제가 이번에 리뷰할 논문도 Affordance 관련 논문입니다. 자신들의 방법론을 AffordanceCLIP이라 하여 관심이 생겨 읽게 되었습니다. 코드는 따로 공개되어있지 않습니다.
Abstract
사람은 도구를 어떻게 사용할지에 대해 인지할 수 있는 타고난 능력이 있으며, 물체의 부분과 행동을 연관시켜 물건을 활용할 수 있습니다. 이러한 물체 영역을 affordance라 하고, 지능형 로봇이 일상생활에서 임의의 물건을 사용할 수 있도록 하기 위해서는 작업에 따라 관련 영역을 인식할 수 있어야 합니다. 기존 지도학습 기반의 방식은 픽셀 수준의 annotation이 요구되므로 많은 비용이 요구되었으며, 특정 영역에 대한 픽셀 수준의 라벨링이 아닌 keypoint를 이용하거나 사람과 물체의 상호작용 이미지로부터 affordance를 학습하는 weakly supervised 방식도 여전히 학습에 사용된 데이터에만 의존한다는 한계가 있습니다. 이러한 확장성 부족과 학습 데이터로의 편향을 해결하기 위해 해당 논문은 AffordanceCLIP을 제안합니다. AffordanceCLIP은 CLIP과 같이 대규모 데이터로 사전학습된 Vision-Language 모델이 내포한 affordance 지식을 활용하고자 하였습니다. 저자들은 실험을 통해 CLIP이 affordance를 명시적으로 학습하지는 않았지만, task에 유용한 정보를 인식할 수 있음을 입증하였으며, AffordanceCLIP을 이용한 zero-shot 방식의 프레임워크를 제안합니다. 해당 방법론은 실험을 통해 사전에 정의되지 않은 행동에 대한 프롬프트가 주어졌을 때도 작동 가능하며, 기존 방식에 비해 적은 수의 파라미터만을 학습하고, action-object 쌍에 대하여 직접적인 지도학습을 수행하지 않으므로써 모델의 확장 가능성한 추론 성능을 보여주었습니다.
Introduction
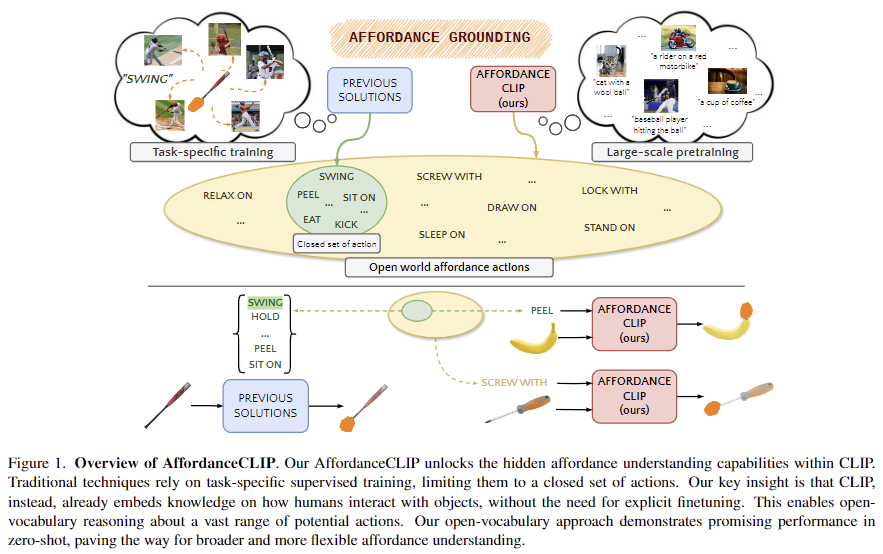
사람은 일상생활에서 목적을 달성하기 위해 다양한 물체와 도구를 접하고 조작하며, 물체의 시각적인 속성(형태, 재질, 부품)을 행동과 연관시키는 타고난 능력을 가지고있습니다. 물체와 기능을 연관시키는 문제는 affordance grounding으로 알려져있으며, 이는 특정 action이 주어졌을 때 물체에서 연관된 영역의 위치를 인식하는 것을 목표로 합니다. 현재, 기본적인 방식은 물체의 일부분에 대하여 기능 정보를 수동 라벨링한 데이터를 활용하여 네트워크를 학습시키는 방식으로, 각 물체의 각 부분에 대한 segmentation 마스크가 필요합니다. 유리컵을 예로 들면, 손잡이는 grip, 잔의 가장자리 입구 쪽은 drink라는 정보가 주어지는 것 입니다. 이러한 픽셀 수준의 라벨 정보를 이용하는 방식은 데이터 수집에 너무 많은 비용이 소요되며, 이러한 라벨링 비용을 줄이고자 물체와 사람이 상호작용하는 이미지들을 통해 affordance를 학습하는 weakly supervised 방식이 연구되었습니다. 이러한 weakly supervised의 예시는 아래의 Figure 1의 왼쪽 상단 이미지와 같이 야구 방망이를 휘두르는 이미지들(Human-Object Interection; HOI image)과 “swing”이라는 정보를 함께 제공하는 것 입니다. 