이번 리뷰 논문은 LERF 저자들의 후속 논문들로 특징으로만 구분하는 경우, 모호한 영역 구분으로 인해 쿼리에 해당하는 영역과 명확한 구분이 어렵다는 문제점이 있습니다. 저자는 이를 해결하기 위해서 유사한 특징들을 미리 그룹하여 사용하는 방법을 제시합니다. 이러한 경우, 더욱 빠른 추론 속도를 얻을 수 있으며, 명확한 구분을 통해 에디팅과 같은 다른 어플리케이션에 활용이 용이해집니다.

서론

최근 Neural Radiance Fields (NeRFs)의 발전은 포즈가 지정된 이미지로부터 사실적인 3D 재구성을 가능하게 하며 주목할 만한 성과를 보여주고 있습니다. 그러나 이러한 기법들은 장면을 단일한 볼륨적 특성만 모델링 할 뿐, 구조적 또는 의미적 정보를 표현에 내포하지 않는다는 한계를 가지고 있습니다. 이러한 한계들은 3D 장면과의 상호작용이 요구될 때 명백해지며, 구조적 이해는 객체 조작, 동적 장면 이해, 3D asset extraction과 같은 작업에서 필수적으로 요구되고 있다고 합니다.
인간은 장면을 다양한 수준의 세분화된 영역들을 알아서 인지할 수 있는 고유한 능력을 지니고 있습니다. 예를 들어,fig 1에서 보이는 바와 같이 굴착기를 하나의 단일체로 보는 것에서부터 바퀴, 크레인, 운전실과 같은 하위 부품을 식별하는 것까지 가능합니다. 이러한 계층적 인지는 복잡한 3D 환경을 이해하고 상호작용하는 데 필수적입니다. 기존 NeRF는 이러한 다중 레벨의 그룹화를 포착하지 못하여 장면을 의미적으로 해석하는 능력에 큰 한계를 보이고 있습니다.
GARField(Group Anything with Radiance Fields)는 3D 장면을 의미적으로 유의미한 그룹의 계층 구조로 분해하는 방법을 제시함으로써 이러한 문제를 해결하고자 합니다. 평면적 계층 구조를 생성하거나 모호성을 해결하기 위해 수작업이 필요한 기존 접근법과 달리, GARField는 scale-conditioned affinity fields를 활용하여 자동으로 계층적 그룹화를 포착합니다. 이 새로운 프레임워크는 3D의 각 점이 원하는 세분성 수준에 따라 서로 다른 그룹에 속할 수 있도록 합니다. Segment Anything Model (SAM)이 생성한 2D 마스크를 활용하여 affinity field를 최적화함으로써 GARField는 다중 뷰 일관성을 보장하고, 모호한 그룹화를 세분화 및 통합 방식으로 해결합니다.
Method
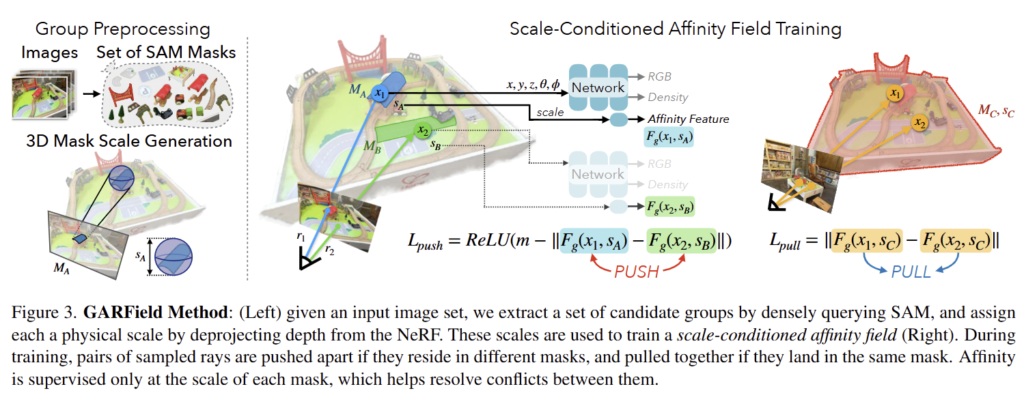
GARField는 연속적인 이미지들을 입력으로 받아 standard 3D volumetric radiance fields와 scale-conditioned affinity field를 활용하여 장면에 대한 계층적 3D 그룹을 생성합니다. 이를 수행하기 위해서 입력 이미지들을 SAM으로 사전 처리하여 마스크 후보군들을 획득합니다. 그 다음, single 3D location과 euclidean scale을 사용하는 affinity filed와 함께 volumetric radiance field를 최적하하고 feature vector를 출력합니다. 여기서 affinity는 points의 feature vectors 쌍들을 비교하여 획득합니다.
