
안녕하세요, 허재연입니다. 오늘 리뷰할 논문은 2020년 ICLR에 게재된 contrastive representation distillation입니다. 이름 그대로 knowledge distillation에 당시 유행하던 contrative loss를 도입하여 성능을 개선한 내용인데, method를 전부 수식적 흐름으로 전개한 성격의 논문이라 수학적 색채가 짙습니다. 분량이 많지 않은데 전부 수식이라 읽으면서 흐름을 따라가기 위해 수식의 의미를 한참동안 고민하느라 읽는 시간이 상당히 오래 걸렸습니다. 어렵더군요. KL divergence, mutual information과 같은 기초 개념들이 나오니 관련 개념이 잘 기억나지 않는 분들은 해당 개념들을 다시 리마인드하시고 이 논문을 읽는게 좋을 듯 합니다. 리뷰 시작하도록 하겠습니다.
Introduction
신경망 추론에 대한 하드웨어 자원의 한정되어 있을 때 크기가 큰 모델의 표현력을 비교적 가볍고 작은 신경망에 전이하거나, 특정 센서 모달리티 지식을 전이하거나, 여러 모델의 앙상블 지식을 하나의 모델로 전이하는 등 종종 어떤 신경망의 representational knowledge를 다른 신경망에 전이해야 할 상황이 있습니다. 보통 이럴 때 Knowledge Distillation이 사용됩니다.
Knowledge Distillation(KD)는 어떤 딥러닝 모델(teacher)의 지식을 다른 모델(student)에 전이하는 기법입니다. 2015년 제프리 힌튼 연구팀이 제안한 기초적인 knowledge distillation 방법은 teacher와 student output 간 KL divergence를 최소화 하는 방법을 사용했습니다(KL divergence는 확률 분포의 차이를 모델링하므로 student와 teacher는 classification model이었죠. 두 모델의 출력값은 클래스에 대한 확률질량함수로 볼 수 있습니다)
하지만 영상 처리 네트워크의 representation을 깊이나 음성 처리 네트워크로 전이하여 영상에 대한 특징을 깊이 정보 혹은 음성 정보와 연관시키는 것과 같이, 종종 representation에 대한 knowledge를 전이해야 할 때가 있지만 출력 확률에 분포를 매칭하는 위와 같은 방법으로는 이를 수행하기 어렵습니다. representation 자체에 대한 KL divergence 연산을 수행할 수 없기 때문이죠. 저자들은 표현적 지식(representational knowledge)가 구조화(structured)되어있으며, 차원(dimension) 표현 정보 간 복잡한 상호 의존성이 있다고 합니다. 힌튼의 기존 KD objective는 입력에 따라 모든 차원을 독립으로 취급하는데, 이러한 objective로는 출력 차원 간 의존성과 같은 구조적인 지식을 온전히 전이하기 충분하지 않았습니다.
이러한 문제를 극복하기 위해 저자들은 고차원 출력 의존성 및 연관관계를 포착할 수 있는 objective를 방법으로 contrastive objective를 활용했습니다. 여기서 contrastive object는 우리가 흔히 아는 InfoNCE와 같은 contrastive loss를 활용한 contrastive learning이라고 생각하시면 되는데, 당시 주로 self-supervised learning 세팅에서 representation learning의 수행 방법으로 많이 활용되고 있었습니다. 이런 contrastive learning을 활용해 teacher와 student의 representation 구조가 동일해지도록 학습하는 것이죠.
저자들이 사용한 objective는 teacher와 student의 representation 간 mutual information의 하한(lower bound)를 최대화합니다. 이러한 방식이 몇몇 knowledge transfer task에서 좋은 성능 결과를 보이는것을 발견했는데, 이는 조건부 독립 출력 클래스 확률(conditionally independent output class probabilities)에 대한 knowledge를 transfer하는 방법보다, contrastive 목적함수가 teacher의 representation에 있는 모든 정보를 더 잘 정보를 transfer 할 수 있기 때문이라고 추축합니다. 또한, contrastive objective는 큰 CIFAR10 네트워크를 작은 네트워크로 압축하는것과 같이 클래스 확률에 대한 지식을 증류하는 본래 task에서도 더 좋은 결과를 냈다고 합니다. 저자들은 다른 클래스 확률 간 관계(correlation)은 학습 learning problem을 regularize하는 좋은 정보를 포함하고 있기 때문이라고 분석합니다.
