1. Introduction
Retrieval-augmented generation(RAG)는 LLM을 커스텀하여 long-tail knowledge를 처리하고, 최신 정보를 반영하며, 특정 도메인에 적용할 수 있는 기술을 의미합니다. 일반적으로 RAG의 동작원리는 이러합니다. 우선 dense embedding 기반의 retriever(검색기)를 이용하여 주어진 질문에 대해 문서 또는 외부 데이터베이스에서 top-$k$개의 청크된 context를 검색합니다. 그런 다음, LLM은 top-$k$개 context를 읽어 답변을 생성합니다.
그런데, 논문의 저자는 현재 RAG 파이프라인의 경우 다음과 같은 한계를 가지고 있음을 언급합니다.
1번. 많은 context 처리의 어려움
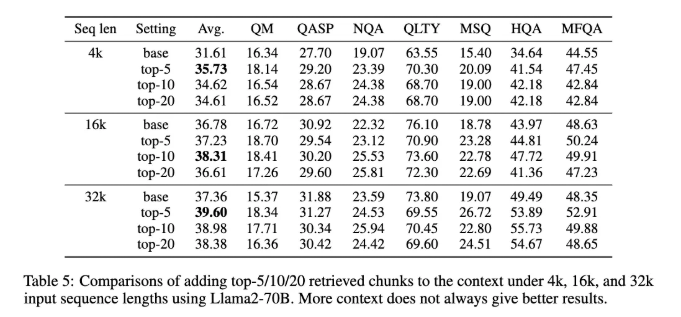
→ LLM은 너무 많은 청크된 context를 그리 잘 읽지는 못합니다. 예를 들어서, top-100개의 context를 읽는 거는 효율성 때문에라도 어렵고, 일반적으로 top-5, top-10개의 context가 더 높은 정확도를 보입니다. 이는 ICLR 2024 논문인 “RETRIEVAL MEETS LONG CONTEXT LARGE LANGUAGE MODELS”의 Table 5를 보면, top-$k$가 늘어남에 따라 성능이 하락하는 것을 볼 수 있습니다. LLM이 처리하는 context가 늘어날 수록 버거워하는 것이죠.
2번. high recall mechanism 필요
→ 만약 검색을 통해 가져오는 정보가 적거나 관련성이 낮은 경우, 모델이 올바른 답변을 만들기 어려울 수 있습니다. 예를 들어, 질문에 관련된 정보를 찾는데 실패한다면, 모델은 당연히 부정확한 답변을 생성하게 됩니다. 이 때문에 관련성이 높은 context를 보장하는 메커니즘이 필요로 합니다. 단순히 retrieval 모델에 의존하는 것은 효과적인 local alignment를 학습하기 어려워 정확하게 매칭하기 힘듭니다. 실제 상황에서는 이를 보완하고자 질문과 candidate context를 cross-encoding하는 별도의 ranking 모델이 top-$k$개의 context를 얻는데, 이는 dense embedding 기반 retriever보다 잘 동작할 수 있습니다.
3번. expert ranking model 한계
→ 하지만, expert ranking 모델의 zero-shot generalization 능력은 다용도로 사용되는 LLM 자체에 비해 상대적으로 제한적일 수 있습니다.
논문의 저자는 위의 challenge를 극복하고자 high-recall context 추출과 high-quality content 생성을 모두 수행하는 RAG instruction tuning pipeline을 설계하고자 하였습니다.
이전 연구에서 말하길, instruction tuning된 LLM은 주어진 질문과 관련된 context에서 답을 잘 추출한다고 하는데, 논문의 저자는 이를 통해서 LLM이 context의 일부가 질문과 관련이 있는지 판단하여 답변 생성을 위해서 유효한지 아닌지를 결정하는 “dual capability”가 있고, 이러한 능력들이 서로 상호적으로 강화시킨다고 가설하였습니다. 이를 기반으로 저자는 RAG framework에서 context ranking과 single LLM을 instruction tuning하는 RankRAG를 제안합니다. 추가로 context-rich QA, retrieval-augmented QA, ranking dataset을 합쳐 기존의 instruction tuning dataset을 확장하여 RAG의 retrieal, generation 단계에서 부적절한 context를 걸러낼 수 있도록 하였습니다.
본 논문의 contribution을 정리하면 다음과 같습니다.
- RankRAG 제안
- 비률이 낮은 rank data를 instruction tuning에 활용해 RAG task 성능을 향상
- RankRAG가 다른 모델에 비해서 높은 성능 달성
2. Preliminaries
2.1 Problem Setup
먼저, RAG에서는 document나 Wikipedia와 같은 context가 제공되어 기초 지식을 제공합니다. 질문 $q$가 주어지면, retriever $R$ (매개변수화된 embedding model)은 가장 관련성이 높은 top- $k$개의 context $C = \{c_1, …, c_k\}$를 먼저 검색합니다. 그런 다음, language model은 최종 답변을 생성하는데, 이 답변은 target task에 따라 짧은 구나 긴 문장이 될 수 있습니다.
