안녕하세요, 이번주 x-review도 Amodal Completion에 관한 논문을 준비했습니다. 이번 논문은 여타 Amodal Completion 논문들과는 다르게 open world 환경에서 추가적인 학습 없이 자연어 쿼리를 기반으로 가려진 객체를 복원할 수 있는 프레임워크를 제안했습니다. 이로 인해 직접적으로 객체를 표현하는 쿼리 뿐 만 아니라 추상적인 쿼리로도 임의의 객체를 복원할 수 있습니다. 이를 위해 reasoning amodal completion이라는 개념을 제안했고, 이미지와 텍스트 쿼리를 기반으로 요청된 객체의 전체적인 형상을 재구성합니다.
Introduction
저자는 현실 세계에서 여러 물체들이 다른 물체들에 의해 가려지는 경우가 흔하고, 이를 증강현실이나 3D 모델링 등에 활용하기 위해서는 amodal completion이 필요하다고 문제를 정의합니다. 또한 기존의 amodal completion 방법론들은 closed set에서 작동한다는 것과 다양한 환경에서 강건하게 적용할 수 없다는 한계가 있다고 정의하고, 현실 영상의 다양한 시각적 특징을 가진 객체들을 유연하게 지정할 수 있도록 자연어 쿼리를 사용했습니다. 저자가 해당 문제를 해결하기 위해서 제시한 방법은 크게 세가지 인데요, 첫 번째로 Reasoning Amodal Completion이 있고, 두 번째로는 Segmentation, Occlusion Analysis, Inpainting을 한 프레임워크로 통합했다는 점입니다. 마지막으로 복원된 객체를 RGBA (RGB + 투명도 alpha) 요소로 출력해 AR, 3D Reconstruction등에 통합 가능하도록 구성했습니다.
Method
입력 이미지에서 가려진 객체를 복원해 RGBA를 생성하는 것이 목표인데요, 앞서 말했듯 자연어 쿼리를 입력으로 받아서 진행하게 됩니다. 저자는 자연어의 유연한 면을 활용해 복원 대상 객체를 추상적으로 지정할 수 있게 되면서 기존의 closed-set에서만 작동하는 기존 모델의 한계를 완전히 뛰어넘을 수 있고, 아래와 같은 파이프라인을 통해 end-to-end로 작동하는 모델의 구조를 설명합니다.
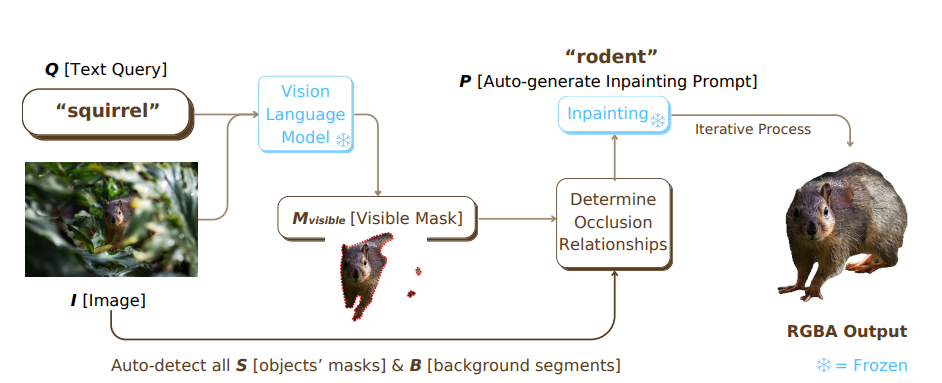
이미지 I와 함께 “squirrel”이라는 자연어 쿼리(Q)를 입력했을 때, SAM을 활용해 가려져있는 대상 객체에 대해 visible mask를 생성합니다. 이후 배경을 분리하는 작업을 거치는데, 배경을 분리하는 과정에서 처음 접하는 모델을 확인해볼 수 있었습니다. Open-set Image Tagging Model을 통해 sky, ground와 같은 배경에 해당하는 요소들의 태그를 생성한 뒤 이를 segmentation 해서 대상객체(S)와 배경(B)를 구분합니다. 이 과정을 통해 대상 객체와 객체를 가리고 있는 물체의 관계를 나타내는 Occlusion Relationship을 결정하기 위한 데이터를 수집합니다.
