오늘 리뷰할 논문은 Learnable Prompt 와 관련된 논문입니다. 2022년 CVPR 에 게재된 논문이고, 바로 리뷰 시작하겠습니다.
1. Introduction / Method
CLIP과 같은 강력한 vision-language 모델 (VLM) 이 등장함에 따라 이후의 연구들에서는 VLM 모델의 강력한 지식/능력을 downstream dataset/task 에 효과적으로 적용하기 위한 연구들이 수행되고 있습니다. VLM 모델은 일반적으로 수억~수십억개의 파라미터로 구성되어 있기 때문에 모델 전체를 미세 조정하는 것은 비현실적일 뿐 아니라 잘 학습된 표현 공간을 손상시킬 수 있습니다.
이보다 안전한 방식은 목표하고자 하는 상황에 맞게 프롬프트를 조정하는(엔지니어링하는) 방식입니다. 가령 애완동물 데이터 셋에 대한 학습을 진행하고자 한다면 “a type of pet” 뭐 이런 프롬프트를 사용할 수 있습니다. 하지만 이러한 프롬프트 엔지니어링 방식은 시행착오를 거쳐야 하기 때문에 시간이 오래걸리고, 최적의 프롬프트를 보장하지는 않는다고 합니다.
이를 해결하고자 NLP 진영에서의 프롬프트를 학습 가능한 vector로 간주하는 컨셉을 VLM에 적용하여, Context Optimization (CoOp) 라고 하는 연구가 제안되었습니다. 이는 문장의 문맥(context) 정보를 학습 가능한 형태로 변환하여 labeled image 몇장만으로 적절한 prompt 를 학습해나간다고 합니다. 아래 그림 1의 중간 부분에서 보시다시피, 기존 clip zero-shot 의 context prompt 인 ‘a photo of a’ 부분을 학습 가능한 M개의 벡터로 대체하여 학습을 진행하는 방식입니다.

본 논문은 CoOp와 동일한 저자들이 수행한 연구로, 학습때 보지 못한 new classes에 대한 일반화 성능이 낮다는 CoOp의 문제점을 꼬집고 새로운 방식을 제안하게 됩니다. 위 그림 1에서 3가지 프롬프트 방식에 대한 base/new classes 성능 비교를 살펴보면 꽤나 인상적입니다.
CoOp가 학습한 context는 base classes 에서는 80.6 으로 세가지 방식 중 가장 높은 정확도를 달성합니다. CoCoOp 의 경우는 79.74로 약 1 정도 낮은 정확도를 보이네요. 하지만 new classes 에서 둘의 성능 차이를 보시면 10 이상이 나는 것을 보실 수 있습니다. 저자는 이에 대해 한번 학습이 되면 평가때는 고정되는 CoOp의 context가 학습때 본 base classes에 최적화되어져 버려 새로운 new classes에는 잘 대응을 하지 못한것이라 언급합니다. 반면 CoCoOp 는 new classes에서 높은 정확도를 보이고 있고, 심지어 CLIP zero-shot 성능도 75 이상인 것을 확인할 수 있습니다.
CoOp의 낮은 일반화 성능을 해결하기 위해, 조건부 프롬프트 학습 (conditional prompt learning) 이라고 하는 새로운 개념을 제안합니다. 핵심 아이디어는 한번 학습된 프롬프트가 고정되지 않고 각 입력 이미지 (instance)에 따라 유동적인 조건부 프롬프트를 만드는 것입니다. 얕은 신경망으로 구성된 Meta-Net을 추가적으로 구성하여 각 입력 이미지 feature로 부터 meta token 을 생성한 후 기존 CoOp의 학습 가능한 context vector와 더해지는 방식으로 프롬프트를 구성하게 됩니다. 방식은 매우 간단하며, 이에 대한 개념도는 아래와 같습니다.
