안녕하세요. 이번에 소개할 논문은 CLIP과 같은 대규모 VLM에서 compositional 표현 능력을 분석하고 그 한계를 평가하는 논문입니다. 연구의 주요 목표는 CLIP이 시각적으로 다양한 객체와 속성 개념을 결합하고, 문장에서 단어나 속성 등의 의미와 그 조합 규칙으로부터 결정되는 구성적 방식으로 추론을 수행할 수 있는지 확인하는 것입니다.
구성적(compositional) 추론이란, 예를 들어 red cube를 식별하기 위해 red와 cube라는 구성 요소를 정확히 조합하거나, “cube behind sphere”와 “sphere behind cube” 같은 구조적 차이를 구별하는 능력을 말합니다.
논문에서는 CLIP이 이런 구성적 개념을 얼마나 잘 인코딩하고, 구조적으로 민감한 방식으로 변수를 결합할 수 있는지 분석하였는데 결론적으로 CLIP과 같은 모델이 compositional 추론에서 한계를 겪고 있음을 보여주며, 이러한 모델들의 시각적 표현을 개선하는 것이 향후 연구에서 중요한 과제라고 강조하고 있습니다. 그럼 바로 리뷰 시작하겠습니다.
1. Introduction
좋은 의미 표현이란 일반적으로 compositionality 와 groundedness 를 가진다는 것으로 가정됩니다. 조합성(Compositionality)은 문장의 의미가 그 문장에 들어 있는 단어들의 의미와 그 단어들이 결합되는 문법적 구조에 의해 결정된다는 뜻으로 단어 하나하나와 그 단어들이 연결된 방식이 문장의 전체적인 의미를 만듭니다. 그리고 그러한 의미는 현실 세계와 참/거짓 여부로 연결되어야 합니다(Groundedness).
현재 semantic representation의 sota 모델은 대규모 신경망을 사용하는데 이런 모델들은 두 가지 유형이 있습니다:
- 텍스트만으로 학습된 모델 (BERT, GPT).
- 텍스트와 이미지를 함께 학습한 모델 (CLIP)
이런 모델들이 좋은 “semantic representation”을 학습 하였는지에 대해서 논쟁이 계속되고 있습니다. 논쟁 주제는 크게 두 가지로, Compositionality: 모델이 단어와 구조를 조합해 문장의 의미를 잘 구성할 수 있는가? 와 Groundedness: 모델이 현실 세계와 의미 있게 연결될 수 있는가?의 논쟁입니다. 현재로서는 모델이 Compositionality와 Groundedness 를 얼마나 잘 가지는지에 대한 명확한 결론이 없고 여전히 연구가 진행되고 있는 상태입니다.
이 논문에서는 비전-언어 모델, 특히 CLIP 및 fine-tuned variants CLIP에 주목하며, 이러한 모델이 기본적인 조합성 테스트를 충족하는지 평가하고자 합니다. 저자는 특히 세 가지 기본 유형의 언어 조합을 고려합니다: 단일 형용사와 명사(red cube ) 조합, 두 개의 형용사와 해당 명사의 조합(red cube and blue sphere ), 두 명사 간의 관계(cube behind sphere ). 이 세 가지 설정은 모두 일정 정도의 조합성과 groundedness이 필요하며, 특히 두 번째와 세 번째 조합에서는 더 추상적인 형태의 조합성이 요구됩니다. 최근 연구에서는 CLIP과 같은 모델의 문장 의미 구성 능력을 측정하기 위한 데이터셋과 벤치마크를 개발하려는 관심이 커지고 있습니다. 그러나 기존 데이터셋은 해킹 가능(hackable) 하다는 문제가 있습니다. Hackable 하다는 뜻은 모델이 실제로 문제를 제대로 이해하거나 의미를 파악하지 않고도 정답을 맞출 수 있다는 뜻입니다. 예를 들어, “말이 풀을 먹는다“라는 이미지를 본 모델이 잘못된 문장인 “풀이 말을 먹는다“와 같은 문장 구조를 봤을 때, 문장 자체가 이상하기 때문에 이미지 정보 없이도 정답을 고를 수 있습니다. 이런 상황에서는 모델이 이미지의 실제 내용을 이해하지 않아도 정답을 맞출 수 있으므로, 데이터셋의 설계가 취약(hackable)하다고 평가됩니다. 반면, 저자는 최종 예측을 위해 이미지와 레이블이 모두 필요하도록 방해 요소를 포함하기 때문에 이러한 hackable 문제에 대응할 수 있다고 합니다
저자의 연구는 조합적 분산 의미론 모델(CDSMs, Compositional Distributional Semantics Models)에 기반하여 진행되고 있습니다. CDSMs는 단어의 의미를 수학적 벡터로 표현하고, 이러한 벡터를 조합해 문장의 의미를 나타내는 모델입니다. 언어는 단순히 단어들의 나열이 아니라 문법과 의미론적 조합 규칙을 따르기 때문에, CDSMs는 이러한 조합 규칙을 반영하도록 설계됩니다. 즉, 단어 벡터를 결합할 때 전통적인 언어학 이론에서 정의한 조합 원리를 따르도록 모델링하는 것이 목표입니다.