이후 visible mask와 자연어 쿼리를 기반으로 Auto-Generated Inpainting Prompt (P)를 생성합니다. P는 맥락적으로 대상 객체를 표현하고, squirrel의 경우 “rodent”를 생성합니다. 다음으로 대상 객체가 어떻게 가려져있는지 객체와 가리고있는 대상의 관계를 분석하는 Occlusion Analysis를 거쳐 Stable Diffusion v2 모델을 통해 Inpainting 됩니다. 이를 통해 최종 RGBA output을 얻을 수 있습니다.
Text Query Interpretation and Image Segmentation
저자는 Amodal Completion을 수행할 때 자연어로 설명된 객체를 다양한, 복잡한 장면에서 정확히 분리하는 것이라고 합니다. 이를 위해서는 이미지 내의 모든 요소들을 segmentation하는게 중요한데, 서로가 서로를 가릴 수 있기 때문에 이미지의 요소들을 전부 부분별로 segmentation하는것이 중요합니다. 이를 위해 입력 영상 I와 대상을 설명하는 자연어 쿼리 Q가 주어졌을 때, 쿼리로 주어진 대상에 해당하는 초기 마스크(가시적인 부분의 마스크) M_visible을 VLM(LISA)를 사용해 생성합니다. 생성된 마스크는 자연어 쿼리와 정렬되고, 이를 통해 구체적으로나 추상적으로 묘사된 객체에 대한 탐지와 서로간의 가림관계를 이해할 수 있게 해줍니다. 대상 객체를 가리는 요소들을 정확하게 파악하기 위해 객체와 배경을 분리하는데, 이 때는 Auto Image Annotation System을 사용해 이미지 내 모든 “이름을 붙일 수 있는 객체들”을 식별합니다. 사전학습된 Open-set Image Tagging Model을 사용해 이미지에서 컨텍스트 태그 세트를 추출하고, 태그 세트 내의 각 태그는 이미지 상의 시각적 특징을 가지고있는 클래스 라벨을 담고있습니다. 이렇게 준비한 태그와 입력 영상 (T와 I)를 이용해서 SAM을 통한 세분화된 마스크(S)를 생성합니다. SAM의 everything 으로 이미지 전체를 계층적인 마스크로 나누고 태그를 통해 라벨링 한다고 이해했습니다. 이를 통해 객체들간의 명확한 경계를 구분하고, 잠재적인 Occluder들을 식별하고 분리할 수 있도록 합니다.
앞서 말한 내용 중 배경을 처리하는 것도 중요한 요소입니다. 이미지에는 명확하게 식별 가능한 객체 외에도 배경요소나 흐릿한 요소, 질감 요소등 설명이나 구분이 모호한 영역이 존재하는데, 기존의 segmentation은 이러한 요소들이 라벨링되지 않거나 배경으로 처리됐는데, 이 요소들에 의해서도 물체는 가려질 수 있습니다. 따라서 해당 방법론은 객체를 카테고리로만 나누지 않고 모호한 요소들을 세분화된 형태학적 연산을 통해 정리하고 분리합니다. 이미지 내의 식별되고 분리되지 않은 영역을 B로 정의하고 배경영역과 아닌 부분을 구분하는 배경 segment(이진 마스크)를 생성합니다. 이 마스크는 배경과 객체를 확실하게 구분짓고, 이후 이 영역에 Dilation을 통해 B를 구분할 수 있다고 합니다. 예를 들어, 이미지에 나무, 풀, 흐릿한 텍스처가 포함된 배경이 있다면 나무와 풀을 구분하고 나무와 관련된 영역을 확장하여 독립된 세그먼트로 통합해서 나무, 풀, 흐릿한 텍스쳐를 구분한다고 합니다. 이 과정을 통해 대상 객체가 덤불에 가려진 빌딩과 같은 경우의 복잡하고 어려운 가려진 조건에서도 어떻게 가려져있는지 파악할 수 있다고 합니다.
