안녕하세요, 55번째 x-review 입니다. 이번 논문은 arxiv 2025년도에 올라와있는 논문으로, 지난 주 리뷰한 Marigold 모델을 depth completion으로 확장한 방법론 입니다.
그럼 바로 리뷰 시작하겠습니다 !

1. Introduction
depth completion은 이미지를 가이드로 해서 Fig.1과 같이 sparse한 depth 값이 들어왔을 때 dense한 depth map으로 변환하는 task 입니다. 기존 연구는 주로 CNN이나 트랜스포머 모델을 기반으로 주어진 세팅 안에서 좋은 결과를 얻고 있었습니다. 그러나 그러한 모델들은 일반화가 잘 이루어지지 않아 새로운 도메인으로 넘어가면 제대로 동작하지 못하는 경우가 발생합니다. 이는 depth 센서가 거의 표준화되어 있지 않고 각 시스템마다 고유한 샘플링 방식이나 데이터 차이, 그리고 발생하는 노이즈가 특성을 가지고 있기 때문입니다.
반면에, 저자가 말하기로 monocular depth estimation은 depth completion보다 훨씬 일반화가 잘 이루어져서 “in the wild” 환경에서도 처리할 수 있을 정도라고 이야기하고 있습니다. 그럼 왜 depth completion은 estimation에 비해 일반화가 잘 이루어지지 못하는 것일까요 ? 그에 대한 답으로 더 강력한 visual prior의 유무에 있다고 말하고 있습니다. monocular depth estimation 모델은 DINOv2나 Stable Diffusion과 같은 FM을 기반으로 만들어져서 real world의 시각적인 구조에 대한 풍부한 prior를 전달받을 수 있는 것 입니다.
그래서 저자는 depth completion도 estimation의 발전 정도를 따라갈 수 있도록 monocular depth estimation을 위한 Latent Diffusion Model(LDM)인 Marigold를 확장하여 Marigold-DC를 설계하였습니다. Marigold를 기본으로 하여 추가적인 가이드 정보를 통해 sparse depth map을 처리할 수 있도록 하였습니다. 가장 중요한 것은 Marigold-DC는 test-time 최적화를 기반으로 해서 Marigold 모델을 변경하지 않기 때문에 베이스 모델의 성능이 저하된다거나, 학습 데이터를 추가로 수집하는 cost를 줄일 수 있다는 것이라고 하네요.
Marigold와 유사하게, 본 논문의 guidance는 DDPM의 반복적인 특성을 활용한다고 합니다. DDPM을 활용하는 여러 장점을 얘기하는데요, 그 중에서 완전히 학습된 DDPM도 inference할 때 적절한 가이드 신호를 넣으면 특정한 출력으로 유도할 수 있기 때문에 재학습 없이도 특정 의도에 맞게 용도를 변경할 수 있다는 장점을 어필하고 있습니다.
본 논문에서는 DDPM의 장점을 가지고 사전학습된 mono depth estimator의 추론 과정에 추가적인 depth를 가이드로 제공함으로써 depth completion을 위한 test-time 가이드를 활용합니다. 이런 Marigold-DC의 main contribution을 정리하면 다음과 같습니다.
- mono depth estimation의 관점에서 depth completion으로 확장하여 SOTA mono depth estimator에 포함된 visual 지식과 일반화 능력을 활용
- sparse depth 정보를 사전학습된 LDM의 diffusion 과정에 통합하는 과정을 도입하여 모델 구조를 수정하거나 베이스 모델을 재학습하지 않고 depth completion을 수행
- latent 공간의 affine-invariant 예측을 metric 공간의 sparse depth에 맞출 수 있는 방식을 설계하여, 추론 과정에서 스케일과 시프트 파라미터를 조정함으로써 모델 예측을 metric depth 값으로 align 가능
2. Method
2.1. Guided Diffusion Formulation

본 논문에서는 depth completion을 단순 보간하는 문제로 보는 것이 아니라, 하나의 이미지만을 보고 depth를 추정하는 모델을 기반으로 sparse depth를 추가적인 가이드로 사용하여 dense depth map을 만들고자 합니다. 그래서 활용하는게 Marigold라는 사전학습된 mono depth estimator 입니다. 원래는 입력 RGB 이미지를 보고 depth map을 생성하는데, 저자는 여기에 sparse depth를 추가적인 가이드로 사용해서 예측을 하는 방식을 제안하는 것이죠.
