안녕하세요, 오늘의 X-Review는 비디오 내에서 텍스트 쿼리와의 상응 구간을 찾는 Temporal Grounding 관련 논문 <SHINE: Saliency-aware Hierarchical Negative Ranking for Compositional Temporal Grounding>을 소개해드리겠습니다. 본 방법론은 24년도 ECCV에 게재되었으며, Temporal Grounding 중에서 특히나 텍스트 쿼리의 각 구성요소(=단어, 절)에 대한 인지 능력을 높이는 Compositional Temporal Grounding task를 수행합니다.
앞에 ‘compositional’이 붙는다고하여 완전 task가 달라지는 것은 아니고, 방법론이 문장 구성 요소인 단어 이해에 좀 더 초점이 맞추어져 있으며, 평가 시 compositionality에 대한 강인함을 확인할 수 있는 데이터셋을 사용한다는 차이점이 있습니다.

1. Introduction
Temporal grounding의 목표는 비디오-텍스트 쿼리 쌍이 주어졌을 때, 서로 의미론적으로 상응하는 시간적 구간을 출력하는 것입니다. 이 때 입력되는 텍스트 쿼리의 자유도에는 제한이 없고, 모델은 어떠한 형태의 자연어 문장을 입력받든 강인하게 구간을 찾아낼 수 있어야 합니다. Temporal grounding 또한 비디오-텍스트 멀티모달 데이터를 다루기에, 최근에는 CLIP과 같은 VLM feature를 추출해 사용합니다. 동시에 이미지-텍스트 관련 진영에서는 VLM이 텍스트 쿼리의 순서가 달라졌을 때 제대로 대응하지 못하거나, 정말 핵심이 되는 단어를 잘 인식하지 못한다고 지적하며 개선 연구가 활발히 진행되고 있기에 충분히 다뤄져야하는 문제라고 생각합니다. CLIP보다 하위 레벨의 feature(GloVe 등) 들은 더더욱 그러한 문제가 심각하겠죠. 제가 최근 작성했던 몇 개의 리뷰에서 이들을 다루고 있으니 필요하신 분들은 참고하셔도 좋을 것 같습니다.
앞서 말씀드린 VLM의 문제점은 결국 텍스트에 대한 compositionality generalliation 실패라고 정의할 수 있습니다. 상대적으로 문장의 수준이 단순한 이미지-텍스트 분야에서도 위와 같은 문제점이 제기되고 있는데, 복합적 정보를 담은 비디오를 인지해야하는 temporal grounding에서는 해당 문제가 더욱 부각될 것입니다. 여기서 문장의 수준이 단순하고 복잡함에 대해 추가 설명을 좀 드리자면, “남자가 문을 닫는다.”는 단순하다 볼 수 있지만, “검은 티셔츠와 선글라스를 낀 남자가 문을 닫은 뒤 샌드위치를 내려놓는다.”는 복잡하다고 볼 수 있을 것입니다. Temporal grounding에선 후자와 같이 시공간적으로 복잡한 문장도 다룰 수 있어야 하기에 더욱 위 문제가 해결되어야 한다는 것입니다.
그렇다면 실제로 최근 temporal grounding의 핵심 연구 갈래인 DETR 기반 방법론들이 compositionality에 얼마나 잘 대응하고 있는지 먼저 살펴봐야겠죠.
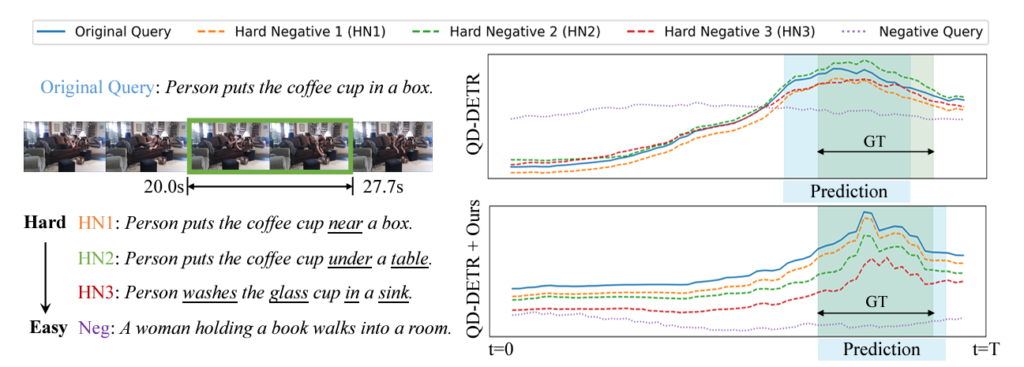
그림 1의 왼쪽은 실제 GT 쿼리 “Person puts the coffee cup in a box.”라는 문장에 대해 저자들이 LLM을 활용해 계층적으로 만들어낸 hard negative 문장 3개와 완전 무관한 문장을 보여주고 있습니다. 오른쪽은 각각의 문장들에 대한 기존 DETR 기반 방법론인 QD-DETR의 상응 score와 QD-DETR의 저자의 방법론을 적용했을 때의 상응 score를 보여줍니다.
