
이번 리뷰 논문은 관절형(articulated) 객체를 이해하고 3차원 재구성을 코드 레벨로 구축이 가능한 기법을 제안한 논문입니다. open review인 ICLR에서 accept을 받은 것으로 확인됩니다.
최근 실제 세계의 객체들을 구조와 3차원적으로 이해하고 이를 시뮬레이터 공간에 올리는 방법에 대해서 깊이 강구하고 있던 와중에 발견한 논문입니다.
간단하게 설명하자면 영상 기반으로 촬영된 객체를 최신 feature matching 기법인 Dus3tr를 이용해 3차원으로 재구성을 수행하고 객체의 부품들을 이해하기 위해서 SAM을 이용합니다. 이렇게 구분된 정보들은 저자가 제안하는 구성을 통해 프롬프팅 되어져 Multi-modal LLM의 입력되어집니다. 이때 LLM은 풍부한 지식을 통해서 객체의 관절형 구조를 해석하고 해당 구조를 코드 레벨로 구성하여 시뮬레이터 공간에서 실제 객체의 움직임을 모사 가능한 결과물을 보여줍니다.
Intro
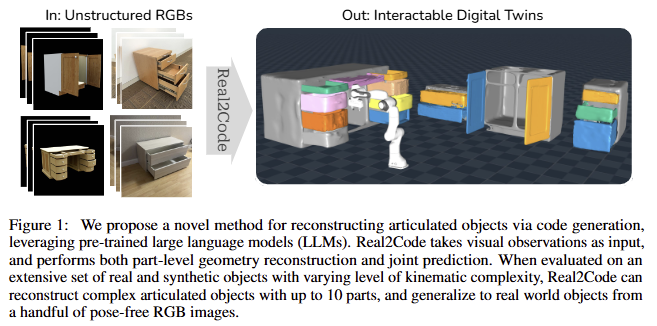
실제 환경의 물체를 시뮬레이션 환경으로 재구성하는 real-to-sim 기술은 VR/AR 경험을 위한 asset 생성 자동화, 실제 환경에서 실행하기 전에 시뮬레이션에서 상호 작용을 검증할 수 있도록 하는 embodied agents, data-driven policy learning을 지원하는 대규모 시뮬레이션 환경 구축 등 다양한 다운스트림 애플리케이션에 사용될 수 있습니다. 특히 최근 가정 및 산업 환경에서는 single-body rigid objects 뿐만 아니라 articulated object에 대해서도 극복하기 위한 움직이 있습니다. 관절형 객체는 여러 개의 부품으로 구성되며, 이러한 부품들은 서로 연결되어 움직일 수 있습니다. 이러한 객체는 주변 환경에서 흔히 볼 수 있으며, 의자, 테이블, 캐비닛, 문, 서랍과 같은 가구에서부터 로봇 팔, 드론, 자동차와 같은 복잡한 기계에 이르기까지 다양합니다. 관절형 객체의 작동 방식을 이해하는 것은 로봇 공학, 컴퓨터 그래픽스, 애니메이션, 인공 지능 분야에서 중요한 역할을 합니다. 예를 들어, 로봇이 관절형 객체를 조작하려면 객체의 구조와 움직임을 정확하게 파악해야 합니다.
관절형 객체를 재구성하기 위해 이전의 학습 기반 방법은 일반적으로 단순한 관절 구조(즉, 객체당 하나 또는 두 개의 움직이는 부품)를 가진 객체에 대해 지도 학습 또는 test-time-optimized을 이용하여 모델을 훈련했습니다. 이러한 학습 방식들은 더 복잡한 외관과 관절 구조를 가진 객체에 대한 일반화 능력을 제한 시키는 요소가 됩니다. 혹은 객체 부품 재구성만 제공하는 방식을 이용합니다. 또한, 재구성된 메시들의 예측된 관절 매개변수는 시뮬레이션에 사용하기 전에 수동 정리해야만 하는 단점이 존재합니다.