이러한 방식을 통해 annotation 비용이 줄어들긴 했지만, 이러한 방식은 test를 수행할 때, 대상 물체가 중심으로 촬영된 영상으로 한정되므로(앞서 예시를 든 야구방망이를 사람이 휘두르는 데이터로 학습할 경우, 야구방망이만 촬영된 영상에 대해서 affordance를 인식하는 방식으로 이루어짐) 실제 application에 사용하기에는 어려움이 있습니다. 또한, open-vocaburary로의 확장과, 다양한 환경 및 상황에 따라 달라지는 affordance를 고려하지 못합니다.
해당 논문은 따라서 사전에 정의된 라벨 정보를 직접적으로 학습하지 않고 affordance 정보를 전달하고자 하였습니다. 이를 위해 대규모 데이터로 학습된 Vision-Language Model이 학습 과정에 사람과 물체의 상호작용에 대한 정보를 학습하였을 수 있다는 점을 활용하고자 하였으며, 이는 잘 구축된 한정된 범위의 affordance 데이터 셋 보다 학습에 사용한 대규모 데이터 셋에 더 다양한 상호작용이 포함되었다고 보았기 때문입니다. 이러한 가설에 대해 저자들은 MaskCLIP[1]이 zero-shot 방식으로도 affordance 데이터 셋인 ADE20K에 대해서 affordance 영역을 추론할 수 있다는 점을 저자들의 가설(대규모 데이터로 학습하며 다양한 affordance와 관련된 정보를 학습하였을 것이다)에 대한 근거로 들었습니다. 하지만 MaskCLIP 논문을 보면 기존 방법론보다는 개선되어있지만 annotation-free인 상황의 zero-shot에서는 mIoU가 10.2정도로 굉장히 낮았고, Image-Net-1K로 self-supervised로 학습한 뒤 zero-shot을 적용한 결과가 그나마 44.5%의 mIoU를 달성하였습니다. (참고로, MaskCLIP은 text와 이미지로부터 global 수준의 표현 사이의 align을 맞춘 기존의 CLIP을 의미론적으로 대응되는 local한 영역을 추정할 수 있도록 제안된 방법론입니다.)
[1] Dong, Xiaoyi, et al. “Maskclip: Masked self-distillation advances contrastive language-image pretraining.” CVPR 2023.
저자들은 frozen된 CLIP에 경량화된 FPN을 적용하여 CLIP의 global한 descriptor를 세분화하고, task에 편향되는 것을 막기 위해 FPN을 학습시켜 프롬프트에 대응되는 물체의 이진 마스크를 추정하도록 하였습니다. 학습에는 직접적으로 픽셀 수준의 action-affordance 정보를 이용하지 않고 CLIP의 global 수준의 이해를 픽셀 수준의 임베딩으로 전달하도록 파이프라인을 설계하였습니다. 저자들은 실험을 통해 기존 연구와 비교하여 경쟁력 있는 성능을 달성하였으며, action-object 쌍을 학습하기 위한 지도학습이 필요하지 않고, open-vocabulary에서 작동 가능하며, 기존 방식대비 학습가능한 파라미터가 매우 적다는 것을 보였습니다.