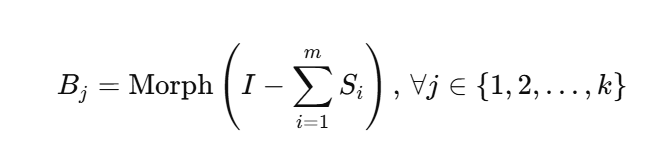
배경 segment는 위와 같은 수식으로 생성합니다. 앞서 말했듯 I는 입력이미지이고, 모든 객체 마스크를 합산해서 픽셀이 어느 하나의 객체에 속하기만 하면 값이 0이 아니기 때문에 이미지에서 S_i들의 합을 빼면 배경 영역만 남게됩니다. 이후 Morph(형태학적 연산)을 통해 배경의 각 영역을 segment합니다.
Occlusion Analysis
이미지를 요소별로 segmentation 한 이후에는 객체 내에서 채워야 하는 가려진 부분을 찾아내는 것이 중요한데, 해당 방법에서는 이를 위한 Occluder Mask를 생성합니다. 입력 이미지 I, 객체들의 마스크 S, 배경 요소 마스크 B가 주어졌을 때 목표 객체를 가리고 있는 모든 객체와 배경 요소 마스크들과 대상 객체의 가시적인 부분의 마스크 (M_visible)간의 공간적 관계를 평가하여 Occluder Mask(M_occ)로 정의합니다. 이 때 InstaOrderNet이라는 가려진 관계를 순서대로 나타낼 수 있는 occlusion ordering 모델을 사용하고, 사전학습된 occlusion ordering은 클래스 라벨없이 세그먼트 마스크와 이미지 패치를 입력으로 받아 occlusion order를 결정합니다. InstaOrderNet은 객체가 다른 객체를 가리고 있다면 occ_i = 1, 가리고 있지 않는 상태라면 occ_i = 0을 의미합니다. 이 과정을 통해 대상 객체를 가리고있는 모든 마스크들을 occlusion mask로 초기화합니다.
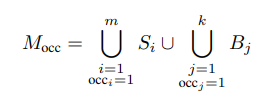
Occlusion Analysis 과정을 수식으로 나타내면 다음과 같습니다. 최종적으로 생성되는 Occluder Mask(대상을 가리고 있는 영역 마스크)인 M_occ는 InstaOrderNet을 통해 각각 객체 세그먼트(S)와 배경 세그먼트(B) 중에서 객체를 가리고 있는 마스크들을 찾아 (occ_i, occ_j = 1인 경우) 합집합을 생성합니다.
또 복원하려는 대상 객체가 이미지의 경계에 접해있는 경우에는 이미지를 확장해가면서 occluder 마스크를 대상 객체의 경계 영역을 따라 확장합니다. 반복적으로 접촉된 경게에 대해 팽창시키는 연산을 수행하여 M_occ를 확장하면서 마스크가 안정화되거나 모든 경계영역이 충분히 팽창되고 나면 M_occ를 확정합니다. 어떤 경우에 마스크가 안정화 되거나 경계영역이 충분히 확장되는지는 더 찾아보려고 합니다..
Prompt and Image Refinement for Inpainting
가려진 부분을 채우는 inpainting에 대한 내용인데요, 논문에서는 다양한 자연어 쿼리를 통해서도 amodal completion을 하도록 설계했기 때문에 자연어 쿼리와 이미지의 문맥을 결합하는 inpainting prompt를 생성한다고 합니다. 입력 이미지 I, 가시적인 마스크 M_visible, 자연어 쿼리 Q가 주어졌을 때 CLIP 기반의 유사도를 비교하는 방법을 사용해 이미지 상에서 대상객체를 분리하고 이미지 태그 T와 자연어 쿼리 Q에서 이미지를 설명하는 후보들 중 M_visible과의 속성과 가장 유사한 후보를 선택합니다.
