안녕하세요. 이번 논문은 Zero-shot Visual Grounding 태스크 중 VLP(Vision Language Pretraining model)와 OVD를 결합한 논문입니다. zero-shot grounding을 주제로 국문저널급을 한편을 쓰기로 되어 있어서 가장 최신의 zero-shot visual grounding 논문은 무엇이 있을까, 어떤 걸 참고해볼 수 있을까 하고 서칭하다가 찾게 된 논문입니다. 저번 세미나 때도 가져왔었는데요, 그럼 시작하겠습니다.
1. Introduction
Visual Grounding은 복잡한 의미 정보를 담고 있는 언어 표현에 의해 묘사된 이미지 영역을 정확히 찾아내는 기술로, 컴퓨터 비전과 자연어 처리의 융합을 대표하는 중요한 태스크입니다. 이 태스크는 대표적으로 크게 두 가지로 나뉘는데요. 바로 REC(Referring Expression Comprehension)와 Phrase Grounding 입니다. REC는 주어진 텍스트 참조 표현에 따라 이미지 속 특정 객체를 식별하는 것을 목표로 하며, Phrase Grounding는 문장의 모든 개체를 이미지 속 대응 객체에 연결하는 것을 목표로 합니다.
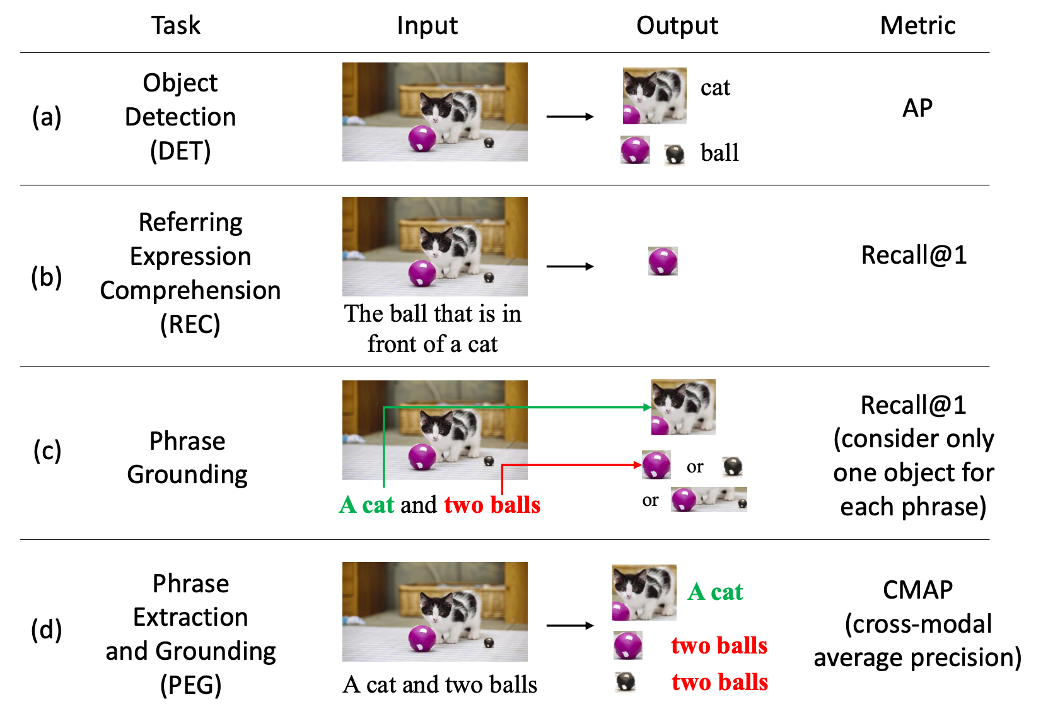
위 그림의 b,c를 보면 REC와 Phrase Grounding 태스크 간의 차이가 어떤 건지 직관적으로 알 수 있습니다. REC는 input 쿼리 전체가 말하고자 하는 대상 하나만을 output으로 찾길 원하고, Phrase Grounding은 input 쿼리 내에 표현되는 모든 객체를 output으로 찾길 원하는 것입니다.
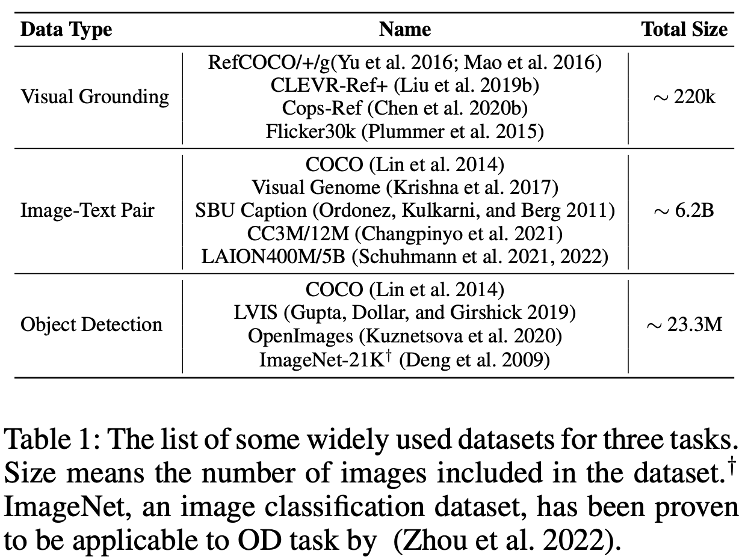
그런데 이러한 기존의 Visual Grounding의 흐름은 보통 supervised 방법론이라 annotation cost가 든다는 문제가 있습니다. 이미지 속 객체 간 상호작용을 세밀하게 분석하고, 공간적 관계 및 속성 정보를 이해한 뒤 이를 주석으로 작성하는 작업이 요구되기 때문입니다. 그러니 Visual grounding을 위해 매번 특정 도메인이나 태스크에 적합하게 annotation을 하기란 쉽지 않죠. 반면 다른 데이터를 생각해보면, 위 표1 과 같이 image-pair나 기본 object detection data는 그에 비해 상대적으로 많습니다.
저자들은 앞서 언급한 annotation cost 문제로 인해, 비교적 쉽게 얻을 수 있었던 저 Image-Text pair와 Object Detection 데이터들에 대해 생각해보다가 각각을 활용해 좋은 연구 성과와 능력을 보여왔던 VLP model과 OVD를 각각 떠올리게 됩니다. VLP 모델은 Vision Language Pretrained model이라고 해서 CLIP과 같은 VLM이라고 보시면 되고, multimodal semantic recognition이 가능한 모델입니다. OVD는 Open Vocabulary Detection model로 또한 위의 CLIP을 사용한 모델이 있거나, 기존 OD 데이터를 활용한 모델입니다. 예를 들면 최신 SoTA로는 Grounding DINO가 있었죠.
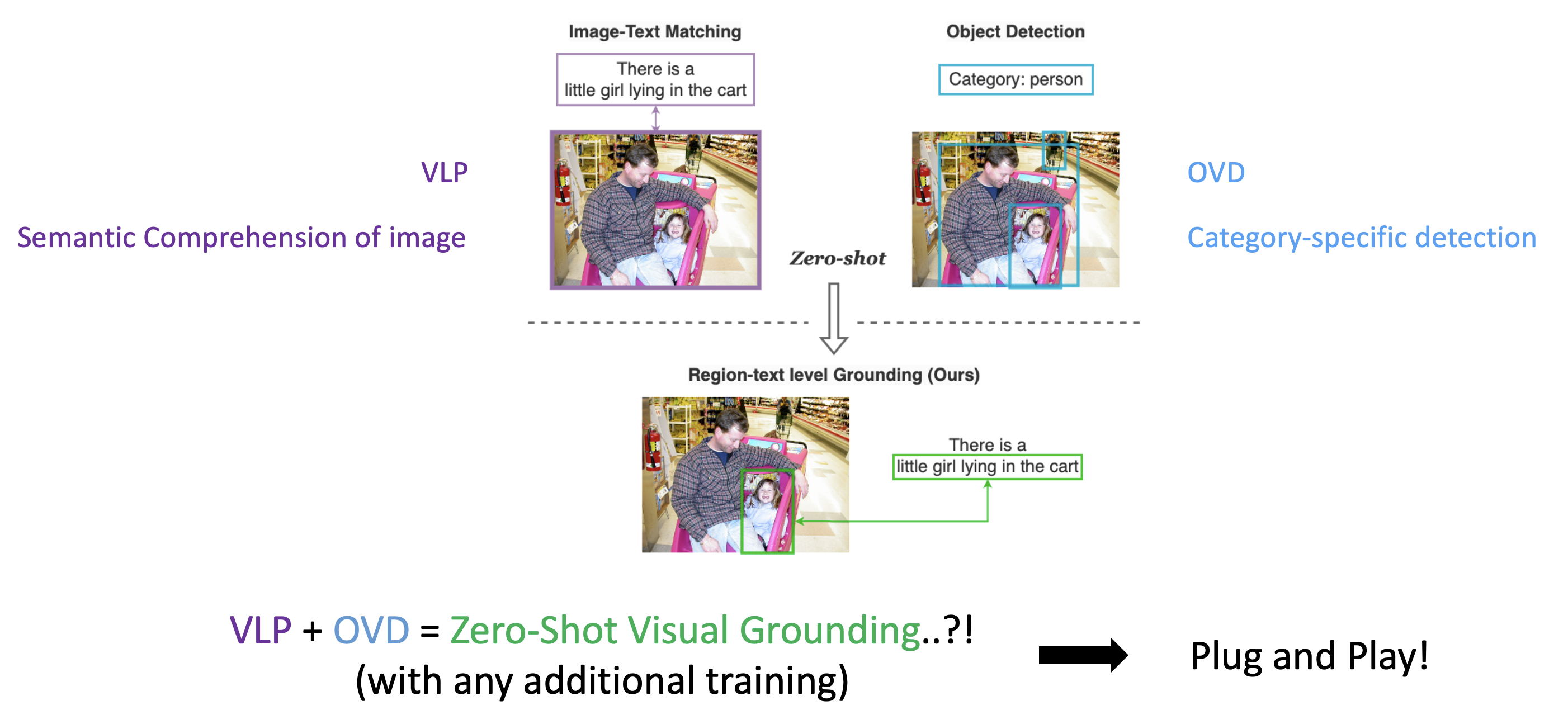
그렇다면 자연스럽게 이런 생각이 드는데요. 여기서 이미지에 대한 semantic comprehension 능력을 가진 VLP와 category-specific하게 detection하는 능력을 가진 OVD를 합치면 visual grounding이 가능한 것 아니겠냐고 저자들은 생각합니다. 더구나 이렇게 되면 Pretrained 모델들을 활용하기 때문에, 추가학습없이 zero-shot grounding 이 가능하지 않나 라고 생각하게 됩니다.
