안녕하세요, 쉰 두번째 X-Review입니다. 이번 논문은 2024년도 CVPR에 게재된 ODM: A Text-Image Further Alignment Pre-training Approach for Scene Text Detection and Spotting논문입니다. 바로 시작하도록 하겠습니다. ?
1. Introduction
본 논문은 OCR task를 위한 새로운 pre-training 기법을 제안하는 논문입니다. 저자는 먼저 컴퓨터 비전에서 일반적으로 사용되는 사전 학습 기법 두가지를 언급하는데요, 첫 번째로 Masked Image Modeling (MIM) pre-training입니다. MIM은 주로 마스킹된 영상을 재구축함으로써 visual representation을 학습하는데 중점을 두고 있으며, 주로 image classification과 같은 vision쪽 task에 적용되는 방식입니다. 두 번째 사전학습 기법은 text와 image를 둘 다 입력으로 넣어 두 모달리티의 semantic한 정보를 추출해내Masked Language Modeling (MLM)입니다.
하지만, 이런 사전학습 기법들을 OCR task에 적용할 때는 두 가지 문제가 발생하게 되는데요. (1) 먼저 MIM 기반 방식을 적용한다고 생각해볼 때 ocr 영상 내에 존재하는 text가 존재하는 영역이 작기 때문에 mask patch가 영상 내 text를 완전히 가려버릴 수 있습니다. 그렇게 되면 오히려 textual feature를 학습하는데 오히려 방해만 되겠죠. (2) 또, MLM 기방 방법은 text input을 masking해서 이를 복원하는 방식으로 학습하게 되지만 학습 중에 text의 location information을 고려하지 않습니다. 즉, 모델이 영상 내의 text가 어디에 있는지 정확히 인식하지 못할 가능성이 있는 있는 것이고 결국 text와 image feature가 제대로 alignment되지 않을 뿐더러 영상 정보도 제대로 활용하지 못하는 문제가 발생하게 됩니다.
본 논문에서는 OCR task에서 text-image alignment 문제를 해결하기 위해 OCR-Text Destylization Model(이하 ODM)이라는 새로운 pre-training 기법을 제안합니다.
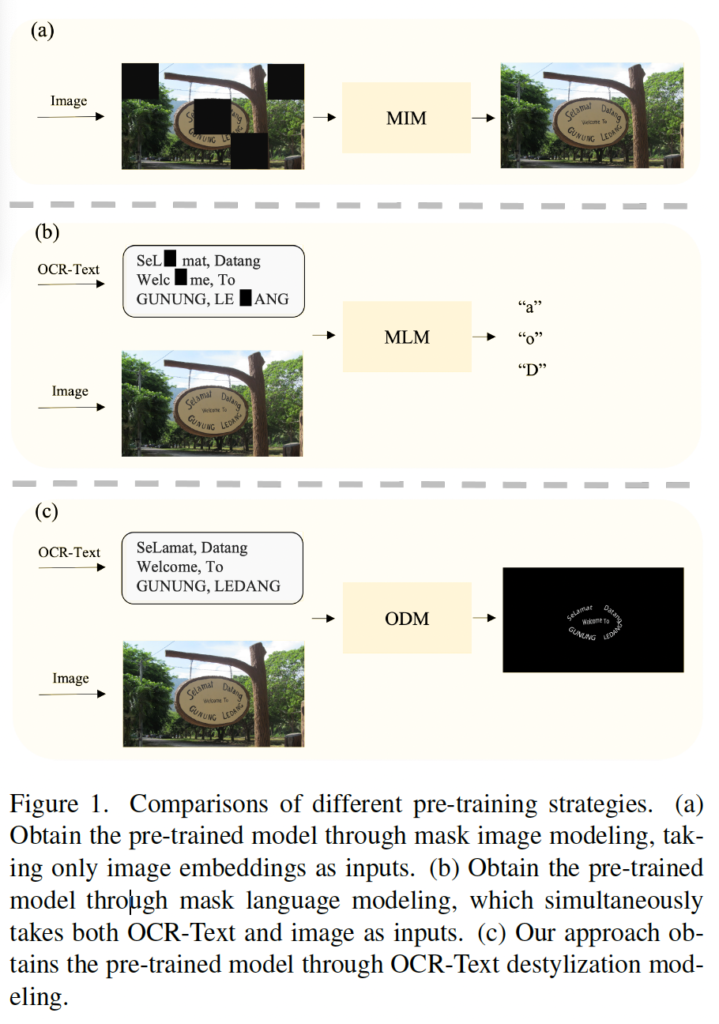
위 Fig1에서는 앞서 언급했던 MIM과 MLM의 대략적인 동작 과정이 그려져 있으며 (c)를 보시면 본 논문에서 제안하고 있는 ODM은 text prompt에 기반한 pixel level의 image reconstruction 기법임을 확인할 수 있습니다. OCR tasks에서는 영상내에 있는 것들 중 text가 가장 중요하며, 나머지 pixel들은 상대적으로 덜 중요합니다. ODM은 이런 특성을 반영하여, text의 style을 제거한 영상을 reconstruction함으로써 text와 OCR-Text(transcription) 간의 alignment를 맞추고자 하였습니다. 이를 위해 기존 RGB 3channel을 reconstruction하는 본래의 방식이 아닌, pixel-level의 reconstruction을 적용한 것이죠.
