안녕하세요, 54번째 x-review 입니다. 이번 논문은 CVPR 2024년도에 oral paper로 게재된 diffusion 모델을 사용한 monocular depth estimation 논문 입니다. 요즘 3D 논문에서도 FM을 사용해서 depth map을 얻어 그대로 사용하곤 하는데, 이렇게 3D나 6D에 사용하는 depth map의 퀄리티를 높이기 위한 방식으로 활용할 수 있을 것 같아 리뷰하게 되었습니다.
그럼 바로 리뷰 시작하겠습니다 !

1. Introduction
monoular depth estimation은 하나의 이미지를 가지고 depth map을 추정하는데, 단안 이미지만으로 3차원의 depth를 이미지에서 얻는다는 것은 어려운 task로 여겨지고 있습니다. depth estimation은 이미지 간의 translation으로 이루어지며, pair한 RGB-Depth map을 가지고 supervised 혹은 semi-supervised 방식으로 학습합니다. 이러한 초기 방법론들은 주로 indoor나 자율 주행 scene과 같이 학습된 데이터에 의해서 한정된 시나리오 안에서 동작할 수 있습니다. 최근에는 좀 더 광범위한 시나리오에서 사용할 수 있거나 작은 스케일의 데이터로 특정 시나리오에 맞게 fine-tuning하는 일반화된 depth estimator을 학습하기 위한 연구가 진행되고 있다고 합니다. 이러한 방향의 연구는 MiDAS라는 다양한 RGB-D 데이터셋에서 샘플린된 데이터로 학습하는 방식을 기저로 따른다고 합니다.
그런데 여기서 중요한 점은 depth라는건 이미지 안의 visual적인 요소도 중요하지만 카메라 intrisic도 영향을 미치는데, 일반적으로 depth estimation은 절대적인 depth 값이 아니라 이미지 안에서의 relative depth를 구한다는 뜻이죠. relative depth는 downstrem task에 사용하기에 제한이 생기기 때문에 여러 연구에서 “affine-invariant depth”를 고려하게 됩니다. affine-invariant depth는 depth 값 자체는 변하지만 scale과 offset 변환이 가능해지면서 depth의 순서만 고려하던 relative depth에 비해 depth 사이의 차이 비율을 유지할 수 있다는 장점이 있습니다.
본 논문에서는 affine-invariant depth를 추정하는 것을 목표로, 최근 diffuson 모델에서 large scale의 이미지를 가지고 학습되어온 부분에 주목하였다고 합니다. monocular depth estimation도 결국에는 real world에 대한 표현력을 가지고 있어야 하는 것이기 때문에 사전학습된 diffusion 모델이 depth estimator로도 동작할 수 있어야 한다고 가정한 것 입니다. 이러한 가정을 가지고 저자는 Stable Diffusion 기반의 Latent Diffusion Model(LDM)을 depth estimation을 위해 fine-tuning하는 프로토콜인 Marigold를 제안합니다.
(LDM은 일반적인 Diffusion Model의 역할을 latent space 안에서 수행함으로써 메모리 효율적으로 동작할 수 있는 Diffusion model을 의미합니다.)
사전학습된 diffusion 모델을 최대한 활용하기 위한 핵심은 latent space를 그대로 유지할 수 있어야 하는데요, 이를 위해 denoising U-Net만을 수정하고 fine-tuning하여 효율적으로 수행할 수 있도록 설계하였다고 합니다. 자세한 방식에 대해서는 Method에서 알아보도록 하고, 결국 Marigold는 학습에서 합성 RGB-D 데이터만을 사용하여 inference 때 depth map이 주어지지 않아도 real 데이터셋에서 SOTA를 달성할 수 있었다고 합니다.
이러한 본 논문의 main contribution을 정리하면 다음과 같습니다.
- 사전학습 LDM을 fine-tunig 할 수 있는 간단하고 resource적으로 효율적인 프로토콜인 marigold 제안
- real-world 데이터셋에서 monocular depth estimation task에 대한 SOTA 달성
2. Method
2.1. Generative Formulation
본 논문에서는 diffusion model 중에서도 conditional denoising diffusion으로 monocular depth estimation을 수행합니다. conditional denoising diffusion은 diffusion model을 특정 조건에 따라 조절하여 원하는 데이터를 생성하는 방식으로, 단순히 무작위의 이미지를 생성하는 것이 아니라 유저가 원하는 특정 결과를 만들 수 있도록 조건을 부여할 수 있습니다.
우선 RGB 이미지 x \in \mathbb{R}^{W \times H \times 3}을 입력으로 받아, depth d \in \mathbb{R}^{W \times H}의 조건부 확률 분포 D(d|x)[latex]를 모델링하는 것을 목표로 합니다. 이를 위해 forward 과정에서는 초기 depth map [latex]d_0에서 가우시안 노이즈를 반복적으로 추가해서 식(1)과 같이 t 레벨에서의 노이즈 샘플 d_t를 생성합니다.
