안녕하세요, 이번 X-review는 재찬이 학회 발표에 도움이 되보고자 읽어봤던 논문이어서 VLM과 LLM을 활용한 affordance localization Prompting 논문입니다. Affordance라는 개념이 생경해서 찾아본 결과 칼은 물체를 “썰 수 있고”, 숟가락은 액체를 “퍼올릴 수 있다”와 같이 어떤 객체가 로봇과의 상호작용을 통해 제공할 수 있는 특성을 로봇이 이해했을 때 객체의 affordance를 이해했다고 표현한다고 합니다.
기존 연구들은 대부분 fine tuning 을 통해 특정 객체와 affordance를 처리할 수 있도록 했습니다. LLM을 fine tuning 하여 affordance 마스크 토큰을 생성하거나 텍스트 인코더를 fine tuning 해서 Open Vocabulary에서 affordance localization을 수행했습니다.
과연 LLM이 affordance를 이해할 수 있을까? 라는 질문에서 출발한 해당 논문은 기성 VLM과 LLM을 적절히 활용하여 finetuning 없이 객체의 affordance를 이해하고 처리할 수 있는 능력을 미리 훈련된 데이터가 없는 Open Vocabulary상황으로 확장했다는 점에 초점을 맞췄습니다. 이러한 일반화 능력은 가정환경이나 사무실 처럼 다양한 객체들이 많고 유연하게 작동해야 하는 환경에서 특히 강점을 가진다고 합니다.
논문의 핵심 contribution으로는 VLM과 LLM이 연결된 open vocabulary 작동을 가능하게 하는 알고리즘을 제시한 점, 자연어 토큰을 사용한 프롬프팅의 중요성을 파악한 점, 새로운 domain에서 finetuning 없이도 최신 supervised 모델들과 견줄만한 성능을 확보했다는 점이 있습니다. 이어서 Affordance Localization, Affordance Prompting을 포함한 전체 프레임워크를 자세히 살펴보도록 하겠습니다.
Overview
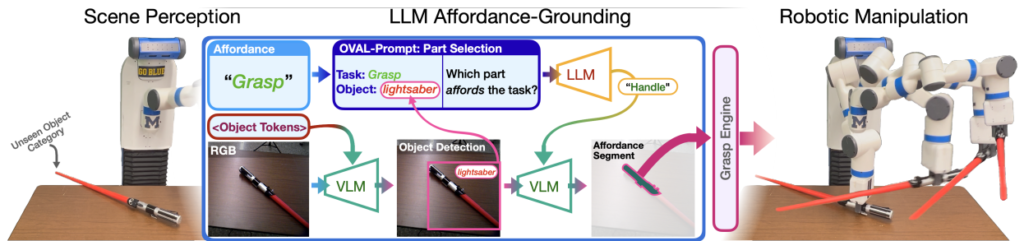
전체적인 프레임워크는 unseen object에 대해 원하는 affordance를 이해하고 액션까지 수행할 수 있습니다. 구조는 Scene Perception, LLM Affordance-Grounding, Robotic Manipulation으로 나뉩니다. RGB-D를 입력으로 받고 RGB 데이터를 이용해 affordance localization, affordance grounding을 수행한 후 depth 정보를 grasp engine에서 활용해 액션을 하는 방식입니다.
위의 figure와 같이 광선검을 예시로 설명하겠습니다. 먼저 Scene Perception 단계에서는 unseen object인 광선검의 RGB이미지와 object token 리스트가 pretrained VLM에 전달됩니다. 이 때 object token에는 원하는 affordance를 수행할 수 있는 물체들을 정리한 자연어 리스트가 들어있습니다. 예를 들어 “퍼올리다” 라는 affordance를 이해하기를 원한다면, object tokens의 리스트에는 무언가를 퍼올릴 수 있는 spoon, shovel 등의 단어가 들어갑니다. Object Token들을 전달받은 VLM의 output 중 confidence score가 0.5 미만인 결과물들은 무시하고 0.5 이상인 Object Detection 결과물만 남겨둡니다. Figure의 경우 광선검이 검출됩니다.
