이번 리뷰 논문은 3D Language Field 중 출판된 가장 최신 기법으로 실시간성과 성능 모두 SOTA를 달성한 기법에 해당합니다. 기존 기법들은 첫 시도들을 제안한 기법이라면 해다 기법은 기존 기법들을 어플리케이션에 적용했을 때, 치명적일 수 있는 느린 추론 속도를 해결하기 위한 Feature Grid Mapping 기법을 소개합니다.
Intro
Semantically interactive radiance field(~3DLF)는 사용자 친화적이고 자동화된 실세계 3D 장면 이해 응용 프로그램을 가능하게 한다는 점에서 매력적인 연구입니다. 그러나 radiance field에서 고품질, 효율적인 zero-shot 능력을 동시에 달성하는 것은 여전히 어려운 과제입니다. 본 연구에서는 고해상도 3D Gaussian Splatting(3DGS) 내에서 실시간 open-vocabulary query를 지원하는 FastLGS라는 방법을 제안합니다. 저자는 semantic feature grid를 제안하며, Segment Anything Model(SAM) 마스크를 기반으로 추출된 멀티뷰 CLIP 특징을 저장하고, 3DGS를 통한 semantic field training을 위해 그리드를 low-dim feature로 매핑합니다. 학습이 완료된 후에는 렌더링된 특징으로부터 feature grid를 통해 pixel-algined CLIP embedding을 복원하여 open-vocabulary query를 수행합니다.
최신 연구와의 비교 실험을 통해, FastLGS가 속도와 정확성 모두에서 최고 성능을 달성합니다. FastLGS는 LERF보다 98배, LangSplat보다 4배, LEGaussians보다 2.5배 빠른 속도를 기록했습니다. 또한, FastLGS는 3D segmentation 및 3D object inpainting과 같은 다양한 다운스트림 작업에 적응 가능하고 호환성이 뛰어나며, 다른 3D 조작 시스템에 쉽게 적용될 수 있음을 실험을 통해 확인했습니다.
Method

Overview
전반적인 구조는 Fig 2를 따릅니다. 입력 이미지들은 초기에 SAM mask를 출력하고 이에 대한 CLIP embeddings을 출력합니다. 해당 정보들은 semantic feature grid와 low-dim feature mapping 구성으로 되어 활용될 수 있죠. 그럼, 얻어진 픽셀 기준으로 정렬된 low-dim feature를 이에 대응되는 Gaussinans으로 재구성된 3D Scened을 학습하기 위해 사용합니다 (저자가 명명하길 “Training Features for Gaussians”). 추론 단계에서는 구축된 semantic field로부터 자연어를 대화형 쿼리로 사용하여 복원된 embedding을 기반으로 해당하는 새로운 뷰에서의 고품질 마스크를 얻을 수 있습니다. 해당 쿼리 전략을 저자는 “Querying Features”라고 명명합니다.
Initialization
먼저, 기본적인 semantics을 초기화를 수행합니다. 주어진 입력 이미지들 { I_t | t=0,1, ... , T} 에서 각각의 이미지 I_i 를 SAM에 regular grid 32 x 32 point prompt 이용해 whole segmentation masks {M_{i,j} | j = 0,1, ... m_i}과 이에 따른 CLIP features {L_{i, j} | j= 0,1,...m_i} 를 얻습니다. Masks와 CLIP embeddings은 이후 pixel-aligned low-dim feature maps을 구축에 사용됩니다. 해당 초기화 이후에는 추론 단계에서의 CLIP text encoder를 제외하고는 사전 학습 모델을 사용하지 않습니다.
Semantic Feature Grid
실질적으로 CLIP을 3DGS에 올리려면 각 가우시안 파라미터에 수백 개의 차원의 정보를 업데이트해야 하기 때문에 메모리 사용량이 급격하게 증가하고 렌더링 효율성이 떨어질 수 있습니다. 또 다른 문제로 CLIP feature는 뷰의 각도, 중복된 배경과 복잡한 가려짐, 자세 문제로 인해 일관되지 못한 variance를 보일 수 있으며, 이는 성능 저하로 이어 질 수 있습니다. 다중 뷰에서 관찰된 동일한 물체의 language features는 동일한 의미론적 정보를 가지고 있어야 하며, 낮은 학습과 쿼리 비용을 요구해야만 합니다. 그러나 기존에 제안된 MLP 기반의 압축과 복원된 특징들은 기존 CLIP들의 문제점을 그대로 가지며, 더 낮은 성능을 가지기 때문에 복잡한 장면에서 고품질의 쿼리를 생성하기 어렵습니다.