본 논문은 독립적으로 발전해 온 두 분야 1.knowledge distillation과 2.representation learning 간 연관성을 제시합니다. 저자들은 이 두 분야 간 연결성을 통해 강력한 representation learning 방법을 활용하여 knowledge distillation에 대한 SOTA를 크게 개선시킬 수 있었습니다.
저자들이 주장하는 contribution은 다음과 같습니다 :
- 딥러닝 네트워크 간 지식을 전이하는 contrastive learning 기반 objective 제안
- 모델 압축(model-compression), 모달 간 전이(cross-modal transfer), 앙상블 증류(ensemble distillation)에의 적용
- 12개 최신 distillation 방법론 벤치마킹. 저자들이 제안하는 CRD는 모든 다른 방법론을 능가하는 성능을 보였습니다(두 번째로 우수한 결과를 보인 힌튼의 Knowledge Distillation 방법보다 평균 57%의 개선).
Method
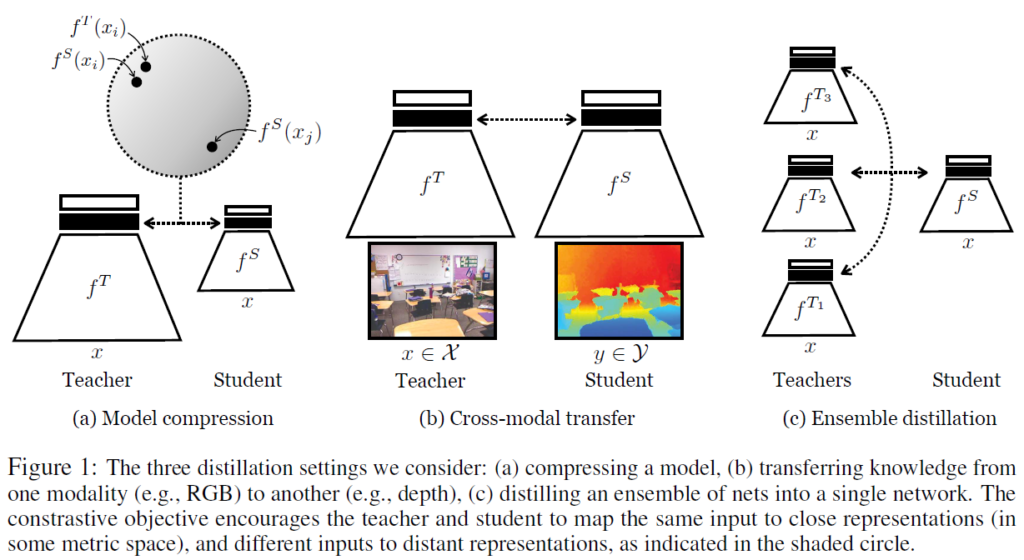
다들 아시듯, contrastive learning의 핵심 아이디어는 어떤 특정한 metric space에서 postive pair 간 유사한 표현을 배우는 동시에 negative pair 간 representation끼리는 그 거리가 멀어지도록 만드는 것입니다. Figure 1에서 저자들이 각기 다른 3가지 task에 어떻게 CL을 활용했는지를 확인할 수 있습니다.
아래 저자들의 수학적 가정과 수식 전개를 나타냈습니다. 우리가 평소에 읽던 것과는 약간 다르게 수식적으로 풀어나가서 이해하기 어려웠네요.
