제가 이번에 리뷰할 논문은 3D Affordance논문으로, 3D 공간에 language 정보를 입히는 3D Gaussian splatting(3DGS, 이에 대한 자세한 설명은 태주님이 리뷰한 이전 X-review를 참고해주세요!)을 이용하였다고 하여 관심을 가지고 리뷰하게 되었습니다. 2024년 12월에 아카이브에 올라온 논문으로, 코드나 데이터 등을 아직 공개하지는 않았습니다. 이제 리뷰 시작하겠습니다.
Abstract
3D 물체에 대하여 affordance 정보를 식별하는 3D affordance learning은 로봇의 상호작용을 위해 중요한 문제지만, 3D annotation이 주어진 데이터가 제한적이며, 기하학적 정보를 encoding하는 3D 백본에 의존하기 때문에 일반화와 강인성 확보에 어려움이 있습니다. 해당 논문은 대규모 데이터로 사전학습된 2D 모델을 이용하여 3D affordance learning의 일반화와 강인성을 향상시키기 위한 GEAL이라는 프레임워크를 제안하였습니다. 저자들은 Gaussian Splatting이 포함된 2개의 브랜치를 가진 모델 구조를 사용하여 3D 포인트클라우드와 2D reference 이미지 사이의 대응 관계를 설정하므로써, sparse한 포인트클라우드에 사실적인 2D 렌더링을 가능하게 하였습니다. granularity-adaptive fusion 모듈과 2D-3D consistency alignment 모듈을 통해 상호 모달리티 간의 alignment와 지식 전이를 강화하고 3D 브랜치에 2D 모델의 풍부한 의미론적 정보와 일반화 능력을 활용할 수 있도록 합니다. 강인성에 대한 평가를 위해 저자들은 공개 데이터 셋을 활용하여 새로운 2개의 밴치마크 PIAD-C와 LASO-C를 제안하였으며, 실험을 통해 GEAL을 통해 손상된 데이터뿐만 아니라 seen과 novel 객체에 대해 기존 방법론보다 더 좋은 성능을 보였으며, 다양한 조건에서 강인하게 affordance를 추론할 수 있었습니다.
Introduction
3D affordance learning은 주어진 이미지와 언어 지시와 같은 의미론적 단서가 주어진 객체의 특정 영역을 식별하는 것으로, 로봇의 상호작용을 위해 필요한 능력입니다. 그러나, 이러한 3D affordance learning은 annotation이 달린 데이터가 제한적이라 풍부한 학습 데이터로 사전학습된 2D 모델에 비해 일반화 성능이 부족합니다. 또한, 3D 모델은 주로 기하학적 정보를 인코딩하는 데 집중하여 의미론적 정보를 파악하기 어려우며, 센서의 노이즈나 복잡한 장면 등의 이유로 발생하는 3차원 데이터의 손상에 취약합니다. 이러한 한계로 인해 3D affordance learning의 일반화 능력과 강인성이 제한적입니다.
해당 논문은 GEAL이라는 새로운 프레임워크를 제안하여 일반화 능력과 강인성을 확보하고자 하였으며, GEAL은 2개의 브랜치 구조로 이루어집니다. 각 브랜치는 2D 와 3D 데이터를 별도로 처리하며, 2D 표현과 3D 포인트 클라우드 사이의 대응 관계를 형성하기 위해 3D Gaussian splatting(3DGS)을 이용하여 sparse한 3D 데이터로부터 사실적인 2D 렌더링을 생성합니다. 이를 통해 사전학습된 2D foundation model의 일반화 능력과 풍부한 의미론적 정보를 활용한 3D affordance 예측이 가능하도록 합니다. 또한, 서로 다른 모달리티의 데이터 사이의 alignment를 맞추기 위해 granularity-adaptive fusion 모듈을 제안하여 다중 level의 visual-textual 특징을 통해 다양한 크기와 레벨의 affordance 쿼리를 처리하였으며, 2D-3D consistency alignment 모듈을 통해 2D와 3D 모달리티의 feature embedding 사이의 대응 관계를 설정하여 3D 브랜치의 일반화 성능과 강인성을 개선하였습니다.
