안녕하세요, 쉰 한번째 x-review 입니다. 이번 논문은 24년도 마지막 날에 arXiv에 올라온 KAIST에서 작성한 논문 입니다. 열화상 영상을 최근에 어떻게 활용하고 있는지에 서베이를 하다가 발견한 논문으로 처음으로 VLM을 활용할 때 열화상 센서 뿐만 아니라 여러 멀티 센서에 대해 고려하였다고 합니다.
그럼 바로 리뷰 시작하겠습니다 !

1. Introduction
최근에 large scale의 VLM이 인공지능의 일반화된 지능(AGI)를 추구하며 여러 task에서 활용되고 있습니다. 인간의 사고 방식과 유사하게 멀티 센서의 정보를 받아 복잡한 inference를 처리할 수 있도록 하죠. 가령 GPT-4o는 사람의 추론 능력과 유사한, 때로는 그 이상을 보여준다고 평가받고 있습니다.
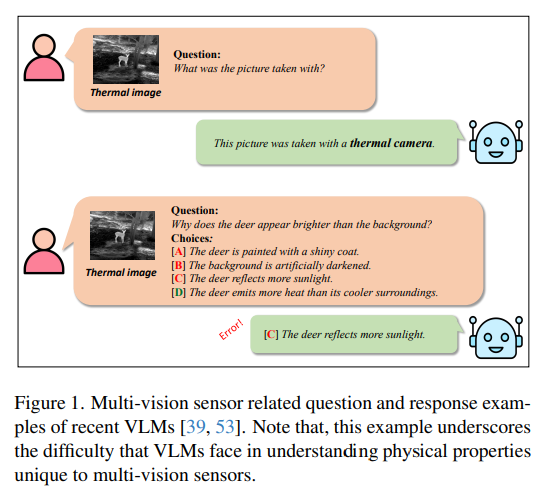
자율주행이나 로보틱스 분야에서 real world 상황에 연결하는 여러 장치들은 흔히 멀티 비전 센서가 있기 때문에 VLM이 멀티 센서의 정보를 이해하는 것은 필수라고 할 수 있습니다. 열화상 영상이나 depth 센서, 그리고 X-ray 검출 영상과 같이 다양한 비전 센서는 인간의 눈으로 보는 그 이상의 정보를 제공하며 real-world 환경의 이해에 기여하고 있습니다. 사람은 이러한 멀티 비전 센서의 이미지를 센서의 특성에 대한 컨텍스트한 지식을 기반으로 해석할 수 있지만, 저자는 VLM은 멀티 비전 센서에 대한 이해에 아직까지 상당한 어려움을 겪고 있다고 지적합니다. Fig.1을 보면 인간과 VLM 사이의 대화 예시가 있는데요, VLM은 이미지가 주어지면 이미지를 제공하는 센서의 종류에 대해서는 쉽게 이해하는 것을 확인할 수 있습니다. 반면 그 이미지 내의 정보에 대해 추론하고 이해하는, 더 고도화된 질문에 대해서는 잘못된 답변을 하게 됩니다. 만약 사람이 Fig.1의 열화상 이미지를 봤다면, 영상 내 장면에 대한 직접적인 경험이 없어도 센서의 특성에 대한 지식과 맥락적인 이해를 통해 열의 분포에 따라 예시의 이미지가 취득된다는 것을 해석할 수 있습니다. 그러나 VLM은 열화상 이미지에서 밝게 나타나는 부분이 열 때문이 아닌 빛 반사 때문이라고 혼동할 수 있다는 것 입니다.
저자는 이러한 오류에 대해 VLM이 보통 RGB 이미지를 기준으로 학습되기 때문이며, 이러한 학습 방식이 RGB 센서 이외의 다른 멀티 비전 센서들 마다의 정보를 제공하는 고유한 특성을 이해하는 것을 어려워하게 된다고 주장합니다. 즉 RGB 이미지 기반의 inference를 통해 멀티 비전 센서에 대한 이해 없이 센서별로 디테일한 정보를 이해하는 능력이 제한되는 것 입니다. 좀 더 예를 들어보면 앞서 예시로 본 것 같이 열화상 이미지에 대해서나, 또는 depth 이미지에서 fog와 haze에 대해 혼동하는 등 센서의 특징을 이해하지 못하는 경우가 종종 발생한다고 하네요. 이렇게 VLM은 멀티 비전 센서의 실제 물리적인 특징을 이해한다기보다는 학습된 RGB 이미지에서 비슷한 이미지의 패턴에 의존하게 됩니다. 이런 오류는 자율 주행이나 의료 영상 진단과 같이 사용하는 센서에 대해 높은 정확도가 중요한 어플리케이션 관점에는 critical한 영향을 미치게 되죠.
