안녕하세요. 박성준 연구원입니다. 오늘 제가 리뷰할 논문은 ECCV 2024에 게재된 TFVTG논문으로 Video Temporal Grounding을 다룬 논문입니다.
Introduction
Video Temporal Grounding(VTG)은 untrimmed video에서 자연어 query와 가장 관련이 깊은 비디오 구간을 찾는 것을 목표로 하는 task입니다. 즉, 입력으로 untrimmed video와 language query가 들어오게 되면 language query가 설명하는 구간을 untrimmed video에서 찾아 해당 구간의 시작점(start timestamp)와 끝점(end timestamp)를 반환하는 task입니다. 기존의 VTG를 포함하는 temporal localization 모델들은 대규모 데이터셋에 의존하여 학습합니다. 하지만 대규모 데이터셋에 의존하여 학습하는 방법은 학습 비용이 많이 들고 zero-shot 혹은 out-of-distribution(OOD) 상황에서는 성능을 보장할 수 없다는 단점이 존재합니다. 저자는 위와 같은 문제가 대규모 학습 데이터셋의 경우 trimmed video(다듬어진 영상으로 자연어에 해당하는 구간이 영상의 시작부터 끝까지 진행)와 해당하는 자연어 클래스로 설정되어 학습하기에 untrimmed video에는 잘 대응할 수 없음을 지적하고 있습니다. 또한 이러한 대규모 데이터셋에서 학습하는 경우 데이터셋에 존재하지 않는 데이터가 평가에 사용된다면, 대응할 수 없다는 점을 지적하며 데이터셋에 편향되는 경향이 있다고 설명하고 있습니다.
VTG는 특히 video와 query간의 fine-grained alignment(정렬)을 수행하는 task로 annotation의 cost가 굉장히 큽니다. AcvityNet Captions 데이터셋과 Charades-STA 데이터셋과 같은 데이터셋들은 video와 natural language query를 제공하고 query에 대응하는 구간의 시간 지점(start timestamp, end timestamp)가 주석으로 존재해 VTG에서 학습 및 평가에 많이 사용되는 데이터셋입니다. 앞서 설명드린 것과 같이 VTG는 annotation cost가 굉장히 크기 때문에 현존하는 많은 VTG 연구들은 특정 데이터셋(ActivityNet Captions, Charades-STA 등)에 많이 의존하고 있습니다. 하지만, 그렇기 때문에 기존 VTG 연구들은 학습 데이터셋의 분포에 크게 의존하게 되고 이는 zero-shot 및 OOD 상황에 취약합니다.
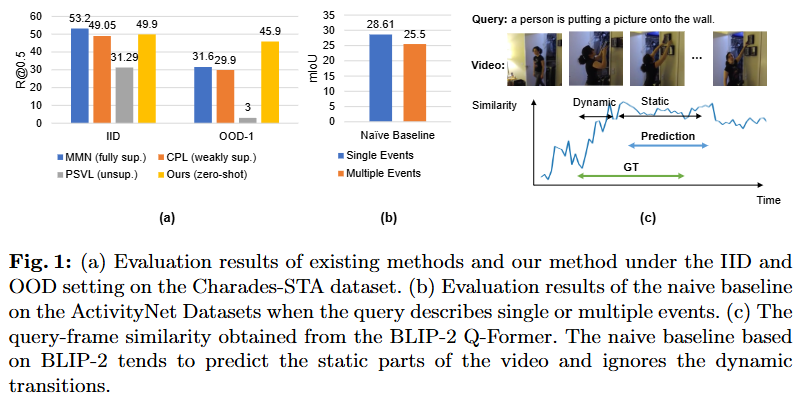
위 Fig. 1 (a)는 기존 연구들이 이러한 OOD 상황에 많이 취약하는 것을 시각적으로 보여주는 자료입니다. MMN, CPL, PSVL 모델들은 각각 fully-supervised VTG, weakly-supervised VTG, unsupervised VTG 연구입니다. Fig. 1 (a)에서 위 연구들은 OOD 상황에서 기존 성능대비 큰 성능 하락폭을 보여주고 있습니다. 저자는 이를 근거로 학습에 비용과 시간이 들지 않으면서도, 일반화 능력이 좋은 VTG 연구의 필요성을 강조하며 추가적인 학습을 하지 않아 데이터셋에 편향되지 않는 방법인 training-free(학습이 필요없는) VTG 연구를 설계합니다. naive하게 대규모 vision-language 사전학습 모델을 사용하여 각 후보 구간과 query의 유사도를 통해 가장 높은 유사도의 구간을 고르는 방식으로 training-free 방법을 사용할 수 있지만, 저자는 이러한 naive baseline(기존 연구들 중 학습을 하지 않은 연구는 존재하지 않았기에 저자는 임의로 naive baseline을 설정했고, naive baseline을 비교삼아 단순히 사전학습된 VLM을 사용하는 것과 저자가 제안하는 방법론의 차이점을 설명합니다)에는 큰 문제가 존재한다고 합니다.
