안녕하세요, 쉰 한번째 X-Review입니다. 이번 논문은 2024년도 ECCV에 게재된 Parrot Captions Teach CLIP to Spot Text 논문입니다. 바로 시작하도록 하겠습니다. ?

1. Introduction
최근 대규모 image-text 데이터를 활용한 contrastive learning 모델들이 많이 발전해왔고, 그 중에서도 CLIP은 vision-language task에서 foundation model로 자리잡았습니다. 하지만, 몇 연구에 따르면 CLIP이 visual text, color, gender 등에 bias가 존재한다고 합니다. 본 논문에서는 CLIP의 visual text bias를 논문으로, 다시 말해 CLIP이 image속 text를 얼마나 잘 spotting하는지에 초점을 맞춘 논문입니다. 기존 연구들은 이러한 bias 자체가 사전 학습 데이터의 노이즈 때문이라고 보고 있는데요. 따라서 본 논문에서는 먼저 가장 많이 사용되고 있는 LAION-2B 데이터셋을 분석해보고자 하였습니다. 이 LAION-2B 데이터셋은 엄청나게 규모가 큰 데이터셋이기에 단순 추정으로 bias를 판단하기는 어렵기에, 먼저 데이터셋을 image clustering한 후, CLIP score를 기준으로 각 cluster를 정렬하여 이를 분석하였습니다. 그 결과, CLIP score가 높은 데이터 샘플 상당수가 image와 caption에서 모두 동일한 text가 나타나는 패턴을 보였습니다.

그 예로 위 그림을 보시면, CLIP score top5%를 뽑아둔 figure인데, 1번 그림에 YES, SHONDA, RHIMES 등의 text가 적혀져 있고 마찬가지로 이 text가 caption에도 있는 것을 확인할 수 있습니다.
이를 보아 CLIP 모델은 원래의 가정, image와 text가 짝지어지도록 학습이 되는 것이라는 가정과는 달리, 이미지 속 text를 단순히 복사(parroting)하고 있습니다. 본 논문에서는 이런 caption을 Parrot Captions이라고 명칭하였는데요, 이 Parrot caption은 CLIP이 이미지의 visual concept을 이해하지 않도고 text spotting을 잘 할수 있도록 돕는 것이죠. 이런 현상을 파악하기 위해 본 논문에서는 이 Parrot Caption을 (1) 데이터셋 관점 (2) CLIP 모델 관점 (3) CLIP 모델 학습 과정 관점 이렇게 세 관점에서 분석합니다.
분석 결과는 아래와 같습니다.
- LAION-2B 데이터셋의 caption은 image속 visual text를 설명하는 경향이 강하다.
저자들은 기존 text spotting 모델을 사용해서 해당 데이터셋에 text가 얼만큼 포함되어 있는지 살펴봤는데요, 그 결과 전체 이미지의 50% 정도가 text(visual text content)를 포함하고 있는 이미지였다고 합니다. 또 이 이미지에서 인식된 text와 caption을 비교해본 결과 caption의 90% 이상이 최소 한 단어를 공유하고 있었으며, caption의 30% 정도가 이미지 속 text와 겹치는 단어로 구성됨을 확인하였습니다. 이런 결과는 CLIP이 image-text semantic alignment 한다고 보는 기존 가정을 무너뜨릴 수 있는 것이죠. 즉, 다시 말해 CLIP이 단순히 이미지 속 text를 caption과 매칭하는 경향이 강하다고 볼 수 있습니다.
- 공개된 CLIP 모델들은 데이터셋을 필터링할 때 visual text가 많은 데이터로 편향됨을 보임.