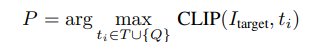
각 후보들에 대한 유사도는 위와 같은 식을 통해 계산됩니다. 이미지 상의 가려진 객체의 가시적인 부분만을 나타내는 I_target과 타겟을 설명하는 태그 후보 사이의 유사도를 CLIP 모델을 통해 구하고 가장 유사한 태그를 프롬프트 P로 활용합니다.
대상 객체를 더 명확히 분리하기 위해, I_target에서 M_visible 외부의 영역을 단색 배경으로 교체합니다. 이전에 리뷰했던 Amodal completion via progressive mixed context diffusion 에서 제안된 배경을 분리하는 기법을 사용한다고 합니다. 이를 통해 잡음을 제거하고 복원해야하는 부분 외의 픽셀을 제거해 대상 객체를 훨씬 확실하게 드러내면서 프롬프트에 관련없는 영역의 영향을 최소화합니다. 이렇게 얻은 프롬프트 P를 inpainting 모델의 입력으로 사용하게 됩니다.
결론적으로 프롬프트 P는 이미지 문맥을 반영해 CLIP 유사도를 기반으로 가려져있는 객체를 어떻게 복원할지 가장 적절한 카테고리입니다. 아래와 같은 이미지로 예를들어보자면 입력 쿼리로 animal in this image가 들어왔을 때, 프롬프트를 만드는 과정에서 북극곰, 얼음 등등의 태그들이 자동으로 생성 되고, 그 중 CLIP 유사도가 가장 높은 북극곰이 최종 프롬프트로 설정됩니다.

Iterative Inpainting and Amodal Completion
비가시적 완성(amodal completion)은 가려진 대상 객체의 현실적이고 완전한 복원을 목표로 합니다. 이를 달성하기 위해, 본 프레임워크는 **반복적 마스크 기반 인페인팅(iterative masked inpainting)**을 수행하여 대상 객체의 가려진 부분을 복원합니다. 이 과정은 **가리개 마스크(occluder mask)**의 안정성 또는 미리 설정된 반복 횟수에 도달했을 때 종료됩니다. 복원이 완료된 이후, 원래 가시적 영역과 복원된 가려진 영역을 매끄럽게 결합하여, 배경이나 불필요한 요소가 제거된 투명한 RGBA 출력을 생성합니다.
복원 과정은 대상 객체를 주변 장면에서 분리하는 것으로 시작됩니다. 이를 위해, 인페인팅 대상 영역 I_target을 아래와 같이 초기화 합니다.
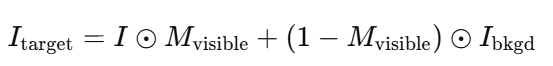
여기서I_bkgd는 깨끗한 배경을 나타냅니다. 이는 가시적 영역만 원본 이미지를 유지하고, 나머지 영역은 자연스럽고 문맥 없는 배경으로 교체하여 대상 객체를 명확히 분리합니다.
초기단계를 복원해야하는 가려진 대상객체로 설정하여 시작됩니다. 각 반복 단계에서 사전 학습된 인페인팅 모델(stable diffusion v2) 갱신된 M_occ와 프롬프트 P를 기반으로 가려진 영역을 복원합니다.
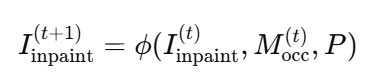
이 때 반복적인 inpainting을 진행하면서 다음 단계의 M_occ는 새로 복원된 영역을 포함하도록 바뀌고, 대상 객체의 경계를 정의하기 위해 M_amodal도 갱신됩니다. 또한 계산을 효율적으로 하기 위해 아래와 같은 식을 통해 지난번 inpainting 결과와 해당 결과의 occluder 마스크의 픽셀 차이가 임계값 보다 낮거나 정해진 횟수에 도달하면 inpainting 과정을 종료합니다.