이후 prompting된 LLM을 활용해 LLM Affordance-Grounding을 수행합니다. 이 때 사전에 프롬프팅된 LLM에 목표 Affordance인 Task와 Scene Perception과정에서 detect된 Object를 입력합니다. 이 때 LLM은 task를 afford하는 (목표 task를 수행할 수 있는) 부분이 detect된 object에서 어떤 part인지를 반환합니다. 이후 Affordance를 이해한 LLM의 대답을 VLM의 input으로 넣고 최종적으로 affordance segment를 진행합니다. 이렇게 object와 task를 통해 목표 부위를 segment하는 과정을 affordance grounding이라고 합니다. 위의 figure의 경우 광선검의 손잡이가 segment 됩니다.
마지막으로 affordance segmentation을 마친 뒤 segmentation mask와 처음 RGBD input의 depth 정보를 활용하여 DexNet에 입력되어 로봇 액션을 수행합니다. DexNet은 binary mask와 depth정보를 통해 모션 플래닝을 진행합니다. 저자의 경우 그리퍼의 방향을 z축으로 고정해둔 채 DexNet의 결과물을 top-down pick-up (인형뽑기 기계처럼 수직으로 들어 올리는 방법)으로 변형시켰다고 합니다. 이렇게 생성된 경로는 MoveIt을 통해 계산되고, 로봇에 전달됩니다. 이 과정으로 grasping의 정확도를 높이고 동적 환경에서 효과적으로 작동할 수 있다고 합니다. 다만 이럴경우 다양한 affordance를 이해하고 수행하는 것에 있어서 제약이 많을것 같다는 생각이 들긴 합니다.
이어서 논문의 Affordance Localization, Affordance Prompting에 대해서 조금 더 자세하게 살펴보도록 하겠습니다.
OVAL-Prompt : Affordance Prompting
앞서 말했듯, 로봇이 목표 객체와 목표 작업을 수행하기 위해 객체의 특정 부분을 인식하고 식별하는 과정에서 LLM이 사용됩니다. LLM은 precise(정확하게) 프롬프팅이 되는것이 굉장히 중요하다고 저자는 언급합니다. LLM을 정확하게 다루기 위해서는 프롬프트의 구조가 중요하다고 특히 강조하면서 잘 정리된 답변을 위해 OVAL-Prompting된 LLM은 상황에 따라 적절한 물체 찾기, 물체에서 task에 관련된 부분 강조하기, 추가적인 부위 생각해내기의 단계들을 거칩니다.
저자들은 아래와 같이 어떤 task를 진행하는 것인지를 알려주고 LLM이 주어진 objects들 중 주어진 task를 해결할 수 있는 것들이 무엇인지, 그리고 그 이유는 무엇인지를 말하게 프롬프팅 한다고 합니다. 이러한 과정은 Chain of Thought의 논리를 거치면서 저 믿을만한 대답을 할 수 있게 해준다고 합니다.

이후에 추가적인 query(VLM을 통해 검출된 객체들과 affordance)를 통해 VLM의 segmentation을 위한 affordability를 가지고 있는 part를 반환합니다. 이 과정에서도 위의 프롬프트와 비슷한 프롬프트가 사용됐다고 하지만 따로 제공되지는 않았습니다. 만약 LLM의 output을 query로 VLM이 part segmentation을 진행하지 못 한다면, 대체 query를 만들어낸다고 합니다. 저자는 “cup side”를 segment하는것을 실패했을 때 alternative로 “cup body”를 출력했다고 합니다. 모델은 일관성 있는 대답을 위해 GPT-4 API의 temperature를 0으로 설정하고 사용했다고 합니다. GPT API의 temperature는 0 부터 무한대 값까지 정할 수 있고, 값이 높을수록 더 다양한 답변을 한다고 합니다. 정작 affordance를 이해하고 part segmentation을 위한 프롬프트는 제공되지 않은 점이 아쉽습니다.