저자는 OpenAI가 공개한 CLIP모델을 대상으로 LAION-2B 데이터셋에서 text를 제거했을 때의 alignment score 차이를 비교한 결과, 이미지 속 text와 caption 간의 상관관계가 무척 높다는 것을 확인하였습니다. 즉, 1에서 말한 것처럼 CLIP이 image와 text간의 semantic alignment를 하는것이 아닌, 이미지 속 text를 그대로 matching하여 높은 score를 갖는 경향을 보이는 것이죠. 또, WIT-400M 데이터셋으로 학습한 CLIP과 LAION-2B(parrot captions이 많은..)으로 학습한 OpenCLIP을 비교한 결과 OpenCLIP이 CLIP보다 text spotting에 편향된 것을 확인할 수 있었는데, 이는 곧 OpenCLIP이 CLIP보다 image속 text를 더 쉽게 학습하지만 vision-language semantic alignment와는 무관할 가능성이 크다는 것이죠. (parrot captions에 의한 것이라고 봄)
- CLIP 모델은 parrot captions을 학습하면 text spotting 능력을 쉽게 얻지만 이건 마치 text를 따라 읽는 앵무새와 같은 방식임.
이는 위 2번과 유사한 말이긴 하지만, 좀 더 모델 학습 관점에서 분석한 부분입니다. 여기서는 LAION-2B 데이터셋을 이미지 속 텍스트 포함 정도 / 캡션과 이미지 속 텍스트의 겹치는 정도 / 이미지 속 텍스트가 없어였을 때 이렇게 3가지의 subset을 구성하여 CLIP을 학습한 결과 CLIP이 text spotting에 좀 더 focus할수록 zero shot 능력이 급감하였다고 합니다. 저자는 현재 CLIP score에 기반한 데이터 수집 방식이 parrot captions의 영향을 받고 있으니 이를 수정해야 한다고 주장합니다. 다시 말해 CLIP 모델을 학습할 때 대규모 웹 이미지-텍스트 데이터를 수집하는 과정에서 CLIP score를 기준으로 구성하게 되는데, 이때 CLIP이 parrot captions에 대해 score가 높을 가능성이 크기 때문에 이 데이터 수집 방식을 수정해야 한다는 것입니다.
아래에서 저자가 분석한 내용에 대해 좀 더 디테일하게 살펴보도록 하겠습니다.
2. Profiling LAION-2B Data
먼저 데이터셋 관점입니다. 이 LAION-2B 데이터셋이 얼마나 Parrot Captions을 갖고 있는지 파악해보고자 한 것인데요. 먼저, K-Means 클러스터링 알고리즘을 통해 4,000개의 cluster로 구분한 다음 각 cluster를 CLIP score를 기준으로 정렬하였습니다. 그다음 당시 SOTA Text Spotting model인 DeepSolo를 사용하여 이미지 안에 text를 spotting하도록 하였고 이렇게 검출 및 인식된 text를 caption과 비교하였습니다. 이후 text spotter가 검출 및 인식한 text와 caption이 얼마나 일치하는지 여부를 계산하였습니다.

이 일치 여부는 위 알고리즘에 적힌 것과 같이 계산됩니다. cap_words가 caption word, ocr_word가 spotter가 인식한 word에 해당하겠고, 둘 간의 interaction의 길이를 caption 길이로 나눈 것이죠. 이 rate가 높으면 높을수록 이미지 속 text와 caption이 많이 겹친다고 볼 수 있겠고 곧 parrot captions일 가능성이 크다는 의미입니다.
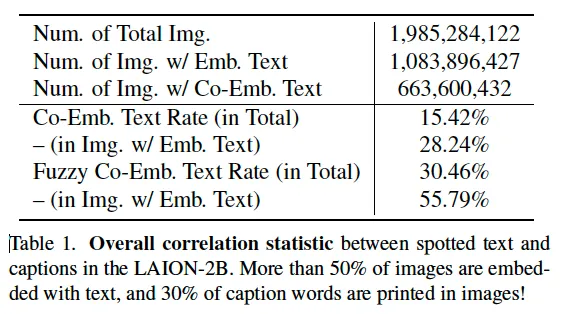
분석한 결과가 위 table1에 나와있는데, 보시면 전체 데이터에서 절반 이상의 이미지에 text가 포함되어 있었으며 caption 단어의 15%가 Co-Emb. Text로 이미지속 text와 겹치는 단어였습니다. 밑에 Fuzzy라고 적힌 부분은 text spotter가 text를 누락할 수 있는 점을 고려한 fuzzy matching을 적용한건데 30%까지 증가하게 되죠. 이런 데이터로 학습된 CLIP 모델은 당연히 text spotting에 bias될 가능성이 있습니다.