우선 총 3개의 HN 문장에 대해, HN1 – HN2 – HN3으로 갈수록 더욱 변형이 많이 가해진 상황이기에 상응 score도 이 순서에 맞게 점점 떨어져야합니다. 그러나 오른쪽 위의 QD-DETR score를 보면 negative는 잘 배제하고 있으나 HN들에 대해 구별력 없이 혼동하고 있는 모습을 볼 수 있습니다. 그렇다보니 최종 구간도 오차가 발생하였네요. 반면 QD-DETR 저자들의 방법론을 붙이면 문장들의 계층적 뉘앙스를 잘 이해하게 되며 각각에 조금 더 뚜렷한 차이를 주고 있음을 볼 수 있습니다. 이렇게 문장간 미묘한 차이를 잘 잡아낸다는 것을 곧 compositionality generalization이 잘 되고 있다는 것으로 이해할 수 있습니다.
본 방법론에서는 compositional generalization을 위해 LLM 기반의 HN를 생성합니다. 기존 방법론들이 배치 내에서 주어/동사를 가져와 대체하고 negative로 학습했던 것과 다르게, 주어/동사 이외에도 다양한 개체를 학습할 수 있으며 가장 중요한 것은 LLM을 활용하기에 “말이 되는” 문장을 학습할 수 있게 되었다는 것입니다. 문장에서 주어/동사만 봐선 안되고, 또한 LLM으로 말이 되는 합리적인 문장을 학습에 사용한다는 것도 중요합니다. 그러나 개인적으로 가장 중요한 것은 “LLM으로 추출한 문장을 방법론에서 어떻게 활용하고 학습할 것이냐”라고 생각합니다. 이에 대해서는 방법론 부분에서 확인해보겠습니다.
2. Method
2.1 Problem Definition and Overview
비디오 V와 텍스트 쿼리 Q가 쌍으로 입력되면, 최종적으로 비디오 내 구간 타임스탬프 (t_{s}, t_{e})를 예측하는 것이 목표입니다. 당연히 학습 때 본 텍스트 쿼리들과 다른 문장이 평가 때 입력되기에 학습 텍스트 쿼리에 대한 overfitting은 방지하면서 novel한 문장에 대한 일반화 성능을 적절히 학습해야 합니다. 둘 간의 균형을 잘 맞추는 것이 중요하다는 이야기입니다.
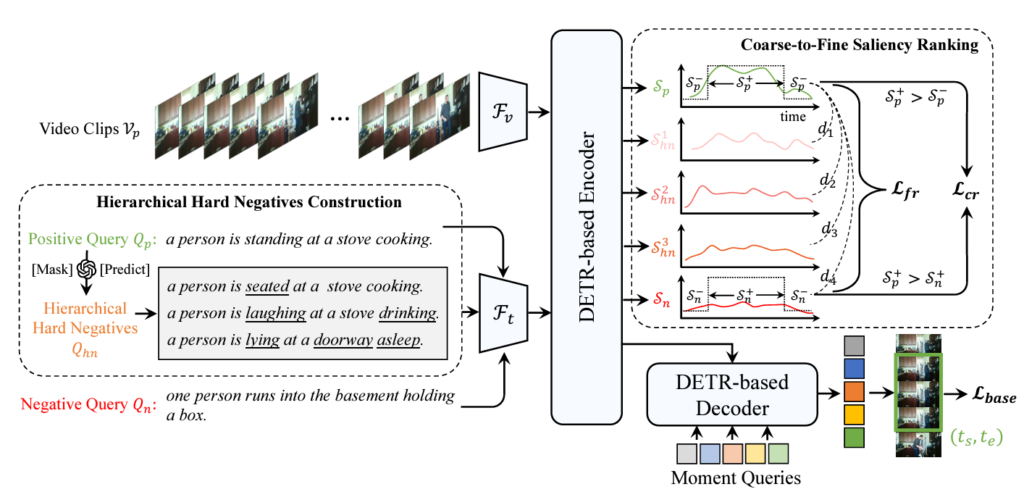
위 그림 2가 저자가 제안하는 방법론 전체 프레임워크입니다. 그림 2에서도 볼 수 있듯 크게 두 가지 모듈을 거쳐 학습이 진행됩니다. 각각은 Hierarchical Hard Negatives Construction, Coarse-to-Fine Saliency Ranking 입니다. 자세한 모듈별 내용은 각 절에서 알아보기로 하고, 큰 그림을 먼저 살펴보겠습니다.