또, 추가로 모델이 text를 더 효과적으로 이해할 수 있도록 돕는 Text-Controller 모듈을 제안하였으며, ODM을 위한 새로운 label 생성 방식을 제안하여 데이터셋에서 pixel-level의 label이 부족한 문제를 해결하였습니다.

pixel-level의 label을 생성할 때 원본 영상에 있는 text의 스타일을 제거하고 글자 모양만 남긴 binary label image를 생성하도록 하였습니다. 위 Fig2에서는 이런 OCR-Text Destylization 영상 예시를 살펴볼 수 있습니다. 위에 행이 원본 영상을 나타내구요, 그 아래 행이 각각에 대한 destylized label이라고 보면 되겠습니다.
보다 자세한 내용안 아래 method단에서 다루도록 하겠습니다.
2. Methodology
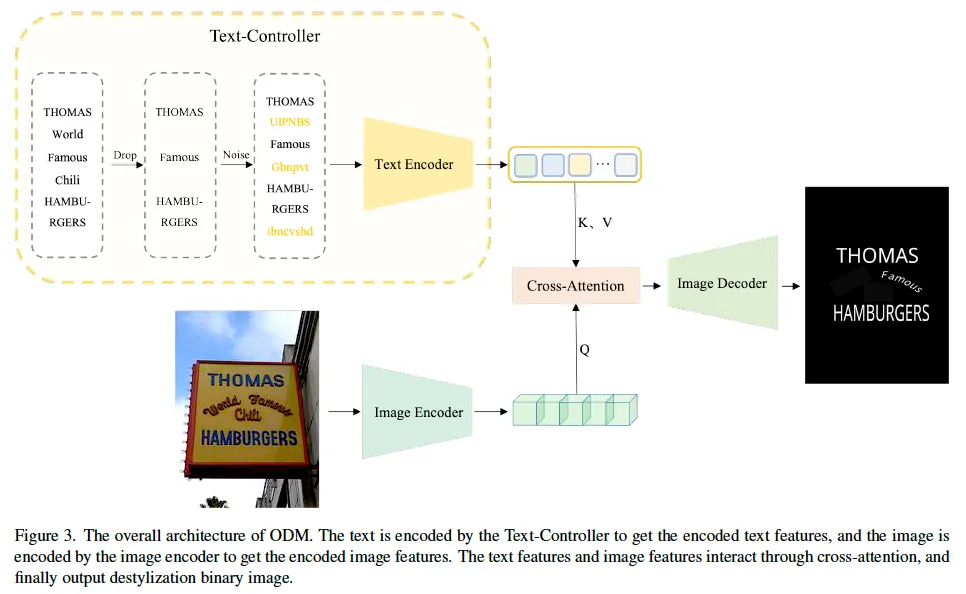
앞에서 간략히 설명했듯이 본 논문은 OCR-Text Destylization Model(ODM)이라는 OCR task에서의 pre-training 기법을 제안한 논문이며, 이 ODM은 OCR-Text의 특성을 활용해 text와 OCR-Text간의 alignment를 수행하며, 명시적으로 location 정보를 학습하도록 설계되었습니다. 본 ODM의 전반적인 아키텍처가 위그림 3에 나타나 있습니다. 제안된 네트워크는 text와 image 두 input을 받아 각각 image, text encoder를 태우는 식으로 동작합니다. 이 두 encoder를 태워 뽑은 각각의 feature들간에 cross-attention을 적용해 서로 align된 image feature를 생성하게 되구요 이렇게 align된 feature들은 image decoder를 타고 최종적으로 text style이 제거된 binary 영상이 생성됩니다.