Contrastive Loss
기호를 먼저 정리하겠습니다. teacher network는 {f}^{T}, student network는 {f}^{S}, input {x}에 대해서, 끝에서 두 번째(logit 이전) 층의 representations를 각각 {f}^{T}(x)와 {f}^{S}(x)라고 합니다. {x}^{i}는 training sample이고, {x}_{j}는 다른 랜덤 샘플입니다. contrastive learning에서는 representation {f}^{S}({x}_{i})과 {f}^{T}({x}_{i}) 간 거리가 가까워지도록 하는 동시에 {f}^{S}({x}_{i})와 {f}^{T}({x}_{j}) 간 거리가 멀어지도록 합니다. 표기의 편의를 위해 데이터에서 student와 teacher의 representation을 랜덤변수 S, T로 표기합니다.

joint distribution p(S,T)과 marginal distribution의 곱 p(S)p(T)를 고려했을 때, 이 분포 간 KL divergence를 최대화함으로써 student와 teacher representation 간 mutual information을 최대화할 수 있다고 합니다. 이 목적을 가지고 적절한 loss를 설정하기 위해, 잠재변수 C로 joint나 marginal의 곱 가진 분포 q를 다음과 같이 정의합니다 :
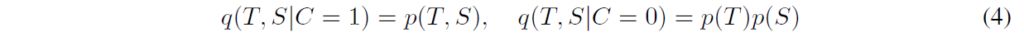
이제 데이터에서, 저자들은 모든 N개의 불일치 쌍(incongruent pairs. product of marginals에서 추출됐으며, T와 S에 독립된 랜덤 추출된 입력)에 대해 1개의 합동 쌍(congruent pair. joint distribution에서 추출됨. 동일한 입력이 T,S에 들어감)이 주어졌다고 가정해 봅시다. 그럼 latent C의 prior는 다음과 같이 된다고 합니다 :
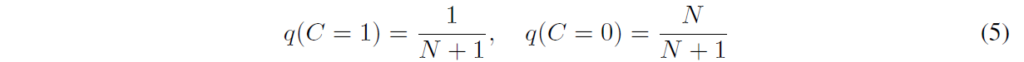
베이즈 정리를 활용하여 식을 사용하여 정리하며, class C=1에 대한 prosterior는 다음과 같이 된다고 합니다 :
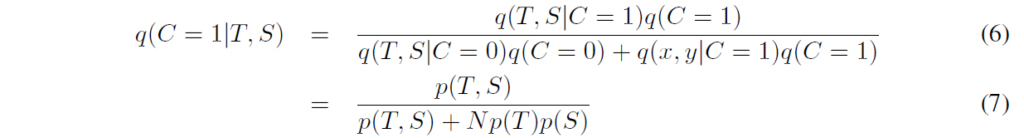
음.. 굉장히 간결하게 정리해서 수식을 따라가기 꽤 힘드네요. 그냥 유도 과정으로 생각하고 따라간 다음 결과를 봐야겠습니다. 이 다음에는, 다음과 같이 mutual information과의 관계를 확인할 수 있다고 합니다 :

여기서 양변의 p(T,S)에 대해 기댓값을 취해주고 정리하면 다음과 같이 작성할 수 있다고 합니다(논문에 전반적으로 중간 수식들의 내용은 따로 작성되어있지 않습니다).
