제가 이번에 리뷰할 논문도 Affordance와 관련된 논문으로, 2024년 10월 말에 아카이브에 공개된 논문입니다.
Abstract
기존 연구들은 3D motion constraints와 affordance에 대하여 제한적으로 이해하고있으며, 이러한 한계를 극복하기 위해 저자들은 통합된 공식으로 3D 객체 중심의 manipulation과 task understanding을 통합하는 포괄적인 패러다임, UniAff를 제안합니다. 구체적으로는 manipulation과 관련된 key attribute로 라벨링된 데이터 셋을 구축하였으며, MLLMs를 사용하여 manipulation에 필요한 affordance 정보와 3D motion constraints를 포함하는 객체 중심 표현을 추론하였다고 합니다. 저자들은 real-world와 시뮬레이터 상에서 다양한 실험을 수행하였고, UniAff가 tool과 articulated object(articulated object란 전자레인지와 같이 조작 가능한 객체를 의미합니다. 해당 논문에서는 tool과 articulated object라고 하여 물체를 크게 두 가지로 구분하고 있습니다.)에서 모두 maniputation의 일반화를 크게 향상시킬 수 있음을 확인하였다고 합니다. 또한 저자들은 UniAff가 로봇 manipulation 작업에서 일반화를 위한 베이스라인이 되기를 바란다는 포부도 밝히고 있습니다.
Introduction
실제환경에서 로봇을 구현하기 위해서는 tools와 articulated objects의 조작이 중요하며, 로봇의 물체 조작을 위해서는 3D 공간의 물리적 제약과 상호작용 영역의 이해가 필요합니다. articulated objects의 효과적인 조작을 위해서는 물체에서 움직일 수 있는 부분, joint의 종류, 3D joint의 파라미터, affordance 등을 인식할 수 있어야 합니다. 또한, 특정 작업에서 tool을 사용하기 위해서는 6D Pose와 grasping 영역, functional 영역을 파악해야 합니다.(칼을 예시로 들면 grasping 영역은 로봇이 물체를 잡기 위한 부분, functional 영역은 물체를 자를 수 있는 날 부분을 의미합니다.) 작업과 관련된 6D Pose와 3D motion constraints, affordance에 대한 예측을 통합하므로써 embodied 로봇은 적응성과 효율성이 강화될 수 있습니다.
그러나 기존 연구들은 대부분 tools와 articulated objects에 초점을 맞추었으므로 여러 작업에 일반화가 어려웠습니다. Vision 모델로 manipulation과 관련된 파라미터를 예측한 뒤, LLM의 추론 능력을 활용하는 2-stage 방식으로 접근을 하였으며, 이러한 방식은 case-by-case 문제로 다뤄져 일반화 능력이 제한적이었다고 합니다. 저자들은 이러한 한계를 극복하기 위해 tools와 articulated objects를 모두에 대해 affordance 표현을 통합하는 UniAff를 제안합니다. 아래의 [그림 1]과 같이 UniAff는 MLLMs(Multimodal Large Language Models)를 이용하여 객체 중심의 manipulation과 task에 대한 이해를 결합하여 3D motion contstraints와 affordance에 대한 인식을 개선하였다고합니다.