한 쌍의 비디오-텍스트 (V_{p}, Q_{p})가 주어지면 먼저 LLM에 mask-and-predict 방식을 적용해 3개의 HN 문장들을 만들어냅니다. 여기서 LLM은 GPT-3.5 Turbo를 활용했다고 합니다. 텍스트는 실제 GT 텍스트 쿼리 Q_{p}와 3개의 HN 문장 Q_{hn}^{1}, Q_{hn}^{2}, Q_{hn}^{3} 그리고 배치 내 다른 텍스트 문장 Q_{n}까지 선택되어있는 상황입니다. 이후 비디오는 비디오 인코더 F_{v}(\cdot{}), 텍스트는 텍스트 인코더 F_{t}(\cdot{})에 입력됩니다. DETR 인코더는 두 모달리티 feature를 입력받아 saliency score \{S_{p}, S_{hn}^{1}, S_{hn}^{2}, S_{hn}^{3}, S_{n}\}을 만들어냅니다. 각 score는 비디오와 각 문장이 프레임별로 상응할 확률값(그림 2 우상단 참고)을 담고 있습니다.
이렇게 추출한 계층적인 score S들은 coarse-to-fine saliency ranking 학습에 사용됩니다. 본 과정에서는 총 2개의 loss를 통해 모델 학습에 관여하게 되는데요, 첫번째는 coarse-grained saliency ranking loss \mathcal{L}_{cr}로, 큰 관점에서의 pos, neg을 구별하는 역할을 수행합니다. 두번째는 fine-grained saliency ranking loss \mathcal{L}_{fr}로, multi-granularity에서의 의미론적인 뉘앙스 차이를 계층적으로 학습할 수 있도록 안내하는 역할입니다. 이 두 loss는 기존 DETR 기반 방법론에 적용되어있던 loss \mathcal{L}_{base}에 추가적으로 더해지며, 기존의 어떠한 방법론에 대해서든 compositional generalization 개선을 도울 수 있는 모듈을 제안한 것입니다.
이제 설명드렸던 각 모듈을 아래 절에서 차례대로 알아보겠습니다.
2.2 Hierarchical Hard Negatives Construction
LLM(=GPT-3.5 Turbo)을 통해 주어진 텍스트 쿼리의 계층적 Hard Negative 문장들을 만들어내는 과정에 대해 살펴보겠습니다. 먼저 HN 구축 과정에서 왜 LLM을 도입하였는지 설득이 되어야할텐데요, 기존 방법론은 미니배치 내 문장들의 주어, 동사를 추출하고 서로를 대체해가며 HN 문장들을 만들어냈습니다. 이러한 방식은 “책상을 먹는다”와 같이 현실적으로 전혀 말이되지 않는 문장도 학습에 포함시키기에 최적의 학습이라고 보기 어려울 것입니다. 수많은 샘플들에 대해 합리적인 HN들을 생성하려면 LLM을 도입해야한다는 것이 저자의 주장입니다.
