제가 이번에 리뷰할 논문은 Affordance 인식을 위해 MLLM을 적용한 방법론으로, 제가 최근 리뷰한 UniAff에서 기존 방법론과의 비교에 활용된 방법론 입니다.(자세한 내용은 이전 리뷰 참고해주세요!)
Abstract
로보틱스 분야에 MLLM(Multi-modal Large Language Model)이 접목되며 자연어 지시문에 대한 이해능력 및 작업 수행 능력이 향상되었으나, 로봇에 특화된 지식이 부족하여 maniupulation task에서는 여전히 성능이 제한적입니다. 이는 MLLMs가 포괄적인 이미지-text 쌍으로 학습되므로 affordance나 물리적 개념과 같이 로보틱스에 필요한 이해가 부족한 것으로, 저자들은 이러한 갭을 줄이고자 ManipVQA라는 VQA(Visual Question Answering) 포맷의 새로운 프레임워크를 제안합니다. ManipVQA는 tool detection, affordance recognition, 물리적 개념에 대한 이해를 포괄하며, 저자들은 이를 위해 다양한 데이터 셋으로부터 사용자가 상호작용할 수 있는 물체를 묘사하는 데이터를 선정하여 데이터 셋을 구성합니다. 또한, 로보틱스 관련 지식을 MLLMs의 시각적 정보로부터의 추론 능력과 효과적으로 통합하기 위해 단일화된 VQA 형식을 적용하고, fine-tuining 방식을 제안합니다. 저자들은 로봇 시뮬레이터와 다양한 vision task 벤치마크에 대한 평가를 통해 ManipVQA의 성능을 입증하였습니다.
Introduction
GPT-4, SPHINX-X등의 Multi-modal Large Language Model(MLLMs)는 두 모달리티의 encoder의 align을 맞춰 대규모의 text-image 쌍으로 학습하였으며, 이러한 MLLMs의 발전으로 text와 이미지에 대한 이해 능력이 크게 개선되었습니다. 거라니 로봇의 affordance 이해 및 manipulation으로의 적용에는 여전히 어려움이 있었습니다.
로봇 manipulation은 로봇이 환경을 인지하고 물체에 수행할 수 있는 잠재적인 동작을 식별하는 것으로, 일반적인 scene 추론 능력을 갖춘 MLLMs를 manipulation에 직접적으로 적용하는 것은 low-level의 action 샘플의 부족으로 성능이 제한적입니다. 기존의 연구는 로봇의 affordance를 인식하기 위해 MLLMs로 이미지에 대한 추론을 수행한 뒤, 이후 action을 생성하도록 하였으나 성능이 낮은 수준이었습니다. affordance grounding은 객체에서 actionable한 영역을 찾는 것을 목표로 하며, 이러한 task는 상황 및 작업에 따라 여러 affordance로 매핑이 될 수 있는 물체의 특정 파트를 명시적으로 설정하는 데에 어려움이 있습니다. 기존 연구들은 이를 위해 LLM을 활용하였으며, MLLMs는 일반적인 이미지와 text 쌍으로 학습되어 affordance정보나 물리적인 관계를 이해하기 위한 로보틱스 관점의 지식이 부족하여 로봇 application으로의 적용이 어려웠습니다.
저자들은 MLLMs의 로보틱스 관점의 지식 부족 문제를 해결하고자 Visual Question-Answering 형식의 ManipVQA를 제안하였습니다. 통합된 VQA 방식과 fine-tuning을 통해 원본의 시각적 추론 능력을 유지하면서 로봇 작업을 위해 중요한 tool detection, affordance recognition, 물리적 개념 에 대한 지식을 추가하였으며, 이를 위해 다양한 상호작용하는 물체 이미지를 수집하였습니다. 시뮬레이터와 다양한 vision task의 벤치마크에 대한 실험을 통해 ManipVQA의 성능을 입증하였습니다.