Experiments
저자들은 UMD 데이터셋으로 OVAL-Prompt를 사용한 파이프라인이 HMP, GSE등의 모델과 비교해서 얼마나 affordance를 이해하고 있는지 실험했습니다. UMD 데이터셋은 7개의 affordance와 17개의 객체 클래스를 가지고 있는 데이터셋이고, 평가지표로 베타 파라미터가 1인 Weighted F-score를 사용한다고 합니다. 저자들의 실험에서도 동일한 평가지표가 사용되었습니다. 실험 결과는 아래와 같습니다. OVAL-Prompt로 진행된 파이프라인은 다른 모델들과 비교해 HMP보다 0.154 높고, GSE 모델 보다는 0.144 정도 낮지만 실제 응용에 적합한 수준이라는 결론을 내렸다고 합니다.
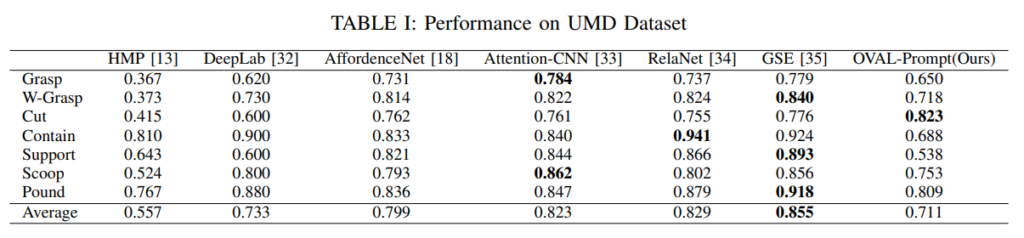
저자는 성능면에서의 문제를 VLM에서 찾았습니다. VML모델의 segmentation 능력이 부족하고, 특정 클래스에서 혼동을 일으켰다고 합니다. 예를들어 plant pot(화분), turner(뒤집개)와 같은 query에 대해 수행하지 못 했고, 이는 pot(냄비), spatula(뒤집개의 상위 카테고리)로 일반화 했을 때 수행할 수 있었다고 합니다. VLM이 일반적인 query에 대해 더 잘 수행할 수 있기 때문에 이를 충족시킬 때 특정 물체의 affordance를 이해하는 것은 더 어려워집니다. LLM이 너무 구체적인 카테고리의 답변 뿐 만 아니라 공간정보가 포함된 답을 낼 때 또한 VLM의 이해능력이 부족해 segmentation을 수행하는데 어려움이 있었다고 합니다. 이럴 때 LLM은 VLM이 이해할 수 있는 다른 alternative query를 제공했다고 합니다. 뭔가 LLM의 이해능력이 사용되지 않고 bottleneck으로 작용하는 VLM에 맞춰진 것이 아쉬운 것 같습니다.
Grasping

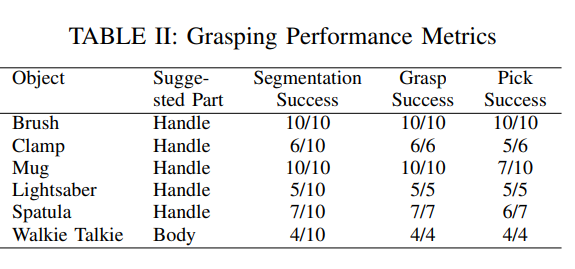
Grasping의 경우 위 사진처럼 DexNet을 top-down pick-up (인형뽑기 기계처럼 수직으로 들어 올리는 방법)으로 변형시켜 그리퍼의 z축 방향을 고정시켜 아래를 보게 하고 진행했습니다. VLM이 part를 segmentation 하는 경우 아래 표와 같이 파지 성공률이 거의 100퍼센트에 달했고, 그렇지 못하고 객체 전체를 segmentation하는 경우에는 비교적 아쉬운 결과를 보였다고 합니다. 하지만 이러한 grasping이 의미가 있을까,, 싶습니다.
