안녕하세요, 쉰 번째 X-Review입니다. 이번 논문은 2025년도 ECCV에 게재된 WeCromCL: Weakly Supervised Cross-Modality Contrastive Learning for Transcription-only Supervised Text Spotting 논문입니다. 바로 시작하도록 하겠습니다. ??
1. Introduction
현존하는 text spotting 모델들은 fully-supervised 방식으로 학습되어 오면서 좋은 성능, 발전을 이뤄왔지만 이들은 학습하는데 필요한 annotation인 bbox의 labeling cost가 크다는 단점이 존재합니다. 오늘 리뷰할 논문은 이런 점을 고려하여 오직 transcription만 사용하여 text spotting을 수행하고자 한 논문입니다. 다시 말해 bounding box 정보를 사용하지 않고 text 정보만을 사용하여 annotation cost를 드라마틱하게 줄일 수 있는 방법론을 소개한다고 보면 되겠습니다.
이 Transcription만 사용하여 text spotting을 수행하는 것은 bbox까지 사용하여 학습하는 full supervision보다 훨씬 어렵습니다. 특히 영상 내에서 text transcription의 위치가 어디인지 찾는 것이 관건이겠죠. 기존 transcription만을 사용하여 학습한 모델에는 NPTS가 있는데, 이 NPTS는 text spotting을 text sequence prediction task로 접근한 방법론입니다. 간단하게만 설명드리자면, 한 영상 내에 있는 모든 text instance들을 쭉 이어 붙여서 하나의 sequence로 구성한 후 이를 auto-regressive 방식으로 모든 character들을 찾아 예측하도록 하는 방식이죠. 이 NPTS가 text detection, recognition으로 구성된 spotting 중 text detection을 수행하지 않을 수 있다는 장점이 있긴 하지만 수렴이 오래걸린다는 단점이 있습니다. 아무래도, text instance를 이어붙여 하나의 sequence로 구성하는 과정에서 어떠한 사전에 정해놓은 순서 없이 이어붙인다는 점에서 모델이 학습할 때 모든 가능한 경우의 수를 판단해야 한다는 점이 그의 원인이 될수도 있겠구요. 또 모델이 명시적으로 text instance와 영상에서 그 text가 위치하는 영역간의 매핑을 학습하지 못한다는 점으로 인해서도 수렴이 느리게 됩니다. 즉, annotation cost를 줄이기는 했지만, 컴퓨팅 자원을 엄청나게 소모해야 한다는 것이죠.
본 논문에서는 두 단계로 나눠서 transcription만을 사용하여 text spotting을 수행하는 방식을 소개합니다. 첫 번째로 weakly supervised 방식으로 영상 내에서 각 transcription에 해당하는 anchor point를 검출하구요. 두 번째로 앞 단계에서 얻어진 anchor point를 pseudo location label로써 사용하여 이 single point만을 가지고 text spotter를 학습하는 것입니다.
첫번째 anchor point를 검출하는 과정은 transcription의 위치 gt 없이 수행해야 하기때문에 특히 어려운 과정이겠으며, 동시에 이 detection 성능이 그 다음 단계에서 수행하는 text spotting 성능에도 영향을 미치게 됩니다. 이런 문제를 해결하기 위해 저자는 weakly supervised cross-modality contrastive learning 방식으로 접근하는 방식을 제안하였습니다.
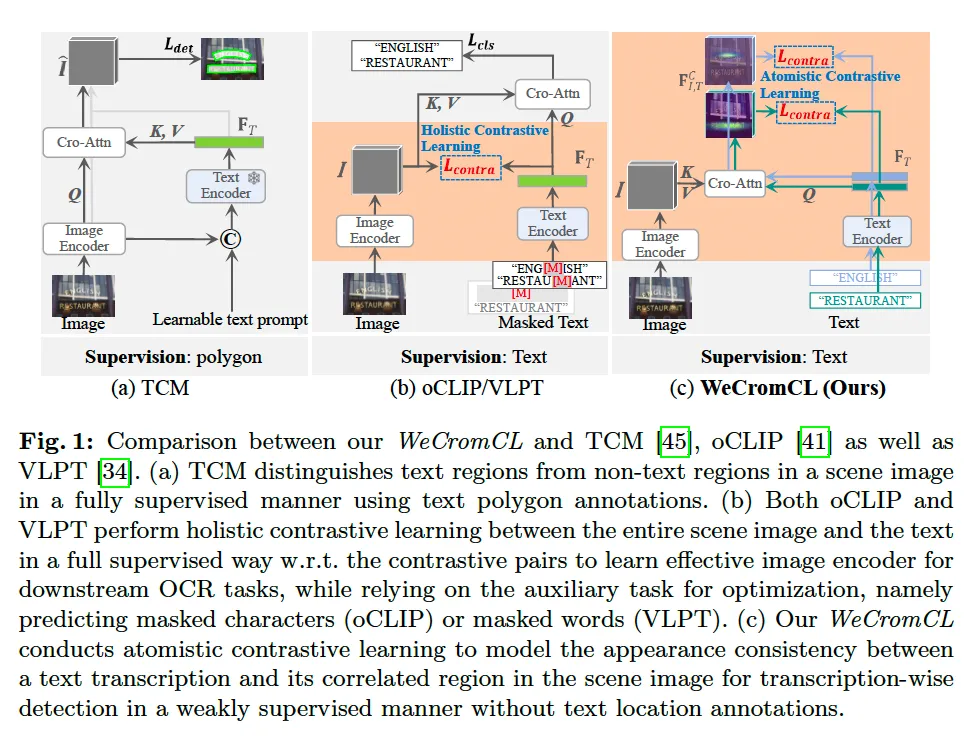
기존에도 text, image간의 cross-modality contrastive learning으로 접근한 방법론이 있었는데요, 위 그림 fig1-(b)의 oCLIP과 VLPT가 그에 해당합니다. 하지만 그림을 보면, 이 기존 방법론들은 전체 이미지와 text 간의 correlation을 모델링하는데 집중한 것을 볼 수 있습니다. 반면에 본 논문에서 제안한 WeCromCL (c)를 보면 text와 그 text에 해당하는 이미지 영역에 대한 correlation을 모델링하는 것을 확인할 수 있습니다. 이에 대한 구체적인 설명은 아래 method 파트에서 하도록 하겠습니다.