이렇게 저자들은 GroundVLP라는 방법론을 제안하게 됩니다. 이는 Visual Grounding 태스크를 위한 혁신적인 제로샷 방법론으로, 참조 표현 이해(REC)와 구문 접지(Phrase Grounding) 모두를 효과적으로 처리하는 데 중점을 둡니다. GroundVLP는 크게 세 가지 주요 요소로 구성됩니다.
- VLP 모델과 GradCAM 활용
GradCAM을 활용하여 주어진 텍스트 표현과 가장 의미적으로 관련 있는 이미지 영역을 식별합니다. 특히, 기존 연구와 달리, GroundVLP는 GradCAM attention 값을 시각적으로 인식 가능한 단어에만 집계하여 텍스트와 이미지 간 모달리티 매핑을 최적화합니다. - OVD(Object Detection) 기반 후보 객체 검출
Object Detection 모듈을 통해 후보 객체를 검출하며, 이전 제로샷 방법과 비교했을 때 잡음이 적은 후보 상자만 선택하도록 범위를 좁힙니다. 이는 텍스트 쿼리에 기반해 객체 카테고리를 정의하거나, Spacy 또는 Stanza 같은 NLP 툴을 사용해 자동으로 예측함으로써 구현됩니다. - 가중치 기반 융합 메커니즘
GradCAM에서 추출한 이미지 영역과 OVD로 검출한 후보 객체 정보를 융합하여 최종적으로 가장 적합한 객체를 선택합니다.
본 논문 GroundVLP의 Contribution은 다음과 같습니다.
- 간단하지만 강력한 zero-shot 방법론 제안
GroundVLP는 REC와 Phrase Grounding를 모두 지원하는 단순하면서도 효과적인 제로샷 접근 방식을 제안했습니다. 이를 통해, GroundVLP는 일부 비-VLP 기반 감독 학습 모델에 필적하는 성능을 달성하며, 쉽게 접근 가능한 데이터(이미지-텍스트 쌍 및 객체 감지 데이터)만으로도 시각적 접지 문제를 해결할 수 있음을 입증했습니다. - RefCOCO/+/g 데이터셋의 성능 저하 원인 분석
GroundVLP는 Ground-Truth 카테고리를 사용하지 않을 경우 발생하는 성능 저하의 원인을 분석했습니다. 이 과정에서 RefCOCO/+/g 데이터셋에 내재된 잡음과 편향이 주요 요인으로 작용함을 밝혀냈습니다. 이러한 분석은 데이터셋의 한계와 모델 성능 저하의 관계를 이해하는 데 중요한 통찰을 제공합니다. - 구성 요소의 효과성 검증 및 OVD 한계 분석
GroundVLP는 각 구성 요소의 효과를 검증하기 위한 Ablation Study을 세밀하게 수행하여, 제안된 컴포넌트들이 모델 성능 향상에 미치는 영향을 확인했습니다. 특히, 실험을 통해 OVD 기반 방법론이 시각적 접지에서 약점을 보이는 점을 명확히 드러냈습니다.
2. Preliminay
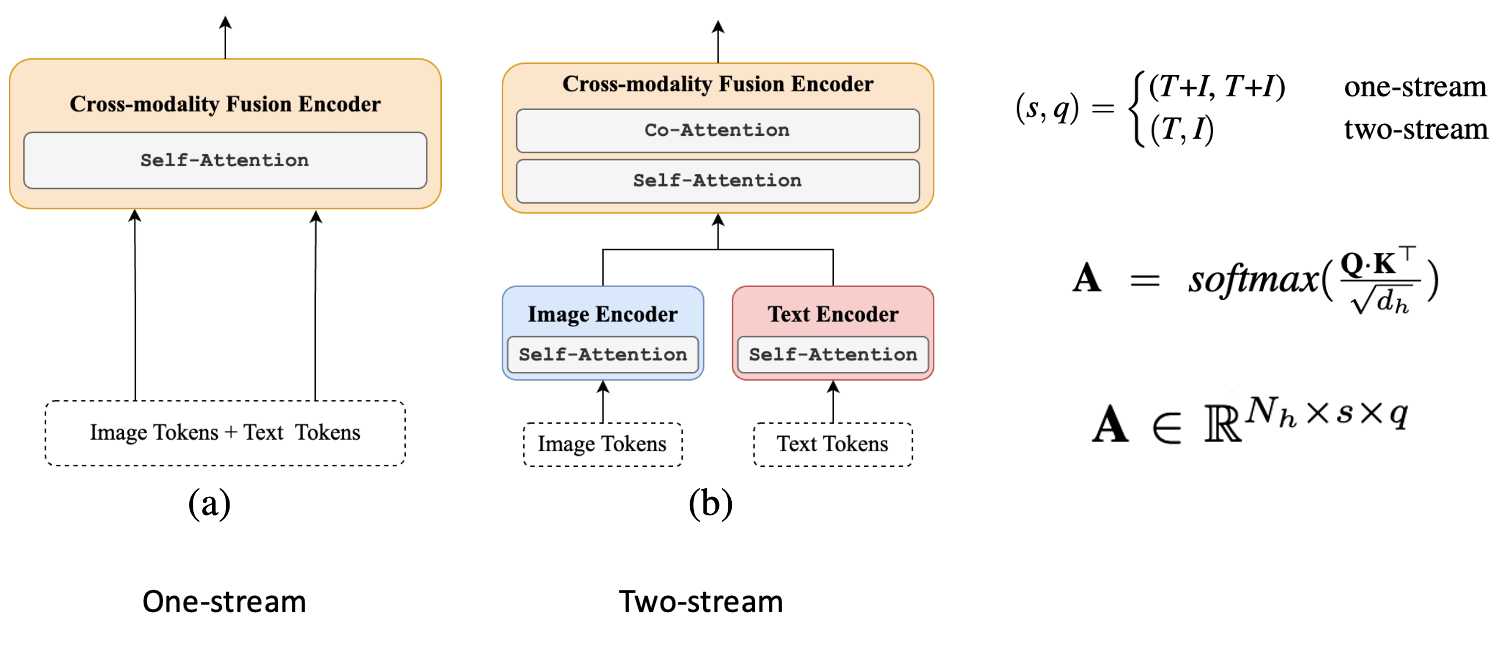
최근의 VLP(Vision-Language Pretraining) 모델들은 Self-Attention과 Cross-Attention, 이 두 가지 주요 attention 메커니즘에 기반하여 설계됩니다. Self-Attention은 입력 시퀀스 자체에서 생성된 쿼리(Q), 키(K), 값(V) 행렬을 활용하는 반면, Cross-Attention은 다른 시퀀스에서 K와 V를 수집합니다. 기존 VLP 모델들은 이러한 메커니즘을 기반으로 one-stream, two-stream, dual-encoder라는 세 가지 아키텍처로 나눌 수 있으며, GroundVLP에서는 주로 one-stream과 two-stream 구조를 활용합니다.
GradCAM은 이러한 attention 메커니즘에서 특정 이미지 영역과 텍스트 간의 연관성을 시각화하는 데 사용되며, GroundVLP는 이 기술을 활용해 텍스트와 이미지 간의 의미적 관계를 더욱 효과적으로 파악합니다. 텍스트-이미지 쌍이 주어지면, 텍스트 T와 이미지 I를 VLP 모델에 입력하여 Attention Map을 계산합니다. 이는 다음과 같은 수식으로 정의됩니다.
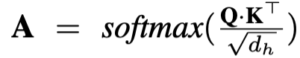
여기서 Q와 K는 각각 Multi-Head Attention에서 쿼리와 키를 나타내며, d_h는 히든 스테이트의 차원을 의미합니다. 원스트림과 투스트림 아키텍처에서는 s와 q 값이 각각 다르게 설정되며, 자세한 정의는 아래와 같습니다.
Q \in \mathbb{R}^{N_h \times q \times d_h}
K \in \mathbb{R}^{N_h \times s \times d_h}
A \in \mathbb{R}^{N_h \times q \times s}
N_h : \text{head num of Multi-Head Attention}
투스트림 아키텍처에서는 텍스트 인코더와 이미지 인코더의 교차-주의 모듈에서 Q가 텍스트 인코더로부터, K는 이미지 인코더로부터 생성됩니다. 이후, 역전파를 통해 그래디언트 맵(\nabla A = \left( \frac{\partial L_{\text{itm}}}{\partial A} \right)^+)을 계산하며, GradCAM을 사용해 최종적인 결과 맵 G를 얻습니다.