그래서 본 논문에서는 앞서 언급한 challenge함을 해결하기 위해 Multi-vision Sensor Perception and Reasoning (MS-PR)이라는 새로운 벤치마크를 제안합니다. MS-PR 벤치마크는 멀티 비전 인지와 추론 task로 구성되어 있습니다. 또한 저자는 VLM에서 멀티 비전 센서에 대한 이해도를 향상시키기 위해 새롭게 Diverse Negative Attributes (DNA) 최적화를 함께 설계하였습니다. DNA 방식은 다양한 negative 샘플을 이용하여 RGB 영상 외에 다른 센서 데이터가 부족한 상황에서 센서 고유의 context 정보 학습을 향상시킬 수 있습니다. 최적화 과정에서 다양한 negative 샘플이 사용되어 VLM이 inference 하는데 있어서 RGB-bounded하다는 한계를 해결하고자 하였습니다.
MS-PR 벤치마크로 평가했을 때 대부분의 VLM은 다양한 범위에서 센서 inference를 하는데 한계가 있다는 것을 확인했으며, 제안한 DNA 최적화를 적용한 VLM은 멀티비전 센서 inference에서 큰 성능 향상을 이루었다고 합니다. 이런 관점에서 본 논문의 main contribution을 정리하면 다음과 같습니다.
- 처음으로 멀티 비전 센서 inference에서 현재의 VLM의 한계에 대해 파악하였으며, 이를 해결하기 위해 MS-PR 벤치마크를 제안하여 멀티 비전 센서 inference 성능을 평가하 수 있는 프레임워크 제공
- 제한된 센서 데이터 내에서 센서에 대한 이해 능력을 향상시킬 수 있는 DNA 최적화를 제안하여 모델 구조를 변경하지 않고 모든 large scale의 VLM에 적용 가능
- MS-PR 벤치마크를 사용하여 10개의 SOTA VLM을 평가하고 DNA 최적화를 통해 멀티 비전 센서 추론에서 개선된 성능을 증명
2. Multi-Vision Sensor Perception and Reasoning (MS-PR) Benchmark
2.1. Evaluation on Multi-vision Sensor Tasks
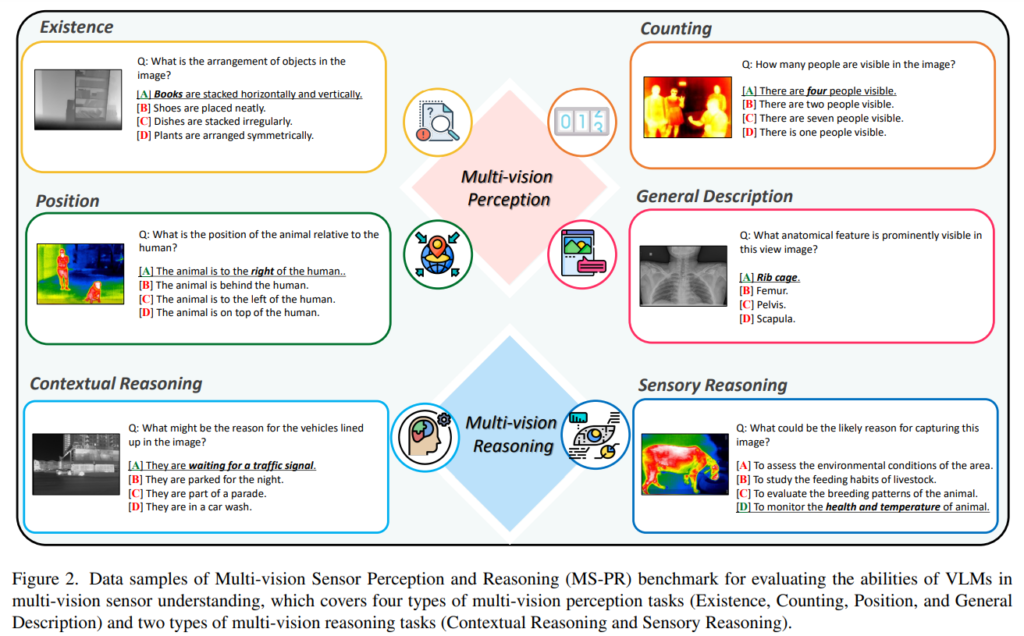
먼저 벤치마크 데이터셋은 두 개의 멀티 비전 task(멀티 비전 인지, 추론)에 대해 수집되었다고 합니다. Fig.2를 보면 멀티 비전 인지는 여러 센서 입력에서 정확하게 물체, 장면, 그리고 관계를 인지하고 해석할 수 있는 능력을 요구합니다. 이는 흔히 아는 object detection, classification 뿐만 아니라 relationshi detection과 scene regognition이 포함되며 모델은 여러 비전 센서 이미지의 내용을 처리하고 이해할 수 있어야 합니다. 핵심적인 목적은 모델이 하나의 정보에 대해 여러 비전 센서가 들어왔을 때 context와 시각적인 요소를 일관되게 인지하고 분류하는 것 입니다.
반면에 멀티 비전 추론은 단순히 인지하는 것을 넘어서 멀티 비전 센서 데이터를 가지고 복잡한 추론이 가능해야 합니다. 이는 센서를 사용하는 의도를 파악하고, 센서에 대한 지식을 이해하는 것과 같이 고차원적인 인지 task가 포함됩니다. 즉 context한 센서 지식을 포함하여 단순한 인지를 넘어 논리적인 추론을 수행하는 것이 VLM의 역할 입니다.