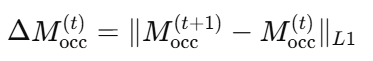
Inpainting 과정이 끝난 후에는 알파 블렌딩 과정을 거칩니다. 복원된 이미지와 원래 이미지가 자연스럽게 한 이미지에 결합하기 위해 가려지지 않은 부분을 1, 완전히 가려진 영역을 0으로 하는 투명도를 입혀 부드럽게 이어줍니다. 이를 통해 RGBA output을 통해 픽셀이 원래 가려져 있던 부분인지 아닌지 알 수 있다고 합니다. 알파값을 기준으로 복원된 영역과 가려져있는 원본 영역의 weighted sum을 통해 부드러운 이미지인 I_blend(RGB)를 얻을 수 있게됩니다. I_blend의 4번째 채널로 M_amodal의 값을 투명도로 추가해 최종적으로 RGBA output을 얻을 수 있습니다.
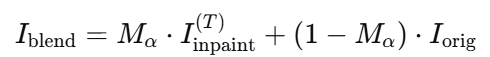
Datasets Collection

기존의 amodal completion은 사용한 데이터셋에도 한계가 있었는데요, 다른 amodal completion 논문에서도 말했듯 기존의 amodal completion을 위한 데이터셋은 객체의 카테고리가 제한적이고 합성데이터를 사용해 occlusion을 만들기 때문에 실제 환경의 복잡성을 잘 반영하지 못했습니다. 저자는 이런 문제를 해결하기 위해 위와같이 50개 이상의 카테고리가 존재하는, open world의 복잡함을 다룰 수 있는 데이터셋을 구축했다고 합니다. 평가 데이터셋을 COCO-A, Visual Genome, LAION, 저작권이 없는 공공 웹사이트에서 다양하게 수집해서 아래 표와 같이 출처에 따라 다른 특성의 데이터들을 정리했다고 합니다.

COCO-A는 데이터셋이 semantic segmentation을 위해 설계됐기 때문에 모든 경우에 occlusion이 존재하는 것은 아니어서 occlusion이 발생한 경우만 따로 취득했다고 합니다. LAION과 공공이미지로부터는 복잡한 occlusion환경의 데이터들을 취득해 조명, 특이한 환경등에 대한 다양한 조건을 포함시켰습니다. 이렇게 구성된 데이터는 위 표와같이 2379개의 데이터, 553개의 클래스를 가지고 있습니다. 이를 위해 3명의 사람이 가려진 객체가 포함된 이미지를 수집하고 가려진 객체에 대한 라벨링을 진행했다고 합니다. 상당한 노동인 것 같습니다.. 저자는 이렇게 다양하게 구성된 카테고리의 데이터셋은 open-world 상황에서의 amodal completion을 위한 도전적인 테스트베드를 제공한다고 합니다.
다른 amodal completion 논문들은 COCO-A를 그대로 사용해서 amodal completion을 위한 데이터셋이 COCO-A인 줄 알았는데 occlusion이 일어나지 않은 장면들도 있고 실제로 데이터셋을 구성하는 이미지 중 Visual Genome 이미지들이 가장 많아서 왜 다른 논문들은 사용하지 않은건지 의문이 생겼습니다.
Implementation Details
현재 공개된 Stable Diffusion v2 inpainting model과 LISA-13B-llama2-v1 model 을 사용했습니다. 실제 inpainting 작업에 stable diffusion을, 초기의 가려진 부분의 텍스트와 매칭해 M_visible을 만드는 데 LISA-13B-llama2-v1 모델을 사용했다고 합니다. A100 GPU에서 공개된 default 세팅으로 아무 fine tuning도 하지 않고 사용했다고 합니다. 방법론에서 효율적인 작업을 위해 최대 반복횟수를 정해둔다고 했는데, 3회로 정하고 실험했습니다.