2. Method
Transcription의 위치에 대한 annotation없이 text spotting을 수행하는 것은 기존의 detect → recognize 방식을 따르기는 어려워 보입니다. 이를 해결하기 위해 본 논문에서는 두 단계로 나누어 transcription-only spotting을 수행하고자 하였습니다.
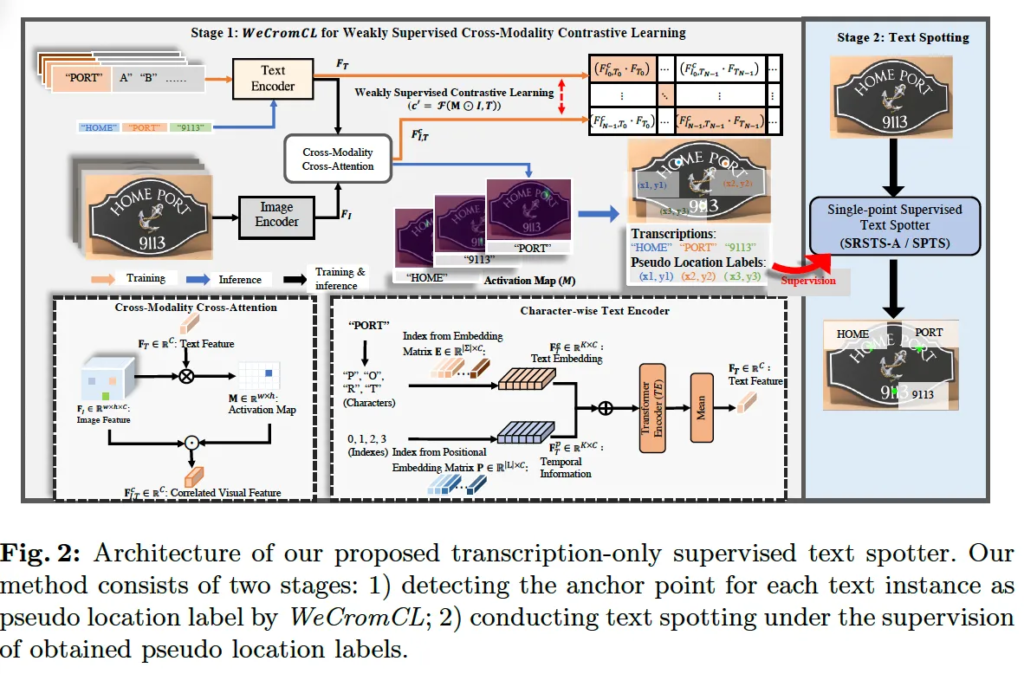
위 그림이 제안된 spotter의 아키텍처 그림인데요, 보시면 stage1이라고 하여 첫번째 단계로 transcription마다 영상 내에서 상응하는 영역을 찾기 위해 anchor point를 검출하는 과정이 존재하고, stage2에서 이를 pseudo location label로 활용하여 single point기반의 text spotting을 학습하는 방식입니다. 즉, bounding box level의 annotation없이도 spotting이 가능하도록 하는 것이 목표인 것이죠.
여기서 핵심은 첫 번째 단계라고 볼 수 있는데요, transcription의 위치에 대한 명확한 annotation이 없는 상태에서 anchor point를 검출해야 하는 것이 어려울 뿐더러 두번째 단계에서 수행하는 spotting의 성능이 이 첫 단계에서 예측되는 anchor point의 정확도에 크게 의존한다는 점도 고려를 해야 합니다. 따라서 본 논문의 저자는 이를 weakly supervised 기반의 atomistic cross-modality contrastive learning 문제로 풀고자 하였고 이를 줄여 본 프레임워크를 WeCromCL이라고 명칭하였습니다.
2.1. Weakly Supervised Atomistic Cross-Modality Contrastive Learning
앞서 intro에서 짧게 언급했듯이 기존 cross-modality contrastive learning 방식인 CLIP이나 oCLIP은 이미지와 text 사이의 전체적으로 얼만큼 관련이 있는지 학습하는 것을 목표로 삼았습니다. 즉, 이미지 I와 text description T간의 relation을 학습한 것이죠. 수식으로는 아래와 같습니다.
