아카이브에 2024년 12월에 개제된 논문입니다. ICLR 2025에 제출했다가 취소한 것으로 보이는데.. sequential 3D affordance reasoning이라는 새로운 task를 제안하였다는 것이 흥미로워 리뷰를 하게 되었습니다.
Abstract
3D affordance segmentation은 사용자의 명령어에 대응되는 객체의 조작가능한 영역을 연결하는 것을 목표로하며, 기존 연구들은 single-object와 single-affordance 형식으로 이루어졌으며, 명시적인 명령어나 affordance type이 객체의 특정 영역으로 정해져있어 long-horizon task(복잡한 명령)를 처리하기가 어려웠습니다. 이러한 기존 연구의 형식은 순차적인 affordance를 포함하는 복잡한 사용자의 의도를 추론하는 데 어려움이 있었으며, 해당 논문은 이러한 복잡한 작업을 처리하기 위한 Sequential 3D Affordance Reasoning task를 제안합니다. Sequential 3D Affordance Reasoning은 사용자의 의도를 추론하고 연속적인 3D segmentation map으로 작업을 분해하도록 전통적인 프레임워크를 확장하였으며, 이를 위해 저자들은 지시문 기반의 affordance segmentation 벤치마크를 구축하였습니다. 또한, 해당 벤치마크를 이용하여 affordance segmentation 능력을 갖춘 SegAfford라는 3D muti-modal large language 모델을 제안하였으며, multi-granular language-point integration 모듈을 제안하여 3D dense prediction을 수행합니다. 저자들은 실험을 통해 open-world에서 기존 연구를 뛰어넘는 일반화 성능을 보였다고 합니다.
Introduction
Affordance는 사람과 embodied agents가 주변의 물체와 상호작용을 하기 위해 중요한 정보입니다. 2D affordance는 시각적인 정보를 수행할 작업과 연결하여 사물에서 조작 가능한 영역을 강조하는 것을 목표로 하며, 3D affordance는 실제 3차원 세계에서 작업을 수행하기 위해 더 직접적인 정보를 제공하여 로봇이 실제로 manipulation을 수행할 수 있도록 정보를 제공합니다.
기존의 3D affordance 연구의 경우 single-object와 single-affordance 형식으로 이루어져있으며, 최근에는 LLM을 이용하여 자연어 질문에 대응되는 특정 affordance를 인식하도록 설계된 언어 모델을 사용한 연구들이 진행되고있습니다. 예시로 “How can you go through the door?”라는 질문이 주어지면, BERT와 RoBEART를 이용하여 “openable” affordance인 문 손잡이를 찾는 식으로 이루어져있습니다. 그러나 affordance type이 고정되어있으며, 이러한 현재 시스템은 사용자의 복잡한 의도를 추론하여 이를 세분화하여 여러 객체에 대한 연속적인 affordance를 추론하기에는 어려움이 있습니다. 예를 들면, 그릇 안에 있는 음식을 전자레인지로 데워달라는 지시가 주어졌을 때, 이를 그릇을 잡고, 전자레인지를 열고 음식을 넣고 버튼을 누르는 연속적인 affordance를 추론하지는 못한다는 것을 의미합니다.
최근 대규모 데이터로 학습된 LLM이 상식적인 지식을 활용하여 순차적인 추론을 할 수 있음이 입증되었으며, MLLm의 등장으로 3차원에서 다양한 물체의 형태를 이해하는 능력도 개선되었으나, 여전히 객체 중심의 text 답변을 생성하는 작업에 집중을 맞추고 있으므로, 3D 객체에 대한 dense affordance 정보를 추론하는 것에는 어려움이 있습니다. 따라서 저자들은 해당 논문을 통해 사용자의 복잡한 지시에 대하여 순차적으로 affordance를 추론하고 이를 세분화할 수 있는 3D multi-modal Large Language 모델을 고안하고자 하였습니다.
이를 위해 저자들은 새로운 Sequential 3D affordance Reasnoning이라는 새로운 task를 제안하였으며, 이를 위해 벤치마크를 구축하였습니다. 또한, SeqAfford라는 순차적으로 affordance를 추론할 수 있는 3D multi-modal Large Langue 모델을 제안하였으며, dense affordance prediction을 위해 multi-granular language-point integration 모듈을 설계하였습니다.
