
안녕하세요, 허재연입니다. 논문 제출 이후, 최근 연구 트렌드를 follow-up 하기 위해 힘쓰고 있습니다. 특히 Foundation Model, VLM 등의 연구들이 어떻게 대규모 사전학습 지식을 활용하는지, 이러한 지식들을 세부 task에 어떻게 적용하는지 알아보고 있습니다. 이번 리뷰에서 다룰 논문은 그 과정에서 살펴보게 된 논문으로, 기존 대규모 사전학습 방법론들의 모델 관점/데이터 관점에서의 한계를 보완하고자 제안된 방법론입니다. NLP쪽 논문의 색채가 있기도 하고, 해당 분야의 이전 연구 흐름을 파악하고 있던 것이 아니긴 하지만, 나름 제가 이해한 대로 리뷰를 작성해 보았습니다.
- 해당 논문은 세미나에서도 간단히 다루었으니, 필요하신 분은 다음 세미나 영상을 참고하셔도 될 것 같습니다 : 세미나 영상 링크
Introduction
Vision-Language Pre-training 방법은 당시 기존보다 훨씬 개선된 성능으로 다양한 multimodal downstream task에서 큰 성공을 거두고 있었습니다. 하지만, 저자들은 기존 방법론에 대해 다음과 같은 모델/데이터 관점에서의 2가지 한계점을 제시합니다.
(1) 모델 관점 : 대부분의 기존 방법론들이 encoder기반(CLIP, ALBEF 등) 혹은 encoder-decoder(VL-T5, SimVLM) 구조를 기반으로 한다. 하지만 encoder 구조 기반 모델들은 이미지 캡셔닝과 같은 generation task를 수행하는데 적합하지 않고 , encoder-decoder 구조 기반 모델들은 text generation에 집중하기에 image-text retrieval과 같은 understanding task에 적합하지 않다.
(2) 데이터 관점 : CLIP, ALBEF, SimVLM과 같은 (당시)SOTA 모델들은 웹상에서 수집된 대규모 image-text pair 데이터셋을 scaling-up하여 성능을 향상시키고자 하였지만, 이렇게 구성된 데이터셋에는 noise가 존재한다. 데이터셋을 확장하여 성능 향상을 이루긴 했지만, noise가 많은 web 데이터가 Vision-Language 모델 학습이 최적이지는 않다.
이에, 저자들은 기존 방법론들보다 넓은 범위의 downstream task를 수행할 수 있는 새로운 VLP 프레임워크인 BLIP(Bootstrapping Language-Image Pre-training for unified vision-language understanding and generation)을 제안합니다. 해당 방법론에서는 모델 관점 및 데이터 관점에서의 개선 방안인 MED, CapFilt를 제안합니다.
(a) Multimodal mixture of Encoder-Decoder (MED) : 효과적으로 multi-task 사전학습 및 유연한 Transfer Learning을 위한 새로운 모델 구조인 MED. MED는 1.unimodal encoder, 2.image-grounded text encoder, 3.image-grounded text decoder로 동작할 수 있으며, 3가지 Vision-Language Objective(1.image-text contrastive learning, 2.image-text matching, image-conditioned language modeling)를 사용해 공동으로 동시에 사전학습 됩니다.
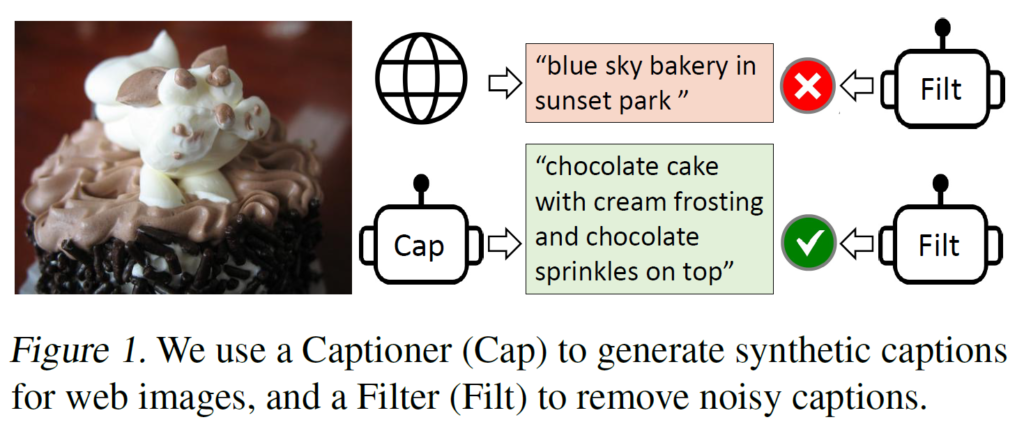
(b) Captioning and Filtering (CapFilt) : 노이즈가 섞인 image-text pair로부터 학습하기 위핸 새로운 dataset bootstrapping 방법인 CapFilt. 사전학습된 MED 를 captioner와 filter라는 두 가지 모듈로 fine-tuining합니다. captioner는 주어진 웹상 이미지에서 새로운 합성 캡션(텍스트)을 생성하고, filter는 original web text 및 synthetic text에서 noisy한 capition을 제거합니다.