저자가 제안하는 Real2Code는 위의 한계를 해결하기 위해 객체 관절을 코드 레벨로 표현한 언어 모델링을 사용하여 시각적으로 추론된 정보를 코드 레벨의 시뮬레이션 정보로 예측하는 새로운 접근 방식을 제시합니다. 해당 방식은 객체의 구조적 복잡성에 이전 연구 대비 유연하게 동작 가능하다는 장점을 가집니다. 여러 관절이 있는 관절형 객체를 처리하기 위해 이전 방법에서는 관절 예측 모델의 출력 차원을 변경하거나 상호 작용 관찰 전후의 쌍에 대해 여러 번 추론을 실행하여 한 번에 하나의 관절을 예측해야 했습니다. 이와 반대로 저자가 제안하는 기법은 언어 모델링에서 next-token prediction을 사용하면 임의 길이의 출력을 생성할 수 있습니다. 즉, 객체 관절 수가 다양하더라도 모델 아키텍처를 조정할 필요가 없다는 장점을 가집니다. 또한 shape programs에 대한 이전 연구에서는 task-specific code syntax을 정의해야 했지만 Real2Code는 사전 훈련된 대규모 언어 모델(LLM)의 code generation 능력을 이용하여 Python으로 알아서 시뮬레이션 공간에 객체를 나타낼 수 있습니다.
기존 텍스트로만 사전 훈련된 LLM은 공간 기하학 정보 추론에 적합하지 않습니다. 저자는 해당 문제를 해결하기 위해서 방향이 지정된 Oriented Bounding Boxes (OBB)를 관절형 객체를 관찰하기 위한 요약된 정보로 활용할 것을 제안합니다. 먼저, 2D segmentation과 3D shape completion model을 활용하여 part-level segmentation and reconstruction을 수행합니다. 그런 다음 재구성된 객체 부품에서 OBB를 추출하고 이를 LLM에 대한 입력으로 사용합니다. 해당 정보를 토대로 LLM은 관절을 선택하기 위해 가장 가까운 OBB 회전 축과 box의 가장자리를 선택하여 관절을 분류 문제로 예측할 수 있게 됩니다.
비정형적인 실제 환경에서는 정확하고 정돈된 깊이 및 영상 정보를 얻기 어렵다는 문제가 있습니다. 저자는 이를 해결하기 위해 사전 훈련된 dense stereo reconstruction model인 DUSt3R을 파이프라인에 통합합니다. DUSt3R에서 예측한 dense 2D-to-3D point map이 미세 조정된 SAM 모델과 결합하여 view-consistent 3D segmentation을 달성할 수 있음을 보여줍니다. 결과적으로 Real2Code는 카메라 포즈 정보 없이 실제 객체를 촬영한 소수의 RGB 영상만으로도 재구성할 수 있음을 보입니다.
요약하자면, Real2Code의 기여는 다음과 같습니다.
- 소수의 비정형 RGB 이미지에서 관절형 객체를 재구성하는 새로운 접근 방식인 Real2Code를 제시합니다. 관절 예측을 코드 생성 문제로 공식화하고 사전 훈련된 대규모 언어 모델을 이 작업에 특화되도록 조정합니다.
- kinematic-aware view-consistent image segmentation과 학습된 3D shape completion model을 통해 부품 part reconstruction를 해결하여 multi-part real-world objects로 일반화되는 고품질 메시 추출을 생성합니다.
- 정성적 결과는 Real2Code가 articulation estimation 및 part reconstruction 모두에서 SOTA를 달성함을 보입니다. Real2Code는 3개 이상의 부품으로 객체를 정확하게 예측하는 최초의 방법이며 훈련 데이터 셋 외의 최대 10개의 관절형 부품으로 객체를 일반화한 결과를 보입니다.