Dataset
affordance segmentation을 위해서는 다양한 맥락에서 사물의 작동 능력을 이해해야 하며, 사용자의 의도가 복잡하고 다양하므로 이를 모두 이해하는 것에는 어려움이 있습니다. 단순한 지시문은 컵을 잡거나, 문을 열기와 같이 대상 물체를 직접적으로 이용하는 것과 관련이 있으며, 복잡한 지시문은 여러 단계의 동작으로 이루어져있거나 특정 상황이나 목적을 위해서 컵을 이용하는 것 과같이 맥락을 이해해야 합니다. 이러한 단순한 지시와 복잡한 지시를 모두 다루기 위해 저자들은 3D affordanceNet을 기반으로 단순 및 복잡한 의도를 포함한 지시문을 생성하여 point cloud와 대응되는 데이터 셋을 구축하였으며, 단일 afforcane segmentation을 위한 162,386개의 지시문-point cloud 쌍과 순차적인 affordance segmentation을 위한 20,847개의 지시문-point cloud 쌍으로 구성하였습니다. 해당 데이터 셋은 23개의 카테고리에 대해 18,371개의 instance로 구성됩니다.
1. Dataset Collection
Point Cloud
3D AffordanceNet 데이터를 사용하였으며, 각 affordance에 대해 단순 명령어 5개를 설정하였으며, 순차적인 affordance에 대해서는 point cloud의 affordance 구성으로부터 여러 조합에 해당하는 지시문을 생성하였다고 합니다.
Instruction

저자들의 데이터 셋 구성 관련 기여는 지시문을 생성하는 과정에 해당하게 됩니다. 이러한 지시문 생성을 위해 저자들은 GPT-4를 이용하여 4가지 방식을 제안하며, 위의 Figure 2는 해당 과정에 대한 이미지입니다. 단순히 text로부터 affordance segmentation에 대한 지시문을 생성하기도 하며, 3D mesh를 랜더링한 이미지와 text 정보를 함께 입력하기도 하며, 추가로 해당 객체를 사람이 사용하고있는 HOI(human object interaction) 이미지를 함께 입력하거나 시나리오에 대한 text 정보를 함께 제공하기도 합니다.
단순히 정리하자면 여러가지 데이터를 조합하여 GPT에 입력하여 지시문을 만들었다는 것으로 이해가 되며, 해당 과정에 대해서는 자세한 설명은 따로 없었습니다. 데이터 관점에서는 지시문을 만드는 부분이 contribution에 해당하는데, 이에 대해 어떻게 데이터를 생성하였고, 이렇게 생성된 지시문에 대한 검증을 수행하였는지, 각각의 입력 조합이 단순 및 연속적인 affordance segmentation에 대한 지시문을 만들때는 어떻게 적용이 되는 지 설명이 따로 없어서 아쉽습니다..
2. Statics and Analysis
저자들의 데이터는 단일 affordance segmentation에 대해 162,386개의 지시문-point cloud 쌍으로 이루어지며, 연속적인 affordance segmentation에 대해 20,847개의 지시문-point cloud 쌍으로 구성된 데이터 셋으로, 23개의 카테고리에 대해 18,371개의 instance로 구성됩니다. 또한 Unseen과 Seen으로 split을 나누었다고 합니다.(이에 대해 카테고리 수를 어떻게 나누고, 그에 대한 instance 수는 어떤지도 이야기하지 않고있습니다.)