Evaluation Metrics
다른 amodal completion 논문도 마찬가지지만 open world, 특히 자연스럽게 획득할 수 있는 이미지 에서 amodal completion을 수행했을 때 가려져있는 부분의 가려지기 전 GT는 존재하지 않기 때문에 사람평가와 정량적인 지표를 조합해서 사용했다고 합니다. 인간의 주관적인 평가와 더불어 CLIP 점수를 사용해 amodal completion된 객체가 class label과 잘 맞는지 측정하고, 목표 객체의 복원되기 전의 가려지지 않은 부분과 복원이 끝난 객체간의 LPIPS, VGG16 feature similarity, SSIM을 평가합니다. 각각 시각적, 의미적, 구조적 유사성을 평가합니다.
Comparisons with other Methods
다른 모델들과 비교를 진행할 때는 180명의 참가자를 Prolific 클라우드소싱 플랫폼에서 구해 선호도를 조사했고, 이와 기존의 정량적 평가 metric을 통해 Pix2gestalt, PD-MC(Progressive Diffusion – Mixed Context), mixed context diffusion을 하지 않은 PD w/0 MC 와의 비교를 진행했습니다. 원본 이미지와 4가지 방법으로 복원된 이미지들을 무작위 순서로 배열해서 평가를 진행했고, 데이터 신뢰성을 보장하기 위해, 명확한 선택을 요구하는 gold standard 질문을 포함했으며, 이 검사를 75% 이상 통과한 참가자들만 최종 분석에 포함했다고 합니다. gold standard질문은 평가에는 활용하지 않고 명확한 정답이 있는 질문으로 구성해 선호도가 아닌 정답을 찾아서 참가자의 능력을 평가하는 요소입니다. 결과는 아래 표와 같이 평가 데이터셋에서 가장 높은 인간의 선호도를 기록했습니다. 다양한 데이터셋에서 1위를 기록했기 때문에, 모델의 강건성도 입증한다고 주장합니다.


위와 같이 정성적인 모습을 봐도 개와 말 등을 기존의 다른 방법들보다 훨씬 잘 복원합니다. pix2gestalt의 논문을 봤을때는 비슷한 케이스에서 복원이 잘 됐던 것 같은데, 잘 될때가 있고 안 될때가 있는 것 같습니다. 저자는 오스카상이나 책과 같은 경우를 따져봤을 때도 다른 방법들이 놓친 구조적인 세부사항을 놓치지 않고 완벽하게 복원해냈다는 점을 어필했습니다. Pix2gestalt 방법도 오스카상의 형상을 잘 복원하는 것을 보면 확실히 Global Context와 Local Context를 같이 활용하는 방법들이 더 성능이 좋은 것 같습니다.

위의 표를 보면, 시각적, 의미적, 구조적인 평가 metric 상의 점수도 가장 높은것을 볼 수 있습니다.
Ablation Studies

텍스트 쿼리 Q만 사용한 경우, LISA로 생성된 auto generated tags T만 사용한 경우, T와 Q를 같이 사용한 경우를 비교해 봤을 때 객체정보와 문맥정보를 비교한 경우 위 표와 같이 확실히 높은 시각적, 의미적, 구조적 향상이 있었습니다. 모호한 배경 B를 처리하는 단계도 의미가 있었는데, Background Segmentation을 진행해서 occlusion을 더 면밀하게 정의 했을 때 쿼리 객체와 주변 환경 (땅, 하늘, 나뭇잎)등과의 scene understanding이 증가했다고 합니다. 배경이 있는 곳에서는 확실히 아래와 같이 주변 자연요소들에 가려져있다는 것을 인지하고 잘 복원하는 모습을 보여줍니다. 뿐 만 아니라 카메라 초점이 이상해서 흐려진 부분에 가려진 경우에도 모호한 부분에 대한 처리가 가능해서 Background Segmentation을 하지 않았을 때와 비교되는 모습을 보여줍니다.