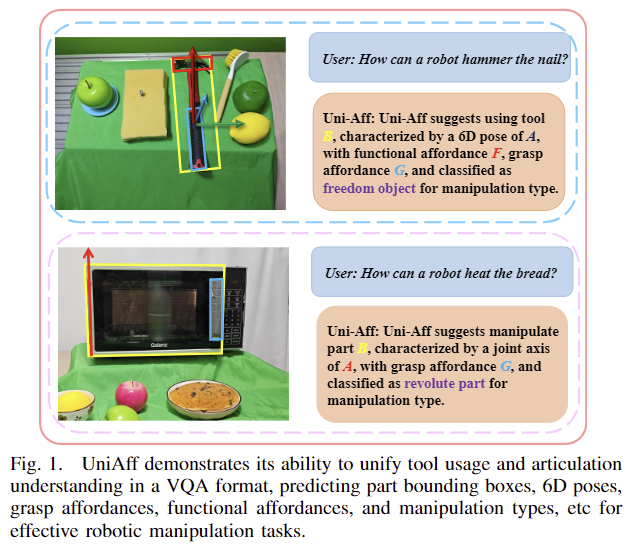
저자들은 UniAff를 학습하기 위해 데이터 셋을 제안합니다. 해당 데이터 셋은 articulated objects manipulation과 tool-use task를 포함하는 데이터 셋으로, 19가지 카테고리의 900개 articulated objects와 12가지 카테고리의 600개 tools로 구성됩니다. 각 물체는 part 수준의 6D Pose와 grasp affordance, manipu;ation types과 functional affordance 정보가 라벨링되어있으며, manipulation을 통합된 공식으로 표현하므로써 객체 중심의 3D motion constraints와 affordance를 통합합니다. 이때, 실제와 유사한 시뮬레이션을 이용하여 대규모로 데이터 셋을 구축하였습니다.
MLLM에 통합된 affordance 능력을 갖추기 위해 저자들은 제안한 데이터 셋을 이용하여 MLLM인 SPHINX[1] 모델을 fine-tuning하여 UniAff가 물체중심의 3D represenstation을 예측하고 tools와 articulated objects에 대한 affordance를 추론할 수 있도록 합니다. 또한, 저자들에 따르면 두 카테고리에 대해 통합된 이해를 제공하는 첫 번째 방법론이라 합니다. 저자들은 real-world와 시뮬레이션에서 다양한 실험을 통해 자신들의 방식이 모두 효과가 있음을 입증하였고, HANDAL 데이터셋에서 좋은 성능을 보였으며, articulated object에 대해서 Unseen instance에서는 기존 방식 대비 7.07%, Unseen categories에서는 9.60% 개선된 성능을 보였다고 합니다. 이러한 실험을 통해 저자들의 방식이 다양한 task에서 일반화가 가능함을 보였으며, 해당 논문의 contribution을 정리하면 다음과같습니다.
[1] Lin, Ziyi, et al. “Sphinx: The joint mixing of weights, tasks, and visual embeddings for multi-modal large language models.” arXiv preprint arXiv:2311.07575 (2023).
- MLLM을 이용하여 물리적 특성과 3D motion constraints, 조작을 위한 affordance를 이해하는 UniAff 제안
- 19가지 카테고리의 articulated objects와 12가지 카테고리의 tools로 구성되며, part수준의 6D Pose와 manipulation type, affordance 라벨을 포함하는, 1,500개의 물체로 이루어진 데이터 셋 제안
- 다양한 실험을 통해 UniAff가 articulated objects와 tools에 대해 일반화 성능이 상당히 개선됨을 입증
Method
방법론은 task 공식을 통합하는 방식을 설명한 뒤, 데이터 셋에 대해 설명한 후, VQA를 이용하여 MLLM을 fine-tuning하는 방식에 대해 설명합니다.
A. Formulation of Structured Manipulation Task
먼저 저자들은 manipulation task T에 대하여 다음과 같이 정의합니다. unkown object M이 K개의 움직일 수 있는 부분으로 이루어진 경우 M=\{ m_i \}^K_{i=1} 로 표현하며, 이러한 물체는 이미지 I와 depth map D에서 확인할 수 있습니다. 또한, 물체의 각 부분 \psi_i=\{ \mathcal{A}_i, \mathcal{B}_i, \mathcal{G}_i, \mathcal{F}_i, \mathcal{J}_i, \mathcal{L}_i \}으로 물체 구조 S=\{ \psi_i \}^K_{i=1} 를 표현합니다. 여기서 \psi_i를 구성하는 각 요소에 대한 내용은 아래와 같으며, 하나의 부분으로 이루어진 tools는 하나로 구성된 물체로 봅니다.