2.2 Limitation of Current RAG Pipelines
본격적으로 RankRAG를 소개하기 전에 현재 RAG가 가지고 있는 한계점들에 대해서 설명드리고자 합니다. 본 논문에서 언급한 한계점은 2개로, “Limited Capacity of Retriever”, “Trade-off of Picking Top-k Contexts”가 있습니다. 좀더 각각에 대해서 설명드리겠습니다.
- Limited Capacity of Retriever : 현재 RAG 시스템은 주로 효율성 고려를 위해서 BM25와 같은 sparse retrieval 혹은 BERT 기반의 중간 크기의 embedding model을 retirever $R$로 사용합니다. 이러한 모델은 질문과 document를 각각 encoding하고 vector similarity metric을 이용해 질문과 document 간의 유사성을 계산합니다. 그런데, embedding model의 한정된 용량과 query와 document의 독립적인 처리는 질문 $q$와 document $d$간의 텍스트 적합성을 추정하는 능력을 제한하여 새로운 도메인으로 확장하거나 새로운 task에 대해서 대응하기 어렵다고 합니다.
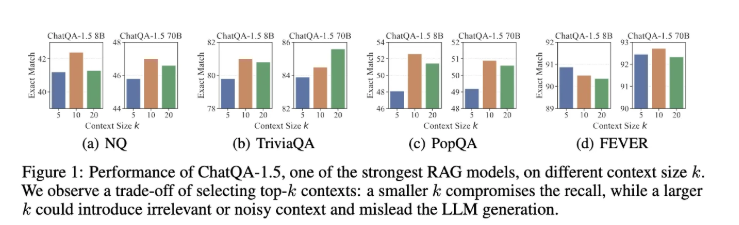
- Trade-off of Picking Top-k Contexts : 많은 SOTA LLM은 대량의 검색된 context를 입력으로 받아 답변을 생성합니다. 하지만, 성능의 경우, context가 증가함에 따라, 즉 k가 증가함에 따라 성능이 빨리 정체되는 경향이 있습니다. 이를 Figure 1을 통해서 확인할 수 있는데요. Figure 1을 보면, 성능이 높은 RAG 모델 중 하나인 ChatQA-1.5를 예시로 들었는데, k=10일 때 답변 생성 성능이 정체되는 결과를 볼 수 있습니다. 일반적으로 더 작은 k는 쿼리와 관련된 정보를 포착하지 못해 recall이 저하되는 반면, 더 큰 k는 recall을 개선하나 LLM이 답변을 생성할 때 이를 방해하는 무관한 콘텐츠를 포함할 가능성이 있습니다.
3. RankRAG

본 논문에서는 위에서 언급한 한계점을 해결하고자 RankRAG를 제안하였습니다. LLM을 instruction-tuning하여 질문과 context 간의 관련성을 포착하고 검색된 context를 답변 생성에 활용할 수 있도록 합니다. 자 그럼, 단계별로 설명드리고자 합니다.
3.1 Stage-1: Supervised Fine-Tuning (SFT)
일반적으로 instruction-tuning 혹은 supervised fine-tuning (SFT)는 LLM이 instruction을 더 잘 하도록 만들며 downstream task에서 개선된 zero-shot 결과를 보입니다. 이를 위해서 높은 수준의 혼합형 instruction dataset을 구축하였습니다. 다음과 같은 dataset을 이용하였습니다.
- a private crowd-sourced conersation dataset, public conversation dataset : OpenAssistant, Dolly, SODA
- a long-form QA dataset : ELI5
- LLM-generated instruction : Self-Instruct, Unnatural Instruction
- FLAN and Chan-of-thought dataset
대략적으로 총 128K sample로 구성되어 있다고 하며, SFT data와 평가 data간의 중복이 없도록 구성하였다고 합니다.
3.2 Stage-2: Unified Instruction-Tuning for Ranking and Generation
Stage-1에서 SFT를 통해서 LLM이 basic한 instruction-following capablities를 가지도록 하였다면, Stage-2에서는 RAG 능력을 개선하고자 합니다. RankRAG는 LLM을 retireval-augmented generation 뿐만 아니라 context ranking 모두를 고려하기 위한 instruction tuning을 수행합니다.
이를 위해서 Stage-2는 5가지 part로 구성되어 있습니다.
- STF data from Stage-1 : Stage-1에서 구축한 데이터셋을 의미합니다.
