안녕하세요. 2025년 새해가 밝았습니다. 시작말로, 금년도부터는 논문을 읽는 시각이 조금 바뀌었습니다. 논문을 작성중이다보니 저자가 본인의 방법론을 어떠한 방식으로 표현하였는지, 그 방법을 실험으로 어떻게 설득시키고자 하였는지에 대해 이목이 집중됩니다. 현재 실험 단계에 있지만, 본 논문의 방법론을 구상하며 “이 방법론을 어떻게 설명하였을 때 이해력과 설득력을 갖출 수 있을 것인지”에 대한 고민을 꾸준히 하고 있습니다. 동일한 방법론이더라도 어떤 글로 표현하였는지에 따라 누군가에게는 허상처럼, 또 누군가에게는 설득되는 글로 읽힐 수 있기 때문입니다. 본 논문은 제목에서 눈치채셨듯, OVD에 관한 논문입니다. 작성 중인 논문에서 OVD로의 확장 실험을 계획하고 있는데, 물론 OVD 논문을 꽤나 읽어보았지만 해당 태스크는 그 특성 상 Pre-training 과정이 포함되며 따라서 일반적으로 OVD 세팅을 실험하기에는 코스트가 큽니다. 하지만 동시에 두 개의 데이터셋 정도로 Pre-training과 Evaluation을 수행하는 방식도 존재하는데, 이러한 실험 세팅을 보이는 논문들을 찾아 다니는 중입니다. 본 논문이 그런 논문일지는 아래의 Experiments에서 확인해보며, 동시에 본 논문을 읽은 이유는 저의 실험 세팅에서도 “왜 OVD를 Pseudo-Label로 학습하면 안돼?”라는 의문이 들었기에, 그런 의문점을 해결한 논문이지 않을까하는 생각이였습니다.
Introduction
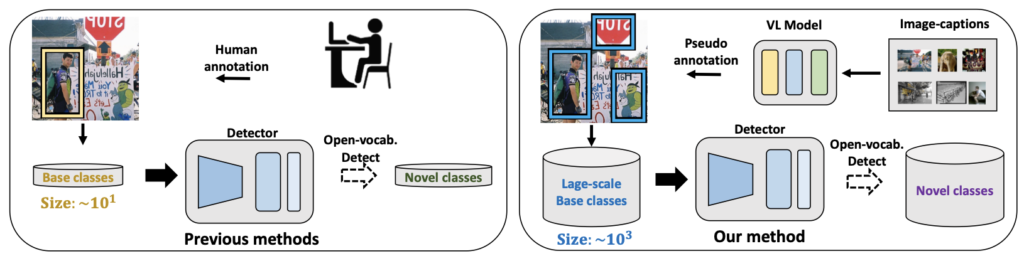
Object detection은 누군가에겐 “예전의 Task, 지금은 이미 포화된 구식의 것”으로 읽혀질 수 있지만, 어느 새로운 Task에서도 근간이 되는 Recognition의 대표 분야입니다. 일례로 3D, 6D, 이외 Referring Expression, Visual Grounding, 심지어는 Foundation Model에서도 Object detection은 근간이 됩니다. 포즈를 추정하는 Pose Estimation에서도 객체를 우선 인지함이 시발점이기 때문입니다. 하지만 Object detection은 처음에 말씀드린 바와 같이 누군가에게는 “예전의 Task”로 읽혀질 수도 있기에 연구자들은 점차 새로운 문제 제기, 확장성을 찾아 나섭니다. 그 대표적인 근 2년 간의 트렌드 중 하나가 OVD(Open Vocabulary Detection)입니다. OVD는 Base/Novel의 구분으로 “특정 객체를 학습 중에 본 적이 있는지”에 따라 “학습하지 않은 새로운 객체도 탐지인식해낼 수 있음”에 집중합니다. 물론, 그 탐지인식에 있어 학습하지 않은 객체를 정의해야하는지/하지 않아도 되는지에 대해서는 OVD는 전자의 역할만을 수행할 수 있습니다 (탐지할 객체를 정의하지도 않았는데 탐지함은 불가능합니다. 그러한 문제를 해결하고자 새로운 의문, “세상 모든 객체를 스스로 알아서 탐지해낼 수 없을까?”에서 시작하는 UOD(Universal Object Detection)도 존재하지만, 그들 또한 Text를 쓴다는 점에서 어찌보면 단순히 탐지 대상이 늘어난 것에 다르지 않았냐하는 의문도 있습니다).