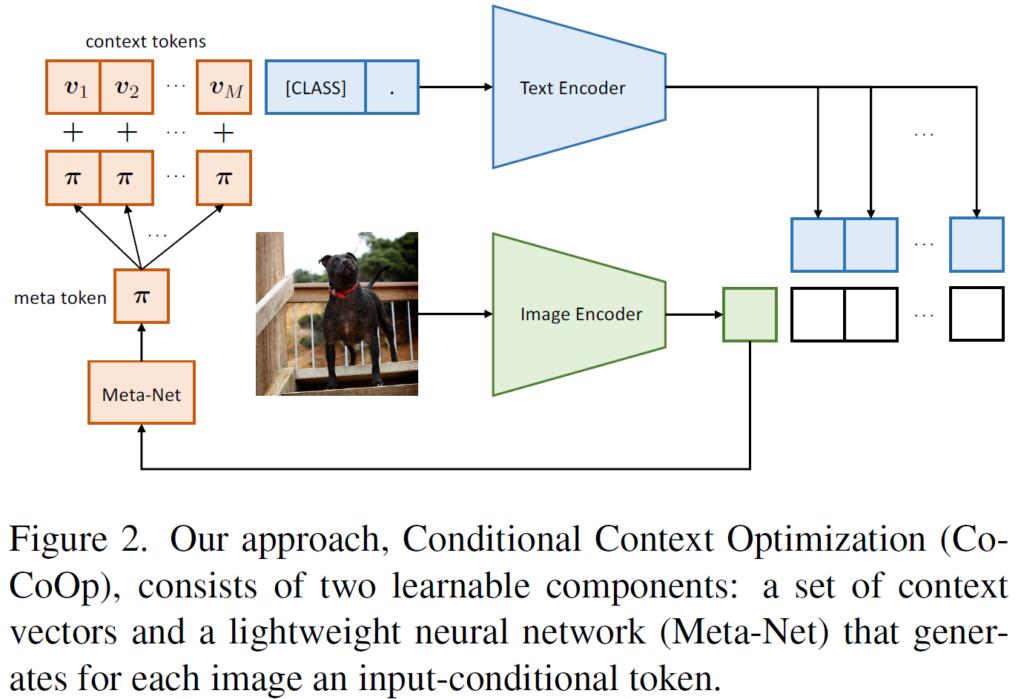
학습 가능한 M개의 context tokens v_1~v_M에 더해지는 meta token 을 구성하기 위해 linear-relu-linear 로 구성된 효율성있는 Meta-Net을 사용합니다. 이때 Meta-Net 의 입력으로 들어가는 것은 각 image instance 로 부터 추출된 feature 입니다. M개의 context token에 meta token 을 더해서 최종 학습가능한 context prompt t_i(x)를 구성하게 되고, 이후는 앞선 CLIP과 동일하게 similarity 기반 확률을 계산할 수 있게 됩니다. 수식으로는 아래와 같습니다.
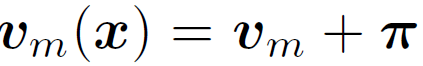
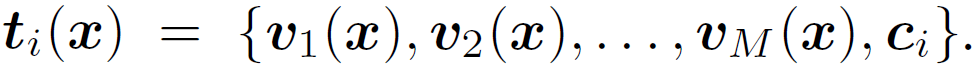

학습이 수행되는 동안 Image/Text encoder는 freeze 된 상태로 진행이 되며, Meta-Net과 context token v_1~v_M 이 update 되게 됩니다.
2. Experiments
실험은 크게 아래 3가지 섹션으로 진행되게 됩니다.
