Abstract
articulated object(관절이 존재하여, 변형이 가능한 물체)를 조작하는 것은 embodide AI의 일반화 달성을 위해 중요한 연구로, 기존의 3D vision 연구는 주로 물체의 depth 정보를 인식하고 pose를 탐지하는 것에 초점을 맞춰왔습니다. 그러나 실제 환경에서는 투명한 뚜껑, 반사가 심한 손잡이와 같이 depth 정보를 얻기 어려운 상황이 존재하며, 또한 유연한 manipulation에 필요한 part 기반의 다양한 상호작용에 대한 이해가 부족합니다. 따라서 해당 논문은 articulated object의 조작을 위한 대규모의 part-centric 데이터 셋을 제안하고 articulated object의 조작 일반화를 위한 새로운 프레임워크를 제안합니다. 최신 연구들과 성능을 비교하였으며, 실험은 시뮬레이션과 실제 환경에서 모두 이루어졌습니다.
Introduction
articulated object는 노트북과 같이 관절이 존재하는 물체를 의미하며, 이런 물체는 실생활에 굉장히 많이 존재합니다. articulated object는 rigid object와 달리 다양한 기능으로 이루어진 다양한 파트로 구성되어 이를 이해하고 조작하기 위한 일반화가 어렵습니다. 기존 연구에서는 객체간의 유사성을 암묵적으로 부호화하여 일반화하는 중간의 표현을 개발하려는 시도와 articulated object에 대하여 7-DoF Pose로 표현하는 GAPart(Generalizable and Actionable Part) 연구가 이루어졌습니다. 그러나, 이러한 방식은 다음의 두가지 한계가 존재합니다.
먼저, point cloud 데이터에 의존하여 투명한 재질이나 반사가 심한 재질에 대해서 실제 depth 정보 취득이 어려워 모든 물체로의 일반화가 어렵습니다. depth 추정 방식을 이용하거나 stero IR을 이용하는 연구가 존재하지만, 데이터 셋의 한계로 인해 일반화가 어렵다고 합니다. 또한, articulated object에 대한 조작을 예측하기 위한 데이터와 방법론이 부족합니다. articulated object로 구성된 데이터가 충분하지 않아 물체의 특정 파트에 대한 조작 예측 결과가 실제로는 실행이 불가능하기도 하며, affordance 영역을 예측하는 방식은 안정적으로 물체를 잡기가 어렵습니다.
저자들은 이러한 기존 연구의 한계를 극복하고자 GAPartManip라는 대규모의 합성 데이터 셋을 제안합니다. 해당 GAPartManip는 실제와 유사한 물리 기반의 IR 이미지를 렌더링하여 다양한 장면에서의 part를 고려할 수 있도록 하며, part-oriented actionable interection pose annotation을 다양한 articulated object에 대하여 제공합니다.(이게 무슨말이냐면, 관절형 물체인 articulated object의 각 부분이 어떻게 움직일 수 있고 상호작용가능한지에 대한 정보를 제공한다는 것 입니다.) 이러한 GAPartManip 데이터를 활용하여 depth reconstruction 네트워크와 pose를 추정하는 네트워크를 별도로 만들어 모듈식으로 구성하여 새로운 articulated object 조작을 위한 프레임워크를 제안하였으며, 시뮬레이션과 실제 세계에서 모두 SOTA를 달성하였다고 합니다.
해당 논문의 contibution을 정리하면
- 사실적인 물리 기반의 렌더링과 다양한 장면에서 articulated object의 조작 가능한 pose 정보라 포함된 대규모의 GAPartManip 데이터 셋 제안
- articulated object 조작을 위한 새로운 프레임워크 제작 및 각 모듈을 개별적으로 평가하여 효과를 입증함
- 실제 환경에서 다양한 실험을 통해 SOTA를 달성
GAPartManip Dataset

해당 논문은 실제 환경에서 다양한 articulated object 조작을 위한 데규모 데이터 셋 GAPartManip를 제안하였습니다. GAPartManip는 노트북, 상자, 양동이, 문 등 19가지의 가정용 물체 카테고리에 대해 918개의 인스턴스로 구성됩니다. 실내 장면에서 사실적인 렌더링을 수행하며, 렌더링을 통해 RGB 이미지와 IR 이미지, depth jmap과 part 수준의 segmenation을 생성합니다. 또한 각 부분에 대한 상호작용 가능한 pose 정보를 생성하였으며, 총 241,680개의 데이터에 대해 80억개 이상의 pose 정보로 구성됩니다. 위의 Fig. 2는 데이터 셋 예시이며, Fig. 3은 데이터 셋을 생성하는 과정입니다.