G = \mathbb{E}_h \left( \nabla A \odot A \right)여기서 \mathbb{E}_h는 attention 헤드 방향으로의 평균을 나타내며, \odot는 요소별(element-wise) 곱셈 연산을 의미합니다.
결론적으로 일단 VLP에서 attention 하는 타입이 두가지가 있는데, 저자들은 이 두가지 attention 타입에 따라 Method의 수식이 조금씩 달라지며 방법론에서는 두 방식 다 실험하겠다는 점을 언급하고 시작하는 것이라고 이해하면 될 것 같습니다.
3. The Proposed Method
GroundVLP의 overview architecture는 다음과 같습니다. 크게 2가지 흐름으로 나뉘는데, 파란색 화살표 흐름이 VLP를 활용해 Heat-map을 생성하는 부분, 분홍색 화살표 흐름이 OVD를 활용해 box proposal을 내뱉는 부분입니다. 이후 이를 Heat-map과 fusion하는 과정을 통해 최종적인 output을 갖게 됩니다.
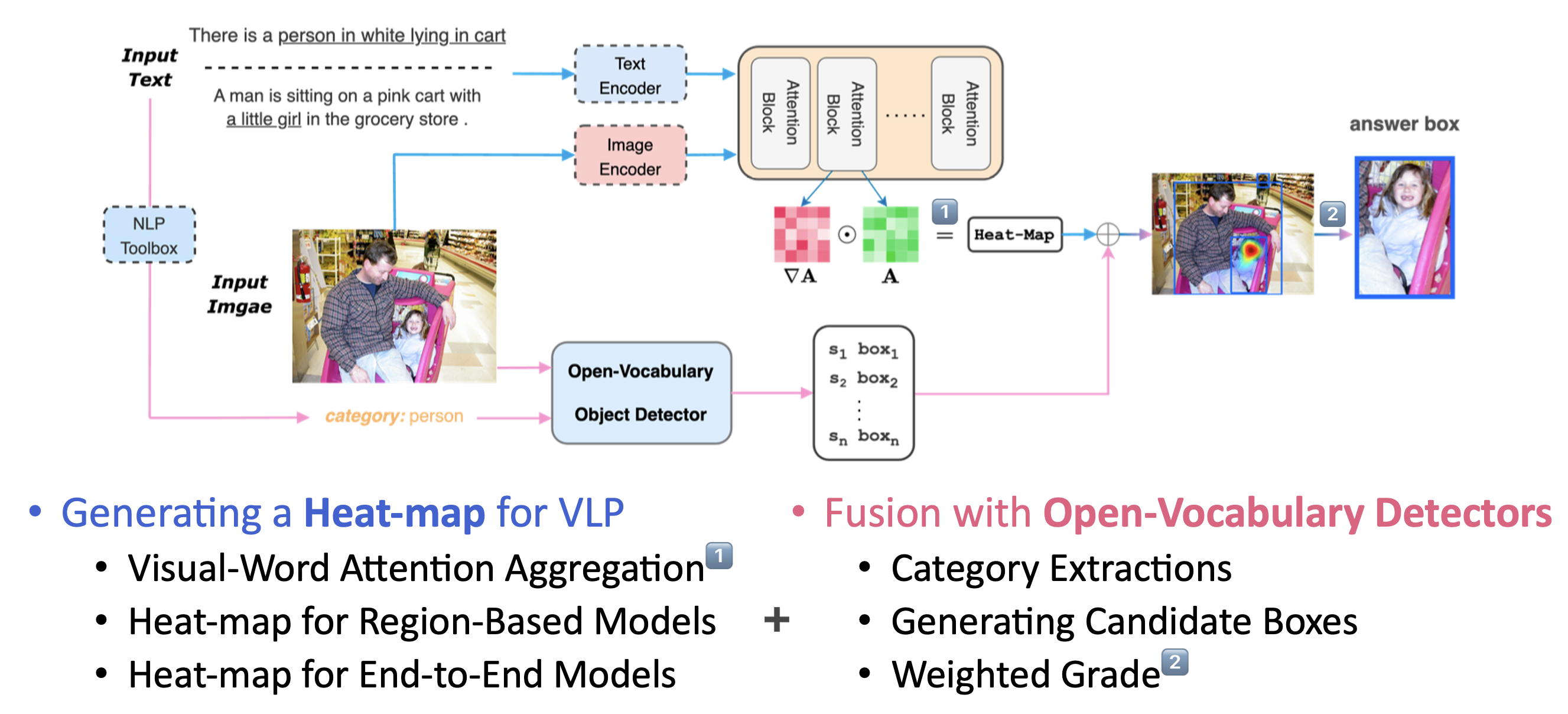
Generating a Heat-map for VLP
VLP 부분의 모델은 두 가지 방식의 주요 아키텍처를 사용합니다.
- 원스트림(one-stream): 텍스트와 이미지 토큰이 동일한 attention 메커니즘을 공유합니다.
- 투스트림(two-stream): 텍스트와 이미지 토큰이 별도의 attention 모듈을 거치며 상호작용합니다.
그래서 GradCAM을 활용하여 히트맵 G를 생성한 뒤, 각 텍스트 토큰이 이미지 토큰에 미치는 영향을 나타내는 G'를 계산합니다:
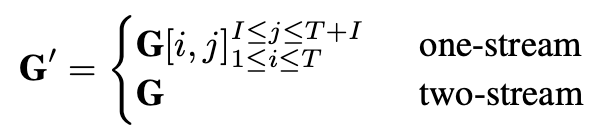
이후, G'를 ~\tilde{G}로 압축하여 텍스트와 이미지 토큰 간의 관계를 나타냅니다. 이는 전체 텍스트 표현([expression])과 각 이미지 토큰 간의 연결을 나타냅니다. \tilde{G} = \mathbb{E}_t (G')_{t \in \mathcal{W}}
여기서 \mathcal{W}는 텍스트 토큰 집합입니다.
저자들은 이 ~\tilde{G}로의 압축 과정에서, visual-word attention aggregation 방법을 제안하게 됩니다.
[Visual-Word Attention Aggregation]
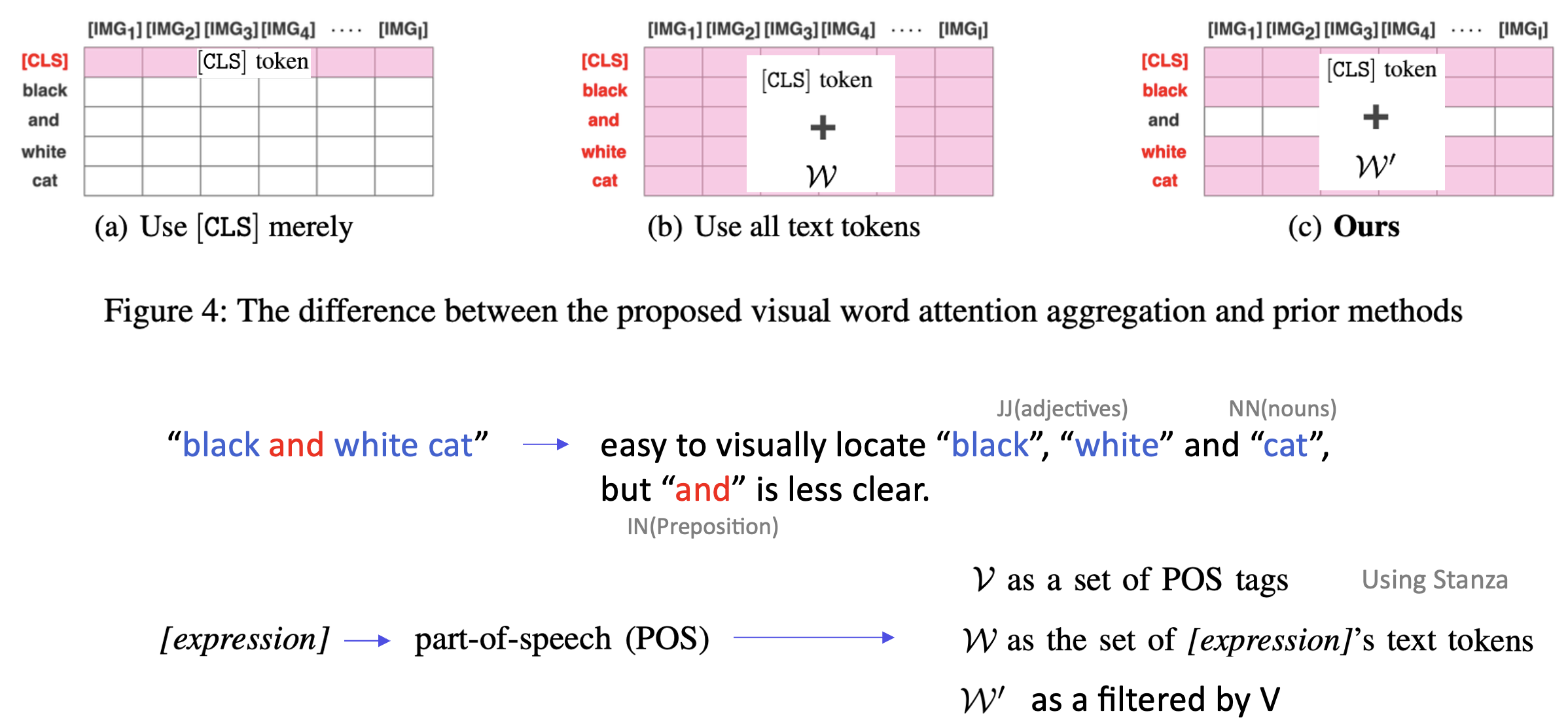
저자들은 이미지 토큰(IMG)과 텍스트 토큰(TEXT) 간의 연관성을 계산할 때, 기존 방법과 차이를 두는 Visual-Word Attention Aggregation 방법론을 제안하여 임베딩합니다.