- 단일 데이터셋 내에서 base classes로부터 new classes로의 generalization 성능 평가
- cross-dataset transfer 성능 평가
- domain generalization 성능 평가
2.1. Generalization From Base to New Classes
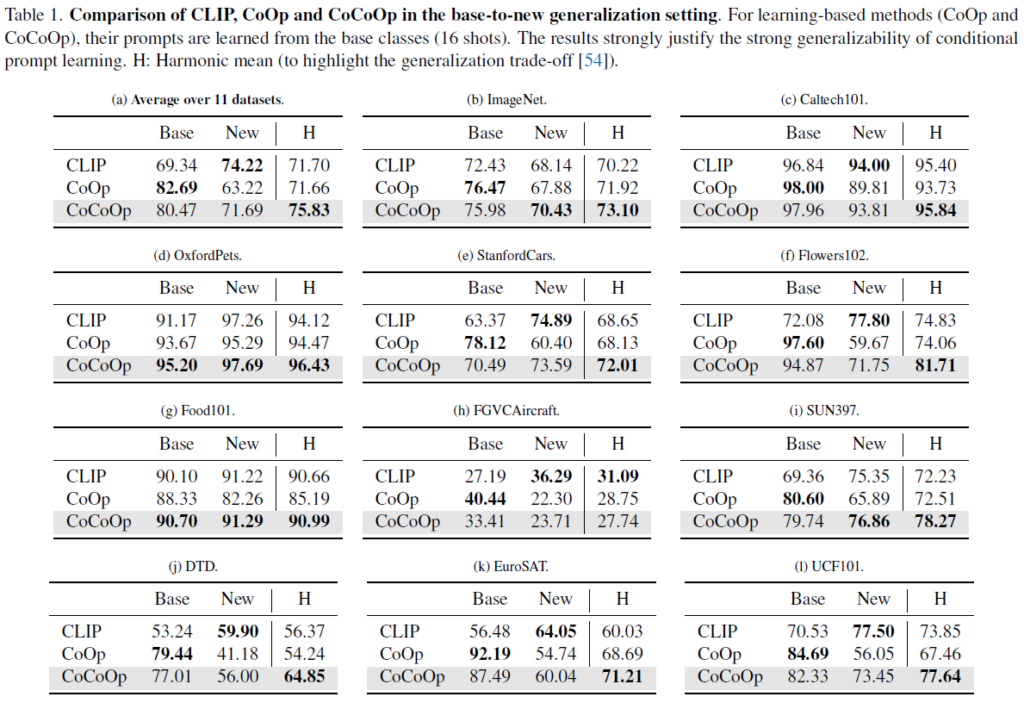
앞선 CoOp 의 약한 일반화 성능 문제 해결이 본 연구의 핵심이였습니다. 이를 비교하기 위해 11개의 datasets에 대해서 비교 실험을 진행하였고, 아래 표 1을 보시면 됩니다. base classes에 대한 학습 후, base/new classes 에 대한 평가를 진행 한 결과입니다.
Failures of CoOp in Unseen Classes
각 데이터셋 별로 CLIP zero-shot 의 base/new classes 성능을 비교해보면 base가 더 높을때도 있고 new가 더 높을 때도 있습니다. 이 말은 즉슨 항상 base가 쉽거나 new가 쉬운 상황으로 split 된 것은 아니라는 말입니다.
하지만 이러한 상황에서도 CoOp의 성능을 비교해보시면 항상 Base에서 높은 성능을, 반면 new 에서는 매우 낮은 성능을 보이는 것을 볼 수 있습니다. 평균으로 봤을때 (좌상단 a) 약 20% 정도나 되는 큰 차이를 보이고 있습니다. 즉 CoOp 방법론이 new(unseen) classes에 대해 일반화 성능이 낮다는 것을 보여줍니다.
CoCoOp significantly Narrows Generalization Gap
위 표 1의 (a) 에서 확인할 수 있듯이, CoCoOp 는 unseen classes 에서의 정확도를 71.69% 로 향상시켜 CLIP 의 manual prompts 와의 격차를 크게 줄였습니다. base 에서는 확연히 높은 성능을 보이고 있구요. 특히 아래 그림 3-(a) 에서 시각화 된 바와 같이, CoOp 와 비교했을 때 모든 데이터셋에서 unseen classes 에 대한 성능이 큰 폭으로 올랐고, 특히 까다로운 Image-Net 에서 2.55가 향상된 70.43%의 성능은 눈여겨 볼 사항이라고 저자들은 말합니다. (CLIP zero-shot 성능은 이보다 낮은 68.14% 입니다.)