2.1.1. Multi-vision Perception
멀티 비전 인지는 VLM이 열화상, depth, 그리고 X-ray 이미지 등 다양한 센서 이미지를 분석하는 기본적인 task로, 이 안에는 시각 데이터가 입력으로 들어왔을 때 기본적인 구성 요소를 인지하고 해석하는 작업이 아래와 같이 포함됩니다.
(1) Existence
- 이미지 내에 존재하는 물체(사람, 자동차, 동물 등)를 인지하고 나열
(2) Count
- 인지되는 물체나 entity의 수를 conting
(3) Position
- 이미지 내 물체의 공간적인 배치를 이해하고 존재하는 물체들에 대한 상대적인 위치를 파악
(4) General Description
- 이미지가 담고 있는 전체 scene에 대한 설명을 생성
정리하면 인지에 대해서 VLM은 멀티 비전 센서로 취득한 raw 데이터에서 필요로 하는 정보를 추출하는데 초점을 맞추게 됩니다. 복잡한 이후의 모든 추론 작업이 가능하기 위해서는 위와 같은 기본적인 인지가 정확하게 동작해야 하겠죠.
2.1.2. Multi-vision Reasoning
앞선 단순 인지를 넘어 VLM은 논리적인 추론을 통해 더 고도화된 insight를 제공할 수 있습니다. 본 논문에서 다루는 추론 작업은 크게 두 가지가 있습니다.
(1) Contextual reasoning
- 기본적인 지식과 context한 정보를 활용하여 주어진 이미지에 대한 판단
- VLM은 이를 통해 추론 과정이 이미지가 제공하는 context와 일관성을 유지할 수 있도록 함
(2) Sensory reasoning
- 2D 이미지를 다양한 멀티 비전 센서와 관련된 물리적인 정보에 매핑하는 복잡한 추론 능력
- raw 이미지를 처리하는 것을 포함하여 real world에서 기본적인 센서 지식에 대한 특정 정보와 통합
- 이를 통해 surface 레벨에서의 이미지 인식을 넘어 VLM이 실제 환경을 얼마나 정확하게 반영하는 지를 알 수 있으며, 센서 데이터에 대한 높은 이해도를 필요로 함
2.2. Evaluation Benchmark Design
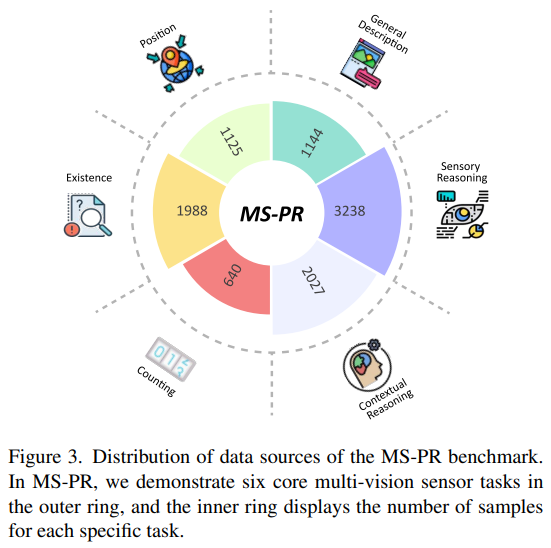
설계한 벤치마크는 VLM이 멀티 비전 센서의 이해 능력을 평가하는 것을 목표로 하기 때문에, Fig.3과 같이 6개의 task에 따라 이미지를 필터링하여 저해상도나 sequence하게 취득된 이미지를 제외하고 해당하는 질문 퀄리티를 개선하였다고 합니다.
