안녕하세요 오늘 제가 리뷰할 논문은 Compositional Moment Retrieval을 제안하는 논문입니다. Moment Retrieval task에서 쿼리의 compositionality를 고려한 task를 소개하는 논문입니다.
Introduction
Moment Retrieval은 비디오와 자연어 쿼리를 입력 받아 쿼리에 해당하는 비디오 내 구간을 반환하는 task입니다. 텍스트에 대한 이해와 비디오에 대한 이해를 필요로 하는 task로 정해진 텍스트가 아닌 free-from 텍스트를 입력으로 하기에 자연어의 의미론적 다양성(semantic diversity)이 중요합니다. 의미론적 다양성은 언어학에서 조합성(compositionality)의 원리를 기반하고 있습니다. 이 원리는 새로운 의미를 이미 알고 있는 단어들을 새로운 방식으로 결합함으로 체계적으로 설명하는 것을 의미합니다. 이러한 능력은 compositional generalization이라고 합니다. 하지만 현재의 Moment Retrieval 데이터셋들은 이러한 compositional generalization 능력을 구체적으로 평가하지 않고 있습니다. 따라서 현존하는 Moment Retrieval 방법론들은 compositional generalization 능력이 부족합니다. 저자는 실험을 통해 현재의 SOTA를 포함한 여러 방법론들이 compositional generalization이 없음을 지적하고 위 능력을 제대로 평가하기 위한 데이터셋과 프레임워크를 제안합니다.

Figure 1. 은 현 SOTA 모델이 compositional generalization 능력이 없음을 보여주는 그림입니다. Original Query A는 기존 데이터셋에서 존재하는 쿼리의 예시입니다. Shuffled Query는 Original Query 문장 내에 존재하는 단어들의 조합을 랜덤하게 섞은 쿼리입니다. 마지막으로 Query B with novel composition은 novel composition (thorows, flowers)를 포함하는 쿼리로 모델의 compositional generalization 능력을 확인할 수 있는 쿼리입니다. 현 SOTA 모델은 문장의 의미론적 정보를 상실한 문장 내 단어의 위치가 섞인 Shuffled Query 상황에서도 Original Query와 같은 성능을 보여주며 compositionality에 대한 이해가 없음을 보여주고 있습니다. 반면, novel composition이 추가된 상황에서는 제대로된 성능이 나오지 않으며 모델이 compositional generalization 능력이 없음을 보여주고 있습니다.
Compositional Dataset
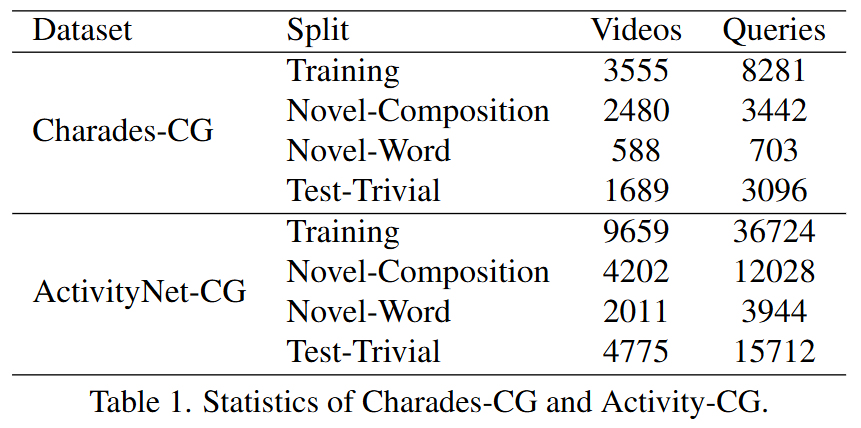
저자는 위 그림을 설명하며 기존의 연구들은 자연어 쿼리의 compositionality를 고려하지 않을 뿐만 아니라 compositionality를 평가할 데이터셋이 존재하지 않았다는 점을 지적하며 새로운 데이터셋을 제안합니다. 기존에 많이 사용되는 데이터셋인 Charades-STA 데이터셋과 ActivityNet Captions 데이터셋을 재조합하여 compositional generalization 능력을 평가할 수 있도록 합니다. 기존의 두 데이터셋은 비슷한 형태의 쿼리가 학습, 평가에 모두 사용될 뿐만 아니라 각각 1.3%, 5.19%의 쿼리만이 평가할 때에 새로운 composition으로 제공되고 있었습니다. 저자는 이는 compositional generalization 능력을 평가할 수 없음을 지적하며 두가지 테스트 분할을 새로 정의합니다. 새로 정의된 Novel Composition과 Novel Word는 이름 그래도 한가지 유형의 새로운 composition, 새로운 단어를 포함하고 있습니다. 이는 모델이 문맥에 따라 학습된 composition을 통해 새로운 composition 혹은 단어의 의미를 추론할 수 있는 지를 평가하는 것을 목표로 합니다.