- (a) (기존)[CLS] 토큰만 사용: 기존 방식에서는 텍스트 표현([expression])을 단일 [CLS] 토큰으로 요약하여 시각적 연결성을 계산합니다.
- (b) (기존) 모든 텍스트 토큰 사용: 모든 텍스트 토큰을 활용해 연관성을 계산합니다.
- (c) 제안된 방법:
- [CLS] 토큰과 함께 POS(Part-of-Speech) 필터링을 적용하여 시각적으로 더 관련 있는 텍스트 토큰 (W’)을 선택합니다.
- 텍스트 쿼리에서 이미지 내에 localizable하게 유의미하다고 생각되는 특정 부분(예: 명사(NN), 형용사(JJ))만 포함해 잡음을 줄인다고 합니다. (하지만, 세미나 때 상인님께서도 질문해주셨듯이, 위 그림의 예시에서 and가 빠지는 게 과연 잡음을 줄이는 데 도움이 될까 싶습니다. and가 중요한 semantic한 의미로써 작용이 될 수도 있는데 말입니다..)
[Heat-map for Region-Based Models]
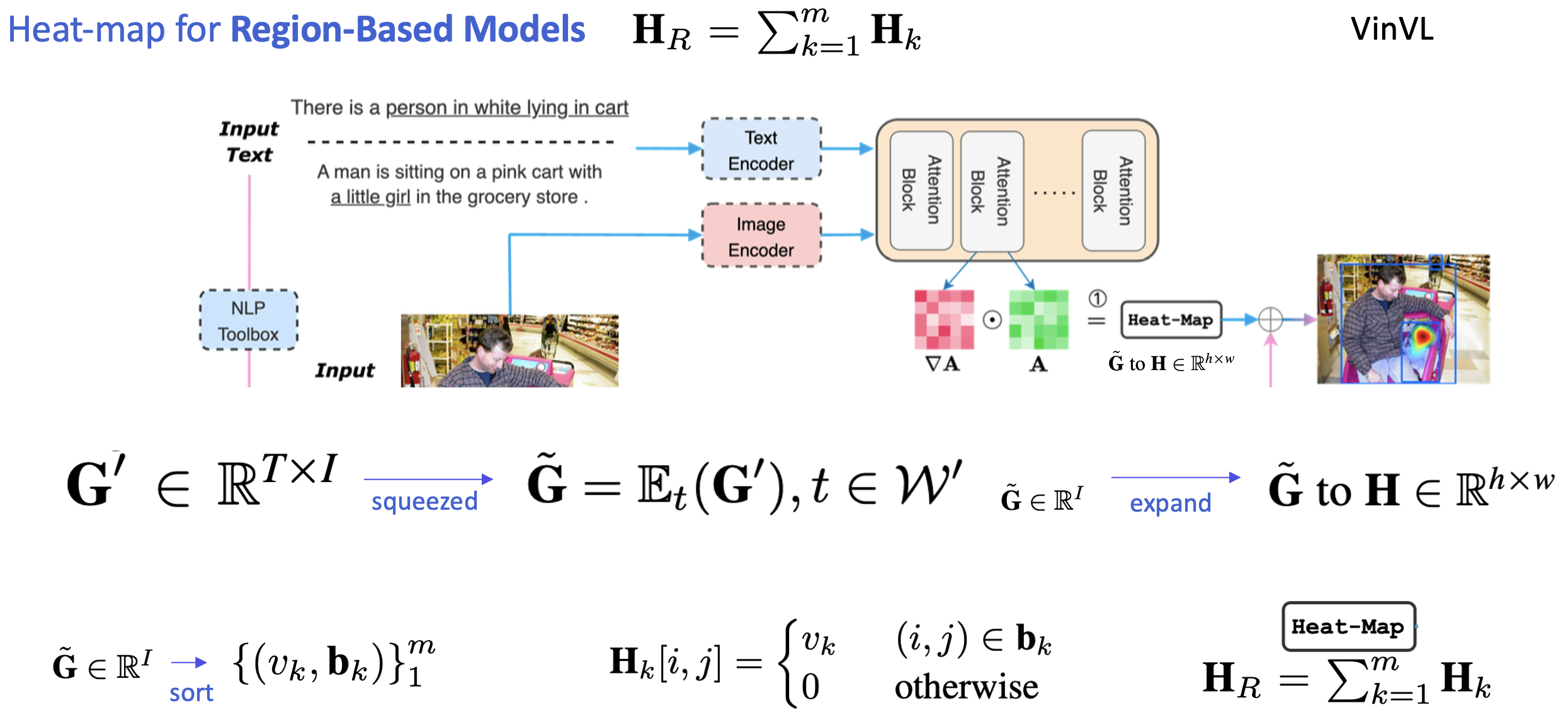
이제 VLP가 Region-based model이냐, end-to-end based model이냐에 따라 heat-map을 생성하는 부분의 수식이 미묘하게 달라져 적용됩니다.
- GradCAM을 통해 텍스트와 이미지 간의 attention map G' (G' \in \mathbb{R}^{T \times I})를 계산합니다.
- G'를 텍스트 차원에서 평균(\mathbb{E}_t)을 취하여 \tilde{G} \in \mathbb{R}^I로 압축합니다. 여기서 텍스트 토큰 집합 W'가 필터링된 토큰입니다: \tilde{G} = \mathbb{E}_t(G'), \, t \in W'
- \tilde{G}를 내림차순으로 정렬하여 상위 m개의 토큰에 대한 값 v_k와 위치 b_k를 추출합니다.
- 각 b_k 영역에 대해 히트맵 H_k를 계산합니다: H_k[i, j] = \begin{cases} v_k, & (i, j) \in b_k \\ 0, & \text{otherwise} \end{cases}
- 최종 히트맵 H_R는 모든 H_k의 합으로 계산됩니다: H_R = \sum_{k=1}^m H_k
- 이 히트맵은 이후 Open Vocabulary Detection(OVD)와의 융합 과정에서 각 객체 상자의 가중치를 계산하는 데 사용됩니다.
[Heat-map for End-to-End Models]
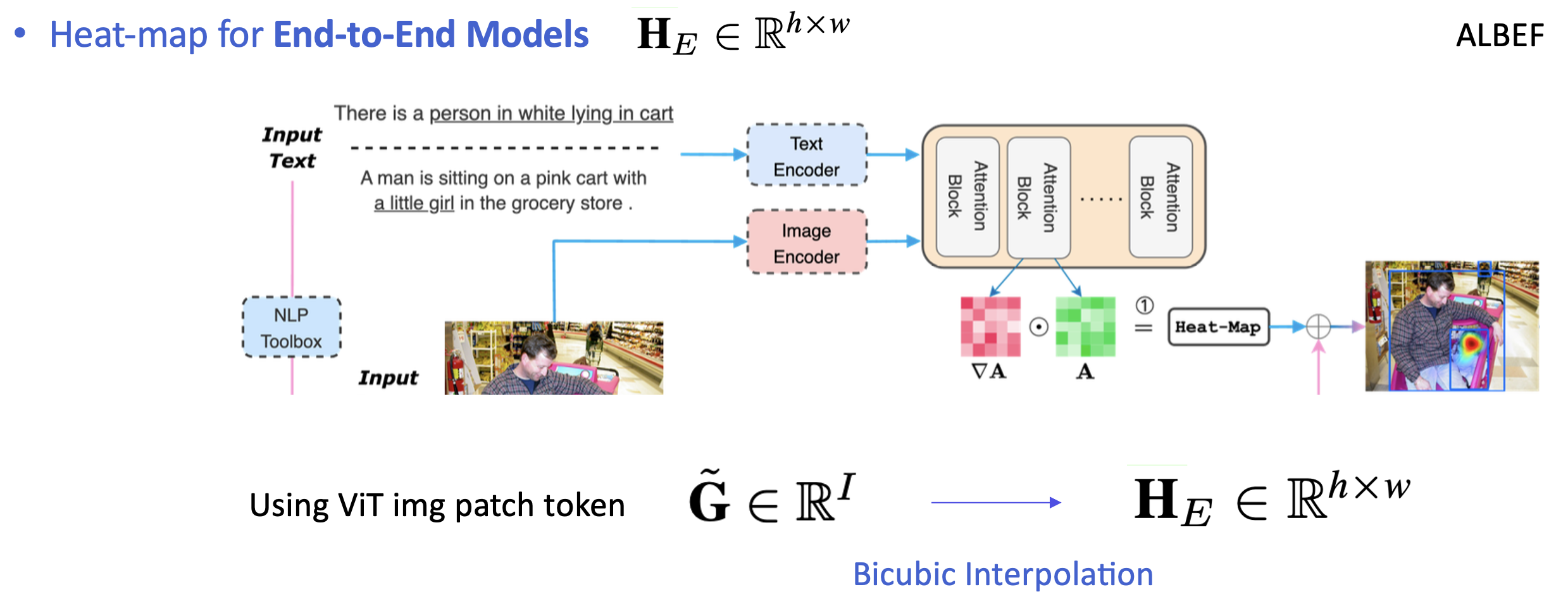
attention map \tilde{G} \in \mathbb{R}^I는 텍스트와 이미지 간의 GradCAM 기반 연관성을 나타냅니다. 이 \tilde{G}를 Bicubic Interpolation을 사용해 히트맵 H_E \in \mathbb{R}^{h \times w}로 변환합니다.여기서 E는 End-to-End 모델을 의미합니다.