첫 번째 문제점은 정확한 시간 경계를 파악하는 것의 어려움입니다. VTG에서의 입력 video는 untrimmed video로 다양한 event가 존재하고 모델은 이러한 여러 event의 시간적 관계를 이해할 수 있어야 합니다. 하지만, 사전학습된 vision-language 모델은 짧은 trimmed video와 자연어로 학습되기에 여러 event가 존재하는 상황에서는 성능이 많이 저하될 수 있습니다. 두 번째 문제점은 naive baseline은 event가 시작되는 동적인 변화가 일어나는(dynamic transition) 정확한 지점을 찾을 수 없다는 것입니다. 조금 더 자세하게 설명하면 “사람이 걸음을 멈추고 달리기 시작하다.”라는 자연어 query가 있을 때에 사람이 걷는 구간과 달리는 구간 사이에서 “걸음”이 “달리기”로 전환되는 정확한 지점을 trimmed video로 사전학습된 vision-language 모델은 찾을 수 없다는 것을 의미합니다. Fig. 1 (c)의 그림이 기존의 VLM(BLIP-2)를 naive baseline으로 사용했을 때의 예측 결과와 유사도를 보여주는 그림으로 실제 GT는 event의 전환이 일어나는 구간(dynamic, 유사도가 증가하는 지점)을 포함하여 있지만, naive baseline은 전환이 끝나고 난 후의 구간(static, 유사도가 높은 지점)만을 예측하고 있습니다.
위 문제를 해결하기 위해 저자는 Large Language Model(LLM)의 query에 대한 이해 및 추론 능력과 Vision Language Model(VLM)의 프레임 단위 vision text align 능력을 활용하는 결합된 형태의 프레임워크를 제안합니다. 결합된 프레임워크는 LLM을 통해 복잡한 형태(fine-grained)의 query를 여러개의 비교적 간단한 형태(coarse-grained)의 query로 세분화한 후에 VLM을 사용하여 간단한 형태의 query가 설명하는 구간을 예측합니다. 그 후에 여러개의 간단한 형태의 query의 예측 구간을 원래(복잡한) query의 순서 및 의미에 일치하도록 후처리(맞추고 정렬)해주는 방식으로 예측을 수행합니다. 또한 위에서 설명한 것과 같이 기존의 VLM은 dynamic 구간에 대한 이해력이 부족하기에 event를 dynamic 구간과 static 구간을 구분한 후에 유사도 변화율(dynamic score)와 유사도(static score)를 통해 예측을 수행합니다. 결과적으로 저자가 제안하는 프레임워크는 Fig.1에서 확인할 수 있듯이 특정 데이터셋의 분포에 편향되지 않고 강건한 예측을 수행할 수 있습니다.
이에 따르는 저자의 Contribution은 다음과 같습니다.
- 저자는 LLM과 VLM을 활용하여 학습이 필요없는 VTG를 위한 파이프라인을 제안합니다. 이 프레임워크는 LLM을 총해 query를 세분화하고 세분화된 query를 VLM을 통해서 예측을 수행하고 temporal order와 temporal relationship을 이용하여 다시 후처리하는 것으로 예측을 수행합니다.
- VLM이 세분화된 query를 통해 좀 더 정확한 예측을 수행할 수 있도록 저자는 dynamic구간과 static 구간을 구분하여 예측을 수행하고 각기 다른 구간을 평가하기 위한 score(유사도 변화률로 dynamic score, 유사도로 static score)를 제안합니다.