3.1. The Text-Controller Module
먼저 Fig3에서 좌상단 부분에 모사되어 있는, Text Encoder로 들어가는 input을 생성하는 Text-Controller 모듈에 대해 살펴보도록 하겠습니다. 이 Text Controller 모듈은 Image encoder-decoder 구조가 character를 효과적으로 이해하지 못하는 문제를 해결하기 위해 제안된 것입니다. 이 모듈은 이미지 feature 추출을 컨트롤하고, OCR-Text feature와 text feature를 hidden space상에서 alignment하는 역할을 합니다.
Drop-Text.
먼저 gt text들에 대해 Drop을 하는 과정을 거칩니다. 모델이 OCR-Text의 특정 부분을 reconstruction하도록 학습하는 것이죠. 일반적인 text encoder, 예를 들어 CLIP의 text encoder는 text prompt를 입력으로 받아 image feature와 alignment하는데 초점이 맞춰져 있습니다. 하지만, 여기 text controller module에서는 text prompt를 활용하여 decoder의 output을 조절합니다. 조금 더 구체적으로 말해보자면 OCR-Text의 일부가 이 Drop단계에서 drop이 되게 될텐데 이때 decoder로 binary map을 생성할 때 모델이 drop되지 않은 부분만 reconstruction하고 나머지는 background로 처리하도록 학습하는 것이죠. 그림을 보면 World라는 영상 내의 text가 Drop 단계에서 사라지게 되는데 최종적으로 decoder가 생성한 map에서 원본 영상 내의 world가 위치한 부분을 보면 배경으로 처리된 것을 확인할 수 있습니다. 학습 중에 이 Drop되는 비율은 0%에서 100% 사이에서 랜덤으로 선택되도록 하였습니다. 이 Drop-Text 방식을 통해 모델이 OCR-Text와 원본 text간의 alignment를 더 효과적으로 수행하도록 유도할 수 있습니다.
Noise-Text.
그림3의 Text-Controller부분을 보면 Drop이후에 Noise라는 과정을 거쳐 영상에 없는 noise label을 추가하는 것을 보실 수 있습니다. 정확하지 않는 label과 같은 노이즈는 모델 학습에 영향을 미칠 수 있는데요, 저자는 이 노이즈를 활용하여 모델의 성능을 강화해보고자 하였습니다. 즉, 단순히 text encoder의 입력에 token encoding 값을 변경해 존재하지 않는 ocr text를 추가하는 것입니다. 이로써 모델이 좀 더 복잡하고 까다로운 scene에서도 text와 ocr-text의 feature를 보다 효과적으로 조정할 수 있다고 합니다. 모델이 영상 내에 실제로 존재하는 OCR-Text와 그렇지 않은 OCR-Text를 구별할 수 있도록 하는 것이 목적이죠.

위 FIg4에서는 text-controller module에서 drop과 noise를 사용할 때에 따른 image의 cross attention 성능을 시각화한 것입니다. (a)가 원본 영상이구요, 그림이 작아서 잘 안보일수도 있는데 영상 내에는 “Rootin” “Ridge” “Toymakers” 텍스트가 존재합니다. (b)는 이 세 텍스트를 모두 입력으로 넣었을 때의 어텐션 히트맵이며, 세 텍스트가 모두 어텐션된 것을 확인할 수 있습니다. (c)는 “Toymakers”라고 하는 아래쪽에 있는 Text를 drop하고 나머지를 입력 텍스트로 넣어준 상황으로 Drop한 해당 텍스트는 heat되지 않고 있습니다. (d)는 원본 텍스트에 추가로 영상에는 존재하지 않는 “Sjehf”이라는 instance를 입력으로 넣어준 것인데, heatmap에는 영상에 존재하고 있는 text 영역에만 heat되어 있는 것을 확인할 수 있습니다. 이렇게 noisy한 text에도 영향을 받지 않도록 함으로써 text와 OCR-text(영상 내의 text 영역)간의 align을 맞추도록 학습합니다.