Fusion with Open-Vocabulary Detectors
[Category Extraction]
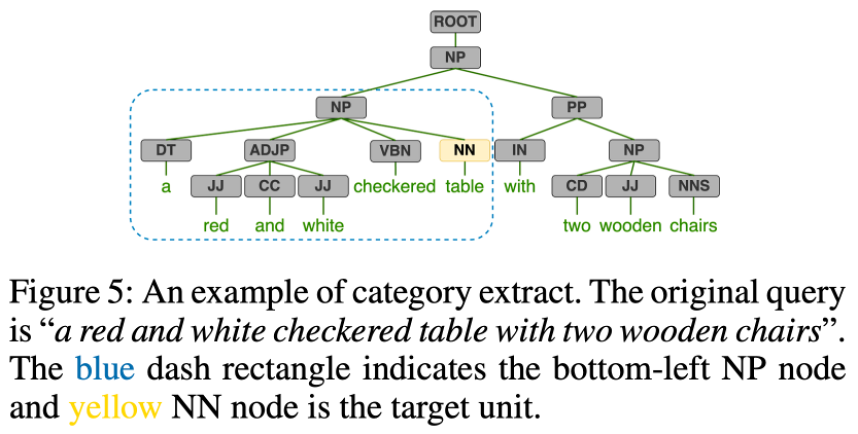
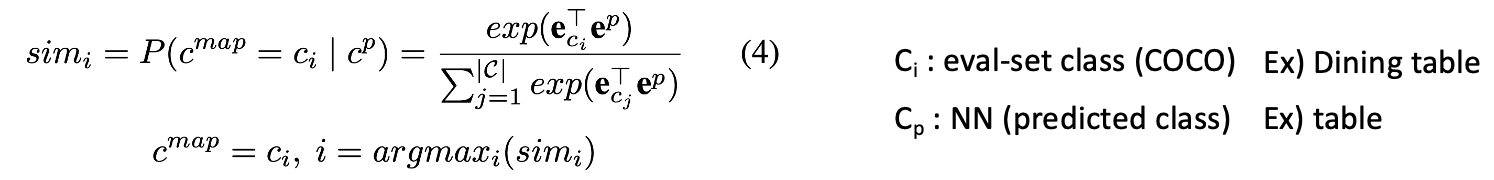
카테고리 추출(Category Extraction):
- 목적: Zero-shot 설정에서 텍스트 쿼리([expression])에서 추출된 예측 카테고리를 평가 데이터셋의 클래스 어휘에 매핑하여 Ground-Truth(GT) 카테고리와 일치시키는 것.
- 방식:
- 의존 트리(Dependency Tree): NLP Toolbox를 사용하여 [expression]에 대해 의존 트리를 생성.
- NP(Noun Phrase)의 좌하단에서 최우측 Normal Noun(NN) 노드를 타겟 카테고리로 설정.
- 카테고리 매핑:
- 예측 카테고리 cpc_pcp를 평가 데이터셋의 클래스 어휘(C)에 매핑하여 c_{\text{map}}을 생성.
- 이를 위해 CLIP을 사용해 c_p와 C의 각 클래스 c_ic를 동일한 임베딩 공간으로 투영.
- 유사도 계산: c_pc와 각 c_i 간의 코사인 유사도를 계산 후 softmax로 정규화하여 최대 유사도를 가지는 c_{\text{map}}을 최종 카테고리로 선정.
- 의존 트리(Dependency Tree): NLP Toolbox를 사용하여 [expression]에 대해 의존 트리를 생성.
[Generating Candidate Boxes]

Open Vocabulary Detector(OVD)는 주어진 이미지(I), 사전 정의된 카테고리(C), 점수 임계값(θ)을 기반으로 객체를 탐지하여 N개의 후보 박스를 반환합니다. 각 후보는 다음과 같은 형태로 정의됩니다:
- 결과: \{(s_k, \text{box}_k)\}_{k=1}^N = \text{OVD}(C, \theta, I)
- s_k: 박스(\text{box}_k) 안의 객체가 C에 속할 확률.
- \text{box}_k = (x_{k1}, y_{k1}, x_{k2}, y_{k2}): 객체의 경계 상자 좌표.
- 신뢰도 조건: s_k = P(o_k \in C \mid I), \, s_k > \theta
OVD는 높은 신뢰도의 후보만 선택해 후속 작업(Visual Grounding, Object Detection)에서 활용되는 효율적인 proposal을 제공하게 됩니다.
[Weighted Grade]
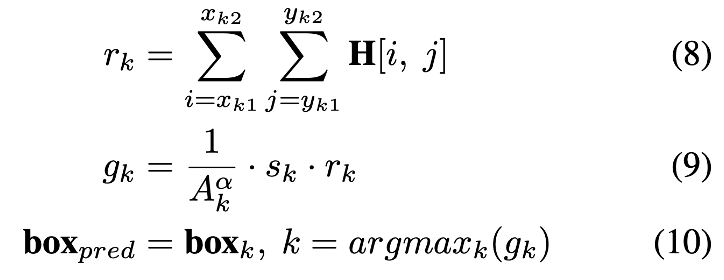
마지막으로 직면한 중요한 과제는 θ의 값을 인증하는 것입니다. θ가 너무 낮게 설정되면 c에 속하지 않는 과잉 상자가 포함될 수 있습니다. 반대로 θ가 너무 높으면 c에 속하는 특정 박스가 누락될 수 있습니다. 그래서 저자들은 상대적으로 낮은 임계값을 설정 –> sk를 rk의 가중치로 하는 공식 제안합니다. rk는 박스k 영역의 총 히트맵 value이고, 이를 통해 c에 해당하는 박스가 누락되지 않도록 하고 점수가 낮은 박스가 결과를 왜곡하지 않도록 균형을 맞추게 됩니다. 마지막으로, (sk , boxk)의 가중치를 나타내는 gk를 계산하고 가장 높은 등급을 가진 boxpred를 GroundVLP의 예측으로 출력하는 것으로 최종 output이 생성되게 됩니다. 만약 box가 없다면?! 다시 모든 박스 사용하는 방식으로 대체한다고 합니다.
4. Experiments
Experiments Settings
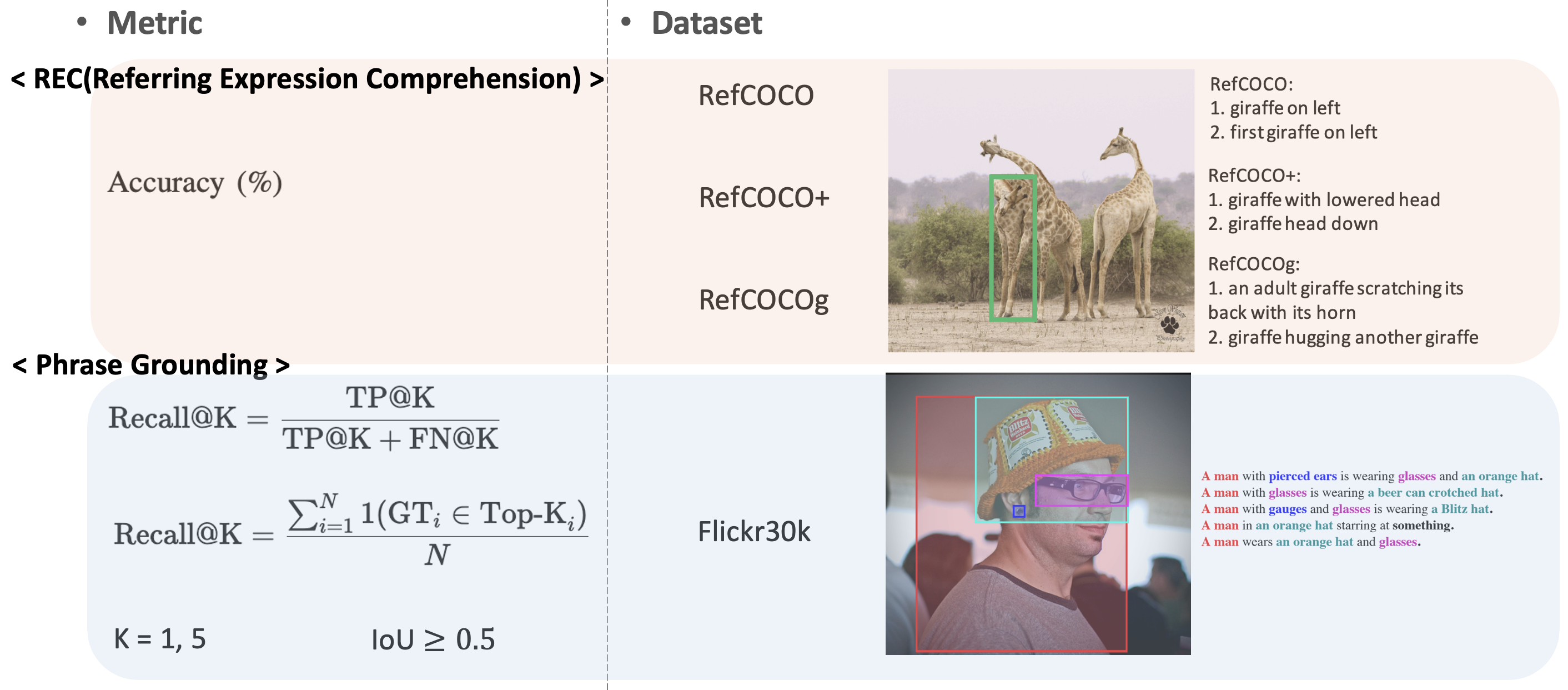
보통 visual-grounding 태스크에서는 RefCOCO 형제들과, Flickr30k 벤치마크가 많이 활용되는 경향성이 있었습니다. 각 데이터셋 별로 특성이 조금씩 달라 구분하여 다뤄보겠습니다.