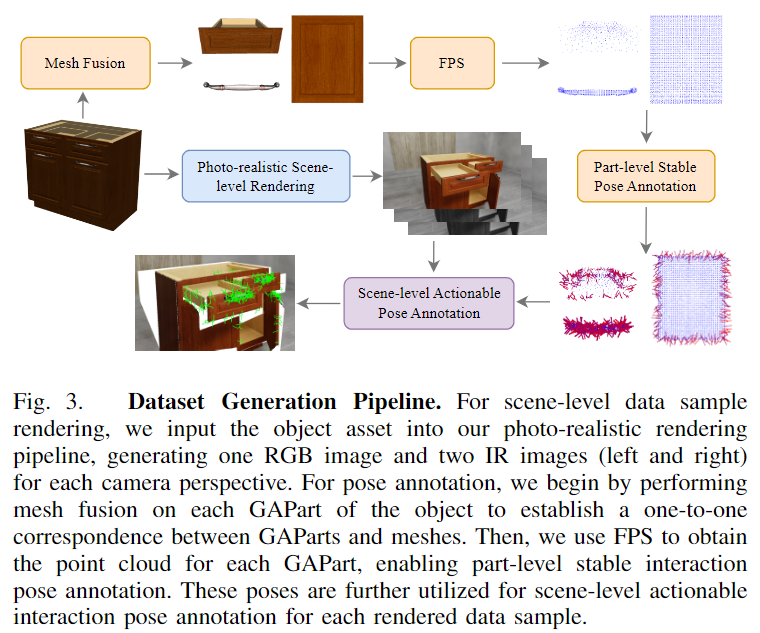
#1. Photo-realistic Scene-level Rendering
먼저, 데이터셋은 NVIDIA Isaac Sim을 이용하여 이용하여 구축하였다고 합니다. 해당 시뮬레이터를 이용하여 RealSense D415의 RGB와 IR image를 취득하는 방식을 시뮬레이션하였다고 합니다. IR projector와 RGB 카메라, 2개의 IR 카메라로 이루어진 D415시스템을 재현한 뒤, D415로 scene에 구조광을 투영하였다고 합니다. (여기까지밖에 설명이 없는데, Fig. 2의 Photo-realistic Scene-level Rendering 이후의 3개의 이미지가 있는 것을 보면 RGB 카메라와 왼쪽 오른쪽 IR 카메라로 촬영된 영상을 생성하였다는 것을 이렇게 표현한 듯 합니다.)
또한, 이전연구들이 real-world의 다양한 조명과 재질 특성을 반영하기 위해 domain randomization기법을 적용하였으며 저자들도 다양한 조건과 재질에서 IR을 모사하기 위해 동일 객체를 20가지의 다른 scene으로 주변 조명과 배경, 재질을 무작위로 변경하여 랜더링하였습니다. 모든 파트에 대하여 투명, 금속 재질 등의 속성을 무작위로 적용하였으며, 관절의 한계를 고려하여 각 파트의 pose를 무작위로 설정하였습니다. 이후 scene level의 렌더링을 위해 각 scene에 대해 객체와 파트를 중심으로 모두 서로다른 5개의 시점을 설정하여 영상을 생성합니다.
#2. GPU-accelerated Scene-level Pose Annotation
<Part-level Stable Pose Annotation>
먼저 object에서 파트의 mesh를 분리한 뒤 FPS를 적용하여 다운샘플링하여 pose 샘플링을 위한 후보 포인트들을 생성합니다. 이후 각 후보 포인트에 대하여 V×A×D 후보 pose를 균일하게 생성합니다. 여기서 V는 그리퍼의 view 수, A는 그리퍼의 회전 수, D는 그리퍼의 깊이 수를 의미합니다. (논문에서 V=64, A=12, D=4로 설정하였다고합니다.)