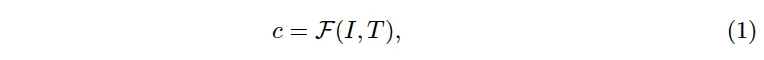
여기서 F는 contrastive learning 모델의 transformation function을 의미합니다. 하지만 이 transcription만 제공되는 text spotting에서는 이 각각의 transcription이 어디에 위치하는지에 대한 annotation이 없기 때문에 이 transcription에 대응하는 위치를 예측하여 pseudo location label로 사용해야 합니다.
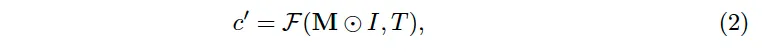
이를 수식으로 표현하면 위 식2와 같은데요, 이미지 I에 포함된 transcription 집합 T가 있을 때 그에 대응된 영상 내 특정 영역간의 relation을 모델링하는 것입니다. 여기서 M은 이미지 I와 같은 크기를 갖는 activation map으로 transcription T에 대응하는 pixel이 activate된 map, 즉 특정 픽셀이 T에 해당하는지 여부를 나타내는 map입니다. 여기서 문제는 M의 GT가 제공되지 않는다는 점으로 이 contrastive learning 모델 F를 weakly supervised 방식으로 최적화하겠다는 결론을 낸 것입니다.
이렇게 식2와 같이 transcription detection 문제를 weakly supervised 기반의 atomistic contrastive learning문제로 정의를 했을 때 아래와 같은 두가지 어려운 점이 존재합니다.
- weakly supervised learning에서의 Activation Map(M)을 추정하는 것
- 기존 contrastive learning과 다르게 atomistic relation(특정 T와 그에 상응하는 영역간의 관계)을 학습하는 것
2.2. WeCromCL
이제 제안된 WeCromCL에 대해 살펴보도록 하겠습니다. WeCromCL은 각 text transcription에 대한 anchor point를 예측하고, 이를 pseudo location label로 사용하여 spotting을 수행합니다. 이 anchor point는 식2의 activation map M을 예측하여 이 중 가장 activated된 영역을 transcription과 연관된 영역으로 보고 이를 anchor point로 지정하게 됩니다.
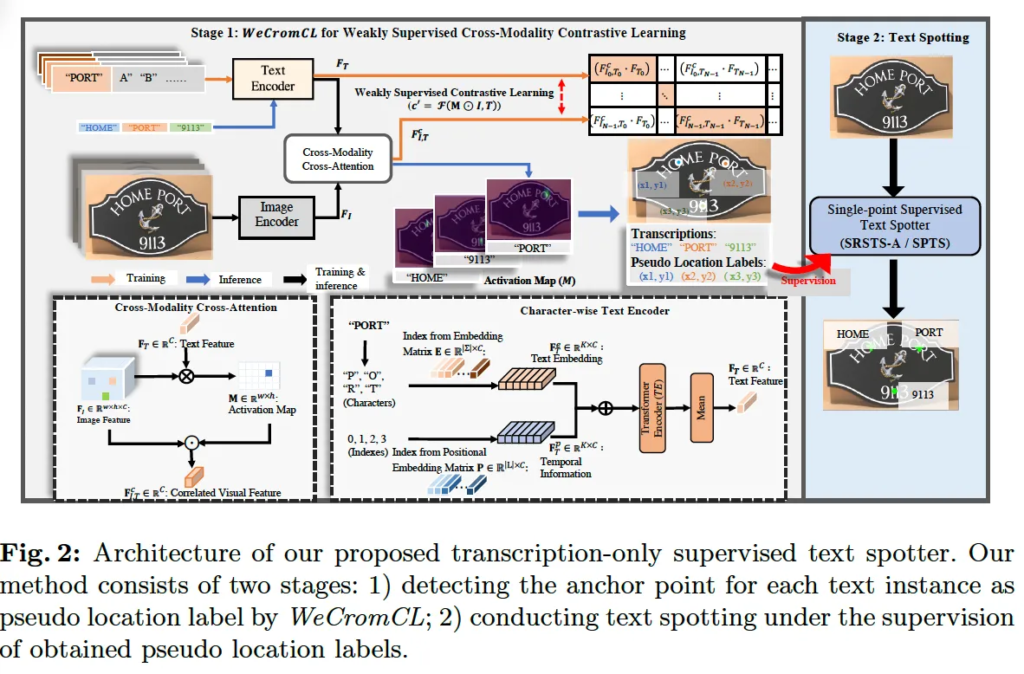
위 그림2에서 볼 수있듯이 WeCromCL은 CLIP과 유사한 구조를 따르는데요, Stage1을 보시면 Image encoder와 Text encoder를 활용하여 이미지와 text transcription에 대한 latent embedding을 학습합니다. 이때 앞에서 언급했던 문제 1인 weakly supervised learning에서의 Activation Map(M)을 추정하는 것을 위하여 soft modeling 방식을 도입하였습니다. 다시 말해 activation map을 학습한느 과정에서 soft modeling방식을 사용해 gt 없이 잘 prediction해보고자 한 것입니다. 또한 두번째 문제인 기존 contrastive learning과 다르게 atomistic relation(특정 T와 그에 상응하는 영역간의 관계)을 학습하는 것 해결을 위해 character-wise text encoder를 설계하엿습니다. 최종적으로 나름의 negative sampling mining 기법을 제안하여 positve, negative pair를 구성한 후 atomistic cross-modality contrastive learning을 수행하도록 하였습니다. 아래에서 각각에 대해 하나씩 살펴보도록 하겠습니다.