해당 논문의 contribution을 정리하면
- affordance segmentation에서 명시적인 방식을 사용하지 않고 문제를 학습 가능함을 입증하였으며
- 대규모 데이터로 사전학습된 Vision-Language models가 action 프롬프트를 다룰 수 있음을 보였으며
- CLIP의 Global descriptor를 미세조정 없이 dense task에 적용하기 위해 language와의 align을 유지하면서 multi-scale에서 feature를 추출할 수 있는 경량화된 FPN을 제안합니다.
Method
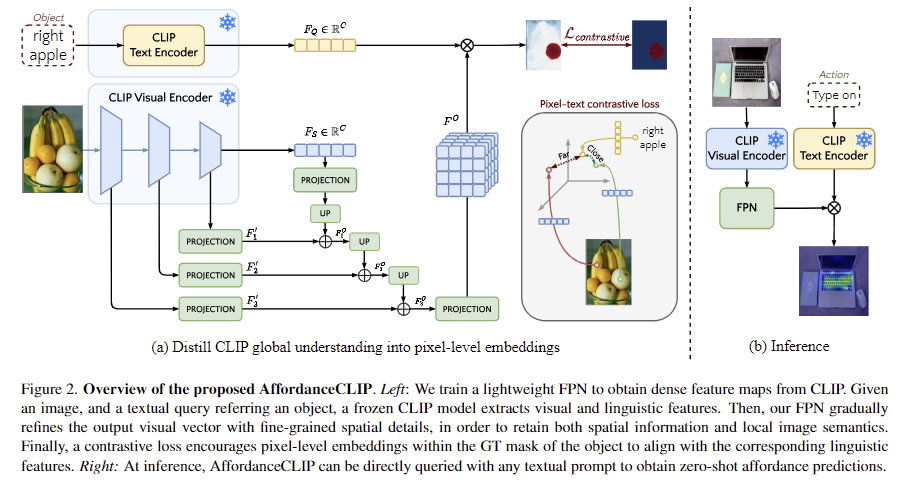
해당 논문은 이미지 속 객체의 affordance를 인식하기 위해 사전학습된 멀티모달 모델인 CLIP의 잠재력을 검증합니다. 저자들이 제안한 프레임워크는 사전학습된 CLIP의 image-language alignment를 활용하여 대응되는 영역을 찾는 것으로, CLIP 모델을 frozen하여 시각 feature와 language feature를 추출합니다. 이때 visusal encoder는 최종적으로 text와 대응되는 global feature를 추출하게되므로, local한 정보를 얻기 위해 encoder의 중간 feature를 사용하며, 공간적 정보를 복구하기 위해 multi scale의 feature에 대해 FPN 적용합니다. FPN은 공간적 디테일을 global feature에 통합하여 물체의 공간적 정보를 얻을 수 있도록 합니다. 마지막으로 CLIP의 학습 방식으로부터 영감을 받아 contrastive learning을 도입하여 픽셀 수준의 추론이 가능하도록 합니다. 이러한 프레임워크는 위의 Figure 2에서 확인하실 수 있으며, 이제 좀 더 자세히 살펴보겠습니다.
1. Feature extraction
feature를 추출하는 과정을 사전학습된 CLIP을 사용하여 시각-언어 정보가 align된 representation을 추출합니다.
< Image Encoder >
입력 이미지 I \in \mathbb{R}^{H⨉W⨉3}가 주어졌을 때, CLIP의 frozen된 ResNet-101를 통해 feature vector F_S \in \mathbb{R}^{C}를 얻으며, 이때 C는 CLIP의 output 차원을 의미합니다. 이렇게 추출된 feature vector는 이미지의 특징이 압축된 정보로, 저자들은 encoder의 중간 feature들을 계층적으로 추출하여 이용합니다. 중간 feature들은 F_3 \in \mathbb{R}^{{{H}\over{8}}⨉{{W}\over{8}}⨉{C_1}}, F_2 \in \mathbb{R}^{{{H}\over{16}}⨉{{W}\over{16}}⨉{C_2}}, F_1 \in \mathbb{R}^{{{H}\over{32}}⨉{{W}\over{32}}⨉{C_3}}로, C_i는 i번째 stage의 feature의 채널 수를 의미합니다.