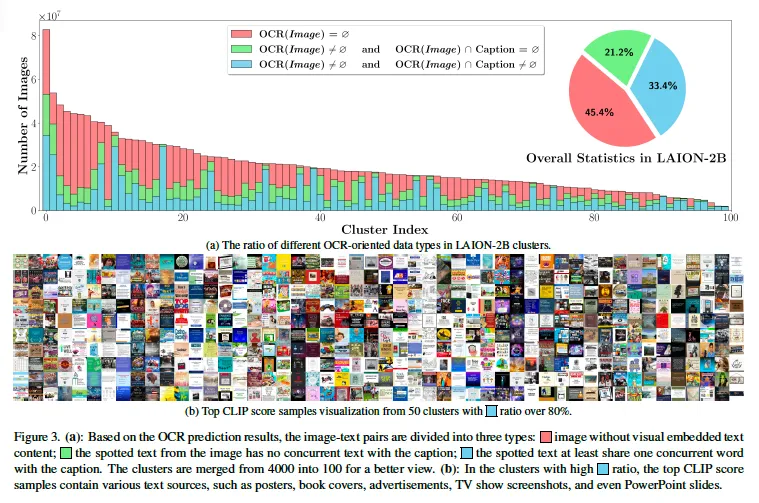
또, 이미지를 100개의 cluster로 나누고 ocr 결과에 따라 3가지로 분류해본 결과가 위 그림3에 모사되어 있습니다. 보시면 모든 cluster에서 text를 포함한 이미지가 일정 비율 존재하고 있습니다. (초록색 + 파랑색) 이는 다양한 scene에서 parrot captions이 나타남을 보여주고 있죠.
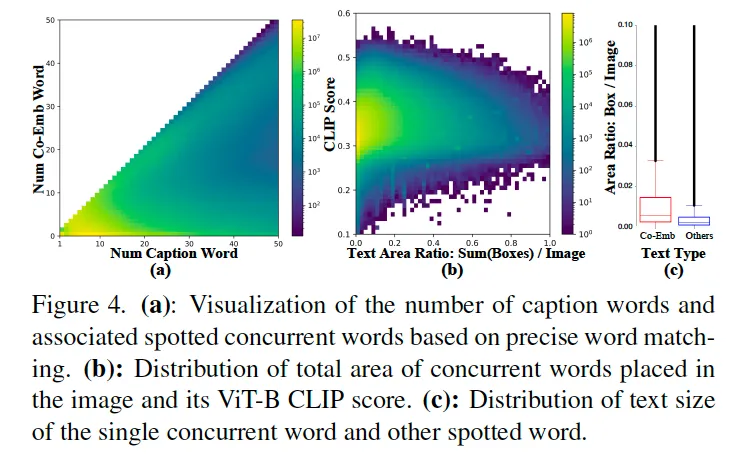
또 이 그림4는 Co-EMb.Text와 CLIP score간의 관계를 분석한 것인데, (a)를 봤을 때 대부분의 Co-Emb. Text는 짧은 단어로 구성되어 있습니다. 하지만 일부 caption은 거의 전체가 parrot captions이구요. (b)를 봤을 때 text 크기가 큰 것이 필연적으로 CLIP score와 연결되지는 않고 작은 크기일때도 score에 영향을 미칠수 있음을 시사합니다. 즉, CLIP은 단순 text 크기보다는 text content와 입력 해상도에 더 영향받을 가능성이 큰 것이죠. 또 (c)를 봤을 때 text 크기가 더 클수록 caption에서 그대로 복사될 가능성이 높은 것을 확인할 수 있습니다. (text가 클수록 parrot captions이 될 확률 up)
3. Inspecting Pre-Trained CLIP Models
3.1. Ablation of Embedded Text Removal
이전까지는 데이터 관점에서의 분석이었다면, 본 섹션에서는 사전학습된 CLIP 모델 관점에서의 분석입니다. 먼저 이미지 안에 있는 Text가 CLIP score에 미치는 영향을 살펴보기 위해 영상 내의 text를 없애는 실험을 수행했는데요, 구체적으로 text가 있는 영역을 inpainting하는 방식으로 제거하였는데 이 떄 두 가지 방식을 사용하였습니다. 첫 번째로 이미지에서 모든 검출된 text를 제거한느 것과 두 번째로 이미지 속 text들 중 caption과 겹치는 것들만 제거하는 것이죠. 또 다른 이미지에서 random으로 선택된 text 영역을 제거한 버전의 비교군도 만들었습니다.