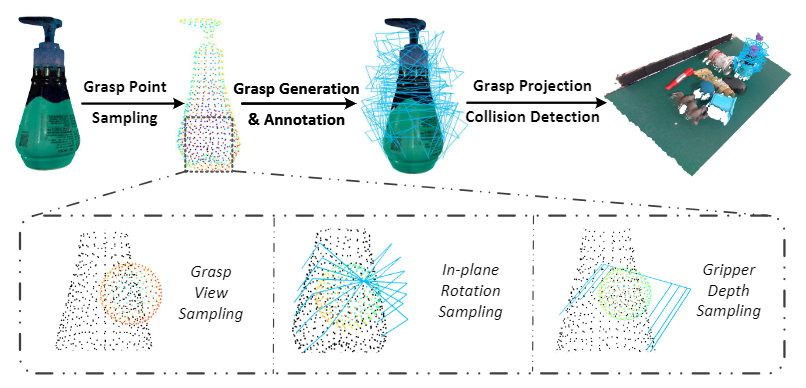
조금더 자세히 설명하자면, 해당 논문이 따르는 pose annotation 방식은 GraspNet으로, 위의 그림이 GraspNet에서 Pose를 annotation하는 과정입니다. 물체에 대하여 후보 point들을 선정한 뒤, 각 포인트에 대해 구형을 균일하게 샘플링하여 view V를 만들고, 각 view에 대해 가능한 회전 A와 depth D를 설정합니다.
<Scene-level Actionable Pose Annotation>
파트에 대한 grasping pose를 구하기 위해, 먼저 pose annotation을 scene에 투영한 뒤, 불가능한 pose들을 필터링합니다. 해당 파트 내에서 포인트와 정렬이 맞지 않는 경우와 다른 물체와 충돌이 이루어지는 경우는 모두 제거합니다. 그러나 이러한 방식으로 3차원으로 투영하여 포인트와의 충돌여부를 고려하는 방식은 계산에 많은 시간이 소요되며, 저자들은 필터링과정을 CUDA기반의 최적화를 적용하여 각 기존의 방식대비 150배 속도를 향상시켰으며(5분 ->2초로 단축하였다고합니다), 해당 과정을 통해 3일만에 필터링을 완료할 수 있었다고합니다.(1년걸릴 걸 3일로 단축했다고합니다. 코드라도..어떻게 최적화하였는지는 자세한 정보가 없고 코드도 없네요.. 어딘가에 게재되기를 기다려야할 듯 합니다..)
Framework
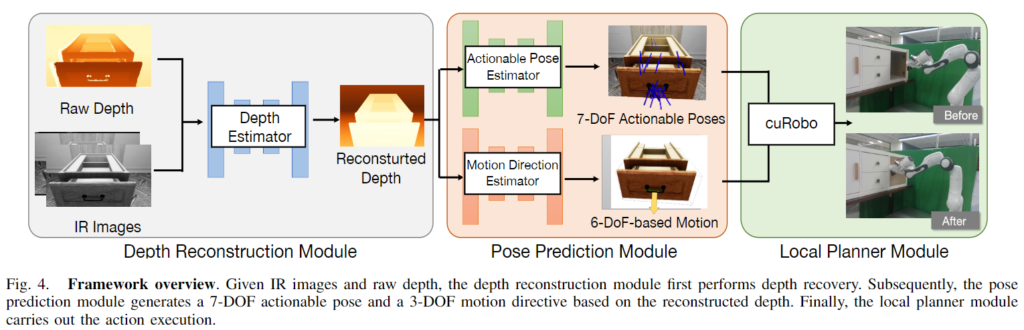
저자들은 articulated object에 대한 grasping을 위해 새로운 프레임워크를 제안하였으며, Fig. 4가 이에 해당합니다. depth reconstruction 모듈과 pose prediction 모듈, local planner 모듈로 이루어지며 각각에 대해 조금 더 설명을 드리겠습니다. (각 파트들은 대부분 기존 연구들을 활용하고있습니다.. 최근 리뷰한 논문들이 다 기존 연구를 가져다 자신들의 데이터로 미세조정을 하였다는 내용들이네요..)
#1. Depth Reconstruction module
먼저, 저자들은 투명한 부분이나 반사가 심한 재질 등에 의해 노이즈가 발생하는 depth를 보완하기 위해 RGBD 이미지로부터 depth reconstruction을 수행합니다. 이때 해당 모듈로는 D3RoMa라는 기존 연구를 활용하였으며, 저자들이 제안한 데이터셋으로 fine-tuning을 수행하였다고 합니다.