3.2. OCR-Text Destylization
방금 설명드린, Text-controller module외에도, 저자들은 OCR-Text의 근본적인 feature를 학습하도록 하기 위해 text의 style을 없애도록 reconstruction하는 단순한 디코더를 디자인하였습니다. 이 디코더는 FPN layer와 1*1 conv으로 구성되어 있습니다.

위 FIg5는 real image를 입력으로 넣었을 때 이 Destylization Decoder를 통해 생성한 binary map을 보여줍니다. 학습 데이터가 오직 합성 데이터셋인 SynthText임에도 불구하고 Realset을 넣었을 때 style을 없앤 text를 잘 뽑아내고 있습니다.
3.3. Loss Function
본 ODM은 최종적으로 binary image를 생성하기 때문에 pixel-level segmentation task로 보고 binary cross-entropy loss를 사용하였습니다.
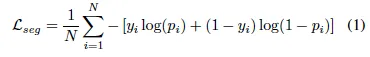
위 식에서 N은 pixel 개수를 의미하구요, p_i는 예측 결과, y_i는 GT를 의미합니다. 근데, 이 ODM은 원본 영상에 대해 text만 존재하는 영역을 구분하는 map을 생성하는 것이 아닌, destylization된 즉, 원본 영상 텍스트에서 스타일을 제거한 binary map을 생성하도록 학습되기 때문에 단순 pixel-level cross-entropy loss만으로는 효과적으로 학습하기 어렵습니다. 저자는 이를 보완하기 위해 OCR-VQGAN에서 제안된 OCR LPIPS loss를 함께 사용하였습니다. 이 loss는 UNet-VGG16과 같은 잘 학습된 detector를 사용해 GT와 prediction을 비교하면서 L1 Loss를 통해 feature representation을 향상시키는 역할을 합니다.
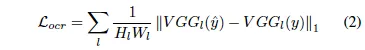
위 식에서 H_l, W_l는 l번째 레이어의 feature map 크기, \hat{y}, y는 prediction, gt입니다.
또 CLIP의 batch-level contrastive loss를 참고해 text와 image를 동일한 semantic space에 매핑하는 contrastive loss를 추가하였습니다.
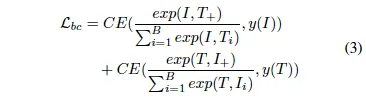
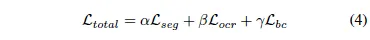
최종 loss는 이 세 loss의 가중합으로 계산됩니다.
3.4. Label Generation
ODM의 supervised training에서 어려움 중 하나는 정확한 pixel level label을 생성하는 과정입니다. 보통 pixel-level segmentation label map이 없을 뿐더러 있더라고 하더라도 ODM이 최종적으로 prediction하고자 하는 destylization된 segmentation map을 더더욱 없을 뿐더러 하나하나 라벨링하기에는 코스트가 너무 많이 듭니다. 본 섹션에서는 이 cross entropy loss를 계산하기 위한 gt label map을 생성하는 과정을 설명하도록 하겠습니다.
우선, 박스 어노테이션은 주로 네 꼭짓점 좌표가 주어지는데 이 정보를 이용해 사각형의 크기를 계산하고, 문자의 개수를 기반으로 각 문자의 크기위 위치를 추정합니다. 이후, NatoSans-Regular과 같은 폰트를 사용해서 문자를 배치하도록 하였습니다.
이외에 여러 점으로 구성된 annotation 즉 polygon의 경우에는 Bezier curve를 사용해 문자의 곡률을 계산해냅니다. 이렇게 얼마나 curve됐는지 정도를 계산한 후 네 점으로 구성되었던 quad anno와 유사한 방식으로 각 문자의 크기와 위치를 결정한 후에 좌상단을 기준점으로 보고 그 다음 연결된 점을 통해 기울기를 계산합니다. 이후 이 계산된 기울기를 통해 문자의 방향을 조정하여 라벨을 생성하게 됩니다.

생성된 label 예시는 위 그림에서 확인할 수 있습니다.