위의 Table1은 저자들이 제안한 데이터 셋을 기존 데이터 셋과 비교하는 것으로, 어떤점이 기존 데이터와 다르게 고려가 되었는지를 어필하고있습니다
Method
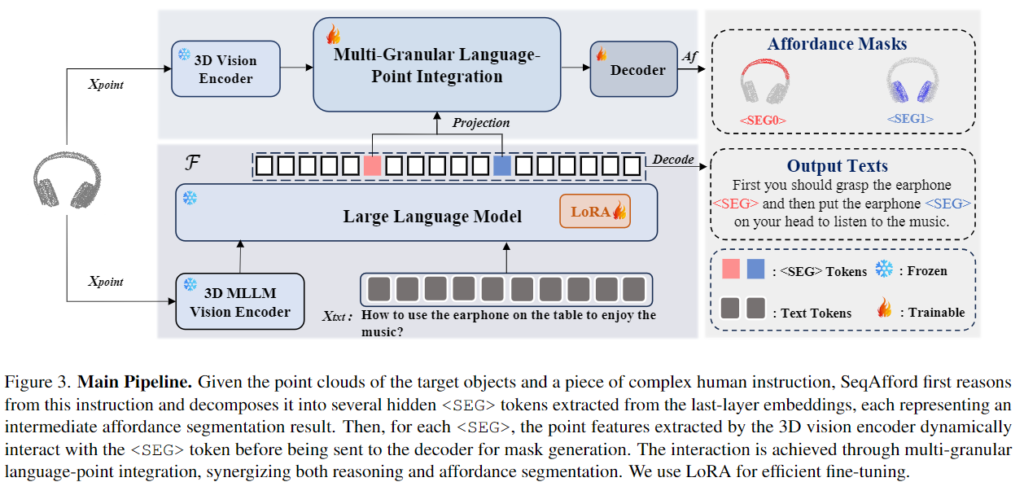
SeqAfford의 구조는 위의 Figure 3과 같습니다. 크게 3가지 부분으로 이루어집니다. 먼저 3D vision encoder를 통해 3D representation을 생성하고, 3D MLLM \mathcal{F}를 통해 사전학습 모델의 지식을 활용하여 3D affordance segmentation 토큰을 생성하며, Multi-Granular Language-Point Integration 모듈을 통해 효과적으로 point cloud에 대한 feature와 MLLM으로 추출한 segmentation 토큰을 통합하게 됩니다.
<3D MLLM Backbone>
open-world에 대한 이해를 고도화하기 위해 제안된 다양한 3D MLLM 모델 중, 저자들은 로봇과 상호작용을 이해하도록 사전학습된 ShapeLLM[1]을 backbone \mathcal{F}으로 채택하였습니다. 저자들은 기존 연구들은 3D affordance segmentation을 위해 3D bacbone을 사용하거나 point cloud와 language에 대하여 볅도의 인코더를 사용하였으나, 저자들은 open-world에 대한 일반화 성능을 높이고자 3D MLLMs를 사용하였다고 합니다. 또한 LLM 모델로는 LLaMa를 사용하고, point cloud 잍코더로는 Recon++[2]을 적용하였습니다.
**[1] Qi, Zekun, et al. “Shapellm: Universal 3d object understanding for embodied interaction.” ECCV 2024 : 최초의 3D multi-modal LLM 모델이라합니다.
**[2]Qi, Zekun, et al. “Contrast with reconstruct: Contrastive 3d representation learning guided by generative pretraining.” International Conference on Machine Learning. PMLR, 2023.
<Sequential Affordance Reasoning>
3D MLLMs이 자연어와 3D representation 사이의 aling을 맞추는데는 효과적이지만 객체에 대한 text를 생성하는 작업에 특화되어있으므로 dense prediction에는 어려움이 있어 해당 논문에서는 3D MLLMs에 segmentation 토큰 <SEG>를 추가하여 segmentation 능력을 캦슐화하였다고 합니다.
point cloud \mathbf{X}_{point}와 지시문 \mathbf{X}_{txt}가 입력으로 주어졌을 때 3D MLLM은 멀티모달 정보로부터 대응되는 text 답변 \mathbf{y}_{txt}를 생성합니다. 이때 \mathbf{y}_{txt}는 여러 개의 <SEG> 토큰으로 이루어지며 각 <SEG>는 sequence에 대한 segmentation 결과를 나타냅니다. (여기서 의미하는 sequence는 복잡한 지시문으로부터 예측된 세분화한 affordance sequence S를 의미합니다.)
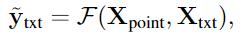
각 <SEG> 토큰으로부터 최종 embedding \{\mathbf{h}_{seg}^{(i)}\}^{S-1}_{i=0}를 생성하게되며, MLP projection layer를 통과해 \{\mathbf{H}_{seg}^{(i)}\}^{S-1}_{i=0}를 얻게 됩니다.