RefCOCO: 위치 기반 지시 표현이 많은 데이터셋.
RefCOCO+: 속성 정보(색상, 크기 등)에 의존하는 더 어려운 데이터셋.
RefCOCOg: 문맥 정보를 고려해야 하는 긴 문장 데이터셋.
Flickr30k Entities: 모든 명사구(noun phrases)를 이미지 객체와 연결해야 하는 Phrase Grounding 데이터셋.
Acc를 사용하는 이유는, 본 GroundVLP는 OVD에서 proposal된 bbox가 히트맵이랑 결합해서 적절한 class를 선택하게 됐냐가 관점이므로, 직접 bbox를 예측하고자 하는 것이 아니라 OVD를 사용해 proposal을 뱉을 거니까, box regression보단 classification을 고려하는 것 같습니다. Recall의 경우는 실제로 존재하는 정답(Ground Truth) 객체들 중에서 모델이 얼마나 잘 검출했는지를 측정하는데, Zero-shot Visual Grounding 작업에서 중요한 것은 텍스트 표현에 기반하여 최대한 많은 관련 객체를 정확히 찾는 것이므로, Recall@k를 이용하여 평가하는 경향을 보입니다.
Eval – REC
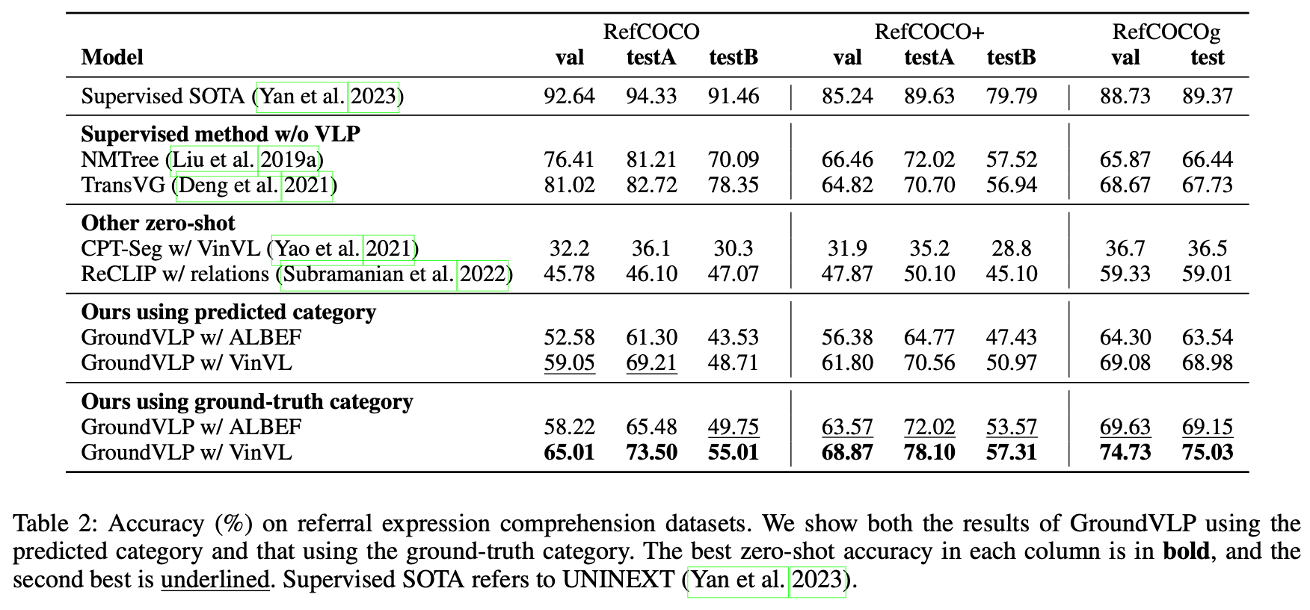
GroundVLP는 VLP(Vision-Language Pretraining)의 장점을 활용하여 RefCOCO/+/g 데이터셋에서 강력한 성능을 보여줍니다. GroundVLP는 이 VLP의 semantic 특성을 잘 활용함으로써 zero-shot 환경에서도 non-VLP-supervised 모델을 능가하는 결과를 달성합니다. 표에 드러나는 쿼리 유형은 val, testA, testB로 나뉘는데, 다음과 같습니다.
- 쿼리 유형(testA vs. testB):
- testA(Person Type): 사람과 관련된 참조 표현을 나타냄.
- testB(Other Type): 비-사람 객체와 관련된 참조 표현을 포함.
- GroundVLP는 특히 Person Type 쿼리(testA)에서 더 강력한 성능을 보여줍니다. 이는 사람 객체가 semantic context에서 더 풍부한 정보를 제공하고, 모델이 이를 잘 이해하도록 설계되었음을 의미합니다.
또한 GroundVLP는 예측된 카테고리(predicted category) 기반의 결과에서도 non-VLP-supervised 모델과 경쟁하지만, Ground Truth(GT) category를 사용했을 때 더욱 강력한 성능을 발휘합니다. GT 카테고리를 사용하면, 모델이 noise와 잘못된 카테고리 매핑 문제를 피할 수 있어 RefCOCO/+/g 모든 데이터셋에서 supervised VLP 기반 모델도 능가하게 됩니다.
- GroundVLP는 VLP(Vision-Language Pretraining)의 장점을 활용하여 RefCOCO/+/g 데이터셋에서 강력한 성능을 보여줍니다.
- 데이터셋의 특성:
- RefCOCO/+/g는 객체의 위치 정보뿐 아니라 텍스트 표현의 semantic한 특성을 모델링해야 하는 쿼리가 포함되어 있습니다.
- GroundVLP는 이 semantic 특성을 잘 활용함으로써 zero-shot 환경에서도 non-VLP-supervised 모델을 능가하는 결과를 달성합니다.
그렇지만 한계도 있다고 합니다. 저자들은 실험 중 마주한 한계를 다음과 같이 분석하고 정의했습니다.
- 참조 대상이 불명확한 경우:
- 쿼리 자체에서 대상 단위가 명확하지 않아 모델이 참조 대상을 올바르게 매핑하지 못할 수 있습니다.
- 예: “검은 모자”는 검은 모자를 쓴 사람을 나타내지만, “모자”만 추출되면 사람 객체와 매핑되지 않아 오류를 초래.
- 훈련되지 않은 문법:
- RefCOCO/+/g에는 NLP 도구 상자가 처리하지 못하는 비정형 문법이 포함되어 있습니다.
- 예: “woman wearing red coat”는 도구에서 “red”를 설명하는 형용사로 간주하고 “coat”만을 대상으로 처리하여 오류를 발생.
- 쿼리에 대상이 없는 경우:
- 참조 대상이 없는 쿼리(예: “left” 또는 “the closest to you”)는 모델이 COCO 클래스에 정확히 매핑하지 못하게 하며, 이는 성능 저하로 이어집니다.
Eval – Phrase Grounding
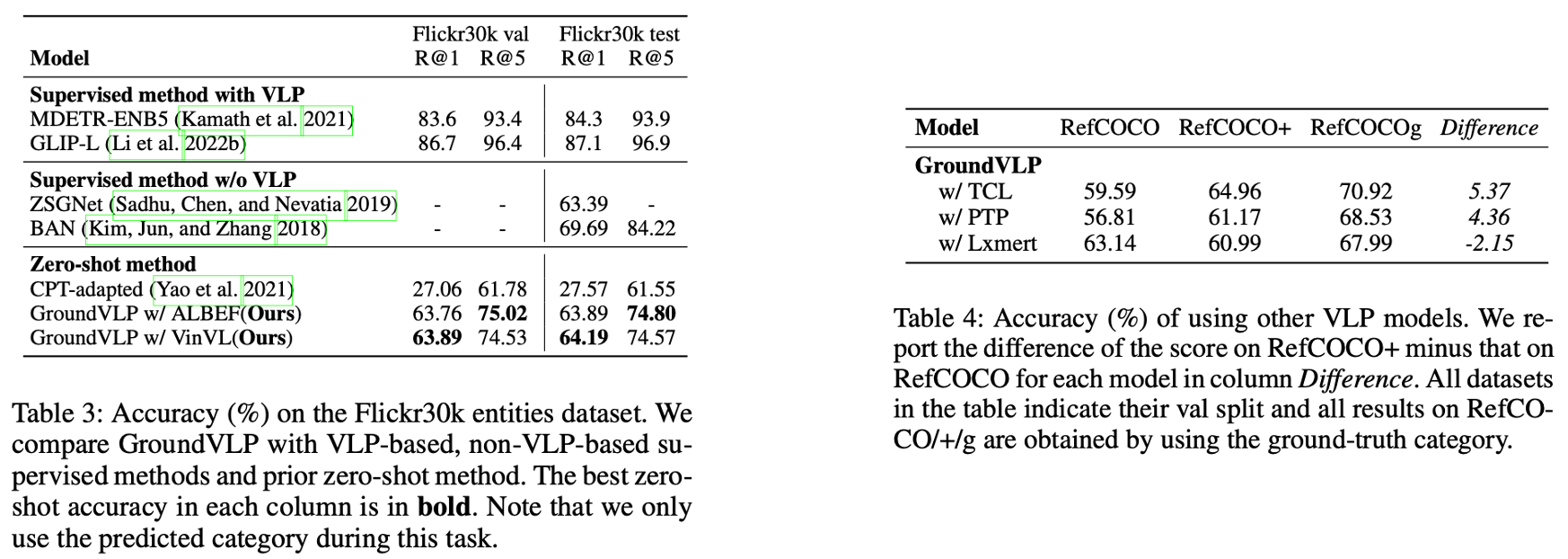
GroundVLP는 더 복잡한 속성이나 행동, 상태를 묘사한 쿼리가 포함된 데이터셋에서 더 높은 성능을 보이는 경향이 있습니다. 예를 들어, 단순히 객체의 위치를 묻는 쿼리보다 객체의 상태나 속성을 명시한 쿼리에서 GroundVLP의 성능이 두드러집니다. 이는 VLP(Vision-Language Pretraining)가 semantic 정보를 잘 학습했기 때문이며, 이는 VLP의 강력한 사전 학습이 GroundVLP의 성능을 뒷받침했음을 의미하고 향후 제로샷 시각적 언어 태스크에서 GroundVLP가 중요한 기반 기술로 자리 잡을 가능성을 보여줍니다.