c \in \mathbb{R}^{W \times H}를 sparse depth라고 표현하는데, sparse depth map 같은 경우에는 metric depth로 제공이 되기 때문에 Marigold에서 원래 예측하는 affine invariant depth를 metric 공간에 맞추기 위해 \hat{a}와 \hat{b}를 각각 스케일, 시프트 변수로 사용해서 모델이 예측한 depth를 조정하게 됩니다. 참고로 이 두 파라미터는 학습되는게 아니라 추론 과정에서 계속 업데이트 되는 파라미터 입니다.
Fig.2는 본 논문에서 제안하는 새로운 추론 과정을 나타내고 있습니다. 먼저 이미지를 latent 공간으로 변환한 z^{(x)}를 생성합니다. 그리고 초기 depth latent로 랜덤 노이즈z^{(d)}_T ~ \mathcal{N}(0,I)를 샘플링하여, DDIM의 스케줄러를 사용해서 50단계(T = 50)으로 추론을 진행합니다. 매번 디노이징 단계 t에서 z^{(d)}와 z^{(x)}를 합쳐서 U-Net의 입력으로 넣어 노이즈 추정값인 \hat{\epsilon}_t를 출력합니다.
여기서 일반적인 Diffusion 모델은 노이즈를 제거하면서 최종 depth 예측을 얻지만, 본 논문에서는 중간 단계에서도 예측을 “미리 보면서” 식(1)과 같이 조정하였다고 합니다.
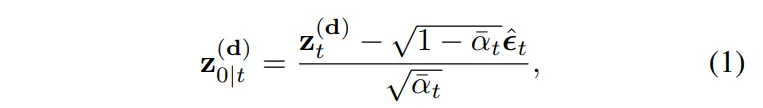
- \bar{\alpha}_t : 노이즈 스케줄러 (현재 스텝에서 노이즈가 얼마나 남아있는지를 결정)
현재 t 스텝에서 최종적으로 예측될 depth z^{(d)}_{0|t}를 계산했는데, 이는 아직 latent 공간의 값이라 이미지로 변환해야 합니다. 이를 위해 디코더를 사용해서 픽셀 레벨의 depth map \hat{d}_t로 변환하는 과정이 필요합니다. 그런데 이 상태로는 metric 공간과 맞지 않는 affine-invariant depth, 즉 정규화된 상대적인 depth 값이기 때문에 추가적인 변환을 필요하며, 변환 공식은 \hat{d}^{(m)}_t := \hat{d}_t \cdot \hat{a} + \hat{b} 입니다. 여기서 \hat{a}, \hat{b}가 앞에서 언급했던 스케일, 시프트 계수로 inference 동안 주어진 sparse depth c와 align이 맞도록 계속 업데이트 되는 파라미터 입니다.
그러면 이제 Marigold-DE는 예측한 depth map \hat{d}_m이 실제 sparse depth c와 비교해서 오차를 줄일 수 있도록 loss 계산을 해야 하는데, c가 일부 픽셀에만 depth 값을 가지고 있기 때문에 loss는 c에 유효한 값이 있는 픽셀에서만 계산되어야 합니다.
손실 함수 \mathcal{L}은 MAE, MSE 이렇게 두 가지 요소로 구성되어 있는데, 그 이유는 직관적으로 생각해봤을 때 MAE만 사용하면 세부적인 조정이 부족할 수 있고 MSE만 사용하면 일부 오류가 너무 크게 반영될 수가 있기 때문에 동일한 가중치로 사용해서 전체적인 깊이 구조와 세부적인 부분까지 동시에 최적화 할 수 있도록 하였습니다.
최적화 한다고 했는데, 그럼 무엇을 최적화하는 것일까요 ? 이 때 \hat{a}와 \hat{b}, 그리고 z^{(d)}_t가 업데이트 됩니다. 디코더와 앞선 수식(1), 그리고 U-Net을 통해 역전파를 하면서 depth 예측 모델의 여러 파트가 손실 함수를 통해 업데이트가 됩니다. 그리고 Adam optimizer를 사용해서 테스트 중에서도 모델이 예측을 조정할 수 있도록 하였습니다.