CDSMs은 본질적으로 compositional 특성을 가지고 있으며, 이를 통해 개념 결합(concept binding)을 효과적으로 모델링할 수 있습니다. 또한, CDSMs는 언어적 및 인지적 현상을 포착할 수 있고, 문장의 의미뿐만 아니라 진리값(truth value)을 모델링하거나, 다의성(polysemy)을 설명하는 데에도 적합합니다. 특히, CDSMs는 형식적 이론에 기반하고 있기 때문에 현재의 대규모 언어 모델보다 더 해석 가능성이 높은 장점을 가집니다.
이 연구에서는 여러 CDSMs를 실제 세계와 연관된 언어(grounded language) 환경으로 적용하고, 다양한 환경에서 조정된 CLIP의 텍스트 인코더 성능을 비교합니다.
저자의 Contribution을 요약하면 다음과 같습니다.
- CLIP과 그 fine-tuned된 변형들이 compositional visual reasoning 작업을 수행할 수 있는지 분석한 결과 제
- 여러 전통적인 조합적 분포론적 의미론(Compositional Distributional Semantics, CDS) 구조를 실제 세계와 연결된 언어(grounded language) 설정에 맞게 조정
- 모든 모델이 추상적 변수 결합(abstract variable binding)을 요구하는 일반화 설정에서 성능이 저조함을 보여주고, CLIP이 시각적 세계를 표현하는 방식에 주요한 한계가 있음을 보여줌
2. Models
저자는 이번 연구에서 end-to-end 방식의 모델과 명시적 구성 모델(CDSMs: Compositional Distributional Semantics Models)을 비교하고자 합니다. 이를 위해 세 가지 유형의 모델을 비교 대상으로 설정하였습니다. 첫 번째는 Baselines. 둘째, 언어와 의미를 명시적으로 조합하여 구조적 관계를 모델링하는 명시적 구성 모델(Explicitly Compositional Models), 셋째, 이미지와 텍스트 간의 관계를 학습하는 contemporary Vision-and-Language Models이 있습니다.
이 연구의 목적은 두 접근 방식의 장단점과 차이점을 분석함으로써, 각각의 모델이 언어와 의미를 이해하고 표현하는 방식의 특징을 분석하는데 있습니다.
2.1 Setup
저자는 CLIP 기반 모델과 CDSM을 사용하여 ompositional task를 수행하는 통합적인 셋팅을 제안합니다. 데이터셋 S={(x1,y1),…,(xN,yN)} 는 이미지 x와 이를 설명하는 문구 y로 이루어져 있습니다.
이미지 임베딩은 CLIP의 이미지 인코더를 사용해 생성하며, 문구 임베딩은 두 가지 방식으로 얻습니다. 첫 번째는 CLIP의 텍스트 인코더를 활용하되, 필요시 fine-tuning을 적용하는 방법이고, 두 번째는 CDSM을 통해 문구를 구성적으로 표현하는 방법입니다. 이 과정에서 다양한 CLIP 변형 모델과 CDSM을 훈련해 각 문구의 임베딩을 생성합니다.
모델은 두 가지 유형의 문구를 처리합니다. 첫째, 형용사-명사 문구로, 형용사 A와 명사 N로 구성됩니다. 모델은 형용사-명사 조합 T(a, n)의 임베딩을 생성해 joint semantic space에 표현합니다. 예를 들어, “red car” 또는 “blue sky”와 같은 문구를 처리합니다. 둘째, 주어-관계-목적어 문구로, 주어(명사) s, 관계 R, 목적어(명사) o로 구성됩니다. 이 경우 모델은 T(s, R, o) 형태의 임베딩을 생성하며, “dog chasing cat” 또는 “bird sitting on tree”와 같은 문구를 표현합니다.
2.2 CLIP and Variants
CLIP은 4억 개의 이미지-텍스트 쌍으로 사전 훈련된 모델로, 이미지와 텍스트를 공통 의미 공간에서 벡터로 표현합니다. CLIP은 이미지 인코더와 텍스트 인코더라는 두 가지 주요 구성 요소를 가지고 있으며, 텍스트 인코더는 자연어 문구를 입력으로 받아 zero-shot classification를 수행할 수 있습니다. 모델은 이미지와 텍스트 벡터 간 코사인 유사도를 계산하여 가장 높은 유사도를 가진 텍스트를 예측 결과로 선택합니다. 이를 통해 CLIP은 별도의 학습 없이도 구성적 작업에 바로 적용 가능합니다.
CLIP은 두 가지 유형의 문구를 처리합니다. 형용사-명사(adjective-noun) 조합의 경우, “a photo of adj noun” 형식으로 프롬프트를 설정하며, 예를 들어 “a photo of red car”와 같이 구성됩니다. 주어-관계-목적어(subject-relation-object) 조합의 경우, “a photo of sub rel obj” 형식으로 구성되며, “a photo of dog chasing cat”과 같은 문구를 처리합니다. 연구에서는 사전 훈련된 CLIP 모델을 사용하는 Frozen CLIP과, 특정 작업에 맞춰 추가 학습된 Fine-tuned CLIP(CLIP-FT)를 모두 평가합니다.