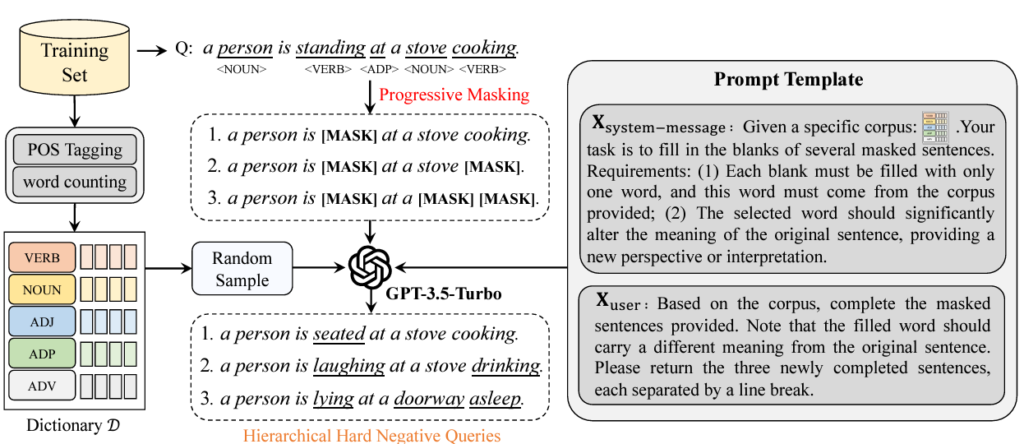
문장은 여러 단어들로 구성되어있을텐데, 먼저 다들 아실법한 자연어처리 라이브러리 SpaCy의 PoS tagging 기능을 통해 각 단어의 품사를 구별해줍니다. 각 단어는 동사, 명사, 형용사, 전치사, 부사 중 하나로 분류되며 5개의 품사를 key로, 각 품사에 속하는 단어들을 value로 갖는 딕셔너리 D를 구축합니다. 이 딕셔너리는 계층적인 HN을 만들 때 활용되는데, 그 이전에 우선 텍스트 쿼리 내에서 동사 – 명사 – 형용사 – 전치사 – 부사 순으로 단어들을 점진적으로 마스킹합니다. 이 과정은 그림 3 가운데 상단의 [MASK] 처리된 문장들을 통해 볼 수 있습니다. 명사를 마스킹하는 경우 문장의 의미를 크게 해칠 수 있기에 최대한 나머지 품사들로 마스킹하고, 그럼에도 부족하면 명사 또한 마스킹했다고 합니다.
이제 LLM을 통해 [MASK] 토큰을 단어로 채워줘야 합니다. 앞서 구축한 D에서 품사만 맞다고 임의의 단어를 가져오는 기존 방식과 다르게 최대한 말이 되는 문장을 만들어주고자 LLM의 힘을 빌리는 것입니다. 그러나 입력 제한이 있는 LLM에 D를 모두 입력해줄 수 없기에, 딕셔너리의 subset을 만들어 그 안에서 단어를 선택해 채우도록 했다고 합니다. 이 과정에서 활용한 프롬프트는 그림 3의 오른쪽과 같습니다. 이렇게 한 샘플마다 3개의 HN를 만들어내며 이들은 원본 텍스트 쿼리와 미묘한 차이를 가지며 말이 되는 문장들입니다. HN은 다음 절에서 설명할 loss를 통해 학습에 관여하게 됩니다.
2.3 Coarse-to-Fine Saliency Ranking
추출한 계층적 문장들은 당연히 비디오와도 계층적으로 상응해야할 것입니다. 원본 GT 쿼리는 GT 구간에 가장 크게, HN들은 GT보다는 약하면서 Negative 샘플보다는 크게 상응해야할 것입니다. 본 절에서는 이 계층을 Coarse / Fine level에서 조절해주는 방식에 대해 설명드리겠습니다.
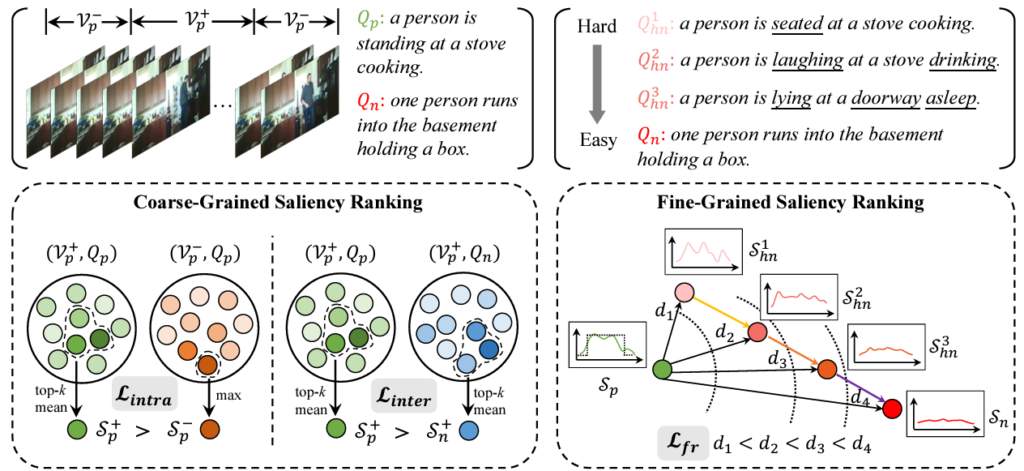
가장 처음 보여드렸던 그림 1에서, 기존 DETR 방법론이 텍스트 쿼리의 미묘한 차이에 잘 대응하지 못하는 모습을 보았었습니다. 이 “대응”의 정도는 DETR 인코더가 출력하는 saliency score로 판별했었죠. 여기서는 비디오-텍스트 saliency score를 계층적 ranking에 맞게 조절해줌으로써 위 문제를 해결하고자 하였습니다.