#2. Pose Prediction module
저자들은 강체에 대한 6D pose예측이 아니라, 부품에 대한 grasping pose와 이후 2D 이동 방향에 대한 예측을 수행하고자 하였으며, 이를 위해 actionable pose를 추정하는 SOTA 방법론인 Economicgrasp가 물체에 대한 graspness를 정의한 것에 아이디어를 가져와 물체의 actionness를 구하였습니다. 또한, GraspNet을 이용하여 이동 방향을 예측하였다고 합니다. actionness는 point에 대한 actionness score s^P_i와 각 view에 대한 actionness score s^V_i로 설정하였으며, 아래의 식으로 정의합니다.
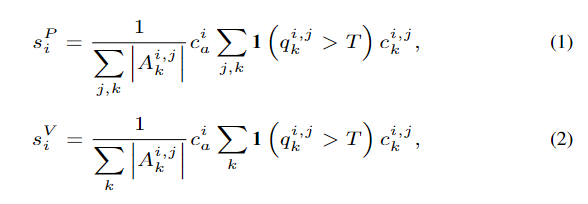
- N개의 포인트로 이루어진 point cloud가 있을 때, 각 point p_i에 대해 균일한 구형의 view v_j를 만들고, 각 view에 대해서 GraspNet의 방식으로 L개의 actionable pose 후보 A^{i,j}_k, k \in [1,L]를 생성합니다.
- grasping quality score q_k^{i,j} \in [0, 1.2]는 GraspNet-1Biliion 논문에서 grasping의 pose의 품질을 평가하기 위해 제안된 것으로, 시뮬레이터 상에서 마찰계수를 1~0.1로 0.1씩 줄여가며 파지에 성공하는 가장 작은 마찰계수\mu를 찾아 1.1 - \mu로 구하는 것으로 보입니다.
- 위의 식 (1)은 각 포인트의 actionness score s_i^{P}이고, 식(2)는 각 뷰의 actionness score s_i^{V}로, 상호작용 가능한 영역인지에 대한 actionable label c_a^i \in \{0,1\}과 각 pose에 충돌이 발생하는 지에 대한 collision label c_k^{i,j} \in \{0,1\}를 이용하여 구하게됩니다.
또한, 사전학습된 motion 방향을 예측하는 GAPartNet을 이용하여 actionable 영역을 graping한 후 어디로 이동할지에 대해 예측을 하게 됩니다.
#3. Local Planner Module
motion planner로 CuRobo를 사용하였다고 합니다. 이는 앞서 예측된 actionable poses들로부터 궤적을 계산하고, 각 궤적에 Inverse Kinemetics를 적용하여 관절의 각도를 계산하는 것 입니다. (Inverse Kinemetics란 특정 위치에 대하여 End-effector의 목표 Pose가 주어졌을 때, 이를 만족하는 관절들의 각도를 구하는 것입니다.)
Experiments