하지만 이렇게 생성된 label조차도 pixel level 단에서 비교해본다면 약간의 간격 차이가 발생할 수 있습니다. 따라서 이렇게 생성된 라벨 안의 개별적인 문자들이 원본 영상 내의 OCR-Text 위치와 정확히 일치하지 않는 경우가 있을 수 있다는 것이죠. 하지만, 이렇게 약간씩의 간격 차이가 발생하는 것은 학습에 큰 영향을 미치지 않는다고 하는데요. 왜냐하면 본 ODM의 접근 방식은 pixel level로 OCR-Text를 완전 정확하게 segmentation하는 것이 아니라 원본 영상을 style이 제거된 binary image로 변환하는 것을 목표로 하는 것이기 때문입니다.
4. Experiment
이제 실험을 살펴보도록 하겠습니다. 본 제안된 Pre-training 기법인 ODM은 오직 합성 데이터셋인 SynthText만 사용해 사전학습하였고 이후 여러 real-data에서 fine-tuning하는 식으로 실험이 수행되었습니다.
4.1. Comparison with Detection Methods
먼저, text detection task에서의 제안된 방법론 효과를 확인하기 위한 실험입니다. 기존 text detection method인 DBNet++, PSENet, FCNet들과의 비교 실험을 진행하였습니다.
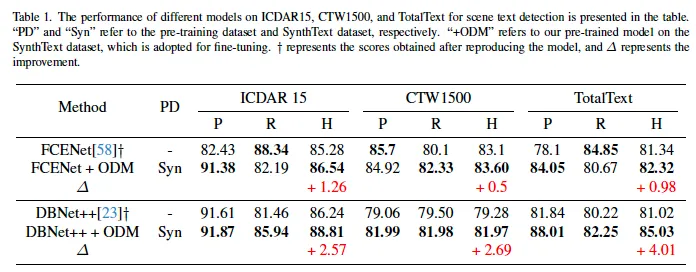
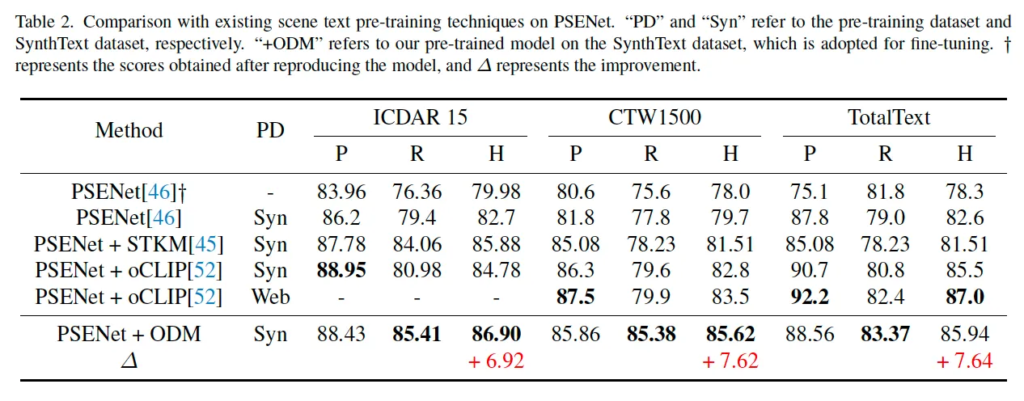
실험 결과는 table1, 2에 정리되어 있는데 table 1같은 경우는 FCENet, DBNet++과의 비교를 보이고 있으며 table2는 PSENet들과 여러 다른 pre-training 기법들을 사용했을 때의 결과를 추가로 비교하고 있습니다. 보시면 제안된 pre-trained backbone ODM을 사용한 모델들이 기존보다 더 성능이 향상된 것을 확인할 수 있습니다. 특히, table2에서 리포팅되어 있는 PSENet과의 비교에서 가장 큰 성능 향상을 보였는데요 (6%~7%정두) 이를 보아 본 사전 학습된 모델이 scene 내에서 text region을 보다 효과적으로 학습할 수 있다고 이해할 수 있습니다. 구태여 들고오지는 않았지만 detection외에 spotting 성능을 확인하는 실험도 있는데 detection과 비슷한 양상으로 ODM을 사용한 경우가 일관적인 성능 향상을 보였습니다.
