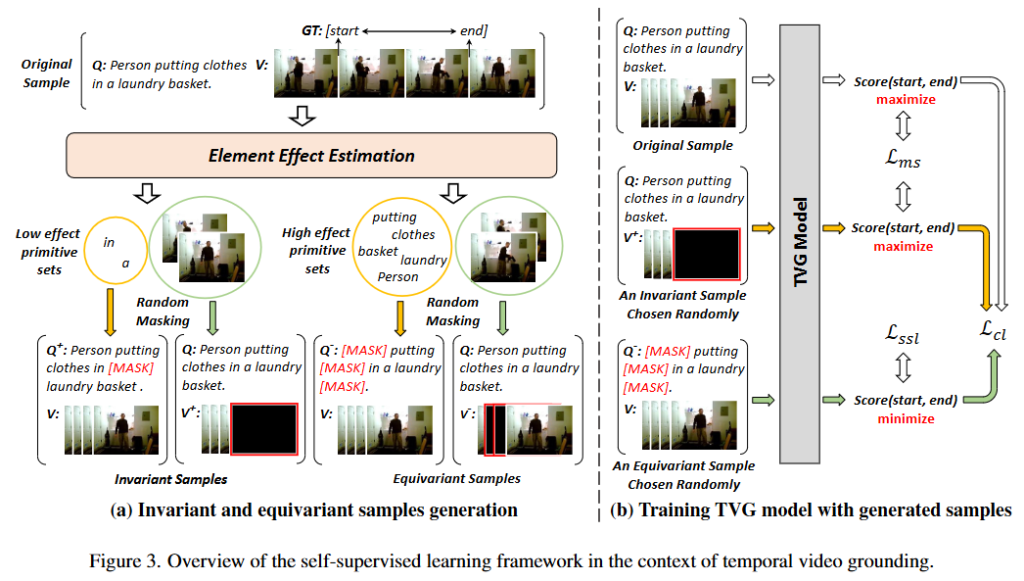
Figure 3.은 저자가 제안하는 프레임워크를 보여주고 있습니다. 저자는 TVG에서의 프레임워크를 통해 자신이 제안하는 방법을 소개하고 있습니다. TVG에서 (V, Q)와 GT Y = (start, ent)를 사용하여 Primitives가 미치는 영향을 확인할 수 있으며 저자의 마스킹 방법은 각각 다음과 같이 수식으로 표현합니다. Equivariance 샘플은 (V, Q^+), (V^+, Q), Invariance 샘플은 (V, Q^-), (V^-, Q)로 각각 위의 +, -가 마스킹 된 것을 의미합니다. 위 샘플들을 통해 refined representation 학습을 진행하며 L_{ms}, L_{ssl}, L_{cl}으로 ms는 method specific으로 TVG 혹은 VQA의 기존 모델의 loss를 의미합니다. ssl은 self-supervised learning으로 자기지도학습에서 사용하는 loss를 의미하고 cl은 contrastive learning으로 contrastive learning 학습을 위한 loss입니다.
저자는 Primitives가 GT에 미치는 영향을 [0, 1] 범위의 값으로 표현합니다. 저자는 Part-of-Speech(POS) tagging을 기반으로 단어를 명사, 동사, 형용사, 부사, 나머지 총 5가지로 분류합니다. 여기서 저자는 명사와 동사는 문장에서 의미적으로 중요한 역할을 수행하고 있으며 형용사와 부사는 문장에서 부수적인 설명을 제공하고 나머지는 GT에 영향을 거의 미치지 않는다고 설명하고 있습니다. 이러한 저자의 생각을 바탕으로 각각의 단어에 정량적 가중치를 할당합니다. \alpha는 명사와 동사, \beta는 형용사와 부사, \gamma는 나머지로 설정했으며 \alpha, \beta, \gamma는 각각 0.6, 0.6, 0으로 설정하여 저자는 명사, 동사, 형용사, 부사는 각각 0.6의 가중치를, 나머지는 0의 가중치를 주는 것으로 각각의 primitives(단어)가 문장의 의미적으로 미치는 영향을 설정합니다.