사실 OVD가 등장하게 된 정말 근본적인 이유는 annotation이 힘들기 때문입니다. 매일 사람들이 촬영하는 영상, 웹 상의 영상, 그외의 모든 데이터는 사실 무한하다고 판단되며, 그 데이터들이 어떠한 힘듦없이 자동으로 사람이 한 수준으로 annotation될 수 있다면 사실, OVD는 등장하지 않았을 것입니다. OVD에서도 중요한, 그러면서도 Foundation model에서도 필수적으로 요구되는 Zero-shot 방식은 사실 학습 도중에 만나는 객체의 카테고리(Base)는 한정적입니다. 현재까지 좋은 annotation이라고 불리는 데이터셋들의 카테고리를 모두 모아도, 아마 10000개가 채 안될 것입니다. 현실 상의 카테고리를 모두 따지면 얼만큼 될지는 모르겠지만, 그 10000개가 뭐 예를 들어 각 카테고리 당 적어도 100개의 annotation을 가지는 것들을 모아보면, 한 100-1000개 수준일텝니다. 그럼 학습에서 만날 수 있는 카테고리가 충분히 적다는 얘기이며, 이로 인해 다양한 카테고리에 대한 추론은 물론 OVD, Foundation model에서는 주로 Text 덕분에 어느정도 해내고는 있지만 그 성능을 높이기 위해선 분주한 노력들이 존재합니다.
저자는 아주 단순한 방식을 활용합니다. 사실 이러한 “특별할 것 없는”, “OVD 관련한 논문을 읽는다면 누군가 한 번 쯤 생각해보았을 법 한” 방식이 ECCV의 수준 높은 학회에 통과되었음이 신기할 따름입니다. 본 논문이 가지는 질문, “현존하는 자원(데이터)에서 자동으로 Bounding-box annotation을 생성하는 방법이 있을까?”, “이들로 Detector에 학습시키면 더 좋은 성능을 얻을 수 있지 않을까?”에 대해, 우선 후자의 질문에 대한 저의 입장은 다음과 같습니다. “물론, 그렇게 생성된 Bounding-box annotation이 충분히 좋을지는 모르겠습니다. 흔히 말하는 Noise가 존재할 수 있겠죠. 하지만, 앞선 질문의 전제인 현존하는 데이터 즉 다량의 데이터를 학습시킨다면 현재까지의 Data-driven 모델들에서는 좋은 성능으로 이어짐은 당연하지 않을까요?”. 제가 이런 의문을 던지는 점은, 저자가 제안하는 방식은 기존의 VLM(Vision-Language Model)에서 추론하는 Bounding-box annotation을 Pseudo-label로 정의하여 그대로 학습에 활용하기 때문입니다. 저자가 말하는 “자동으로 Bounding-box annotation을 생성하는 방식”이 본 논문의 핵심이지만, 결국 활용하는 모델 자체는 기존의 VLM입니다. 즉, Data-driven 특성의 모델 뒤에 숨어 정말 어찌보면 당연하지만, 남들이 하지 않았기에 그 의의를 인정받았지는 않았을까 싶으면서도, 본 글의 처음에 말한 바와 같이 과연 이들을 어떻게 실험적으로 나에게 설득력이 있을까에 대해 궁금합니다.
Our Approach
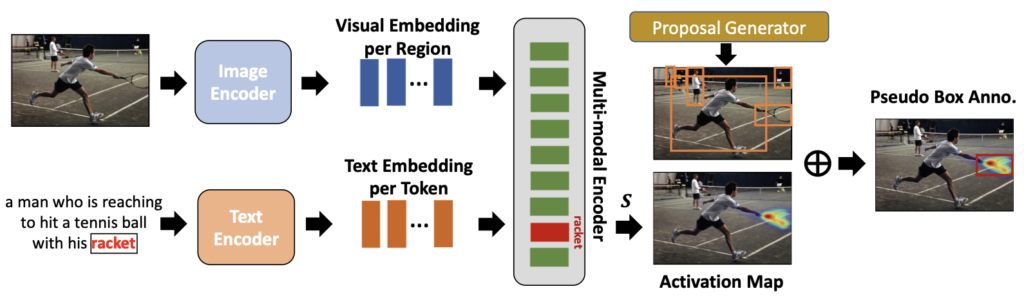
위의 Figure는 Pseudo-label을 생성하는 과정을 설명합니다. 앞서 말한 바와 같이 양/질의 데이터는 인공지능에서 필수적입니다 (오죽하면 Chat-GPT를 위해 OpenAI는 데이터를 마치 구독 시스템처럼 꾸준히 돈 들여 사고 있습니다). 우선, 양적으로는 웹 수준의 영상-캡션 데이터만한 것이 없습니다. 위 Figure의 좌측에 보이는 테니스를 치는 그림과 그에 대한 설명(캡션)이 존재하는 데이터는 Bounding-box annotation의 데이터에 비교하기가 어려울 정도로 그 수가 많습니다 (생각해보면 요즘에는 영상만 있어도 LLM이 해당 영상에 대한 캡션 정도는 훌륭하게 생성해낼 수 있으며, 그럼 데이터는 영상만 필요하니 이젠 정말 그 수가 가늠하기가 어려울 정도겠네요. 물론, 그런 작업을 우리 연구실에서 수행할 수는 어렵겠지만서도).