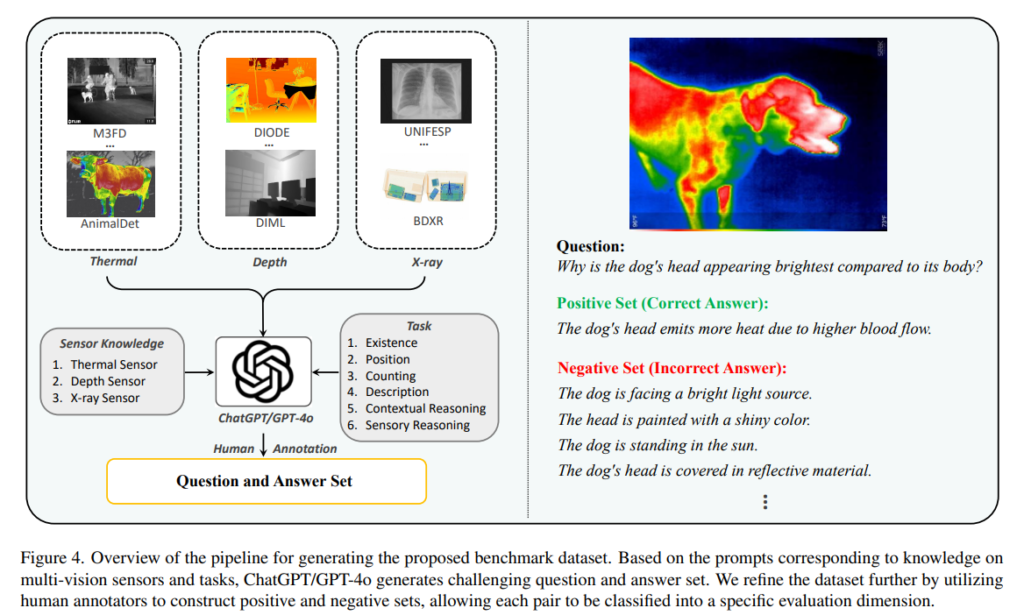
그리고 멀티 비전 센서 입려과 관련된 세부적인 질문 set을 curating하여 VLM이 이미지 정보를 해석할 수 있도록 하였습니다. 그 다음 ChatGPT와 GPT-4o를 사용해서 센서에 대한 지식과 task 프롬프트를 기반으로 challenge한 질문-답변 pair set을 생성하였습니다. 이를 통해 각 센서는 특정 센서의 특성과 관련된 고유한 정보를 제공할 수 있으며, multi-hop 추론과 센서에 대한 높은 이해가 필요한 challenge한 질문도 생성할 수 있게 되죠.
이렇게 만들어진 질문-답변 데이터에 대해서는 사람이 검토하여 최종 positive set을 완성하게 됩니다. 반면에 negative set은 아예 틀린 답변 뿐만 아니라 그럴 듯 하지만 맞지 않는 답변까지 포함하였습니다. 추가적으로 각 질문-답변 쌍은 인간의 추론 능력을 모방하여 단계적으로 세부적인 정보에 집중할 수 있도록 CoT instruction으로 구성하였다고 하네요.
3. Enhancing Multi-vision Sensor Reasoning
3.1. Problems on Multi-vision Sensor Data
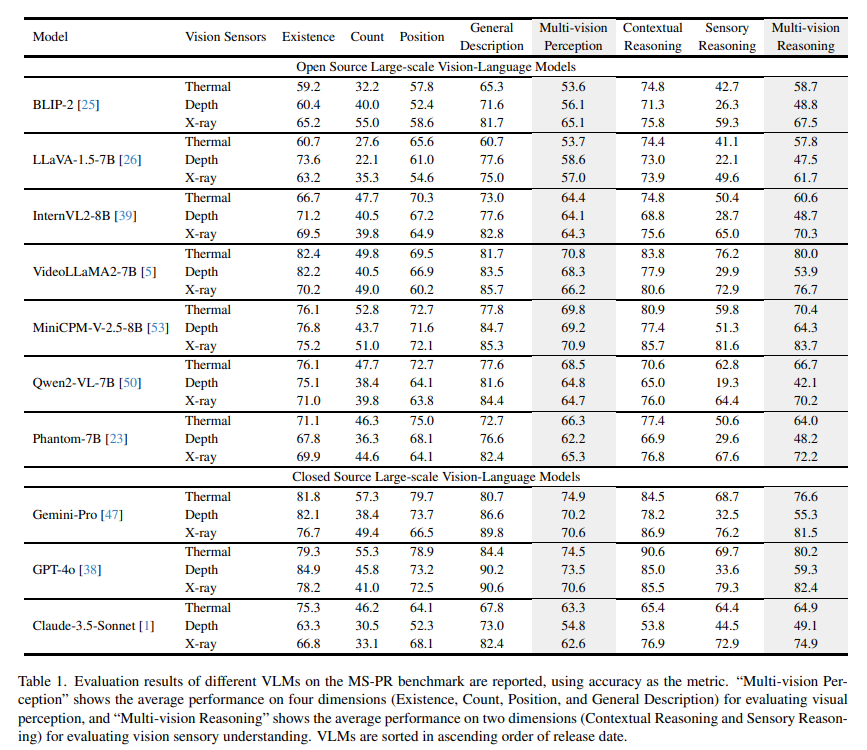
MS-PR 벤치마킹을 통해 VLM의 멀티 비전 센서 추론 한계를 Tab.1과 같이 확인할 수 있습니다. 이런 결과가 나타나는 가장 큰 이유는 공개적으로 사용할 수 있는 멀티 비전 센서 instruction-tuning 데이터셋이 부족하기 때문이라고 합니다. 여러 센서에 대한 지식을 학습할 수 없기 때문에 VLM이 이미지 정보를 잘못 이해하고 분석하는 경향이 나타나는 것이죠. 그래서 본 논문에서는 이러한 한계를 고려하여 제한된 데이터셋에서도 효과적으로 학습할 수 있는 데이터 중심의 접근을 하게 됩니다. 데이터의 일부마을 사용해서 원래 규모의 데이터셋에서와 비슷한 성능을 도달할 수 있도록 하기 위해 센서 종류별로 200개씩, 총 약 600개의 멀티 비전 센서 이미지를 따로 구성하였다고 합니다. (MS-PR 평가 벤치마크에 포함도지 않는 600개의 데이터를 별도로 구성한 것 입니다.)