구체적으로 저자는 AllenNLP를 사용하여 먼저 명사, 형용사, 동사, 부사, 전치사를 형태소 분석하고 라벨링합니다. 이후 동사-명사, 형용사-명사, 명사-명사, 동사-부사, 전치사-명사 총 5가지의 composition 유형을 정의합니다. 쿼리마다 각각이 존재하는 composition을 파악하고 저자는 새로운 composition 및 단어를 선정하여 기존의 훈련, 평가 셋만 존재하던 데이터셋을 훈련, novel-composition, novel-word, 평가 셋 총 4가지 셋으로 분류하여 Charades-CG, ActivityNet-CG로 새로 이름붙여사용합니다. CG는 compositional generalization을 의미합니다. 아래의 table 1은 새로 재구성된 Charades-CG와 ActivityNet-CG 데이터셋을 보여줍니다.
Method
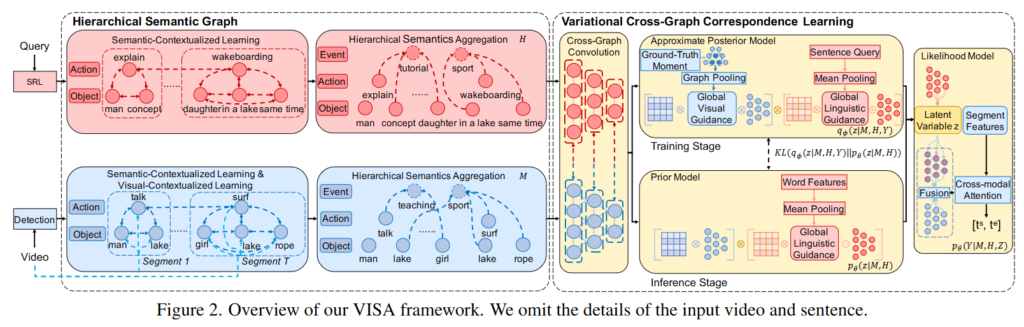
Figure2는 저자가 제안하는 VISA 모델의 프레임워크입니다. 기존 방법론들이 고려하지 않았던 compositional generalization 능력을 갖추기 위하여 구성된 프레임워크로 Hierarchical Semantic Graph와 Variational Cross-Graph Correspondence Learning으로 구성되어 있습니다. untrimmed video V와 query sentence Q가 주어졌을 때 Hierarchical Semantic Graph는 global events, local actions, atomic objects 총 3가지 의미 계층으로 나눕니다. 이는 coarse level부터 fine-grained level까지의 정보를 모델링할 수 있습니다. 이후, Variational Cross-Graph Correspondence Learning은 두 그래프 사이의 의미적 대응관계를 설정하는 것으로 주어진 쿼리와 의미적으로 대응하는 순간을 검색할 수 있습니다.