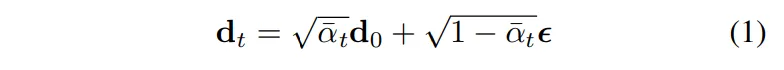
- \epsilon ~ N(0,I) : 가우시안 노이즈
- \bar{\alpha}_t : 특정 vairance schedule에 따른 가중치로, 단계적으로 원본 depth 정보를 지워냅니다.
reverse 과정은 노이즈를 제거하는 과정으로, 학습된 파라미터 \theta로 파라미터화된 조건부 denoising 모델 \epsilon(\dot)을 사용해서 단계적으로 노이즈를 제거하여 그 전 레벨의 depth map을 구하면서 최종적으로 깨끗한 depth map d_0을 복원합니다.
학습할 때는 RGB-Depth pair 데이터 (x,d)에서 랜덤한 타임스텝 t에서 depth map d에 노이즈 \epsilon을 추가합니다. 그럼 모델 \epsilon_{\theta}가 노이즈가 추가된 d_t와 원본 이미지 x를 입력으로 받아서 추가된 노이즈를 \epsilon을 예측하는 것이죠. 모델이 예측한 노이즈 \hat{\epsilon}과 실제 추가된 노이즈 t의 차이를 줄일 수 있도록 식(2)와 같이 모델을 학습합니다.
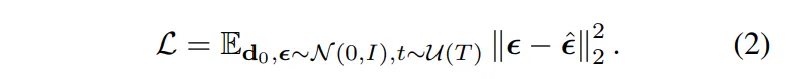
- \epsilon ~ N(0,I) : 랜덤한 가우시안 노이즈 \epsilon 생성
- t ~ U(T) : 랜덤한 타임 스텝 t
- \hat{\epsilon}=\epsilon_{\theta}(d_t,x,t) : 모델이 예측한 노이즈
여기서 marigold는 latent diffusion을 활용해서 원본 depth map에서 직접 연산하는게 아니라 latent space에서 동작함으로써 효율적인 계산을 수행할 수 있습니다. latent space는 VAE를 사용해서 만드는데요, 원본 데이터를 저차원으로 압축하는 역할을 하며 diffusion 모델과는 독립적으로 사전학습됩니다. 즉 VAE를 사용해서 저차원 공간으로 변환한 후에 그 공간 안에서 diffusion을 수행하는 것이죠.
원본 depth map d가 주어지면, VAD의 인코더 E를 사용해서 latent code z(d)로 변환합니다. 이 과정이 depth map을 압축된 표현으로 변환하는 과정을 의미합니다. latent space에서 표현된 z(d)를 다시 원래 depth map으로 복원할 때는 VAE의 디코더 D를 사용해서 \hat{d} = D(z(d))의 과정을 거쳐 원본 depth map으로 복원할 수 있습니다. 여기서 조건으로 주어지는 RGB 이미지 x도 동일한 방식으로 VAE 인코더를 통해 latent space로 변환되어 depth map 뿐만 아니라 RGB 이미지도 z(x) 같이 압축된 형태로 변환하여 사용하게 됩니다. 결국 학습은 \epsilon_{theta}(z(d)_t, z(x), t)로 정의할 수 있는데요, 원본 데이터가 아니라 압축된 latne space의 데이터로 노이즈를 예측할 수 있습니다.
inference 때는 단계 하나가 더 추가되어 diffusion 모델 \epsilon_{theta}가 깨끗한 depth latent code z(d)_0을 생성하고, VAE의 디코더 D를 사용해서 원래의 depth map 이미지 \hat{d}로 복원합니다.
2.2. Network Architecture
이제 Marigold의 구조에 대해서 살펴보도록 하겠습니다.
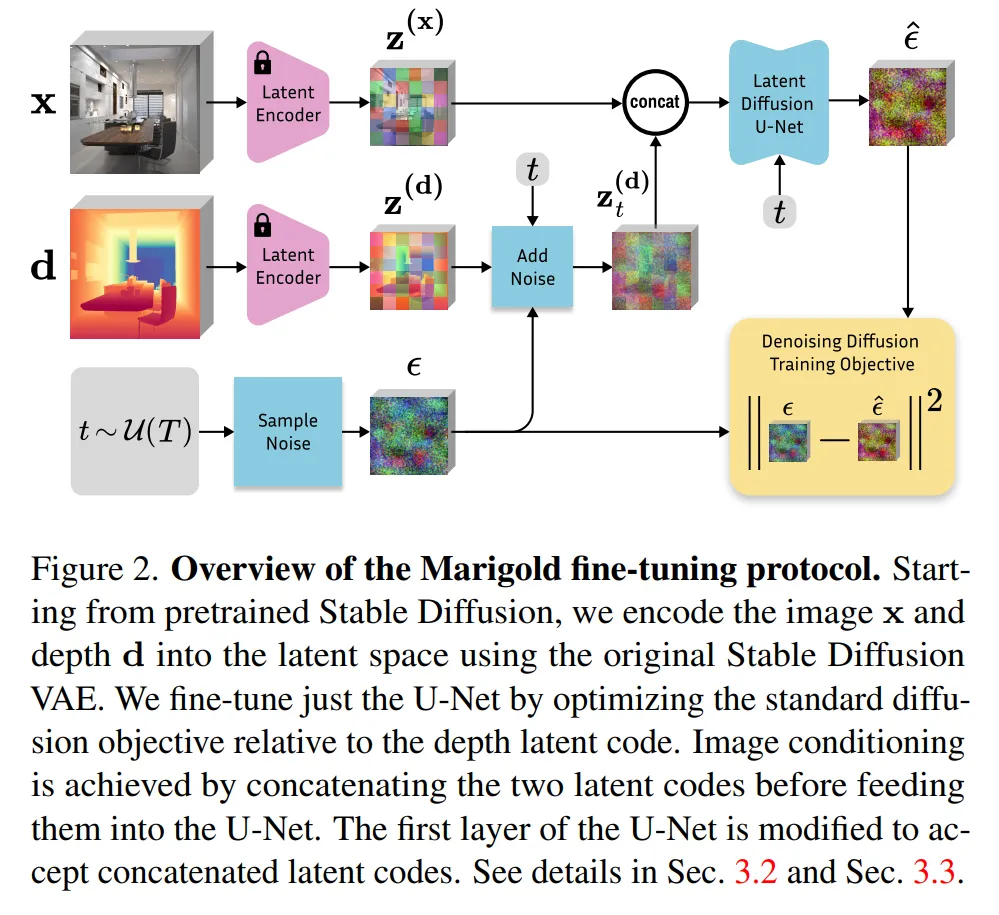
Depth encoder and decoder