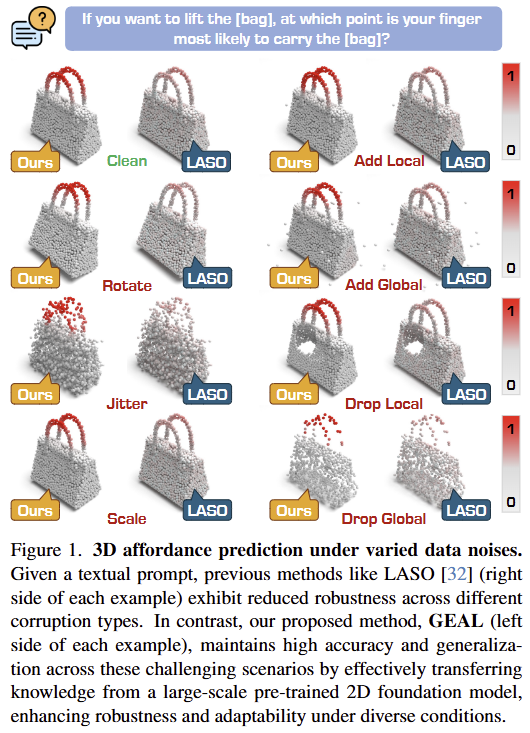
저자들은 3D affordance의 강인성에 대한 평가를 위해 2가지 데이터 셋을 제안하여 벤치마킹을 수행합니다. 기존의 공개 데이터 셋을 활용하여 PIAD-Corrupt와 LASO-Corrupt라는 파생 데이터 셋을 제안하며, 이를 통해 scaling과 cropping 등을 적용하여 3D affordacne에 대한 강인성을 평가합니다. 위의 Figure 1에서 저자들이 노이즈 및 변형을 준 예시를 확인할 수 있습니다. (Clean 버전이 기존 공개 데이터 셋이고, 이에 대해 다양한 변형을 주어 강인성에 대한 평가를 수행하고자 한 것 입니다. ImageNet-C 데이터와 같은 관점이라 보시면 될 것 같습니다.)
기존 벤치마크와 데이터에 손상을 주어 생성한 데이터 셋에 대한 실험을 통해 GEAL 방식의 강인성과 일반화 성능을 검증하였으며, GEAL이 본 적 없는 unseen 데이터에 대해서도 효과적으로 지식을 전이하고, 손상된 데이터에 대해서도 높은 성능을 유지할 수 있음을 입증하였습니다.
해당 논문의 contribution을 정리하면
- GEAL이라는 새로운 3D affordance learning 프레임워크를 제안함. GEAL은 3DGS를 사용하여 3D 포인트클라우드에 대한 2D affordance prediction 브랜치를 만들어, 사전학습된 2D foundation model의 일반화 성능과 이해 능력을 활용함.
- granularity-adaptive fusion 모듈과 2D-3D consistency alignment 모듈을 제안하여 2개의 브랜치 구조 전반에 걸친 지식을 통합하고 전이하여, 2D 지식을 통해 3D 브랜치의 일반화 성능을 개선함
- PIAD-C와 LASO-C 벤치마크를 제안하여 실제 시나리오를 고려한 3D affordance learning의 강인성 평가가 가능하도록 함.
- 다양한 실험을 통해 기존 데이터 셋과 손상이 발생한 데이터 셋 모두에서 가장 좋은 성능을 달성하였으며, 이를 통해 제안한 GEAL의 일반화 성능과 강인성을 입증함.
Methodology
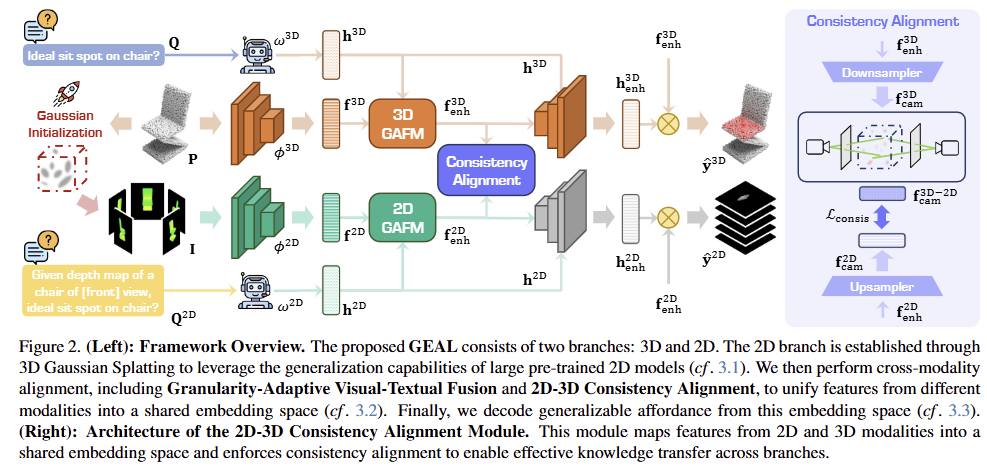
Figure 2는 GEAL의 전체적인 프레임워크를 나타낸 그림으로, 지시문 Q와 N개의 포인트로 이루어진 물체의 3D 포인트크라우드 \mathbf{P} \in \mathbb{R}^{N⨉3}가 주어졌을 때, GEAL은 각 포인트에 대하여 특정 기능에 대한 확률값인 affordance score \mathbf{y} \in \mathbb{R}^{N}를 예측합니다.