저자들은 다양한 분석 및 실험을 수행했으며, 다음과 같은 주요한 점을 발견하였습니다 :
- captioner와 filter를 함께 사용하여 caption을 bootstraping함을 통해 다양한 downstream task에서 상당한 성능 개선을 이루었다. 또한 다양한 캡션을 사용할수록 성능 개선에 이점이 있다는것을 발견하였다.
- BLIP은 image-text retrievel, image captioning, visual question answering(VQA), visual reasoning, visual dialog 등 다양한 vision-language tasks에서 SOTA를 달성했다.
Method
저자들은 noisy한 image-text pair로부터의 학습을 위한 통합된 Visual-Language Pretraining(VLP) 프레임워크인 BLIP을 제안하였습니다. 저자가 제안하는 모델 구조인 Multimodal mixture of Encoder-Decoder (MED)와 이를 위한 사전학습 objective를 알아본 다음, dataset bootstrapping을 위한 Captioning and Filtering (CapFilt) 알아보겠습니다.
Model Architecture
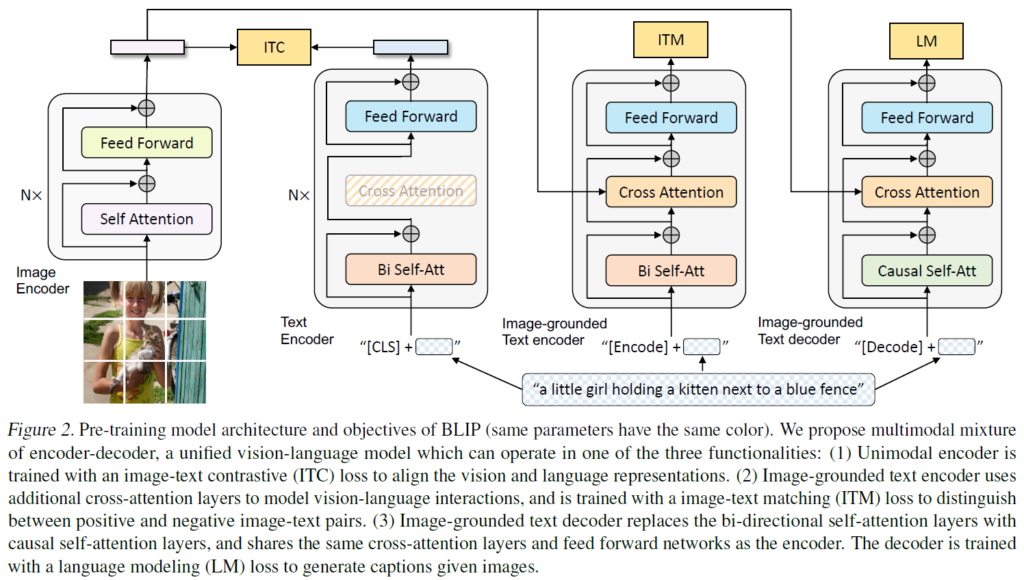
모델 구조는 Figure2와 같이 1.Unimodal Encoder, 2.Image-Grounded Text Encoder, 3.Image-Grounded Text Decoder로 구성됩니다. 동일 색상은 가중치를 공유하는것을 의미합니다. 앞서 말씀드렸듯, Understanding 및 Generation 능력을 모두 갖춘 모델을 사전 학습시키기 위해 Multi-Task 모델인 MED(Multimodal Mixture of Encoder-Decoder)를 제안하였습니다.
(1) Unimodal Encoder : 이미지와 텍스트를 별도로 인코딩 하기 위해 unimodal encoder를 사용합니다. Image Encoder로는 ViT를 사용하여 입력 이미지를 패치 단위로 나누어 임베딩 시퀀스로 인코딩하였고, 이 때 global iamge feature를 표현하기 위해 [CLS] token을 추가하였습니다. Text Encoder는 BERT와 동일하며, 문장을 요약하기 위해 텍스트 입력 시작 부분에 [CLS]토큰을 추가하였습니다.