Marigold는 VAE를 사용해서 RGB 이미지와 depth map을 latent space로 변환하는데, 여기서 인코더가 원래는 RGB 3채널 이미지만 받도록 설계되었기 때문에 1채널의 depth map을 바로 사용할 수 없어서 3채널로 복제하여 마치 RGB인 것처럼 VAE에 입력으로 넣습니다. 그 다음에 VAE를 수정하지 않고 depth map을 거의 원본 그대로 복원할 수 있는데, 결국 depth map의 정보를 잘 보존하여 압축함으로써 메모리는 아끼고 depth map은 원본과 같이 복원할 수 있다는 이야기를 하고 있습니다.
inference 때는 section 2.1.에서 말한 것과 같이, latent space에서 깨끗한 depth latent code를 얻고 다시 depth map으로 변환하면 됩니다. 단, 여기서 depth map을 인코더에 넣을 때 3채널로 변환했기 때문에 디코더 출력도 3채널로 나와서 최종적으로 3채널 출력을 평균하여 1채널의 depth map을 얻을 수 있습니다.
Adapted denoising U-Net
latent space에서 노이즈를 제거하는 denoiser \epsilon_{theta}를 학습하는데, 여기서 depth 정보만 아니라 RGB 이미지 정보도 같이 받아야 더 정확한 depth estimation을 할 수가 있습니다. 그래서 depth map의 latent code z(d)_t와 RGB 이미지의 latent code z(x)를 합친 새로운 하나의 입력 z_t를 만듭니다. 근데 이제 원래 denoiser는 z(d)_t 하나만 입력으로 받았기 때문에 두 데이터를 합치면 입력 차원이 2배로 증가하기 때문에 denoiser의 입력 레이어를 변경하고 가중치도 2배로 늘려야 합니다. 단, 가중치를 그냥 늘려버리면 모델이 불안정해질 수 있기 때문에, 입력 채널이 늘어난 만큼 가중치를 복사하되 값의 크기를 절반으로 줄여서 네트워크가 기존과 동일한 출력을 유지할 수 있도록 하였습니다.
2.3. Fine-Tunin Protocol
Affine-invariant depth normalization
Marigold는 VAE를 사용하여 laent space에서 연산을 수행하는데, VAE의 입력값 범위가 주로 [-1, 1]로 설계되어 있기 때문에 GT depth map도 동일한 범위로 변환하기 위해 linear normalization을 사용하였다고 합니다. 즉, depth 값이 원래는 [min depth, max depth] 였다면, 이를 [-1, 1] 범위에서 선형적으로 변환한 것 입니다.
이렇게 정규화를 한 또 다른 이유는 affine-invariante dpeth를 학습할 것이기 때문에 depth map이 특정 범위 안에서 일관되게 유지되어야 하기 때문입니다. 일반적으로 원본 depth map은 사용하는 카메라나 데이터셋마다 depth 값의 범위가 다를 수 있어서 이런 차이를 없애기 위해 모든 depth map을 동일한 범위로 변환하여 서로 다른 데이터셋에서도 일관된 방식으로 학습할 수 있도록 하였습니다.
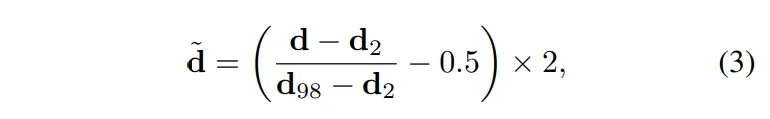
- d_2 : 각 depth map의 가장 작은 2%의 depth 값
- d_{98} : 각 depth map의 가장 큰 2%의 depth 값
식(3)이 affine-transformation 수식으로 전체 depth 값 중에서 너무 작거나 큰 값을 제외하고 나머지 값들을 [-1, 1]로 정규화하게 됩니다. 결국 정규화를 하는 목적은 논문에서 하고자 하는 affine-invariant depth를 더 잘 학습하기 위함이라고 정리할 수 있습니다.