최적화를 수행한 다음에, affinity field는 3D에서 feature embedding을 coarse-to-fine manner로 내림차순으로 재귀적으로 클러스터링하여 장면을 분해하거나 사용자 지정 쿼리를 분할하여 사용하는 방식을 이용합니다. 이에 대한 전반적인 파이프라인은 fig 3에서 확인 가능합니다.
2D Mask Generation
GARField는 Segment Anything Model (SAM)을 활용하여 포즈가 지정된 이미지로부터 2D 마스크 집합을 생성합니다. 이 마스크들은 3D 공간에서 그룹화를 위한 후보로 사용됩니다. 구체적으로 SAM의 automatic mask generator를 활용합니다. automatic mask generator는 그리드 방식으로 쿼리를 수행하여 각 쿼리 포인트마다 3개의 후보 세분화 마스크를 생성합니다. 이후, 마스크의 신뢰도를 기준으로 필터링하고, 유사한 마스크를 제거하여 다양한 크기의 마스크 후보 목록을 생성합니다. 이 과정은 뷰 포인트와 독립적으로 수행되므로, 생성된 마스크가 뷰 간에 일관되지 않을 수 있습니다.
+ automatic mask generator는 SAM의 every-thing 기능이라고 보시면 됩니다.
GARField는 물리적 크기를 기반으로 그룹 계층 구조를 생성하는 것을 목표로 하며, 이를 위해 각 2D 마스크에 물리적 3D 스케일을 할당합니다. Fig 3에 나타난 것처럼, 이를 위해 Radiance Field를 부분적으로 학습시키고, 각 학습 카메라 포즈로부터 깊이 이미지를 렌더링합니다. 이후, 각 마스크 내의 3D 점을 분석하고, 해당 점들의 위치 분포 범위에 따라 스케일을 결정합니다. 이러한 방법은 마스크의 3D 스케일이 동일한 월드 스페이스에 위치하도록 보장하며, Scale-Conditioned Affinity Field를 가능하게 합니다.
Scale-Conditioned Affinity Field
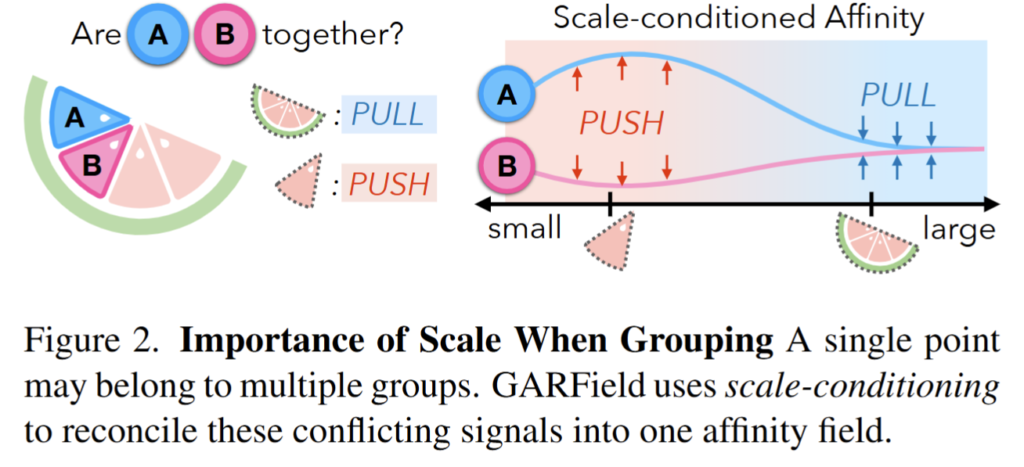
Scale-Conditioned Affinity Field는 GARField의 핵심 구성 요소로, 불일치하는 2D 마스크 후보를 통합할 수 있도록 합니다. 동일한 지점에서 다양한 그룹화 수준에 따라 여러 방식으로 그룹화될 수 있기 때문에, 이는 그룹화의 모호성을 해결하는 데 중요합니다. Scale-Conditioned을 통해 동일한 지점에 대한 충돌하는 마스크들이 학습 중에 서로 간섭하지 않고, 다양한 친화도 스케일에서 공존할 수 있습니다.
Scale-Conditioned Affinity Field F_g(x, s) -> R^d 는 LERF에서 정의된 구조와 유사하게 3D points x와 euclidean scale s 에 대해 로 정의됩니다. 출력은 unit hypersphere로 제한되며, 스케일에서 두 점 간의 친화도는 다음과 같이 정의됩니다:
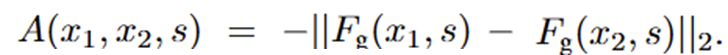
이 특징들은 NeRF density를 기반으로 동일한 렌더링 가중치를 사용하여 가중 평균 방식으로 볼륨 렌더링할 수 있으며, ray 단위로 값을 얻을 수 있습니다. fig 2는 이러한 Scale-Conditioned Affinity Field가 점들 간의 affinity를 어떻게 계산하는지 시각적으로 보여줍니다.