저자는 위 문제를 해결하기 위해서 장면 내 각각의 물체들의 다중 뷰 language features를 저장하고, low-dim feature를 맵핑하는 semantic feature grid를 제안합니다. 구체적으로 같은 물체의 language features L를 공통된 low-dim features f를 가지도록 맵핑하는 L \in R^D 를 t \in \(0,1\)^d 를 만드는 것을 목표로 합니다. 각각의 f는 size \mathcal{K}^{-1/d} 의 grid에 할당되며, 여기서 \mathcal{K} 는 cross view matching 중에 계산된 특정 장면의 물체의 수를 나타냅니다.
이렇게 만들어진 low-dim feature는 해당하는 마스크에 따라 pixel-level로 할당됩니다. 이를 통해 3DGS에 효율적이며, 정확한 CLIP embedding을 복원이 가능해지게 됩니다.
+ 간단하게 설명하면 mask를 토대로 zero-shot multi classifiaction을 수행하여 이에 대해 추론된 값을 grid로 보고 low-dim feature를 생성한다고 보시면 됩니다.
Cross view Grid Mapping

서로 다른 뷰 내의 객체의 일관된 특징을 만들기 위해서 저자는 인접한 image set I에 순차적으로 denoised mask를 매칭시키고 features를 할당합니다. 또한, muti-view에서 CLIP features가 불안정할 수 있다는 점을 고려하여 matching process는 key point correspondece와 feature similarity 비교로 구성됩니다.
Key points correspondence. 안정적이고 정확한 매칭을 위해 SIFT와 KNN을 이용하여 얻은 키 포인트 별로 마스크 대응쌍의 우선순위를 선정합니다. 임계값 τ 이상의 키 포인트 쌍이 대응하는 SAM 마스크는 동일한 f에 할당되고 다른 시점의 객체에 대한 분할 마스크로 간주합니다.
Feature similarity comparison. 일부 마스크들의 픽셀들은 매끈한 텍스쳐를 가져 키포인트가 거의 없는 경우가 있습니다. 저자는 이러한 경우에도 대응하기 위해서 CLIP embedding L과 color distribution C의 융합된 feature로 계산된 유사도에 따라 매칭 프로세스를 진행합니다. 만약에 일치지되지 않은 마스크 m_i와 m_j가 있을 경우에는 similarity matrix SIM_{m_i \times m_j} 를 계산하고 이중 점수가 가장 높은 마스크 쌍을 선택합니다. 임계값 θ보다 높은 마스크는 동일한 특징 f를 가진 것으로 간주합니다. 이외에는 새로운 low-dim feature라고 가정합니다.
구체적으로 마스크 M_i, M_j에 대한 유사도 sim_{i, j} 는 다음과 같이 계산됩니다.
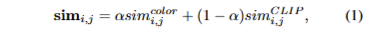
여기서 α는 color distribution feature C의 유사도에 대한 가중치에 해당합니다. sim^{CLIP}_{i, j} 는 Bhattacharyya distance*로 계산되며, sim^{color}_{i, j} 는 cosine similarity로 계산됩니다. 이는 다음과 같이 구현됩니다.
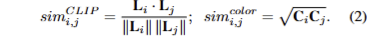
Alg 1은 이에 흐름을 보여주는 설명으로 참고하시면 좋을 것 같습니다.
Training Features for Gaussians
맵핑된 low-dim feature f_m을 각각의 gaussian g에 구축하기 위해 학습을 위해 적응적으로 통합을 시켜야 합니다.
Rendering Features. 카메라 포즈 v가 주어지면 3DGS의 색상에 대한 연산과 동일하게 정렬된 Gaussians \mathcal{N} 집합을 블렌딩하여 픽셀의 feature F_{v,p} 를 계산합니다. 이는 다음과 같습니다.
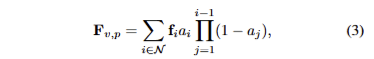
여기서 a_i는 opaticity에 해당합니다.
Optimization. 저자가 제안한 low-dim features는 3DGS optimization을 그대로 따라, L1과 D-SSIM loss를 사용합니다. 이는 다음과 같습니다.
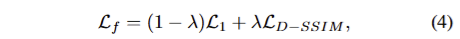
여기서 λ는 0.2를 사용합니다.
Querying Features
학습이 끝나면, FastLGS는 open vocabulary text prompts를 사용하여 장면 내 다양한 물체에 대해서 대화형으로 쿼리를 수행할 수 있습니다. 앞서 정의한 low-dim feature를 활용하여 쿼리된 feature를 투영하여 2D에 대한 pixel-aligned semantics F_v를 쿼리 가능합니다. 이는 모든 카메라 포즈 v 내의 모든 쿼리에 적용 가능합니다.