<Multi-Granular Language-Point Integration>
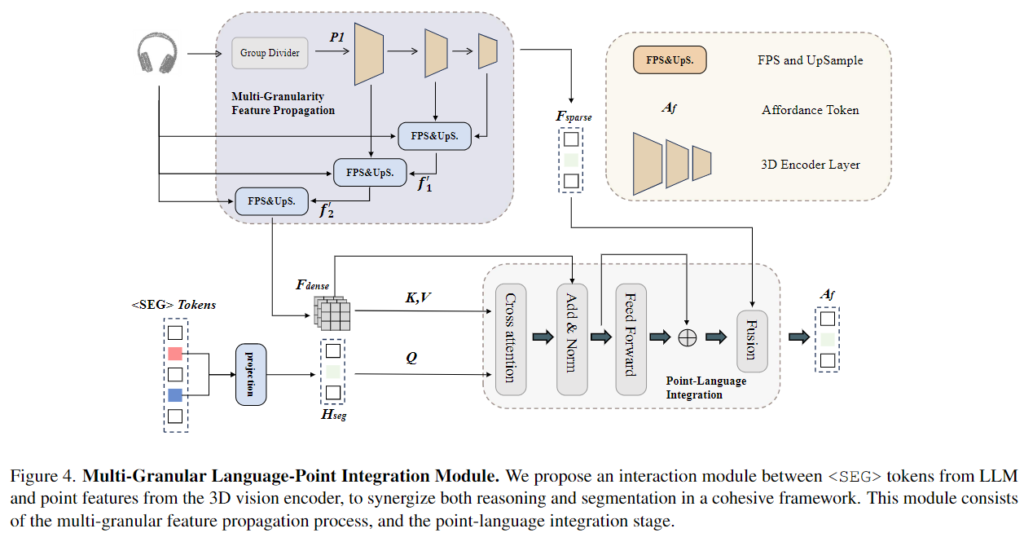
segmentation 토큰을 얻은 뒤 이를 3D point cloud에 대한 dense prediction을 구하기 위해 저자들은 Multi-Granular Language-Point Integration를 설계하였습니다. 해당 모듈은 point cloud의 feature를 dense feature로 upsampling하는 과정과 <SEG>토큰의 정보를 dense feature로 전파하고 dense feature를 global sparse feature와 통합하는 과정을 통해 최종적으로 affordance segmentation을 생성하게됩니다.
위의 Figure 4는 해당 모듈의 개요로, 3D encoder의 중간 feature로부터 계층적인 upsapling을 수행합니다. 또한 FPS(farthest point sampling) 방식으로 feature를 전파하여 f_1과 f_2를 생성한뒤 최종적으로 dense feature f_{dense}를 구합니다.
point-language integration 과정은 앞서 upsampling으로 구한 f_{dense}를 Key와 Value로 이용하고 <SEG> 토큰으로부터 구한 \mathbf{H}_{seg}^{(i)}를 Query로 이용하여 cross-attention을 수행하고(즉, dense feature와 segmentation에 대한 토큰을 융합) 얻은 결과와 3D encoder의 output인 f_{dense}를 합쳐 \mathbf{A_f}를 생성합니다. \mathbf{A_f}에 decoder를 적용하여 affordance mask \mathbf{\tilde{y}}_{mask}를 구합니다.
<Training Objectives>
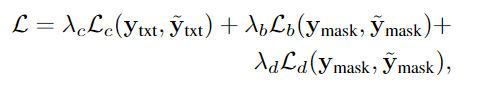
MLLM을 end-to-end로 학습하기 위해 text를 생성에 대해 cross-entropy loss \mathcal{L}_c와 segmentation mask 예측을 위한 Dice loss\mathcal{L}_d 및 binary cross-entropy loss \mathcal{L}_b를 가중합하여 최종 loss \mathcal{L}를 구하게 됩니다.