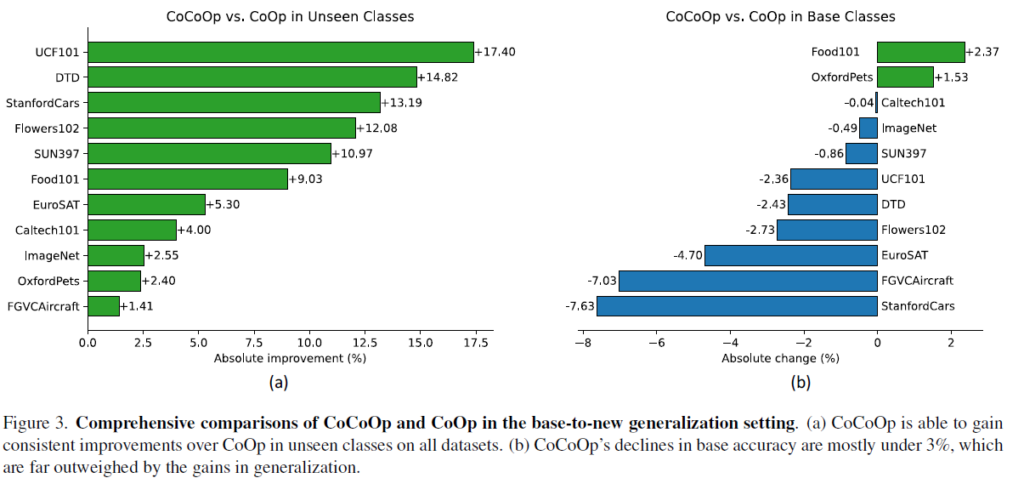
CoCoOp’s Gains in Generalization Far Outweigh Losses in Base Accuracy
위 그림 3-(b)를 보시면 대부분의 데이터셋에서 CoOp 대비 base classes 의 성능 하락이 발생합니다. 이는 어쩔 수 없는것이 CoOp는 base classes에 대해서만 최적화 하는 반면 CoCoOp는 전체 작업에 대한 일반화를 위해 각 instance에 대해 두루두루 최적화를 진행하기 때문입니다. 다만 이렇게 base classes에서의 성능 하락이 조금 발생했다고 한들 unseen classes 에서의 일반화 성능 향상폭이 훨씬 크기 때문에 전체 평균적으로 봤을때에는 성능 향상을 달성했다고 합니다.
2.2. Cross-Dataset Transfer
위 2.1 절에서 단일 데이터셋 내에서의 일반화 성능을 보였다면, 본 절에서는 서로 다른 데이터 셋 상황을 고려하여 성능 비교를 수행합니다 (A->B).
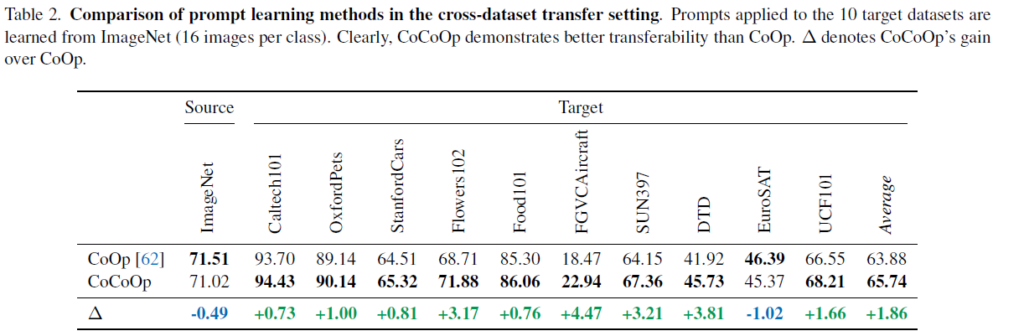
1000개의 class, 각 class 당 16장의 이미지를 사용하여 context prompt 를 학습한 후 다른 10개의 target dataset에서의 성능 평가를 수행한 결과입니다. source 에서는 유사한 성능을 보인대에 반해 target 에서의 평균치를 보면 약 2%의 성능 향상이 이루어 진 것을 볼 수 있습니다.