3.2. Diverse Negative Attributes Optimization
본 논문에서 MS-PR 벤치마크와 더불어 DNA 최적화 방식을 설계하였다고 말씀드렸는데요, 이전의 강화 학습 기반의 방식과 다르게 DNA 최적화는 supervised fine tuning에 loss를 추가하여 학습 과정에서 RGB 기반의 추론을 줄이도록 하였습니다. 이는 모델이 positive를 찾아냄과 동시에 제한된 데이터에서 다양한 negative 샘플을 사용하여 negative 답변에 헷갈리지 않도록 학습하는 최적화 방식이라고 할 수 있습니다. 아래의 식(1), (2)와 같이 autogressive supervised fine-tuning(SFT) loss를 사용하였다고 합니다.
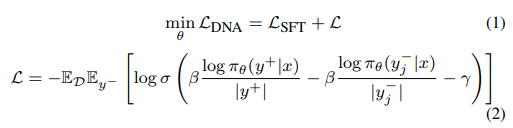
- \theta : 학습되는 파라미터
- \mathcal{L}_{SFT} : 질문-답변 쌍에 대한 SFT loss
- x : 특정 입력 프롬프트
- y^+ : positive 답변
- y^-=\{y^-_1, y^-_2, …, y^-_k\} : k개의 부정확한 negative 답변
DNA 최적화 방식은 학습 데이터가 제한되는 시나리오에서 다양한 negative 샘플을 통해 학습 과정에서 모델이 positive 샘플에 집중할 수 있도록 설계되었습니다. 이러한 설계 방식은 다양한 센서 데이터가 부족한 상황에서 유용하게 사용할 수 있게 됩니다. 또한 VLM이 RGB-bounded 추론에 의존도가 높기 때문에 멀티 비전 센서 데이터를 잘못 해석하게 되는데요, DNA는 여러 negative 답변을 생성하여 VLM이 비슷해 보이는 RGB 이미지와 혼동하지 않도록 할 수 있습니다. 결국 멀티 비전 센서 데이터에 대해 VLM이 센서마다 특화된 context 정보를 더 정확하게 이해할 수 있는 것 입니다.
4. Experiment
4.1. Experimental Setup
4.1.1. Dataset Collection
MS-PR 벤치마크 데이터셋을 구축하기 위해 다양한 상황을 나타내는 약 7천 개의 이미지를 포함하는 총 13개의 데이터셋을 수집하고, 수집한 이미지로부터 약 1만 개의 평가용 질문을 생성하였다고 합니다. 멀티 비전 센서 데이터 중 depth 이미지는 indoor/outdoor 환경에서 여러 환경과 물체를 포함하고 있습니다. 열화상 이미지는 차량 내 센서와 풍경, 사람, 동물, 열화상 screening&scanning과 같이 다양한 시나리오에서의 데이터로 구성되어 있습니다. 마지막으로 X-ray 이미지는 인체의 특정 부위 이미지와 공항 수하물 보안 검사 데이터셋으로 이루어져 있다고 하네요.
추가적으로 학습 데이터 같은 경우에는 앞서 언급하였듯이 MS-PR 벤치마크에 포함되지 않는 600개의 이미지를 사용하여 3,600개의 질문-답변 쌍을 생성하였습니다. 얼마나 높은 수준의 추론이 가능한지 확인하기 위해 앞서 정의한 6개의 task에서 평가를 진행하였다고 합니다.
4.2. Experiment Result
4.2.1. Evaluation on MS-PR Benchmark
구축한 MS-PR 데이터에서 멀티 비전 인지/추론으로 나누어 VLM의 성능을 평가하였습니다. 먼저 멀티 비전 인지는 시각적인 인지 능력 평가를 위해 4가지 task의 평균 성능으로 평가하였고, 멀티 비전 추론은 센서 데이터를 이해하고 추론하는 능력 평가를 위해 2가지 task의 평균 성능을 확인했다고 합니다.
Tab.1에서 확인할 수 있듯이 멀티 비전 센서의 종류에 따라 성능이 크게 달라지는 것을 확인할 수 있습니다. 특히나 멀티 비전 인지에서는 평균적인 성능을 내고 있지만, context 정보 및 센서 추론에서는 센서 마다의 큰 성능 차이를 보이고 있습니다. 이러한 결과가 나타나는 이유는 역시 VLM이 센서 추론을 위해 이미지를 인지하고 설명할 수 있는 것 뿐만 아니라 센서 데이터를 기반으로 물리적인 특성도 이해해야 하기 때문 입니다. 열화상 데이터를 해석하려면 열화상이 어떤 원리로 동작하는지 알아야 하고, depth 데이터는 2차원을 넘어 공간적인 지식에 대한 이해가 필요하죠. 따라서 Tab.1은 센서 데이터를 물리적으로 해석하는데 있어 VLM의 능력이 제한적이라는 것을 의미합니다.