Character-Wise Text Encoder.
먼저 character-wise text encoder입니다. 기존 CLIIP과 같은 cross-modality contrastive learning은 이미지와 text간의 전반적인 semantic한 relation을 학습하는데 초점을 맞추고 있었습니다. 이건 text encoder가 입력된 text의 전체적인 의미를 학습하도록 설계되지만, WeCromCL의 경우 transcription과 영상 내에서 해당 text가 위치한 영역 간의 semantic한 relation을 학습하도록 해야합니다. 즉, 이를 위해서 기존 방식과는 달리 transcription을 이루는 개별 character-level로 feature를 추출할 수 있는 text encoder 구조를 설계한 것입니다. 이로써 각 문자를 독립적으로 구별할 수 있는 character별 vector를 학습하는 것이죠.
예를 들어 “home”이라는 transcription이 있을 때 h, o, m, e 각 문자가 vector space에서 고유한 embedding을 갖게 되고 이 h, o, m, e embedding을 순차적으로 배열하면 home transcription을 표현하는 vector가 생성되는 것입니다.
하지만, 이렇게 문자별 vector를 단순 나열하는 것만으로는 transcription 내에서 문자들의 순서 정보를 반영하기는 어렵겠죠. 이를 해결하기 위해 각 문자의 위치를 나타내는 positional embedding을 추가하였습니다. 이렇게 학습된 positional 정보를 기존 character embedding과 더해 최종적으로 각 문자의 의미뿐만 아니라 transcription 내에서의 위치까지 고려한 embedding을 생성합니다.
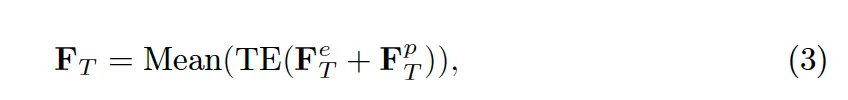
식3에서 F^e_T와 F^p_T에 해당합니다. 이후 Transformer encoder를 태운 후 transcription 내의 embedidng을 평균때려 최종 text feature를 생성합니다.
Soft Modeling of Activation Map by Cross-Modality Cross-Attention.
다음으로는 activation map M을 prediction하는 과정인데요, 이는 앞에서 뽑은 text feature와 image feature를 사용하여 prediction하게 됩니다. 본 논문에서는 soft modeling 방식을 도입하여 map을 생성한다고 했었는데, 이는 간략하게 말해 text와 image feature를 동일한 space로 변환한 다음에 cosine similarity를 기반으로 유사도를 계산하는 식으로 수행됩니다.
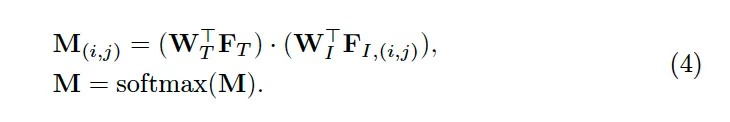
식 4를 보면 이 과정이 나와있는데 두 feature간의 내적을 통해 activation map을 생성하게 되고 이후에 softmax를 태워 binary가 아닌 0~1사이의 연속적인 값을 갖는 map을 뽑은 것입니다.
학습된 map M은 이후에 transcription과 관련된 픽셀 feature를 모아 하나의 representation을 만드는데 사용되는데요, 이는 아래 식5를 참고하시면 됩니다.
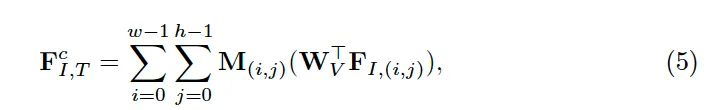
즉, transcription과 관련이 높은 pixel일수록 activation map에서 높은 값을 갖게 되겟고 이런 pixel들의 feature가 더 크게 반영되도록 가중치를 적용하여 F^c_{I, T}를 뽑은 것입니다. 결과적으로 보면 이 과정은 기존 cross-modality cross-attention과 유사하게 동작한다고 볼 수 있는데요. Text Transcription feature F_T는 query, 이미지 feature F_I는 key, value 역할을 하여 요과적으로 transcription이 이미지 내에서 위치하는 영역을 찾도록 학습되는 것입니다.
Cross-Modality Contrastive Learning by Negative-Sample Mining.
다음으로는 contrastive learning을 수행하기 위해 저자가 제안한 negative sampling 방식을 설명드리도록 하겠습니다. 본 논문에서 contrastive loss는 두 가지 방식으로 구성이 되는데요, 첫 번째는 text-to-image 방식으로 특성 transcription T_i와 그에 대한 이미지 I_i를 positive pair로 삼고, pair가 아닌 나머지 영상과 text pair를 negative pair로 설정하였습니다. 두번째는 Image-to-Text 방식으로 특정 image I_i와 그에 대한 transcription T_i를 positive pair로 삼고 다른 transcription들과의 pair를 negative pair로 삼아 이들의 유사도를 줄이는 방향으로 학습하고자 하였습니다.