Experiment
fine-tuning과정에 LoRA를 적용하였으며, A100 GPU 1개를 이용하였으며, 평가지표는 Area Under the Curve (AUC), Mean Intersection Over Union (mIOU), SIMilarity (SIM), Mean Absolute Error (MAE)를 이용합니다. 단일 affordance segmentation에 대해서는 기존의 SOTA와 비교를 수행하며, sequential affordance segmentation에 대해서는 모델이 sequential하게 추론을 할 수 있는 지를 관점으로 평가를 수행하였다고합니다.
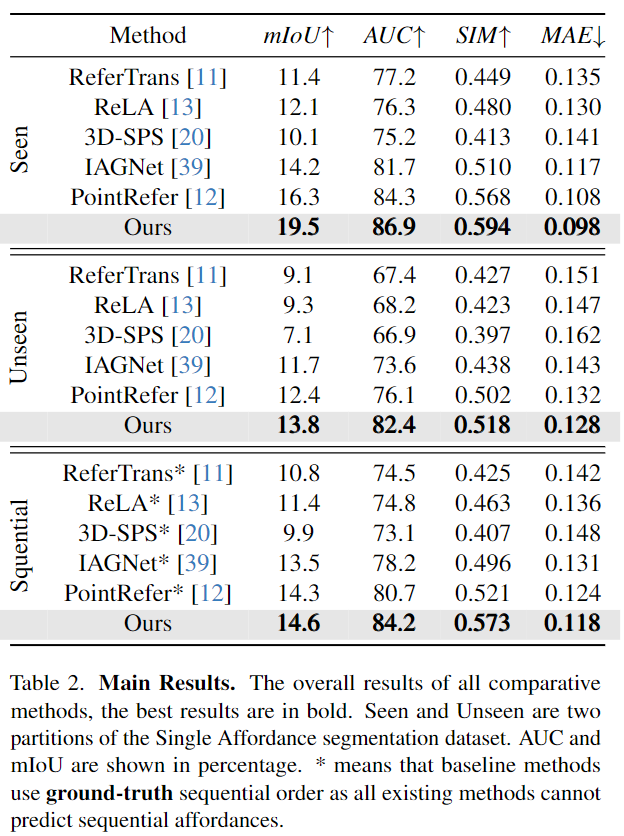
Single Affordance Segmentation Task와 Sequential Affordance Segmentation Task에 대한 실험 결과는 Table 2에서 확인할 수 있습니다. Single에 대해서는 저자들이 제안한 방식이 모든 평가지표에서 가장 좋은 성능을 보이며 Unseen에 대한 실험 결과를 통해 기존 방법론대비 저자들이 제안한 방식이 더 잘 작동한다고 이야기합니다.(성능 자체가 mIoU에서 20% 이하라는 점에서 성능이 좋다고 이야기하기는 어려운 것 같습니다..)
기존 연구들은 Sequential에 대한 고려를 하지 않았으므로 성능 비교를 위해 저자들은 기존 방법론에는 복잡한 명령어를 GPT를 적용하여 새로운 sequence로 분해한 뒤, <SEG> 토큰을 적용하여 affordance의 sequence를 구하고 이를 순차적으로 decoding 하는 방식을 적용하였다고 합니다. 이에 대한 성능도 해당 논문에서 제안한 방식이 가장 좋은 성능을 보였으며 저자들은 이를 통해 복잡한 명령어를 LLM으로 순차적으로 분해하여 각각의 segmentation을 적용하는 것 보다, 3D MLLMs를 통해 sequential한 작업을 더 효과적으로 처리할 수 있었다고 어필합니다.