(2) Image-grounded text encoder : 텍스트 인코더의 각 Transformer Block에 Self-Attention Layer와 Feed-Forward Network 사이에 Cross-Attention Layer를 삽입하여 시각적 정보를 추가해주었습니다. Task-Specific한 [Encode] Token이 텍스트에 추가되어 입력되고, [Encode]의 출력 embedding은 image-text pair의 multimodal representation으로 사용됩니다.
(3) Image-grounded text decoder : Image-Grounded Text Encoder의 Bidirectional Self-Attention Layer를 Casual Self-Attention Layer로 대체합니다. 시퀀스 시작 신호로 [Decode] token을 사용하며 시퀀스 종료 신호로 end-of-sequence(EOS) token을 사용하였습니다.
Pre-training Objectives
저자들은 사전학습 단계에서 3가지 objective(understanding 기반 objective 2개, generation 기반 objective 1개)를 동시에 최적화 하였으며, 각 loss term 이름은 Image-Text Contrastive Loss (ITC), Image-Text Matching Loss (ITM), Language Modeling Loss (LM)입니다. 최종 loss는 3가지 loss term의 총합으로 구성됩니다. 하나씩 살펴보겠습니다.
Image-Text Contrastive Loss (ITC) : 는 Unimodal Encoder에 대한 loss입니다. CLIP의 학습 과정을 생각하면 좋을 듯 한데, positive image-text pair가 유사한 representation을 갖도록, negative는 representation 거리 간 패널티를 부여해 visual transformer와 text transformer의 feature space를 정렬하는것을 목표로 합니다. 해당 loss term은 당시 연구들을 통해 vision-language understanding에 효과적임이 알려져 있었기에, ALBEF라는 기존 방법론의 {L}_{itc}를 사용했습니다. 해당 loss는 negative 쌍의 potential positive를 고려하기 위해 momentum encoder로부터 soft label을 생성해 사용했다고 합니다.
Image-Text Matching Loss (ITM) : Image-Grounded Text Encoder를 학습하기 위해 ITM loss를 사용합니다. 해당 loss의 목적은 Vision-Language 사이의 Fine-Grained Alignment를 포착하는 Image-Text Multimodal Representation을 학습하는 것입니다. 모델이 주어진 multimodal feature에 대해 ITM Head(linear layer)를 통해 image-text pair가 positive(matched)인지 negative(unmateched)인지를 예측하는 이진 분류를 수행합니다. 더욱 정보량이 많은 negative를 찾기 위해, 배치 내부의 contrastive similarity가 높은 negative pair들이 loss 계산에 사용되는 hard negative mining을 함께 사용했다고 합니다.
Language Modeling Loss (LM) : LM은 주어진 이미지에 대한 textural description을 생성하는 mage-Grounded Text Decoder를 학습하는데 사용됩니다. 해당 loss는 autoregressive방식으로 텍스트의 likelihood를 최대화도록 모델을 훈련시키는 cross-entropy를 최적화합니다(loss 계산 시 0.1의 loss smoothing을 적용했다고 합니다).VLP에서 널리 사용되는 MLM loss와 비교해 LM은 일반화 능력을 갖춘 보델이 시각적 정보를 일관된 캡션으로 변환할 수 있게 해준다고 합니다.
학습 과정에서 효율적인 사전학습을 위해 text encoder와 encoder는 self-attention을 제외한 모든 매게 변수를 공유합니다. 이는 self-attention 계층이 인코딩 및 디코딩 작업 간 차이점을 잘 파악할 수 있기 때문이라고 합니다. 특히, 인코더는 현재 입력 토큰의 representation을 만들기 위해 bi-directional self-attention을 사용하는 반면 디코더는 다음 토큰 예측을 위해 causal self-attention을 사용한다고 합니다.
반면 임베딩 계층, cross-attention 계층, FFN은 인코딩과 디코딩 작업 간 유사한 기능을 수행하므로 레이어를 공유해 multi-task learning의 이점을 누리면서 학습 효율을 높일 수 있었다고 합니다.
CapFilt
막대한 어노테이션 비용으로 인해 사람이 직접 어노테이션한 고품질의 image-text pair의 수는 제한되어 있어서, 최근 연구에서는 웹에서 자동으로 수집되는 훨씬 더 많은 수의 image-text(alt-text) pair를 활용합니다. 하지만 이렇게 수집된 text 는 시각적 정보를 올바르게 기술하지 못하여 vision-language alignment 학습에 있어 방해가 되는 신호로 작용할 수 있습니다. 이에 저자들은 text corpus의 품질을 개선할 수 있는 방법인 Captioning and Filtering(CapFilt)를 제안합니다. Figure 3에는 CapFilt를 나타내었습니다. 여기에는 1.주어진 웹상 이미지의 캡션을 생성하는 captioner와, 2.image-text pair의 노이즈를 제거하는 filter를 활용합니다. captioner와 filter는 모두 동일한 사전학습된 MED로 초기화되고, 개별적으로 COCO 데이터셋으로 파인튜닝됩니다.