그 다음 각 디노이징 스텝에서 현재 노이즈를 제거한 결과를 기반으로 다음 스텝을 진행하게 되는데, 디노이징이 모두 완료되면 모델이 얻은 최종 depth map은 affine-invariante 상태이겠죠. 여기서 업데이트된 \hat{a}와 \hat{b}를 가지고 실제 metric 공간 단위로 변환하여 최종 depth 예측값을 반환할 수 있습니다.
위와 같은 최적화 과정은 각 디노이징 단계 T마다 추가적인 변수인 \hat{a}와 \hat{b}를 포함하여 반복적으로 진행하며 affine-invariant한 depth 예측을 sparse depth에 맞도록 align을 맞출 수 있습니다. 이는 일반적인 depth completion 모델과 유사할 수 있지만 Stable Diffusion 모델을 활용함으로써 이미지만 보고도 depth 추정이 우선 비교적 정확하게 가능하며, sparse depth에서 데이터가 부족하더라도 Stable Diffusion이 가지는 real world의 지식을 활용하여 예측이 가능하게 됩니다.
본 논문의 최적화 방식은 베이즈 규칙을 사용해서 score function을 조정하는 기존의 가이드 방식을 변형하였다고 합니다. 기존의 가이드 방식은 원하는 조건을 따르도록 유도하는 방식인데, 본 논문에서는 depth completion을 위한 sparse depth 데이터를 가이드로 모델을 유도하고 있습니다. 여기서 베이즈 규칙을 적용했다는건, 기본적으로 diffusion 모델에서 추가적인 조건(sparse depth)를 반영하기 위해 베이즈 규칙의 사후 확률을 조정한 것을 의미합니다. 저도 베이즈 규칙을 잘 알진 못하지만 정리하면, 모델이 기존의 이미지만 보고 depth를 추정하는 것 뿐만 아니라 sparse depth 데이터와 일치해야 한다는 조건도 반영하도록 만든 것이죠.
2.2. Scale and Shift Parameterization
스케일과 시프트를 적절하게 파라미터화하는 것은 좋은 퀄리티의 depth map을 얻기 위해 매우 중요한데요, 즉 \hat{a}와 \hat{b}의 값을 어떻게 설정하느냐에 따라 depth map의 퀄리티가 결정되는 것 입니다.
Marigold의 depth 예측 결과는 Affine-invariant 값이기 때문에 실제 depth 값과 직접적으로 대응되진 않습니다. 그래서 여러 개의 \hat{a}와 \hat{b} 조합이 같은 depth 구조를 표현할 수가 있기 때문에 이 두 파라미터를 어떻게 설정하느냐가 중요하겠죠. 여기서 Marigold는 [0, 1] 범위의 정규화된 값을 출력하지만, 출력으로 원하는 최종 값은 미터, 센치미터 등의 실제 거리값이어야 합니다. 따라서 변환된 깊이 값 d^{(m)}은 \hat{b}에서 시작해서 \hat{a} + \hat{b} 범위까지만 가능해야 합니다. 만약에 이 변환 범위가 [2m, 3m] 밖에 안된다면, 만약 실제 depth 값이 10m 같은 큰 값이 필요하면 모델이 이를 표현하지 못하게 됩니다. 결과적으로 모델이 출력 범위에 억지로 맞추려 하면서 예측이 틀려질 수 있다는 것 입니다. 이렇게 되면 모델이 오차를 줄이려다가 계속 같은 값으로 수렴하는 saturation 문제가 발생할 수 있습니다.
여기서 저자는 sparse depth에 대해 Least Squares하면 입력된 sparse depth 데이터를 가장 잘 맞추는 선형 변환을 찾을 수 있지만, 실제 depth 데이터가 특히나 원거리에서 부정확한 경우가 많아서 depth 예측 범위가 원래보다 작아지는 현상을 확인했다고 합니다. 그래서 모든 최적화 요소가 잘 업데이트 될 수 있도록 스케일과 시프트를 식(2)와 같이 Min-max 초기화 방법을 통해 파라미터화 하였습니다.