- \mathcal{A}_i \in \mathbb{R}^{4⨉3} : 3D공간에서의 6D Pose 정보. 1×3의 position 정보와 3×3의 rotation 정보로 구성
- \mathcal{B}_i \in \mathbb{R}^{4⨉2}: part의 rotated BBOX로 2D 이미지상에서 key point 4개의 (x,y) 좌표([그림2]예시처럼 rotation이 적용된 형태)
- \mathcal{G}_i \in \mathbb{R}^{4⨉2}: grasping affordance에 대한 BBOX로 2D 이미지상에서 key point 4개의 (x,y) 좌표([그림2]예시처럼 rotation이 적용된 형태)
- \mathcal{F}_i \in \mathbb{R}^{4⨉2}: functional affordance에 대한 BBOX로 2D 이미지상에서 key point 4개의 (x,y) 좌표([그림2]예시처럼 rotation이 적용된 형태)
- \mathcal{J}_i: manipulation의 타입을 의미하며, 아래의 [그림 2]의 예시에서 확인할 수 있듯이 bottle cap, revolute parts, sliding lids, prismatic parts 4가지와 6DoF 자유도를 갖는 freedom object로 타입을 정의함.
- bottle cap의 경우 축이 있고 회전하여 위아래로 움직일 수 있는방식
- revoluate part의 경우 회전 축을 중심으로 회전만 가능. 즉, 위아래 움직입에는 제한이 있음.
- sliding lid는 위로 움직이며, 그 거리에 제한이 없음
- prismatic part는 위로 움직이며, 그 거리에 제한이 있음
- freedom object는 움직임 자체에는 제한이 없음
- 각 joint type에 대해 논문에서 정확하게 명시되어있지는 않으나, 일반적으로 물체 조작 방식이 1DoF의 P와 R joint를 각 각 혹은 합친 형태로 존재한다는 말과, 3D motion constraints라는 점에서 위의 내용으로 구분을 한 것이라 추정합니다…
- \mathcal{L}_i: part의 상태나 기능에 대한 묘사(Discriptive Sentence)
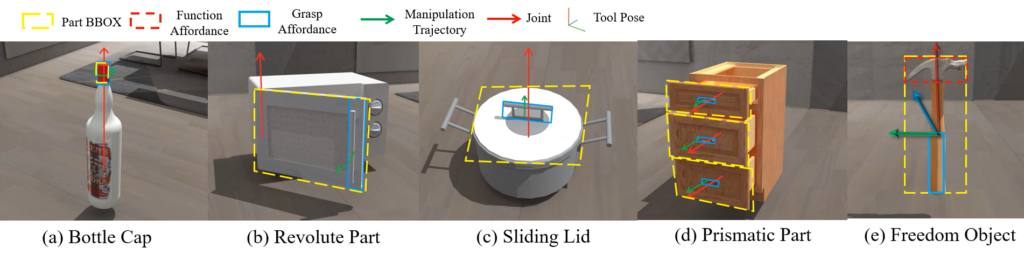
저자들이 articulated objects와 tools 모두에 대해 3D motion constrains와 affordance를 통합하여 표현하였다는 것이 결국은 물체를 조작 가능한 부분으로 나누어 다양한 정보를 통합하여 표현한 것이라 이해하였습니다.
B. Synthetic Data Generation
앞서 정의한 물체의 부분 표현에 대한 통합된 구조 \psi를 기반으로 tools와 articulated object에 대한 합성 데이터를 생성합니다. 저자들은 real-world data를 구축하는 것에는 시간과 비용이 많이 들기 때문에 실제와 유사한 시뮬레이션을 이용하였으며, 이를 통해 효율적으로 대규모의 데이터를 구성할 수 있었다고 합니다. 대규모 합성 데이터를 이용하여 VLM 모델을 fine-tuning하며, 동시에 large model의 능력을 통해 시뮬레이션 데이터를 real-world로 일반화할 수 있었다고 합니다.