저자는 TVG와 VQA에서 primitives의 영향을 파악합니다. VQA와 TVG는 vision과 language의 상관관계를 파악해야한다는 task라는 점에서 공통점이 있지만, 서로 수행하는 일이 다르기 때문에 서로 다른 방식으로 primitives의 영향을 파악합니다. 먼저, VQA에서는 POS tagging을 통해서 문장 내에서 핵심 단어(명사, 동사, 형용사, 부사)를 추출하고 이미지 혹은 비디오의 영역을 선정해서 이미지 내 영역과 핵심 단어와의 유사도를 측정합니다. 유사도를 CLIP 모델의 사전지식을 활용하고 [0, 1]로 정규화하여 표현합니다. 저자가 이미지(비디오) 내 영역을 선정하고 유사도를 구하는 이유는 VQA의 질문이 “이미지 내에 사과의 색깔은 무슨 색인가요?”와 같이 이미지 내 특정 객체의 특성을 물어보는 경우가 많기 때문이라고 합니다. 개인적으로 모델의 일반화 성능을 올린다는 관점에서 효율적인 접근은 아닌 것 같지만, 여러 VQA 방법론에서 활용되는 방법 중에 하나로 성능 향상을 위해 꽤 자주 활용되는 방법이라고 합니다. TVG에서는 GT 구간을 1, 나머지를 0으로 설정합니다. 그 후 입력 문장과의 유사도를 구하게 되는데 이때는 기존 Temporal Contrastive Learning(TCL) 모델을 사용했다고 합니다.
4가지의 마스킹 방법을 통한 샘플링 과정은 50%의 확률로 (V^-, Q), (V, Q^-) 중에 하나를 선택하고 마찬가지로 (V^+, Q), (V, Q^+) 중 하나를 선택합니다. 그 후 저자가 제안하는 마스킹을 수행합니다. 이때 단어를 선택하는 것 또한 균등한 확률로 선택합니다.
Loss는 L_{ms}는 기존 task의 loss를 그대로 사용합니다. 여기서 마스킹을 통한 샘플과 original 입력의 결과를 통한 loss에는 하이퍼파라미터 \lambda를 사용해 결정합니다.
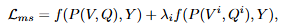
마스킹된 샘플은 실제 GT가 아닌 마스킹을 통해 변경된 GT를 사용하여 자기지도학습 기법을 통해 학습됩니다. 샘플의 의미가 더 많이 손상될수록 모델의 원래 정답을 얻는 것은 어려워지기 때문에 자기지도학습에서도 이를 고려하여 학습을 수행합니다.
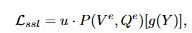
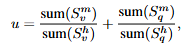
여기서 u는 손상된 정도를 측정하는 가중치로 위의 수식을 통해 계산됩니다.
마지막으로 contrastive loss는 Invariance 샘플은 positive로 가까워지도록, Equivariance 샘플은 멀어지도록 학습합니다.

최종 loss는 다음과 같습니다.