Method
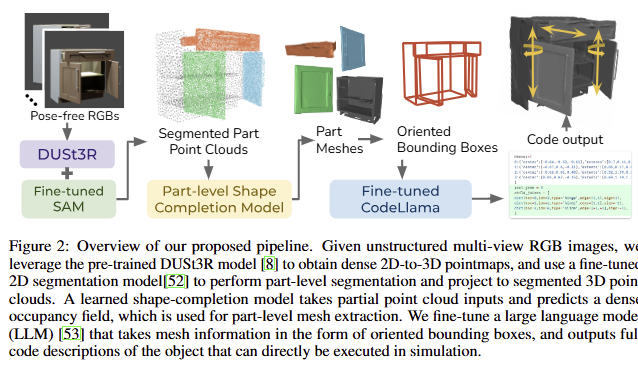
저자는 시각적 관찰에서부터 multi-part articulated object를 재구성하는 문제를 해결하는 것을 목적으로 합니다. 관절형 객체는 관절을 통해 연결된 일련의 rigid-body parts으로 구성됩니다. 여기서, 관절 유형은 prismatic 또는 revolute이라고 가정합니다. prismatic joint은 joint axis u^p \in \mathbb{R}^3 및 translation offset d 로 매개변수화됩니다. revolute joint은 position p^r \in \mathbb{R}^3 , rotation axis u^r \in \mathbb{R} 및 rotation angle \theta 으로 매개변수화됩니다. N개의 움직이는 부품이 있는 객체의 경우 각 부품이 정확히 하나의 1-DoF 관절을 통해 부모에 연결되었다고 가정합니다. 따라서 각 부품의 프레임과 부모 프레임 간의 변환은 관절 매개변수에 의해 고유하게 결정됩니다. 이러한 가정은 OBB 기반 표현 방법에 대한 모티브가 되며, 자세한 내용은 후술하도록 하겠습니다. 또한, 시각적 입력을 얻기 위해 객체가 조작되어 각 관절형 관절이 0이 아닌 상태, 즉 d>0 또는 θ>0에 있고 객체의 영상들이 있다고 가정합니다. 해당 기법은 일련의 3D 메시(객체 각 부품의 재구성)와 코드로 표현된 관절 유형 및 매개변수를 출력합니다. 그런 다음 메시와 관절을 사용하여 시뮬레이션에서 객체의 디지털 트윈을 만들고 다운스트림 애플리케이션을 활성화할 수 있습니다. fig 2는 제안된 방법의 개요를 제공합니다. Real2Code는 reconstruction of object parts’ geometry과 joint estimation via LLM code generation의 두 가지 주요 단계로 구성됩니다. 두 단계 사이에서 객체 부품의 OBB는 LLM이 3D 공간 정보에 대해 추론하고 정확한 관절 매개변수를 예측할 수 있도록 하는 추상화 계층 역할을 합니다.
Part Reconstruction
먼저, 카테고리에 구애받지 않고 임의의 개수의 부품으로 구성된 articulated object를 다룰 수 있는 2D-to-3D 접근 방식을 제안하여 object’s part-level shape geometry를 재구성하는 것을 목적으로 합니다. 먼저 RGB 이미지에서 2D 분할을 생성하고 3D 포인트 클라우드에 투영하는 SAM 모델을 미세 조정합니다. 그런 다음 부분적으로 관찰된 포인트 클라우드에서 watertight meshes를 추출하는 shape completion model을 훈련합니다.
+ watertight meshes는 닫힌 구조의 mesh를 의미합니다.
Kinematics-aware Part Segmentation.
사전 훈련된 2D 분할 모델을 활용하여 먼저 kinematic structure에 따라 articulated object의 부품을 분할합니다. 이러한 설계 방식은 객체에 대한 일반화 및 객체 별 부품이 임의인 점을 확장 가능하게 분할하기 위해 제안하였다고 합니다. 여기서는 SAM을 이용하여 일반화를 가져갑니다. 허나 SAM은 분할 능력은 뛰어나나, 관절 기준의 부품 구분 능력이 떨어지기 때문에 이를 위해서는 사용자의 프롬프트가 필요합니다. 저자는 이러한 문제점을 극복하기 위해서 PartNet-Mobility 데이터셋을 사용하여 사전 훈련된 SAM을 조정할 것을 제안합니다. 모델의 heavy-weight image encoder를 고정된 상태로 유지하면서 SAM의 lightweight prompt-decoder layer를 미세 조정하여 이미지와 하나의 샘플링된 2D 포인트 프롬프트를 입력으로 받아 객체의 운동학적 구조와 일치하는 해당 마스크를 예측합니다.