Coarse-Grained Saliency Ranking
학습 중 비디오의 상응 구간 라벨을 알고있는 상황이기에, 쌍 (V_{p}, Q_{p})가 주어졌을 때 GT 구간 내외부의 클립을 각각 V_{p}^{+}, V_{p}^{-}로 지정할 수 있습니다. Postive 텍스트 쿼리 Q_{p}와 배치 내 다른 텍스트 쿼리중 임의로 하나를 선택하여 negative 쿼리 Q_{n}으로 삼습니다. 직관적으로 V_{p}^{+}의 score들은 V_{p}^{-} score들보다 높아야하며, Q_{p}의 score는 전반적으로 Q_{n}의 score보다 높아야 할 것입니다. 위 두 조건을 만족시킬 수 있도록 아래와 같은 coarse-grained ranking loss \mathcal{L}_{cr}을 학습합니다.
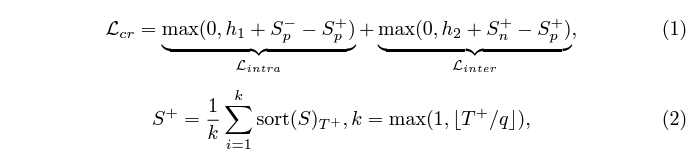
수식에서 S_{p}^{+}, S_{n}^{+}은 각각 V_{p}^{+}와 Q_{p}, Q_{n} 간 score의 top-k mean 값입니다. 그리고 S_{p}^{-}는 V_{p}^{-}와 Q_{p} 간 score의 최대값입니다. 위 수식 (1)을 통해 비디오 내부적으로 GT인 구간, GT가 아닌 구간 간 차이를 학습하고, 더 나아가 GT 구간 중 실제 GT 텍스트 쿼리와 negative 쿼리 간 상응 관계도 학습하는 것입니다.
Fine-Grained Saliency Ranking
LLM이 추출한 3개의 HN 문장들은 점진적으로 마스킹된 단어를 복원하는 형식으로 생성되었기에 순서대로 점점 본래의 텍스트 쿼리와 멀어집니다. 이러한 미묘한 차이까지 모델이 학습할 수 있도록 제안하는 loss가 바로 fine-grained ranking loss \mathcal{L}_{fr}입니다. 마찬가지로, 문장 계층에 따라 모델이 출력하는 saliency score도 비디오의 GT 구간 내에 한해서는 그 계층을 유지해야한다는 것이 기본적인 아이디어입니다.
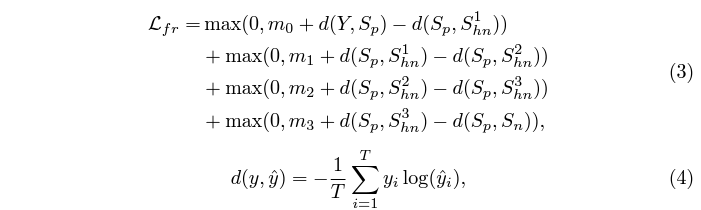
수식 (3)에서 S는 각 문장과 비디오의 saliency score를 의미합니다. 수식 (4)에서 d는 NLL를 의미하며 결국은 각 문장의 계층별로 saliency score 또한 margin m만큼 계층을 갖도록 만들어주게 됩니다. 기존 텍스트 쿼리 뿐만 아니라 HN 문장까지 포함하여 그들의 뉘앙스 차이를 학습시키는 것입니다.