ImageNet class는 보통 다양한 사물과 개 품종을 포함하고 있기에 Caltech101, OxfordPets 등의 데이터어센 평균적으로 높은 성능을 보입니다. 반면 GVCAircraft, DTD(다양한 텍스처를 포함) 과 같은 세분화/전문화된 데이터셋에서의 평균적인 성능은 낮지만, CoOp 보다는 더 높은 성능 향상을 달성합니다.
2.3. Domain Generalization
다음으로는 domain generalization 관점에서의 실험 결과입니다. 위 2.2절과 동일하게 ImageNet에서 1000개의 class, 각 class 당 16장의 이미지를 사용하여 학습을 수행하였고 평가로는 ImageNet의 여러 도메인 상황을 반영한 4가지 평가셋을 사용했습니다.
CLIP 과 비교했을 때 CoOp, CoCoOp 모두 source ImageNet 에서도 4 이상의 성능 향상을 달성하였습니다. 또한 target 상황에서의 CoOp vs CoCoOp 성능을 비교했을 때 ImageNetV2를 제외하고는 더 높을 일반화 성능을 달성하였습니다. 이를 통해 저자들은 intance conditional prompts 방식이 DG에서도 좋은 역할을 한다고 주장합니다.

+ Limitations
성능적으로는 CoOp 에 비해 전반적으로 좋지만, 저자들은 본 CoCoOp 방식에 몇몇 한계가 있다고 말합니다. 우선 학습 효율성 입니다. 설계 특성 상 학습 속도가 느리고, 각 instance 개별적으로 meta token 을 만들고 text encoder로 전달해야 하기 때문에 상당한 시간/메모리 소모가 있다고 합니다. 또한 CLIP 과 비교했을때 표 1에서 전체 11개 데이터셋 중 7개의 데이터셋에서 아직 unseen classes의 성능이 CLIP 대비 낮다는 점을 짚습니다.
방법론 자체는 간단하지만, 그 컨셉 및 효과가 톡톡한 learnable prompt 논문이였습니다. 학습 가능한 prompt 를 사용하는 CoOp 에다가 각 instance 별로 독립적으로 생성되는 meta token을 더해주는 과정을 통해 unseen classes 로의 일반화 성능을 잘 달성하였습니다. 그럼 리뷰 마치도록 하겠습니다.
안녕하세요 권석준 연구원님 좋은 리뷰 감사합니다.
prompt learning 의 대표적인 연구인 CoCoOp에 대해 리뷰해주신 것 같습니다.
제가 이해한 바로는, 기존에는 “A photo of (class)” 를 토큰으로 바꿔서 텍스트 인코더의 input으로 넣었다면, 본 연구에서는 “A photo of”의 토큰값을 임의의 벡터값으로 바꿔서 실험을 진행한 것 같습니다. 이 때, 이미지 벡터로부터 뽑은 메타토큰을 텍스트 토큰에 추가하여, 이미지 입력에 따라 prompt에 다른 값을 더해주는 것이 목적인 것 같습니다.
여기서 이 Meta Token에 대해 궁금한 점이 있어서 질문 드립니다.
Meta Token을 만들어주기 위한 Meta-Net은 Linear-ReLU-Linear이라는 아주 단순한 구조라고 하셨는데, 왜 이런 구조를 가지는지 메타 토큰과 관련된 또 다른 실험은 없는지 궁금합니다. 즉, 다른 방식으로 Meta-Token을 설정하였을 때의 실험이 없는지요?