< Text Encoder >
text query t가 주어졌을 때 토큰화된 표현 T \in \mathbb{R}^L을 추출합니다. 여기서 L은 length이며, BPE 방식으로 49152개의 단어에 대해 토근화가 이루어진 뒤, global token인 [CLS]와 end 토큰인 [EOS]가 추가됩니다. 이후 Transformer 모델을 통해 각 토큰에 대한 feature F_i \in \mathbb{R}^{L⨉C}를 추출합니다. 최종적으로 Transformer의 global context를 나타내는 text representation F_Q \in \mathbb{R}^C를 얻습니다.
2. Recovering spatial details
해당 파트는 앞서 image encoder에서 구한 visual feature vector F_S 는 global한 정보를 포함하고있어, segmentation을 위한 세분화된 정보를 얻기 위한 과정입니다. 픽셀 수준의 정보를 추정하기 위해 FPN을 적용하여, 저해상도로 인코딩되는 고수준의 feature인 F_S 에 시각적 특성을 유지한 F_1, F_2, F_3를 통합하는 것으로, F_S 에서부터 점차 고해상도의 정보를 융합하는 방식입니다.
서로 다른 차원의 feature를 융합하기 위해 먼저 visual feature들을 C’ 차원으로 투영하여 F'_S, F'_1, F'_2, F'_3를 만든 뒤, F'_S를 upsapling한 뒤 F'_1와 융합하여 F_1^O를 구하고 이후 F_{i-1}^O를 upsampling하고 다시 F'_i와 융합합니다.
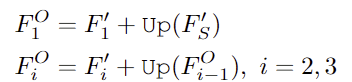
최종적으로 융합된 F_3^O을 C’에서 C 공간으로 투영시켜 최종 feature F^O \in \mathbb{R}^{{{H}\over{8}}⨉{{W}\over{8}}⨉C}를 얻습니다.
3. Affordance Head
CLIP의 visual-text alignment를 유지하기 위해 CLIP을 frozen 시켜 global descriptor를 생성하지만 FPN을 통해 local한 정보를 복원한 features F^O를 얻을 수 있도록 하였으며, F^O와 F_Q 사이에 행렬 곱을 하여 activation map Y_{pred} \in \mathbb{R}^{H⨉W}를 구합니다.
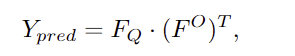
4. Pixel-Text Contrastive Training
CLIP은 positive인 이미지와 text 사이의 거리를 최소화하면서 batch안의 negative인 이미지들과는 멀어지도록 학습을 수행합니다. 해당 task에서는 픽셀 수준의 정보를 추정할 수 있도록 학습하기 위해 pixel-text contrastive loss를 적용합니다. 해당 loss는 referring image segmentation 연구(주어진 text 프롬프트에 해당하는 영역을 segmentation하는 연구로, affordance는 기능적/상호작용적 측면에서의 이해가 요구된다는 점에서 차이가 있습니다..)에서 제안된 것으로, 0은 negative ,1은 positive를 의미하며, 픽셀 수준에서 아래의 식을 통해 학습이 진행됩니다.
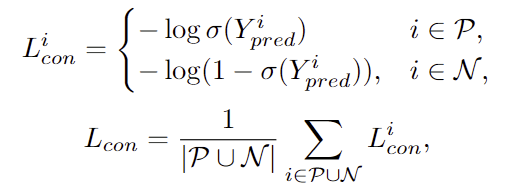
- \sigma: 시그모이드 함수
- |\mathcal{P} ⋃ \mathcal{N} |: negative와 positive 요소의 개수
해당 loss를 보면 Positive는 활성화될수록 loss가 작아지고, negative는 활성화되지 않을수록 loss가 작아지도록 설계가 된 함수입니다.