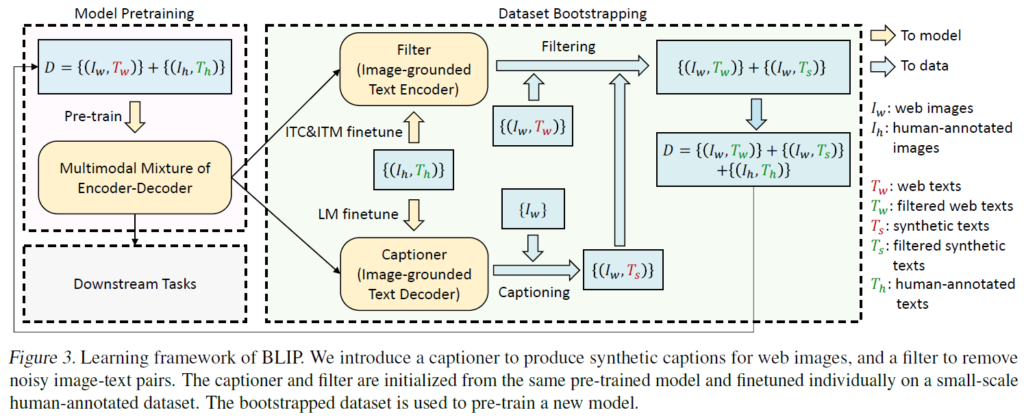
Captioner는 Image-Grounded Text Decoder입니다. 주어진 이미지에 대해 text를 디코딩(생성)하기 위해 앞에서 살펴본 LM loss로 finetuning됩니다. 주어진 웹상 이미지 {I}_{w}에 대해 captioner는 합성 캡션 {T}_{s}를 생성합니다(이미지 당 하나의 캡션 생성).
Filter는 Image-Grounded Text Encoder입니다. 텍스트와 이미지의 매칭 여부를 학습하기 위해 ITC loss와 ITM loss로 finetuning됩니다. 웹상 텍스트({T}_{w}) 및 합성 텍스트({T}_{s}) 모두에서 노이즈 텍스트를 제거하는데, ITM head가 이미지와 일치하지 않는 것으로 예측하는 텍스트를 noise가 있는 것으로 판단합니다. 마지막으로, 필터링된 이미지-텍스트 쌍과 사람이 어노테이션한 이미지-텍스트 쌍을 결합하여 새로운 모델을 사전학습하는데 사용하게 됩니다.
정리하면, BLIP은 멀티모달 인코더 및 디코더들이 혼합된 구조로 구성됩니다. 이 때, unimodal encoder는 ITC loss를 활용해 영상과 텍스트 간 관계성을 학습하고, image-grounded text encoder는 ITM을 활용해 image-text pair의 positive/negative 여부를 예측(Filtering)하게 학습하게 되고, image-grounded text decoder는 LM을 활용해 주어진 영상에 대한 텍스트 캡션을 생성하게 됩니다. 웹상에서 수집한 영상-텍스트 쌍에는 노이즈가 많으므로, Captioner를 통해 영상에 대한 캡션을 생성하고 Filter를 통해 원본 및 합성 텍스트에서 noise가 있다고 판단되는 텍스트는 제거합니다.
Experiment
사전학습에는 2가지 human-annotated dataset(COCO, Visual Genome)과 3가지 웹상 데이터셋(Conceptual Captions, Conceptual 12M, SBU captions)가 사용되었다고 합니다.
Effect of CapFilt
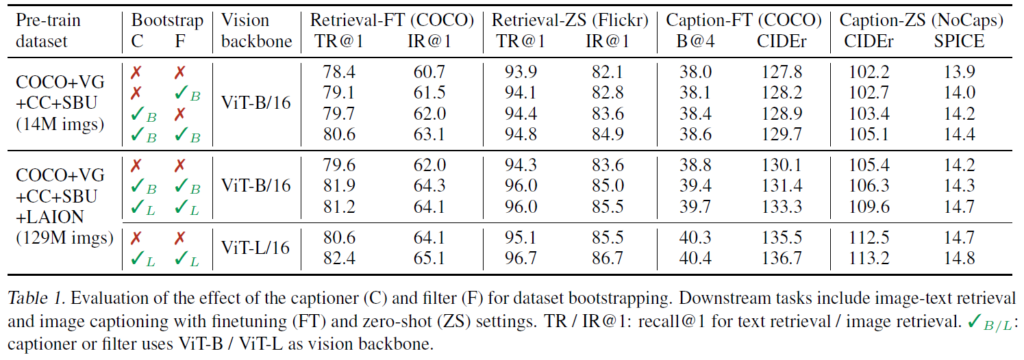

Table 1에서는 Image-Text Retrieval, Image Caption의 downstream task에서 CapFilt의 효율성을 보였습니다. Caption, Filter를 함께 사용하면 상호 보완하는 효과가 있어 noise가 많은 web text를 사용할 때보다 성능이 크게 향상되었으며, 더 큰 데이터셋과 Vision Backbone으로 성능을 더욱 향상시킬 수 있었습니다. Figure 4는 영상에 대한 캡션의 예시를 나타낸 것으로, captioner가 새로운 textual description을 생성하는 것과 filter가 텍스트를 제거하는 것을 정성적으로 확인할 수 있습니다.