- Context-rich QA data
: 여기서는 다양한 context-rich QA task를 활용해 LLM이 context를 더욱 잘 사용하도록 합니다. 데이터는 다음과 같이 2가지로 구성되어 있습니다.
- standard QA and reading comprehensive dataset : DROP, NarrativeQA, Quoref, ROPES, NesQA, TAT-QA
- conversational QA datasets : HumanAnnotatedConvQA, SyntheticConvQA. 해당 데이터셋에 대해 간단히 설명하면 사용자와 assistant 간의 대화를 포함하여 모델은 이를 기반으로 답변을 생성하여야 합니다.
- Retrieval-augmented QA data
- Context ranking data : MS MARCO passage (context) ranking dataset을 사용하였습니다.
- Retrieval-augmented raking data : SQuAD, WebQuestions에 BM25을 결합하여 사용하였습니다.
3.3 RankRAG Inference: Retrieve-Rerank-Generate Pipeline

RankRAG는 추가적인 reranking step을 포함하기 때문에 각 질문에 대해서 retrieve-rerank-generate pipeline으로 확장됩니다. inference 각 단계에 대해서 설명드리겠습니다.
- retriever R이 먼저 데이터베이스로부터 top-k개의 context를 검색합니다.
- RankRAG 모델은 질문과 검색된 N개의 context 간의 relevance score를 계산합니다. Table 1에 있는 promt를 사용하는 데, 답변이 True로 생성될 확률을 구한 후, context를 다시 정렬하여 top-k(k << N)개 context만 남겨둡니다.
- 최종적으로, 질문과 함께 top-k context를 합쳐 RankRAG 모델로 전달하여 최종 답변을 생성합니다.
본 논문에서는 effiency에 대해서도 언급하는데요. 추가적인 reranking step을 가져가면 추가 처리 시간이 발생하기 때문입니다. 실제로 각 질문에 대해 intext 생성 및 검색에 소모되는 시간을 t_1로, LLM을 사용하여 relevance score를 계산하는데 소모하는 시간을 t_2, 답변 생성하는데 드는 시간을 t_3라고 나타낸다면, 추가된 시간 overhead는 \frac{N\times t_2}{t_1 + t_3}라고 합니다.
4. Experiments
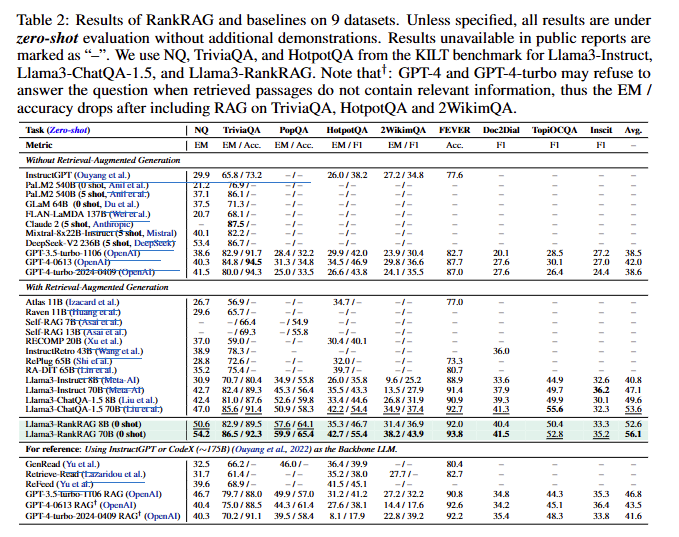
논문의 저자는 해당 방법론에 대해서 성능을 굉장히 다양한 벤치마크에서 보였는데요. Table 2를 보시면 zero-shot 성능을 확인하실 수 있습니다. Llama3를 기반으로 RankRAG를 사용했을 때, RAG를 사용하든, RAG를 사용하지 않든 RankRAG가 가장 높은 성능을 보이는 것을 알 수 있습니다.
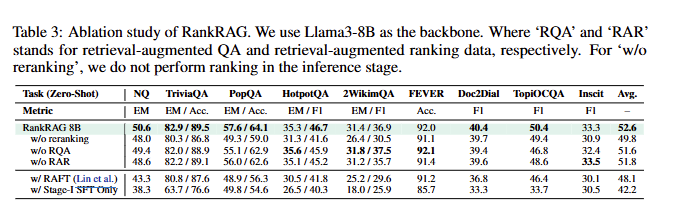
Table 3를 통해 ablation study를 확인할 수 있습니다. 우선 conbtext ranking을 제거한 경우 모든 벤치마크에서 성능이 하락한 것을 볼 수 있으며, RQA(retrieval-augmented QA), RAR(retireval-augmented ranking)을 제거했을 때 성능이 하락한 것을 통해 RQA, RAR이 성능 향상에 도움이 되었음을 볼 수 있습니다. 또한 재미있는 부분은 RAFT 또한 실험해봤다는 것인데요. RAFT는 domain-specific하게 동작하기 위해서 약간의 fine-tuning된 RAG라고 생각하시면 되는데, 성능이 하락한 것을 볼 수 있습니다. 이에 대해서 저자는 RAFT는 instruction tuning 동안 검색된 context를 개별적으로 처리하기 때문에 동일한 학습 데이터를 사용하는 RankRAG와 비교할때 optimal한 결과를 산출한다고 합니다.