+ 16개의 point prompts를 원하는 부품을 찾도록 학습을 진행함. 학습 데이터는 28,020장
Test-time Prompting for View-consistent Segmentation
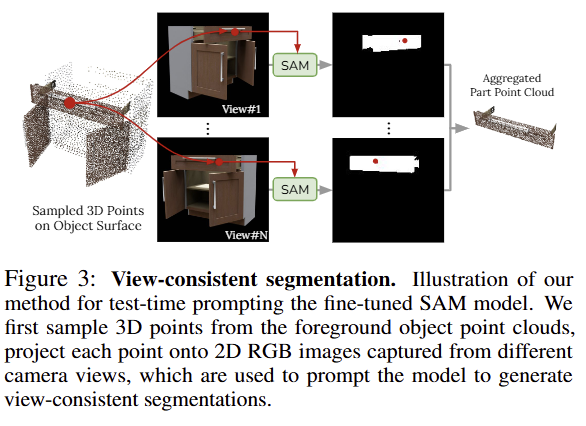
위에서 설명한 point-based segmentation을 사용하면 미세 조정된 SAM이 articulated object의 부품 수에 따라 쉽게 확장할 수 있습니다. 그러나 SAM은 서로 다른 카메라 뷰에서 객체 부품 대응 관계를 인식하지 못하기 때문에 본질적으로 뷰 일관성이 떨어집니다. 이를 해결하기 위해 예측된 2D 마스크를 view-consistent 3D segmentation로 투영하는 test-time prompting를 제안합니다. 깊이 및 영상 입력 설정에 따라 다른 방식을 이용합니다.
- Multi-view RGB-D and Camera Input: 먼저 각 RGB 이미지에서 2D 포인트를 대략적으로 샘플링하고 SAM 모델을 실행하여 배경 마스크를 얻습니다. 이를 통해 서로 다른 뷰에서 전경 객체를 분할하고 포인트 클라우드에서 3D 포인트를 균일하게 샘플링할 수 있습니다. 그런 다음 각 3D 포인트를 각 이미지에 다시 투영하고 SAM 프롬프트에 대해 뷰 일관성 있는 2D 포인트를 얻습니다(fig 3 참고). 또한 confidence and stability scores를 기반으로 모델 예측 마스크의 순위를 지정하고 NMS를 통해 최종 3D 분할을 생성합니다.
- Multi-view Unstructured RGB Input: 실제 세계에서는 고품질의 깊이 및 카메라 정보를 얻기 어려운 상황에 대응하여 multi-view stereo reconstruction model을 이용하여 pose-free RGB에서 part segmetation을 수행합니다. RGB 입력 영상에서 dense 3D point map을 예측하도록 사전 훈련된 DUSt3R 모델을 사용합니다. 그런 다음 하나의 RGB 이미지에서 2D 포인트를 샘플링하고 가장 가까운 이웃을 통해 다른 모든 RGB 이미지에서 각 포인트에 해당하는 포인트를 찾습니다.
+ 3DLF와 동일한 기법
Part-level Shape Completion
articulated object에서 빈번한 self-occlusion으로 인해(예: 서랍 내부가 보이지 않는 경우가 많음) RGB-D 입력은 각 객체 부품을 완전히 관찰하지 못하므로 분할된 포인트 클라우드는 완전한 모양 형상을 만들어 내지 못합니다. 이는 watertight meshes를 얻기 위해 shape completion model을 제안합니다. 이전 단계에서 part-segmentation이 이미 처리되었으므로 여기서는 객체 부품 수준에서 모양 완성을 다룹니다. Convolutional Occupancy Nets를 기반으로 합니다. 모델 아키텍처는 포인트 클라우드 백본으로 PointNet++를 사용했으며, 해당 임베딩을 입력으로 occupancy에 대한 logit을 예측하는 3D Unet encoder와 선형 MLP decoder로 구성했다고 합니다. 저자는 PartNet-Mobility의 실제 부품 메시를 사용하여 부분 포인트 클라우드 입력 및 occupancy가 레이블링된 데이터 셋을 생성하여 학습을 시켰다고 합니다.