Parameter Sharing and Decoupling
사전학습 과정에서 텍스트 인코더와 디코더는 self-attention layer를 제외한 모든 파라미터를 공유합니다. Table 3은 서로 다른 파라미터 공유 전략에 대한 사전학습의 효과를 평가하였습니다. 결과적으로 저자들이 사용한 것과 같이 SA 제외하고 파라미터를 공유하는 것이 학습의 효율성을 높이면서도 좋은 결과를 보였습니다. SA layer까지 공유하면 인코딩 및 디코딩 작업 간 충돌로 성능이 저하되었습니다.

CapFilt에서 captioner 및 filter는 개별적으로 COCO에서 finetuning되었습니다. Table 4에서는 captioner 및 filter 간 파라미터 공유 전략을 비교하였습니다. 결과적으로 downstream task에서의 성능이 저하되었습니다. 파라미터 공유로 인해 caption에 의해 생성된 noise caption이 filtering될 가능성이 낮아지며, 이는 노이즈 비율이 25%에서 8%로 낮아진 것에서 확인할 수 있습니다.

Comparison with State-of-the-arts
Image-Text Retrieval에 대한 결과는 Table 5에 나타내었습니다. COCO, Flickr30k 데이터셋에서 image-to-text retrieval(TR), Text-toimage Retrieval(IR) 모두에 대한 BLIP과 타 방법론을 비교하였습니다. 사전학습한 모델을 ITC 및 ITM loss로 튜닝하였습니다. Table 5에서 확인할 수 있듯, BLIP은 기존 방법론들 대비 상당한 성능 개선을 이루었습니다. Table 6에는 COCO에서 finetuning된 모델을 Flickr30K에 directly transfer하여 zero-shot retrieval을 수행한 결과를 나타내었습니다. 마찬가지로 BLIP이 상당히 개선된 결과를 보였습니다.
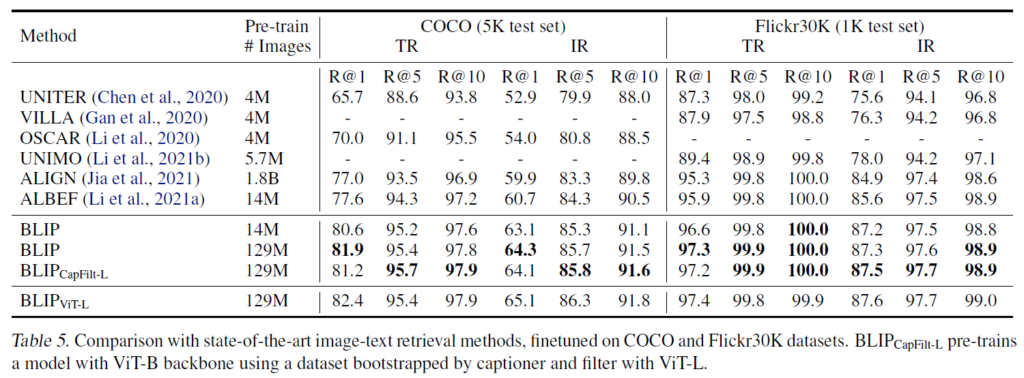