그 예시가 fig2에 나와 있습니다.
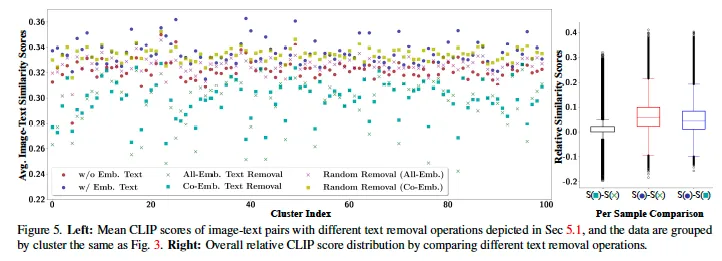
결과를 살펴보면,, 살짝 한 눈에 들어오지는 않지만,, 결과를 간략히 말씀드리면 우선 text가 포함된 이미지가 CLIP score가 더 높다는 점을 확인할 수 있습니다. 또, 연두색 X와 청록색 네모를 확인해보면 파란색 동그라미보다 score가 엄청 떨어져 있습니다. 이는 곧 이미지에서 text를 제거(inpainting)하게 되면 random removal한 경우와 다르게 CLIP score가 크게 낮아졌다는 것인데, 이 두 점을 미루어보아 parrot captions이 CLIP score와 높은 상관관계가 있다고 볼 수 있습니다.
3.2. Prompting with Syn-Emb. Text
Generating Synthetic Images from N-gram Vocabulary:
다음으로는 CLIP 모델이 text spotting을 어떻게 수행하는지를 확인하기 위해 합성 text를 활용한 실험을 진행했습니다. 즉, 임의의 빈 배경에 특정 text를 렌더링하여 CLIP이 어떤 text를 더 잘 인식하는지를 평가한 것입니다. synthetic image는 위의 fig2에 맨 오른쪽 부분에서 확인할 수 있는데 글자 색과 배경 조합에 따라 총 4가지의 text-background 조합을 사용하여 실험ㅇ르 수행하였습니다.
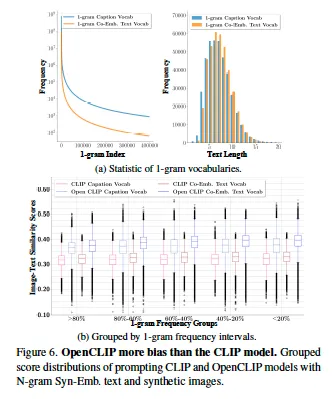
먼저 CLIP 모델이 더 자주 등장하는 단어에 대해 score가 높은지를 확인해봤는데요, fig6(b)를 보면 파란색인 open cliip이 빨간색 CLIP보다 score가 전반적으로 높은 경향을 보입니다. 여기서 흥미로운 점은 아래 x축이 단어 빈도 비율인데 빈도가 낮은 단어에서 약간 더 높은 score가 나왔다는 점인데요, 이건 CLIP 모델이 빈번하게 등장하는 단어보다는 특정 유형의 단어에 대해 더 반응할 수 있음을 시사합니다.