Training on synthetic data
기존 연구들과 달리 Marigold는 합성 depth 데이터만을 사용하여 학습하는데 그 이유에 대해서 2가지로 나누어 설명하고 있습니다.
먼저 합성 데이터는 모든 픽셀에 대한 depth 값을 제공받을 수 있기 때문인데, VAE가 안정적으로 학습할 수 있습니다. 두번째는 합성 데이터가 렌더링 과정으로 생성되기 때문에 노이즈가 없는 깨끗한 depth map을 얻을 수 있다는 것 입니다. 실제 depth 데이터에서 깨끗하게 완전한 depth 값이 포함된 dpeth map을 얻기가 어렵기 때문에 이렇게 합성 데이터를 사용한 것 같네요. 만약에 논문의 사전학습된 모델을 짧은 시간동안 fine-tuning 했을 때 일반화된 depth estimation이 가능하다는 가정이 맞다면, 합성 데이터가 깨끗할수록 모델이 노이즈 없이 학습되어 gradient를 업데이트하는 과정에서 불필요한 노이즈가 줄어들 수 있습니다. 다만 합성 데이터만 사용하기 때문에 실제 데이터와의 갭이 생겨 일반화 성능이 떨어질 수 있는데요, 이는 실험적으로 real 데이터에서도 zero-shot 성능이 뛰어남을 검증하였다고 합니다.
2.4. Inference
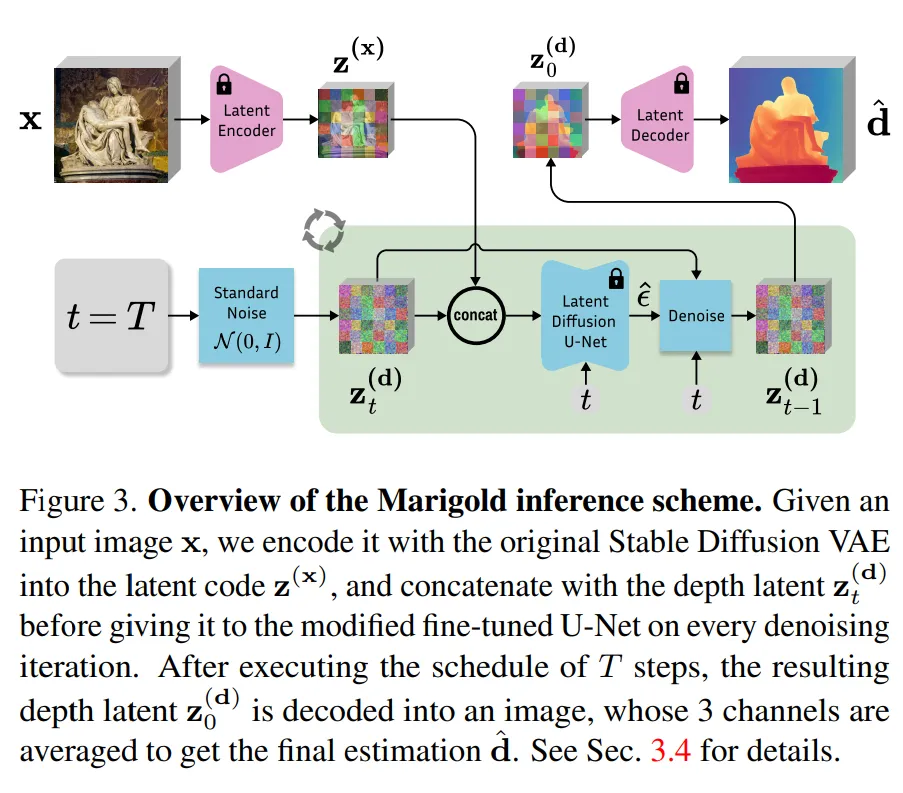
Latent diffusion denoising
Fig.3에서와 같이, inference 때는 입력 이미지만을 받아서 최종 depth map을 생성하게 됩니다. 입력 RGB 이미지를 VAE 인코더를 사용하여 Latent space로 변환하고, 가우시안 노이즈에서 단계적으로 노이즈를 제거하는 방식으로 depth map을 생성합니다. 이 때, fine-tuning 때 사용했던 variant schedule을 동일하게 사용하여 노이즈를 제거함으로써 일관된 방식을 유지하였다고 합니다.
여기서 이전 연구인 DDIM 방식을 사용하여 샘플링을 수행하였는데, DDIM은 비마르코프 샘플링 방식을 사용하여 기존의 마르코프 체인 방식보다 더 적은 스텝으로도 depth map을 복원할 수 있도록 최적화된 샘플링 방식이기 때문에 이를 그대로 적용하여 inference 속도를 높이고자 하였습니다.
Denoising이 끝나면 최종적으로 latent code를 얻을 수 있고, 이를 VAE 디코더를 사용해서 다시 원본 depth map으로 복원하며 3채널에서 1채널로 변환하는 과정까지 끝내면 최종 출력인 이미지 형태의 depth map을 얻을 수 있습니다.