Experiments
Datasets
Affordance grounding에서 주로 사용하는 AGD20K 데이터셋에서 평가를 수행하며, affordance 정보가 포함된 어떠한 데이터로도 학습을 수행하지 않았다고 합니다. 대신, global한 feature를 추출하는 CLIP으로부터 dense prediction을 수행하기 위해 FPN을 학습해야하며, 이를 위해 RefCOCO/+/g dataset만 이용하였다고 합니다. 해당 데이터 셋은 referring image segmentation 분야에서 사용하는 데이터로, 초록색이 target일 때 이에 대한 설명과 segmentation mask가 주어집니다. 이때 설명은 affordance를 고려하지 않습니다.
< AGD20K >
평가에 사용된 AGD20K는 exocentric한(사람이 물체와 상호작용하는 이미지) 20,061장의 이미지와 egocentric한 이미지(객체만 주어진 이미지) 3,755장으로 구성됩니다. 해당 데이터 셋은 36개의 affordance 카테고리가 있으며, Seen과 Unseen 세팅으로 구분되어있습니다. Unseen에는 Seen에 존재하지 않는 새로운 카테고리가 포함되어있으나, 해당 논문은 AGD20K를 아예 사용하지 않았으므로 둘 다 Unseen이라 할 수 있습니다. 따라서 Seen을 Test A, Unseen을 Test B라 표현으 수정합니다.
< RefCOCO/RefCOCO+/RefCOCOg >

해당 데이터 셋의 예시로 이미지를 가져와 보았습니다. RefCOCO는 평균 3.6개의 단어로이루어진 짧은 설명으로 이루어지며, RefCOCO+는 위치 정보를 제외하고 외관에 대한 묘사에 집중한 버전이며, RefCOCOg는 평균 8.4개의 단어로 이루어진 더 복잡한 표현을 사용합니다.
Evaluation metrics
평가지표는 기존 Affordance Grounding에서 사용하던 Kullback-Leibler Divergence (KLD), Similarity (SIM), Normalized Scanpath Saliency (NSS)를 사용합니다. 해당 지표들은 GT와 예측된 분포 사이가 유사한지를 측정하는 것으로, 이에 대한 자세한 설명은 제가 이전에 작성한 X-Review를 참고해주세요.
Results
1. Comparison with State-of-the-art
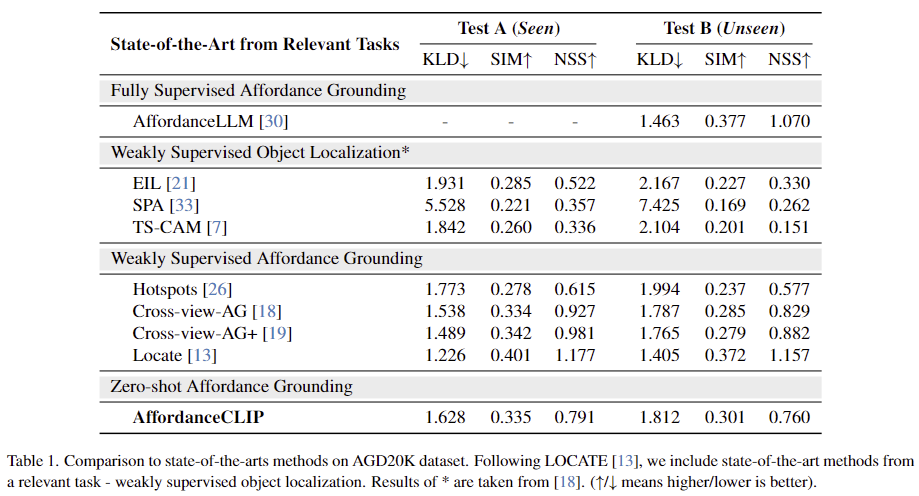
비교를 위해 supervised 방식과 weakly supervised 방식을 함께 비교하였습니다. 실험 결과 AffordanceCLIP이 뛰어난 성능을 보이지는 않지만 경쟁력 있는 성능을 달성하였습니다. 무엇보다도 Affordance 정보를 학습에 사용하지 않았음에도 어느정도 작동한다는 점에서 의미가 있는 것 같습니다.