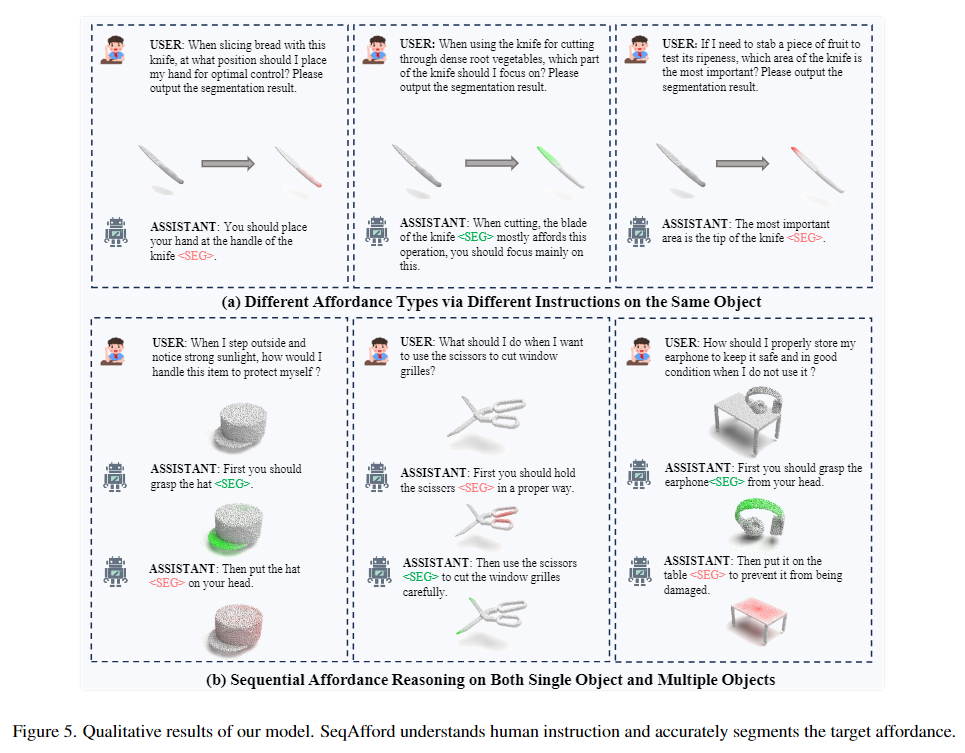
Figure 5는 정성적 결과로, (b)의 결과를 통해 모델이 여러 객체에 대해 순차적으로 작업을 수행하기위한 affordance를 인식할 수 있음을 이야기합니다. (b)의 결과를 살펴보면 모자를 쓰는 작업에 대해서도 모자의 챙을 잡고, 모자의 캡 부분이 머리로 향하도록 segmentation이 되어있으며, 가위로 자르는 작업을 할 때도 손으로 손잡이를 잡고 날로 자르도록 segmentation이 수행됩니다. 또한 객체가 여러가지인 경우에 대해서도 헤드폰을 잡아서 테이블의 상판에 올려두도록 순차적으로 segmentation이 수행됩니다. 또한, (a)에 대한 결과를 살펴보면 같은 칼에 대해서도 수행할 작업에 따라 예측되는 영역이 달라지는 것을 볼 수 있습니다. 사람이 칼을 어디 잡아야겠는 지 물어보는 질문에는 손잡이가, 채소를 자르기 위해서는 어디에 집중해야하는 지 묻는 질문에는 칼날이, 과일이 익었는 지 체크하기 위해서는 칼날의 끝부분이 마스킹 되는 등의 결과를 확인할 수 있습니다. 하나의 질문에 대해 sequential하게 affordance 영역을 예측할 수 있다는 것이 인상깊었습니다.
Ablation study
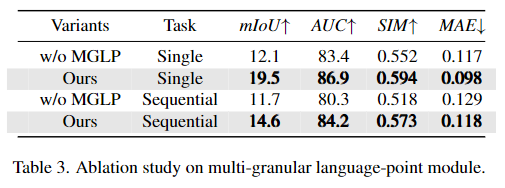
Table 3은 저자들이 제안한 dense prediction을 위한 모듈의 효과를 확인하기 위한 실험 결과로, Multi-Granular Language-Point Integration 모듈을 통해 성능 개선이 개선되었음을 실험적으로 보였습니다.
안녕하세요, 좋은 리뷰 감사합니다! 토큰이라는 것은 라는 문자열을 그대로 사용하는게 아니라 그 토큰 안에 그때마다 segmentation 결과가 포함된다는 의미이겠죠 ??? 제가 이전에 읽었던 논문에서 포인트 클라우드 데이터를 segmentation하기 위해 문장 중에 segmentation 해야 할 클래스에 대한 힌트를 주기 위해 라는 문자열 그대로를 하나의 토큰으로 사용했었는데, 혹시 본 논문에서도 그런 역할로 토큰을 사용한 것인가 헷갈려 질문 드립니다.