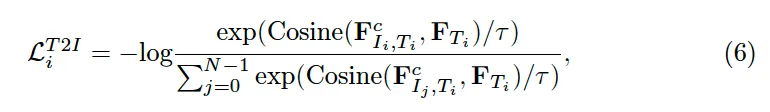
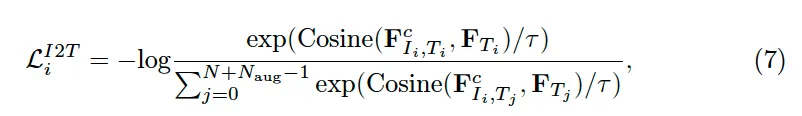
식으로 살펴보자면 위 6, 7과 같은데 식6이 Text-to-image loss이고, 식7이 image-to-text loss입니다. 식7에서 볼 수 있는 N_{aug}같은 경우는 추가적인 negative transcription 개수를 의미하는데 negative pair의 다양성을 증가시키기 위해 추가한 부분입니다. 즉, hard negative mining 같이 모델이 헷갈리는 순으로 negative로 삼는 것처럼 정답 transcription과 유사하여 학습과정에서 헷갈릴 수 있는 transcription에 해당합니다.
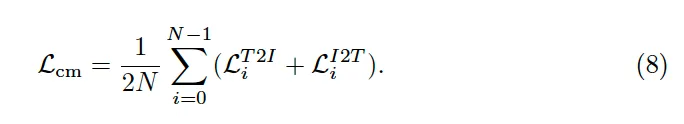
그 다음 두 loss의 평균을 계산하여 최종 loss로 사용함으로써, transcription과 영상 내의 anchor point간의 relation을 학습하게 되는 것이죠.
2.3. Anchor-Guided Text Spotting
이제 두번째 단계인 앞에서 추출한 anchor point를 pseudo location label로 삼아 spotting을 수행하는 부분입니다. 저자는 기존의 모든 single-point기반의 supervised text spotter를 적용할 수 있다고 어필하고 있으며, WeCromCL의 효과를 검증하기 위해 두 가지 방식으로 text spotter를 구현하여 실험을 진행하였습니다.
먼저, 대표적인 single-point supervised text spotter인 SPTS를 적용해보았으며, 이후 SRSTS를 기반으로 transcription-only text spotting을 위한 새로운 single point text spotter를 구성하였습니다.
Instantiation of Text Spotter with SPTS.
먼저 첫 번째 부분입니다. SPTS는 각 transcription에 대해 단 하나의 point만을 location supervision으로 활용하여 text spotting을 수행하는 모델이며, 저자는 WeCromCL이 prediction한 anchor point를 pseudo location label로 사용해 SPTS를 학습하였습니다. 이 SPTS의 text spotting 성능이 곧 WeCromCL의 anchor point prediction 성능을 반영한다고 볼 수 있겠죠.
Instantiation by Adapting SRSTS.
다음으로는 SRSTS기반의 spotter 구현 부분입니다. SRSTS는 원래 text bbox를 사용해 학습하도록 설계된 supervised text spotter인데요. 저자는 이를 single-point기반으로 학습이 가능하도록 수정하여 SRSTS-A라고 명명하였습니다. 이 둘에 대한 성능은 실험에서 살펴보도록 하겠습니다.
4. Experiments
Evaluation Protocol
본 논문에서 제안된 방법론은 transcription과 anchor point만을 prediction하기 때문에 기존의 bounding box의 정확한 예측을 평가하는 fully supervised 기반의 평가 방식은 적합하지 않습니다. 따라서 실험시에 기존 single point 기반의 spotting을 수행한 모델인 SPTS를 참고하여 single-point와 edit distance기반의 평가 지표를 사용하였습니다. single-point metric은 예측된 anchor point를 gt bounding box의 중심점들 중 가장 가까운 점과 매칭한 후, 해당 transcription이 일치하는지를 확인하는 방식이구요. Edit distance metric은 예측된 transcription과 gt transcription 간의 edit distance를 기준으로 매칭을 수행하는 방식인데, edit distance란 하나의 문자열을 다른 문자열로 변환하는데 필요한 최소한의 연산 횟수를 의미합니다. 예를 들어 gt text가 cart인데 cat으로 예측한 경우는 하나의 문자를 추가해야 정답이 될텐데 이 경우는 edit distance가 1이 되겠죠. 아무튼 이는 위치 정보와 무관하게 text 내용이 얼마나 정확하게 인식되었는지를 평가하는데 초점을 맞춘 방식입니다.
4.1. Ablation Studies of WeCromCL
이제 ablation study를 살펴보도록 하겠습니다.
Comparison between different text encoders.
먼저 WeCromCL의 character-wise text encoder와 기존 CLIP의 token 기반의 text encoder를 비교하는 실험입니다. 실험은 WeCromCL의 text encoder를 CLIIP의 text encoder로 대체한 후에 transcription detection 성능을 비교해보았습니다. CLIP text encoder를 사용했을 때 “There is a word ‘transcription’”이라는 prompt를 일관되게 사용했구 여기서 ‘transcription’부분에는 gt text가 들어가게 됩니다.