1. 3D-2D Mapping with Gaussian Splatting
저자들은 먼저 해당 과정의 motivation에 대하여 밝힙니다. 앞서 introduction에서도 이야기하였듯, 3D affordance learning은 제한적인 데이터로 인해 일반화에 어려움을 겪으며, global한 의미론적 정보를 파악하기 어려워 강인성이 약합니다.(예를들어, 의자인 걸 알아야 앉는 부분에 대하여 인식할 수 있고, 가방이라는 걸 알아야 가방을 들기 위해 손잡이를 인식할 수 있습니다.) 저자들은 2D affordance learning 방법론들은 2D foundation model을 사용하여 높은 일방호 ㅏ 성능과 강인성을 확보하였다는 점을 통해 3D affordance learning에 이를 적용하고자 하였습니다. 그러나 3D 포인트클라우드를 2D에 바로 투영하는 방식은 깊이 정보 등을 잃고 sparse하여 2D foundation model로 feature를 추출하기 어려움이 있습니다. 이를 해결하고자 저자들은 3D 장면을 학습 가능한 가우시안 분포로 표현하는 3D Gaussian Splatting(3DGS)을 적용하여 임의의 view point에서 사실적이고 다양하며 빠른 렌더링이 가능하게 하였습니다. 이를 통해 sparse한 포인트클라우드로부터 사실적인 2D 이미지를 합성하여 affordance learning을 위한 의미론적-기하학적 정보를 보존할 수 있었다고 합니다.
<Gaussian Initialization>
3DGS에서 각 가우시안 초기값은 3D 위치를 나타내는 3D 좌표 \mu와 형태와 분포를 나타내는 공분산 행렬 \Sigma, 색상을 나타내는 파라미터 c, 투명도를 나타내는 값 \alpha로 이루어집니다. 3D 가우시안 초기값을 2D 이미지 평면으로 렌더링하기 위해 \alpha-blending(영상처리기법으로 투명도에 대한 알파값을 이용하여 색상을 혼합하는 방식)을 적용하며, 각 픽셀 v에 렌더링되는 색상은 다음의 식으로 정의됩니다.
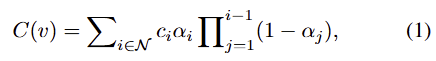
- c_i: i번째 가우시안의 색상
- \mathcal{N}: tile 수
- \alpha_i = o_iG_i^{2D}(v)로 o_i는 i번째 가우시안의 투명도, G_i^{2D}(.)는 i번째 가우시안의 2D 평면으로의 투영 함수
이와 유사하게 Depth map은 다음의 식으로 렌더링을 할 수 있습니다.
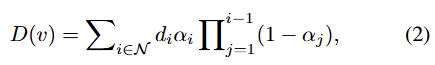
- d_i: 주어진 카메라 위치에서 i번째 가우시안의 깊이
렌더링된 이미지가 입력된 포인트클라우드 \mathbf{P}의 기하학적 정보를 정확하게 반영하기 위해 가우시안의 평균 위치가 포인트 클라우드와 일치하도록 설정합니다. (\mu = \mathbf{P}) 공분산 \Sigma와 불투명도 \alpha는 수동 조정을 통해 설정해둔 뒤, 학습 과정에서 고정하여 기하학적 정보를 유지하도록 합니다. V개의 카메라 포즈와 사전에 정의된 컬러맵을 앞서 구한 depth와 함께 사용하여 사실적인 이미지들 \mathbf{I} \in \mathbb{R}^{V⨉3⨉H⨉W}를 생성합니다.
affordance score \mathbf{y} \in [0,1]의 초기값은 흑백 이미지의 색상으로 설정하고(c = \mathbf{y} ), 2D affordance mask \mathbf{y}_{2D} \in \mathbb{R}^{V⨉3⨉H⨉W}를 생성하여 각 픽셀이 연관된 3D 포인트의 affordance score를 나타냅니다. 이 과정을 통해 사실적인 2D representation을 생성함으로써 3D 포인트클라우드와 affordance score가 2D에서 일관되게 매핑되도록 합니다.
<Encoding>
GEAL 프레임워크는 2D와 3D 브랜치로 구성되며 각 브랜치의 백본을 \phi^{2D}(.)와 \phi^{3D}(.)라 할 때, 3D 브랜치의 백본은 PointNet++, 2D 브랜치의 백본은 DINOv2를 이용합니다. 두 네트워크는 다중스케일의 feature를 제공하며 각 스케일 i로부터 특징을 추출합니다.
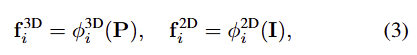
- \mathbf{f}_i^{3D} \in \mathbb{R}^{B⨉C_i^{3D}⨉N_i^P}: B는 배치사이즈, C_i^{3D}는 feature의 차원수를 의미하며, N_i^P는 스케일 i에서의 포인트 수를 나타냅니다.