데이터셋 구성에 있어서 real world 관점으로 봤을 때 중요해보이는 sequential 동작을 다루는 것이 main contribution으로 이해하였습니다. 그런데 제가 Affordance task를 잘 몰라서 그럴 수 있지만 2. Statics and Analysis에서 World Knowledge가 정확히 어떤 정보인가요 ? 여태껏 어떤 데이터셋에서도 포함이 안되었던 정보를 처음 제공하는 것 같은데 위에서는 별다른 언급이 없었던 것 같아 이 데이터를 포함한 이유와 강점이 무엇인지 궁금합니다.
다음으로
감사합니다.
질문 감사합니다.
기존 연구들은 단순하게 특정 affordance가 라벨링이 되는 방식이었다면, 해당 방법론은 작업에 따라 영역의 affordance가 달라질 수 있습니다. 이러한 점에서 world knowledge를 반영한 데이터라고 표현한 것으로 보입니다. 어찌보면 중요한 강점인 것 같은데 저자들이 논문에서 Table 1에 대해 언급을 안하고 있어서 저도 의도는 추측만 됩니다…
순차적인 작업이 필요한 경우에 각 순차적인 작업에 대한 토큰을 생성하고 이를 3D feature와 융합하여 최종적인 segmentation을 수행하게 됩니다. 이러한 점에서 건화님이 이야기하신 역할로 이해하시면 될 것 같습니다.
안녕하세요 좋은 리뷰 감사합니다.
affordance segmentation 능력을 갖춘, 3D MLLM을 제안하였다는 것으로 이해하였는데, 그렇다면 3D의 다른 task로의 확장 실험은 따로 없었는 지 궁금합니다.
질문 감사합니다.
해당 내용에 대한 실험 결과는 따로 존재하지 않습니다.
저도 저자들이 제안하는 방식이 3D MLLM이라 하여 affordance segmentation 분야에 대한 실험 뿐만 아니라 3차원 데이터에 대한 모델의 이해 능력을 평가하는 실험이 있을 줄 알았는데 없어서 아쉽습니다..
좋은 논문 리뷰 감사합니다.
제가 Multi-modal LLM의 학습에 대해서 선입견이 있는 편인데요…
대용량 데이터 셋이 없으면 학습이 어려운 것으로 알고 있었습니다.
3D 객체는 18k, Sequential segmentation에 대한 데이터는 20k라면 객체당 하나만 존재하는 걸로 볼 수 있습니다. 즉, 다양성이 엄청나게 떨어질 수 밖에 없는 상황인 것 같아요.
그리고 학습과 평가까지 나눈다면… 일반화된 평가는 물 건너 간 것 같고…
정리해서 질문을 드리자면, Multi-modal LLM의 학습 데이터가 이 정도로 충분한지…
Sequential segmentation의 수가 객체 당 하나가 맞는지 확인 부탁드립니다!
질문 감사합니다.
학습 측면에서 다양성이 떨어질 수 밖에 없다는 의견에 대해서는 어느정도 동의합니다.
그러나 이를 학습과 평가 set으로 카테고리 수준과 instance 수준에서 나누어 평가를 한다는 측면에서는 일반화된 평가가 가능하다고 할 수 있지 않을까 하는 생각을 가지고 있습니다. (제가 최근 서베이하고 리뷰한 논문 대다수가 데이터 셋의 구성을 카테고리 수준의 unseen과 instance 수준의 unseen으로 구분하여 평가를 수행합니다. 그 중 카테고리 수준의 unseen은 학습에 사용한 데이터와 크게 차이가 있으므로 일반화에 대한 평가는 가능하지 않을까합니다. 물론 성능은 아직 낮은 수준인 것으로 보입니다.)
MLLM의 학습 데이터가 충분한지에 대해서는 실험 결과도 성능이 낮은 편이라 데이터가 더 필요할 것 같다는 의견에 저도 동의합니다. 추가로, Sequential affordance segmentation은 객체 하나에 대한 sequential만을 의미하는 것이 아니라 여러 객체로 구성되는 경우도 존재합니다.