Method
a. Modeling of Affordance and Physical Concepts
로봇 manipulation을 위해서는 물체의 affordance를 이해하고 이를 모델링하는 것이 다른 물체와 상호작용을 하기위해 필수적이며, 이러한 로보틱스 관점의 지식을 MLLMs에 어떻게 추가하였는지를 다루고있습니다. 먼저 일반적인 물체 \mathbf{O_{tool}}에서 잡을 수 있는 affordance 영역 \mathbf{A_{grasp}}을 모델링하여 튜플 형태(\mathbf{A_{grasp}}, \mathbf{O_{tool}})로 표현하고 각 object의 부분에 대한 BBox 정보를 이용합니다. (저자들은 HANDAL 데이터를 따라서 구성하였다고합니다.)
또한, task \mathbf{T}에 따라 ffordance가 달라진다는 점을 고려하여 다양한 맥락에 일반화가 가능하도록 작업별로 affordance를 연관시켜 튜플(\mathbf{A_{T}}, \mathbf{O_{tool}})로 표현하였습니다. 여기서 \mathbf{A_{T}}는 특정 작업에 대한 affordance를 의미하며, \mathbf{T}는 task를 묘사하는 자연어 문장입니다.
물리적 개념을 모델링하기 위해 물리적 개념 \mathbf{P}_i를 대응되는 객체 \mathbf{O}로 연결하여 튜플형태 (\mathbf{P}_i, \mathbf{O})로 표현하며, 여기서 물리적 개념은 아래의 Table1에서 확인할 수 있듯 물체의 투명도, 액체를 저장할 수 있는 능력, 밀봉 가능성을 의미합니다.

b. Instruction Dataset Construction
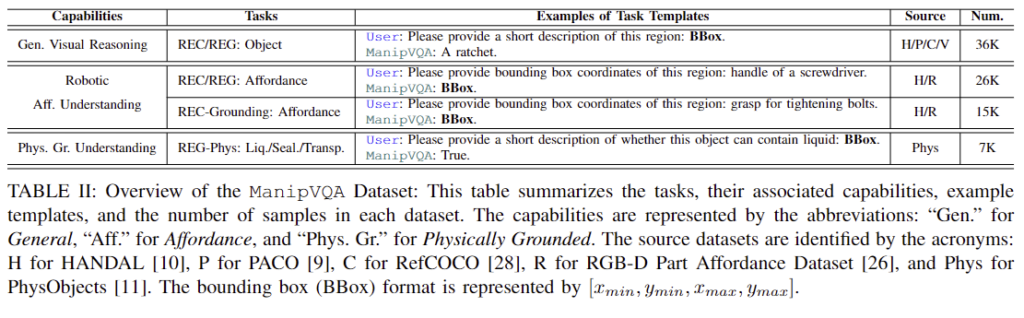
다음은 저자들이 VQA 방식으로 로보틱스 관련 지식을 추가하고자 하였으므로 이러한 fine-tuning에 사용하기 위한 공개 데이터 셋을 구축한 방식에 대하여 설명을 합니다. affordance 이해 능력과 시각적 추론 능력, 물리적 근거를 기반으로 한 모델을 드는 것을 목표로 저자들은 Robotic Affordance Dataset, Physically Grounded Dataset, General Visaul Reasoning Datasets으로부터 데이터 셋을 구축하였으며, 이에 대해 GPT-4를 이용하여 지시문을 생성합니다. 먼저 데이터 구축을 위해서 각 측면의 기존 공개 데이터 셋을 활용하였으며 이에 대한 내용은 다음과 같습니다.
- Robotic Affordance Dataset 저자들은 affordance 정보를 구성하기 위해 212개의 real-world 물체에 대하여 손잡이 부분을 라벨링한 HANDAL 데이터 셋을 베이스로 사용하였으며, RGB-D Part Affordance Dataset을 통합하여 grasp, cut, contain 등의 7가지 affordance를 추가합니다. AGD20K라는 grasping grounding에서 사용되던 데이터의 경우 sit-on, drink와 같이 affordance에 대한 라벨이 사람 중심으로 이루어져있어 학습에는 사용하지 않고 zero-shot 평가 데이터로만 사용하여 모델의 일반화 능력을 검증하는 데 사용하였다고 합니다.
