1. Introduction
free-form 형식의 human instruction과 human-robot dialogue를 로봇이 실행 가능한 plan으로 해석하는 것은 language의 다양성과 복잡성 때문에 어렵습니다. 또한 human language는 long-term reference와 질문, 에러, 생략, 또는 사용자에 특화된 루틴 등을 포함하기 때문에 더더욱 이해하기 어렵습니다. 로봇은 이러한 사람의 언어를 해석하는 것 뿐만 아니라, 환경적 context에서 instruction을 해석해야 하고, plan 실패에 대응하기 위해 closed-loop로 설계될 필요가 있습니다.
위의 작업을 수행하기 위해서는 예전에는 다양한 방법들을 사용했었지만, 최근에는 이를 해결할 수 있는 방법으로 LLM이 사용되고 있습니다. LLM의 prompt를 task를 수행하도록 설계하여 수행하는 것이죠.
본 논문의 저자들은 여기서 한가지 의문점을 표합니다. 어떻게 LLM 프로픔트를 확장할 수 있을까? open-domain, free-form instruction, correction, human-robot idialogue를 포함하면서도. 심지어 prompt engineering 시점에서는 알 수 없는, 즉, LLM의 prompt를 설계할 때는 알지 못하는 사용자의 특정 루틴에 대해서도 포함하면서 확장할 수 없을까?를 질문합니다. 단순히 context window의 크기를 늘리는 것은 어떨까요? 물론 이 방법이 해결책이 될 수 있지만, 논문의 저자에 따르면, tabetop rearragement와 같은 특정 task의 prompt의 경우 이미 LLM의 최대치의 context window를 가진다고 합니다. 또한 context window의 크기가 커질수록 더 많은 연산을 수행해 추론 시간과 자원 사용량을 증가시키는 문제를 가지죠. 즉, 단순히 context window의 크기를 늘리는 것은 해결책이 될 수 없습니다.
본 논문에서는 이를 위해서 HELPER (Human-instructable Embodied Language Parsing via Evolving Routines)를 제안하였습니다. HELPER는 외부의 memory를 사용하여 language-program pair를 기억하고, 이를 기반으로 prompt를 동적으로 생성합니다. 또한, HELPER를 사용하면서 사용자의 지시를 성공적으로 수행하는 경우 이를 memory에 넣어 확장합니다. 이를 통해 사용자가 일반적인지 않은 특정한 지시를 내려도 바로 반응할 수 있는 것이죠. 여기에 추가로, VLM(Vision-Language Model)을 사용하여서 language format으로 plan 실패를 파악하고, 이를 기반으로 비슷한 실패 사례와 그 해결책을 memory에서 검색하여 prompt에 반영합니다. 최종적으로, LLM이 생성한 프로그램을 실행하기 위해서 semantic 및 occupany map 구축, LLM의 상식을 이용한 object detection 등을 결합하여 로봇이 작업을 성공적으로 수행할 수 있도록 합니다.
본 논문의 contribution을 정리하면 다음과 같습니다.
- HELPER라는 새로운 agent 제안
- TEACh 벤치마크에서 SOTA 달성
2. Method
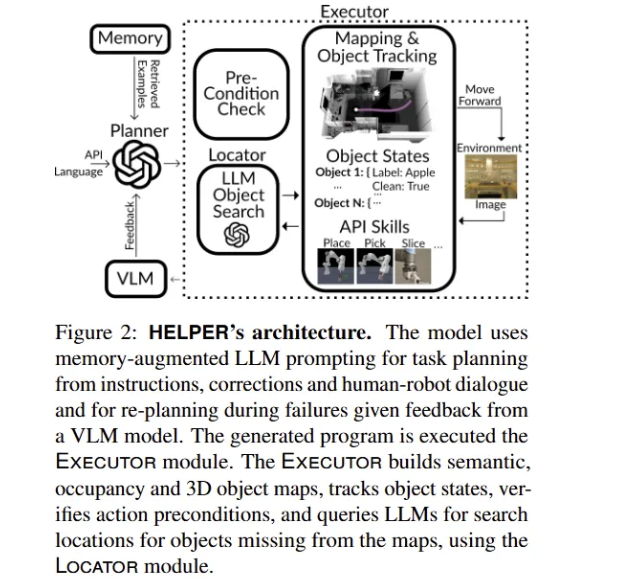