+ Convolutional Occupancy Nets을 거의 그대로 사용한 것으로 보임
Articulation Prediction via Code Generation

해당 챕터에서는 부품을 연결하는 관절 구조를 예측하는 것을 목표로 합니다. LLM 코드 생성을 사용하는 이 접근 방식은 몇 가지 이점을 제공한다고 합니다. 첫째, 코드는 관절을 위한 간결한 표현이며 객체의 운동학적 구조의 복잡성에 따라 예측 길이가 달라지는 것을 유연하게 대응 가능합니다. 둘째, 사전 훈련된 LLM에는 객체에 따른 상식적인 사전 지식과 이에 대한 올바른 코드를 생성하기 위한 강력한 사전 학습 능력이 갖춰져 있어 이 작업에 쉽게 적용할 수 있습니다. 마지막으로 LLM에서 생성된 코드는 시뮬레이션에서 직접 실행할 수 있으므로 이전 연구에서 요구하는 예측된 관절 매개변수를 수동으로 정리할 필요가 없다는 장점을 가집니다.
Oriented Bounding Box as Input Abstraction
관절 예측에는 관절 매개변수(예: 위치 및 회전)의 수치적 정밀도와 raw sensory input을 통한 추론이 필요하지만, 텍스트에 대해 사전 학습된 LLM은 이러한 문제에 능력이 부족합니다. 저자는 이를 해결하기 위해 sensory input (object point clouds)을 OBB로 나타냅니다. 각 상자는 segmented되고 completed object part을 나타냅니다. 3D 포인트 클라우드 또는 2D 이미지와 같은 대체 객체 표현과 비교하여 OBB는 compactness(i.e. 추가 기능 인코더가 필요하지 않음)과 preciseness(i.e. numerical 3D pose information) 사이의 균형을 맞춥니다. 또한 OBB는 관절 정보에 대한 정보를 제공하는 역할을 합니다. 객체 부품의 pose는 0이 아닌 상태에서 1-DoF 관절에 의해 결정된다는 것에 따라 관찰된 객체 부품의 변위에서 관절 매개변수를 복구할 수 있습니다. 부모에 연결된 부품의 OBB가 주어지면 관절 유형에 관계없이 관절 축은 OBB 회전 행렬의 세 축 중 하나에 평행합니다. 또한 많은 일반적인 articulated object는 직육면체와 같은 부품(예: 문 또는 랩톱)으로 구성되어 있으므로 해당 회전 관절의 위치는 OBB 가장자리 중 하나에 가깝습니다. 이러한 관찰을 기반으로 OBB 회전 축을 관절 축으로 선택하고 회전 관절의 경우, 축에 평행한 OBB 가장자리를 관절 위치로 선택하여 관절 축 예측 문제를 재구성할 수 있습니다. 이에 대한 내용은 fig 4에서도 확인 가능합니다.
Fine-tuning a Code Generation LLM
이제 regression task(즉, 연속 값 예측)을 LLM에 대한 더 쉬운 classification tas(즉, 축 및 가장자리 선택)으로 효과적으로 변환 가능합니다. 저자는 이를 위해서 사전 학습 모델인 7B-CodeLlama 모델을 사용합니다. PartNet object (위에서 저자가 가공한 데이터 셋)을 사용하여 LLM을 위한 미세 조정 데이터 셋을 구성합니다. 여기서 기본 URDF 파일은 1) 더 컴팩트한 Python 구문이고 2) MuJoCo 물리 시뮬레이션에서 실행할 수 있으며 3) 각 객체의 관절이 해당 부품의 OBB 정보에 따라 할당된 MJCF 코드로 변환됩니다. LLM은 부품 OBB 정보(즉, 중심, 회전 및 반 길이) 목록을 입력으로 받아 관절 예측을 목록으로 출력합니다. 여기서 각 줄에는 OBB의 축과 가장자리에 대한 인덱스가 포함됩니다.