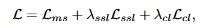
Experiments
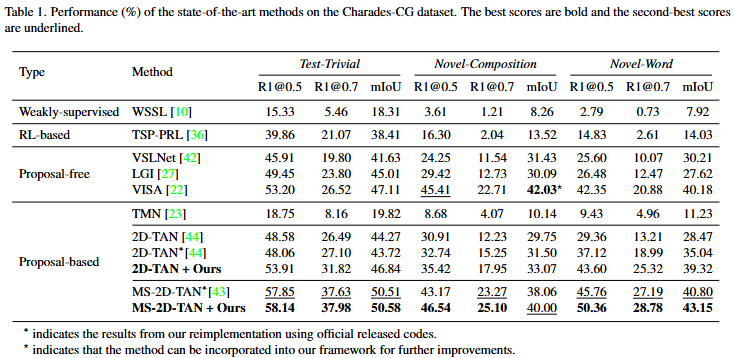
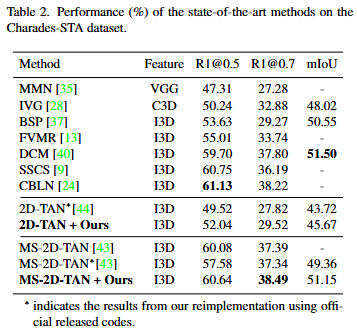
위는 실험결과입니다. Table 1와 Table 2는 TVG에서의 실험결과로 기존 방법론에 저자의 프레임워크를 통해 모델의 Compositional Generalization 능력을 강화한 결과, 기존 모델의 성능은 유지한채 compositionality를 증가시킬 수 있습니다. Table 1에서 평가에 사용한 데이터셋은 Charades-CG 데이터셋으로 기존 Charades-STA 데이터셋에서 학습셋과 평가셋에서 composition의 분포가 비슷했던 데이터셋을 학습셋과 평가셋의 composition 분포를 다르게 하여 평가하는 데이터셋입니다. Novel-Composition은 평가셋에 학습셋에 없던 composition을 추가한 평가, Novel-Word는 학습셋에 없던 단어를 추가한 평가입니다. 기존 데이터셋에서는 확인할 수 없었던 Compositionality 능력을 평가할 수 있습니다. Test-Trivial에서는 성능의 상승폭이 거의 비슷하지만, Novel-Composition 및 Novel-Word에서는 평균적으로 약 2~3 퍼센트 상승한 모습을 보이며 기존 모델의 약점이었던 Compositional Generalization 능력을 향샹시켜준 것을 확인할 수 있습니다.
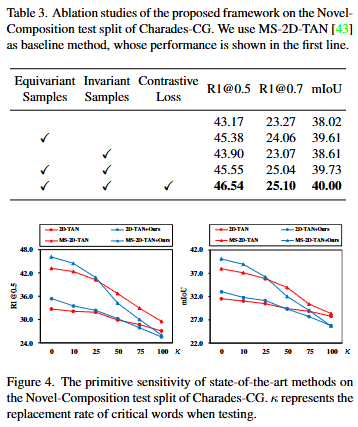
Ablation Study를 통하여 저자는 각기 제안하는 방법론이 모델의 Compositional Generalization 능력을 향상시킴을 보여주고 있습니다. 특히, Equivariant 샘플을 통해 중요한 primitives의 정보를 파악하는 것이 성능이 제일 많이 향상되는 것을 보여주며 Primitives의 영향력을 보이고 있습니다.

위 Figure 5.는 정성적 결과입니다. TVG에서 저자의 방법론을 통해 기존 방법론이 잘 대응하지 못하는 Novel-Composition과 Novel-Word에서의 성능이 향상되는 것을 확인할 수 있습니다.
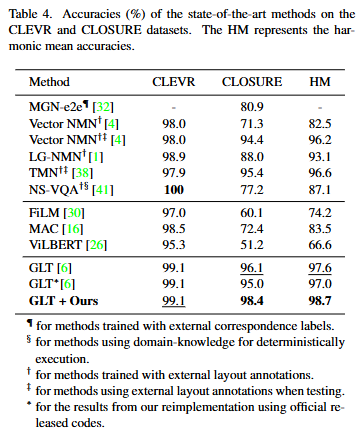
Table 4.는 VQA에서의 성능을 보이고 있습니다. 저자는 CLEVER 데이터셋과 CLOSURE 데이터셋에서의 성능을 보이고 있습니다. HM은 Harmonic Mean으로 조화평균입니다. 조화평균은 일반적인 평균과는 달리 특정 데이터셋에 편향된 성능보다는 일반적으로 성능이 높은 것을 많이 반영하여 일반화 성능을 올릴 수 있다는 것을 보여줄 수 있습니다. CLOSURE 데이터셋은 이미지 내 객체들 사이의 관계를 질문으로 물어보는 데이터셋으로 모델이 자연어 질문의 의미론적 정보를 파악할 수 없다면 질문에 대한 정확한 대답을 할 수 없습니다. 저자는 CLOSURE 데이터셋에서의 성능 향상폭이 높다는 것은 결국 모델이 Compositional Generalization 성능이 높다는 것을 보여주며 저자가 제안하는 방법이 VQA에서도 Compositional Generalization 능력을 올릴 수 있다고 설명합니다.