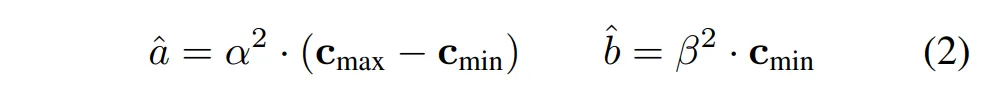
- c_{max}, c_{min} : 최대, 최소 깊이
\hat{a}는 depth 범위를 조절하는 값으로, 최소-최대 깊이 차이를 반영해서 설정하게 됩니다. \alpha^2는 학습 가능한 파라미터로, 처음에는 1로 설정하고, 최적화 과정에서 업데이트 됩니다. \hat{b}는 전체 depth 값을 이동시키는 역할로, 최소 깊이를 기준으로 설정됩니다.
2.3. Ensembling Procedure
Marigold-DC는 diffusion 모델 기반이기 때문에 같은 입력 이미지와 sparse depth가 들어가더라도 매번 조금씩 다른 depth map을 생성할 수 있습니다. 그래서 sparse depth를 가이드로 제공하더라도 완전히 고정된 값을 만들 수 없습니다. 특히나 depth 센서가 데이터를 잘못 측정하는 영역에서 모델도 더 불안정하게 예측하게 되는데요, 특히 반사되는 표면이나 엣지 영역, 그리고 먼 거리의 평면 등이 depth 센서의 한계로 인해 측정을 제대로 하지 못하는 영역들이 됩니다.
본 논문에서는 이러한 변동성을 이용해서 앙상블 기법을 metric 공간에 적용하게 됩니다. 단일 예측값만 사용하는게 아니라 여러 번 반복해서 예측한 후에 이를 조합해서 더 안정적인 결과를 만드는 것이죠.
먼저 여러 번의 예측을 수행합니다. 같은 입력 이미지와 sparse depth 데이터에 대해 여러 번 depth map을 예측하는 것이죠. 그 다음에 각 예측을 선형 변환하여 metric 단위로 변환 합니다. 그리고 나서 픽셀 단위이 중앙값을 계산하하여 최종 depth map을 생성합니다.
여기서 평균 대신 중앙값을 사용하는 이유는 평균값이 이상치에 영향을 더 많이 받기 때문에 이상치에 영향을 덜 받고 안정적인 결과를 제공할 수 있기 때문이라고 합니다. 특히 depth 예측에서 반사 표면이나 먼 배경 같은 어려운 영역에서 예측값이 튈 수 있는데 중앙값을 사용하면 이를 보정할 수 있는 것도 중앙값 사용의 이유라고 합니다.
3. Experiments
실험은 베이스 모델이 학습한 합성 데이터를 제외하고 6개의 indoor/outdoor real world 데이터셋에서 zero shot 세팅으로 평가하였다고 합니다.
- NYU-Depth V2, ScanNet, VOID, iBims-1, KITTI DC, DDAD
3.1. Comparison with Other Methods
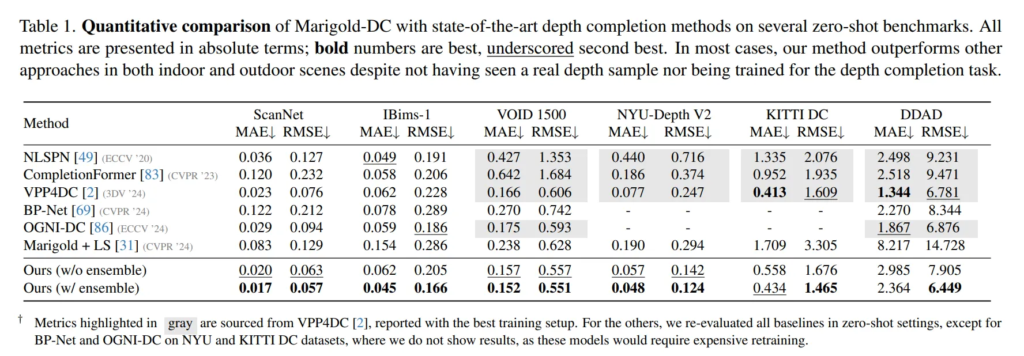

Marigold-DC는 Tab.1과 같이 NYU-Depth v2와 KITTI DC에서 좋은 성능을 보인 5개의 베이스라인과 비교하였습니다. NLSPN, CompletionFormer, 그리고 BP-Net은 멀티 모달 융합과 depth refinement 방식을 활용한 모델 입니다.