Contrastive Supervision.
Contrastive Supervision은 DrLIM에서 제시된 margin-based constrastive objective를 사용하여 field를 학습합니다. 이 손실은 두 가지 주요 구성 요소로 이루어져 있습니다: 특정 스케일에서 동일 그룹 내의 특징은 서로 가까워지도록 끌어당기며, 다른 그룹의 특징은 멀어지도록 밀어냅니다.
구체적으로, 동일한 학습 이미지 내의 마스크 M_A, M_B, 에서 샘플링된 두 ray r_A, r_B를 고려합니다. 해당 스케일은 각각 s_A, s_B 입니다. 이 ray에 따라 scale-conditioned affinity featurtes를 볼륨 렌더링하여 ray-level feature F_A, F_B 를 얻습니다.
만약 M_A = M_B 라면, 특징은 L_{pull} = ||F_A - F_B || 의 L2 거리로 끌어당겨집니다.
반면 M_A \ne M_B 라면, 특징은 L_{push} = ReLU(m - ||F_A - F_B ||) 로 서로 밀어냅니다. 여기서 m은 lower bound distance에 해당합니다.
중요한 점은, 해당 손실은 동일한 이미지에서 샘플링된 rays에만 적용되며, 서로 다른 뷰포인트의 마스크는 대응 관계 고려하기 힘들기 때문입니다.
Densifying Scale Supervision
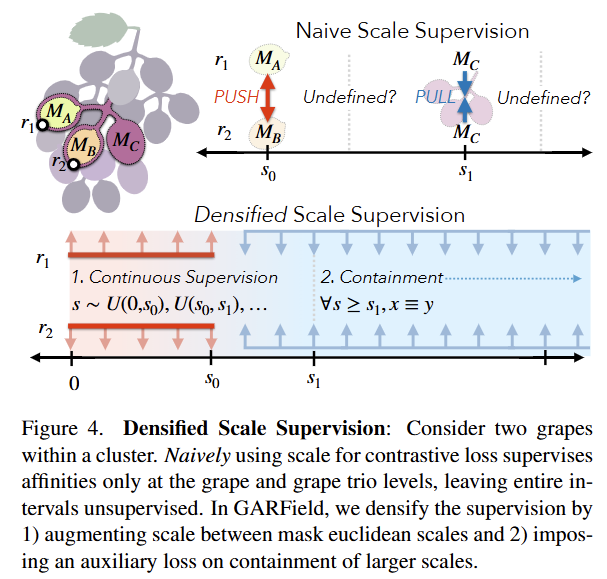

기존 constrastive loss만으로는 계층 구조를 유지하기에 충분하지 않습니다. 예를 들어, fig 9보면 scale 0.22에서는 달걀이 수프와 올바르게 그룹화되었으나, 더 큰 스케일에서는 분리됩니다. 이러한 그룹화 불안정성의 원인은 저자는 다음과 같이 가정을 세웁니다. 1) 마스크가 존재할 때만 스케일 감독이 희소하게 정의되며, 2) 작은 스케일 그룹이 더 큰 스케일에서 유지되도록 강제하는 요소가 없기 때문이라고 가정합니다. 저자는 이를 해결하기 위해 2가지 기법을 제시합니다.
Continuous scale supervision. 만약 3D mask scale만을 사용하여 그룹핑을 수행하면 마스크가 선택된 이산 값에서만 정의됩니다. 이로 인해 Fig 4 상단에 나타난 것처럼, 스케일에서 큰 unsupervised regions이 발생합니다. 스케일에 대한 지도학습 비율을 높이기 위해 현재 마스크 스케일과 다음으로 작은 마스크 스케일 사이를 균등하게 랜덤 샘플링하여 스케일을 보강합니다. 특정 뷰포인트에서 가장 작은 마스크에 해당하는 ray의 경우, 0과 s_0 사이를 보간합니다. 이를 통해 필드 전반에 걸쳐 continuous scale supervision을 보장하여 unsupervised regions을 제거합니다.
Containment Auxiliary Loss. 만약 두 광선 r_1과 r_2이 스케일 s에서 동일 마스크에 속한다면, 더 큰 스케일에서도 함께 묶여야 합니다. 직관적으로, 동일 클러스터 내의 두 포도알은 더 큰 스케일에서도 함께 그룹화됩니다(예: 포도송이 전체). 각 학습 단계에서, 스케일 s에서 그룹화된 광선에 대해 더 큰 스케일 s’을 샘플링하여 해당 광선들이 이 스케일에서도 함께 묶이도록 합니다. 이를 통해 작은 스케일에서의 affinity가 더 큰 스케일에서도 유지되도록 보장합니다.