HELPER는 human-robot dialogue, correction, VLM description을 활용하여 로봇의 내비게이션 및 조작 프로그램을 생성하는 시스템(agent)를 의미합니다. 제안된 HELPER의 전체적인 구조는 Figure 2를 통해서 확인할 수 있습니다. 간략하게 해당 구조를 설명하면, plan 및 plan 조정을 위해서 LLM을 사용하는데, 이 과정에서 구축해둔 language-program pair를 검색한 것을 기반으로 plan을 수행합니다. 생성된 프로그램은 이후 Executor로 넘어가 각 프로그램 단계를 구체적인 내비게이션 및 manipulation action으로 변환합니다. 이때, 프로그램의 각 단계를 실행하기 전에 Executor는 action을 수행하는데 필요한 전제 조건(예를 들어서 로봇이 이미 object를 들고 있는지)이 충족되었는지 확인합니다. 만약에 조건이 충족되지 않으면 현재 환경 및 agent 상태에 따라 plan을 조정합니다. 만약 프로그램의 어떤 단계에서 탐지하지 못한 object를 포함하면, Executor는 Locator 모듈을 호출하여 이전 사용자가 지시했던 것, LLM의 일반 상식을 활용해 필요한 object를 찾아냅니다. action을 실행 중에 실패하였다면, VLM이 pixel input에서 이러한 실패의 이유를 예측하여 이를 Planner에 feedback하여 plan을 조정합니다.
이렇게 전체적인 흐름을 설명드렸는데, 해당 방법론의 구체적인 요소를 설명드리고자 합니다.
2.1 Planner: Retrieval-Augmented LLM Planning
Planner는 dialogue segment, instruction, correction로 구성된 input $I$를 실행 가능한 Python 프로그램으로 변환하는 역할을 수행합니다. Planner가 변환한 프로그램은 goto(X), pickup(X), slice(X) 등과 같이 Executor가 수행할 수 있는 매개변수화된 manipulation, navigation primitives $G \in \{G_{manipulation} \cup G_{navigation} \}$에 따라 설정됩니다.
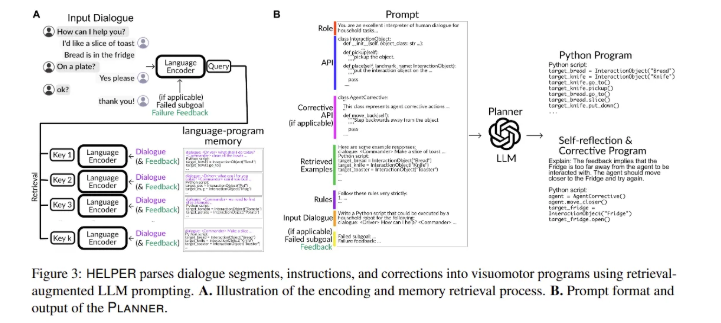
HELPER는 language-program pair에 대해서 key-value memory를 Figure 3A와 같이 가집니다. 각 langugae key는 LLM의 frozen한 language encoder를 사용하여 1D vector로 맵핑합니다. 현재의 context $I$를 고려하여서, 모델은 input context $I$의 embedding과 $L_2$ distance를 비교하였을 때 가장 작은 값을 가진 top-$k$를 검색하고, 해당 language-program pair를 LLM prompt에 추가하여 현재 input $I$를 해석합니다.
Figure 3B는 Planner의 prompt format을 보여줍니다. 해당 prompt는 Python function으로 매개변수화된 primitives $G$를 지정하는 API, 검색된 example 그리고 langugae input $I$로 구성되어 있습니다. 이렇게 구성된 prompt를 통해 LLM은 $G$를 기반으로 Python 프로그램을 생성합니다.