Relevancy Score. prompt가 제공되면, LERF와 유사한 grid image feature 기반의 language relevancy scores를 계산합니다. images embedding \phi_{img} 와 canonical phrase embeddings \phi^i_{canon} 에 대한 cosine similarity를 계산합니다. 그런 다음 image embedding과 text prompt embedding \phi_{query} 사이의 pairwise softmax를 계산합니다. 이는 다음과 같이 정리 할 수 있습니다.
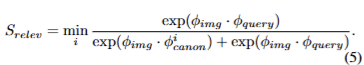
canonical phrase의 경우 모든 쿼리에 “object”, “stuff” 및 “texture”를 사용합니다.
Target Mask. low-dim feature grids에 맵핑된 image features을 복원하고 이를 사용하여 text embedding과의 relevancy score를 계산합니다. 해당 스코어가 가장 높은 그리드를 쿼리에 대한 그리드로 간주됩니다. 그리드에는 멀티 뷰에 대한 정보가 담겨져 있기 때문에 보지 못한 쿼리 뷰에 대해서도 쿼링이 가능합니다.
쿼리 뷰에 대해 복원 feature F_p^v 로부터 해당하는 마스크를 찾기 위해서 앞서 선정된 grid에 대응되는 low-dim features와의 Euclidean distance로 계산합니다. 이는 다음과 같습니다.
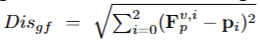
해당 스코어가 τ_ac보다 낮다면 target mask로 선정합니다.
Experiment
Implementation Details. OpenClip VIT-B/16 model, SAM ViT-H을 활용함. 3DGS는 30,000 iterations을 수행. 모든 실험은 a TITAN RTX GPU에서 수행됨
Datasets. SPIn-NeRF, LERF, 3D-OVS에서 수행됨
Comparison With Other State-of-the-art Methods
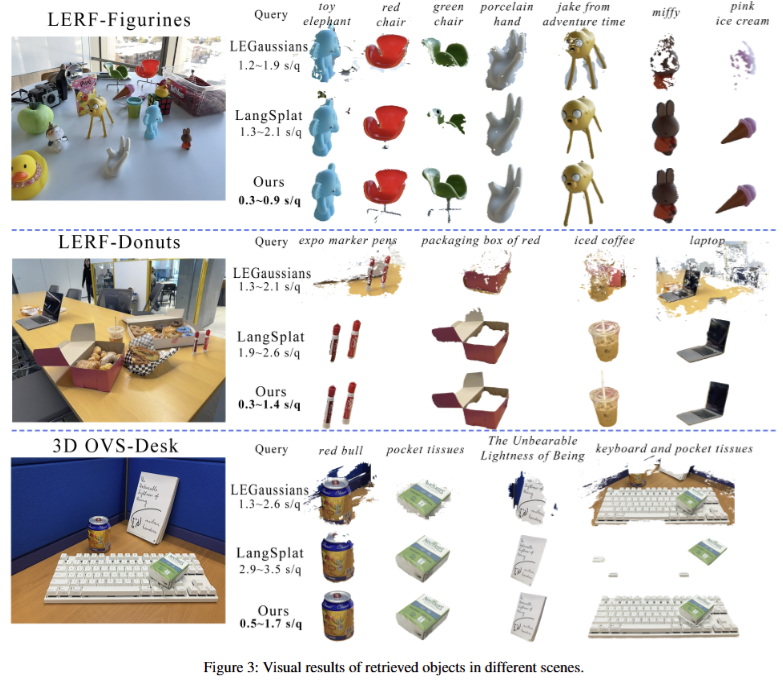
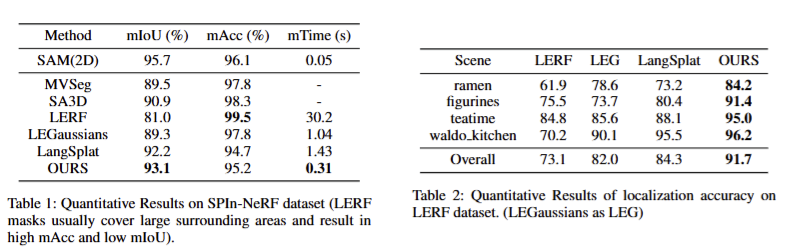
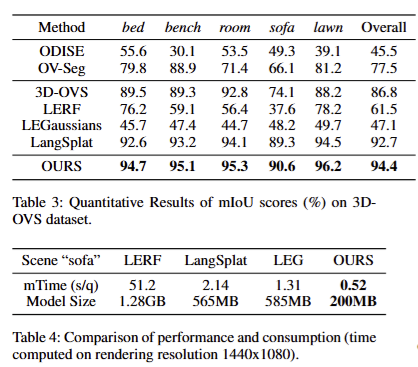
정성/정량적인 결과 모두 기존 기법을 뛰어넘는 결과를 보여줌. 추론 속도에서도 다른 기법 대비 월등하게 빠른 추론 속도를 보여주고 있음. 또한 Table 4에서는 연산 효율성을 보여주고 있음
Ablation studies
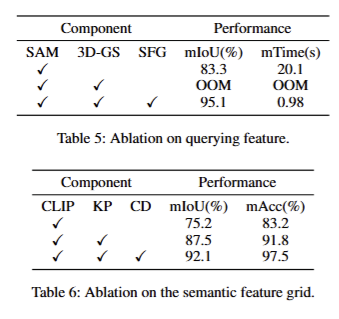
Querying Feature. Tab 5에서 보이는 바와 같이 제안한 semantic feature grid (SFG)를 사용했을 때, 가장 좋은 성능을 보여줌. SAM을 3DGS에 단순하게 올리는 경우, 수백 차원의 feature를 업데이트 해야 하기 때문에 높은 연산량으로 OOM이 발생함

Cross View Matching. fig 4와 tab 6에서 key point (KP)와 color distribution feature C (CD)에 대한 성능 리포팅을 확인 가능함. 다중 뷰에 따른 feature의 일관성을 유지하는 기능에 대해서 증빙함을 보임