또한, Compositional Soft Prompting(CSP)은 CLIP의 구성적 능력을 향상시키기 위해 설계된 parameter-efficient learning technique입니다. 이 기법은 모델의 텍스트와 이미지 인코더 파라미터를 고정(frozen)한 상태에서 형용사, 명사, 관계 등의 토큰 임베딩만 fine-tuning합니다.

여기서 [adj],[noun], [sub], [rel], [obj]은 각각 미세 조정된 토큰 임베딩입니다. 이와 같은 방식으로 CSP는 사전 훈련된 CLIP 모델의 능력을 확장하면서도 파라미터를 효율적으로 학습하며, 학습이 완료되면 추론 단계에서 새로운 형용사와 객체 조합으로 구성된 문구를 처리하며, 이를 통해 제로샷(zero-shot) 추론을 수행할 수 있습니다.
2.3 Compositional Distributional Semantics Models (CDSMs)
저자는 구성적 분포 의미론 모델(CDSMs: Compositional Distributional Semantics Models)을 활용하여 문장 구성 요소의 임베딩을 결합하는 다양한 방법을 제시합니다. CDSM은 단어(명사, 형용사, 관계 등)의 임베딩을 학습하고 이를 조합해 문구의 구성적 임베딩을 생성하며, 이 과정에서 CLIP의 고정된 이미지 임베딩과 정렬되도록 학습됩니다. CDSM은 세 가지 주요 방식으로 나뉩니다.
- Syntax-Insensitive Models
첫 번째는 구문 순서에 민감하지 않은 모델(Syntax-Insensitive Models)입니다. 이 접근법에는 세 가지 간단한 방법이 포함됩니다. Add 모델은 단어 벡터를 단순히 더해 문구 임베딩을 생성하며, Mult 모델은 단어 벡터를 요소별 곱셈(pointwise multiplication)을 통해 결합합니다. 마지막으로 Conv 모델(Circular Convolution)은 circular convolution을 사용하여 단어 벡터를 결합합니다. circular convolution은 각 요소를 순환적으로 더하고 곱해 결합하는 방식으로, 벡터 내 요소가 순서를 고려하지 않고 결합됩니다.
- Type-Logical Model
두 번째는 Type-Logical Model 입니다. 이 접근법은 문법 구조를 벡터 공간으로 매핑하며, 명사는 벡터로, 형용사는 행렬로 표현됩니다. 형용사-명사 조합은 행렬-벡터 곱셈(matrix-vector multiplication)을 통해 결합됩니다.
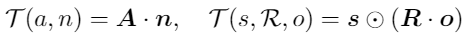
n, s, a는 학습 가능한 임베딩이고, A, R은 학습 가능한 가중치 행렬입니다.
- Role-Filler Model
세 번째는 Role-Filler Model 입니다. 이 모델은 구조적 정보를 벡터 공간에서 표현하는 방식으로, 역할(role)과 채우기(filler)라는 두 가지 구성 요소를 결합합니다.
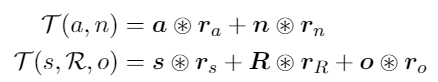
여기서 a와 n은 각각 형용사와 명사의 벡터이고, r_a와 r_n은 형용사와 명사에 대응하는 역할 벡터입니다. 이 결합은Circular Convolution을 통해 이루어집니다.
3. Concept Binding Benchmark
이 섹션에서는 VLMs의 compositional generalization 능력을 평가하기 위해 concept binding benchmark를 제안합니다. 이를 위해 세 가지 데이터셋(단일 객체, 두 개 객체, 관계적 데이터셋)을 생성하여 모델이 학습 데이터에서 본 적 없는 새로운 조합에 대해 얼마나 잘 일반화하는지를 측정합니다. 모든 데이터셋은 간단한 모양(큐브, 구, 실린더)과 색상(파란색, 회색, 노란색 등)을 가진 객체로 구성되며, 이 데이터셋은 학습과 테스트 간에 클래스 라벨이 겹치지 않도록 설계되었습니다.

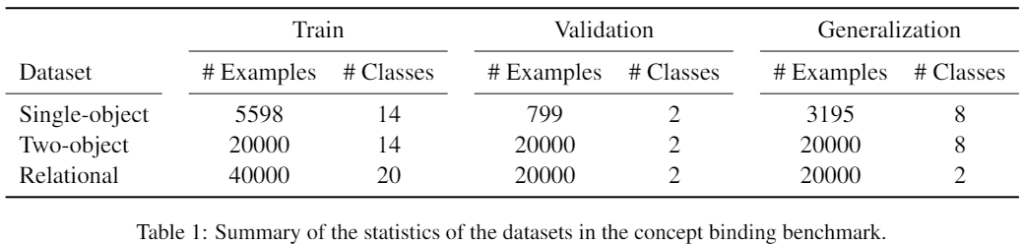
- Single-object dataset (Fig 1.a)
이 데이터셋은 단일 객체를 포함한 이미지로 구성되며, 객체는 세 가지 모양과 여덟 가지 색상의 조합으로 이루어집니다. 총 24개의 가능한 조합이 있으며 각 이미지는 형용사-명사 라벨로 표시되며, 정답 외에 네 개의 오답 후보가 제공됩니다.