- 이 방법은 데이터셋을 통해 직접 학습하는 방법보다 test셋에서의 성능은 낮을 수 있지만, zero-shot 상황과 OOD 상황에서의 성능을 많이 개선시켜 기존 모델이 가지고 있던 데이터셋에 편향되는 문제를 해결하고 모델의 일반화 능력을 향상시켰습니다.
Method
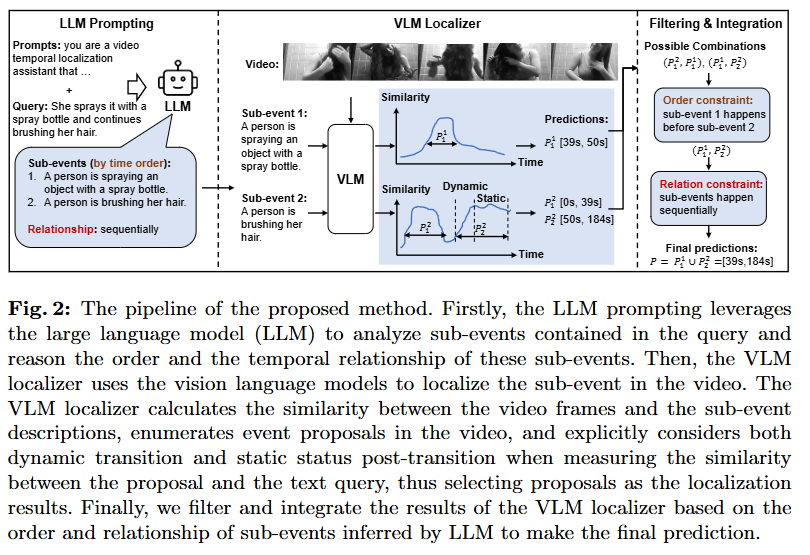
Fig 2는 저자가 제안하는 파이프라인의 overview입니다. 첫 단계에서는 query를 LLM으로 분석하여 여러 하위 event와 그 하위 event들의 시간, 논리적 관계를 파악합니다. 그림에서의 예시처럼 “She sprays it with a spray bottle and continues brushing her hair.”라는 복잡한 형태의 query가 입력으로 들어오면, 위 query를 “A person is spraying an object with a spray bottle.”과 “A person is brushing her hair.”로 세분화합니다. 그리고 두 문장의 관계를 정의합니다. 이때 문장의 관계를 single-event(하나의 event), simultaneously(동시에 발생), sequentially(순차적으로 발생)의 세가지 중 하나로 정의합니다. 두 번째 단계에서는 VLM localizer를 통해서 각 하위 event들의 구간(proposal)을 구합니다. 그리고 세 번째 단계에서는 dynamic 구간과 static 구간을 분리하여 각각의 점수를 계산한 후에 LLM이 추론했었던 문장 사이의 관계를 통해 결과를 통합하는 것으로 최종 예측을 생성합니다.
LLM Prompting
위와 같은 방법을 통해 저자는 학습이 없이도 VTG를 수행할 수 있습니다. 좀 더 정확한 예측을 수행하기 위해서 저자가 말하는 핵심은 LLM을 통한 query 세분화와 구분된 dynamic, static score를 통한 event 전체 과정을 예측하는 것입니다. 첫 번째 핵심인 query 세분화를 위한 LLM의 구체적인 prompt는 4가지 단계를 통해 진행되며 query를 분석하고 sub-events로 분할하는 Reasoning, 세분화된 query를 시간 순으로 정렬하는 Order of sub-events, 세분화된 query의 관계를 분석하는 Relationships between sub-events, 그리고 세분화된 query에 대한 설명을 생성하는 Textual descriptions입니다. 위 4가지 과정을 통해 저자는 복잡한 query를 간단한 query로 세분화하고 각각의 관계를 구조적으로 이해함으로 VTG과정에서 좀 더 정확한 매칭이 가능하다고 주장합니다.
Grounding with Vison Language Model
VLM을 통해 세분화된 query들이 설명하는 구간을 검출하는 과정에서는 BLIP-2의 Q-Former를 사용합니다. 이때 유사도를 기반으로 검출하게 되는데 유사도는 심플하게 코사인 유사도를 사용합니다. 수식은 아래와 같습니다.