2.4 Model Training Objectives
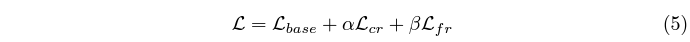
최종적으로는 기존 DETR 기반 모델이 학습하던 loss \mathcal{L}_{base}에 제안하는 loss 2개를 더해 학습하게 됩니다. \mathcal{L}_{base}에는 이분 매칭 loss, L1 regression loss, saliency loss가 포함되어있습니다.
3. Experiments
평가는 모델의 compositional generalization 능력을 평가할 수 있는 두 데이터셋 Charades-CG, ActivityNet-CG에 대해 진행됩니다. 두 데이터셋은 총 4개의 split(Training/Test-Trivial/Novel-Composition/Novel-Word)으로 나뉘어져있으며 이 중 마지막 3개는 각각 IID sample, seen words의 새로운 조합, unseen words의 새로운 조합으로 평가 셋이 구성되어있습니다. 보통은 “Novel-Composition” split을 주 평가 대상으로 삼는 경우가 많습니다.
3.1 Comparisons with the State-of-the-arts
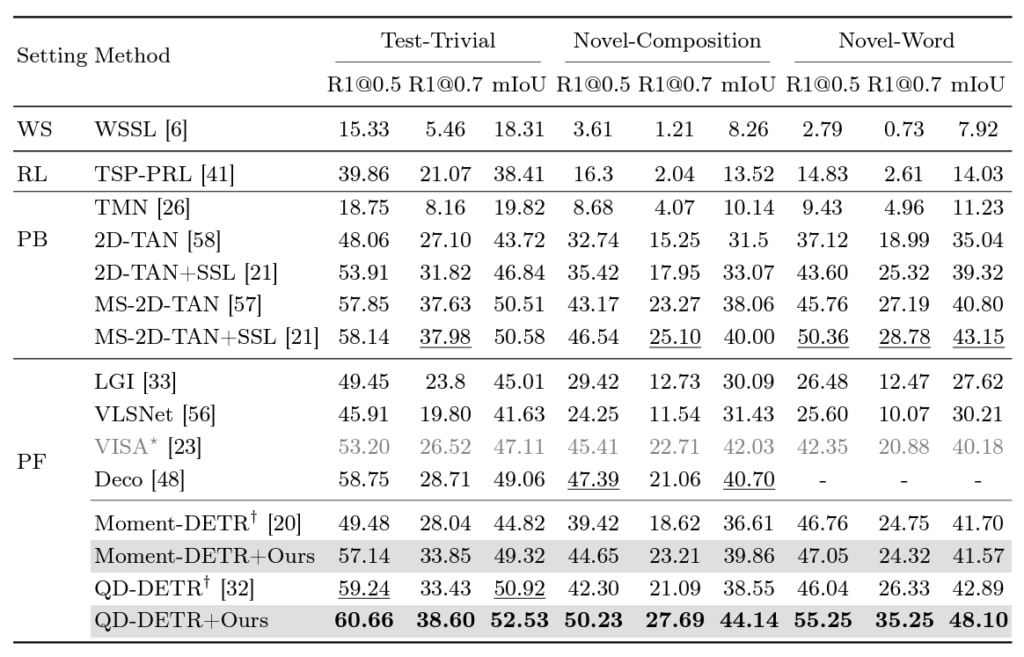
표 1은 Charades-CG 데이터셋에서의 벤치마크 성능입니다. 우선 DETR 기반 방법론 QD-DETR을 해당 데이터셋에서 평가했을 때, 각 split에 대한 성능을 보겠습니다. Test-Trivial은 IID 상황이기에 최신 방법론인 QD-DETR이 좋은 성능을 보여주지만, 확실히 CG을 고려해주지 않았기에 Novel-Composition, Novel-Word split에선 이전 방법론에 못미치는 성능을 보여주고 있습니다. QD-DETR은 텍스트 일반화 성능이 떨어진다는 것이죠. 여기서 알 수 있는 점은 일반 데이터셋에 대해 temporal grounding을 잘하는 것과 composition generalization을 잘하는 것은 별개의 문제라는 것입니다. 중점적으로 고려해줘야하는 부분이 서로 다를 수 있다는 것이죠.
QD-DETR에 저자들의 방법론을 붙여 학습하면 기존 방법론들을 큰 차이로 모두 제치고 가장 높은 성능을 달성하고 있으며, 같은 DETR 기반이지만 QD-DETR의 하위호환 격인 Moment-DETR에 붙였을 때도 CG 성능이 올라가는 것을 볼 수 있습니다. 또한 기존 방법론들 여럿에 쉽게 얹어 학습할 수 있는 모듈을 제안하는 것이 설득력이 좋다는 것이 느껴집니다.