4. Training CLIP on Emb. Text Curated Data
다음으로는, CLIP 모델이 embedded text에 의존하는 정도와 그에 대한 영향을 분석하고자 하였습니다. 여기서는 Parrot Captions이 포함된 데이터셋이랑 포함되지 않은 데이터셋을 비교하였는데요, 실험 방법을 먼저 설명드리자면 LAION-2B 데이터셋을 사용해 embeeded text가 포함된 subset, text를 제거한 subset을 구성하여 학습하였습니다. 평가로는 Zero-shot과 retrieval 성능을 평가하고자 하였고, 특히 텍스트의 감지 정도를 분석하기 위해 합성 데이터셋과 parrot caption을 포함하지 않는 real data, parrot caption을 포함하는 real data를 평가 데이터셋으로 사용하였습니다.

이 Table3은 Parrot caption과 embedded text가 clip 모델 학습 성능에 미치는 영향을 비교하고 있는 실험 결과입니다. 다시 말해 embeeded text가 포함된 이미지로 학습을 하게 되면 clip의 zero shot classification, retrieval 성능이 저하되는지 확인한 것이죠. Random으로 sampling한 데이터셋을 사용한 경우와 비교해봤을 때 embedded text가 포함된 이미지로 학습한 CLIP 모델은 모든 지표에서 성능이 하락한 것을, 꽤나 큰 복으로 하락한 것을 확인할 수 있습니다. 즉, 이미지 속 text 정보가 많을수록 CLIP모델이 visual 의미보다는 text를 감지하는 것에 의존하는 경향이 강하다고 해석해볼 수 있습니다.
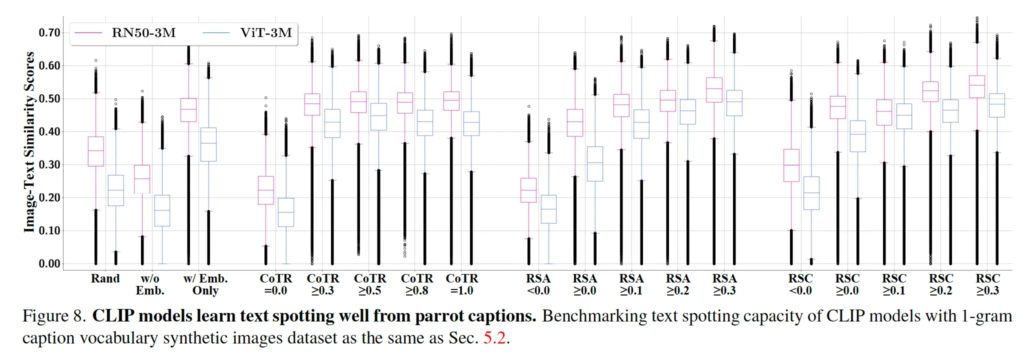
Fig 8에서는 CLIP 모델이 text spotting을 얼마나 잘 하는지 평가하기 위해 CoTR, RSA, RSC 등으로 데이터셋을 정제한 후에 실험한 결과를 시각화한 것입니다. 먼저 CoTR이란 Co-Embedded Text Rate라고 해서 이미지 속에 text가 포함된 비율을 의미합니다. CoTR이 높을수록 데이터셋에 포함된 이미지 속 text (간판이라던지 광고 문구라던지 등등)의 비중이 높은 것입니다. 이 CoTR이 증가할수록 CLIP모델이 단순 OCR처럼 동작하는지 확인하기 위한 실험이죠. RSA는 Relative Score Alignment의 약어로 text를 제거하기 전후의 CLIP score 변화를 기반으로 한 text 비율 지표입니다. RSA가 높을수록 이미지 내 text가 clip 모델 학습에 더 큰 영향을 미친다는 의미입니다. 그냥 단순히 RSA가 높으면 이미지에서 텍스트를 제거했을 때 CLIP score가 크게 변화했다는 것을 의미합니다. 마지막으로 RSC같은 경우는 Relative Score Captions 약어로 parrot captions이 clip 모델 학습에 미치는 영향을 나타내는 지표입니다. 리뷰에 table로는 들고오지 않았지만 CoTR, RSA, RSC를 fig8에 나온 비율대로 나눠 zero shot, retrieval 평가를 수행한 결과 CoTR, RSA, RSC가 상승할수록 성능이 엄청 떨어졌었습니다. 