< Tools >
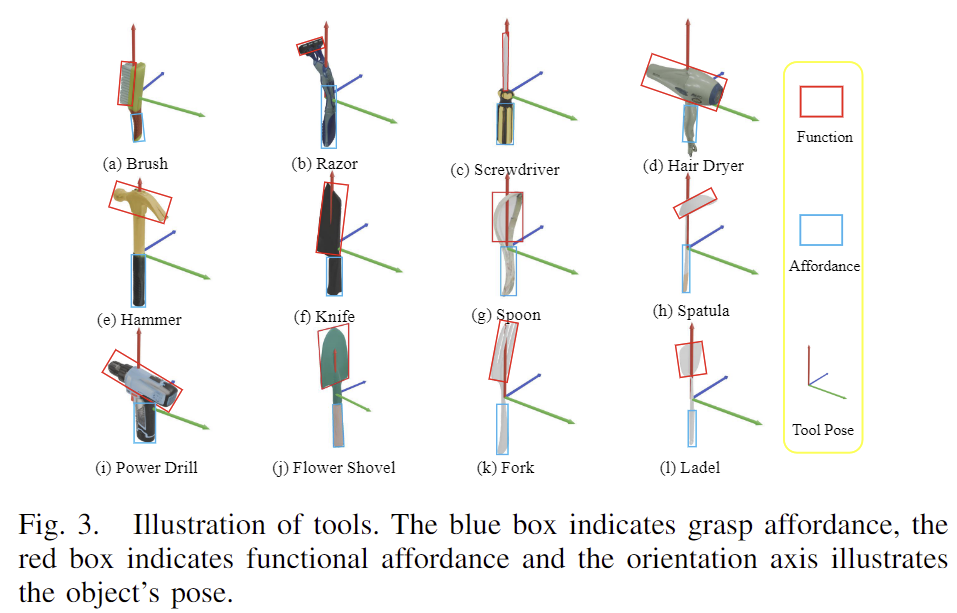
tool의 사용은 3D 공간에서 6D Pose와 밀접한 관계가 있으므로 tool의 6D Pose와 grsping/functional affordance 정보를 모델링해야 합니다. 저자들은 PACE와 OmniObject3D라는 기존 데이터 셋에서 실제 물체를 스캔한 230개의 tools 모델을 활용하였으며, 저자들이 추가로 370개의 tools를 추가로 스캔하였으며, 일관성을 유지하기 위해 모든 도구를 공통 축으로 맞춥니다. Blender(프로그램)를 이용하여texture mesh를 grasp affordance parts와 functional affordance parts로 세분화하였으며 이 작업에는 약 5분이 소요된다고합니다.
실제와 유사한 시뮬레이션을 이용하여 clutter하게 렌더링하여 복잡한 scene을 구성하였으며, 각 장면은 앞서 정의한 \{ \mathcal{A}, \mathcal{B}, \mathcal{G}, \mathcal{F}, \mathcal{J}, \mathcal{L} \} 형식으로 자동으로 라벨링이 수행되며, 이때 tools의 manipulation type은 “freedom object”가 됩니다. 장면 구성과 tools의 방향, 주변 객체를 다양하게 변화를 주어 광범위한 시나리오를 포함하여 모델이 다양한 작업에 일반화 될 수 있도록 합니다.
< Articulated Objects >
articulated objects를 효과적으로 조작하기 위해서는 각 부품의 manipulation type \mathcal{J}과 3D 공간에서 해당 joint의 축 \mathcal{A}, grasp affordance \mathcal{G}를 이해해야 합니다. 이를 위해 PartNetMobility 데이터셋의 19가지 카테고리의 900개의 물체에 대해 마찬가지로 앞서 정의한 통합된 구조 \psi로 공식화 하여 라벨을 적용합니다. 이때 기존 데이터는 movable한 파트로 나눠져있지 않은 경우가 있어 이를 저자들이 각 링크로 분리하였다고합니다.