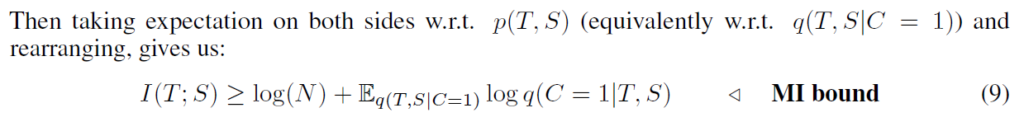
수식 (9)에서 I(T; S)는 teacher와 student 임베딩의 분포 간 mutual information입니다. 따라서 student network S에 대해 {E}_{q(T,S|C=1)}log q(C=1|T,S)를 최대화하는것은 mutual information의 하한(lower bound)를 증가시킵니다. 하지만, 우리는 q(C=1|T,S)의 실제 분포를 모르기에, 대신 모델 h : {T,S}->[0, 1] 을 데이터 분포 q(T; S|C = 1)와 q(T,S|C = 0)의 샘플에 맞추어 추정합니다. 이제 이 모델 상황에서 데이터의 log likelihood를 최대화합니다(이진 분류 분제로 가정하면) :
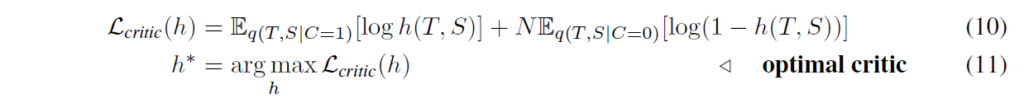
여기서 이후 critic 점수를 최적화하도록 representation을 학습할 것이기 때문에 h를 critic이라고 한다고 합니다. h*(T|S)=q(C=1|T,S)라고 하면 Gibbs 부등식에 따라 다음과 같이 (9)번 수식을 h*에 대해 다시 쓸 수 있다고 합니다:
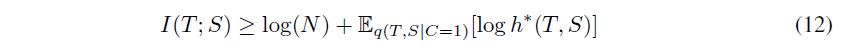
따라서 optimal critic은 mutual information에 대한 기댓값을 하한하는 estimator임을 알 수 있습니다. 저자들은 teacher와 student의 representation 간 mutual information을 최대화하는 student를 학습시키고자 합니다. 이를 위해 당므 최적화 문제를 제안합니다 :
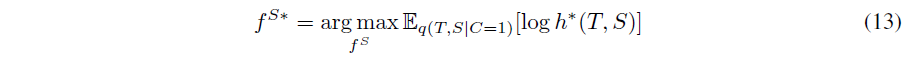
여기서 어려운 점은, optimal critic h*가 현재 student에 의존한다는 것입니다. 저자들은 (12)번 수식의 bound를 약화시키도록 하여 이 어려움을 피하였습니다 :
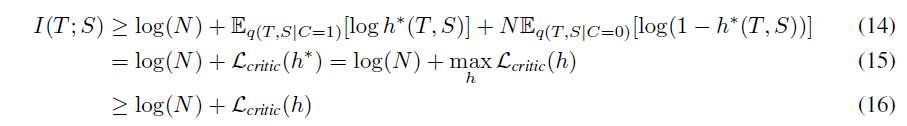
(14)는 (12)번 수식에 단순히 N{E}_{q(T,S|C=0)}[log(1-h*(TS))]를 더한 것으로, 음수를 더하였기에 등호가 유지됩니다. student에 대해 (15)을 최적화하여 다음을 얻을 수 있습니다 :
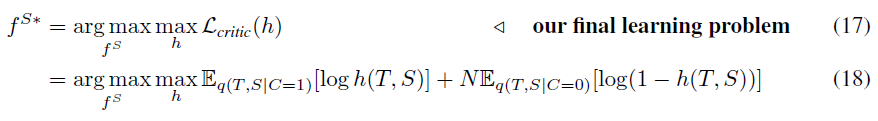
위 수식을 통해 h를 학습시키는 동시에 {f}^{S}를 최적화시키게 됩니다. 수식 (16)으로 인해 어떤 H에 대해서 {f}^{S*}= {arg max}_{{f}^{S}}{L}_{critic}(h)도 mutual information의 lower-bound를 최적화하는 표현이므로 위 식이 h가 완벽하게 최적화되는 것에 의존하지 않는다고 합니다.