Marigold + LS는 RGB 입력만을 사용하는 기본 Marigold와 Least square를 적용한 모델로, Marigold-DC와 비교하기 위해 추가하였다고 합니다.
실험 결과, 대부분의 케이스에서 베이스라인보다 성능이 개선되었습니다. 특히 이런 결과에 대해 다른 task를 위해 합성 데이터로 학습된 베이스 모델을 사용함에도 불구하고 다른 depth completion 모델보다 개선된 성능을 보였다는 것을 강조하고 있습니다. 베이스 모델에서 제공하는 monocular depth 추정 값을 활용하면서, 동시에 sparse depth 가이드를 따를 수 있다는 것을 확인할 수 있습니다. 이는 task-specific한 학습 모델보다 visual prior가 풍부한 사전 학습에서 많은 정보를 얻을 수 있다는 저자의 가정과 일치하는 결과라고 볼 수 있습니다.
3.2. Ablation Studies
Learning rates
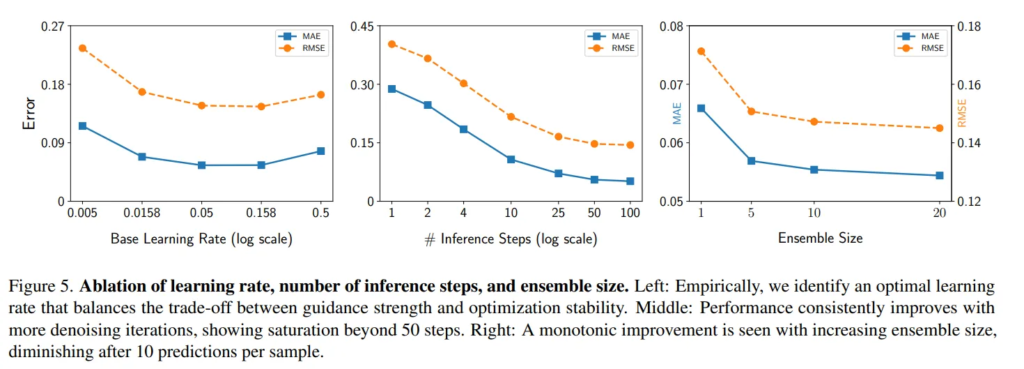
이제 ablation study로, Fig.5는 최적화 과정에서 사용한다고 했던 learning rate 조절에 따른 실험 결과를 보여주고 있습니다.
로그 스케일에서 값을 0.005에서 0.5까지 다양하게 설정하여 depth latent에 대한 learning rate를 해당 값으로, 스케일과 시프트에 대한 learning rate를 1/10으로 설정하였습니다. 실험 결과, 0.05에서 최적의 값이 보여지며 양방향으로 성능이 저하되는 것을 확인할 수 있습니다. 이 결과를 통해 값이 너무 낮으면 가이드의 영향이 약해지고, 값이 높을수록 최적화 과정이 불안해지기 때문에 본 논문의 디폴트 세팅도 0.05로 설정하였다고 합니다.
Test-time ensembling
이번엔 앙상블 사이즈에 따른 효과를 확인하는 ablation study 입니다. Tab.1과 Fig.5에서 보이는 것처럼, 단일 예측만을 사용하는 것 만으로도 이미 좋은 성능을 보이고 심지어는 SOTA를 달성하기도 합니다. 그러나 앙상블 했을 때 성능이 향상되며 앙상블 사이즈가 커짐에 따라 일반적으로 오류는 감소하지만 런타임이 선형적으로 증가한다고 합니다. 그리고 앙상블 사이즈가 10을 넘어가게 되면 상대적으로 개선 효과가 감소하기 때문에 런타임과 성능 간의 균형을 맞추어 10으로 설정하였다고 하네요.