댓글 감사합니다.
아랫 문단의 질문에 대한 답변을 드리자면, 아쉽게도 관련 실험은 없습니다. Meta-Net의 구조를 어떤식으로 설계하면 더 효율적일지~ 에 대한 인사이트를 제공하고자 한 것이 아니라, 간단한 구조를 사용하더라도 효과가 있음을 강조하고자 이렇게 간단하게 설계한 듯 합니다.
부가적으로 저자들은 ‘future work 에서 다른 연구자들이 meta-net 구조와 관련된 연구도 수행하길 바란다~’ 라는 식으로 언급하고 있긴 합니다.
좋은 리뷰 감사합니다.
간단한 방법이지만 novel class에 대해 일반화 성능을 끌어 올린 것이 인상 깊었습니다.
리뷰 내용 중 상세하게 궁금한 부분이 있어 질문 드립니다.
“CoCoOp’s Gains in Generalization Far Outweigh Losses in Base Accuracy”에서의 내용 중
“이는 어쩔 수 없는것이 CoOp는 base classes에 대해서만 최적화 하는 반면 CoCoOp는 전체 작업에 대한 일반화를 위해 각 instance에 대해 두루두루 최적화를 진행하기 때문입니다. ” 해당 내용에 따르면 CoOp와 CoCoOp의 학습 방식이 상이한 것 같습니다. 어떤 부분이 다른지 설명 부탁드립니다.
추가로 CLIP 모델 크기와 크기에 따른 성능 리포팅 결과는 따로 없는지 궁금합니다.
댓글 감사합니다.
CoOp는 meta-token 을 더하는 과정 없이 모든 학습 데이터셋들이 하나의 learnable prompt 를 업데이트하는 방식으로 학습이 진행됩니다. 그렇기에 학습때 만나는 base class에 치중될 수 밖에 없고 novel class에 대한 성능은 떨어지죠.
반면 CoCoOp 의 경우는 이런 base class fitting 문제를 막고자 학습때 입력으로 들어오는 각 image instance(각각) 에서 구해지는 feature 를 meta-net 에 통과시켜 meta token 을 더해서 prompt learning 을 수행하게 됩니다. 즉 계속해서 조금씩 다른 meta token 들이 추출될것이기에 매번 조금씩 다른 learnable prompt 들이 학습때 사용되고 이에따라 base class fitting 문제도 완화됩니다.
안녕하세요. 좋은 리뷰 감사합니다.
본 논문에서 meta token이라는 것을 제안한 이유가 CoOp의 context token(vector)가 학습때 본 base classes에 최적화되어버려 new classes에는 잘 대응하지 못하기 때문이라 이해하였습니다. 그런데 의아한 부분은 meta token이라는 것을 간단한 신경망을 통해서 구한 다음 context token에 전체적으로 일괄적으로 더해주는데, 단순히 A라는 token에 A+알파가 되는 것이 어떻게 new classes을 대응하는데 큰 도움이 되었는지 잘 이해가 되지 않습니다. 더해주는 알파가 학습되면서 값이 달라지기 때문인가요?
감사합니다.
댓글 감사합니다.
이 부분에 대한 간접적인 이해를 위해선 data augmentation 을 예로 들어 생각해보면 될 듯 합니다. 아무런 augmentation 없이 모델을 학습하게 될 경우 모델이 학습 데이터에 치중되어 버리는 문제가 발생하게 됩니다. 그렇기에 augmentation 기법을 통해 학습 이미지들을 조금씩 다른 형태로 넣어서 치중/과적합을 방지하죠.
그런 관점에서 본 논문에서는 마치 입력 learnable prompt 에 계속해서 유동적으로 변화하는 meta token 을 더하고자 합니다. 마치 prompt augmenation과 같은 효과를 볼 수 있는 것이지요. 즉 이를 통해 base classes 로의 과적합을 방지할 수 있다고 생각하시면 될듯합니다.