Figure 6.은 CLOSURE 데이터셋에서의 정성적 결과를 보여줍니다. 기존 VQA 모델 GLT는 제대로 예측하지 못하고 있지만, 저자의 방법이 더해지니 더 예측을 잘 하는 모습을 보이고 있습니다.
저자는 새로 Semantic Equivariance와 Semantic Invariance 능력을 정의하고 Compositionality Generalization을 위해서는 필수적인 능력임을 설명하며 정의한 능력을 향상시키기 위한 방법을 제안했습니다. 방법 자체는 간단하지만, 저자의 주장을 잘 보여주고 증명해서 우수학회에 게재될 수 있었던 것 같습니다. 이것으로 리뷰 마치겠습니다. 감사합니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
CLIP 모델을 사용한다고 말씀해주셨는데, CLIP은 A, The라는 관사만으로도 성능 변화가 큰 것으로 알고 있는데, 본 논문의 저자는 문장에서 관사의 변화는 전혀 문장의 의미적으로 영향을 미치지 않는다고 판단한 것 같습니다. 혹시 관사에 대한 중요도를 낮게 봄으로써 CLIP의 기존 성능에서 발생하는 것과 동일한 문제가 발생하지는 않을까요 ? 성준님 의견이 궁금합니다 !
마지막으로 PoS tagging이 굉장히 성능에 영향을 많이 미칠 것 같은데 이 가중치에 대한 ablation study는 없었을까요 ?
감사합니다.
안녕하세요 손건화 연구원님 좋은 댓글 감사합니다.
말씀해주신 것처럼 CLIP과 같은 vision-language 사전학습 과정에서 prompt에 ‘A’ 혹은 ‘The’와 같은 관사를 바꾸는 것이 성능에 큰 영향을 미치는 것으로 알고 있습니다. 저자는 관사의 변화로 인한 문장의 의미가 크게 바뀌지 않는다고 판단했지만, 모델의 입장에서는 어떻게 반영되는 지를 명시적으로 확인할 수 없기에 관련된 단어들의 영향력을 확인할 수 있는 실험 혹은 정성적 결과가 같이 논문에 있었으면 더 좋았을 것 같네요. Table 3.에서 Invariant Samples를 추가했을 때 다른 모듈에 비해 성능 향상 폭이 낮고 R@0.7에서는 오히려 성능이 낮아지는데 특정 상황에서는 관사의 정보가 중요할 수 있음을 보여주는 지표라고 생각합니다.
PoS tagging은 저자가 NLTK를 통해서 수행했다고 말하고 있고, 따로 이와 관련된 ablation study는 저자가 진행하지 않았습니다.
감사합니다.
안녕하세요, 박성준 연구원님. 리뷰 감사합니다.
뭔가 BERT, MAE와 같은 기존의 masking 기반 방법론을 TVG와 VQA같은 VLM에 확장시킨 느낌이 드네요. 사실 primitive의 영향 같은 경우 각 language, vision 모델이 세부적인 사항까지 잘 학습했다면 좋았겠지만 그렇지는 못한 것 같고, 마스킹을 통해 그 영향력을 분석하고자 한 것이 인상 깊었습니다.
질문이 있는데, video task의 경우 특정 시간 축을 마스킹 하는 것으로 보이는데, 이미지에 대한 VQA에서는 어떻게 마스킹을 진행하나요? 본문에는 영역에 대해서 마스킹한다고 설명되어있는것 같은데 그럼 local한 patch를 무작위로 마스킹하게되나요? 하지만 랜덤하게 마스킹하면 caption과의 연관성이 깨질 것 같아서 적절하게 마스킹해줘야 할 것 같은데, 그 방법이 궁금합니다.
감사합니다.
안녕하세요 허재연 연구원님 좋은 댓글 감사합니다.