- Physically Grounded Dataset 물리적 특성에 대한 이해를 모델에 반영하기 위해 PhysObjects 데이터 셋을 활용합니다. 8가지의 물리적 개념이 있지만 저자들은 앞서 언급된 물체의 투명도, 액체를 저장할 수 있는 능력, 밀봉 가능성에 대한 annotation만을 선택하여 사용합니다.(왜인지는 따로 나와있지 않습니다.. 근데 논문에서 확장 가능하다는 표현이 있어서 이 부분은 더 고민해봐야할 것 같습니다..)
- General Visaul Reasoning Datasets 시각적 추론 능력을 유지하기 위해 PACO(2023년 공개된 데이터 셋으로 물체의 일부분과 특성에 대한 정보), Ref-COCO(coco 데이터 셋에 특정 객체에 대한 위치 특성 등의 언어적 정보를 라벨링한 데이터 ), Visual Genome(coco 데이터에 대해 What, Where, When, Who, Why, How에 대한 정보를 Question Answering 형식으로 구성한 데이터)과 같이 일반적인 물체에 대한 데이터를 사용합니다.
저자들은 GPT-4를 이용하여 robotic affordance 데이터 셋의 기존의 annotation 정보를 맥락을 고려하여 다양하게 변형하였습니다. 아래의 Listing 1이 해당 과정이며, 먼저 로봇이 물체의 적절한 부분을 잡도록 적절한 부분에 대한 grounding 정보를 제공하는 전문가라는역할을 주고, 로봇 팔에 부착할 수 있는 OBJECT_NAME이 주어졌을 때 일상에서 수행될 수 있는 다양한 작업 목록을 생성하도록 하며, 이 과정에 가이드라인과 예시를 제공합니다.

c. Task Formulation
ManipVQA를 학습하기 위해 Referring Expression Comprehension (REC)과 Referring Expression Generation (REG)을 통합하였다고 합니다. REC는 자연어 설명과 이미지가 주어졌을 때 설명이 묘사하는 물체에 대한 bounding box를 예측하는 작업이며, REG는 이미지와 이미지 내 특정 영역(bounding box)에 대한 설명을 생성하라는 프롬프트가 주어졌을 때 이에 대한 설명을 생성하는 작업입니다. 저자들은 추가적으로 로봇의 affordance와 물리적 특성을 고려하도록 REC에 변형을 주어 REC와 REG task와 통합합니다.
**REC-Grounding-Affordance;**먼저 REC에는 물체나 특정 부분의 이름을 직접 지정하지 않고도록 task에 변형을 주었으며, REC-Physical; 물리적 속성을 기반으로 질문에 관련되도록 변형을 주었다고 합니다.
D. MLLM Fine-tuning Strategy
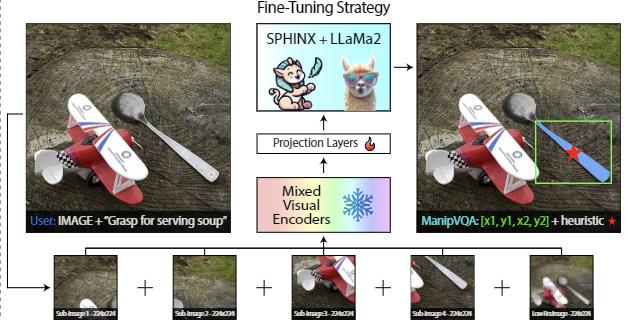
<Model Architecture>
저자들은 MLLM 모델로 SPHINK를 선정하였으며, LLaMa2를 language 백본으로 사용하였습니다. CLIP의 visual encoder를 통해 local한 feature를 추출하고 Q-former를 이용하여 global한 feature를 추출합니다. 두 feature를 projection layer를 통과시킨 뒤 channel-wise concatenation을 수행하여 이미지 token을 얻습니다. 이미지 token을 언어 지시문과 함께 모델에 입력하여 지시문(프롬프트)에 대한 시각적 정보를 제공합니다. 이때 이미지는 고해상도 정보를 유지하기 위해 448×448의 이미지를 224×224로 줄이는 게 아니라 패치 형태로 잘라(4개의 가장자리와 중심)입력으로 사용합니다. 이러한 모델의 구조와 관련된 내용은 UniAff(최근 리뷰한 이후 연구)방법론이 ManipVQA 구조를 거의 동일하게 사용한 것으로 보입니다. UniAff에서는 추가로 DinoV2를 local feature 추출을 위한 encoder로 사용했다는 점이 모델 구조 관점에서의 차이점입니다.