- \mathbf{f}_i^{2D} \in \mathbb{R}^{B⨉V⨉C^{2D}⨉N^I}: 동일하게 B는 배치사이즈, V는 view의 수, C^{2D}는 feature의 차원수를 의미하며, N^I는 스케일 i에서의 이미지 패치의 길이를 나타냅니다.
3D와 2D에 대한 입력 프롬프트를 처리하기 위해 Q는 경량화된 language 모델 \omega^{3D}(.), \omega^{2D}(.)을 이용하며, 2D 입력에는 "Given a depth map of a [object] in [view]"를 추가하여 Q^{2D}로 수정합니다. 이는 프롬프트가 시점에 따라 달라지도록 하여 맥락 정보에 대한 이해를 높이도록 하며, text embedding들은 다음과 같이 구해집니다.
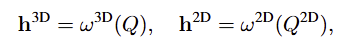
- \mathbf{h}^{3D} \in \mathbb{R}^{B⨉C^{txt}⨉L}
- \mathbf{h}^{2D} \in \mathbb{R}^{B⨉V⨉C^{txt}⨉L}
- L: 시퀀스의 길이
2. Cross-Modal Consistency Alignment
포인트클라우드, 이미지, 언어 feature가 서로 다른 공간에 임베딩되므로,, 서로 다른 모달리티간의 공통의 embedding 공간에 매핑하기 위해 저자들은 alignment 모듈을 설계하였습니다. 먼저 Granularity-Adaptive Visual-Textual Fusion을 통해 다양한 수준의 세분화에 대한 시각적 특징을 텍스트와 융합하여, 다양한 수준의 따라 조절이 가능하도록 합니다. 이후 2D-3D Consistency Alignment를 통해 2D와 3D feature사이의 일치를 강화합니다.
<a. Granularity-Adaptive Visual-Textual Fusion>
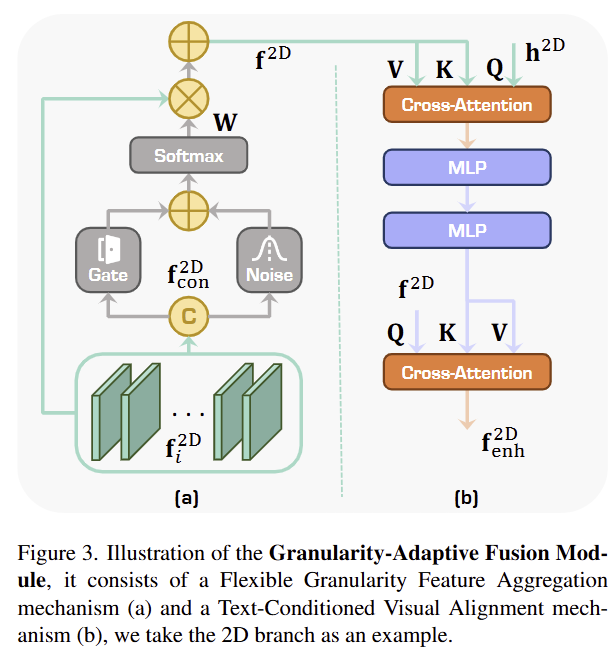
2D와 3D 모두 레이어의 깊이에 따라 다른 수준의 세분화를 인지합니다. low-level의 feature는 디테일에 초점을 맞추고 high-level의 feature는 더 넓은 맥락정보를 포착합니다. affordance는 물체의 여러 부분에 걸쳐있을 수 있으므로 다양한 수준의 세분화를 고려하는 것이 좋고, 이를 위해 저자들은 Granularity-Adaptive Fusion Module (GAFM)을 제안하였습니다. GAFM의 구조는 Figure 3에서 확인할 수 있으며, 해당 모듈을 통해 다양한 수준의 세분성을 feature에 적응적으로 융합합하여 affordance를 예측할 수 있도록 합니다. 먼저 2D 브랜치에서의 과정을 설명하면 다음과 같습니다.
(a) Flexible Granularity Feature Aggregation
먼저, 해당 과정은 서로 다른 수준의 세분화된 시각 feature를 융합하는 것을 목표로 합니다. 이를 위해 여러 수준의 feature를 하나의 tensor \mathbf{f}^{2D}_{con} \in \mathbb{R}^{B⨉V⨉(m⨉C^{2D})⨉N^I}로 융합한 뒤, 학습된 gating 함수와 가우시안 노이즈를 이용하여 각 특징에 가중치를 주어 최종의 2D feature map \mathbf{f}^{2D}을 생성합니다. 이를 통해 다양한 수준의 정보를 고려할 수 있도록 합니다
(b) Text-Conditioned Visual Alignment
해당 과정은 시각 feature \mathbf{f}^{2D}와 text 지시문에 대한 feature \mathbf{h}^{2D}를 통합하는 모듈로 두 feature를 받아 트랜스포머 블록에 입력합니다. \mathbf{h}^{2D}를 쿼리, \mathbf{f}^{2D}를 key,value로 cross-attention과 2개의 MLPs를 사용하여 시각적 특징으로 \mathbf{h}^{2D}를 개선한 뒤, 개선된 \mathbf{h}^{2D}를 key,value로 이용하여 개선된 시각 feature인 \mathbf{f}^{2D}_{enh}를 구합니다.