Test-time ensembling
특이한 점은 여러 번 추론해서 여러 depth map을 얻고 이를 합쳐서 더 정확한 depth map을 생성하도록 Test-time ensembling(TTE) 방식을 사용하는 것 입니다.
depth map을 생성할 때 초기 depth에서 가우시안 노이즈에서 시작하기 때문에 확률적인 특성을 가지는데요, 같은 입력 이미지에 대해서도 초기 노이즈 값이 다르면 서로 다른 depth map을 생성할 가능성이 있습니다. 이런 확률적인 특성을 사용해서 여러 번 inference 수행한 다음에 그 결과를 합친 TTE 방식을 제안하고 있습니다. 먼저 한 입력 이미지에 대해 N번의 inference를 수행하여 N개의 depth map \{\hat{d}_1, …., \hat{d}_N\}을 생성합니다. 이 때, 각 depth map은 서로 다른 초기 노이즈에서 시작하였기 때문에 스케일과 오프셋이 다를 수 있어서 depth map 마다의 스케일 \hat{s}_i와 오프셋 \hat{t}_i도 함께 추정합니다. 만들어진 depth map들의 alignment를 맞추기 위해 가능한 모든 depth 쌍 \hat{d}_i, \hat{d}_j 사이의 차이를 최소화하는 방식으로 최적화를 수행합니다. 여기서 같이 추정한 스케일과 오프셋을 이용해 depth map을 \hat{d}’ = \hat{d} \times \hat{s} + \hat{t}를 이용해 변환하게 됩니다. 이 과정은 여러 번 inference한 depth map들이 서로 다른 범위를 가질 수 있기 때문에 일관된 범위로 변환하여 비교하기 위함이라고 하네요.
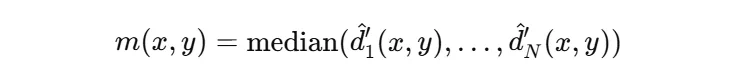
그 다음 위의 수식과 같이, 모든 depth map을 정렬하여 같은 위치 (x,y)에 있는 depth 값들의 중앙값을 계산하여 합쳐진 하나의 depth map m을 생성합니다. 여기서 합칠 때 중앙값을 선택한 이유는 이상치의 영향을 최대한 줄여 안정적인 값을 이용하기 위함이라고 합니다. 추가적으로 R = |min(m)| + |1-max(m)|을 align된 depth map이 비정상적으로 수렴하는 것을 방지하고자 추가하였다고 합니다.
그래서 최종적인 objective function을 정의하면 식(4)와 같습니다.
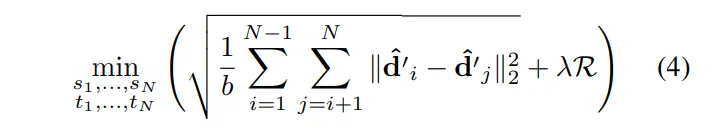
이렇게 최적화가 완료되면, 합쳐진 하나의 depth map m이 최종 예측 출력값으로 나오게 됩니다. TTE 방식을 통해 inference를 여러 번 수행하면 성능이 향상될 순 있지만, 계산 비용이 증가하는 trade-off 관계를 가지게 됩니다. 그래서 유저가 몇 번 반복할 지에 대한 N을 조절함으로써 적정한 수준으로 균형을 맞추어 사용할 수 있습니다.
3. Experiments
3.1. Evaluation
학습 데이터셋으로는 Hypersim, Virtual KITTI라는 합성 데이터셋을 사용하였고,
평가 데이터셋으로는 NYUv2, ScanNet, KITTI, ETH3D, DIODE 이렇게 5개의 real 데이터를 사용하였다고 합니다.
Comparison with other methods
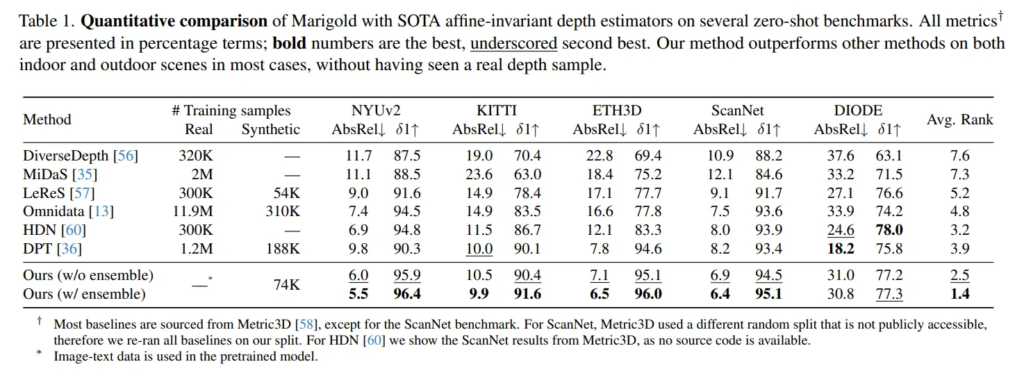
zero shot depth estimation에 있어서 일반화를 어필하는 모델을 비교 모델로 사용하였습니다. Tab.1을 보면 주장한 것과 같이, 대부분의 데이터셋에서 SOTA를 달성한 것을 확인할 수 있습니다. 이러한 결과를 통해, 합성 데이터셋으로만 학습했음에도 불구하고 넓은 범위의 scene을 담은 real 데이터셋에서 잘 동작한다는 것을 검증할 수 있었습니다. diffusion 모델을 depth estimation 모델로 잘 활용함으로써 인트로에서 이야기한 것처럼 depth estimation 역시 real world에 대한 표현력이 기본이 되는 task임을 확인할 수 있습니다.