Table1에 그 결과가 나와있는데요, 보시면 token-wise의 CLIP encoder를 사용했을 경우보다 제안된 character-wise text encoder를 사용했을 경우에 확실히 성능이 더 높은 것을 확인할 수 있습니다. 이로써 전체 text와 image간의 relation을 학습하는 것보다 문자 단위의 correlation을 학습하는 것이 더 효과적임을 입증합니다.
Ablation on the negative-sample mining scheme
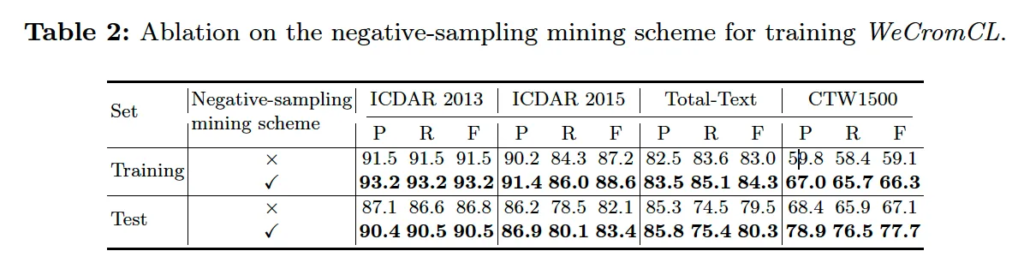
다음으로는 저자가 제안한 negative sample을 선정하는 방식에 대한 ablation study 결과입니다. 이때 negative-sample mining 기법을 적용했을 때와 적용하지 않았을 때의 anchor point detection 성능을 비교한 결과가 표2에 나와있는데요. 봤을 때 앞선 character-wise text encoder보다는 성능차이폭이 대체로 크지는 않지만 그래도 negative sample mining 기법을 적용했을 경우 성능 향상을 보입니다. 다만, CTW1500 데이터셋에서 10% 정도의 성능 향상을 보이는 부분은 흥미로운 점인 것 같습니다.
Atomistic contrastive learning VS. holistic contrastive learning: comparison with oCLIP.
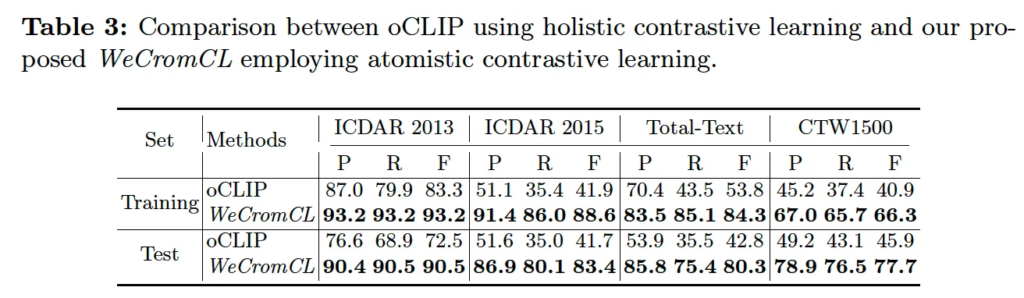
다음은 atomistic contrastive learning과 holistic contrastive learning과의 비교입니다. 즉, oCLIP과 제안된 WeCromCL을 비교한 것인데요, oCLIP은 image encoder를 학습하기 위해 이미지 전체와 그 이미지에 포함된 모든 text 간의 contrastive learning을 수행하는 방법론입니다. 이때 auxililary task를 하나 도입하였는데, 특정 transcription내의 문자를 하나씩 마스킹한 후 이를 prediction하는 식으로 학습하는 것입니다.
무튼, 이 oCLIP과 WeCromCL을 비교하기 위해 oCLIIP을 weakly supervised 방식으로 변형하였습니다. 구체적으로, 예측된 masking된 문자에 대한 attention map을 aggregate한 후에 이 map 중 가장 활성화된 pixel을 픽하여 이 transcription에 대한 location으로 본 방식을 사용하였습니다. 결과는 위 표3에서 확인할 수 있는데, 적게는 18부터 많게는 40에 육박하는 성능 차이를 보임을 확인할 수 있습니다. 다만,, oCLIP의 원래 설계 목적 자체가 WeCromCL과는 근본적으로 다륵게 weakly supervised text detection을 수행하도록 최적화되지 않았기 때문에 compare한 비교로 보기는 살짝 어려워 보이기도 하고, 나름 weakly supervised 방식으로 oCLIP을 개조하기 위해 attention map을 aggregated 하는 방식을 사용했지만 이 임의의 방식이 최적의 모델 성능을 이끌어내지 못하는 구조일수도 있음을 고려하여 실험 결과를 봐주시면 될 것 같습니다.
Enhancing Fully-Supervised Spotting.