Ray and Mask Sampling
NeRF 학습과 마찬가지로, GARField는 손실을 계산하기 위해 광선을 샘플링합니다. 그러나 GARField는 각 학습 이미지 내에서 대조 손실을 사용하므로, 훈련 중에 픽셀을 균일하게 샘플링하는 것만으로는 각 미니배치에서 충분한 훈련이 어렵습니다. 이를 보완하기 위해, 먼저 N 개의 이미지를 샘플링하고 각 이미지에서 M 개의 광선을 샘플링합니다. 이미지 수와 학습을 위한 point pairs를 균형 있게 유지하기 위해, 16개의 이미지를 샘플링하고 각 이미지에서 256개의 광선을 샘플링하여, 학습 반복당 총 4096개의 샘플을 생성합니다.
각 샘플된 광선에 대해, 해당 학습 단계에서 그룹 레이블로 사용할 마스크를 선택해야 합니다. 이를 위해 학습 과정 동안 픽셀과 마스크 레이블 간의 매핑을 유지하며, 각 학습 단계에서 각 광선의 대응 마스크 목록에서 무작위로 마스크를 선택합니다. 이 샘플링 과정에서 두 가지 중요한 고려사항이 있습니다:
- 마스크가 선택될 확률은 마스크의 2D 픽셀 면적의 log에 반비례하도록 가중치를 부여합니다. 이는 큰 스케일의 마스크가 더 많은 픽셀을 통해 샘플링될 가능성이 높기 때문에, 샘플링 과정에서 큰 스케일이 주가 되지 않도록 합니다.
- 마스크 선택 중, 동일 이미지 내의 광선들 간에 무작위로 선택된 스케일 값을 동기화하여 positive pair의 확률을 높입니다. 이를 위해, 각 이미지마다 0에서 1 사이의 값을 샘플링하고, 각 픽셀의 마스크 확률 누적 분포 함수(CDF)에 동일 값을 인덱싱하여 동일 그룹 내 픽셀들이 동일 마스크에 할당하도록 합니다. 그렇지 않으면, 손실은 밀어내는 힘에 의해 지배되어 학습이 불안정해질 수 있다고 합니다.
Experiment

LERF 데이터 셋과 저자가 추가로 제안한 데이터 셋에서의 실험 결과, 정성적인 분석들은 3DGS를 기반으로 실험을 진행하였다고 합니다. fig 7 결과를 통해 의미있는 부위들을 마스킹 하는 결과를 보여줍니다.

fig 8에서는 단독 이미지에서의 SAM으로 분할을 수행한 결과입니다. 저자가 제안한 기법들은 다양한 시점을 기반으로 분할이 가능하기 때문에 세밀한 부분까지 깔끔하게 구분하는 결과를 보여줍니다.
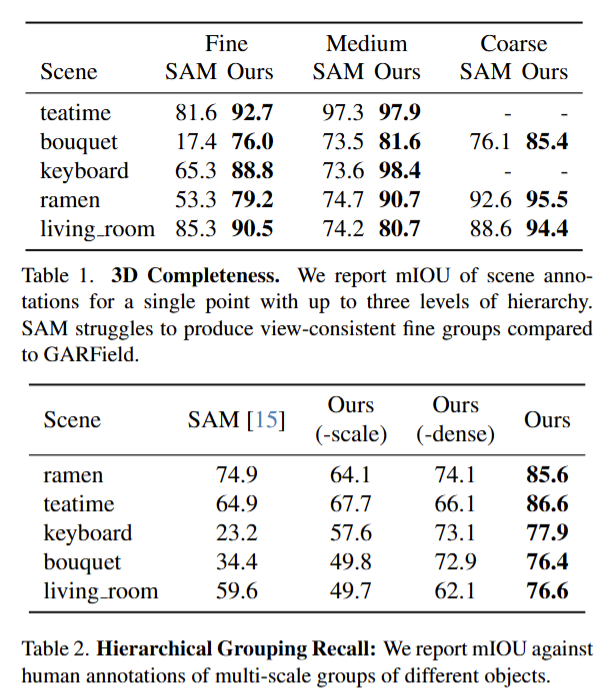
Tab 1,2에서는 SAM과 저자가 제안한 기법을 기반으로 한 mIOU 성능 비교 분석 결과입니다. 여러 뷰포인트를 고려 가능하기 때문에 단독 뷰포인트를 활용하는 SAM 보다 좋은 성능을 보여주고 있습니다. 또한 Tab 2에서는 mask에 대한 scale만 이용한 기법과 dense 있도록 학습을 구성한 기법만 사용한 결과를 비교합니다.