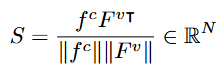
기존 연구들 및 naive baseline은 전체 video에서 유사도를 기반으로 후보구간을 생성하고 그 중에 평균 유사도를 통해 예측을 수행합니다. 하지만, 단순하기 유사도의 평균이 높은 구간을 예측으로 사용하는 것은 event가 시작하는 dynamic transition을 놓치기 쉽습니다. 평균을 통해 계산하면 event가 시작하는 지점은 유사도가 높은 static 구간에 도달하기 전 유사도가 높아지기 시작하는 dynamic한 구간을 놓칠 수 있기 때문입니다. 이때 유사도가 높아지는 지점을 저자가 dynamic transition이라고 칭하는 이유는 유사도가 동적으로 변화하는 구간인 동시에 실제 video에서도 동작을 수행하는 dynamic한 구간을 나타내기에 dynamic이기 때문입니다. 만약에 “사람이 자리에 앉는다”라는 query가 입력으로 들어온다면 사람이 앉아 있는 구간은 유사도가 높게 존재하지만, 사람이 일어서있다가 앉기 사이에 앉고 있는 구간은 유사도가 점차 증가하는 구간으로 평균 유사도는 낮지만, 실제 예측에는 사람이 앉으려고 움직이는 구간 또한 앉아있는 구간과 마찬가지로 포함되어 있어야하기 때문입니다. 따라서 저자는 유사도가 높아지는 dynamic transition을 찾기 위해서 dynamic score는 유사도의 변화율을 측정하는 것으로 선정하고 static한 구간은 평균 유사도를 통해서 계산합니다.
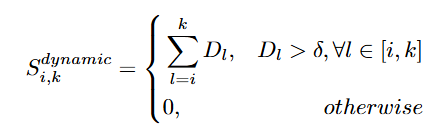
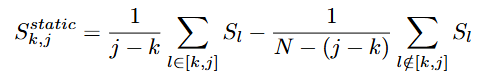
dynamic score와 static score를 수식으로 표현하면 위와 같습니다. 여기서 S는 유사도를 의미하고 D는 유사도의 차이를 의미합니다. 유사도의 변화율(차이)를 통해 dynamic score를 측정하고 유사도의 절대값(절대적 수치)을 통해 static score를 정의합니다.

VLM을 통한 세분화된 query의 구간을 선정하는 최종 score는 위 dynamic score와 static score를 합한 형태입니다.
Prediction Filtering and Integration
VLM을 통한 m개의 proposals 중 상위 k개를 반환하고 이를 통해 만들 수 있는 조합(combination)은 k^m개 존재합니다. 조합 중에서 가장 점수가 높은 조합을 선택한 후에 LLM prompting을 통해 생성했었던 sub-query간의 관계를 통해 교집합 혹은 합집합을 통해 결정합니다. 수식으로 표현하면 아래와 같습니다.
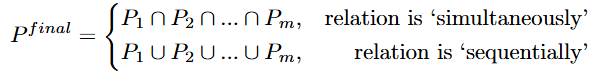
Experiments
저자는 저자가 제안하는 파이프라인의 성능을 보여주기 위해서 Charades-STA데이터셋, ActivityNet Captions 데이터셋에서의 성능을 비교하고, 추가적으로 OOD 상황에서의 성능을 보여줍니다.