또, table2에 다른 사전 학습 기법인 STKM과 oCLIP과의 비교도 확인해볼 수 있습니다. oCLIP은 synthetic 데이터셋을 학습한 경우와 Web 데이터를 사용해 학습 한 경우 두 가지가 있는데, 동일한 세팅에서 학습했을 때 기존 사전학습 기법들보다 더 좋은 성능을 보이고 있습니다. 흥미로운 점은 CTW1500 데이터셋에서의 ODM 성능이 Web image (4억 장)에서 학습된 oCLIP보다 더 뛰어난 성능을 보인 점입니다. ODM이 사용한 SynthText는 고작,, 80만 장인데 말이죠 . .
4.2. Ablation Experiments
마지막으로 ablation study 살펴보고 마치도록 하겠습니다.
Proportion Ablation
먼저 Drop-Text와 Noise-Text에서 어느정도 비율로 text를 drop하고 noise를 넣을건지에 따른 모델 성능을 평가한 실험입니다. 본 실험에서는 0%, 30%, 50%, 70% 이 네 비율로 나눠 실험을 수행하였습니다.
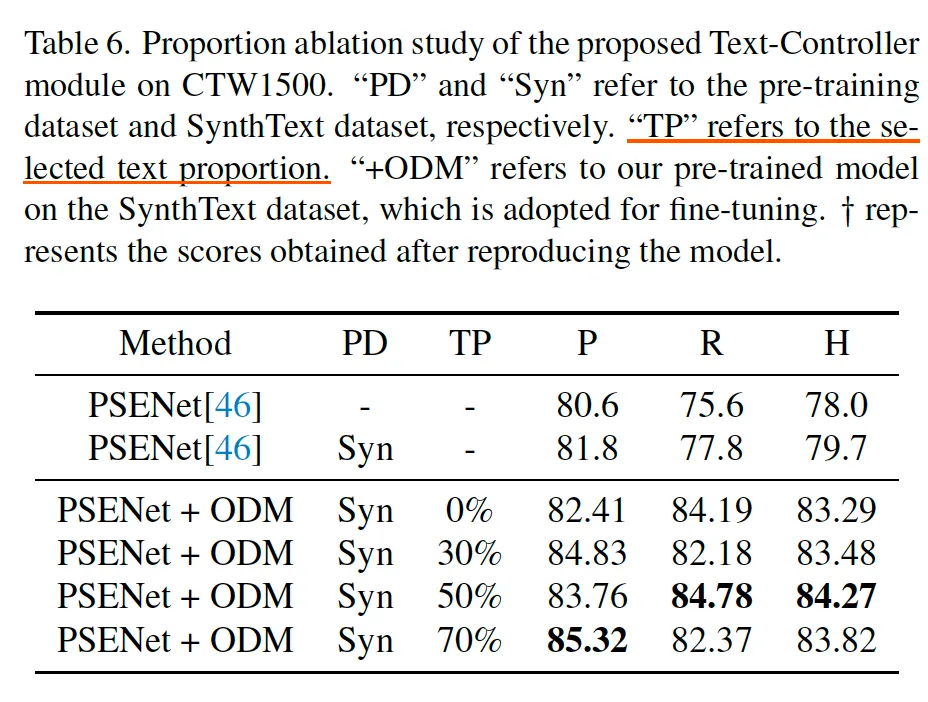
실험은 PSENet을 베이스로 ODM을 붙어 CTW1500 데이터셋에 대해 fine-tuning하였는데요 table6을 보시면 Drop-Text, Noise-Text 0%일때보다 적용했을 경우가 항상 성능이 더 좋은 것으로 보아 이 제안된 방식이 text-image alignment를 수행하며 모델 성능을 올린 것으로 해석됩니다. 30% 정도를 선택했을 경우보다는 그 보다 많은 비율인 50%, 70%를 선택하는 것이 더 효과적으로 보이지만 너무 높은 비율 (70%)를 사용하는 것보다 적절한 양인 50%만을 선택했을 경우가 가장 좋은 성능을 보입니다. 이렇게 적절한 비율로 Drop하고 Noise를 넣음으로써 보다 복잡한 상황에서도 OCR-Text와 text를 alingment하는 모델의 능력을 향상시킬 수 있었을 것이며 동시에 robustness도 높일 수 있었을 것이라고 생각했습니다.