<Fine-Tuning Strategy>
저자들은 VQA 프레임워크를 따라 MLLMs 모델을 학습시켰으며, 이를 위해서는 cross-entropy loss를 이용하였다고 합니다.(저자들이 fine-tuning 전략을 제안하였다는 점은 VQA형태로 문제를 정의하고, VQA에 기존 task 뿐만 아니라 affordance와 물리적 개념을 고려하도록 추가하였다는 점을 어필한 것으로 보입니다.) 또한 학습에는 SPHINX 프레임워크에 대해 80GB A100 8장으로 6시간 학습하였다고 합니다.
추가로 이후에 affordance 영역을 추정할 때, bounding box를 이용하는 것은 배경도 함께 고려하게 되므로, SAM을 적용하여 더 정확한 affordance map을 생성하도록 하였다고 합니다. (이를 SAM-HQ라 표현합니다.)
Experiments
1. Robotic Affordance Detection Evaluation
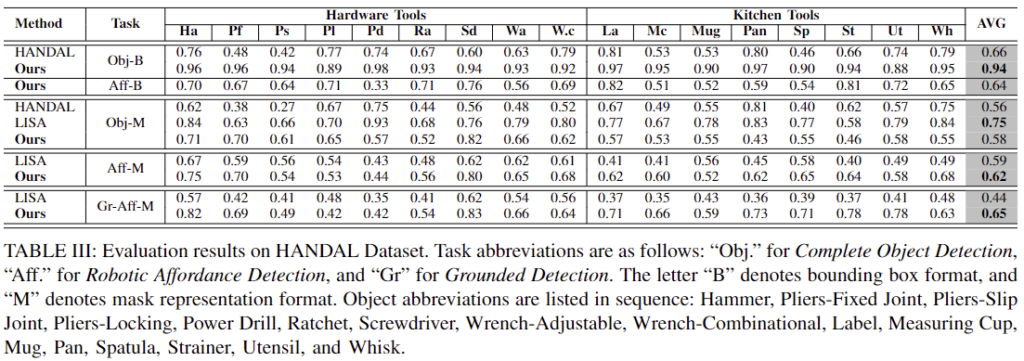

- Affordance 인식 능력을 평가하기 위해 HANDAL 데이터 셋에 대한 실험을 진행하였으며, LISA는 LLM과 SAM decoder를 합친 방식이고 평가지표로는 bounding box에 대한 AP를 측정합니다.
- 위의 Table3을 통해 ManipVQA가 객체와 객체의 affordance 영역을 인식하는 데 좋은 성능을 보이는 것을 확인할 수 있습니다.
- Fig. 3는 해당 실험에 대한 정성적 결과로, 앞의 4개 열은 affordance detection 결과를, 뒤의 2개 열은 grounding 결과를 나타냅니다.
2. Physical Concept Grounding Evalutation
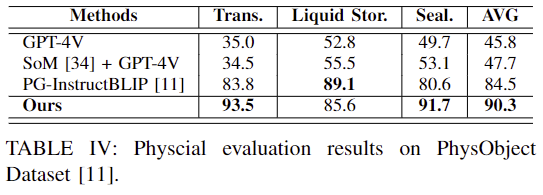
- Table 4는 PhysObject 데이터에 대한 평가결과로, 물리적 개념에 대한 grounding 성능을 평가합니다.
- GPT-4의 경우에도 물리적 개념에 대한 이해가 필요한 작업에서 어려움을 겪으며, 대체로 ManipVQA가 좋은 성능을 보입니다.