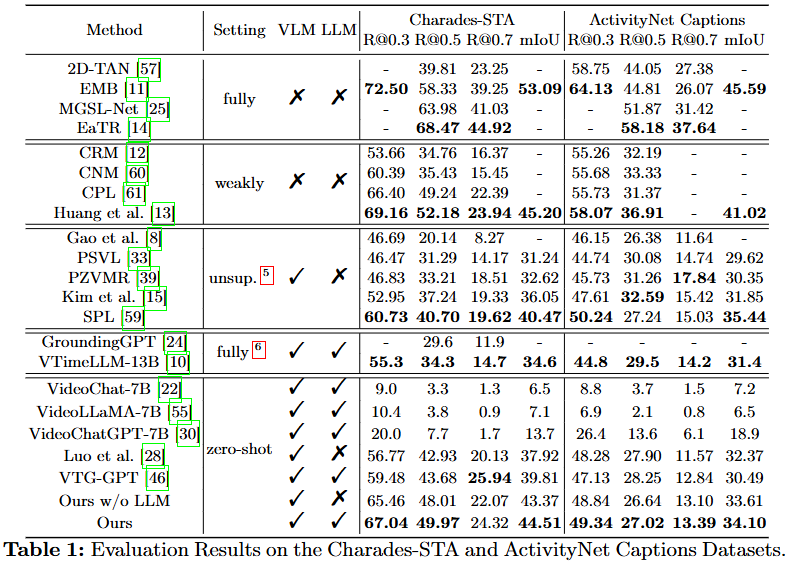
Table 1은 일반적인 Charades-STA 데이터셋과 ActivityNet Captions 데이터셋에서의 성능입니다. 저자가 제안하는 파이프라인은 zero-shot에서 SOTA를 달성했습니다. Fully-supervised 연구의 성능에 비하면 아직 낮은 것은 사실입니다. 하지만 저자가 본 연구를 통해 보여주고 싶은 결과는 아래의 Table 2, 3에 있습니다.
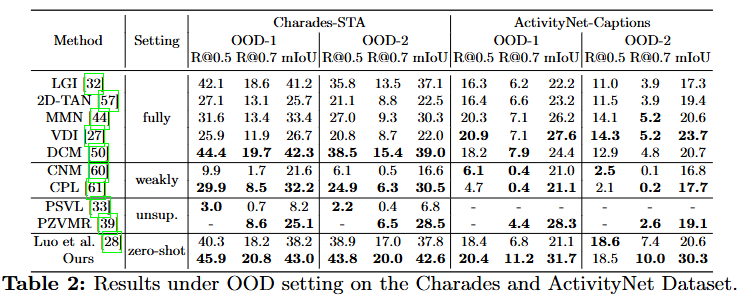
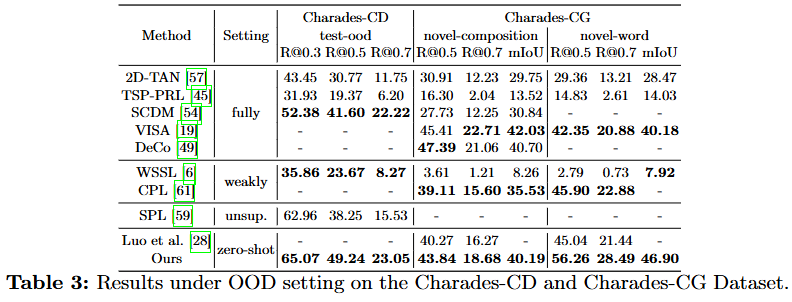
Table 2,3는 각각 -OOD와 -CG 데이터셋으로 -OOD 데이터셋은 원래의 두 데이터셋의 학습 셋과 평가 셋을 재구성한 데이터셋입니다. -CG데이터셋 또한 재조합 및 재구성한 데이터셋입니다. OOD 데이터셋은 기존 데이터셋들의 학습 셋과 평가 셋의 GT분포가 영상의 특정 시점(e.g., 3~5초, 10~15초(설명을 위해 임의로 지정한 구간으로 실제 GT의 구간과는 다름) 사이에 70퍼센트의 GT가 존재)에 치중되어 있는 것을 재구성하여 학습 셋의 GT의 구간과 평가 셋의 GT의 구간이 서로 다른 시간에 존재하도록 하여 모델이 데이터셋의 GT의 구간을 기억하는 것을 방지하고 모델의 일반화 능력을 평가하는 데이터셋입니다. -CG 데이터셋은 compositional generalization의 약자로 모델의 compositional generalization 능력을 평가하기 위해 재구성된 데이터셋입니다. novel-composition과 novel-word 평가셋이 추가되어 novel-composition은 학습셋에서의 단어가 새로운 조합(composition)으로 구성된 query를 평가합니다.