- Supervised 방법:
- MDETR-ENB5(Kamath et al., 2021) 및 GLIP-Li(Li et al., 2022)의 supervised 방법은 여전히 높은 성능을 보이며, R@1 및 R@5 모두 GroundVLP를 능가합니다.
- 이는 대규모 학습 데이터에 기반한 fine-tuning이 supervised 방법론의 성능을 강화했기 때문입니다.
- Zero-shot 방법:
- GroundVLP는 기존 제로샷 방법(CPT-adapted, Yao et al., 2021)과 비교했을 때 현저히 높은 Recall 성능을 기록합니다.
- 특히 Flickr30k val/test 데이터셋에서 GroundVLP는 R@1, R@5 모두에서 큰 격차를 보이며 성능 우위를 입증했습니다.
- 예: CPT-adapted 대비 36.09%(Flickr30k val R@1 기준) 향상.
Ablation Study – Weighted Grade
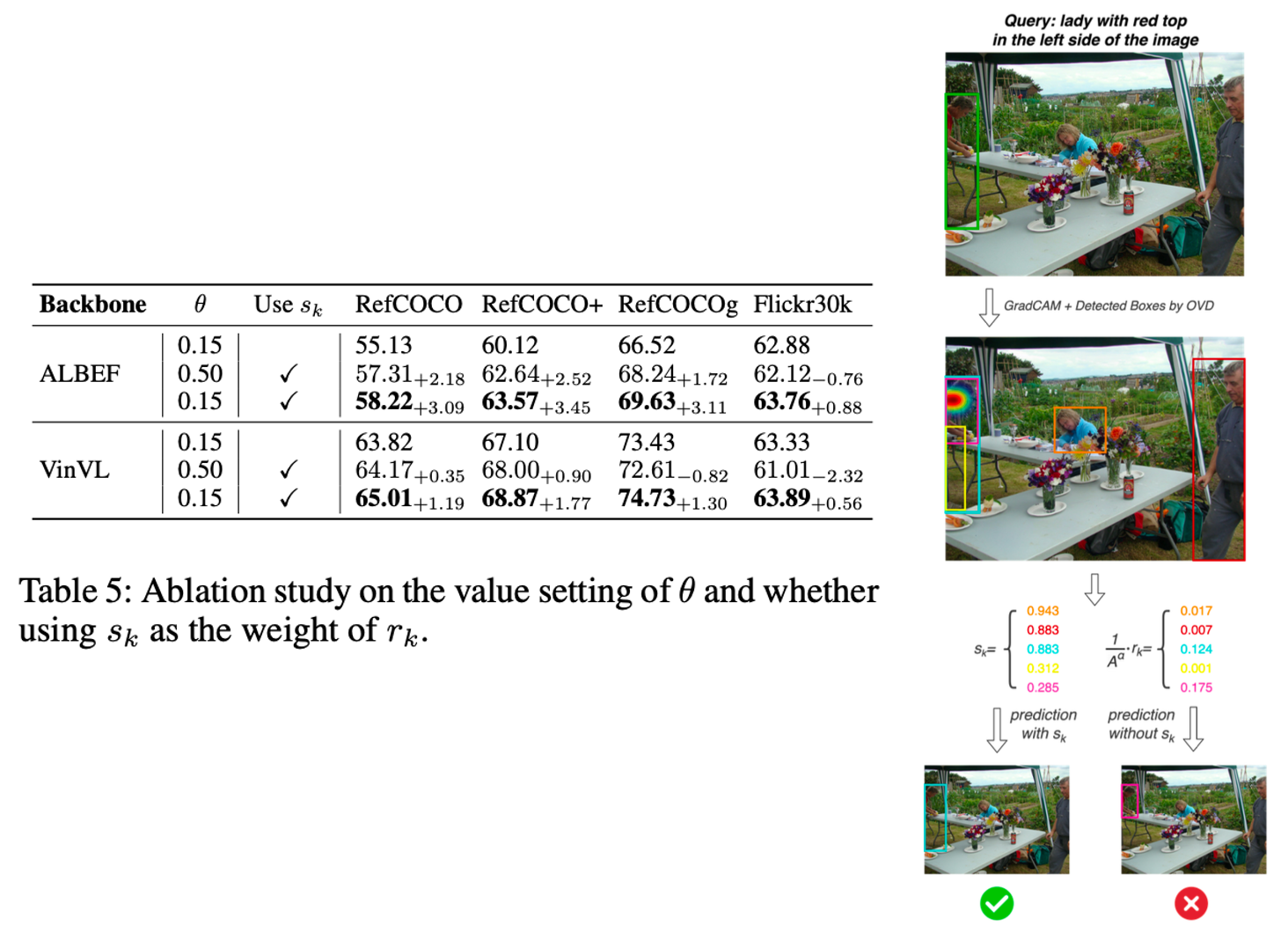
- θ 값 설정:
- θ 낮음 (0.15): 보다 강한 제약을 적용하여 노이즈 후보를 배제하지만, 필요한 후보까지 필터링될 위험이 있음.
- θ 높음 (0.50): 필터링 강도가 낮아 더 많은 후보를 포함하지만, 노이즈 증가로 인해 성능 저하 가능성.
- 가중치 s_k 사용:
- 사용하지 않을 때: 이미지와 텍스트의 매핑 강도를 고려하지 않아 적합하지 않은 후보가 선택될 가능성이 높아짐.
- 사용할 때: GradCAM과 OVD 기반 후보를 가중치로 결합하여 적합성을 강화, 예측 정확도 향상.
- ALBEF Backbone:
- 최적의 조합인 θ 낮음 + s_k 사용 시, 가장 높은 성능을 기록(예: RefCOCO 58.22, RefCOCO+ 63.57).
- VinVL Backbone:
- 특히 RefCOCOg와 같은 더 복잡한 데이터셋에서 성능 향상이 두드러짐(예: RefCOCOg 74.73).
- s_k를 적용하지 않은 경우, GradCAM이 탐지한 중요한 영역이 후보 점수에 반영되지 않아 부정확한 예측이 발생할 가능성이 있었다고 하며 저자들은 위의 오른쪽 그림을 예시로 가져왔는데, 사실 저는 너무 gt annotation에 편향된 결과를 내려고 한 거 아닌가 라는 생각이 들었습니다. 사실 x표시된 빨간 박스가 더 합리적으로 사람을 찾은 것이라고 생각이 들거든요.
아무튼 좀 찝찝하긴 하지만 결론적으로 θ를 낮게 설정(0.15)하여 강한 필터링을 적용하면서, 가중치 s_k를 활용해 중요한 후보를 강화하는 방식이 가장 효과적이었으며, 이는 GradCAM과 OVD 후보의 결합이 단순 필터링을 넘어, 시각적 언어 매핑에서 중요한 역할을 함을 시사했습니다.
Ablation Study – etc..
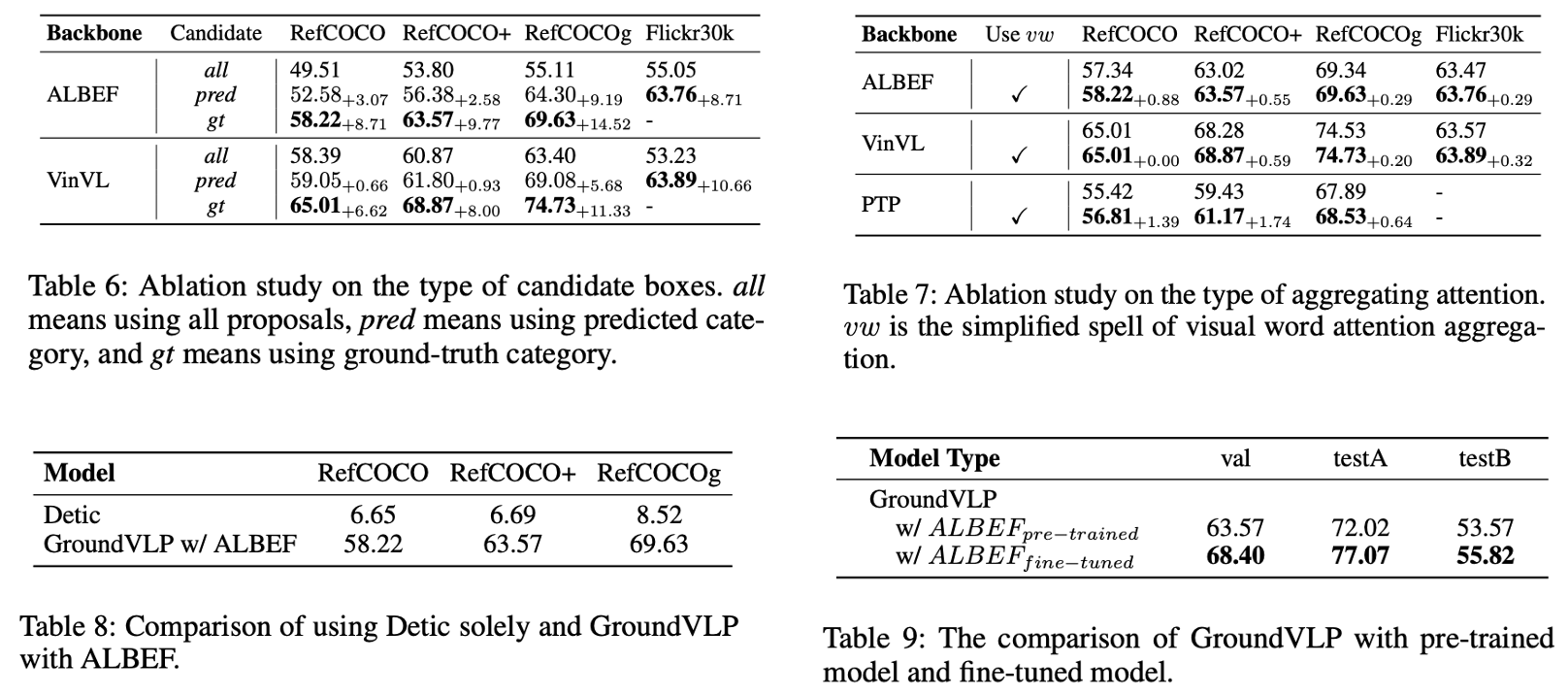
<Table 6: Candidate Box 유형별>
- Predicted Category vs. Ground Truth (GT) Category:
- GT 카테고리를 사용한 경우 성능이 크게 향상되었음.