이미지 I 와 그에 대응되는 캡션, X = \{x_1, x_2, ..., x_{N_T} \} ( N_T 는 캡션 내 단어의 수)가 모델에 입력되면, Image Encoder는 Image Features V 를, Text Encoder는 Text Representation T 를 생성해냅니다. 참고로, 이 과정과 다음의 Multi-modal Encoder의 설명부까지는 아시겠지만 저자가 새롭게 설계하지 않은 이전의 VLM 방식을 그저 소개하고 있습니다. 이후 Multi-modal Encoder는 L개의 연속되는 Cross-attention Layer로 구성되어 있으며, 이들은 당연히도 V 와 T 간 연산을 수행하여 캡션과 대응되는 영역(위 Figure의 Visual Embedding per Region에 해당)에 대해 학습됩니다 (물론 이러한 방식으로 이미 학습한 VLM모델을 일컫습니다). 그럼 최종적으로 위의 예시에서 “racket”에 대응되는 Multi-modal Encoder에서의 Visual Embedding을 획득할 수 있으며, Grad-CAM의 방식으로 Activation Map을 생성해낼 수 있습니다 (왜 이 과정에서 Activation Map으로 접근하였는지는 지금은 의문입니다). 여러 번의 Cross-attention Layer에서 생성해낸 “racket”에 대응되는 Activation Map을 평균한 이후, Mask R-CNN 방식으로 이들에 대한 Proposal Generator를 통과하면 곧 “Pseudo Box Anno.”를 획득할 수 있습니다. 물론 수식으로 Cross-attention Layer에서의 attention score에 대한 계산, 그리고 몇 차례의 Cross-attention Layer에서 추출하는 Activation Map에서 평균내어 최종 Map을 정하는 과정이 논문 상에는 표현되어 있지만, 이들은 특별할 것이 없으니 (위에 한 문장으로 설명한 것 외의 것이 없으니) 넘기도록 하겠습니다. 저자는 위 Figure과 같이 이러한 방식으로, Activation Map을 통해 생성한 Pseudo-Label이 좋은 품질을 가진다고 하며 (논문을 읽으며 이러한 문장을 보면, 이들이 좋은 품질을 가지는지에 대한 증명이 실험으로 표현되어 있겠지?라는 의문을 가져야 합니다), 그러므로 이들로 학습시키면 기존 방식들의 성능을 높일 수 있음을 주장합니다.