- Two-object dataset (Fig 1.b)
이 데이터셋은 서로 다른 모양과 색상을 가진 두 개의 객체가 포함된 이미지로 구성됩니다. 각 객체는 형용사-명사 라벨을 가지며, 오답 후보는 정답과 비슷한 조합(예: “노란 큐브”의 경우 “파란 큐브”)과 무작위로 선택된 조합으로 구성됩니다. 이를 통해 모델이 더 복잡한 조합을 처리할 수 있는지 평가합니다.
- Relational dataset (Fig 1.c)
마지막 데이터셋은 두 개의 객체 간의 공간적 관계가 라벨로 포함됩니다. 세 가지 객체와 네 가지 관계를 사용하여 구성됩니다. 객체 a와 b가 있을 때, R이라는 관계를 통해 aRb 형태로 표현되며 오답 후보는 다음과 같이 구성됩니다:
- bRa: 주어와 목적어의 순서를 바꾼 관계.
- aSb: 관계 R의 반대 관계 S를 사용한 조합.
- aRc: a,b와는 다른 객체 타입 c를 목적어로 추가한 조합.
- cRb: a,b와는 다른 객체 타입 c를 주어로 추가한 조합.
4 Experiments and Results
CLIP의 구성적(compositional) 능력을 이해하기 위해, 섹션.2에서 소개된 CLIP과 구성적 모델들을 섹션.3에서 설명된 세 가지 데이터셋에서 테스트했습니다.
- 4.1 Single Adjective-Noun Composition
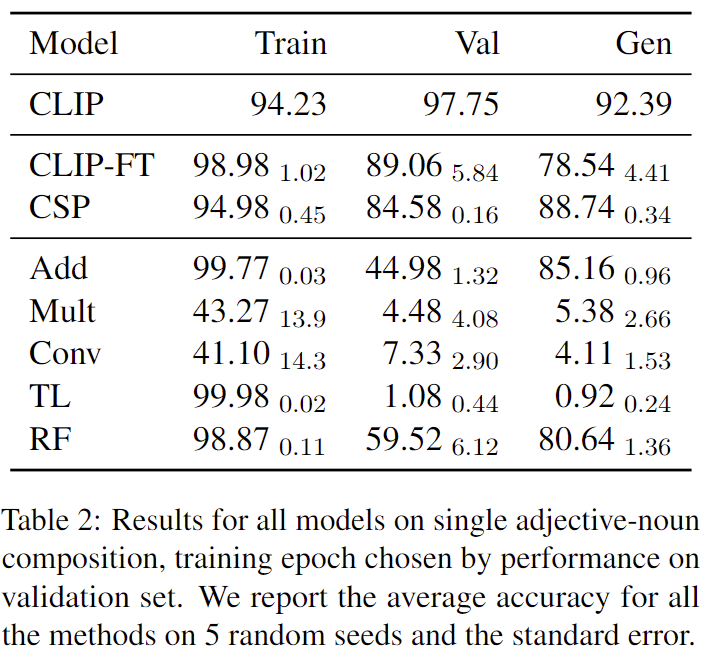
결과는 표 2에 나와있습니다. Frozen CLIP이 가장 좋은 성능을 보였으며, 검증 세트에서 97.75%, 일반화 세트에서 92.39%의 정확도를 기록했습니다. 그러나 CLIP을 fine-tuning한 경우, 성능이 검증 세트에서 89.06%, 일반화 세트에서 78.54%로 떨어졌습니다. CSP(Compositional Soft Prompting)도 유사한 경향을 보이며, 검증 세트에서는 84.58%로 성능이 감소했지만, 일반화 세트에서는 88.74%로 약간 더 나은 성능을 보였습니다. 이 성능 감소는 모델이 학습 세트에 있는 실제 조합에 overfitting 되었기 때문이라고 저자는 추측하고 있습니다.
CDSMs의 성능
CDSM 중에서는 Add와 RF(Role-Filler)가 각각 일반화 세트에서 80.64%와 85.16%의 정확도로 괜찮은 성능을 보였습니다. 그러나 Conv, Mult, TL 모델은 검증 세트와 일반화 세트에서 성능을 일반화하지 못했습니다. 이 세 모델은 몇 에포크 동안 학습 세트에서 높은 정확도(90% 이상)를 달성할 수 있었지만, 검증 세트에서의 성능이 크게 감소하는 문제를 보였다고 합니다.