최근 해당 기법에 대해서 논문들을 많이 읽고 있습니다. 최근 동향은 표현에 대한 고도화와 효율성을 나타내기 위해서 많은 움직임과 해당 기법을 다른 어플리케이션에 녹이기 위해 변형을 하는 방향으로 제시되고 있습니다. 다양한 기법 중 다중 뷰에 따라 변형되는 CLIP feature를 일관되게 만들고 이를 기반으로 grid를 생성하는 방법이 가장 참신한 것 같습니다. 추후 제 연구 방향도 해당 기법에 대한 변형으로 이뤄질 것 같습니다.
좋은 리뷰 감사합니다.
속도가 굉장히 많이 개선되었음에도 성능이 유지되고 있다는 점에서 실제 application으로 적용하기 좋은 베이스라인이 될 것 같습니다.
이와 관련하여 몇가지 질문이 있습니다.
SAM으로 예측한 mask의 모든 세분화 수준에 대해 각 mask별로 CLIP embedding을 구하는 것으로 이해하였는데 맞을까요? 이렇게 진행할 경우 학습과정에 시간이 굉장히 오래 걸릴 것 같습니다.
또한, inference 과정에서 어떻게 세분화 수준을 지정할 수 있는 지 궁금합니다.
서로 다른 뷰의 객체에 대한 일관적인 특징을 만들기 위해 인접한 이미지에 순차적으로 denoised mask를 매칭였다고 하셨는데, 여기서 denoised mask가 일관적인 특징과는 어떻게 연관이 되는 지 궁금합니다. keypoints correspondence와 Feature similarity comparison과정을 거친 것을 denoised mask라 하는것일까요??
Q1. SAM으로 예측한 mask의 모든 세분화 수준에 대해 각 mask별로 CLIP embedding을 구하는 것으로 이해하였는데 맞을까요? 이렇게 진행할 경우 학습과정에 시간이 굉장히 오래 걸릴 것 같습니다.
A1. 넵 MASK 별로 추출하는 방식을 이용합니다. 단, 학습이 아닌 feature를 올리는 방식을 이용하여 파이프라인 전체의 시간이 단축된다는 장점을 어필한 방법론 입니다.
Q2. 또한, inference 과정에서 어떻게 세분화 수준을 지정할 수 있는 지 궁금합니다.
A2. 해당하는 영역에 feature를 올리는 방식을 이용하기 때문에 mask+clip을 여러 단계로 추출하고 영역에 올린다면 여러 레벌을 활용 할 수 있겠죠
Q3. 서로 다른 뷰의 객체에 대한 일관적인 특징을 만들기 위해 인접한 이미지에 순차적으로 denoised mask를 매칭였다고 하셨는데, 여기서 denoised mask가 일관적인 특징과는 어떻게 연관이 되는 지 궁금합니다. keypoints correspondence와 Feature similarity comparison과정을 거친 것을 denoised mask라 하는것일까요??
A3. denoised mask란, mask의 내부 영역이 부분적으로 채워지지 않은 영역들을 노이즈라고 가정하고 이를 제거한 마스크라고 보시면 됩니다. 즉, keypoints correspondence와 Feature similarity comparison과정 이전에 수행되는 방법이라고 보시면 됩니다.
시차에 따른 마스크 일관성은 keypoints correspondence와 Feature similarity comparison를 통해 구하는 방식입니다.