3. General Affordance Grounding
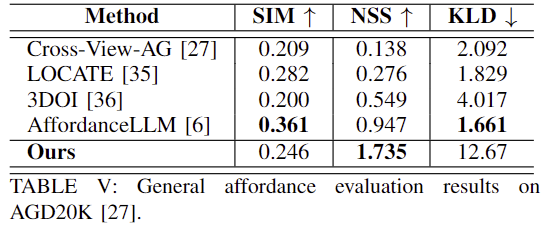


- Table 5는 AGD20K 데이터 셋에 대한 평가 결과로, 로봇이 수행할 수 있는 작업에 대해서만 학습이 되었음에도 불구하고 일반적인 affordance grounding에 대해서도 경쟁력있는 성능을 보여줍니다.
- 저자들은 KLD에서 ours의 성능이 크게 저하되었는데, 이에 대해 SAM이 과도하게 세분화된 마스크를 생성한 것과, GT는 affordance 영역에 대한 point들로부터 가우시안 필터링을 적용한 heatmap형태이지만 저자들은 예측된 bounding box에 SAM을 적용하였기 때문이라고 추정합니다.
- Fig. 4를 통해 시각화 결과를 확인할 수 있으며, “Hold”와 “Sit on”에 대해 적절한 영역을 찾을 수 있음을 보였습니다.
- Fig. 5는 동일한 물체 class에서 주어진 affordance에 따라 유의미한 영역을 효과적으로 추론할 수 있음을 보여줍니다.
4. Robotic Manipulation in Simulator
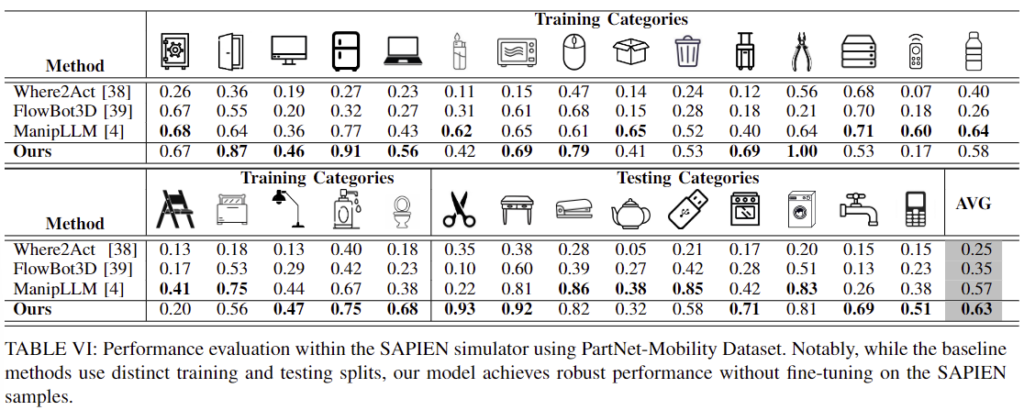
- ManipVQA의 조작 성공률을 평가하기 위해 시뮬레이터에서 평가를 진행한 것으로, fine-tuning을 수행하지 않고 zero-shot 방식으로 평가를 수행합니다.
- Table 6은 이에 대한 실험 결과 작업에 대한 fine-tuning 없이도 효과적으로 로봇 조작이 가능하였다는 것을 실험적으로 보였습니다.
5. Ablation Study
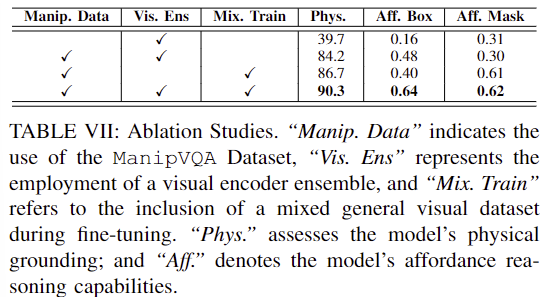
- Tablee 7은 ablation study 결과로, ManipVQA 데이터 셋을 활용하였을 때 physical grounding과 Affordance 인식에서 성능이 크게 개선되는 것을 확인할 수 있으며,
- 학습 과정에 일반적인 vision 데이터를 사용하지 않을 경우(Mix. Train)에는 상당한 성능 저하가 발생하는 것을 확인할 수 있습니다.