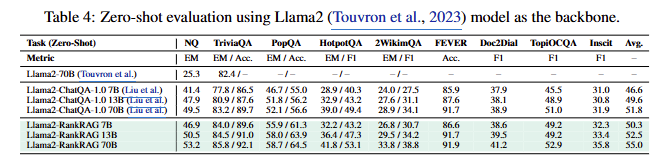
본 논문에서는 백본 변경에 대해서도 실험을 진행하였는데요. 기존 Llama3에 비해서 Llama2로 변경했을 때 성능이 떨어진 벤치마크도 있지만 얼추 비슷한 성능을 보이는데 이는 RankRAG가 백본 상관없이 강인하게 동작한다는 것을 보여줍니다.
김주연 연구원님 좋은 리뷰 감사합니다.
expert ranking model 한계에 대한 설명 중, ‘LLM이 context의 일부가 질문과 관련이 있는지 판단하여 답변 생성을 위해서 유효한지 아닌지를 결정하는 “dual capability”가 있고, 이러한 능력들이 서로 상호적으로 강화시킨다고’ 하셨는데, 여기서 의미하는 이러한 능력들은 질문과 관련된 context에서 답변을 추출하는 능력과 답변이 유효한지를 판단하는 능력을 의미하시는 건가요?
또한, document와 query를 동일 임베딩 모델을 이용하는지, 임베딩 된 feature는 동일한 크기와 형태인지 궁금합니다. global한 정보들 간의 유사도 비교를 위해 동일한 크기의 feature가 생성될 것 같은데, 그렇다면 둘을 임베딩하기 위한 전처리 등의 작업은 따로 없는 지 궁금합니다.
안녕하세요 주연님, 좋은 리뷰 감사합니다.
초반에 워딩들이 잘 이해가 안가서 생긴 질문과 마지막 문단에서 느낀 질문이 있는데요.
1. 질문과 candidate context를 cross-encoding하는 별도의 ranking 모델 중, cross-encoding 방식은 어떻게 이루어지나요?
2. dense embedding 기반 retriever 에서 dense embedding이란 무엇인가요?
3. 마지막에 백본 변경에 대한 실험에서 강인하게 동작한다는 결과에 이어, 결국 본 논문의 RankRAG 방법론은 오픈소스 LLM에 Instruction tuning을 기반으로 하고 있는 것 같은데, 그럼 얼마 전 주연님이 a100에 세팅해두셨던 deepseek LLM에 대해 이 RankRAG 방식을 적용해볼 수 있는건가요? deepseek 모델을 다시 instruction tuning 시켜야될까요?
감사합니다.
안녕하세요 주연님 좋은 리뷰 감사합니다.
제가 해당 분야 논문을 많이 접하지 않아서 질문이 정리가 되지 않은 점 죄송합니다
먼저, LLM의 청크의 단위가 어떻게 되는지 궁금합니다. 하나의 문서라면 일반적으로 하나의 청크로 묶이게 되는지요?
다음으로, Limited Capacity of Retriever 문제에서 query와 document를 독립적인 처리가 새로운 task 대응의 어려움을 발생시킨다고 말씀해주셨는데, 동일한 모델로 임베딩을 할 경우 처리가 독립적이더라도 같은 표현 공간에 임베딩 되는것이라고 알고있었는데, 이것이 아닌가요? (왜 독립적인 처리가 두 입력의 적합성 추정 능력을 제한하는지 궁금합니다)
또한, 이러한 현상이 왜 새로운 task 확장에 어려움을 발생시키는지 궁금합니다.
마지막으로, 제안 방법이 Supervised Learning 방법인데, 기존 방법 대비 장점이 더욱 많은 데이터셋을 활용한 것과 Stage-2의 context-rich QA task 기반 학습방식을 새롭게 제안한것으로 이해하면 될까요?
감사합니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
RAG 동작원리를 설명해주신 부분에서 언급되는 dense embedding이 무엇인가요 ?
또, RAG 파이프라인의 현재 한계를 언급해주신 부분의 high recall mechanism 필요에서 언급되는 candidate context는 어떻게 얻어지는 것인지 궁금합니다. document나 wikipedia에서 제공되는 것인가요 ?
감사합니다.