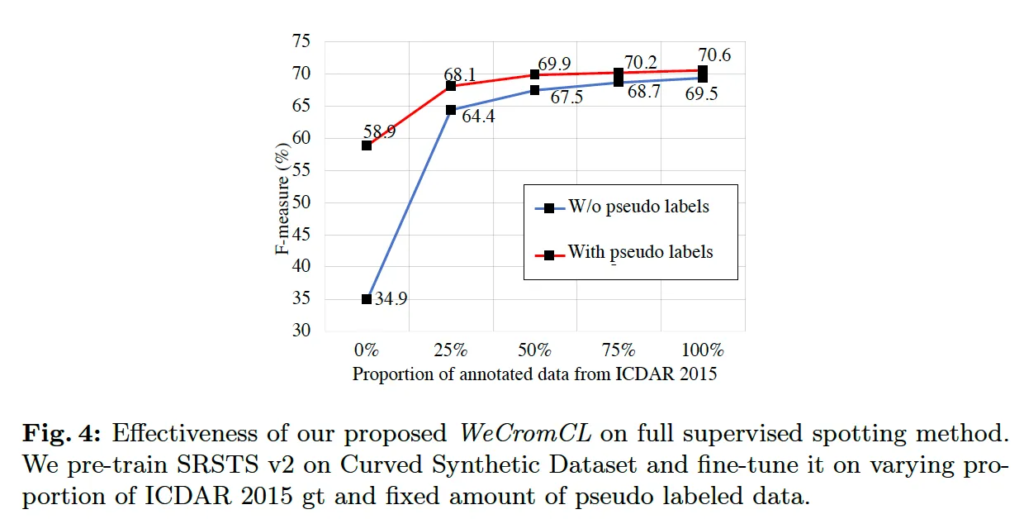
마지막 ablation study입니다. WeCromCL은 annotation cost없이 text-image 쌍에서 pseudo location label을 생성할 수 있었습니다. 이 실험은 이렇게 생성한 pseudo data를 사용한다면 single point 기반의 text spotter의 성능 향상에 기여할 수 있을지에 대한 검증 실험입니다.
이를 수행하기 위해 먼저 MLT, ICDAR2013, Total-Text, TextOCR 데이터셋에 대해 pseudo location label을 생성하였구요, 기존 single point를 기반으로 text recognition을 수행할 수 있는 모델을 사전학습 했습니다. 그 후 ICDAR2015 데이터셋에 대해 fine-tuning할 시 실제 annotation 데이터셋을 점진적으로 증가시키면서 모델을 학습하였구요, 동시에 WeCromCL이 생성한 pseudo label데이터를 일정량 추가하여 성능에 미치는 영향을 확인하였습니다.
실험 결과는 fig4에서 확인할 수 있는데요, 파란색 라인이 pseudo label을 사용하지 않았을 경우이며, 빨간색 라인이 pseudo label을 일정량 추가하며 학습한 경우입니다. 100% gt를 사용했을 경우에 추가로 pseudo label을 사용한 경우 미미한 성능 개선을 보이긴 하지만, 그 전에 0%부터 75% 정도의 데이터만 사용하여 학습했을 경우에 pseudo label을 함께 사용하는 경우가 더 효과적임을 보입니다. 이 과정에서 추가적인 human annotation 비용이 발생하지 않다는 점이 장점으로 볼 수 있겠습니다.
4.2. Transcription-only Supervised Text Spotting
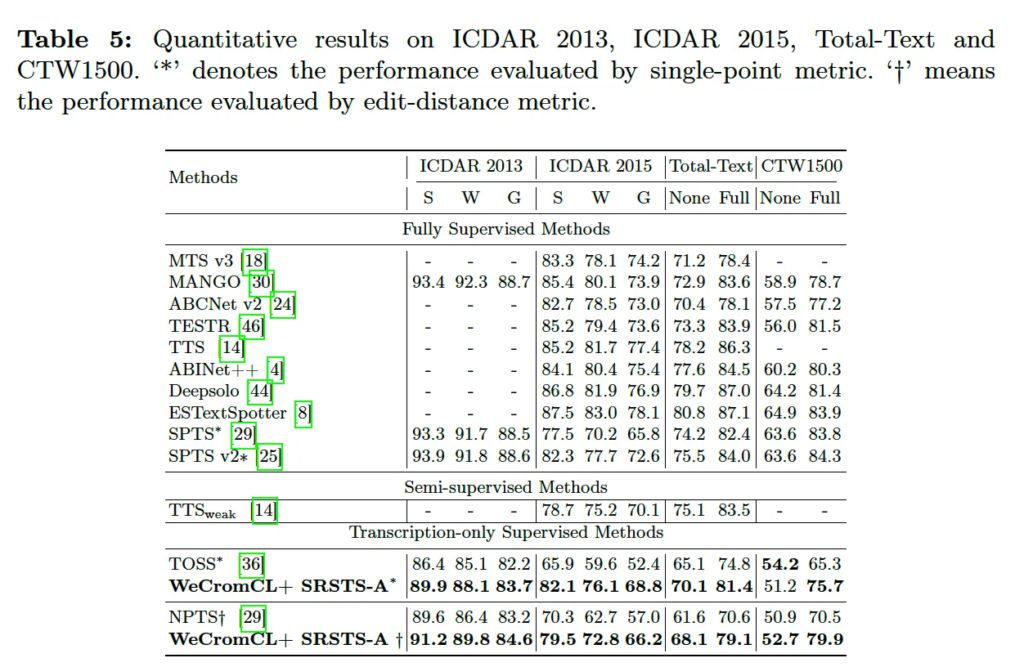
마지막으로 WeCromCL과 SRSTS-A(single point 기반으로 spotter를 수행하는 모델)을 합쳐 transcription-only supervised text spotting 성능을 평가하고 마무리하도록 하겠습니다. 표5에서 결과를 확인할 수 있는데 제안된 방식이 다른 transcription only supervised 모델인 TOSS나 NPTS와 비교했을 때 더 좋은 성능을 보입니다. 특히 ICDAR 2015에서는 NPTS대비 약 16%, TOSS 대비 9% 정도로 꽤나 큰 차이를 보입니다. 물론 fully supervised method 대비 성능이 떨어지기는 합니다. 다만, 중간에 있는 semi supervised method인 TTSweak는 text boundary가 포함되어 있는 fully supervised synthetic data와 transcription이 주어진 real data로 학습된 모델인데, 이 모델과 견줄만한 성능을 보이고 있습니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
리뷰를 봤을 때, oCLIP이라는 모델도 마찬가지로 character-wise text encoder를 사용한 것으로 보이는데, 이 oCLIP에서 사용된 text encoder와 WeCromCL에서 제안된 text encoder의 차이가 존재하나요?