Experiment
Dataset. PartNet-Mobility 데이터 세트의 5가지 범주(Laptop, Box, Refrigerator, Storage-Furniture 및 Table)의 자산을 사용합니다. 467개의 훈련 객체와 35개의 테스트 객체가 이미지 분할, 모양 완성 및 코드 데이터 세트를 구성하는 데 사용됩니다. Blender를 사용하여 각 객체에 대한 RGB-D 및 실측 분할 마스크를 렌더링한 다음 RGB-D 이미지와 마스크를 사용하여 부품 수준 포인트 클라우드를 생성했다고 합니. 코드 데이터의 경우 부품 메시에서 OBB를 추출하고 각 객체의 원시 URDF 파일을 Python MJCF 코드로 처리합니다. 여기서 각 관절의 회전 및 위치는 이 관절이 부모 부품에 연결하는 자식 부품의 OBB를 기준으로 합니다.
3D Part-level Shape Completion.
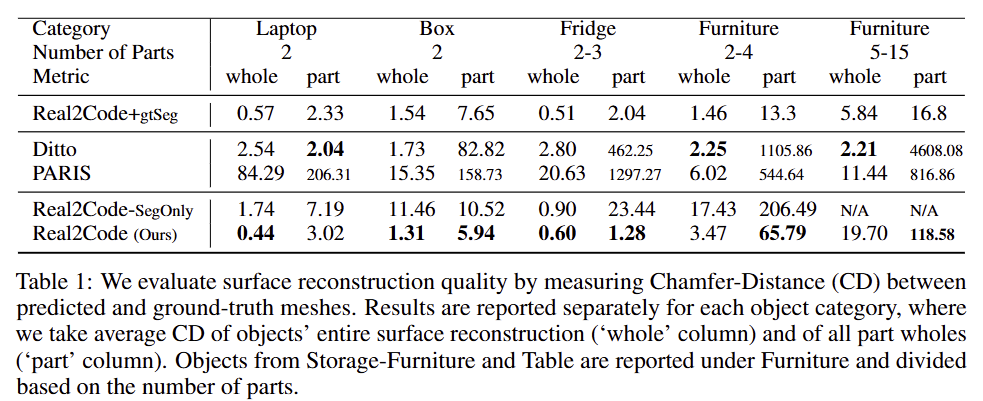
부품 수의 증가에 따라 압도적인 성능 차이를 보여줍니다. 또한 Real2Code-SegOnly 중 N/A의 결과는 세부 부품에 대한 SAM의 표현 민감성에 따라 노이즈가 발생하여 발생한 결과로 shape completion model의 필요성을 보여줍니다.
Articulation Prediction Experiments
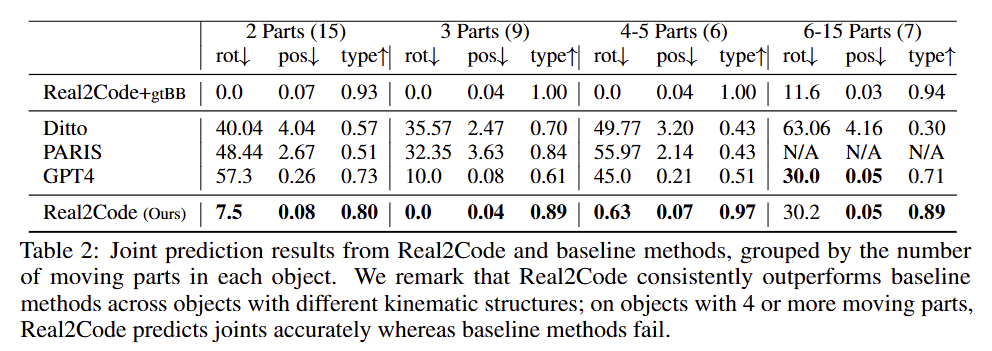
Articulation Prediction에 대한 결과로 tab 2에서 보이는 바와 같이 기존 기법 대비 가장 좋은 성능을 보이는 것을 확인 할 수 있습니다. 여기서 GPT4는 LLM을 저자가 미세 조정한 모델이 아닌 GPT4를 사용한 결과로 복잡도가 올라간 6-15 parts에서는 제안한 기법과 유사한 결과를 보여주지만, 이외의 구성에서는 압도적인 성능 차이를 보여줌에 따라 제안한 기법의 안전성을 보여줍니다.