저자는 VQA에서의 마스킹 방식은 TVG와 같은 방식을 취한다고 설명하며 랜덤하게 마스킹을 진행했다고 설명하고 있습니다. Invariant 샘플의 경우, GT가 아닌 영역을, Equivariant 샘플의 경우, GT 영역을 마스킹했는데, Figure 혹은 코드가 공개되어 있지 않아서 정확한 설명은 힘들 것 같습니다. VQA task에 대해서 제가 깊게 공부한 적은 없지만, 논문에서의 저자의 설명에 따르면 재연님이 지적해주신 것처럼 만약 GT에 대한 정보를 GT가 아닌 구간의 영역으로부터 추론해야하는 경우, 정보에 손실이 생길 수 있을 것 같습니다.
감사합니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
Primitives가 GT에 미치는 영향 [0, 1] 범위에 값으로 표현한다고 했고, 명사와 동사, 형용사와 부사, 나머지로 나누어 각각에 대해 0.6, 0.6, 0 가중치를 주어 문장의 의미적으로 미치는 영향을 설정한다고 이해했습니다. 이때 이 가중치 범위는 [0, 0.6]이라고 보는것인가요 ? 맥시멈이 0.6인 것 같은데 왜 1이 아닌 0.6으로 했는지 의문이 듭니다.
또 본 논문은 학습 프레임워크 방식을 제안하는 것으로 보이는데, 그럼 여기서 언급되는 TVG는 기존의 방법론인 것인가요 ?!
감사합니다.
안녕하세요 정윤서 연구원님 좋은 댓글 감사합니다.
우선 두번째 질문에 먼저 답하면, TVG는 기존의 방법론이 맞습니다. 기존의 방법론을 저자가 제안하는 프레임워크를 통해 강화할 수 있는 plug-and-play 방법론입니다. 그리고 가중치의 범위에 대해서는 저자가 명사, 동사, 형용사, 부사, 나머지로 문장 내 구성요소를 의미론적 중요도에 따라 상한선을 다르게 주어지게됩니다. 따라서, 어떤 primitives는 맥시멈이 1, 어떤 primitives는 맥시멈이 0.6 등으로 다르게 설정하는 것을 의미합니다.
감사합니다.
안녕하세요 성준님.
리뷰 흥미롭게 읽었습니다. 감사합니다.
마스킹한 데이터를 가지고 모델이 각 단어가 문장 안에서 문장의 의미를 구성하는데 얼마나 영향을 주는지에 대해 학습하고 추후 모델이 학습하지 않은 단어나 보지 못한 영상 데이터가 포함된 입력에 대해서도 추론 성능을 높인다고 이해를 했는데 제가 제대로 이해한 게 맞을까요? 그리고 이때 마스킹한다는 게 데이터의 일부를 없애는 것이고 그래서 리뷰에서 성준님께서 데이터를 손상시킨다는 표현을 사용하신 걸까요?
안녕하세요 류지연 연구원님 좋은 댓글 감사합니다.으로 대체하여 입력하게 됩니다. 실제 문장 속 단어를 사용하지 않아 정확한 의미와는 달라지기에 데이터의 의미가 손상되는 것이라고 표현했습니다. 중요한 단어를 마스킹할수록 의미가 많이 손상된다고 볼 수 있습니다.
마스킹 기법은 일반적으로 문장 내에서 마스킹한 단어의 문장 내 중요도, 역할 등을 모델링하기 위하여 많이 사용되는 기법입니다. 즉, 문장 구조 속 마스킹된 단어, 단어의 위치 등이 어떠한 맥락적 의미를 갖고 있는 지를 모델이 학습을 통해 알 수 있게 됩니다. 이러한 관점에서 학습하지 않은 조합(composition) 혹은 단어가 주어지더라도 문장 내 맥락을 파악할 수 있기에 추론 성능을 높일 수 있게 되는 것입니다. 마스킹 기법은 제가 본문에서 자세하게 다루지는 않았지만, 단어 토큰을 마스크 토크
감사합니다.