저자가 제안하는 파이프라인 FTVTG(Training-Free Video Temporal Grounding)은 일반적인 데이터셋에서는 fully-supervised 모델들보다 낮은 성능을 보이지만, OOD 및 CG 세팅에서는 오히려 더 좋은 성능을 보이며 기존의 학습을 통해 VTG를 수행하는 모델들보다 일반화 능력이 뛰어남을 보이고 있습니다. 저자는 이와 같은 결과의 이유를 학습을 학습을 하는 것은 데이터셋의 학습 셋에 편향될 수 밖에 없기 때문이라고 설명하고 있습니다. 추가로 데이터셋을 라벨링은 사람이 진행하기 때문에 annotator에 따라서도 편향될 가능성이 있고 특히나 VTG와 같은 fine-grained level에서 grounding을 수행해야하는 task는 이러한 편향이 더 크게 나타날 수 있음을 지적하고 있습니다.
실생활에 적용하기 위해서는 모델의 일반화 능력이 필수적임을 강조하며 저자는 학습을 통해 일반적인 데이터셋에서의 성능을 올리기에만 치중하는 것은 오히려 실생활에 적용하는 것에서 멀어지는 방향일수도 있음을 시사하며 저자가 제안하는 파이프라인의 효율성을 강조하고 있습니다.
Ablation Study

ablation study에서 저자는 사용한 LLM과 VLM에 따른 성능의 변화에도 주목하고 있습니다. 저자는 BLIP-2와 GPT-4 Turbo를 사용할 때에 성능이 제일 좋았다는 것을 설명하고 있고, LLM의 성능보다는 VLM의 성능이 크게 영향을 미치고 있다는 것을 확인할 수 있습니다. InterVideo와 ViCLIP은 사전학습 단계에서 video를 활용했고, CLIP와 BLIP-2는 Image를 활용했습니다. video를 사용한 VLM보다 image를 사용한 BLIP-2의 성능이 더 높은 것이 개인적으로 좀 신기했는데 저자는 이를 BLIP-2가 dynamic transition에 대한 이해가 더 좋았기 때문이라고 설명하고 있습니다. 이해가 더 좋은 이유로 저자는 현존하는 대규모 사전학습을 위한 데이터셋의 규모가 video-language보다 image-language 가 더 크기 때문이라고 설명하고 있는데, 데이터의 규모는 곧 일반화 성능에 직결되는 중요한 요소로 BLIP-2의 사전학습에 사용된 데이터의 양이 아래의 video로 사전학습한 데이터의 양보다 많기 때문에 더 다양한 상황에 대응할 수 있어 위와 같은 결과가 나왔다고 설명하고 있습니다.
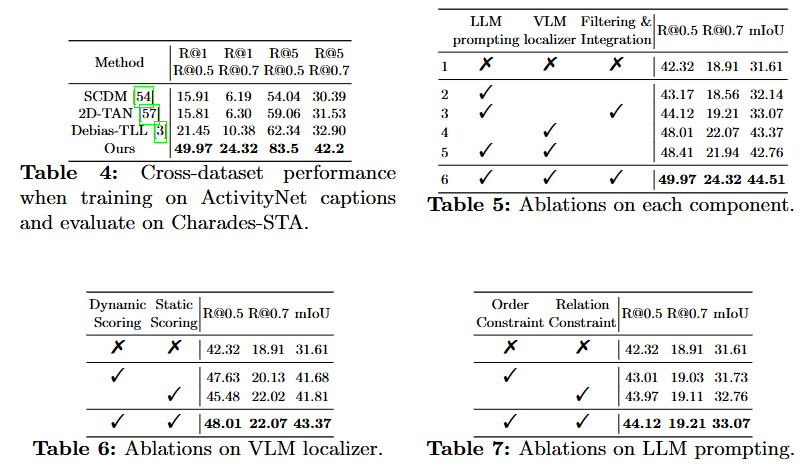
위의 ablation study는 모델의 순서래도 Cross-Dataset(서로다른 데이터셋에서 평가했을 때)에서의 성능, 모델의 각 구성요소에 따른 ablation그리고 VLM, LLM prompting에서의 ablation study입니다. Cross-Dataset의 경우 기존 연구의 성능 하락폭이 굉장히 큰 것을 보이며 저자가 학습하는 것이 일반화 능력을 잃어버린다는 것에 대한 근거로 보여주고 있습니다. Table 5, 6, 7은 저자가 제안하는 파이프라인에서 각 구성요소가 없을 때의 성능 비교로 VLM Localizer의 유무에 따른 성능차이가 제일 큰데, 저자가 제안하는 dynamic, static에 따른 서로다른 score 계산법이 중요하다는 것이 눈여겨 볼만한 것 같습니다.