3D는 해상도와 차원이 다르므로 모든 스케일의 feature에 대하여 가중치를 주어 직접적으로 결합하는 데 어려움이 있으므로, (b)과정을 먼저 모든 scale에서 적용한 뒤, 이를 upsampling하여 동일한 해상도로 만든 뒤, (a)과정을 수행합니다.
<b. 2D-3D Consistency Alignment>

2D feature는 사전학습된 백본을 통해 풍부한 의미론적 정보와 일반화 성능을 제공할 수 있고, 3D feature는 기하학적-공간적 정보를 보존하여 self-occlusion이 발생할 경우 2D 정보가 손실되는 것을 보완할 수 있습니다. 따라서 저자들은 2D와 3D 정보를 상호보완적으로 활용하고, alingment를 맞추기 위해 Consistency Alignment Module(CAM)을 제안합니다.
저자들은 2D-3D 사이의 대응관계를 고려할 때, 동일한 공간에 대한 2D와 3D representation은 유사한 feature representation을 가져야 한다고 생각하였으며, 위의 그림과 같이 \mathbf{f}^{3D}_{enh}와 \mathbf{f}^{2D}_{enh}를 공통 공간으로 매핑하고자 하였습니다.
3D와 2D를 동일 공간으로 임베딩하기 위해 2개의 Conv1D 레이어로 구성된 donw-sampler를 사용하여 \mathbf{f}^{3D}_{enh}의 차원 수를 줄인 \mathbf{f}^{3D}_{cam}를 구한 뒤, Gaussian splatting을 활용해 3D feature를 2D로 투영하여 2D-3D 매핑을 설정하였으며, 각 가우시안에 대해 point feature vector를 특성으로 고려하여 픽셀 v의 2D feature는 다음의 식을 이용하여 렌더링 하였습니다.
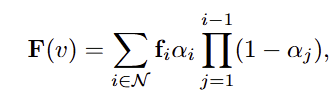
유사하게 2D feature를 동일 공간으로 임베딩 하기 위해 2개의 Conv2D 레이어로 구성된 up-sampler를 이용하여 \mathbf{f}^{2D}_{enh}의 해상도를 높이고 차원수를 줄인 \mathbf{f}^{2D}_{cam}을 구합니다.
이렇게 구한 두 feature의 consistency를 강화하기 위해 L2 loss를 이용하여 학습하며,
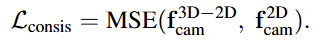
해당 과정을 통해 2D와 3D feature가 동일 공간으로 임베딩 되도록 하며, 2D의 사전학습된 모델의 지식을 3D로 전이할 수 있도록 합니다.
3. Decoding Generalizable Affordance
affordance score는 입력된 지시문에 따라 decoding되며, transformer decoder를 통해 텍스트와 시각적 특징을 결합하여 어포던스 점수를 예측합니다. 디코더는 2D 브랜치와 3D 브랜치가 공유하며, 2D 브랜치에서는 \mathbf{h}^{2D}가 쿼리, \mathbf{f}^{2D}_{enh}가 key, value로 사용됩니다. transformer decoder를 통과하여 구한 textual feature \mathbf{h}^{2D}_{enh}와 \mathbf{f}^{2D}_{enh}를 곱한 뒤 시그모이드를 적용하여 최종적인 affordance score를 구합니다. 이렇게 하여 지시문에 따라 다른 영역이 활성화 되도록 합니다.
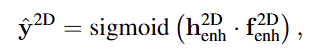
<Training>
저자들은 2D의 정보를 3D로 전이하기 위해 1단계에는 2D 브랜치를 먼저 학습하여 강인한 feature를 추출하고 affordance decoding을 예측할 수 있도록 한 뒤, 2단계 학습시에는 CAM을 제외한 2D 브랜치를 모두 freeze하여 학습을 수행합니다.
학습에 사용되는 loss를 살펴보면, 먼저 2D 브랜치는 Binary CrossEntropy와 segmentation에서 사용되는 Dice loss를 사용합니다. BCE Loss를 통해 affordance score에 대한 예측 오차가 최소화 되도록 하고, Dice Loss를 통해 GT와 예측된 영역의 IoU가 최대가 되도록 합니다.