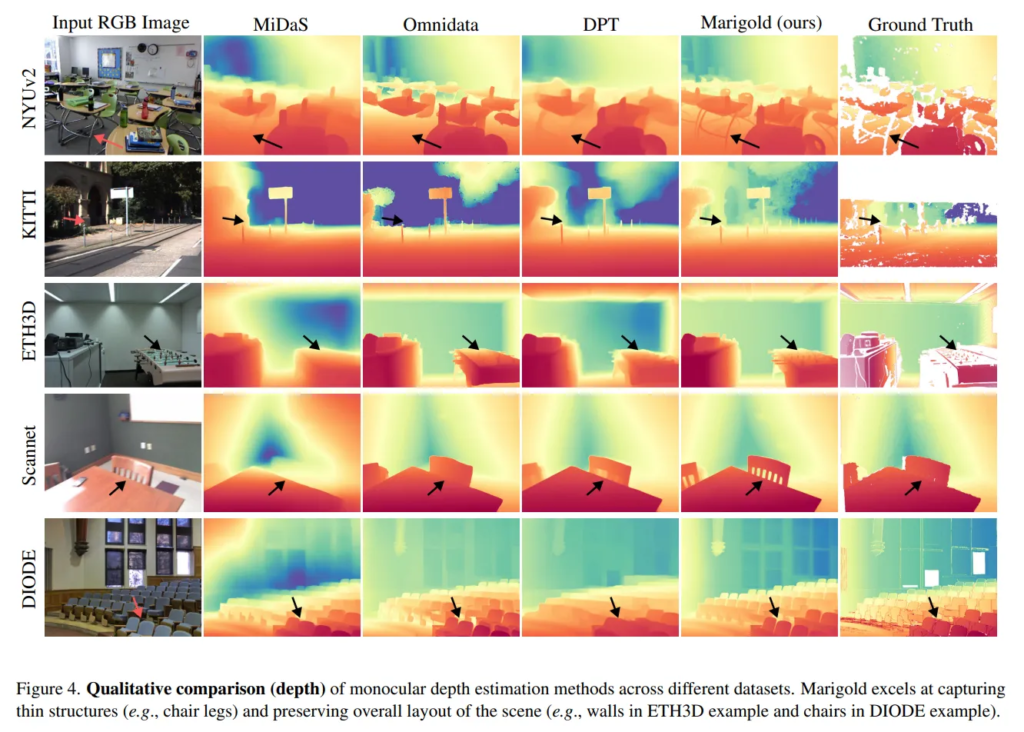
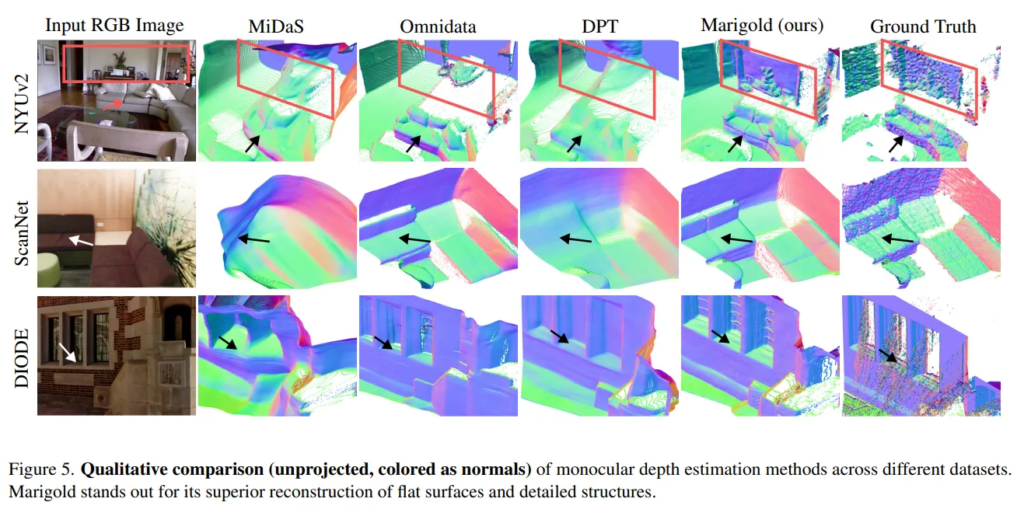
Fig.4는 정성적인 결과를 보여주며, 추가적으로 Fig.5와 같이 surface normal에 대한 정성적 결과를 보여주고 있습니다. Fig.5의 첫번째 행과 같이, 벽과 가구 사이의 공간 관계를 정확하게 파악할 수 있으며 Fig.4에서 화살표로 표시된 부분들을 봤을 때 타 방법론 대비 디테일한 영역에서까지 depth map을 정확하게 표현하는 것을 어필하고 있습니다.