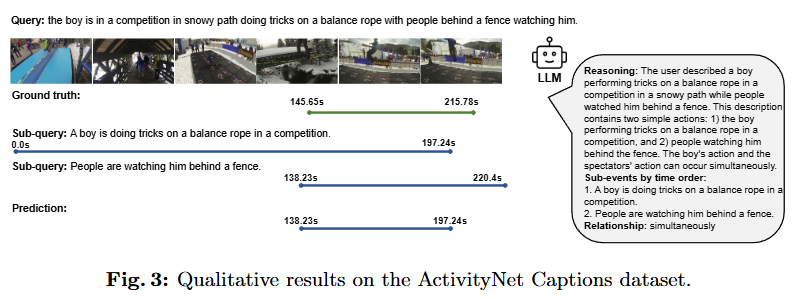
마지막으로 ActivityNet Captions 데이터셋에서의 정성적인 결과와 함께 리뷰를 마치도록 하겠습니다. 위 정성적 결과는 sub-query의 예측과 LLM prompting을 통해 정의한 sub-query들의 관계를 통해 최종 예측을 생성하는 예시로 저자가 제안하는 LLM prompting의 정교함을 보여주고 있습니다.
모델을 설계하는 과정에서 학습을 하지 않는다는 전혀 고려하지 않았는데 저자는 오히려 학습을 하는 것이 데이터셋에 편향되기에 일반화 능력을 해칠 수 있다는 관점을 제안하며 논문을 작성했습니다. 방법론 자체도 굉장히 심플한데 문제를 잘 정의하고 이에 따른 해결책을 창의적?으로 잘 제안한 논문인 것 같습니다. 현재 상황에서 기존 연구들이 간과하고 있던 문제를 잘 지적한 것 같습니다. 처음에 훑어볼 때는 학습도 안하고 이런 논문이 어떻게 우수학회에 게재된 건가 싶었는데 꼼꼼히 읽어볼 수록 잘 설계되고 잘 작성된 논문이라는 생각이 듭니다. 문제 정의와 문제에 대한 해결책을 설득력 있게 제안하는 것이 중요하다는 것을 다시 한번 깨닫게 되는 것 같습니다.
감사합니다.
안녕하세요 박성준 연구원님. 좋은 리뷰 감사합니다.
제가 해당 연구에 대해 지식이 적어 질문이 부족한 점 미리 죄송합니다 ㅎㅎ
해당 논문에서 dynamic영역과 static 영역을 구분하여 감지하는 방법을 제안한 것 같습니다. 한데, 실험된 데이터셋인 activitynet, charades-sta은 짧은 action을 포함하는 데이터셋으로 알고있습니다. 이러한 경우 장면에 전환이 발생하는 frame은 대부분 dynamic 영역에 속해 overfitting이 발생할 우려가 있지 않나 궁금합니다. dynamic 영역과 같은 모호한 영역을 명시적으로 평가 등에 배제하여 (논문에서 말하는 static 타입의 프레임에서의) grounding의 성능을 개선한 부수적 효과도 있지 않을까 한데, 혹시 해당 관점이 틀린 관점인지 궁금합니다.
안녕하세요 황유진 연구원님 좋은 댓글 감사합니다.
저자가 말하는 dynamic 장면이라는 것은 중의적인 의미로 유사도가 변화하는 부분, 장면에 동적인 행동이 존재하는 부분을 말하게됩니다. 이렇게 중의적으로 표현할 수 있는 이유는 주어진 쿼리와 영상 내 장면의 유사도를 계산하게 되면 장면이 시작하는 지점은 유사도가 낮다가 높아지게 되는데 이를 평균내게 된다면 시작점의 유사도가 낮아 정확한 예측이 어려워지기 때문입니다. 즉, 유사도가 dynamic하게 변화하는 구간이라고 생각하시면 될 것 같습니다. 특정 데이터셋에 학습하는 방법론이 아니라서 overfitting의 위험은 낮을 것으로 예상되는데(실제 저자의 contribution이 일반화 능력이기도합니다) 찾으려고하는 특정 구간이 어떤 구간이냐에 따라 성능의 차이가 있긴 할 것 같습니다.
감사합니다.