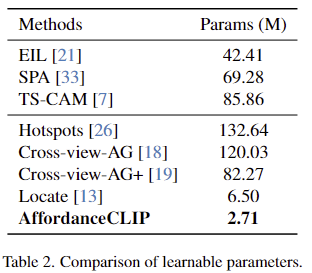
또한, 저자들은 학습되는 파라미터가 다른 방법론과 비교했을 때 크게 줄어들었다는 것을 Table 2에서 확인할 수 있으며. 이를 통해 효율적으로 학습이 가능함을 어필합니다.
2. Ablation study
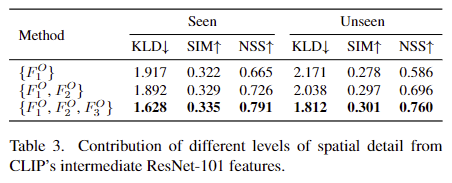
저자들은 local한 정보를 복구하기 위해 ResNet-101의 중간 feature를 사용하였으며, 이에 대한 ablation study를 진행하였습니다. Table 3을 보면 점차 고해상도의 feature를 융합함에 따라 성능이 개선됨을 보였습니다.(해당 표는 왜 Seen과 Unseen으로 썼는 지 모르겠습니다.. ) 저자들은 이를 통해 CLIP의 중간 feature들이 affordance에 대하여 유의미한 정보가 포함되어있다는 것을 어필합니다.
3. Qualitative results
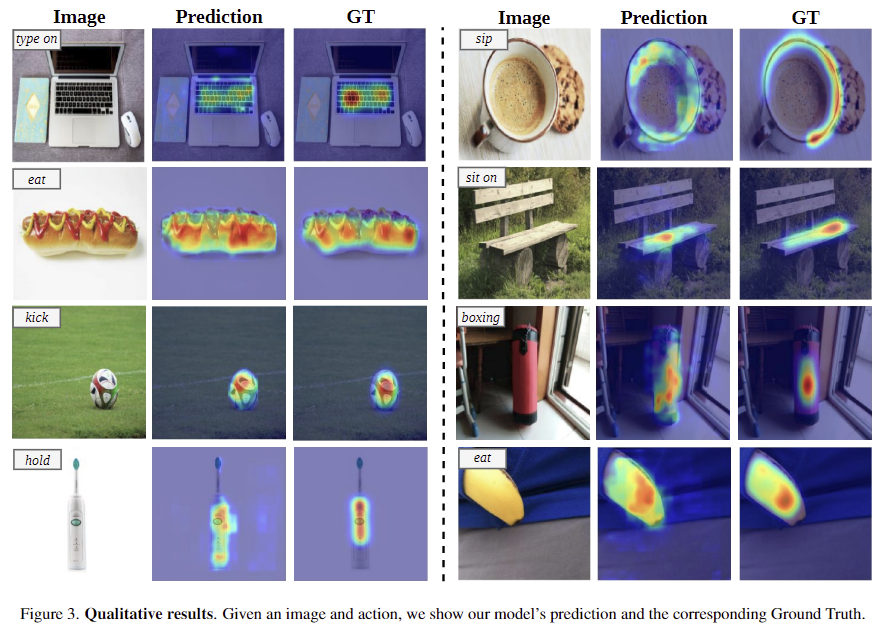
Figure 3은 정성적 실험 결과로, 이미지에서 시각적으로 유사하거나 맥락적으로 연관이 있는 물체를 구분하였으며, query에 대응되는 affordance의 특정 영역을 식별하는 것을 확인할 수 있습니다. type on이라는 affordance가 query로 들어왔을 때, 해당 방법론은 여러 객체 를 구분하여 type on의 대상이 되는 물체를 찾았으며, 그 안에서도 자판 영역을 구분하고 있습니다.