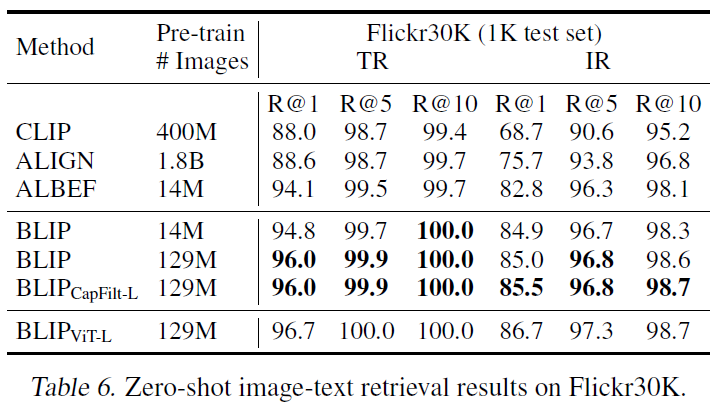
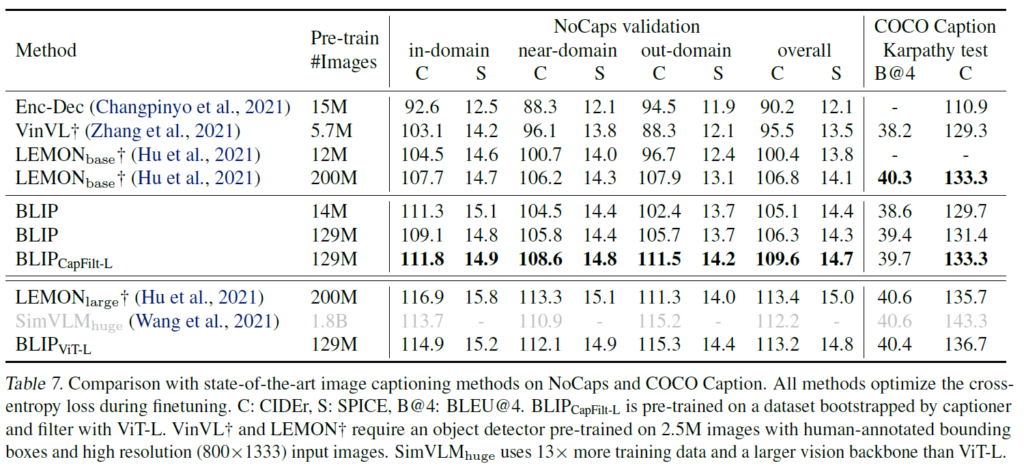
Image Captioning에는 No-Caps 및 COCO 데이터셋이 사용되었다고 합니다. 둘 다 COCO 데이터셋에 대해 LM loss를 사용하여 Finetuning되었습니다. 여기에도 “a picture of”라는 프롬프트를 추가해 약간 개선된 결과를 얻을 수 있었다고 합니다. 결과적으로, 14M개의 사전학습 이미지 셋을 사용한 BLIP은 비슷한 양의 사전핛브 데이터를 사용한 타 방법보다 성능이 월등히 뛰어났습니다. 129M개의 사전학습 이미지 셋을 사용했을 때는, 기존 방법론인 LEMON과 비등한 결과를 보였습니다. 하지만 LEMON이 계산량이 많이 필요한 사전 학습된 object detector와 고해상도(800×1333) 입력 이미지를 필요로 하기에 cost가 heavy하다는것을 언급하며, 저해상도(384×384) 입력 이미지를 사용하며 detector가 없는 BLIP이 가볍다는 것을 강조합니다.
다음은 VQA 및 Natural Language Visual Reasoning(NLVR2)입니다.
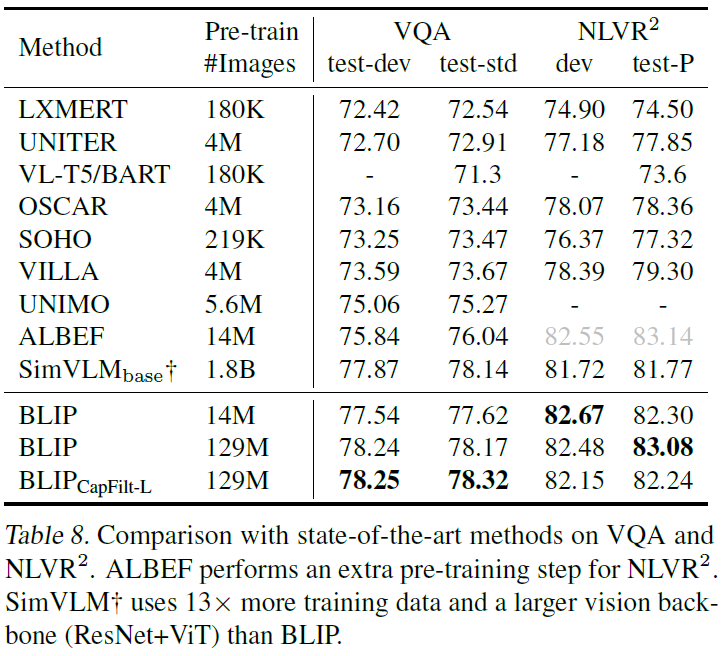
VQA(Visual-Question-Answering)은 다들 아시겠지만 이미지와 질문이 주어지면 모델이 질문에 대한 답을 이미지를 참조하여 예측하는 task입니다. 기존 연구들은 이를 answer generation task로 간주하였다고 합니다. fine-tuning 과정에서 GT answer를 타겟으로 LM loss를 적용하였다고 합니다. 결과는 아래 Table8에서 확인할 수 있는데, 14M개의 이미지를 활용해 test set에서 BLIP이 ALBEF를 +1.64%를 능가하는 결과를 보였으며, 129M개 이미지를 활용하였을 때는 13배의 사전학습 데이터와 더 큰 vision backbone을 필요로 하는 SimVLM보다 뛰어난 결과를 보였습니다.