Ablation
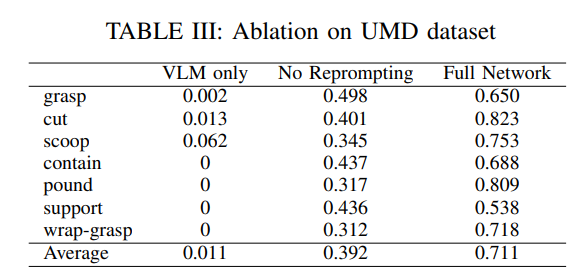
저자는 LLM 없이 어포던스 목록과 함께 VML만 사용한 경우, VLM이 LLM의 query에 대한 part segmentation을 진행하지 못 했을 때 reprompting을 하지 않은 경우, Full Network로 나누어서 실험을 진행했습니다. 당연한 이야기이지만 자연어 이해 능력이 부족한 VLM만을 사용한 경우 거의 task를 진행할 수 없었습니다. 또한 Reprompting 과정의 필요성을 어필했습니다. 다만 reprompting을 통해 VLM이 이해할 수 있는 query를 만들어 내는것이 모든 경우에 affordance를 이해한 segmentation을 진행하는데 도움이 되는지는 약간 의문입니다.
Conclusion
저자들은 OVAL-Prompt의 Open Vocabulary 상황에서의 Affordance 이해능력의 잠재력이 높음을 강조했습니다. Zero-shot affordance localization을 진행하는데 있어서 여러 객체를 처리할 때 문제가 생겼다고 합니다. LLM이 제대로 할 일을 못 하는것 같은데, 이러면서 파이프라인 설명에는 객체의 리스트 중에 가능성이 있는 여러 물체들에 대해 affordance localization을 실행하는 것 처럼 말하면서 예시 figure나 한계점에서 단일 객체에만 잘 작동한다고 하는것은 모순이 아닌가 싶습니다. VLM에 인간으로부터 사전 정의된 object token들이 필요하다는 점과 grasping이 너무 작업 성공에 치우쳐져 있어서 실용성이 없을 것 같은 점도 그렇고 뭔가 기존의 모델들을 그저 이어붙이기만 하고 문제가 풀린건 없는것 같은 아쉬움이 있는 논문인 것 같습니다.
안녕하세요. 영규님. 리뷰 감사합니다.
object token 리스트에 대해서 간단하게 질문이 있는데요. object token 리스트에는 어떠한 affordance를 수행하기 위해 spoon, shovel와 같이 affordance를 수행하기 위한 object가 들어가는 것을 이해했습니다. 그러면 object token의 경우 afforadance가 달라질 때 마다 업데이트 되는 걸까요? 아니면 고정된 list일까요?
또한, 궁금한 것이 llm의 output을 쿼리로 vlm이 part segmentation을 진행하지 못했다고 하면 대체 쿼리를 만들어 수행하는데, 예시로 든 것이 cup side가 안되면 cup body를 출력할 수 있다고 하였는데 그러면 이는 object token list에서 confience score가 높은 것 중의 하나로 대체하여 동작하는 걸까요?
감사합니다.
김영규 연구원님 좋은 리뷰 감사합니다.
Affordance Prompting에서 VLM을 통해 part segmentation을 수행하는 데 실패하면 대체 query를 만들어낸다고 하셨는데, 여기서 성공과 실패에 대한 판단은 어떻게 진행되는 지 궁금합니다.
또한, open-vacabulary 상황으로 확장을 보이기 위해 “affordance”에 해당하는 표현을 유의어로 다양하게 바꿔 실험을 해보거나 하지는 않았는 지 궁금합니다.