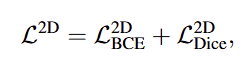
3D loss는 아래의 식으로 정의되며, 앞서 정의된 consistency loss가 추가됩니다.
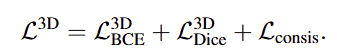
이후, Inference 시에는 3D 브랜치만을 이용하게 됩니다.
4. Corrupt Data Benchmark
3D affordance의 강인성을 평가하기 위해, 저자들은 PIAD와 LASO test 셋에 변형을 주어 PIAD-C와 LASO-C를 제안합니다. 저자들은 7가지의 변형(Add Global, Add Local, Drop Global, Drop Local, Rotate, Scale, Jitter)에 대해 5가지의 정도로 이루어진 변형을 주어 23개의 물체와 17개의 affordance 카테고리에 대해 4,890개의 물체-affordance 쌍을 생성합니다.


Experiments
1. Comparisons to State-of-the-Art Methods
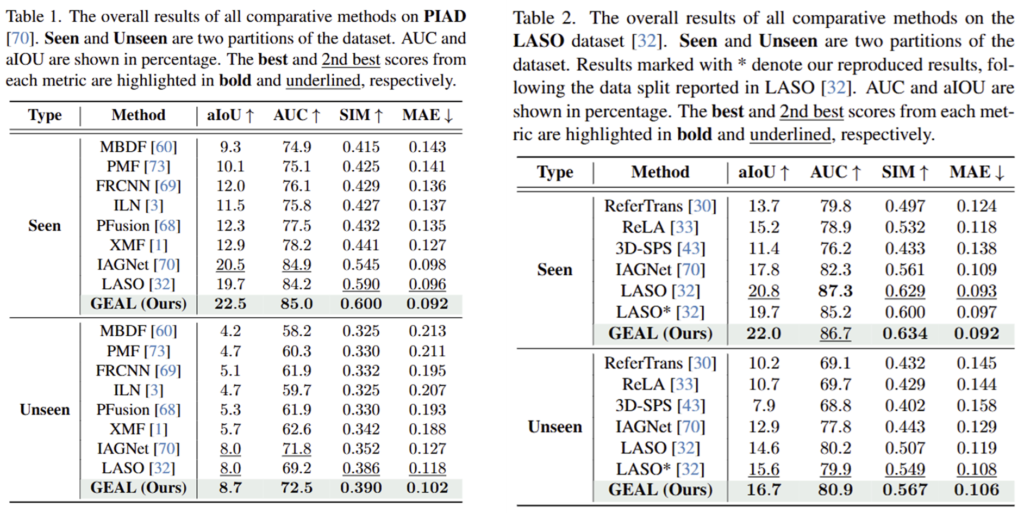
- 기존 공개 데이터인 PIAD와 LASO 데이터에 대한 실험 결과로, seen과 unseen 객체에 대해 두 데이터에서 모두 GEAL이 가장 좋은 성능을 달성하였습니다.(LASO의 Seen에서 AUC는 2번째로 좋은 성능이긴 하지만 전반적으로 모두 성능이 개선되었습니다.)
- 저자들은 사전학습된 2D feature를 활용하였으며, 2D-3D cross modal의 일관성을 확보하는 방식을 통해 정확도가 개선되었다고 어필하고있습니다.
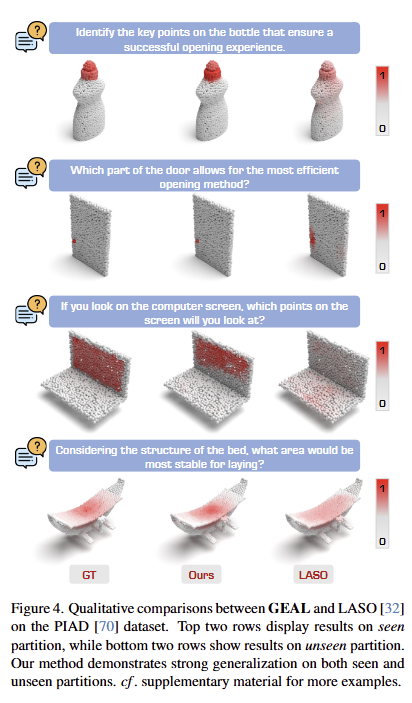
- 아래의 그림은 정성적 결과로, Ours의 활성화 된 부분이 LASO방식보다 더 정확한 영역에 나타나는 것을 볼 수 있습니다.