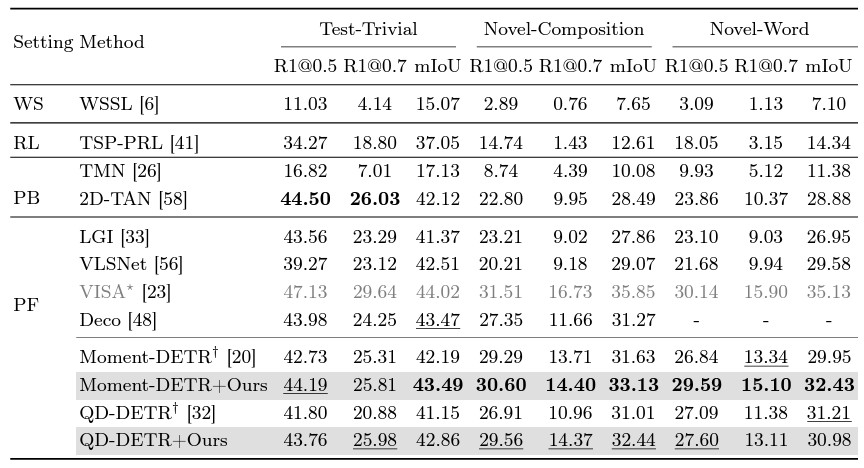
위 표 2는 ActivityNet-CG 데이터셋에서의 성능이며 마찬가지로 QD-DETR에 저자의 방법론을 붙이는 경우 기존 방법론들보다 압도적으로 높은 성능을 달성하고 있습니다. 참고로 회색 처리된 VISA가 전반적인 성능이 더 높은데 이는 Object Detector를 추가로 사용했기 때문이라고 합니다. 중요한 Novel split에선 저자의 방법론이 꽤나 견줄만한 성능을 냈기에 크게 문제되진 않을 것 같습니다.
3.2 Ablation Studies
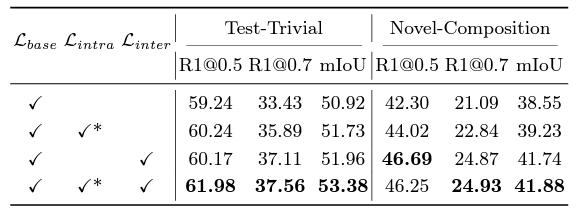
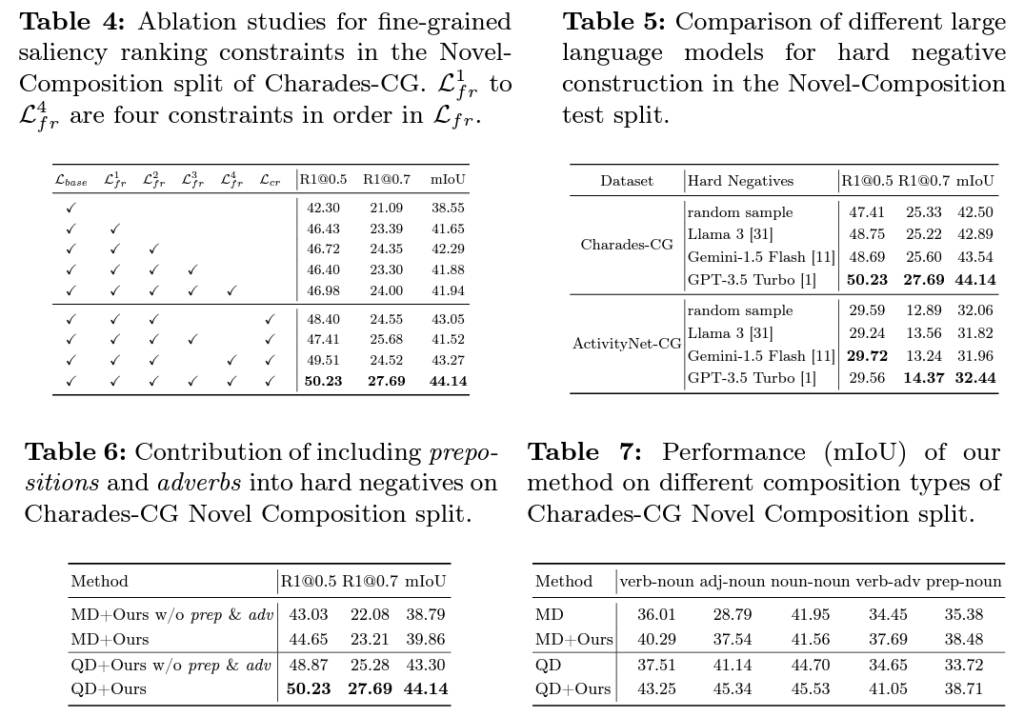
위 표 3, 4는 각각 \mathcal{L}_{cr}, \mathcal{L}_{fr}의 효과에 대해 이야기하고 있습니다. 특히 표 4에서 \mathcal{L}_{fr}의 학습 요소를 더해갈 때마다 저자의 의도대로 확실한 성능 향상을 보여주는 것이 인상깊습니다. 표 5는 HN 생성 시 활용한 LLM ablation 성능인데, GPT가 성능이 제일 좋다고는 하지만 실제 downstream task에까지 영향을 미친다는 점이 놀랍습니다. 지금은 LLM이 필요하면 LLaMa를 무료로 사용하고 있는데, 생각보다 성능 차이가 크네요.