Conclusion
이 논문은 다른 amodal completion 논문들과 같이 diffusion을 사용해 open world에서의 amodal-completion을 위한 프레임워크를 제안했습니다. 다른 논문들과 비교했을 때 amodal completion이 잘 됐는지를 여러 방면에서 평가하는 metric이 존재한다는 점이 사람의 주관적인 평가가 들어가는 만큼 더 중요하게 작용할 것 같다는 생각이 들었습니다. 또 RGBA의 output을 반환한다는 점에서 novel view synthesis와 같은 다목적 활용에 있어서 의미가 있다고 하는데, Alpha 채널이 추가되는게 어떤 의미가 있는지 아직 정확히 이해하지 못 했습니다. 또 데이터 신뢰성을 보장하기 위해 질문의 10% 정도는 골드 스탠다드 문항으로 구성해 참가자들을 시험해봤다는 점이 인상깊었습니다. 또 논문 후반부에 사용한 모델들에 대한 정보를 더 기재해뒀는데, DINO SwinT OGC에 대한 정보가 등장했는데, visible mask는 처음에 SAM으로 구한다고 본문에 나와있어서 DINO는 어디에 쓰인건지 좀 더 자세히 읽어보거나 찾아봐야 할 것 같습니다.
김영규 연구원님 좋은 리뷰 감사합니다.
해당 연구는 open-world와 open-vocabulary중 어느것에 해당하는 지 궁금합니다.
추가로, visible mask를 생성할 때, 그림에서는 뒷다리 부분의 가려진 영역도 인식하는 것으로 나오는데, occlusion이 발생해 물체가 분리된 경우 잘린 부분을 모두 하나로 인식하지 못하면 해당 작업이 잘 수행되지 않을 것 같은데 이에 대해서는 저자들이 어떻게 고려를 하는 지 궁금합니다.(SAM이 occlusion이 발생해 분리된 물체를 인식하는 성능이 좋다던가, 혹은 이르 고려해서 여러 segmentation mask간의 유사성을 고려하여 분리된 영역을 포함할 수 있도록 한다던가 하는 방식이 궁금합니다.) 정리하면, Occluder를 식별한다고 하여 뒷다리 부분과 같이 분리된 영역을 동일 객체에 대한 영역으로 인식하는 것에는 어려움이 있을 것 같아 이에 대한 저자들의 고려가 궁금합니다.
안녕하세요 영규님, 좋은 리뷰 감사합니다.
초반에 입력 쿼리와 이미지로부터 M_visible을 VLM(LISA)를 통해 뽑아낼 수 있다고 이해했는데, LISA는 어떤 방식으로 정확히 저 다람쥐를 뽑아낼 수 있는 건가요? 본 논문은 직접적으로 객체를 표현하는 쿼리 뿐 만 아니라 추상적인 쿼리로도 임의의 객체를 복원할 수 있는 장점이 있다고 언급했는데, 이는 LLM을 사용하는 것이 아니면 불가능할 것으로 예상됩니다. LISA의 내부 파이프라인에 LLM이 사용되나요?
평가지표 중 Semantic Consistency를 평가하는 지표로 VGG16 feature Similarity라는 독특한 지표가 있는데, 해당 지표에 대한 설명 부탁드립니다. 가려지기 전 물체와, amodal completion 된 물체 간의 semantic한 유사성을 비교해보고자 함인 것으로 이해했는데, 이때 배경 요소도 같이 판단하는 건가요? 아니면 투명배경 혹은 흰배경으로 실험하는 건가요? 그리고 왜 하필 VGG백본으로 semantic feature를 뽑은 건지에 대한 저자들의 고찰이 있나요?