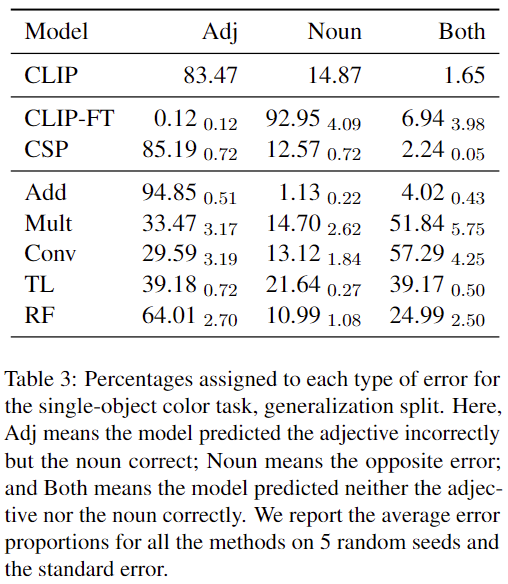
Generalization Error Percentages
Generalization 세트에서의 Error Percentages 결과는 표 3에 나와있습니다. CSP, Add, RF 모델은 유사한 유형의 오류를 보였습니다. 이들 모델은 종종 형용사를 잘못 예측했지만, 명사를 정확히 예측했습니다. 반면, CLIP-FT는 형용사(색상)를 정확히 예측했지만, 명사를 잘못 예측하는 경향을 보였습니다.
- 4.2 Two-Object Adjective-Noun Binding
이 실험에서는 CLIP이 개념을 올바르게 결합할 수 있는지 평가합니다. 두 개의 객체가 주어졌을 때, CLIP이 이미지를 단순히 개념의 집합(“bag of concepts”)으로 표현하는 것이 아니라, 형용사를 올바른 객체에 결합할 수 있는지 확인합니다. 예를 들어, Figure 1b에서 CLIP이 이미지에 “red cube”가 포함되어 있다고 정확히 예측할 수 있는지, 아니면 “yellow cube”로 잘못 예측하는지를 테스트합니다
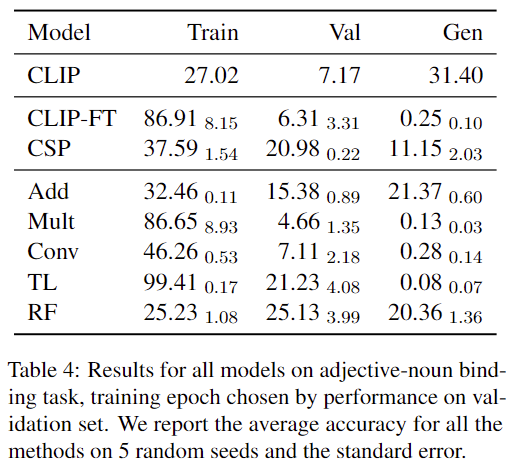
결과는 표 4에 나와있습니다. 이 테스크는 모든 모델이 어려워 특히, Frozen CLIP은 거의 랜덤 수준의 성능을 보였습니다. CLIP-FT는 학습 세트에서 overfitting되어 학습 정확도는 86.91%로 높았으나, 검증, 일반화에서는 성능이 급격히 떨어졌습니다.
CSP는 학습 세트에서 CLIP-FT보다 낮은 성능을 보였으나, 검증 세트와 일반화 세트에서는 약간 더 나은 성능을 보였습니다. 그러나 표에는 나와있지 않지만 저자는 학습이 진행됨에 따라 CSP도 학습 세트에 과적합되는 경향이 나타났다고 합니다.
Conv, Mult, TL 모델 역시 학습 세트에서 높은 정확도를 기록했으나, 검증 세트와 일반화 세트에서는 성능이 크게 저하되었습니다. 반면, Add 모델과 RF(Role-Filler) 모델은 학습 세트에서 underfitting 했으며, 검증 세트와 일반화 세트에서도 랜덤 수준의 정확도를 보였습니다.
- Generalization Error Percentages
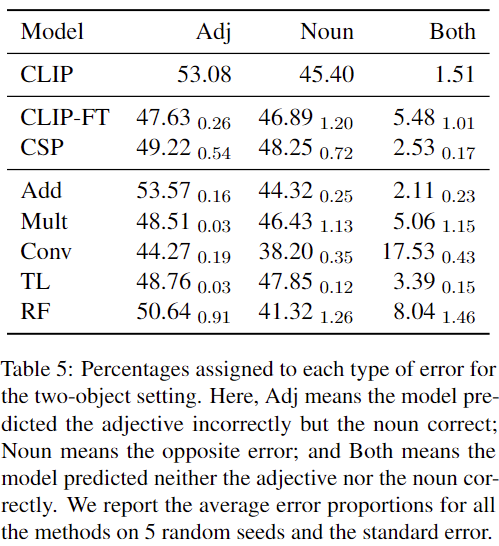
Generalization 세트에서의 Error Percentages 결과는 표 5에 나와있습니다. 대부분의 모델은 형용사와 명사에서 비슷한 비율로 오류를 나타냈으며, 형용사와 명사를 모두 잘못 예측한 경우는 거의 없습니다. 그러나 Conv 모델은 형용사와 명사를 모두 잘못 예측하는 경향을 보였습니다. 가장 성능이 좋은 모델인 Add와 RF의 경우, 명사보다는 형용사를 잘못 예측하는 경향이 있었습니다.
- 4.3 Relational Composition
이 실험에서는 객체 간의 공간적 관계(spatial relationships)를 이해하는 능력을 테스트합니다. 모델이 객체와 위치를 올바르게 결합할 수 있는지 평가하며, 두 물체 간의 순서 또는 관계를 정확히 인코딩해야 합니다.