다음으로 표 6은 HN 생성 시 기존 방법론들처럼 주어, 동사만 고려하지 않고 형용사나 전치사 또한 변형해주는 것의 효과를 보여주고 있습니다. 형용사 전치사 사용 여부는 사소한 차이이지만 문장의 다양성을 극대화하여 일반화 성능 향상에 유의미한 역할을 했다고 생각합니다. 마지막으로 표 7은 품사별 novel composition에 대한 성능이고, 모든 composition 조합에서 성능 향상을 일으킨 것을 볼 수 있습니다.
나머지 실험들은 전부 하이퍼파라미터 ablation이라 궁금하신 분들은 질문주시면 답변드리도록 하겠습니다.
4. Conclusion
가장 최근에 리뷰한 DeCo라는 논문과 더불어 Compositional Temporal Grounding을 수행한 몇 안되는 논문입니다. 대부분의 방법론은 CG 능력을 기르기 위해 어떻게 HN 샘플을 증강할지 고민하는데, 마침 LLM을 계속 써보던 요즘 찾게된 적절한 활용방안이라고 생각이 듭니다. 공개한 코드에 문제가 좀 있긴하지만 그럼에도 GPT로 뽑은 HN 문장들과 전반적인 코드도 공개해줘서 원복에도 무리가 없었습니다.
본문에서는 자신들의 방법론의 한계점으로, 멀티모달 task임에도 불구하고 비디오를 참고하지 않고 문장을 변형했다는 점을 짚고있습니다. 개인적으로는 HN의 기준은 비디오에서 벌어지는 사건에 따라 천차만별이 될 수 있다고 생각하기에, visual feature를 고려한 HN 생성이 또 다른 열쇠가 될 수도 있겠다는 생각이 듭니다.
이상으로 리뷰 마치겠습니다. 감사합니다.
안녕하세요 김현우 연구원님 좋은 리뷰 감사합니다.
일반적으로 많이 사용되는 데이터셋에서의 성능보다 Compositionality를 확인할 수 있는 -CG 데이터셋에서의 성능을 많이 개선시켜 논문의 문제정의와 잘 align된 실험 결과를 보여주는 것 같습니다. saliency score를 계층적으로 따르는 ranking loss를 추가했는데 MR의 성능이 많이 오른 점에서 saliency score의 역할도 꽤나 중요한 것 같은데 구체적으로 saliency score가 어떠한 영향을 미치는 지에 대한 저자의 고찰이 있었나요?
감사합니다.
안녕하세요 김현우 연구원님 좋은 리뷰 감사합니다.
Compositionality 관련 논문이라 흥미롭게 읽었습니다. 사실 Video 관련된 분야다 보니, temporal 축에 대해 고려한 모델 학습 기법 설계가 이뤄질 것 같은데, 비디오가 아닌 이미지에 대한 VLM과 동일하게 HN 데이터셋을 만들고 이 차이를 학습하기 위한 Loss 설계만 진행해서, 조금 의아했던 것 같습니다.
Temporal Grounding 에서는 기본이 되는 질문일 것 같은데, DETR 인코더가 출력하는 saliency score가 의미하는 바가 무엇일까요? 시간 축에 대해 해당 텍스트가 프레임과 얼마나 대응하는지를 나타내는 것으로 이해해도 되나요?