Module Ablation

마지막으로 제안된 여러 모듈을 추가함으로써 성능을 확인해보는 실험입니다. 당연하게도 Text Encoder, Drop-Text, Noise Text, OCR Loss를 보두 사용했을 경우에 85 → 88 정도로 성능이 향상되었으며 단순 다른 모듈 없이 text를 Destylization하도록 하는 사전 학습 기법을 적용하기만 하는 것도 효과적임을 시사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
소개해주신 ODM이라는 pre-training 기법은 contrastive loss를 사용한 것으로 보이는데 이 때 positiva sample과 negative sample은 어떻게 정의되는 건가요? 한 영상 내에 있는 Text안에서 pos/neg이 구분되는 것인지 혹은 batch-leve인지 궁금합니다.
또, OCR LPIPS loss라는 것에서 사용하는 GT가 pre-trained UNet-VGG16의 prediction인 것인가요?
감사합니다.
댓글 감사합니다.
1. batch-level contrastive loss이기 때문에 positive와 negative sample은 동일 batch 내에서 정의됩니다.
2. 아뇨 OCR LPIPS loss는 모델이 생성한 binary destylization 영상과 gt binary image간의 feature-level의 차이를 줄이는 목적의 loss이기에, 여기서의 gt는 pre-trained UNet-VGG16의 prediction이 아니라 저가들이 하나의 폰트 파일이랑 텍스트 위치 정보를 기반으로 생성한 destylized binary 영상입니다. VGG16은 그냥 두 영상 간의 feature 차이를 계산하는 비교 기준으로 사용한 것 뿐입니다.
안녕하세요, 좋은 리뷰 감사합니다.
text prompt에 기반한 픽셀 단위의 이미지 reconstruction을 통해 text spotting을 위한 self-supervised learning을 하게 되네요. 다른 object-level SSL 방법이 많은데 text spotting만을 위한 SSL이 따로 있는 것이 흥미로웠습니다.
중간 과정을 보면 text style을 제거하기 위한 과정들이 나오는데, text style이 구체적으로 무엇인지, 그리고 왜 사전학습 과정에서 text style을 없애려고 하는 것인지 궁금합니다.
감사합니다.
댓글 감사합니다.
ODM에서 말하는 text style이란 정말 말 그대로 글꼴이나, 색, texture 같은 visual 적으로 text를 표현하고 있는 스타일을 의미하는 것입니다. 이를 제거하는 이유는 모델이 visual적인 noise에 영향 받지 않고 오로지 text 본질적인 의미 정보에만 집중해 학습하도록 하기 위함입니다. 이런 식으로 사전학습을 하면서 style-invariant한 representation을 생성하도록 하면 이후에 실제 style이 다양한 real image에도 robust하게 대응할 수 있겠죠.
안녕하세요 정윤서 연구원님 좋은 리뷰 감사합니다.
ODM 과정을 위한 라벨을 생성하는 과정이 굉장히 흥미로운 것 같습니다. 저자는 본 ODM의 접근 방식은 pixel level로 OCR-Text를 완전 정확하게 segmentation하는 것이 아니라 원본 영상을 style이 제거된 binary image로 변환하는 것을 목표로 하는 것이기 때문에 실제 이미지와 라벨의 차이가 중요하지 않다고 했는데 이부분이 이해가 잘 되지 않습니다. 이미지 정보만을 활용하여 이미지 내 존재하는 언어의 특징을 추출하는 task의 특성상 라벨과 이미지의 align이 맞지 않는 다면 어느정도의 성능 하락이 있을 것으로 예상되는데 라벨 생성 cost가 너무 크기 때문에 어느정도의 trade-off라고 생각하면 될까요? 같은 관점에서 style을 없애는 것이 어떻게 도움이 될지 궁금합니다.
감사합니다.
댓글 감사합니다.
우선, ODM이 text의 style에 영향을 받지 않고 text의 content에만 집중하도록 하기 위해 style을 없애는 것입니다. 그럼 라벨이 실제 이미지와 차이가 생기게 될텐데, 결국 ODM이 하려고 하는건 정확한 위치 정보를 알고 segmentation을 하는 것이 아니라 텍스트의 content를 reconstuction하는 것입니다. 예를 들어서 영상 내에서 ‘home’이 기울어지고 독특한 폰트로 적혀 있다고 할 때 라벨은 하나의 정해진 폰트로 ‘home’이 그 비슷한 위치에 있기만 한다면 모델이 이 영상 내 이 위치쯤 ‘home’이 있다는 것을 학습해가는 것으로 조금씩 align이 맞지 않더라도 큰 문제는 안될 것으로 예상됩니다.