Robustness on Corrupt Data
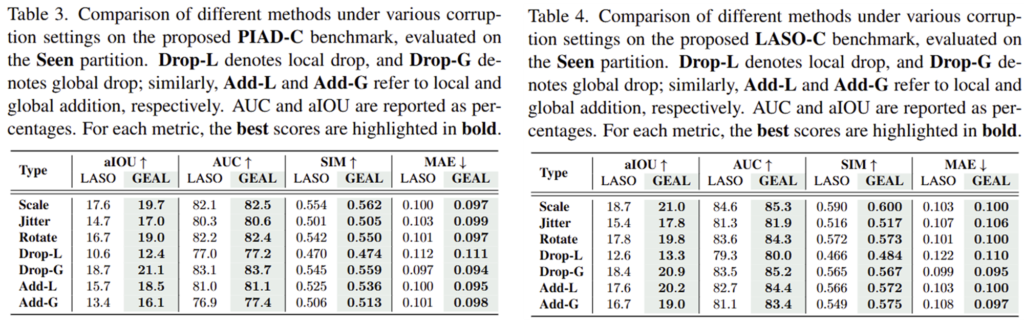
- 해당 실험은 저자들이 제안한 PIAD-C와 LASO-C 데이터 에 대한 결과로, 실제 시나리오에서 3D 포인트클라우드 정보에 손상이 생겼을 때 얼마나 강인하게 작동하는 지를 확인할 수 있습니다.
- LASO 방식과 비교했을 때 GEAL이 모두 높은 성능을 달성하였으며, 이를 통해 저자들은 손상된 정보가 주어졌을 때도, GEAL이 더 강인하게 작동 가능함을 보였습니다.
2. Ablation study
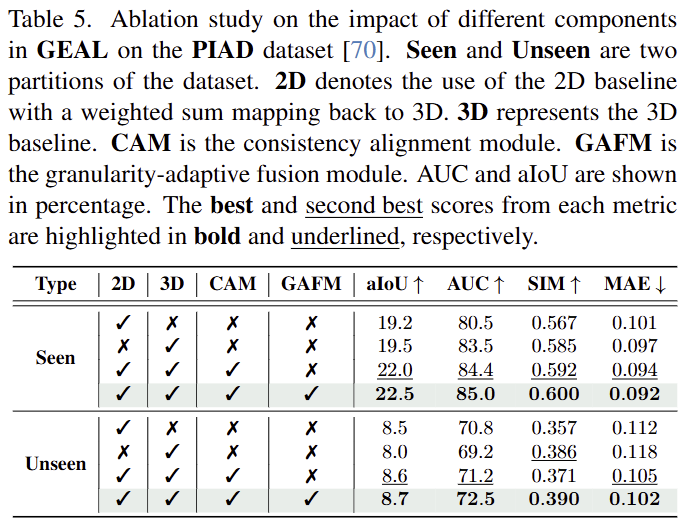
- PIAD 데이터에 대한 ablation study결과로 모두 적용한 것이 가장 좋은 성능을 보였으며, 2D와 3D를 모두 사용하는 게 효과적임을 실험적으로 입증하였습니다. 하지만 Unseen에 대하여 SIM의 성능이 CAM을 사용하였을 때 저하가 발생하는 데, 이에 대해서는 별다른 분석이 없습니다.
Conclusion
해당 논문은 대규모 데이터로 사전학습된 2D 모델을 활용하여 3D affordance의 일반화와 강인성을 높이기 위한 GEAL 프레임워크를 제안하였으며, 3DGS를 사용하는 2개의 브랜치 구조로 사실적인 렌더링을 수행하고 서로 다른 모달리티의 데이터들 사이의 alignment를 맞추기 위한 모듈을 제안하여 효과적으로 2D 정보를 3D로 전이할 수 있도록 하였습니다. 또한 실험 다양한 실험 결과들을 통해 GEAL의 성능이 우수함을 보였습니다.
안녕하세요 승현님 리뷰 감사합니다.
해당 방법론은 대규모로 학습된 2D 모델의 2D 성능을 3D에 잘 녹여내서 3D affordance를 강화하겠다는 컨셉으로 이해했는데 맞는 이해일까요?
또 Unseen에 대하여 CAM을 사용했을 때 저하된다고 한 부분은 2D를 3D로 합치는 모델의 한계라고 생각해도 될까요?
질문 감사합니다.
이해하신대로, 저자들은 대규모 데이터로 학습되어있는 2D 모델의 지식을 활용해서 3D affordance에 대해 서 잘 예측하고자 하였습니다.
저자들이 이에 대해서 별도의 분석은 이루어지지 않았습니다. 2D와 3D를 합치는 과정에서 생기는 한계라 보시면 될 것 같고, 2D와 3D 레이어가 깊이마다 다른 수준의 세분화 정보를 인지하므로, 이를 적응적으로 융합하여 affordance 예측을 고도화하기 위한 GAFM을 통해 이를 조금 완화한 것으로 이해하시면 될 것 같습니다.
안녕하세요. 승현님 리뷰 감사합니다.