앞서 정의된 \psi에 따라 다양한 상태의 물체를 렌더링하였으며, 이때 \mathcal{J}는 4가지(bottle caps, sliding lids, revolute parts, prismatic parts) 중 하나로 분류됩니다. \mathcal{G}의 경우 part의 상태에 따라 affordance 영역이 달라지므로(예를들어 문이 닫혀있을 경우 손잡이만 affordance 영역이 되지만, 문이 열려있을 경우에는 손잡이 뿐만 아니라 문의 가장자리도 affordance 영역이 될 수 있습니다.) 별도의 처리를 수행합니다. 상태에 따른 affordance 영역 변화를 고려하기 위해 문의 가장자리에 joint의 상태에 따라 가중치를 주는 방식으로 affordance 정보가 제공됩니다. 가중치는 아래의 식(1)로 정의가 되며, 이때 \mathbf{J}는 joint의 각도, \theta는 사전에 정의한 임계치를 의미합니다. 즉, 임계치 이상 넘어가지 않았을 경우에는 가중치가 음수가 되도록 한 것입니다.
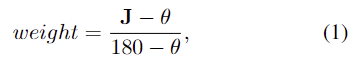
< VQA Design >

효과적으로 6가지 파라미터 \{ \mathcal{A}, \mathcal{B}, \mathcal{G}, \mathcal{F}, \mathcal{J}, \mathcal{L} \}를 고려하기 위해 위의 [표 1]과 같이 multiple VQA(Visual Question Answering) 프롬프트를 활용하여 4가지의 task를 설계하였다고 합니다. task별 프롬프트로 모델에 가이드로 제공하는 multi-task learning 프레임워크를 개발하였으며, 이러한 VQA 기반의 방식을 통해 다양한 manipulation과 관련된 사전 지식을 통합하여 다양한 물체 카테고리와 시나리오에서 복잡한 manipulation task를 처리할 수 있도록 하였다고 합니다. 이러한 multi-task MLLMs는 작업 효율성뿐만 아니라 다양한 로봇작업으로의 일반화 능력도 개선합니다.
- 2D-Part-Detection Task: object part와 대응되는 BBOX (\mathcal{B}) 인식
- 6D-Pose-Detection Task: manipulation type (\mathcal{J})과 6D Pose (\mathcal{A}) 인식
- 2D-Grasp-Affordance Task: grasp 영역 (\mathcal{G})
- 2D-Functional-Affordance: functional 영역(\mathcal{F})
C. MLLMs-based Manipulation and Model Fine-tuning
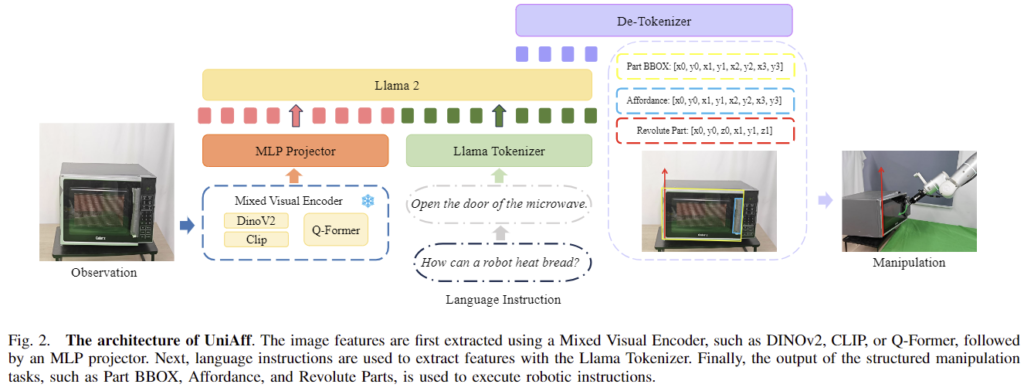
저자들은 위의 [그림 4]에서 확인할 수 있는 UniAff 알고리즘을 제안하며, 이 구조는 SPHINX[1]를 기반으로 하며, 언어모델로는 LLaMA2를 사용하여(SPHINX이 언어모델로 LLaMA2를 사용함) 시각적 입력과 언어 입력 사이의 강력한 상호작용이 가능하도록 합니다. 이를 통해 manipulation task에 중요한 물체의 특성을 파악하는 데 중점을 둡니다.