실험은 각 모듈에 대해 진행한 뒤, 전체 프레임워크에 대한 평가를 진행합니다.
1. Depth Estimation Experments
저자들이 제안한 GAPartManip 데이터 셋으로 depth estimation에 대한 평가를 진행합니다. 데이터는 8:2로 train과 test를 분할하고, 모든 카테고리가 train과 test에 분포할 수 있도록 하였다고 합니다.(최근 많은 연구들이 Unseen을 고려한 split으로 구성하려는 흐름과는 차이가 있네요)
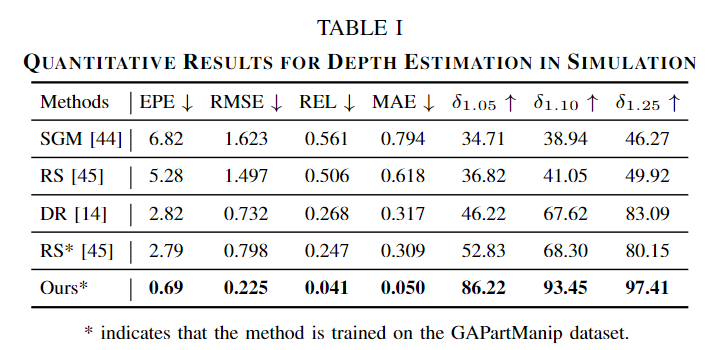
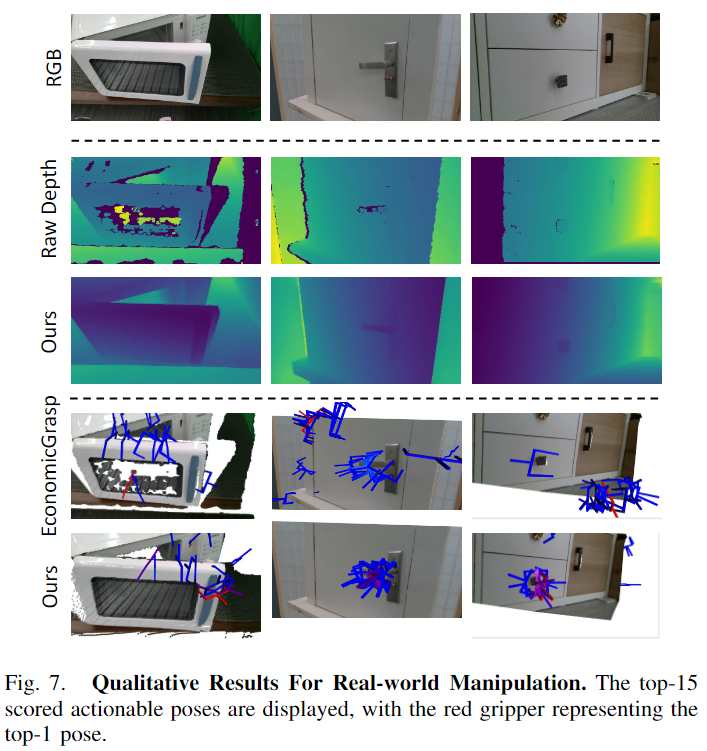
Table 1이 이에 대한 실험 결과로, 높은 성능을 달성하고 있다고 이야기합니다. 그런데 자세히 보시면, RS*과 Ours*만 저자들의 데이터 셋으로 학습이 된 성능이라 아쉽습니다.. 기존 데이터 셋에 학습하였을 때 가장 좋은 성능을 보였던 DR(Diffusion을 이용한 stereo depth estimation 방법론 D3RoMa)에 대해서도 학습하여 실험을 해보았으면 더 설득력이 있을 것 같아 아쉽습니다. 아래의 Fig. 4는 depth estimation 결과에 대한 정성적 결과로, 유리와 같이 까다로운 재질에 대해서는 Real world 데이터에 대해서 Raw 데이터보다도 더 좋은 품질의 depth map을 만들어내고 있다는 것을 어필합니다.

2. Actionable Pose prediction Experiments
저자들은 해당 파트는 articulated object에 대한 actionable pose estimation 성능 개선에 저자들이 제안한 데이터 셋의 효과를 검증합니다. 여기서는 데이터를 7:3으로 train과 test로 나누고, 카테고리를 Seen, Seen과 유사한 객체들로 이루어진 Unseen, novel instance 카테고리로 나누었다고 합니다.(각 모듈에 대한 데이터 구성을 다르게 하는 것에 대해 의문이 생깁니다…)
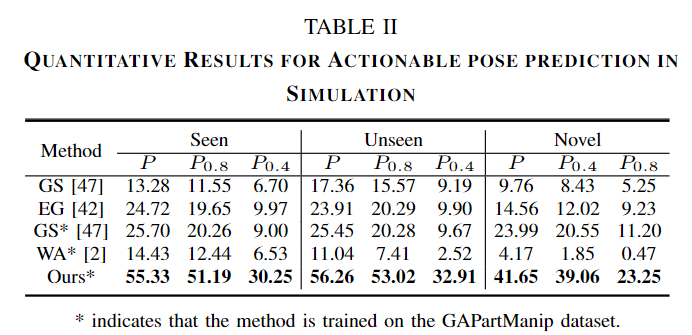
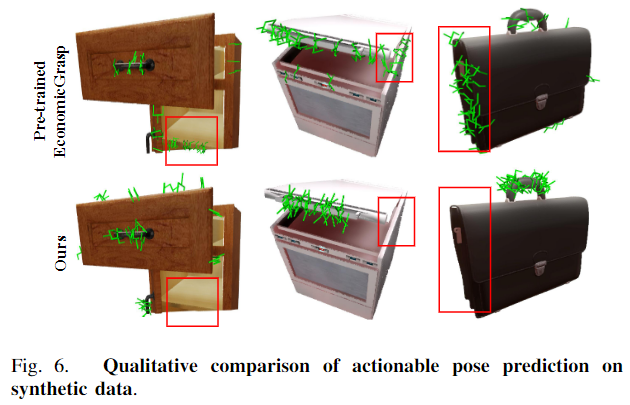
위의 Table2는 작업 성공률에 대한 precision으로, 시도 횟수에 대한 성공 횟수를 의미하며, 아래첨자는 마찰계수를 의미합니다. 실험 결과를 통해 저자들이 제안한 방식이 가장 좋은 성능을 보였다는 것을 확인할 수 있습니다. 아래의 Fig. 6은 정성적 결과를 나타낸 것으로, 빨간 박스에 해당 하는 영역들을 통해, articulated object에 대한 grasping pose가 개선되었음을 이야기합니다.