4.2.2. Evaluation on the Effects of DNA Optimization
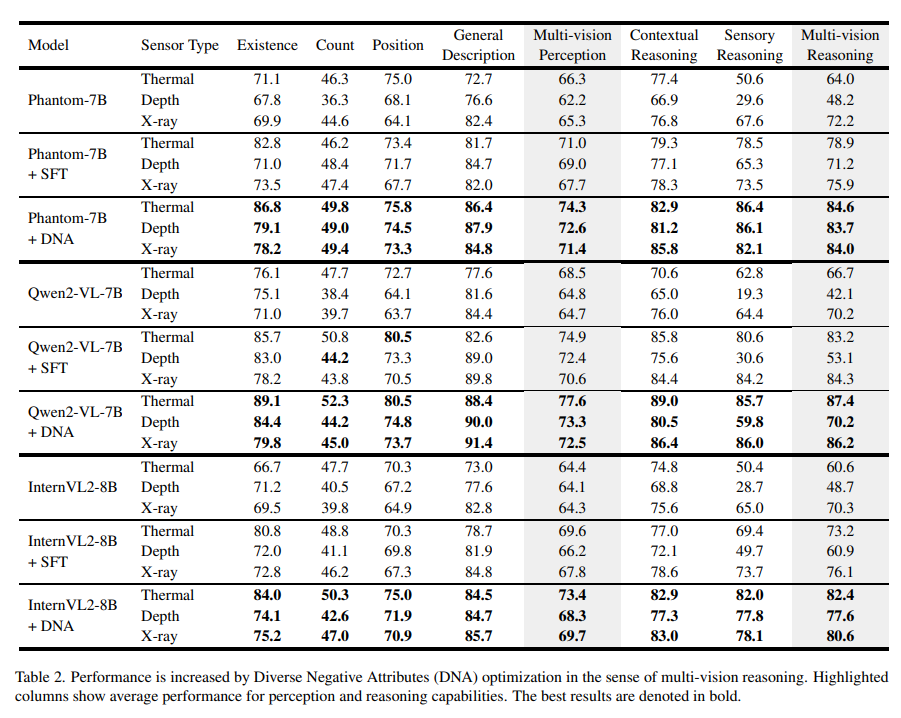
Tab.2는 negative 샘플을 사용하는 DNA 최적화가 VLM의 멀티 비전 센서 추론 성능을 향상시킨다는 것을 보여주는 실험 결과 입니다. SFT를 통해 Phantom-7B와 Qwen2-VL-7B 모델은 모든 task에서 성능이 향상되는 것을 확인할 수 있습니다. 이러한 결과를 통해 DNA가 특히나 센서별 특성과 정보에 대한 이해를 필요로 하는 작업에서 추론 능력을 향상시킨다는 것을 보여주고 있습니다.
4.3. Generalizability of DNA Optimization
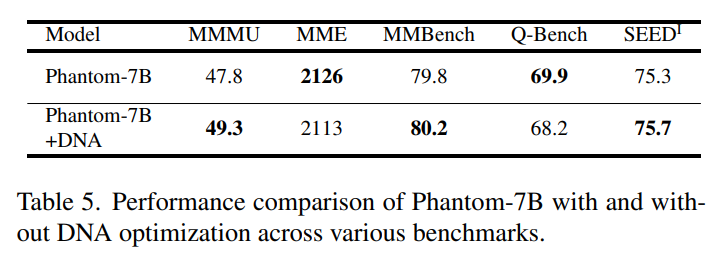
추가적으로 다른 데이터셋에 대해서도 DNA 최적화를 활용했을 때의 일반화 성능을 평가하기 위해 Tab.5와 같이 실험을 진행하였다고 합니다. 결과적으로 여러 벤치마크 데이터에서도 MS-PR 벤치마크에서와 비슷한 성능 결과를 보였는데요, 이는 VLM downstream task 추론 작업에서의 일반화 가능한 능력을 가지고 있다는 것을 알 수 있습니다. 또한 합성 데이터를 이용하는 fine-tuning 과정이 다른 벤치마크에서 VLM의 추론 성능을 저하시키지 않고 오히려 향상시키면서 일반화 가능성을 높여준다는 것을 강조하고 있습니다.