저자들은 representation h로 h : {T,S}->[0,1]를 만족하는 함수를 사용할 수 있다고 하는데, 실제로는 다음을 사용하였다고 합니다(여기서 T와 S는 임베딩 도메인입니다) :
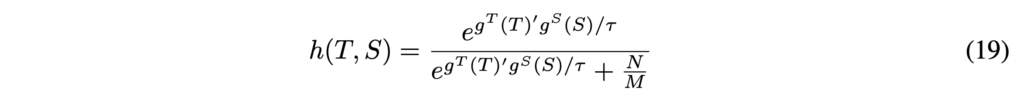
여기서 M은 데이터셋의 cardinality이고, 타우는 temperature 파라미터입니다. 실제로는 S와 T의 차원이 다를 수 있기 때문에 {g}^{S}, {g}^{T}를 동일한 차원으로 선형 변환하고 내적 연산 이전에 L2 정규화를 진행해줍니다(일반적인 contrastive learning이라고 생각하면 될 것 같습니다). 19번 수식은 contrastive loss로 자주 사용되는 infoNCE loss와 유사하지만, 실험을 통해 보다 효과적인 loss를 찾은 것이라고 합니다(이를 통해 mutual information의 lower bound를 maximize합니다).
Knowledge Distillation Objective
2015년 힌튼의 논문에서 제안된 KD loss는 student output {y}^{S}와 원핫 레이블 y 사이 일반적인 크로스 엔트로피 손실이 아닌, student network 출력이 teacher network 출력과 유사해지도록 출력 확률 분포 간 cross-entropy를 최소화하는 방향으로 학습합니다.
학생 출력 yS와 One-hot 레이블 y 사이의 규칙적인 교차 엔트로피 손실 외에도, 학생 네트워크 출력이 교사 출력과 최대한 유사하도록 요구하여 출력 확률 간의 교차 엔트로피를 최소화합니다.
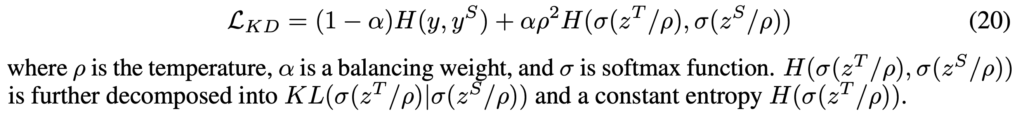
수식 (20)에서 ρ는 temperture, α는 가중치, σ는 softmax입니다.
Cross-Modal Transfer Loss
cross-modal transfer task의 그림은 Figure 1의 (b)에서 확인할 수 있습니다. RGB->depth로의 transfer네요. teacher는 대규모 소스 데이터셋으로 지도학습을 수행하고, 이를 다른 데이터셋/모달리티에 대해 적용하여 knowledge를 transfer하고 싶습니다. 해당 transfer task에서, 저자들은 수식 (10)의 contrastive loss를 사용하여 student와 teacher의 feature를 매칭합니다.
Ensemble Distillation Loss
Figure 1 (c)의 앙상블 증류에서, 1개 이상의 teacher network의 지식을 하나의 student에 전이합니다. 저자들은 teacher network들과 student network 간 다중 페어 contrastive loss를 정의하여 contrastive framework를 적용합니다. 이 loss들은 합하여 최종 loss로 사용됩니다.
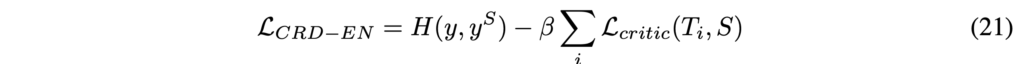
Experiment
실험에 대한 데이터셋으로 CIFAR10, ImageNet, STL10, TinyImageNet, NYU-Depth 등 다양한 데이터셋이 사용되었습니다.
Model Compression
CIFAR-100, ImageNet 데이터셋에서 ResNet, WideResNet의 다양한 capacity의 teacher-student 조합으로 수행되었습니다. Table1, Table2는 다양한 distillation objective에 대해 top-1 accuracy를 비교하였습니다. Table 1에서는 동일한 모델 구조 스타일의 student와 teacher를 비교하였고, Table2에서는 다른 구조의 student-teacher에 대한 실험을 나타내었습니다.