3. Real-World Experiment
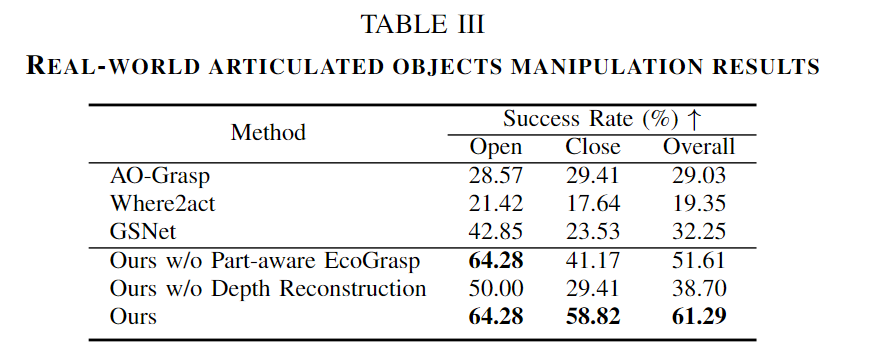
GAPartManip는 시뮬레이션상의 데이터로, 저자들은 real-world에서 작동 가능한지에 대한 평가를 수행하였습니다. 서랍장, 박스, 전자레인지에 대하여 프랑카 로봇으로 Realsense 카메라로 실험을 진행하였으며, Table 3은 Open과 Close에 대해 각각 14번과 17번의 시도에 대한 성공률을 리포팅한 결과입니다. Ours의 방식이 전체적으로 61.29%로 기존 방법론대비 성능이 크게 개선되었음을 어필합니다. 아래의 Fig. 7은 이에 대한 정성적 결과를 나타낸 것 입니다. 총 15개의 상위 actionable pose를 나타내었고 그중 빨간색은 가장 score가 높은 pose를 의미합니다.
안녕하세요 승현님 리뷰 감사합니다
articulated object에 대한 grasping능력을 일반적으로 향상시킨 논문인 것 같은데요, 강체에 대한 6D pose예측과 부품에 대한 grasping pose와 이후 2D 이동 방향에 대한 예측이 정확히 어떻게 다른건가요? 조금 더 디테일한 예측을 한다고 생각하면 되는걸까요? (전자레인지를 예로 들면 전자레인지에 대한 6d pose가 아닌 전자레인지 손잡이에 대한 6d pose + 이동경로 인건가요?)
질문 감사합니다.
Grasping pose는 물체를 잡을 때 그리퍼의 pose를 예측하는 것이며, 2D 이동 방향은 잡은 이후의 action을 수행하기 위해 이동할 방향에 대한 예측 입니다.
말씀하신 예시로는 전자레인지 손잡이에 대한 6d pose + 이동경로로 이해하시면 될 것 같습니다.
안녕하세요, 좋은 리뷰 감사합니다.
#1에서 관절의 한계를 고려하여 각 파트의 pose를 무작위로 설정하였다고 했는데, 이는 이미지 레벨에서 이루어지는 것일까요 .. ? 이미지 레벨에서 pose를 무작위로 설정하는 과정의 필요성이 잘 이해가 되지 않아 해당 과정의 목적이 무엇인지 조금 더 설명해주시면 감사하겠습니다.
질문 감사합니다.
관절의 각도를 고려하여 각 파트의 pose를 무작위로 설정하였다는 것은 시뮬레이터 상에서 3D asset에 대한 표현으로 이해하였습니다. 이후 시뮬레이터 상에서 물체의 자세와 구성을 다양하게 한 뒤, 이를 2D 영상으로 렌더링하게 됩니다. 여기서 pose를 무작위로 설정한 것은 다양한 데이터를 포함하기 위한 것 입니다. 해당 논문에서 articulated object라 표현하였는데, 물체는 관절이 있을 때 여러 형태가 되도록 변형이 이루어질 수 있으므로 이러한 다양한 형태의 물체를 표현하기 위한 것 입니다.