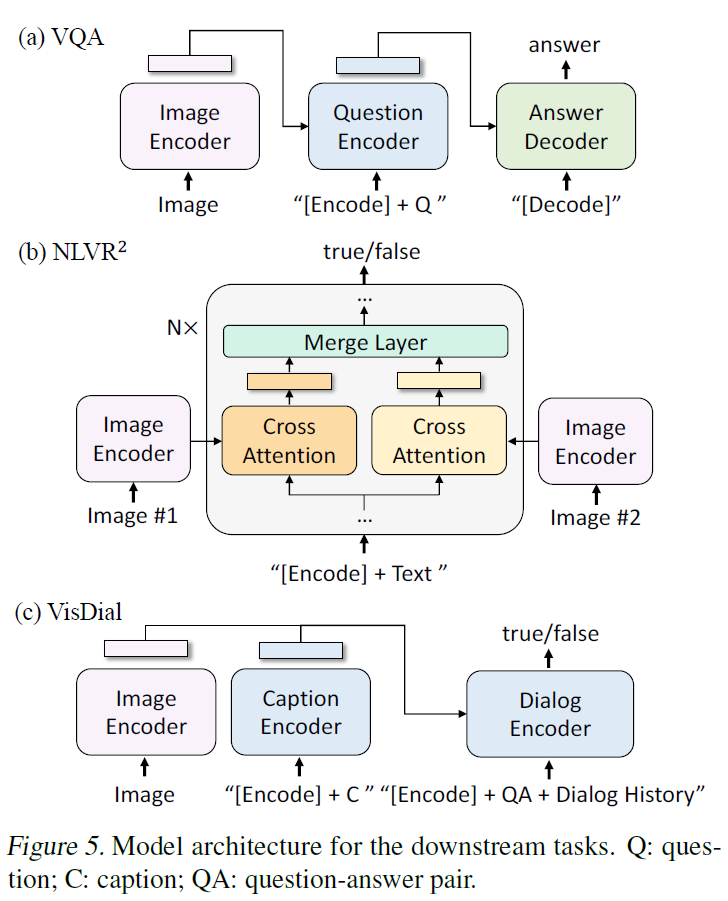
Natural Language Visual Reasoning (NLVR2)는 저에게 생소한데, 주어진 문장이 이미지 쌍을 잘 설명하는지 여부를 모델이 예측하는 task라고 합니다. 2개 이상의 이미지를 추론하도록 하기 위해 저자들은 아래 Figure 5(b)처럼 image-grounded text encoder에 있는 각 transformer block을 수정하였다고 합니다. 두 입력 이미지를 처리하기 위해 두 cross-attention 모듈이 있으며, FFN으로 들어가 두 출력이 합쳐집니다. Table 8에서 보다시피 ALBEF를 제외한 방법론들보다 개선된 결과를 보여줍니다.
마지막으로 Visual Dialog(VisDial)에 대한 평가도 진행하였습니다. 새삼 멀티모달 쪽에 굉장히 많은 벤치마크 task가 있는 것 같네요.
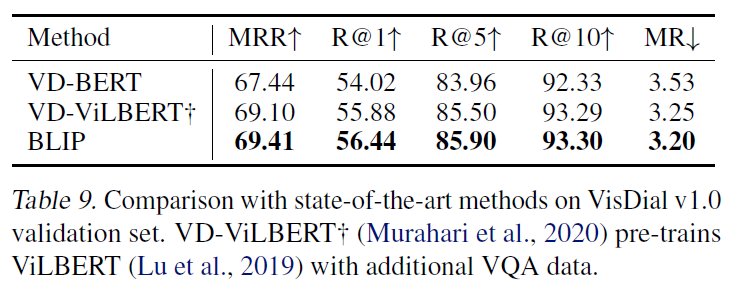
Visual Dialog는 자연스러운 대화 환경에서 VQA를 확장하여 모델이 이미지-질문 쌍을 기반으로 답변을 예측할 뿐만 아니라, 대화 기록과 이미지 캡션도 고려해야 하는 task라고 합니다. 이미지와 캡션 임베딩을 concat하여 cross-attention으로 dialog encoder로 전달하고, dialog encoder는 전체 대화 기록 및 이미지 캡션 임베딩을 고려하여 질문에 대한 답변의 참/거짓 여부를 판별하기 위해 ITM loss로 훈련된다고 합니다. Table 9에서 확인할 수 있듯 VisDialv1.0 validation set에서 SOTA를 달성하였다고 합니다.