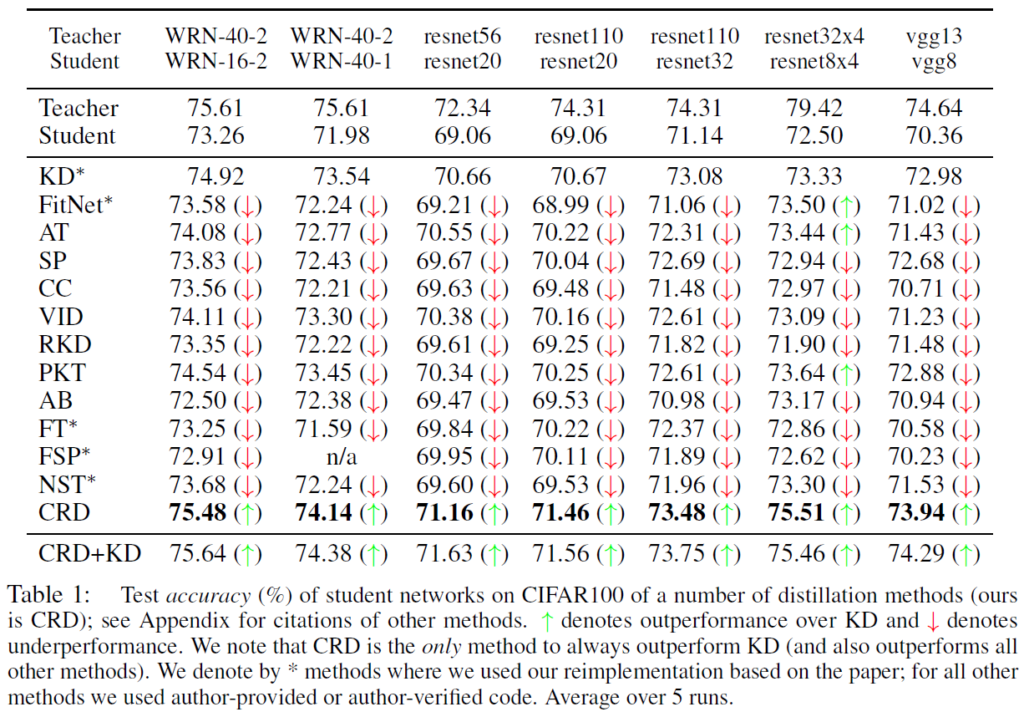

저자들이 제안한 CRD(Contrastive Representation Distillation)은 일관적으로 original KD를 포함한 다른 모든 distillation objective를 능가하는 성능을 보였습니다. 재밌는것은 해당 실험에서는 일관적으로 단순한 KD의 성능을 능가하는 방법론이 그리 많지 않았으며 original KD가 굉장히 잘 동작한다는 것입니다.
또한, student-teacher의 조합을 동일한 모델 구조에서 다른 구조로 변경할 때 중간의 representation을 증류하는 방법이 마지막 layer부분들에서 증류하는것보다 안 좋은 성능을 보인다는 것입니다. 예를 들어 Attention Transfer(AT)와 FitNet 방법은 기본적인 student보다 성능이 떨어지는 반면 마지막 여러 계층에서 작동하는 PKT, SP, CRD들은 좋은 성능을 보여주었습니다. 이는 서로 다른 스타일의 모델 구조가 입력에서 출력으로 매핑되는 자체적인 solution path를 가지고 있어서 중간의 representation을 모방하는 것이 이러한 inductive bias와 충돌할 수 있기 때문이라고 설명하고 있습니다.