Hierarchical Semantic Graph
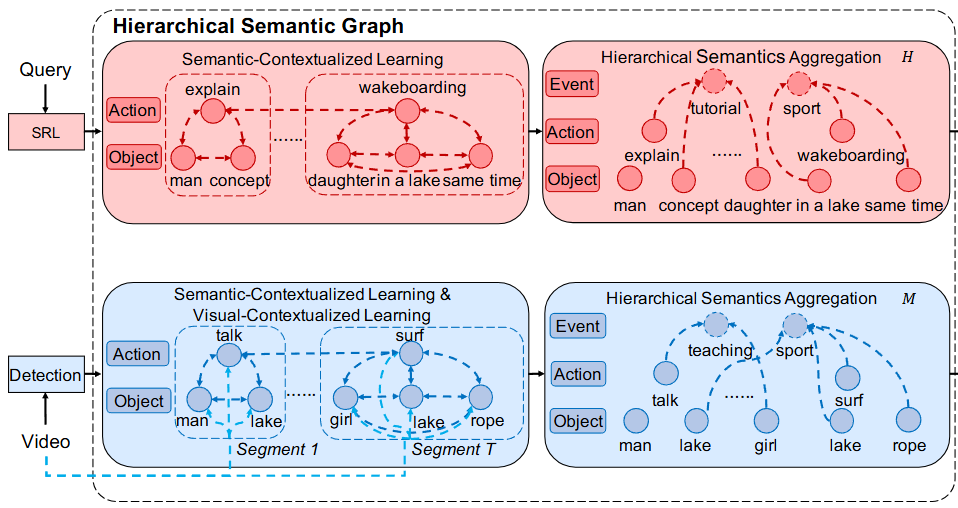
저자는 자연어 쿼리는 일반적으로 몇가지 semantic events를 설명하고 있으며 이는 predicate(술어)와 해당하는 arguments로 구성된다고 분석하고 있습니다. 비디오는 여러 objects(객체)의 다양한 action(행동)으로 구성된 여러 사건들로 구성된다고 분석하고 있습니다. 따라서 저자는 언어와 비디오는 본질적으로 계층적 구조를 가진다고 설명하고 있습니다. 이러한 저자의 해석을 바탕으로 저자는 주어진 비디오 V와 쿼리 Q에 대해서 global events, local actions, atomic objects에 해당하는 세가지 의미 계층으로 분해하고 비디오와 쿼리를 대응시킵니다.
먼저 그래프를 초기화하는 방법입니다. 저자는 비디오를 고정된 길이(2초)의 segment(비디오의 단위)로 분할한 후에 사전 학습된 3D CNN 모델을 사용하여 video feature를 추출합니다. 추출한 video feature은 object detection 및 action recognition 모델을 사용하여 객체와 행동을 추출합니다. 이때 사용하는 object detection 과 action recognition에 사용하는 모델은 일반적으로 사용하는 모델을 사용한다고합니다(모델에 대한 정보는 제공하지 않네요). 쿼리의 경우 semantic role labeling(SRL)을 사용하여 주어, 술어 그리고 몇몇 대응되는 arguments를 추출합니다. 쿼리의 feature를 추출할 때에는 GloVe를 사용합니다. 추출한 각각의 객체와 행동은 그래프에서 계층 구조로 연결되어 그래프를 초기화합니다.
Semantic-Contextualized Learning
그래프를 초기화한 후에는 events는 비디오 문맥의 고수준 의미적 추상화로 서로 다른 의미론적 개념들 사이의 상호작용을 의미합니다. 여기에는 세가지 공간적 관계, 시간적 관계, 행동적 관계가 존재합니다. 따라서 저자는 이러한 events를 복합적으로 이해하기 위한 방법으로 Semantic-Contextualized Learning을 제안합니다.
구체적으로 저자는 세가지의 방향 없는 엣지(undirectional edge)를 정의합니다. Action-Action, Action-Object, Object-Object로 각각의 엣지들을 연결하는 것으로 복잡한 events를 이해합니다.
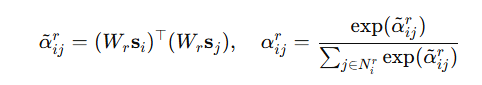
위 수식은 각 엣지 유형 r에 대한 인접 상관도입니다. W는 relation-specific projection 행렬을 의미합니다.
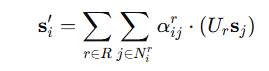
그 후 위 수식에 따라 노드들을 업데이트합니다. R, U_r은 각각 세가지의 엣지(relation)유형, 변환 행렬을 의미합니다. W, U는 각각 연산을 위해 shape을 맞추는 역할을 수행하고 학습가능합니다.
즉, 비디오의 복잡한 events를 이해하기 위해서는 문맥을 이해할 수 있어야합니다. 저자는 이를 세가지의 Action-Action, Action-Object, Object-Object 연결을 통해 해결하고 각각의 관계 인식 그래프의 합성곱을 통해 상관도를 계산, 노드를 갱신하고 계층적 관계 학습을 통해 문맥을 파악할 수 있습니다.
Hierarchical Semantic Aggregation
비디오에 대해서는 추가로 Hierarchical Semantic Aggregation을 통해 비디오 의미 그래프와 관련된 시간적 문맥을 학습합니다.
의미 노드 s_i[/latex[에 대해서 [latex]f^i_j는 프레임의 특징을 의미합니다. 먼저 저자는 segment 내에서 각 프레임에 대한 시각 필터를 계산하고 필터링된 visual feature를 얻습ㄴ디ㅏ.