3.1.1 Memory Expasion
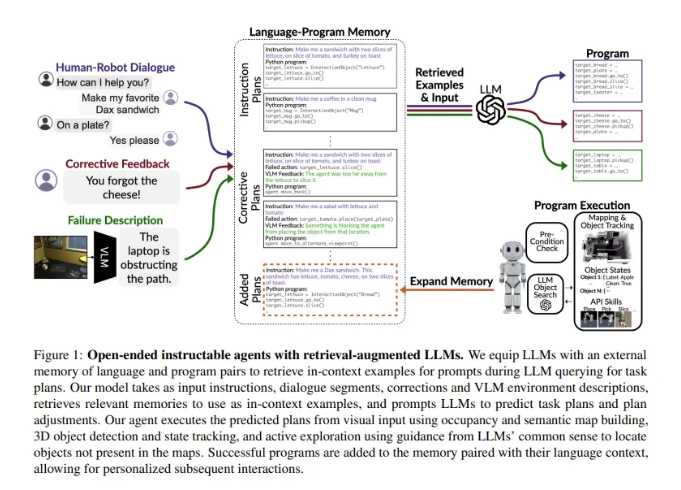
HELPER의 key-value memory는 사용자의 특정 루틴에 맞춰 계속해서 확장할 수 있는데, 사용자가 지시한 작업을 성공적으로 수행할 때마다 language instruction와 executation plan이 pair를 이루는 key-value를 memory에 추가합니다. 이후에 HELPER는 해당 plan을 기억하고 있다가 사용자가 다시 요청하면 이를 조정합니다. Figure 1을 보시면 사용자가 일반적이지 않은 Dax sandwich를 요청하고 있는데, robot은 이를 잘 알아듣는 것을 볼 수 있습니다.
3.1.2 Incorporating user feedback
사용자의 feedback은 로봇의 성능을 향상시킬 수는 있지만, 빈번하게 feedback을 요청하는 것은 사용자의 경험을 부정적으로 만드는데요. 논문의 저자는 사용자의 feedback을 효율적으로 가져가기 위해서 HELPER가 프로그램 실행을 완료했을 때만 사용자 feedback을 요청하도록 하였습니다.
예시를 들어 설명하면, HELPER가 task를 완료한 뒤, “Is the task comleted to your statisfaction? Did I miss anything?”이라고 질문합니다. 사용자가 잘 완료되었어라고 답하면 프로그램을 종료하고, 혹은 사용자가 free-form natural language로 “You failed to cook a slice of potato. The potato slice needs to be cooked”라고 문제가 있음을 말합니다. 그러면 HELPER는 해당 문장을 Planner에 다시 입력합니다. 그러면 이를 기반으로 다시 task를 수행하는 식으로 사용자 feedback을 사용합니다.
3.1.3 Visually-Grounded Plan Correction using Vision-Language Models
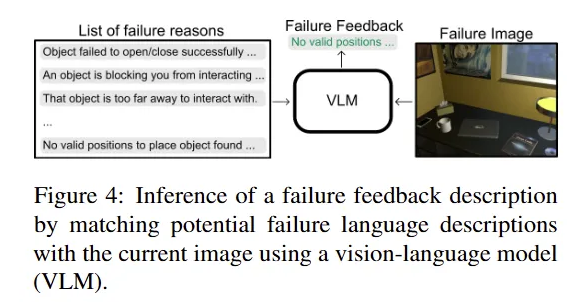
본 논문에서는 VLM을 통해 사용자 feedback 말고도 실패했을 때를 대비하고자 하였는데요. LLM으로 생성된 프로그램은 plan의 일부 단계가 누락되거나 plan 수행하는 과정에서 사용되는 object가 가려지거나 하는 등의 이유로 실패할 수 있습니다. 프로그램이 실패하면 HELPER는 web-scale data로 사전학습된 VLM을 사용하여 현재의 visual observation을 미리 텍스트로 정의된 실패 사례 목록과 매칭합니다. Figure 4로 예시를 들면, “an object is blocking you from interacting with the selected object”이라고 할 수 있습니다. 리스트 중에서 지금 실패한 상황과 가장 잘 맞는 사례를 failure feedback $F$로 간주합니다. 그러면 Planner가 input $I$와 VLM에서 가져온 failure feedback $F$의 encoding 기반으로 memory에서 가장 관련성이 높은 error correction examples를 top-$k$개 검색합니다. 참고로 각 example은 input dialogue, failure feedback, corresponding corrective program을 포함합니다. 그러면 LLM은 실패한 프로그램의 단계, VLM으로부터 예측된 failure description $F$, in-context examle, original dialogue segment $I$를 기반으로 prompting 합니다. LLM은 실패가 발생한 이유에 대해서 self-reflection을 출력하고, primitives $G$에 대한 프로그램을 생성하여 추가적인 corrective primitives $G_{corrective}$ (예를 들어서, step-back(), move-to-an-alternative-viewpoint()와 같이)를 만듭니다. 이렇게 프로그램을 만들었으면 실행을 위해서 해당 내용을 Executor로 넘깁니다.