Capturing inter-class correlations
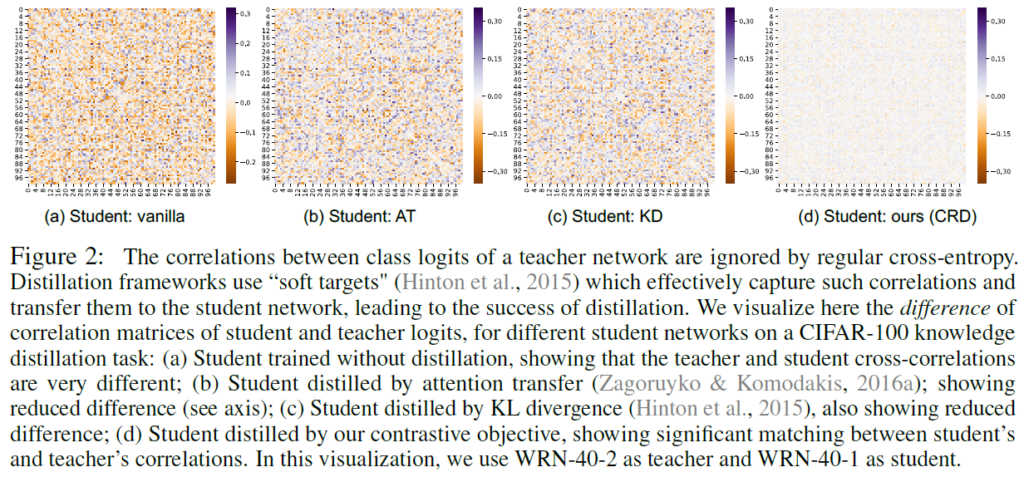
Figure 2에서는 3가지 다른 student(distillation 없는 vanilla student, AT나 KD로 학습된 student, CRD로 학습한 student)와 teacher의 logit에 대한 correlation matrix들 간 차이를 계산한 것이라고 합니다. teacher와 student 간 차이가 작은 것을 확인함으로써 CRD의 objective가 다른 방법들에 비해 logit에서 가장 많은 correlation structure를 포착할 수 있다는 것을 확인할 수 있습니다.
Results on ImageNet

Table 3에는 ImageNet에 대한 결과를 나타내었습니다. teacher로는 ResNet-34을, student로는 ResNet-18을 사용하였습니다. teacher와 student 간 top-accruacy의 차이는 3.56%인데, AT는 이 차이를 0.95% 줄이는 반면, 저자들의 CRD는 상대적으로 50% 개선된 1.42%를 줄여 CRD의 확장성을 검증하였습니다.
Transferability of representations
representation learning의 목표는 훈련 중에 보지 못한 데이터나 태스크에 대해 transfer되는 general한 knowledge를 확보하는 것입니다. 저자들의 관심사가 이 representation의 확보에 있기 때문에 distillation한 knowledge가 잘 transfer되는지 확인하는 실험을 수행하였습니다. WRN-16-2을 WRN-40-2 teacher로부터 증류시키거나 스크래치부터 학습시켰으며, 이 student network는 STL-10이나 TinyImageNet 이미지에 대해 frozen representation extractor(logit 이전 layer까지)로 사용하였습니다(SSL이나 representation learning에서 사용되는 linear evaluation 세팅이라고 생각하면 됩니다). 이후 linaer classifier를 학습시켜 학습한 표현의 전이 능력(transferability)을 정량적으로 비교하였습니다.
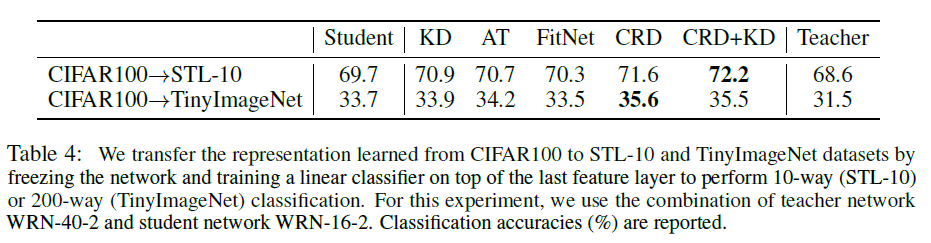
Table 4에서, FitNet을 제외한 모든 방법론들이 STL-10과 TinyImageNet 모두에서 학습된 representation의 transferability의 개선을 보였습니다. teacher는 original CIFAR100 데이터셋에서 가장 우수한 성능을 보이지만, 이 representation은 다른 두 데이터셋에 데이터셋에 representation이 잘 transfer되지 못했습니다. 저자들은 이를 teacher의 representaion들이 본래 태스크에 bias되었기 때문이라고 추측합니다. 더불어, CRD+KD distillation의 student가 teacher보다 훨씬 잘 transfer되는것을 강조합니다(STL-10에서 3.6, TinyImageNet에서 4.1%).