4.4. Ablation on the Number of Negative Sample
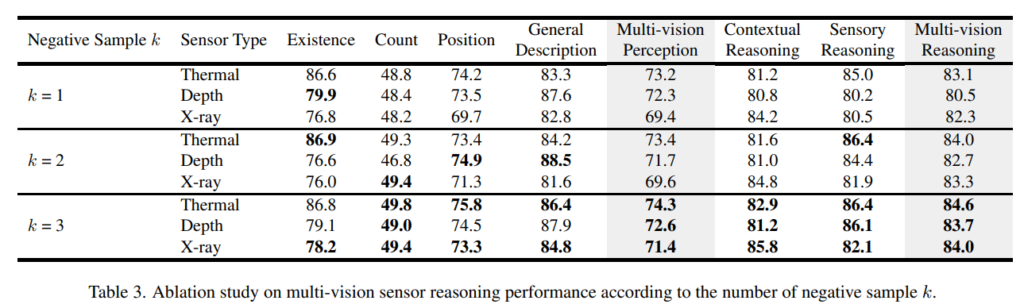
지금부터는 ablation study로, 먼저 Tab.3은 negative 샘플 수에 따른 추론 성능에 대한 실험 결과 입니다. 실험 결과, negative 샘플의 총 개수인 k가 증가하면 일반적으로 멀티비전 인지 및 추론 score가 향상되며, 그 중에서도 특히나 context 및 센서 추론 작업은 많은 negative 샘플을 사용할수록 센서별 고유한 context와 속성을 잘 구별해낸다는 것을 확인할 수 있습니다. 즉 다양한 negative 샘플을 사용하게 되면 여러 멀티 비전 센서에서 VLM이 센서에 대한 포괄적인 이해가 가능함을 알 수 있습니다.
4.5. Ablation on the Number of Training Images
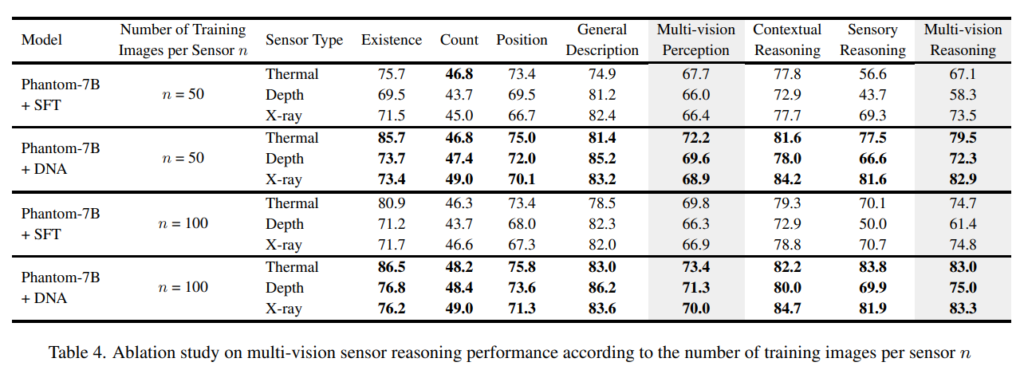
마지막으로 Tab.4는 멀티 비전 센서의 추론 성능을 학습 이미지 개수(n)으로 비교한 실험 결과 입니다. 이 실험은 센서별로 학습에 사용하는 이미지 수를 변경하여 SFT와 DNA 최적화 방식에 미치는 영향을 평가하였습니다. 결과를 보면, 학습 이미지 수가 제한된 상황에서도 DNA 최적화가 SFT 보다 나은 성능을 보이는데요, 이러한 결과를 통해 DNA 최적화가 작고 제한된 데이터에서도 더 큰 규모의 데이터셋에서 얻는 성능과 유사한 결과를 낼 수 있음을 입증하고 있습니다.
좋은 리뷰 감사합니다.
다양한 센서에 대해 VLM이 분류는 가능하지만 RGB가 아닌 도메인의 이미지에 대한 센서의 특징은 잘 고려하지 못한다는 분석이 인상적입니다.
DNA 최적화가 RGB 기반의 추론을 줄이도록 하였다고 하셨는데,
여기서 여러가지 negative 답변을 생성하는 것이 비슷한 RGB 이미지와 혼동하지 않도록 할 수 있도록 하였다는 것은 기존 VLM이 다른 센서데이터에 대해 RGB센서의 특성을 고려한 답변을 할 경우 패널티를 주는 방식이기 때문으로 이해하였는데 맞을까요?
또한, 해당 논문에서 제안한 벤치마크는 RGB는 고려하지 않은 것으로 보이는데, 그렇다면 RGB 센서의 정보는 학습 과정에 고려하지는 않는 것으로 이해해도 될까요? 그렇다면 RGB에 대한 추론 능력에 저하는 없을 지 궁금합니다.
안녕하세요, 리뷰 읽어주셔서 감사합니다.
DNA 최적화는 다양한 negative 답변을 생성해 모델이 단순히 RGB 이미지와 유사한 시각 정보에만 근거해 판단하지 않도록 유도하고, 그 과정에서 RGB 기반의 오답에는 상대적으로 패널티가 주어지도록 설계돼 있습니다.
제안된 MS-PR 벤치마크는 RGB 이미지를 포함하지 않고, 학습 과정에서도 RGB 정보를 사용하지 않고 있습니다. 그런데도 기존 VLM 벤치마크에서도 성능 저하 없이 유지되는 점은 기존 RGB 이미지 사전학습 기반의 모델에 타 모달리티를 잘 이해할 수 있도록 fine tuning하였기 때문에 RGB 추론 능력에 큰 영향을 주지 않음을 보여줍니다.
감사합니다.
좋은 리뷰 감사합니다
다양한 센서에 VLM 의 동작을 확장하는 연구라니 정말 인상깊습니다.