Scale and shift initialization
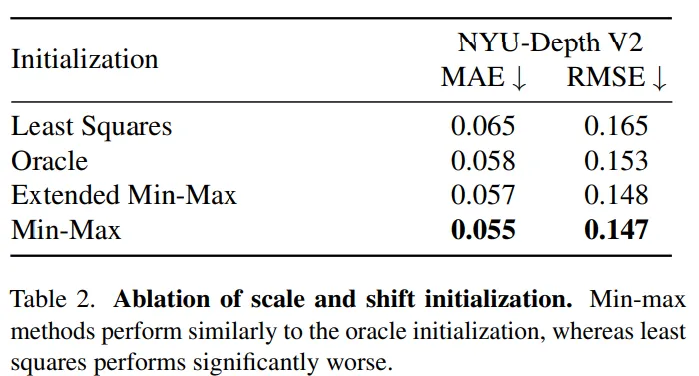
스케일과 시프트 매개변수를 초기화 하는 방식은 sparse depth에 잘 부합하는 방식으로 수렴하기 위해 매우 중요합니다. 그래서 Min-Max 초기화 이외에 다른 3개의 초기화 방법도 추가적으로 Tab.2에서 실험을 수행하였습니다.
(1) sparse depth와 align 맞추기 위한 least-squares
(2) 실제로 사용할 순 없지만 가장 완벽하다고 볼 수 있는 초기화 방식으로, sparse 데이터와 GT의 결합을 사용하는 Oracle
(3) sparse 입력이 depth에 대해 하한선만 제공한다는 가정 하에 범위를 Max보다 5%, Min보다 5% 확장하는 Min-Max 스케일링 방식
(4) sparse 입력의 최소 최대값을 매치시키기 위한 min-max scaling 방식
실험 결과, 확장된 Min-Max는 오라클 초기화는 거의 유사한 성능을 달성하고 있으며, Least Squares는 그에 못 미치는 성능을 보이고 있습니다. 우선 세팅 설명을 보면 가장 성능이 좋은 Min-Max를 단일로 사용하고 있는 거 같긴 한데, 이론적으로 이런 결과를 바탕으로 봤을 때 프레임워크 내에서 가장 잘 동작할 수 있는 방법은 Min-Max와 Extended Min-Max를 adaptive하게 변환하면서 사용하는 것이라고 하네요.
건화님 좋은 리뷰 감사합니다.
Scale and shift initialization에 대한 실험 결과에서, Oracal 방식보다 Min-Max를 사용하는 두가지 방식이 GT를 이용하는 방식보다 더 좋은 성능을 보이고 있는데, GT를 사용하는 것 보다 성능이 더 좋은 이유가 무엇일지 건화님의 의견이 궁금합니다.
안녕하세요, 리뷰 읽어주셔서 감사합니다 !
GT를 사용하는 것보다 성능이 좋은 이유에 대해서 논문에 나와있진 않습니다만,
제가 생각했을 때는 정성적 자료에도 보이듯이 GT 자체가 저희가 생각하는 완전한 clean depth가 아니기 때문에 오히려 주어지는 depth c에 대해서 min-max를 구하여 온전한 depth map을 이용하는 것이 좀 더 좋은 성능을 낼 수 있었던 이유가 아닐까 생각합니다 ! 실제로 그렇게 GT를 사용한 성능과 차이가 크지 않아서 이런 미세한 차이가 발생하는 것 같습니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
depth estimation 모델의 결과가 affine-invariant한 depth이기 때문에 metric 공간의 sparse depth map과 align을 맞추기 위한 scale, shift 파라미터화가 굉장히 중요한 부분인 것 같습니다…
여기서 궁금한게 depth estimation 모델을 metric depth를 출력하는 모델이 아니라 affine-invariant한 depth를 출력하는 모델을 사용한 이유가 있을까요 .. ? 처음부터 metric depth를 예측할 수 있는 모델을 사용하거나 혹은 그러한 모델을 사용하여 scale,shift 파라미터화 과정을 생략하였을 때의 성능에 대해서 리포팅하지는 않았는지가 궁금합니다 ! !
감사합니다.
안녕하세요, 리뷰 읽어주셔서 감사합니다.
저도 말씀하신 파이프라인이 읽으면서 계속 생각이 들었었는데, 아무래도 본 논문의 저자들이 Marigold 저자와 동일하여 depth completion으로 확장하기 위해 Marigold를 선택하지 않았나 싶습니다.
그리고 물론 metric depth를 출력할 수 있는 MDE 모델이 최근에 나오고 있긴 하지만 아직까지 대부분의 MDE 모델이 affine-invariant depth나 relative depth를 예측하기 때문에 이러한 프레임워크를 설계하였다고 생각합니다. 따라서 말씀하신 ablation study는 논문에 리포팅되어 있진 않습니다.