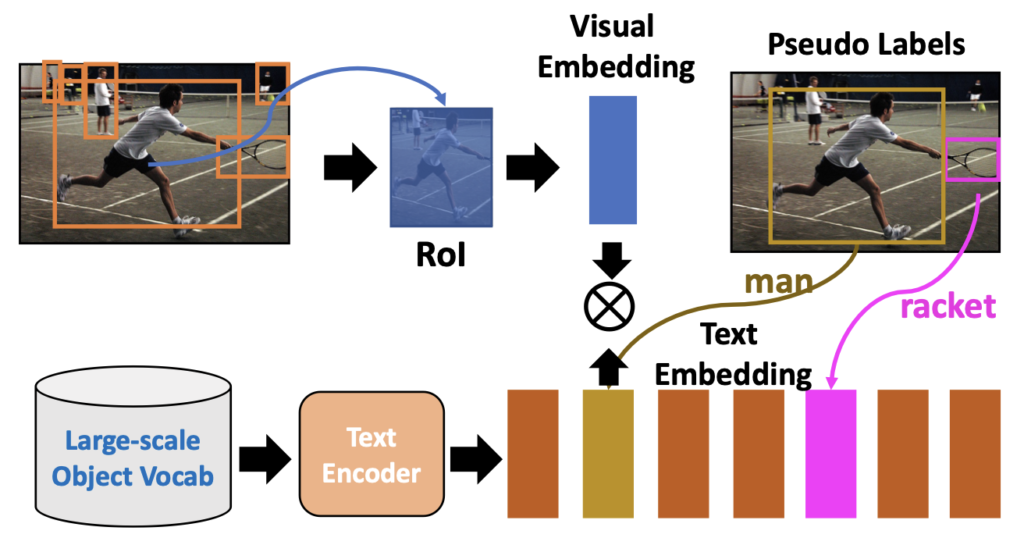
이제는 위의 방식으로 획득한 Pseudo-label로 OVD를 학습하는 과정을 설명합니다. 그래도 본 논문의 방법이 유용한 점은, 학습 과정에서 생성해낼 필요가 없기에 모든 프레임워크에서 활용될 수 있습니다 (그냥 일종의 새로운 데이터라고만 보면 됩니다). 일반적인 OVD는 위의 Figure로 설명하는데, 오히려 이 그림이 OVD를 처음 보는 분에게는 더 어려울 수 있곘네요. 사실 그렇습니다. 실제로 본 논문을 읽어보면, 이들에 대한 설명이 1.5P 분량 (물론 ECCV기에 One-column입니다)인데, 그 설명이 일반적인 OVD 모델의 학습 방식에 대한 설명이므로 OVD를 아는 사람 입장에서는 이들의 내용은 Related Work의 OVD 설명으로도 충분히 끝낼 수 있습니다. 명심할 것은, 본 논문의 핵심 방법은 새로운 카테고리를 포함할 수 있는 데이터를 Pseudo-Label로 생성해내는 방법일 뿐, OVD에 대한 고려는 아닙니다. 그래도 몇 문장으로 짚고 넘어가자면, 결국 추출한 RoI에 대해 Text Encoder를 통과한 Representation( T )와 cosine-similarity를 계산하여 학습합니다. 유사한 Text Embedding과는 가까이, 유사하지 않은 Text Embedding과는 멀리하는 Contrastive Learning 방식입니다. 보통 이때의 Localization(Regression) Loss는 Class-agnostic하게 이루어집니다 (그래서 실제로, OVD 방법들을 실제 데모를 해보면, Person, Car과 같이 이미 충분히 많은 annotation으로 supervision 학습할 수 있는 카테고리와 그렇지 않은 카테고리들의 시각화 결과, Bounding-box의 품질 수준 자체는 개인적인 견해로는 차이가 있습니다).
Experiments
위 리뷰에서 제가 몇 차례 의문을 내세웠습니다. 그 의문들은 주로 “이들은 어떻게 해당 문장을 실험으로 설득시키려 할까?”, “그리 특별하지 않은 방법론으로 보이나, 이들에 대한 실험은 어떻게 다양히 이루어졌을까?” 또는 읽다보면 드는 “이런 실험들은 당연히 했겠지?”와 같은 의문입니다. 방법론만 따지고 본다면 만약 제가 심사위원이었다면 Weakly Reject이였습니다. 과연, 실험에서 설득되었을 지 함께 알아보겠습니다.
우선 Training Dataset에서의 핵심은 Pseudo-Label을 생성한다는 점인데, 이들에 있어 COCO Caption, Visual-Genome, SBU Caption 데이터셋을 활용하였습니다. COCO Caption과 Visual-Genome은 Referring Expression, Visual Grounding에서 익히 들어본 이미지-캡션 데이터셋입니다. 따지고 본다면 Object detection 자체에서는 활용하기가 어렵습니다. 하지만 Object Vocabulary로는 COCO, Pascal VOC, Objects365, LVIS를 통합한 1,582개의 카테고리를 Pseudo-label을 생성하는데 활용하였습니다. 물론, 이들에 대해 어느정도 아시는 분이라면 아실 법 한데 LVIS 자체가 1500개 정도의 카테고리로, “본 방법이 더 많은 카테고리를 학습 중에 포함하였는가”로 따진다면 그렇지 않습니다. 다만, LVIS가 Long-tailed 분포임을 고려하면 그 양이 많지 않은 카테고리들에 대해선 더 많은 Annotation을 가질 순 있었겠네요. Baseline Detector로는 “Open-Vocabulary Object Detection Using Captions”를 택했습니다. 제가 볼 땐, 본 논문의 방법론은 실험면에서 다양한 Detector에 적용되어야 하는데 정말 어찌보면 다행이게도? 2022년 ECCV니 즉 2021년까지는 OVD가 이제서야 걸음마를 뗀, 손에 꼽을 논문 정도만 존재하였습니다. 따라서 지금에서는 Baseline Detector로 하나 정도를 선택해서 성능 향상을 보인다? 본 논문의 방법론을 고려했을 때는 Strong Reject입니다 (이러한건 모두 개인적 의견입니다, 우리끼리의 공간이니 편히 이야기합니다).