4. Open-Vocabulary capabilities
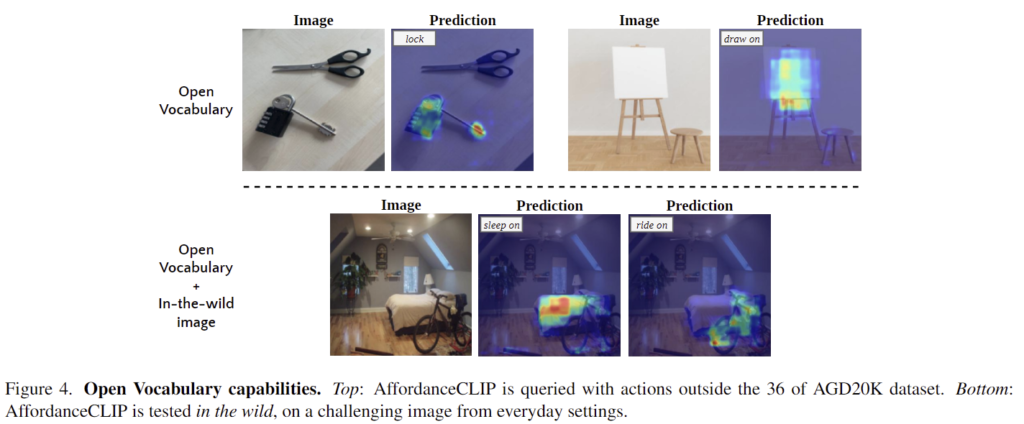
위의 Figure 4는 open-vocabulary에 대한 정성적 결과로 인터넷데이터에 대한 시각화 결과입니다. lock과 draw 등의 affordance가 주어지더라도 유의미한 영역에 잘 활성화가 되는 것을 확인할 수 있습니다.
5. Limitations

위의 Figure 5는 failure cases로, 흥미로운 게 write에 대해 예측은 연필의 끝 주변이 활성화되었는데, 이에 대해 저자들은 CLIP이 write이라는 개념에 대해 사람이 조작하기 위한 물체 영역이 아니라, 물체가 write을 하기 위해 연관된 영역에 집중을 하였다고 분석합니다. 또한, ride에 대한 예측 결과 안장이 아니라 자전거 전 영역을 나타내며, 이에 대해서는 CLIP이 학습에 사용한 데이터는 사람이 자전거를 타고있어 안장을 잘 보지 못했을 수 있다고 분석하였습니다.
해당 논문은 방법론 자체는 굉장히 단순하지만, CLIP이 affordance에 대한 지식을 내포하고있는지에 대해 실험적으로 검증하였다는 점에서 컨트리뷰션이 어느정도 인정 받은 것 같습니다.
안녕하세요, 좋은 리뷰 감사합니다.
제가 다른 affordance 관련 논문이 학습하는 방식을 잘 몰라서 그럴 수도 있지만,
해당 논문에서 CLIP 의 이미지와 텍스트 인코더를 그대로 사용한 것이 어떻게 affordance가 inference에 들어갔을 때 작동을 하는 지 잘 이해가 되진 않습니다 ㅎㅎ ..
학습에서 텍스트 인코더에도 액션에 대한 텍스트가 아니라 물체에 대한 텍스트 정보가 들어가는 것일까요 ?
그렇다면 VLM 학습 방식 그대로를 사용하는게 affordance에도 효과가 있다는 것은 정말 저자의 가정이었고 실험을 해보니 실제로도 그랬다라고 이해하는게 맞을지 궁금합니다 ..
감사합니다.
질문 감사합니다.
입력으로 들어오는 단어가 단순 apple이라기보다 right apple과 같이 설명 묘사하는 표현이 들어가다보니 이를 어느정도 이해할 수 있도록 학습된 것으로 보입니다.
< RefCOCO/RefCOCO+/RefCOCOg > 데이터 셋의 예시 이미지를 보시면, 학습에 사용한 데이터 셋인 RefCOCOg 예시에, 이미지 뿐만 아니라 “a baseball player swings a blue bat”라는 텍스트가 대응되는 데, 이처럼 action 정보를 포함한 데이터를 학습에 활용하였기 때문이라 생각합니다.
안녕하세요 승현님, 좋은 리뷰 감사합니다.