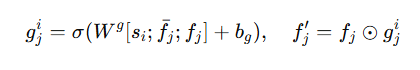
⊙는 Hadamard product를 의미하고 \bar{f_j}는 visual feature에 average pooling을 거친 결과입니다. 이후에 max pooling을 수행하고 노드에 concat하고 변환 행렬 W^v를 통해 변환하여 더해주는 것으로 시각전 문맥을 학습합니다.
정리하면 비디오에서 segment별 시각적 정보를 통합하여 시각 필터 g^i_j를 얻고 Hadamard product를 사용해visual feature f'_j를 구합니다. 그 후에 max pooling을 거쳐 노드s_i에 더하고 변환행렬을 통해 최종 representation을 얻습니다. 이 과정을 통해 비디오의 시각적 문맥을 학습할 수 있습니다.
Variational Cross-Graph Correspondence
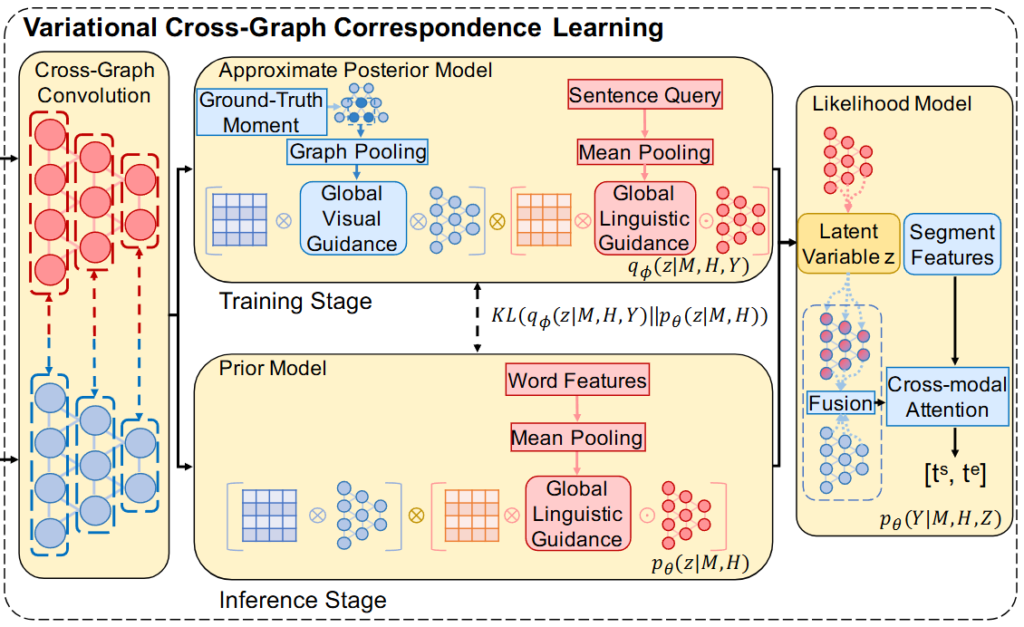
비디오와 쿼리를 계층적 의미 그래프로 모델링한 후에 저자는 Cross-graph convolution을 통해 두 모달 간의 상호작용을 모델링합니다. 이 과정에서 fine-trained semantic correspondence를 학습하는 것이 목표입니다. 저자는 학습의 목적 함수를 P(Y|M,H)로 정의합니다. 이때 Y는 목표 구간(moment), M은 비디오의 계층적 그래프, H는 쿼리의 계층적 그래프입니다. 즉, 비디오와 쿼리의 게층적 그래프를 바탕으로 목표 구간을 반환하는 것을 목표로 합니다. 그래프 간의 대응을 파라미터 z로 간주해 최적화합니다.
저자는 여기서 P(Y|M,H)를 최대화하는 대신에 Evidence Lower Bound(ELBO)를 최대화한다고합니다.