Qualitative Results
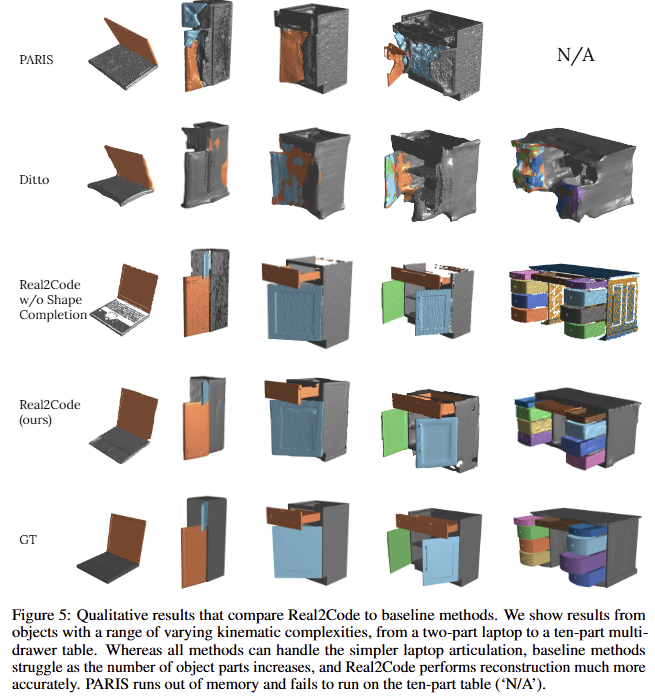
정성적인 결과로, 기존 기법 대비 명확하게 개선된 결과를 보여줍니다.
Ablation Studies

Regression on Joint Parameters. OBB 회전 축과 에지를 선택하는 대신 동일한 입력을 받지만 관절값에 대해 연속적인 수치 값을 출력하도록 두 개의 CodeLlama 모델을 추가로 미세 조정. 첫 번째 모델은 각 조인트 축에 대해 3개의 값을 직접 예측하고(tab 3의 ‘OBB Abs.’), 두 번째 모델은 Real2Code와 동일한 방식으로 조인트 축을 예측하지만 조인트 위치를 OBB의 중심에 대한 상대 위치로 예측(tab 3의 ‘OBB Rel.’).
-> 회귀 방식은 관절 위치를 덜 정확하게 예측합니다. 절대 관절 위치(‘OBB Abs.’ 열)를 예측하는 것과 OBB 중심으로부터 상대 위치를 예측하는 것(‘OBB Rot.’ ) 모두 OBB 가장자리를 joint position을 선택하는 것이 낮은 오차를 가짐. 반대로 rotation error는 명확한 차이는 가지진 않지만, 이는 모델이 입력 프롬프트에 포함된 OBB 회전 행렬에서 올바른 축 열을 복사하는 방법을 학습했기 때문인 것으로 저자는 분석하였고, 이는 공간 표현으로 OBB를 사용하는 것의 효과를 더욱 입증한다고 함.
Provide LLM with Visual Inputs. OBB가 충분한 공간 정보를 제공하는지 확인하기 위해 RGB와 OBB 입력을 활용 가능한 Multi-modal LLM을 미세 조정함. 이미지 임베딩 정보를 CodeLlama 모델 가중치와 인터리빙하기 위해 OpenFlamingo 방식을 채택하고, 이미지 인코더에 사전 학습된 동일한 ViT 가중치를 사용. (tab 3의 ‘+RGB Cls’)
-> ‘+RGB Rel.’ 행과 ‘OBB Rel.’를 비교했을 때, 적은 차이를 기반으로 OBB만 이용했을 때의 장점을 더 뚜렷하게 보인다고 저자는 주장함
Experiments on Real-World Objects

마지막으로 실제 환경에서 추론한 결과물에 대한 예시입니다.
DeepSeek도 그렇고 최근 강화 학습이 크게 떠오르는 것 같습니다. 본래 대가 들이 추측한 방향은 3D로 넘어가는 것이였는데, 이러한 흐름도 최근에는 강화 학습이 중요해지고 있는 것 같습니다. 이러한 기조 상 로봇 쪽에서는 시뮬레이터 데이터가 있어야 학습이 가능하기 때문에 Real-to-Sim이 중요해질 것 같습니다. 그런 흐름 상…. 해당 연구들도 엄청 중요해질 것 같습니다.