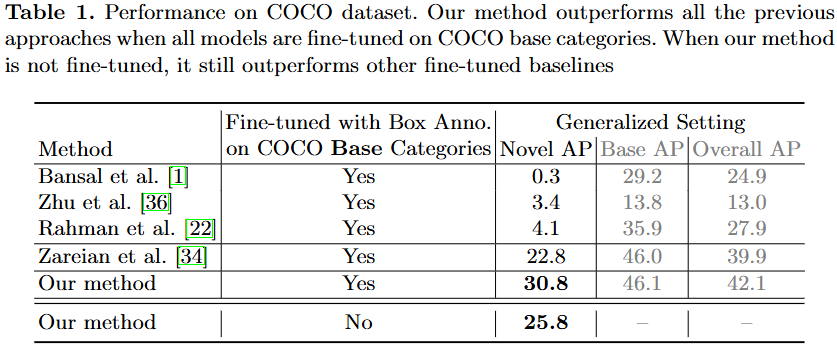
일반적인 OVD 실험 세팅 중 하나는 COCO dataset을 기반으로, 총 80개의 클래스 중 48개의 클래스를 Base/Seen으로 학습한 이후, 평가 시에는 17개의 클래스를 Novel/Unseen으로 두어 Base와 Novel에 대한 평가를 진행합니다. 저자의 방식은 COCO Base에 대해서 GT로 학습하지 않은 채, 저자의 Pseudo-Label로 학습했을 때의 성능을 보입니다. 이에 대한 성능은 아래 Table 1에 나오는 바와 같이, Our method를 Base클래스에 대해 GT로 학습하는 방식 (Our method-Yes)이 아닌 저자의 Pseudo-Label 방식으로 학습하는 경우 (Our method-No)에도, 이전보다 좋은 성능을 보이며 GT로 학습하는 방식에도 견줄만하다고 설명합니다.

동시에 해당 방식으로 (Our method – Yes/No) COCO에서 학습한 모델을 Pascal VOC, Objects365, LVIS 데이터셋에서 평가한 결과, 이전의 방법론(Zareian)에 비해 우수한 성능을 보이며 이는 곧 본 논문의 방식으로 생성된 Pseudo-Label의 품질이 괜찮은 결과를 나타냄을 보여줍니다 (하지만, 개인적으로 이러한 Detection 성능 측면에서의 접근 방식은 꽤나 아쉽습니다. 물론 해당 표는 벤치마킹에 집중하지만, 그럼에도 GT가 존재하는 하나의 데이터셋을 기준 삼아 본 방식으로 생성된 Pseudo-Label이 적어도 GT클래스와 비교했을 때 (물론 GT외에도 더 많은 클래스에 대한 Pseudo-Label을 생성한다는 점에서는 논외지만), 그 품질을 측정함이 어땠을까 하는 아쉬움이 있습니다.
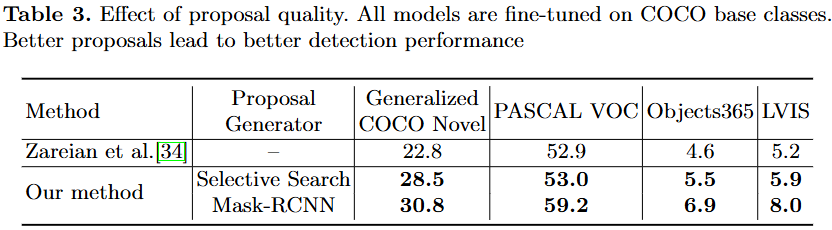
Ablation Studyㄹ로는 “How does the quality of bounding-box proposals affect performance?”, 즉 본 방법에서 Activation Map으로부터 생성되는 Proposal Generator를 어떤 방식을 활용하는지에 대한 성능도 리포팅하고 있으니, 저자도 글 상으로 더 좋은 proposal일수록 더 좋은 퀄리티의 pseudo bounding-box annotation을 생성해낸다고 표현하듯, 어찌보면 당연합니다. 그렇기에 이런 Ablation은 추가적인 하나의 실험으로 그렇게 설득력이 와닿지는 않네요.