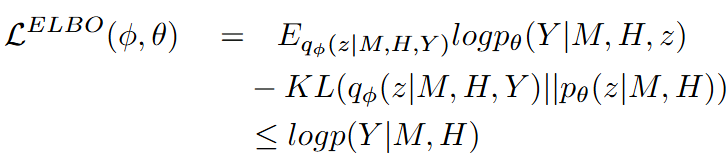
ELBO는 저도 처음 들어보는 개념이라 찾아보니 베이지안 방법에서 구하고자하는 분포가 다루기 힘든 경우에 이를 조금 더 다루기 쉬운 분포로 근사해서 표현하는 방법이라고 합니다. 저도 자세하게 수식적으로 어떻게 증명하는 것인지는 아직 모르지만, 목적함수를 계산하기에 더 쉬운 형태로 표현하는 방법으로 두 분포의 차이를 최소화하는 것으로 lower bound를 구하는 방법입니다. p_{\theta}(z|M,H)는 prior model, q_{\theta}(z|M,H,Y)는 posterior model, p_{\theta}(Y|M,H,z)는 likelihood model을 의미합니다.
Cross-Graph Convolution
두 그래프 M과 H가 주어졌을 때, 동일한 계층 끼리의 convolution 연산을 수행하는 것으로 두 모달리티를 상호작용합니다. 이때 convolution은 다음과 같이 정의됩니다.
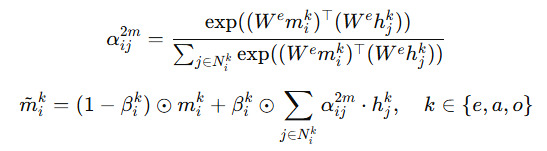
여기서 N^k_i는 계층 k의 H에서의 i의 이웃 노드를 의미합니다. \beta는 H에서 M으로의 정보를 제어하는 파라미터입니다.
Prior Model
위에서 목적 함수를 ELBO를 최대화하는 과정으로 이해할 때의 Prior Model입니다. latent variable z를 통해 cross-graph correspondence를 추론하는 것을 목표로 합니다.
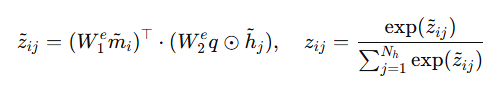
위 수식과 같이 정의되고 q는global sentence feature입니다.
즉, 그래프 간의 의미적 대응 관계를 추론하기 위하여 latent variable z를 모델링하는데 이때 Hadamard product와 가중치 행렬 W를 통해 관계를 표현하고 Sofrmax함수(수식의 우측)를 통해 마지막에 확률로 변환합니다.
Approximate Posterior Model
위에서 목적 함수를 ELBO를 최대화하는 과정으로 이해할 때의 Posterior Model입니다. posterior model은 추가 정보 GT moment Y를 활용합니다. GT 정보를 활용하여 시간적 segment에 관련된 노드를 식별하고 관련 event의 의미를 기반으로 그래프 간 대응 학습을 진행합니다.
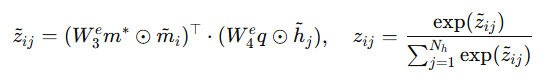
위 수식과 같이 정의되고 m*는 노드들에 대해 mean pooling을 수행한 결과입니다. global visual guidance의 역할을 합니다. q는 global linguistic guidance의 역할을 수행합니다. 즉, 각각 비디오, 쿼리의 global 정보를 의미합니다.
즉, GT의 정보를 활용하여 시간적 segment와 관련된 노드를 식별하는 과정으로 비디오와 쿼리의 global 정보를 추출해 상관도를 계산, 확률로 변환하여 표현합니다. 이 과정을 통해 비디오와 쿼리의 의미적 대응 관계를 학습할 수 있습니다.
Likelihood Model
위에서 목적 함수를 ELBO를 최대화하는 과정으로 이해할 때의 Likelihood Model입니다. Likelihood model은 latent variable z와 계층 적 의미 그래프 M, H를 통해 시간적 관계를 모델링합니다. 학습된 그래프 간의 대응을 통해 두 그래프를 통합한 Multimodal representation을 얻습니다.
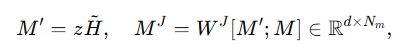
W^J, M^J는 각각 projection matrix와 Multimodal representation을 나타냅니다. 그 후에 multi-head cross-modal attention을 통해 상호작용합니다.
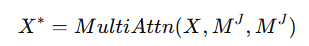
X*는 semantics-aware segment representations입니다. 마지막으로 sentence feature q를 기반으로 attentive pooling을 수행합니다.
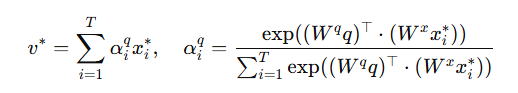
이렇게 해서 얻은 v*는 MLP를 통해 moment(start, end timestamp)를 예측합니다.