2.2 EXECUTOR: Scene Perception, Pre-Condition Checks, Object Search and Action Execution
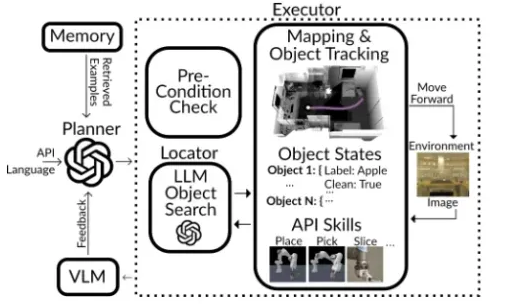
위에 있던 Figure 2를 다시 가져와봤는데요. 해당 파트에서는 앞에서 계속 언급되었던 Executor에 대해서 설명드리고자 합니다. Executor는 예측된 Python 프로그램을 실행하여 코드를 low-level manipulation, navigation action으로 변환합니다. 해당 과정에서 Executor는 각 time step마다 RGB image를 받고 monoclular depth estimation을 통해 depth map을 추정하며, off-the-shelf object detector를 통해 object mask를 얻습니다.
2.2.1 Scene and object state perception
Executor는 depth map, object mask, 그리고 각 time-step에서 agent의 approximate egomotion을 사용하여 장애물을 피하고 home environment의 3D occupancy map과 object memory를 통해 이전에 본 object를 기억합니다. 해당 방법은 이전 연구와 같다고 하니 참고하시면 좋을 것 같습니다. 다시 돌아와서, 매 frame마다 object를 감지하고 예측된 3D centroids를 기준으로 병합하여 object instance를 구성합니다. 각 object instance는 사전 학습된 ALIGN 모델을 사용해 object crop을 각 attribute와 매칭하여 객체의 현재 상태를 지정합니다. 예를 들어서, cooked, sliced, dirty 와 같은 속성을 부여하는 것이죠. 해당 attribute 상태는 manipulation action을 통해 object가 작용될 때 업데이트 됩니다.
2.2.2 Manipulation and navigation pre-condition checks
Figure 2를 보시면 Executor 안에 “Pre-condition check”라는 것이 있는데요. Pre-condition check라는 것을 통해, Executor가 action을 수행하기 전에 먼저 action의 사전 조건을 확인하고, 검증하여서 action이 성공할 가능성이 있는지를 확인합니다. 본 논문에서는 사전 조건으로 확인해야 하는 것들에 대해서 각 action에 대해 미리 정의해하여 체크해두었는데요. 예를 들어서, object를 slice하기 위해서는 먼저 칼을 들고 있어야 한다와 같이 정의를 해둔거죠. 이렇게 사전 조건을 확인할 때 만약 해당 조건을 충족하지 않는다면, 새롭게 plan을 조정하여 action이 성공하도록 합니다. 추가로 논문의 저자가 말하길, open-ended action inferface라면 LLM의 상식을 활용하여 사전 조건을 유추할 수 있기 때문에 미리 정의할 필요가 없다고 하는데요. 그래서 아래와 같이 Locator를 추가로 제안하였습니다.
2.2.3 LOCATOR: LLM-based common sense object search
Locator는 HELPER가 이전에 감지되지 않은 object를 찾아야 할 때 사용합니다. Locator는 language input $I$를 LLM에게 주며, 해당 object가 있을 만한 장소를 제시하도록 합니다. 예를 들어서, 컵과 관련된 지시를 수행해야 한다면 컵을 찾기 위해 “search near the sink”, “search in the cupboard”와 같이 LLM의 상식을 이용하여 object가 있을 법한 공간을 알려주는 것이죠. 그러면 이를 기반으로 해당 장소가 semantic map에 포함된다면, 그곳으로 이동해서 필요한 object를 찾습니다.
본 논문은 위와 같이 action을 성공적으로 수행하기 위한 장치를 여러개 두어 이들이 융합하여 돌아가도록 구성화였습니다.
3. Experiments
본 논문에서는 제안한 agent를 평가하기 위해서 TEACh라는 데이터셋을 사용하였습니다. 해당 데이터셋은 3000개 이상의 human-human interactive dialogue로 구성되어 있으며, 시뮬레이션 환경 AI2-THOR 기반으로 household task를 완료하기 위해서 설계되었습니다.