이를 기반으로 시각화 결과를 보면 CoTR이 증가할수록 값이 image text similarity score가 상승하는 것을 확인할 수 있습니다. CoTR이 증가한다는 것은 이미지 속에 text(embedded text)가 많아진 다는 것이고 이는 모델이 이미지 속 텍스트를 더 많이 학습하게 된다는 것입니다. 결과적으로 CLIP은 image와 text간의 semantic alignment보다는 text spotting에 집중하는 경향이 생긴다고 볼 수 있죠. 다음으로 RSA가 증가할수록 similarity score가 증가하고 있습니다. RSA값이 높다는 것은 이미지 속 text가 사라졌을 때 CLIP의 prediction이 크게 차이가 난다는 의미로 CLIP이 이미지에 대해 visual semantic을 이해하려고 하는 것이 아닌 embedded text에 의존하고 있었던 것이죠. 결과적으로 RSA가 높을수록 CLIP이 OCR 처럼 동작하는 경향이 강해지고 similarity score가 올라간 것입니다. RSC도 마찬가지 입니다.
5. A Simple Fix with Text-Orientated Filtering
마지막으로 본 섹션에서는 기존 CLIP 모델의 text spotting bias를 줄이기 위한 data filtering 기법을 제안하고, 이를 적용한 데이터셋을 사용해 학습한 CLIP 모델의 성능을 분석합니다. 구체적인 필터링 과정은 다음과 같습니다. 먼저 OCR을 사용해 검출된 텍스트가 포함된 모든 이미지를 제거하구요, 남은 이미지들 중 CLIP score가 0.3이상이고 aesthetic score가 0.45 이상인 데이터만 필터링하여 퀄리티가 좋은 데이터만 남기도록 합니다. (aesthetic score가 뭔지는 정확하게 모르지만,, 선명도나 해상도 등을 평가하는 score인 것 같습니다.) 이후 K-means clustering을 통해 중복된 데이터를 제거해 최종적으로 100M 개의 sample을 확보합니다. 이렇게 정제한 데이터셋을 기반으로 CLIP 모델을 학습하였고 그에 대한 성능은 아래 table10에서 확인해볼 수 있습니다.
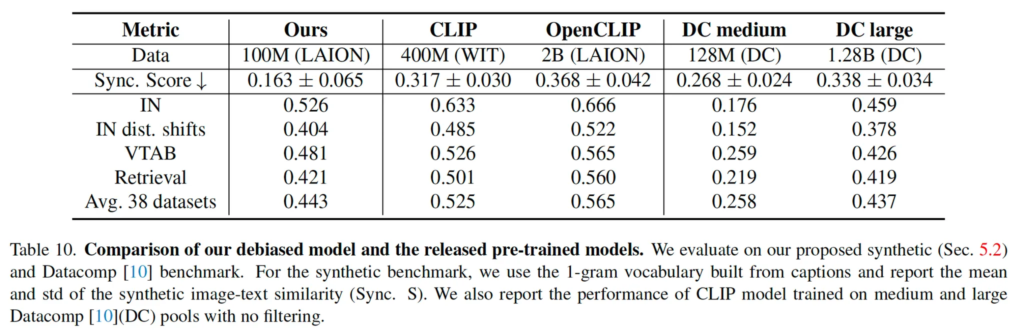
성능을 보면 zero shot, retrieval에 대한 성능과 함께 sync.Score라고 text spotting에 대한 bias score가 리포팅되어 있습니다. text를 포함하지 않은 이미지만을 사용한 100M 규모의 데이터셋을 사용한 결과 이 Sync. Score가 크게 하락한 것을 확인할 수 있지만 기존 CLIP과 OpenCLIP 대비 전반적으로 제로샷 성능이나 retrieval 성능이 낮아진 것을 확인할 수 있습니다. 저자가 여기서 말하조 싶은 것은 자신들이 제안한 필터링 기법을 적용하면 CLIP이 ocr처럼 동작하는 문제를 해결해볼 수는 있지만 일부 성능과의 trade-off가 존재한다는 것인데,,, text spotting 편향이 더 컸을 때 성능이 더 높다면 굳이,, 편향되지 않게 해야하는 것인지 근본적인 의문이 들긴 합니다.