궁금한 점은 사실 AGI 관점에서 사람의 인식 과정 역시 새로운 도메인에 대한 정보를 인식할 때 기존 갖고있는 지식(ex. RGB 도메인 이미지에 대한 정보)에 의존하는 것 같습니다. 이러한 관점에서 새로운 학습 과정을 제시하는 것만큼 zero-shot 기반의 추론 성능 개선 연구의 중요도가 클 것 같은데, 해당 방법론과의 비교 성능이 없는 이유는 성능 차이가 크기 때문일까요?
안녕하세요, 리뷰 읽어주셔서 감사합니다.
말씀하신 것처럼 AGI 관점에서 사람이 새로운 정보를 받아들일 때 기존 지식을 기반으로 추론하는 경향이 있습니다. 이와 유사하게 VLM도 기존 RGB 도메인에서 학습된 지식을 다른 센서 도메인으로 전이해 사용하는 제로샷 추론 성능이 매우 중요합니다만 .. 이 논문에서는 그런 zero-shot 추론이 기존 방식만으로는 잘 작동하지 않는다고 이야기하고 그 보완책으로 DNA 최적화를 제안하고 있습니다.
기존 방식과의 비교가 생략된 건 성능 차이가 크기 때문이라기보다는, 이 연구의 초점이 “멀티센서 reasoning 성능을 높이기 위한 방식”에 맞춰져 있어서 실험 구성 자체가 RGB 외 도메인 환경에 집중돼 있다 보니까 직접적인 제로샷 비교 실험은 포함되지 않은 것으로 보입니다.
감사합니다.
좋은 리뷰 감사합니다.
문제 정의의 접근이 참신하네요.
MS-PR 벤치마크를 만드는 과정에 질문이 있습니다. 잘 이해를 하지 못했는데요, 한 장의 이미지에 대해 question 을 던지고, 이에 대해서 positive 답변과 negative 답변들을 얻고 이를 직접 검토해나가는 식으로 구성하는게 맞나요?
figure 4에서의 예시를 보니 question 같은 경우에도 이미지별로 개별적으로 다 생성해야 할 거 같은데,,, 하나하나 다 한거죠,? 저자들이??
감사합니다.
안녕하세요, 리뷰 읽어주셔서 감사합니다.
처음에는 GPT를 사용해서 질문 후보를 자동으로 만드는데요, 다만 이 결과를 바로 사용하는건 아니고 저자들이 하나하나 직접 검수해서 질문이 이미지와 맞는지 또는 정답과 오답이 유의미한지를 확인하고 수정한 후에 최종 데이터셋으로 만들었다고 합니다.
감사합니다.
좋은 리뷰 감사합니다. 세미나를 듣고 이어서 리뷰를 읽으니 내용이 잘 들어오네요.
질문 하나 드리겠습니다. 기존 VLM이 RGB데이터에 편향되어 이의 영향력을 줄이기 위해 loss 구성에 이를 억제하는 것이 필요하다는 것으로 이해했는데요, 그럼 negative sample 이외에 RGB의 영향력을 줄이는 loss 설계 요소가 추가적으로 있는 것인가요? 몇 개의 negative sample만으로는 RGB로 혼동했을 때의 다양한 상황을 반영하기 충분하지 않을 것으로 보여 질문 남깁니다.
감사합니다.
안녕하세요, 리뷰 읽어주셔서 감사합니다.
현재 구조에서는 별도로 RGB의 영향력을 직접 억제하는 loss는 따로 있진 않고, 다양한 센서 간 물리적 속성 차이를 반영할 수 있도록 다양한 negative를 포함시켜 RGB와의 혼동 상황을 간접적으로 커버할 수 있도록만 설계되어 있습니다.
즉, loss 자체보다는 negative 구성의 다양성으로 말씀하신 문제를 해결하고 있으며, 다양한 상황을 반영하기 충분하지 않을 것이라고 우려할 순 있지만 오답 안에 의미론/물리적/shape 기반 등 다양한 상황이 주어져 있기 때문에 충분히 커버 가능할 것이라는게 저자의 주장 입니다.
감사합니다.
안녕하세요 건화님 리뷰 감사합니다.
negative sample을 활용해 기존의 RGB만 잘 추론하고 다른 센서에 대해서는 오류가 많던 모델을 좀 더 다양하게 고려하는 형태로 finetuning한다고 이해했는데 맞는 이해일까요? 또 DNA최적화를 진행하고 나서 기존 RGB에서 잘 보던 것들을 놓치게 되지는 않는지 궁금합니다!
안녕하세요, 리뷰 읽어주셔서 감사합니다.
넵 이해하신게 맞습니다 ! 또한 걱정하신 것처럼 RGB에 대한 성능이 떨어지지 않을까 생각하실 수 있지만 기존 RGB 기반 벤치마크에서도 성능 저하 없이 성능이 유지되거나 오히려 향상된 결과를 보여주고 있어서 RGB 추론 능력까지도 잘 보존되고 있다는 것을 실험적으로 확인할 수 있습니다.
감사합니다.