Impact on Pre-Existing Vision Reasoning Ability
저자들은 ManipVQA가 시각적 추론 능력이 저하되지 않았는지 확인하기 위해 RefCOCO+ 데이터에 대한 평가를 수행하였으며, fine-tuning되기 전인 86.6%에 비해 81.8%로 약간 하락되었으나 여전히 추론 능력의 일반화 성능이 좋다고 어필합니다.(이에 대해서는 별도의 표나 그림이 없습니다..)
안녕하세요 승현님, 좋은 리뷰 감사합니다.
1. Task Formulation에서는 REC와 REG task를 통합해서 로봇의 affordance와 물리적 특성을 고려하도록 세팅했다고 하셨는데, REG를 통해 설명을 생성하는 과정을 파이프라인 내에서는 구체적으로 어떤 식으로 활용하는 것인가요? 추가적으로 이 REG task를 결합하지 않았을 때(즉 그냥 REC를 통해서만 affordance 부분에 대한 grounding만 하게 하는 경우)에 대한 ablation study는 없었나요?
2. 모델 아키텍쳐에서의 핵심이, MLLM 모델인 SPHINK에 대해 저자들이 세팅한 ManipVQA 데이터셋(bbox가 anntation인)으로 fine-tuning 학습방식을 진행한 것으로 이해했는데, 해당 방법론이 contribution으로 내세우는 물리적 개념에 대한 이해를 도와주는 부분은 SPHINK에서 이루어지는 것인지, LLaMa2에서 이루어지는 것인지 조금 헷갈려서 해당 부분 또한 질문드립니다.
3. 또한 Fig.3에서 앞의 4개 열은 affordance detection 결과, 뒤의 2개 열은 grounding 결과라고 해주셨는데, 여기서 affordance detection 과 grounding 의 의미가 서로 어떤 차이점이 있나요..?
감사합니다.
질문 감사합니다.
1. 우선 REG는 영역에 대한 묘사를 생성하는 작업입니다. 이러한 REG는 Table 2에서 사용되고 있음을 확인하실 수 있습니다. 즉, VQA 방식으로 grasping을 위한 로보틱스적 정보를 추가하도록 학습하기 위한 과정(구체적으로는 데이터 생성 과정)에 사용됩니다.
2. 우선, 논문에서 이야기하는 물리적 개념은 물체의 투명도, 액체를 저장할 수 있는 능력, 밀봉 가능성을 의미합니다. 이에 대하여 데이터에 관련 개념을 함께 제공하므로써 SPHINX를 학습시킨다고 이해하였습니다.
3. affordance detection과 affordance grounding의 차이에 대하여 질문하신 것으로 이해하였습니다. 시각정보를 기반으로 Affordasnce Detection은 affordance label이 있는 영역을 찾는 perception 중심의 작업이고, Affordance Grounding은 언어에 대응되는 영역을 찾는 것에 집중한 understanding 중심 작업이라 이해하였습니다. affordance라는 표현만 빼고 봤을때, detection과 grounding의 차이와 동일합니다.
안녕하세요. 좋은 리뷰 감사합니다.
ManipVQA를 학습하기 위해서 REC와 REG를 통합하였다고 이해했습니다. 궁금한 점이, Task에 따라서 REC를 요할때가 있고, REG를 요할 때가 있을 거 같은데 이러한 구분은 따로 수동으로 작업해줘야 하는지, 아니면 학습을 하면서 해당 하는 TASk에 자동으로 선택하여 답변하는지 궁금합니다.
감사합니다.
질문 감사합니다.
추론 과정에서는 이를 구분하여 선택하지 않는 것으로 알고있습니다. 다양하게 만든 데이터를 통해 MLLM에 추가적인 정보를 제공하는 것을 목표로 하며, MLLM이 task별로 나눠지지 않는다는 점에서 자동으로 답변한다고 이해하였습니다.