Experiments
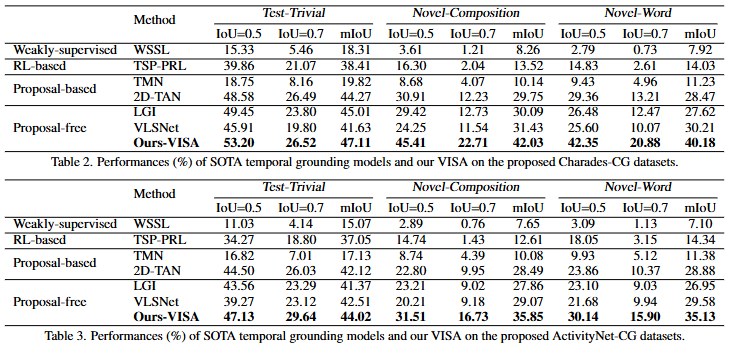
위 Table 2, 3은 저자가 제안하는 Charades-CG와 ActivityNet-CG에서의 저자가 제안하는 프레임워크의 성능과 기존 SOTA 방법론들의 성능을 비교하는 표입니다. Test-Trivial은 일반적인 Charades-STA데이터셋과 ActivityNet Captions 데이터셋이고 compositional generalization 능력을 확인할 수 있는 평가는 Novel-Composition과 Novel-Word입니다. 기존 데이터셋에서의 성능도 기존 SOTA모델보다 좋은 것을 통해 저자가 제안하는 방법론의 효과를 확인할 수 있고 특히 저자가 제안하는 Novel-Composition과 Novel-Word에서는 기존 SOTA보다도 월등한 성능을 보여주면 저자가 문제정의한 compositionality를 고려하지 않는 기존 방법론들과 달리 저자가 제안하는 VISA는 compositional generalization 능력을 갖추고 있는 것을 확인할 수 있습니다.
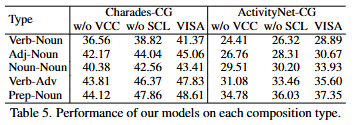
저자는 추가로 composition 종류에 따른 성능 차이를 보여주고 있습니다. Verb-Noun 즉 동사-명사의 관계가 가장 어려운 compositon이라는 것을 확인할 수 있으며 저자는 정확하게 verb-noun composition을 이해하는 것이 비디오 내의 객체와 행동을 정확하게 구별하기 위해서는 제일 중요한 composition인 동시에 가 어려운 composition이라고 언급하고 있습니다.
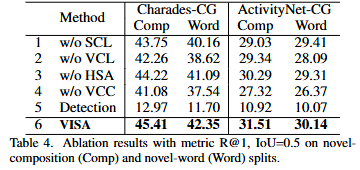
Table 4는 저자가 제안하는 VISA 프레임워크에서 각 모듈을 제외했을 때의 성능을 비교하는 ablation study입니다. VCC가 없을 때의 성능이 제일 낮은 것을 확인할 수 있습니다. 저자는 이것을 VCC가 없는 경우, 비디오와 문장의 그래프를 직접 결합하게되면 의미적 대응 관계가 손상되기에 성능에 저하가 생기게 되는 것으로 분석하고 있습니다. 결국 VCC가 시간적 연결 성능을 극대화하는 데에 핵심적인 역할을 하는 것은 VCC가 없을 때의 성능 저하가 제일 심한 것을 토대로 보여주고 있습니다. 추가로 저자는 일반적인 데이터셋이 아닌 저자가 제안하는 compositional generalization 성능을 통해 ablation study를 진행함으로 compositional generalization 능력에 크게 영향을 미치는 모듈에 집중한 것으로 보입니다.

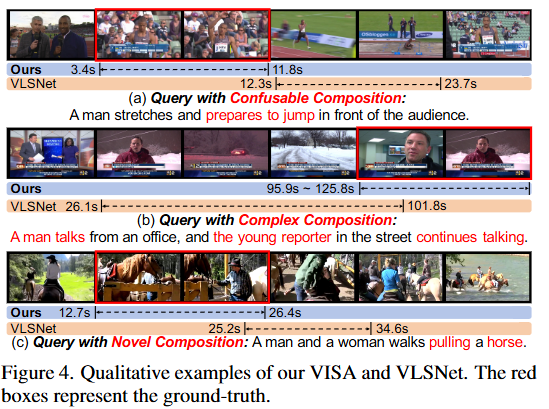
Figure 3, 4는 VISA 모델의 정성적 성능입니다. 결국 저자가 제안하는 VISA가 기존 SOTA 모델보다 novel-composition, novel-word에서의 성능이 뛰어난 것을 정성적으로 보여주고 있습니다.