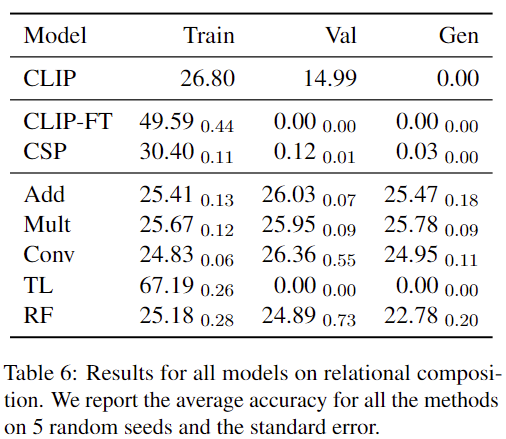
결과는 표 6에 나와있습니다. Frozen CLIP은 학습 세트에서는 랜덤 수준 성능을 보였으나, 검증 세트와 일반화 세트에서는 성능이 더 낮아져 이 테스크가 어렵다는 것을 알 수 있습니다. CLIP-FT은 학습 세트에서 약 50%의 성능을 기록했지만, 검증 및 일반화 세트에서는 일반화에 실패했습니다. CSP와 TL도 CLIP-FT와 유사한 패턴을 보이며, 검증 및 일반화 세트에서 성능이 크게 저하되었습니다.
다른 CDSM 모델들(Add, Mult, Conv)은 모두 랜덤 수준을 약간 웃도는 성능을 기록했으며, 이는 이 모델들이 교환법칙(commutative)을 따르기 때문에 관계를 구별하는 데 한계를 가진 것으로 보인다고 저자는 말하고 있습니다. 교환법칙이란 두 값을 결합할 때 순서가 바뀌어도 결과가 동일한 연산을 말합니다. 하지만 교환법칙을 따르는 모델은 두 객체의 순서를 구별할 수 없기 때문에, 관계를 제대로 학습하거나 일반화하지 못합니다. 따라서 이 모델들은 순서와 방향성 정보를 제대로 학습하지 못해, 랜덤 수준의 성능을 보이게 됩니다.
한편, Role-Filler(RF) 모델은 랜덤 수준 이상의 성능을 보이지 못했습니다. 이는 RF가 role과 filler 파라미터만 fine-tuning하여 모델의 복잡도가 낮았기 때문일 가능성이 크다고 저자는 분석하고 있습니다. 저자는 이미지 인코더까지 함께 미세 조정한다면 모델의 복잡도가 증가하여 성능 향상이 기대된다고 평가하고 있습니다.
전반적으로, Relational Composition 테스크에서 모든 모델이 어려움을 겪었으며, 특히 일반화 세트에서의 성능이 떨어졌네요.
- Generalization Error Percentages
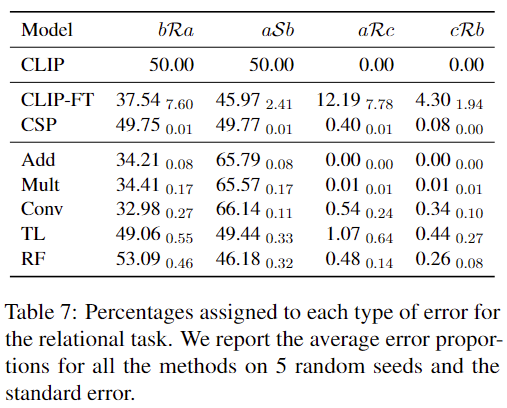
표 7에서는 각 모델의 오류 패턴을 분석하여 정리한 결과를 보여줍니다.
CLIP, CSP, TL 모델은 객체를 구별하는 데는 성공했지만, 관계를 구분하는 데에서 오류가 발생했습니다. 대부분의 오류는 학습 데이터에서 본 적 있는 조합 bRa와 aSb 형태에서 나타났습니다.
교환법칙(commutative)을 따르는 Add, Mult, Conv 모델도 유사한 오류 패턴을 보였습니다. 이들 모델은 bRa와 aSb에서 오류가 집중되었으며, 약 1:2의 비율로 분포했습니다. 이러한 결과 역시 교환법칙 모델의 한계로, 입력 순서에 따른 관계 구별이 어렵기 때문에 발생한 결과라고 저자는 설명하고 있습니다.
RF(Role-Filler) 모델은 전반적인 성능은 위 모델들과 비슷했지만, 오류 패턴은 CLIP, CSP, TL 모델과 더 유사했습니다. 이는 RF 모델이 객체를 구별하는 데는 성공했지만, 관계를 처리하는 데 약점이 있음을 보여줍니다.
한편, Fine-tuned CLIP(CLIP-FT)은 다른 모델들과는 다른 오류 패턴을 보였습니다. CLIP-FT는 관계보다는 객체 자체를 잘못 예측하는 경향이 있으며, 이러한 오류는 더 불규칙적이고 무작위적(noisier)인 특성을 보였다고 합니다.