과거 승현님께서 리뷰하신 AffordanceLLM을 지나가면서 읽었던 터라(댓글은 달지 못하였지만,,ㅎㅎ…) 해당 AffordanceCLIP 논문의 CLIP의 사전지식을 이용한 zero-shot 방법이 꽤나 흥미롭게 다가왔습니다.
그러나 승현님께서 마지막 문단에서 언급하시듯 failure case로 CLIP이 연필에 대한 write 부분을 연필심 부분으로 잡아낸다는 것이 물체가 write을 하기 위해 연관된 영역에 CLIP이 집중을 하였던 것이라고 저자들의 분석내용을 담아주셨는데, 사실 이렇게 되면 CLIP 자체의 bias 문제를 간과할 수 없었다는 의미가 되는데, 혹시 CLIP외의 다른 LVLM 모델(GLIP, LLaVA 등)의 인코더나 MLLM(GPT4V, GPT4o 등)의 prompting으로 바꾸어 zero-shot 실험을 진행해볼 수 있게 된다면 유의미한 결과가 생길 수 있을까요? 승현님의 생각이 궁금합니다!
좋은 질문 감사합니다.
이야기하신 것 처럼, CLIP의 bias가 영향을 줄 것이라 생각합니다. 더 고도화된 모델을 이용하여 접근하면 zero-shot으로 유의미한 결과를 얻을 수 있을 것이라 생각합니다. 이후 연구들도 LLaVA등의 모델을 상당수 사용하는 것으로 보입니다.
좋은 리뷰 감사합니다.
제가 이해한 바로는 해당 논문이 CLIP이 물체간의 상호작용 지식을 충분히 학습하였음을 밝히고 특히 multi scale feature를 통해 물체의 세부 영역에 대한 표현력을 개선시에 해당 테스크에 유의미함을 보인것이 컨트리뷰션인것 같습니다.
소개해주신 해당 논문의 Limitation을 보면 write 예제에서 연필 심을 activation 하였는데, 이것이 종이-연필의 상호작용과 사람-연필의 상호작용을 헷갈린것 같은데요, write라는 동사가 사람-연필 상호작용 보다는 사람-종이 상호작용에 많이 사용되는것이 이유가 아닐까 합니다 (예를 들어, human is writing with the pen 보다는 human write on the paper, human grip the pen를 주로 사용하지 않나 싶습니다)
즉, 해당 limitation을 text 모달리티에 과적합함으로서 생긴 문제로 이해해도 되는지 궁금합니다.
질문 감사합니다.
이야기해주신대로, “write”에 대하여 사람과 연필의 상호작용보다는 “write”에 대한 연필과 종이의 상호작용을 많이 학습한 것으로 분석합니다. text 모달리티에 대한 과적합보다는, 사용한 CLIP모델의 bias에 의한 문제로 보는 것이 더 적절할 것 같습니다..!
안녕하세요 승현님! 좋은 리뷰 감사합니다!
제가 지식이 부족한 터이라 해당 논문의 컨트리뷰션을 완변하게 이해하지 못한 것 같습니다.
그래도 중간에 부분적으로 궁금했던 부분이 있어서 댓글 드립니다!
FPN을 통한 Spatial Detail 복원을 하였다고 나와있는데, FPN 구조 외에도 attention이나 transformer기반 네트워크를 사용하면 FPN보다는 CLIP의 alignment를 더 잘 보존할 수 있었지 않을까 생각이 들었습니다!
여기서 FPN을 사용한 이유는 단지 파라미터 수 측면에서 좀더 효율적이기 때문에 사용한 것 인지 혹은 추가적인 이점이 있어서 사용한 것인지 궁금합니다! (단지 가볍기 때문에 사용한 것인지 궁금합니다! )
감사합니다!
질문 감사합니다.
이야기하신대로 attention이나 transformer를 사용하는 방식도 가능할 것 같습니다. 일단 해당 논문은 학습에 사용되는 파라미터가 크게 줄었다는 점을 어필하고있어, 효율성 측면에서 FPN을 적용한 것을 보입니다.