- 그러나 GT를 사용하는 것은 완전한 zero-shot 환경이라고 보긴 어렵다는 한계가 있음.
<Table 7: Attention Aggregation 방식>
- GradCAM Attention Map 생성 시, 시각적으로 인식 가능한 단어로만 구성한 경우 성능이 더 좋음.
- 예: ‘and’, ‘the’ 같은 불필요한 단어를 제거하여 더 정확한 Attention Map을 생성.
<Table 8: OVD 단독 적용 vs. VLP 통합>
- OVD(Object Detection) 단독으로는 Visual Grounding이 제대로 수행되지 않음.
- OVD + VLP 모델을 결합했을 때 Visual Grounding이 가능해졌고, 성능이 크게 향상됨.
<Table 9: Zero-shot vs. Fine-tuning>
- Fine-tuned 모델은 zero-shot보다 당연히 높은 성능을 보임.
- 예: RefCOCO val에서 Fine-tuning으로 약 5.37% 성능 향상.
Qualitative results – REC
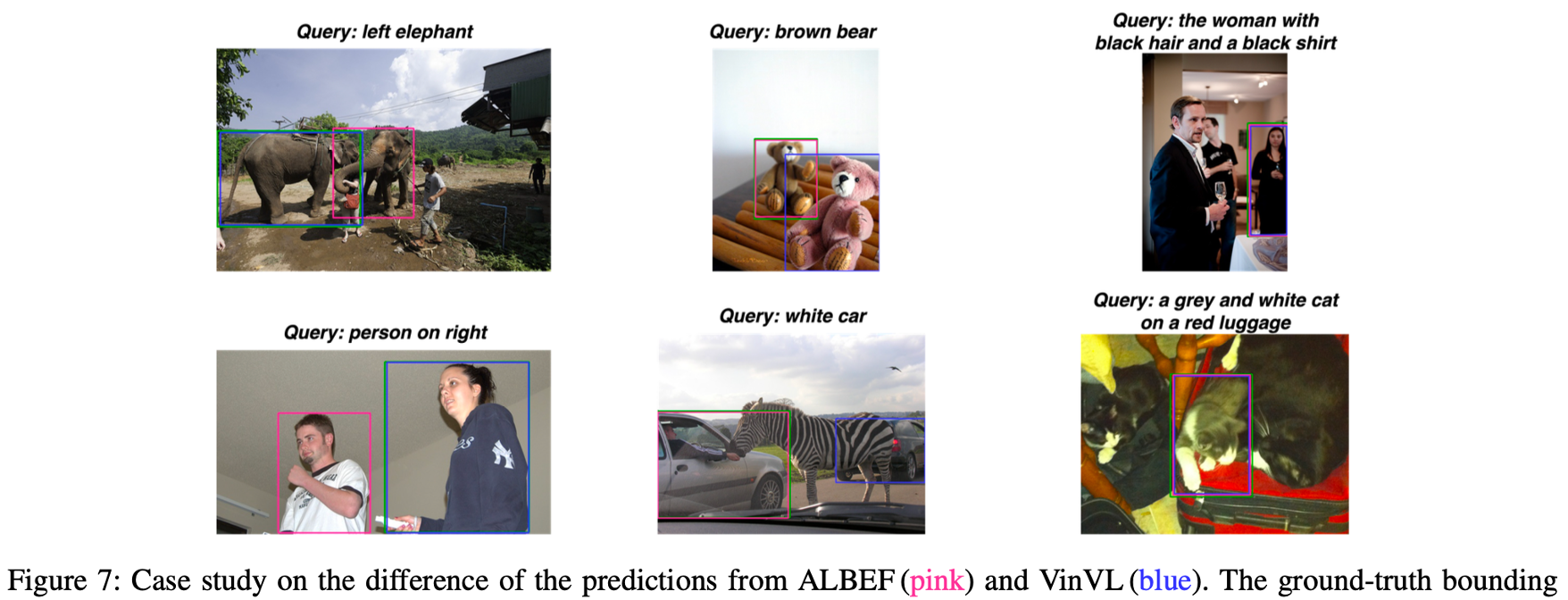
ALBEF = end to end VLP 모델이므로 localization 관련 특성에 약한 모습을 보이고, VinVL = region-based 모델로 semantic 특성에 약한 모습을 보였습니다.
Qualitative results – REC (GT category using?)

앞선 method 중 카테고리 추출(Category Extraction) 에서 Gt category 쓰면 더 잘 잡는 경향이 있고, Pred category만 쓰면 textual noise로 인해 잘 못 잡는 경향이 있습니다. 근데 사실 이건, GT category를 쓴다는 게 과연 온전한 zero-shot 태스크라고 할 수 있을까 싶어서, 이 부분은 리뷰어들에게 어떻게 받아들여졌는지 좀 궁금하네요. 개인적인 생각으로는 저자들이 ablation 중 table 9와 conclusion에 fine-tuned에 대한 성능 또한 reporting 한 것으로 보아, 자기네들 것이 완전 zero-shot이 아니고 gt category 참고하면 오히려 성능이 올라가니 좋은 게 좋은 거 아니냐~ 라는 식으로 어찌어찌 막은 것 같습니다.
5. Conculsion
GroundVLP는 이미지-텍스트 쌍과 객체 감지 데이터를 기반으로 학습된 모델을 결합(VLP+OVD, with GradCAM)한 zero-shot visual grounding 태스크입니다. VLP에서 GradCAM을 뽑아내서 처리하고, OVD에서 proposal을 뽑아내고 여기서 특히 GradCAM을 가중치의 형태로 합쳐서 proposal 중 괜찮은 prediction을 가져가겠다는 것이 흥미로웠습니다. 특히 GradCAM의 역전파? 부분은 코드를 살펴봐도 조금 이해하기 힘든 부분이 있어서 다루지 못했습니다. 이 부분 댓글 남겨주시면 추후에 시간 들여 더 찾아보고 답글 남기도록 하겠습니다.
GroundVLP의 limitation으로는 기존 VLP나 OVD 모델들이 가지고 있는 bias나 error 등을 그대로 상속하게 된다는 문제가 있습니다. 그럼에도 저자들은 VLP+OVD 형식이 plug and play 방식으로 설계되어 있기 때문에, 향후 더 강력하고 개선된 백본 모델이 나오면 이를 재통합하여 bias나 error등의 한계를 극복할 수 있을 것이라고 주장하면서 마무리하네요.
이상 리뷰 마치겠습니다. 감사합니다.
안녕하세요 재찬님 좋은 리뷰 감사합니다.
GradCAM을 활용하여 히트맵을 추출하는 과정에서 시각적으로 인식 가능한 단어에만 집계하여 텍스트와 이미지 간 모달리티 매핑을 최적화한다고 하셨는데 시각적으로 인식 가능한 단어라는 것은 이미지 내 객체만을 집계하는 것인가요? 그렇게 된다면 Object Detection을 통한 후보 객체 검출과 어떠한 차이점이 있는 것인지 궁금합니다.
감사합니다.
안녕하세요 성준님, 리뷰 읽어주셔서 감사합니다.
시각적으로 인식 가능한 단어라 함은 VLP+GradCAM+OVD로 구성되는 Method 세부 방식 중, VLP에서의 Visual-Word Attention Aggregation 파트에서 언급되는 내용이라고 이해하시면 될 것 같습니다. 해당 파트는 이미지 토큰과 텍스트 토큰 간의 연관성을 계산할 때 모든 텍스트 토큰을 사용하지 않고, 텍스트 쿼리에서 이미지 내에 localizable하게 유의미하다고 생각되는 특정 토큰(명사, 형용사 등등)만 포함하는 것을 의미합니다.
즉, 이미지 내 ‘객체’만을 집계하는 것이라고 단정할 순 없고, 이미지 내의 어떤 동작 상태, semantic하거나 localizable한 정보까지만 추려서 토큰을 집계하고 싶었던 것이라고 이해하시면 될 것 같습니다.
그런 다음 위의 방식을 통한 VLP+GradCAM 을 통해 나온 결과(heatmap value)를 OVD를 통한 후보 객체 검출에서 weighted grade로써 활용하며, OVD proposal 들에서 최종 output proposal을 택하는 방식을 취하게 됩니다.
감사합니다.