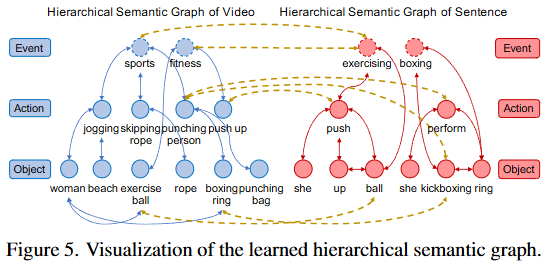
Figure 5는 학습된 계층적 의미정보를 보여주는 그래프입니다. 그래프 간의 의미 대응 정보는 노란색으로 시각화하여 보여주고 있습니다. 저자는 시각적 의미를 뜻하는 punching person, boxing ring과 같은 정보를 kickboxing과 같은 언어적 표현과 성공적으로 대응시켰음을 보여주고 시각적 의미와 언어적 표현을 fine-grained level에서 대응할 수 있도록 모델링했음을 강조하고 있습니다.
감사합니다.
안녕하세요 성준님 좋은 리뷰 감사합니다.
Hierarchical Semantic Graph는 global events, local actions, atomic objects 총 3가지 의미 계층으로 나뉜다고 하셨는데 atomic objects가 무엇인가요? Hierarchical Semantic Graph 그림에서 object에 ‘in a lake’와 같이 단순히 object를 의미하는 것 같지는 않아서 질문 드립니다.
감사합니다!
안녕하세요 정의철 연구원님 좋은 댓글 감사합니다.
Video에서의 atomic objects는 objects를 의미하는 것이 맞습니다. 비디오 내 객체를 검출하여 그 객체를 atomic object로 사용하기 때문입니다. Query에 대해서는 상황이 살짝 다른데 이미 주어진 Query를 계층적으로 구분하는 것으로 가장 낮은 단계의 의미를 갖는 자연어를 atomic objects로 구분했다고 이해해주시면 될 것 같습니다. 즉 위 그림에서의 예시를 들면, event는 어떠한 사건(sports등)을 의미하고 action은 사건 내에서의 행동(wakeboarding 등) 그리고 objects는 행동의 주체와 추가적인 설명(in a lake 등)으로 구분하였습니다.
저자가 Query를 이렇게 구분한 이유에 대해서는 크게 언급하지 않아 이유는 알 수 없지만, 비디오에서와 마찬가지로 계층적으로 Query를 구분하기 위함이라고 생각됩니다. 네이밍은 비디오에서의 이름을 Query에서도 똑같이 적용했습니다.
감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
해당 논문에서 event, action, object로 나누어 모델링하는 것이 contribution이라 이해했습니다. action이랑 object의 경우 예가 없어도 이해가 되는데 event의 경우 “predicate(술어)와 해당하는 arguments로 구성”되어 있다고 하셨는데 어떤식으로 데이터가 들어가는지 잘 이해가 되지 않습니다. 어떠한 텍스트가 들어잇는 걸까요?
안녕하세요 김주연 연구원님 좋은 댓글 감사합니다.
arguments는 여기서는 파라미터와 비슷한 의미를 갖습니다. 즉, “predicate(술어)에 해당하는 파라미터를 event에 할당했다”라는 것을 의미하는데 쿼리 내에서 objects와 actions를 묶어주는 역할을 합니다. objects와 actions를 통해 추론하여 데이터가 들어가게 되는데 예를 들어, “He is playing the guitar”이라는 Query가 있을 때에 Objects는 He와 the guitar가 되고 actions는 playing이 됩니다. 그렇다면 events는 objects와 actions가 relation을 기반으로 매칭되는 쌍을 묶어주고 He, playing, the guitar를 그래프로 연결해 하나의 triplet형태의 event가 되는 것입니다. 위와 같은 방식으로 저자는 비디오와 쿼리에 대한 계층적인 그래프를 생성하고 이 관계를 통해 예측을 수행합니다. 위 그림 예시에서의 단어는 설명을 위해 저자가 추가한 단어로 실제로 특정 단어가 매핑되는 것은 아닙니다.
감사합니다.