먼저, 평가 방식으로 사용하는 TfD (Tragjectory from Dialogue)에 대해서 설명드리자면, agent가 에피소드 시작 시 dialogue segment를 받아 이를 기반으로 모델이 사용자의 의도에 맞게 작업을 수행하는 것을 평가합니다. 두 번째 평가 방식으로는, EDH (Execution from Dialogue History)를 사용합니다. 먼저 TfD 에피소드를 session으로 나누어, agent가 이전 session의 대화 및 action 기록을 바탕으로 다음 session으로 가기 위한 작업을 수행하는 것을 평가합니다.
또한, 데이터 셋은 학습 데이터셋에 포함된 방의 존재 여부에 따라 Unseen과 Seen으로 평가 데이터셋을 구분하였습니다.
평가 지표에 대해서도 설명드리자면, 사용된 평가 지표는 아래의 두개를 사용하였습니다.
- SR(Task success rate): agent가 목표 조건을 모두 충족한 session의 비율
- GC(Goal condition success rate): 모든 session에서 달성한 목표 조건의 비율
두 평가지표로 평가할 때 PLW variants도 동시에 고려합니다. PLW(Path Length Weighted) variant는 에이전트가 목표를 달성하기 위해 따라야 할 경로의 길이에 기반하여 추가적인 패널티를 부과하는 평가 방식을 의미하는데요. 만약 에이전트가 주어진 경로를 초과하여 행동한다면, 경로 길이를 초과한 정도에 따라 점수를 잃게 됩니다. 예를 들어, 로봇이 컵을 가져오는 작업에서 주어진 경로가 ‘3 걸음’인데, 실제로 ‘6 걸음’을 수행하면 PLW variant에 따라 패널티를 받는 것이죠.
자 그럼, 이제 실험 결과를 살펴봅시다.
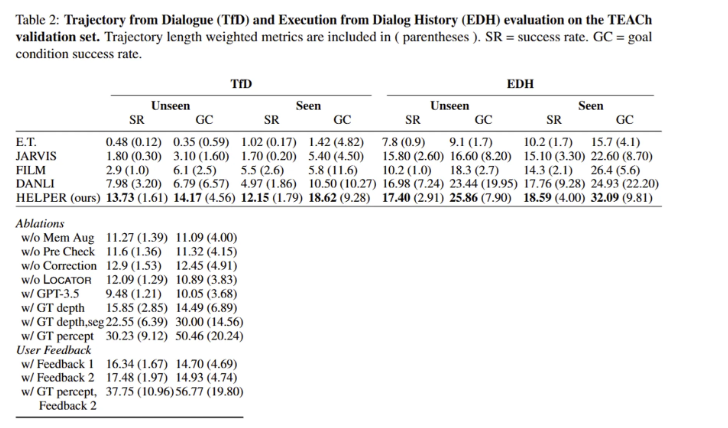
TfD에서 Unseen 상황에서 SR을 보면 다른 방법론에 비해서 HELPER가 13.7로 거의 두배 가까이 높은 것을 볼 수 있습니다. EDH도 HELPER가 높은것을 볼 수 있는데 특히나 Seen 상황에서 GC를 보면 다른 방법론은 20%대의 성능을 달성한 것에 비해서 HELPER만 30% 이상의 작업 성공률을 보인 것을 볼 수 있습니다.
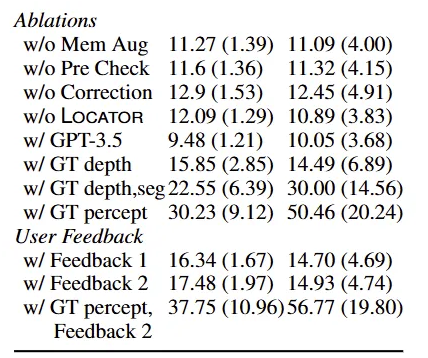
위의 Table 2에서 ablation study 결과를 보기 위해서 조금 확대해서 가져와봤습니다. 두 번째, 세 번째 열 모두 TfD의 Unseen 평가 데이터셋에서의 성능이고, 왼쪽이 SR, 오른쪽이 GC 성능을 의미합니다.
Retrieval-augmented propting이 과연 효과적인지 보기 위해서 memory를 제거하였을 때(w/o Mem aug) 성능이 약 0.18배 감소한 것을 통해 memory를 통해 증강하는 것이 효과적임을 볼 수 있습니다. w/o Correction의 경우, VLM을 통해 실패한 plan을 수정하는 것을 제거한 성능을 의미하는데 역시나 성능 하락한 것을 통해 실패한 plan에 대해서 수정하는 것이 성능에 도움을 주는 것을 볼 수 있습니다.