결론적으로, 대부분의 모델은 객체를 구별하는 데는 성공했지만, 관계에 대한 혼동이 주요 오류 원인이었습니다. 특히 교환법칙을 따르는 모델들은 관계를 제대로 구별하지 못하는 구조적 한계를 드러냈으며, Fine-tuned CLIP은 객체를 처리하는 데서 추가적인 오류를 보였습니다.
5. Discussion
앞에서 CLIP이 구성적 언어 표현(compositional language representations)을 처리하는 데 한계를 가지고 있음을 보여주었습니다. 연구에서 얻은 주요 결과를 다시 정리하면 다음과 같습니다.
CLIP은 단일 객체 상황에서 형용사와 객체를 올바르게 구분하고 조합할 수 있지만, 두 객체 간의 관계나 순서를 이해해야 하는 더 추상적인 작업에서는 필요한 구조적 능력이 부족합니다. 특히, 구문에 민감한 변수 결합(syntax-sensitive variable binding)과 같은 복잡한 작업을 처리하기 어렵다는 한계를 드러냈습니다.
CLIP을 fine-tuning하거나, 구성적 모델(CDSMs)을 학습시켜도 두 객체와 관계적 데이터에서는 학습 데이터 외의 새로운 조합에 대한 일반화 능력이 부족했습니다. Fine-tuned CLIP(CLIP-FT)은 학습 데이터에서 높은 정확도를 보였지만, overfitting으로 인해 검증 및 일반화 세트에서는 성능이 크게 저하되었습니다. CSP(Compositional Soft Prompting)는 학습 정확도를 향상시키고, 때로는 검증 및 일반화 세트에서 성능 개선을 보이기도 했으나, 항상 안정적이지는 않았습니다.
CDSM 모델들 역시 한계를 보였습니다. Add, Mult, Conv 모델은 단일 객체와 두 객체 설정에서는 학습 정확도가 향상되었지만, 관계적 데이터에서는 교환법칙(commutative)을 따르기 때문에 순서를 구별하지 못해 정확도가 랜덤 수준의 정확도에 머물렀습니다. Type-Logical Model(TL)은 학습 데이터에서는 높은 정확도를 기록했지만, 검증 및 일반화 세트에서는 거의 0에 가까운 성능을 보였습니다. Role-Filler(RF) 모델은 단일 객체 데이터에서는 일반화가 가능했으나, 두 객체와 관계적 데이터에서는 랜덤 수준의 성능에 그쳤습니다.
하지만 저자의 실험은 CLIP에 초점을 맞추었기 때문에, 결과는 신중하게 해석되어야 한다고 말하고 있습니다. 다른 학습 목표를 사용해 훈련된 새로운 비주얼 인코더는 동일한 텍스트 인코더를 사용하더라도 더 나은 결과를 낼 가능성이 있습니다. 전반적으로, 위의 결과는 VLM에서 구성적 능력을 개선하기 위해 결합(binding)을 고려한 사전 학습 방법의 필요성을 강조하고 있습니다.
저자는 compositional zero-shot learning에 사용되는 벤치마크 데이터셋에도 주목합니다. 기존의 대표적인 벤치마크 데이터셋(MIT-States, UT-Zappos, C-GQA 등)은 주로 단일 객체 설정에 초점이 맞춰져 있어 형용사와 명사를 결합하는 능력을 테스트하지 못하며, 순서를 인식하거나 추상적 구문을 처리하는 능력을(abstract, order-aware syntax) 요구하지 않습니다. ARO와 같은 새로운 데이터셋은 CLIP을 더 어려운 hard negative images,captions 으로 fine-tuning하여 관계적 데이터에서의 성능을 개선할 수 있음을 보여주었으나, 여전히 시각적 정보를 충분히 활용하지 못하는 한계를 드러냈습니다.
저자의 실험 셋팅 또한 hard negative captions을 포함한다는 점에서 유사하지만 fine-tuning 후에도 성능 개선은 보이지 않았습니다. 최근 연구에 따르면, ARO 벤치마크에는 비주얼 인코더를 사용하지 않고도 해결할 수 있는 테스트 예제가 포함되어 있으며, 이는 실제로 비주얼 인코더가 문제를 해결하는 데 기여했는지 판단하기 어려운 경우가 발생합니다. 따라서 모델의 진정한 구성적 능력을 평가하기 위해 개선된 데이터셋 설계가 필요함을 보여줍니다.
6. Conclusion
저자는 CLIP과 그 변형 모델, 그리고 CDSM이 구성적 시각 추론(compositional visual reasoning) 테스크를 수행할 수 있는 능력을 조사했습니다. 실험 결과, CLIP은 단일 형용사-명사(adjective-noun) 조합에서는 좋은 성능을 보였지만, 변수 간의 관계를 정확히 결합해야 하는 복잡한 테스크에서는 어려움을 겪었습니다.일부 CDSM 모델은 단일 형용사-명사 조합에서는 좋은 성과를 보였지만, 두 객체와 관계적 테스크에서는 성능이 랜덤 수준에 가까웠습니다.
이 연구는 CLIP의 한계를 드러내는 동시에, VLMs의 사전 학습 과정에서 결합(binding)과 순서(order)를 고려해야 더 나은 구성적 일반화(compositional generalization)를 달성할 수 있음을 보여줍니다.