위 3가지 downstream task에 대한 모델 구조는 아래 Figure 5와 같습니다.
Conclusion
VLM pretraining 방법론인 BLIP에 대해 살펴보았습니다. 평소 비전 쪽 논문만 읽다 멀티모달 쪽 논문을 읽으려니 익숙하지 않네요. 본 논문에서는 전반적으로 그 이전 연구인 ALBEF의 요소를 많이 차용했는데, 해당 논문을 정독한 적은 없어서 아주 디테일한 요소들까지 파악하기는 어려웠습니다. 필요 시 해당 논문을 참고해봐야 할 듯 합니다.
감사합니다.
안녕하세요 재연님 좋은 리뷰 감사합니다.
CapFilt에서 웹상 이미지의 캡션을 생성하는 captioner와 image-text pair 노이즈를 제거하는 filter는 사전학습된 MED로 초기화 후에 개별적으로 COCO에 파인튜닝된다고 언급해주셨는데 사전학습 과정에서는 CapFilt 방식이 사용되지 않는 건가요? CapFilt의 목표는 noisy한 데이터를 잘 정렬된 데이터로 조정하여 학습에 방해가 되지 않도록 하는 것으로 이해했습니다. 파인튜닝보다는 사전학습 과정에서 중요한 역할을 할 것으로 생각했는데 MED를 통해 CapFilt가 초기화되려면 MED가 먼저 사전학습이 된 상태여야 할 것 같아서 궁금합니다.
감사합니다.
사전학습 단계에서는 capfilt가 직접적으로 적용되지는 않고 capfilt를 통해 증강/정제된 데이터 셋을 사전학습에 활용하게 됩니다. 해당 방법으로 다시 MED를 학습하고, 다시 capfilt를 적용해 업데이트하게 됩니다.
안녕하세요. 좋은 리뷰 감사합니다 !
Intro단에서 기존 방법에 대해 모델 관점에서의 한계로 encoder-decoder 구조 기반 모델이 retrieval이나 understanding task에 적합하지 않다고 집어주었는데, 바로 아래에 encoder-decoder 구조 기반인 MED를 제안하였다고 나와있었습니다. 이 MED같은 점은 앞서 언급했던 한계점을 갖지 않도록 설계된 것인지, 그렇다면 어떤 점으로 인해 그러한지 궁금합니다.
다음으로 Image-Text Contrastive Loss에서 ALBEF의 L_{itc}를 사용했다고 했고 이 loss는 negative pair의 potential positive를 고려하기 위해 momentum encoder로부터 soft label을 생성해 썼다고 하는데, 본 모델 구조에는 momentum encoder가 없는데 soft label을 어떻게 생성하나요 ? 또, 여기서 고려한 potential positive란 어떤 경우인지 그 예가 궁금합니다 !
감사합니다.
MED에는 text encoder, imag encoder가 있어서 encoder 기반 방법에 활용할 수 있고, 문장을 생성하는 decoder도 있어서 understanding / generation task 모두 활용할 수 있습니다.
ITC loss에 대한 자세한 설명은 본 논문에는 나와있지 않고, ALBEF라는 기존 방법론의 ITC loss를 그대로 활용했다고 나와있습니다. ALBEF의 논문을 참고해보면, image / text 각 modality에 대한 embedding bector간 내적을 통해 유사도를 구하고, 이를 softmax를 태워 확률 분포 형태로 만든 다음 cross-entropy를 통해 학습을 진행하게 됩니다. 일반적으로 사용되는 contrastive loss와는 약간 다르죠. 여기서 두 encoder를 학습할 때 momentum encoder를 사용한다고 생각하시면 됩니다. ALBEF논문에서는 inspired by MoCo라고 되어있으니, MoCo의 학습 방식을 연상하면 좋을 것 같습니다. potential positive는 negative pair이긴 하지만 서로 그 특성이 매우 유사한, 일종의 hard negative같은 것으로 생각하면 좋을 것 같습니다. contrastive learning은 아예 매칭되어있는 positive pair가 아닌 모든 pair 간 거리를 (raw data 간 아무리 관계성이 높아도) 멀게 강제하기 때문에 이를 완화하기 위한 것으로 받아들이시면 됩니다.