구조를 세부적으로 살펴보면, 먼저 448⨉448 해상도의 입력 이미지를 더 작은 하위 이미지로 분할하여 정보를 유지하는 “Any Resolution” 방식을 적용한 뒤, global과 local visual grounding을 위해 CLIP의 visual encoder를 통합하여 local semantic feature를 추출하였다고 합니다. 또한 DINOv2를 통합하여 모델이 디테일한 local semantic을 파악할 수 있도록 하였으며, Q-Former를 통해 global한 시각적 정보를 요약할 수 있도록 하였다고 합니다. 이러한 local 및 global feature를 채널 차원으로 concatenated하여 manipulation task를 위한 시각적 이해를 향상시켰습니다.
저자들은 자연어 표현으로 3D 물리적 정보와 affordance를 인코딩하여 VQA 프레임워크에 맞춰 fine-tuning을 수행합니다. 학습에는 Cross-entropy loss를 주요 loss로 활용하였으며, 시각적 정보를 투영하는 MLP Projection layer와 language model을 공동으로 학습합니다. 마지막으로 De-Tokenizer를 통해 decoding 된 manipulation 정보와 시각 데이터를 결합하여 지정된 task를 완료합니다.(VQA task)
Experiments
실험은 시뮬레이션과 real-world에서 모두 수행되었으며, (1) UniAff가 tool에 대해 grasp와 functional affordance를 효과적으로 인식할 수 있는지?와 (2) UniAff가 3D 공간에서의 motion constraints와 manipulation을 위한 affordance를 동시에 파악할 수 있는지?, (3) UniAff가 real-world application에 효과적으로 일반화가 가능한지?를 관점으로 분석을 수행합니다.
0. Experimental Setting
Model Setting)
- 80GB A100 8장으로 SPHINX 기반의 모델을 fine-tuning하였으며, 총 3 epoch으로 10시간 소요되었습니다. 또한 사전학습된 모델의 성능을 유지하기 위해 visual encoder는 모두 freeze하여 학습을 진행하였습니다.
Dataset Setting)
- Tools: 9개의 카테고리를 선정하여 450개의 tools를 training set으로 하고, 70개의 tools는 Unseen instance로 설정합니다. 또한 나머지 3개 카테고리의 80개의 tools를 Unseen categories로 설정하여 training tools로 10000개의 scene을 구성하고, unseen instance로 3000 scene을 구성합니다.
- Articulated Objects: 13개 카테고리를 선정하여 502개의 object를 training set으로 하고, 160개의 object를 Unseen instance로 설정합니다. 또한, 나머지 6개 카테고리의 238개의 object를 Unseen categories로 설정합니다. training object는 20가지 state로 5개의 시점에서 랜더링하여 총 50200개의 이미지를 생성하고, 렌더링된 데이터는 [표 1]과 같이 구조화된 \psi에 따라 변환하여 UniAff를 학습합니다.
1. Robotic Affordance Detection Results

HANDAL dataset을 이용하여 affordance에 대한 평가를 수행하였으며, 픽셀수준의 segmentation AP를 평가지표로 사용합니다. HANDAL의 베이스라인 모델은 물체 전체를 감지하지만 저자들의 방식은 grasp와 functional affordance를 모두 효과적으로 인식하는 것을 확인하였으며, 이에 대해서는 [그림 5]로 확인할 수 있습니다. 그러나 베이스라인 방식과 직접적인 비교를 위해 UniAff로 예측한 회전된 BBOX를 표준화된 BBox로 표현한 뒤 SAM을 적용하여 예측한 픽셀 수준의 영역을 구하였습니다.