3.3. Ablation Studies
Test-time ensembling
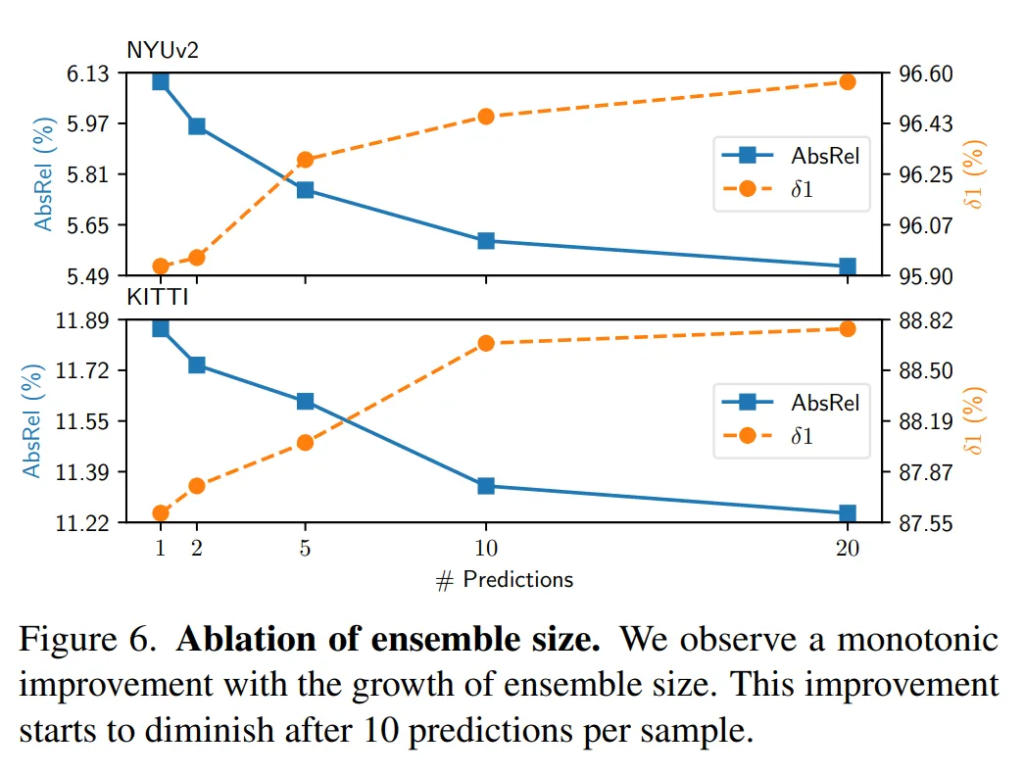
Fig.6은 TTE를 몇 번 수행하는 지에 따른 효과를 확인하는 ablation study 입니다.
우선 단일 예측만으로도 좋은 결과를 얻고 있지만, 10번을 반복하여 합쳤을 때 absolute relative error(AbsRel)은 약 8% 감소하고 20개의 예측을 합치면 약 9.5%의 개선되는 성능을 보입니다. 예측 수가 증가함에 따라 성능이 계속해서 개선되는 경향을 확인했지만, 성능 개선이 되는 margin을 보았을 때 10번의 반복이 가장 효과적이라고 판단하여 기본 세팅은 10번으로 지정하였다고 하네요.
Number of denoising steps

마지막으로 DDIM schedule에 따라 inference에서의 적은 노이즈 step 수를 활용하였는데, 이에 따른 성능 변화를 평가하고 있습니다. 1000개의 DDPM 단계로 학습했지만, inference 시에 많은 단계를 거치면 성능 향상이 이루어지지만, 50개로 단계를 선택하여도 만족스러운 결과를 얻기에 충분하다고 분석하고 있습니다. 이는 더 많은 노이즈 단계를 사용해도 성능이 saturation되는 지점이 데이터셋마다 조금씩 다르지만, 평균적으로 항상 10 단계 미만이라는 것을 확인하였기 때문에, 성능을 유지하면서 효율성을 높이기 위해 노이즈 제거 단계를 10단계 이하로 줄일 수 있음을 의미합니다. 특히 이 10단계라는 노이즈 제거 단계는 일반적인 diffusion 모델에서 사용하는 50단계보다 훨씬 적다는 것을 어필하고 있습니다.
안녕하세요. 건화님 리뷰 감사합니다.
실험 파트에서 DDIM이라는 단어가 자주 등장하는데 간략하게 설명한 것이 마르코프 체인 방식이 아닌 비마르코프 체인 방식을 사용했다는 것인데 마르코프 체인 방식이 어떤 방식일까요?
감사합니다.
안녕하세요, 리뷰 읽어주셔서 감사합니다.
DDPM은 마르코프 체인을 기반으로 한 방식인데요, 이는 각 타임스텝의 상태가 오직 그 직전 상태에만 의존한다는 특징을 갖습니다. 다시 말해, 노이즈를 점점 추가하면서 이미지를 흐리게 만들고, 그 반대 방향으로 노이즈를 제거하면서 이미지를 복원하는 과정 전체가 일련의 마르코프 과정으로 구성돼 있다고 보시면 됩니다.