3D와 2D를 다루기 위해서 프롬프트 Q를 2D로 변환하여 동시에 사용하는 것이 재밌는 부분인 것 같습니다. 특히나 2D로 변환하며 시점을 추가하는 부분이 특히 그러한데, prompt의 “[view]”에 해당하는 것은 어떤식으로 입력이 들어가게 되나요? feature로서 입력이 들어가는지 아니면 view에 대해서 미리 text list를 정해두고 이를 불러와서 사용하는지 궁금합니다.
감사합니다.
질문 감사합니다.
Figure 2의 예시에는 front라 되어있으나, 이에 대한 정확한 설명은 따로 없었습니다. 이에 대해 추론해보자면, text가 들어가는 지 확인이 어렵지만, 경량화된 language mode을 통해 Q^2D로 수정한다는 점에서 [view]에는 front와 같이 시점에 대한 text 정보가 들어가는 것으로 알고있습니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
지금 3D-GS를 거쳐서 사용하는 2D 이미지가 depth map을 의미한다고 이해하였습니다. 보통의 의미론적-기하학적 정보를 보존하였다고 함은 RGB 이미지를 사용 해당 방법론에서 추가적으로 RGB 이미지를 사용하진 않는건가요 ?
그리고 인코더로 들어가는 입력이 pair한 포인트-depth map이라면 “Given a depth map of a [object] in [view]”가 들어갔을 때 포인트는 어떤 시점이라도 동일한 시점의 데이터가 들어가는걸까요 ? 하나의 시점을 가진 포인트에 대해 여러 시점의 depth map이 들어가면 구분하기 위한 추가적인 과정은 없는 것인지 궁금합니다.
마지막으로 3D-GS의 결과가 최종 성능에 영향을 크게 미친다고 생각이 드는데, 혹시 다른 GS 방식을 적용했을 때 성능에 대한 ablation study는 없었을까요 ??
감사합니다.
질문 감사합니다.
3D-GS과정에 RGB 이미지는 사용하지 않는 지 질문하신 게 맞을까요? 우선 데이터 셋 자체가 RGB 정보를 포함하지 않고있는 것으로 알고있습니다.
여러 시점의 depth map을 구분하기 위해 프롬프트에 [view]가 들어가게 됩니다. 이게 코드로 어떻게 구현이 되었는지는 공개가 되어있지 않아 정확히 확인이 어렵고, 논문에서는 이렇게 프롬프트에 [view]를 추가하므로써 view-dependent prompt를 구성할 수 있었다고 표현합니다.
말씀하신 GS 방식에 대한 ablation study는 따로 없습니다. 이야기하신대로 GS가 중요한 역할을 하고있다보니, 적용하는 GS에 따라 성능과 소요시간이 크게 변할 것 같습니다.
안녕하세요 승현님, 좋은 리뷰 감사합니다.
1. (a) Flexible Granularity Feature Aggregation에서
gating 함수와 가우시안 노이즈를 이용하여 각 특징에 가중치를 주어 최종의 2D feature map를 생성하여, 다양산 수준의 정보를 고려할 수 있게한다고 하셨는데, 해당 gating함수는 어떤 구조로 이루어져 있나요?
2. affordance score 의 초기값을 흑백 이미지의 색상으로 설정하는 이유가 뭔가요?
3. Granularity-Adaptive Visual-Textual Fusion 이 먼저 이루어진 후, 2D-3D Consistency Alignment 가 이루어지는 이유가 뭔가요? 뭔가 해당 모듈의 순서가 앞뒤가 바뀌어도 무리가 없을 것 같단 생각이 듭니다. 예를 들어 2D-3D Consistency Alignment를 먼저 맞춰주고 나서, 3D와 text간의 visual align을 맞추고 동시에 2D와 text간의 visual align을 맞추는 것도 괜찮지않나 라는 생각이 드는데, 해당 순서가 정해진 이유가 있을까요?
감사합니다.
질문 감사합니다.
1. 논문에서는 W=Softmax(f^{2D}_{con} \cdot W_g + \sigma \cdot \epsilon)로 구성된다고 합니다. 여기서 W_g는 학습된 가중치를 의미하며, \epsilon은 0~1 사이의 노이즈입니다.
2. 픽셀의 색상이 affordance score와는 연관이 없다고 생각하여,, 저는 큰 이유는 없이 초기화한 것이라 이해하였습니다.
3.
일단 2D-3D consistency는 2D feature와 3D feature 간의 일치를 강화하는 과정으로, 각각의 feature를 query와 합쳐 개선한 뒤, 이들 사이의 일관성을 높이는 방식이 보다 설득력 있어 보입니다. 또한, Text-Conditioned Visual Alignment 과정에서는 2D와 3D 간의 형태적 차이로 인해 순서가 조금 다르며, 해당 과정을 통해 두 feature의 형태를 맞춰준 뒤 두 feature 사이의 consistency를 강화한 것으로 보입니다.