Cross-Modal Transfer
저자들은 Luminance -> Chrominance와 RGB- > Depth 로의 두 가지 cross-modal transfer에 대한 실험을 수행했습니다
Luminance -> Chrominance 실험에서, 저자들은 Lab color space에서 실험을 수행했습니다(L이 Luminance, ab가 Chrominance라고 합니다). 우선 L 네트워크를 TinyImageNet으로 학습하고 이 L 네트워크를 ab 네트워크로 다른 object를 사용하여 unlabeled STL-10으로 전이하였습니다. 편의를 위해 teacher와 student는 같은 구조를 사용했으며, ab 네트워크의 knowledge를 다음 2가지로 평가하였습니다. (1)linear probing : 네트워크를 freeze하고 linear classifier를 학습시킵니다. (2)fully finetuning : 말 그대로 ab 네트워크를 전체 fine-tuning하는 것입니다.
RGB->Depth transfer에서는 사전학습된 teacher ResNet-18의 knowledge를 depth 이미지에서 작동하는 5계층 student network에 transfer하였습니다.
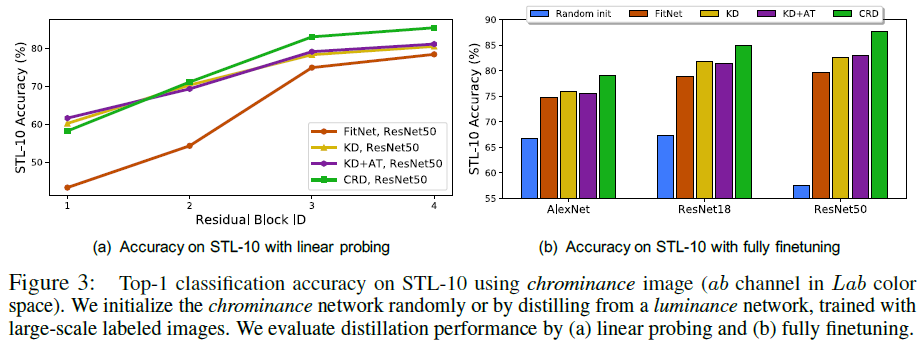
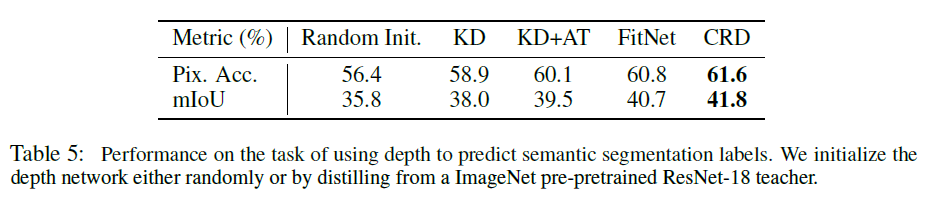
위 두 실험에서도 저자들이 제안한 CRD이 좋은 transfer 결과를 보임을 확인할 수 있었습니다.
오랜만에 KD 논문을 찾아보다 읽어보게 되었는데, 수식이 많아서 이해하는데 좀 애를 먹었습니다. 아직도 완벽히 내용을 이해했다는 느낌이 들지는 않네요.. 그래도 일긍며 KD라는 task에 대해 좀 더 감을 잡을 수 있었습니다.
감사합니다.