하지만 이런 방식은 샘플링 속도가 느리고, 타임스텝마다 복잡한 계산이 필요해서 시간이 오래 걸리게 됩니다. DDIM은 이런 문제를 개선하기 위해 등장한 방식으로, 마르코프 체인을 따르지 않는 비마르코프(non-Markovian) 방식을 제안합니다.
중간 타임 스텝에서 꼭 이전 상태에만 의존하지 않아도 되도록 설계하여서 적은 타임 스텝으로도 높은 퀄리티의 샘플을 생성할 수 있습니다.
감사합니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
diffusion 모델에서 노이즈를 랜덤한 가우시안 노이즈를 주었다고 적혀있는데, 학습과 추론에서 모두 단순 랜덤 가우시안 노이즈로 초기화하게 되나요 ? 그렇다면 혹시 다른 방식의 노이즈로 초기 노이즈를 설정해줬을 때의 성능 변화에 대한 ablation study는 없는 것인지 궁금합니다 !!
감사합니다.
안녕하세요, 리뷰 읽어주셔서 감사합니다.
diffusion 모델에서는 학습과 추론 모두 일반적으로 표준 정규분포에서 샘플링한 랜덤 가우시안 노이즈를 초기화에 사용합니다. 이 논문에서도 마찬가지로 초기 노이즈는 랜덤한 가우시안으로 설정되어 있습니다. 다만, 말씀하신 다른 방식의 노이즈를 사용했을 때의 성능 변화를 다룬 별도의 ablation study는 리포팅 되어 있지 않습니다.
감사합니다.
안녕하세요 좋은 리뷰 감사합니다.
보고 궁금한점이 생겨서 질문을 드려봅니다
1. 인간의 눈은 affine invarient 한 것과 affine invarient 하지 않은 것을 구별할 수 있는지? 궁금합니다.
2. TTE 방식말고 가우시안 블러를 여러번 만든 후 평균내서 하나의 depth map 을 바로 추론하게되면 어떠한 장단점이 있을지 궁금합니다.
아직 잘 모르는 VAE 나 diffusion model 을 간접적으로 찾아보게 되어서 흥미로웠습니다.
감사합니다!
안녕하세요, 리뷰 읽어주셔서 감사합니다.
1. 인간의 눈은 affine-invariant한 depth와 그렇지 않은 depth를 직관적으로 완전히 구별하기는 어려울거라고 생각합니다. 왜냐하면 affine-invariant depth는 상대적인 거리 구조는 유지되지만 절대적인 거리나 정확한 스케일은 손실된 상태이고, 인간의 시야는 양안을 통해 여러 정보를 종합적으로 활용하기 때문에 단일한 depth map의 차이를 판별하기는 쉽지 않습니다. 특히 화면에 출력된 이미지나 영상처럼 제한된 평면 정보만 있을 때는 두 결과가 다르게 느껴지지 않을 수도 있겠죠 ??
2. 우선 장점으로는 예측 결과를 어느 정도 안정적으로 만들 수 있을 거라고 생각이 듭니다. 단점은 가장 크게는 모델의 확률적인 특성을 제대로 활용하지 못할지 않을까 싶은데요, TTE가 샘플마다 예측 분포를 보정하면서 일관된 결과를 만들고자 하는 것인데 단순 가우시안 블러로 평균을 내면 구조적으로 일관된 depth를 만들 수 있을까 의문이 들긴 합니다.
감사합니다.
안녕하세요 좋은 리뷰감사합니다!
depth를 생성형으로 한다는 점이 흥미로웠습니다.
읽고궁금한점이 생겨 질문드립니다
Marigold에서는 depth latent code와 RGB latent code를 결합해 denoising U-Net에 입력된다고 말씀하셨는데 이때 두 modality의 latent를 단순한 채널 concat 방식으로 통합하는지 궁금합니다.
단순 concat만 했다면 만약 그렇다면, 처음에는 구조적 정보가 없는 Gaussian noise에서 시작해서 어떻게 의미 있는 depth 구조를 복원해낼 수 있는지 궁금합니다. 생성형에 대해 잘 몰라서 드리는 질문일수도 있겠네요..ㅎ
감사합니다
안녕하세요, 리뷰 읽어주셔서 감사합니다.
넵 이 논문에서는 modality latent를 concat하는 방식으로 통합합니다.
어떻게 gaussian noise에서 시작해서 depth 구조를 복원하는지에 대해서는, 처음에 RGB와 Depth 이미지를 입력으로 하여 점차적으로 가우시안 노이즈를 추가하게 됩니다. 그 이후에 denoising 과정에서 역으로 가우시안 노이즈에서 원래의 Depth 이미지를 복원할 수 있도록 하는 것이 diffusion 자체의 목적이라고 할 수 있습니다. diffusion 수식이나 학습 방식에 대해서는 제 해당 논문 뿐만 아니라 다른 diffusion 기반 depth 논문 리뷰에도 여러번 올려놓았으니 참고해주시면 감사하겠습니다.