마찬가지로, w/o Pre Check와 w/o LOCATOR를 통해서 사전 조건을 미리 체크하고, LLM의 상식을 기반으로 장소를 추정하는 것 역시 성능 향상에 도움이 됨을 볼 수 있습니다.
논문의 저자는 LLM의 성능에 따라 성능 변화가 얼마나 일어나는지도 확인하고자 하였는데, 현재 베이스라인으로 사용된 GPT-4에서 GPT-3.5로 변경할 경우 매우 큰 성능 하락이 발생하는 것을 볼 수 있습니다. 확실히 해당 방법론이 LLM을 메인으로 사용하는 것이다 보니, LLM의 자체적인 planing 능력이 얼만큼인지에 따라 성능이 매우 달라질 수 있습니다.
또한 본 Ablation Study에서 추가적으로 확인할 수 있는 것은 Perception이 성능 향상의 bottleneck이라는 것인데요. w/ GT depth는 GT depth를 사용했을 때의 성능으로 기존의 RGB로부터 추정한 depth를 사용한 성능과 비교하면 높은 성능을 달성하는 것을 볼 수 있습니다. 본 논문에서는 이러한 성능 향상을 가져온 이유로 depth estimation network가 원거리의 depth에 대해서 정확도가 낮기 때문에 agent가 환경을 맵핑하고 noisy obstacle map을 탐색하는데 더 시간이 많이 소요되기 때문이라 설명합니다.
마찬가지로 w/ GT depth, seg는 GT depth, segmentation mask를 사용한 것인데 베이스라인에 비해서 매우 큰 보폭의 성능 향상을 이뤘습니다. 이는 frame기반 object detection과 detection response의 late fusion이 지닌 한계 때문이라 언급하는데, 여러 view에서 feature를 더 일찍 fusion하는 3D scene representation을 사용하면 3D object detection 성능을 크게 향상시킬 수 있다고 설명합니다.
최종적으로 depth, segmentation, action success, oracle failure feedback, 횟수를 늘린 API failure limit(50)을 포함한 w/ GT percept를 봤을 때 기존 성능에 비해서 매우 높은 성능 향상을 볼 수 있습니다. 이러한 실험을 넣은 이유는 제안된 방법론이 기존에도 좋지만 앞에서 언급된 depth, segmentation 등이 성공적으로 잘 생성된다면 이정도까지 성능 향상이 될 수도 있는 잠재력이 있음을 어필하고자 넣은 것 같습니다.
User Feedback의 경우, 한 번만 피드백 했을때(Feedback 1), 두 번 피드백 했을 때(Feedback 2)의 성능을 보이며 user feedback을 한 경우 성능 향상을 보이는 것을 알 수 있습니다. 마지막으로 GT percept + Feedback2 성능은 정말 높은 성공률을 보여주네요. 특히 GC를 보면 절반 이상의 성공률을 확인할 수 있습니다.

마지막으로, 본 논문에서 얼마나 사용자 특화된 명령어를 잘 planning하는 가를 평가하였는데, 기존의 plan에서 1번 변화를 주었을 때, 2번 변화, 3번 변화 이런 식으로 수정 횟수를 늘렸을 때의 성능 또한 측정하였는데, 3번의 변화를 주었음에도 성공적으로 planning하는 것을 볼 수 있습니다.
안녕하세요 주연님 좋은 리뷰 감사합니다.
HELPER가 이전에 감지되지 않은 object를 찾아야 할 때 사용하는 LOCATOR에서 LLM의 상식을 통해 있을 법한 위치를 알려주는 방식으로 object가 있을 법한 위치로 이동해도 이전에 감지 되지 않았다면 semantic map에 포함되지 않을 것 같은데 LLM의 사전지식을 활용하는 건가요? 추가로 semantic map은 어떻게 구성되는 지 궁금합니다.
감사합니다.
안녕하세요 주연님 리뷰 감사합니다.
HELPER가 새로운 물체를 찾을 때 LOCATOR가 필요하다고 이해했는데요, LOCATOR 없이 씬 전체를 보는것과 차이점이 무엇인가요? 물체가 있을법한 자리에 없는 경우에도 작업을 수행할 수 있어야 할 것 같은데, 혹시 속도를 높이기 위해 존재하는 것인지, 작업 성공에 긍정적인 영향을 미치는건지 궁금합니다