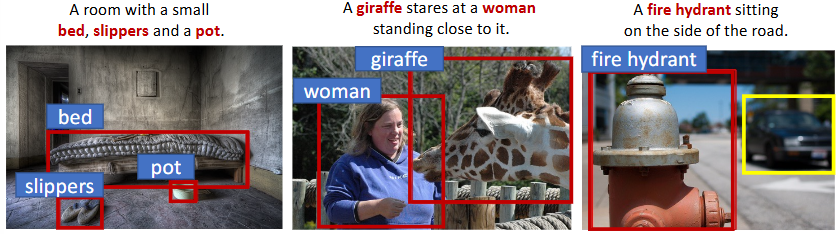
오히려 이러한 정성적 결과가, 저자의 방법론이 이미지-캡션 데이터셋에서 얼마나 좋은 Pseudo-Label을 생성하는지에 대한 결과를 보여줍니다. 저자가 말하는 하나의 한계점으로는 오른쪽의 노란색 Bounding-box, Car 클래스와 같이 “캡션에 존재하지 않는다면, Bounding-box annotation으로 삼을 수 없음”이 되겠지만, 그럼에도 우선 Localization 측면에서는 굉장히 우수한 측면을 보입니다. (이 때의 궁금증은 과연 Road와 같이 다수의 객체가 Occlusion, Truncated가 존재하는 상황에서, 또는 하나의 클래스가 여러 개가 존재하는 상황에서도 그들을 모두 Pseudo-label로 채택할 수 있을지에 대해서는 의문입니다).
개인적으로, 이제는 3년전이지만 약 2년전의 2022년 ECCV 논문임에도, OVD가 나온지 얼마되지 않아서인지 벌써 위의 실험들은 요즘의 OVD를 고려할 때 구식의 실험들로 느껴집니다. 개인적으로 해당 논문의 방법론이 “Pseudo-label에서 캡션만으로 새로운 객체에 대한 Bounding-box annotation을 생성해낼 수 있음”은 인상 깊지만, 그 외의 방법론은 어찌보면 너무 아쉽습니다.
안녕하세요 이상인 연구원님 좋은 리뷰 감사합니다.
VLM으로 만든 label을 pseudo-label로 사용하는 연구를 리뷰해주신 것 같습니다.
이상인 연구원님이 리뷰에 작성해주신 것처럼, 저도 궁금했던게 Occlusion이나 Truncated 상황에서도 강인하게 동작하는지가 궁금했는데.. 그 실험은 빠져있나 보군요 결국 이 부분에서 어느정도 효과가 있어야 VLM을 pseudo-label로 활용하는 것이 효과가 있다고 볼 수 있을 것 같은데 말이죠..
한 가지 궁금한 점은, activation map 기반으로 mask r-cnn 기반 proposal generator에 입력해서 psuedo-box 생성 시, 박스가 object에 타이트하게 생성되지 않을 것 같다는 생각이 드는데 이 부분과 관련한 저자의 고찰 및 실험이 있을까요?
리뷰 감사합니다.
pseudo label 을 사용하여ㅑ ovd 를 학습하는 뭐 직관적이면서도 생각할 법 한 방법론인데 이를 activation map 을 통해 pseudo label 을 만든 것이군요. 근데 이 부분 말고는 딱히 contribution 이 없는것처럼 보이는데 제가 이해한 바가 맞는걸까요?
그리고, 음.. ovd 자체의 이름에서 의미하는 바가 결국 open한 vocab 에 대한 예측, 학습때 보지 못한 unseen class에 대한 예측을 수행하는 것인데 pseudo label 시 텍스트 쪽으로 입력되는 단어가 캡션 속 단어인 것으로 보여집니다. 그럼 캡션에 없는 단어들에 대해선 pseudo box 가 생기지 않는것이지 않나요? 그럼 음.. open vocab 가 맞을지가 좀 의문이 들긴 합니다.
감사합니다.