안녕하세요, 좋은 리뷰 감사합니다!
task가 낯설어인지 기본적인 개념에 대해서 궁금한 점이 생기는 것 같습니다.
우선 여러 CDSMs를 실제 세계와 연관된 언어 환경으로 적용하였다고 했는데, 그럼 원래 CDSMs가 텍스트를 어느 수준으로 다루고 있었던건가요 .. ? 어떤 기준으로 실제 세계의 언어 수준인지 아닌지를 나누어 다룬 것인지 모호하다는 생각이 듭니다.
그리고 인트로에서 3개의 언어 조합을 고려하는데, 그 중 두번째가 두 개의 형용사와 명사의 조합이라고 설명해주셨습니다. 그럼 CLIP과 CDSMs는 이 두 번째 조합에 대해서는 어떻게 처리하게 되나요 ?? 단순 A와N으로 이루어진 구성에 and라는 텍스트를 추가로 고려한 것이라고 이해하면 될까요 ?
마지막으로 CLIP에서 형용사-명사 조합의 경우 기존 프롬프트인 “a photo of adj noun” 형식을 사용하는데, 이 CLIP이라는게 a를 쓰고 안 쓰고에서도 성능 차이가 꽤나 발생하는 것으로 알고 있습니다. 형용사를 구성할 때 관사를 활용하는 것에 대해서 본 논문에서 고려하고 있지는 않나요 ?
감사합니다.
안녕하세요 건화님 좋은 질문 감사합니다.
1. CDSMs를 실제 세계와 연관된 언어 환경으로 적용했다는 의미는, CDSMs가 본래 텍스트 데이터만으로 학습했다고 하면, 실제 세계와 연관된 언어 환경이란 텍스트뿐만 아니라 이미지, 영상 등의 실제 경험적 정보를 함께 학습한다고 이해하시면 될 것 같습니다.
2. 두 번째 조합에서는 이미지에 두 개의 물체가 존재하지만, CLIP 모델에는 이미지와 함께 “a photo of adj noun” 형식의 텍스트가 입력됩니다. Fig1(b)에서 {yellow sphere, yellow cube, … }의 예시가 있는 것을 확인할 수 있는데 여기서 모델에게 이미지와 “a photo of yellow sphere”가 입력되고, 또다시 같은 이미지와 “a photo of yellow cube”가 입력되어 모델이 이 항목중에 옳바른 객체를 검출한다고 이해하시면 될 것 같습니다.
3. 저자가 제안한 데이터셋은 한 이미지에서 라벨이 겹치지 않도록 구성되어 있습니다. 즉 이미지에서 동일한 객체가 한 개 이상 존재할 수 없기에 관사를 활용하는 것은 고려하지 않은 것 같습니다.
감사합니다.
안녕하세요 좋은 리뷰 감사합니다.
1. 가장 먼저 헷갈리는 것이, CDSM은 저자가 제안한게 아니고 이미 있는 개념을 CLIP 모델과 비교하기 위해 적용한 것이 맞나요?
2. 만약 CDSM이 원래 있던 모델이라면, 근본적으로 CDSM과 CLIP을 단순 비교만하는 것이 어떠한 학술적 의미를 갖는지 궁금합니다. 자연어처리 분야에서는 CDSM이 CLIP만큼 활발히 사용되는 모델인 것인가요? 리뷰의 conclusion에 작성해주신대로 CLIP과 CDSM의 성능이 서로 어떨땐 좋고 어떨땐 나쁜데, 결론적으로 저자가 이야기하는 바가 무엇인지, 그리고 의철님께서 이 논문으로부터 결국 얻어가는 정보가 무엇인지 궁금합니다.
안녕하세요 현우님 좋은 질문 감사합니다.
1. 네 맞습니다. CDSM은 NLP분야에서 활용되던 개념입니다.
2. 자연어 처리에서 CDSM이 얼마나 활용되고 있는지는 명확하지 않지만, VLM의 Compositionality를 연구한 논문에서는, CLIP처럼 단순히 이미지와 텍스트를 연결하여 의미를 학습하는 방식만으로는 한계가 있다고 분석하고 있습니다. 보다 정교한 의미 처리를 위해서는 텍스트의 구성적 의미까지 학습하는 것이 필요하며, 이를 위해 CDSM의 개념을 활용하면 향후 VLM 개선을 위한 방향성을 제시할 수 있을 듯합니다.
감사합니다.
안녕하세요 의철님 좋은 리뷰 감사합니다.
최근 compositionality에 관심이 있는 와중에 다뤄주셔서 재밌게 읽었습니다. 사실 나이브하게 생각을 했을 때에는 “말이 풀을 먹는다”를 양성으로, “풀이 말을 먹는다”를 음성으로 설정하게 된다면 모델이 이러한 compositionality를 학습할 수 있지 않을까하는 생각이 드는데 혹이 이런 방식의 연구가 있었나요? 아니면 제가 놓친 문제점이 있는지 궁금합니다. 추가로 CDSM이 CLIP의 단점인 compositionality에 강점을 가지는데 CDSM이 활용되는 연구는 어떤 연구가 있는지 궁금합니다.
감사합니다.