정윤서 연구원님. 좋은 리뷰 감사합니다.
CLIP의 사전학습 과정에서 대규모 데이터셋에 대한 contrastive learning을 수행하기 때문에 latent space에서 각 모달의 representation이 충분히 의미론적으로 잘 정렬 되어 있을 거라 생각했는데, 그렇지 않을 수 있군요. 이미지에 대한 전반적인 이해를 수행하지 않고 단순히 등장 text를 뱉는 것을 앵무새라고 표현한 것이 인상 깊습니다.
제가 해당 task에 대한 지식이 얕아 리뷰 내용에 대한 질문 드리겠습니다.
1. K-Means로 클러스터링을 수행한 이후 CLIP score을 기준으로 정렬한다고 하는데, 이 CLIP score가 구체적으로 무엇인가요?
2. text spotting은 이미지에 대한 text의 위치와 그 자연어를 반환하는 것으로 알고 있는데, 그럼 CLIP은 입력 이미지에 대한 CLIP reprsentation을 transformer decoder같은거에 넣어서 text generation을 수행하는 것인가요? 그럼 텍스트의 위치는 어떻게 인식하게 되나요?
감사합니다.
댓글 감사합니다.
1. CLIP score란 이미지와 텍스트 간의 cosine similarity를 의미합니다.
2. 아뇨. CLIP은 text를 생성하지도, 위치 정보를 다루지도 않습니다. 본 논문에서 말하는 CLIP이 text spotting을 수행할 수 있는 이유는 학습 과정에서 사용되는 이미지들 속에 존재하는 text가 caption에 자주 등장하기 떄문인데요. 즉, CLIP이 학습 도중에 반복적으로 이미지 안에 있는 단어는 캡션에도 있다는 상황을 많이 보다보니까 text를 읽고 그대로 말하는 (parror) 식의 text spotting bias가 생긴 것이라고 보면 됩니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
Parrot Captions이 얼마나 있는지 파악하는 부분에서 K-means 알고리즘을 통해 4,000개의 cluster로 구분한 다음 각 cluster를 CLIP score로 정렬하였는데, 굳이 클러스터링을 한 이유가 있을까요? 또 SOTA spotting model인 DeepSolo를 사용해 파악을 했는데 이 모델이 영상 내 모든 텍스트를 100% 인식하지는 못할 것 같은데 이에 대한 고려를 하고 있는지 궁금합니다.
감사합니다.
댓글 감사합니다.
1. 데이터셋(LAION-2B)이 20억 쌍이나 되는 대규모 데이터셋인데, 이걸 그대로 다루기엔 너무 크기도 하고 그렇다고 랜덤 샘플링을 하기에는 전반적인 맥락을 파악하기 어렵기에 클러스터링을 한 것으로 유추됩니다.
2. 넵 맞습니다. DeepSolo도 영상 내 텍스트를 100% 인식하지는 못할 것이기에 이에 대한 고려를 하고 있는데. 첫 번째로 복잡한 scene(예를 들어 글자 수가 100개 이상이라던지..)에서는 성능이 낮을텐데 이건 전체 데이터셋 중에 2%미만이라 이에 대한 영향이 미미할 것이라고 보았습니다.