또한 논문에서 negative sample mining 기법에 대한 실험이 존재하나, 단순 이를 적용했을 때와 적용하지 않았을 때의 비교만 하고 있는 것으로 보이는데 이 mining 기법 안에 언급해주신 text-to-image 방식과 image-to-text 방식이 있는 것 같은데 이 각각에 대한 ablation study는 없는건가요?
감사합니다.
리뷰 감사합니다.
1. 넵 oCLIP도 WeCromCL과 마찬가지로 character-wise text encoder를 사용하는데요, 둘의 차이점은 학습 목적에 있다고 보면 되겠습니다. 구체적으로 oCLIP같은 경우는 image와 text가 매칭되는지 학습하는 것이구요(영상 내에 이 단어가 존재하는지 global-level), WeCromCL 같은 경우는 특정 text가 영상 내의 어디에 있는지를 찾는 pixel-level의 매칭이 목적입니다. encoder 구조적인 측면에서도 약간의 차이가 있는데 각 character level의 embedding에다 positional embedding을 더하는 것까지는 동일하지만 WeCromCL에서는 그 이후 transformer encoder를 태워 character간의 관계 (sequence context)를 학습하도록 하였습니다. 그럼 최종적으로 character level 정보에 문맥 정보를 반영한 embedding이 나오게 되겠죠.
2. 넵 논문에서는 text-to-image 방식과 image-to-text 방식을 항상 함께 적용한 경우에 대한 실험 결과만 리포팅되고 있고, 각각에 대한 ablation study는 존재하지 않습니다.
안녕하세요 윤서님, 좋은 리뷰 감사합니다.
activation map을 활용한 anchor-point 생성을 통해, weakly-supervised learning 으로 transcription 을 검출하는 방식이 흥미로웠습니다. 궁금한 점은 해당 방법론이 이미지나 텍스트 데이터가 noisy한 경우, 혹은 text가 매우 오밀조밀하게 뭉쳐있을 땐 잘 작동할 수 있을지 궁금합니다. 또한 한 이미지 안에 동일한 text가 여러번 등장한다거나, 철자 하나만 다르지만 그 생김새가 너무 비슷한 단어들 (예를 들면, adapt/adopt, sea/see)의 경우엔 negative pair로써 구분되기가 상당히 쉽지 않을 것 같다는 생각이 듭니다. 마지막으로 activation map의 특성상 어쩔 땐 딱 text 와 연관된 이미지 내의 좁은 영역을 잘 캐치할 수 있을 지 몰라도, 어쩔 땐 매우 넓은 범위를 커버하는 activation map이 될 수도 있을 것이고, 어쩔 땐 전혀 관계 없는 부분이 활성화될 수도 있어서 이런 pseudo label로써 작동하기에는 어려운 부분도 있을 거라고 생각합니다.
이런 부분들에 있어서 저자들의 고찰이 있었을까요? 없었다면 윤서님의 고찰이 궁금합니다.
댓글 감사합니다.
결론부터 말하자면, 재찬님이 언급해주신 이런 경우에 대해서는 논문에 담긴 고찰은 없습니다. 하지만 간접적으로 언급한 부분으로 말씀드리자면, conclusion 부분에서 WeCromCL의 limitation으로 고해상도 입력 이미지가 필요하다고 언급되고 있는 것으로 보아 noisy한 저해상도 상황에서는 성능이 떨어질 수 있음을 예상해볼 수 있을 것 같습니다.
또, text가 매우 오밀조밀하게 뭉쳐있을 경우에 대해서는 CTW, TT 데이터셋이 말씀해주신 밀집형 텍스트 데이터셋이라고 볼 수 있는데 높은 성능을 보인 것으로 말미암아 anchor point 방식은 잘 작동하는 것 같습니다 . . 하지만 유사한 단어가 오밀조밀 존재할 경우에는 activation map이 잘못된 곳을 선택할 가능성도 있다고 봅니다.