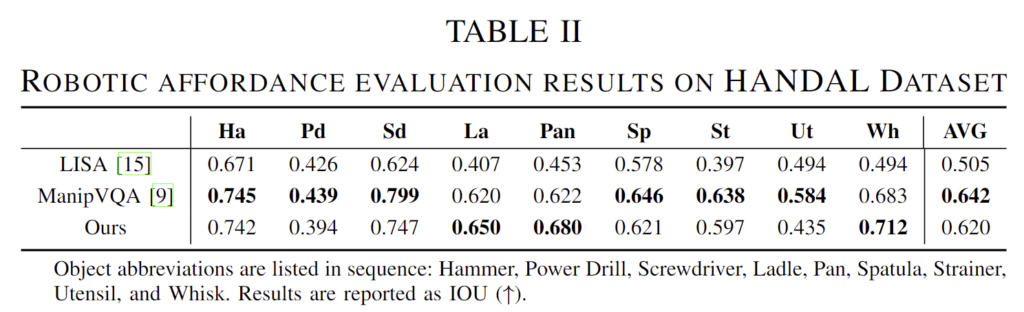
이에 대한 실험 결과는 [표 2]에서 확인할 수 있으며, 시뮬레이션 데이터로만 학습한 UniAff가 경쟁력 있는 성능을 보였다고 분석합니다. 평균적으로 ManipVQA와 비교했을 때 2.2% 낮은 성능을 보이지만 ManipVQA는 HANDAL 데이터 셋에 대한 학습이 수행되었다는 점에서 저자들이 제안한 방식의 효과를 어필합니다.
2. Tool Usage Understanding Evaluation
UniAff의 tool 사용에 대한 이해도를 평가하기 위해 test set에 대한 평가를 수행합니다. 해당 실험은 grasp와 functional affordance 모두에 대한 평가를 수행하며, ManiVQA와 비교를 수행합니다.

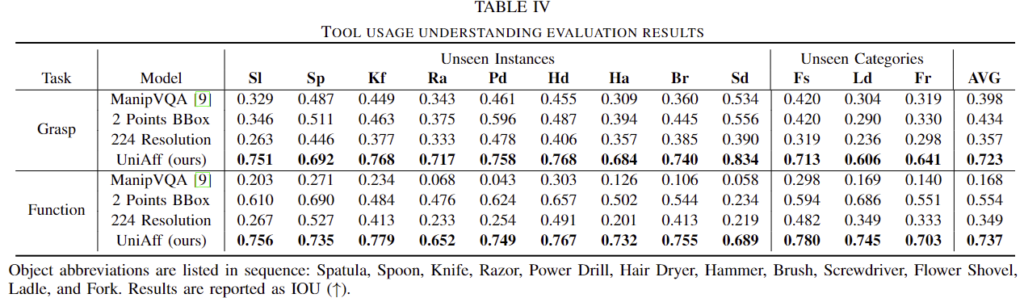
[표 3]에서 확인할 수 있듯이 functional affordance에서 상당한 개선이 이루어졌으며, grasp에 대해서도 가장 좋은 성능을 보이는 것을 확인할 수 있습니다. 이를 통해 UniAff가 다양한 tools에 대해 일반화가 가능함을 보였습니다. 224 Resolution 결과는 “Any Resolution” 방식을 이용하지 않고 해상도를 224×224로 설정하는 방식을 실험한 것으로 해상도 저하에 따라 성능이 크게 저하되는 것을 통해 고해상도의 영상 입력이 필요하다는 것을 보였습니다. 또한, 2 Poit BBOX는 회전된 BBOX가 아닌 방식으로 affordance를 표현한 방식으로, 회전을 고려한 BBOX가 성능 개선에 도움이 도니다는 것을 실험적으로 보였습니다.
3. Articulated Manipulation Evaluation
articulation task를 평가하기 위해 seen 카테고리에 대해 opening bottle caps, sliding lids, and both revolute and prismatic parts 작업을 수행하였으며, unseen 카테고리에 대해서는 sliding lids and revolute/prismatic parts 작업을 수행하였습니다. 평가는 160개의 unseen instance와 238개의 unseen categories에 대해 수행하였으며, 작업성공률로 평가를 수행합니다. (작업 성공 여부는 조작 후 변화된 joint state가 임계치 이상인지를 판단하는 방식입니다.)
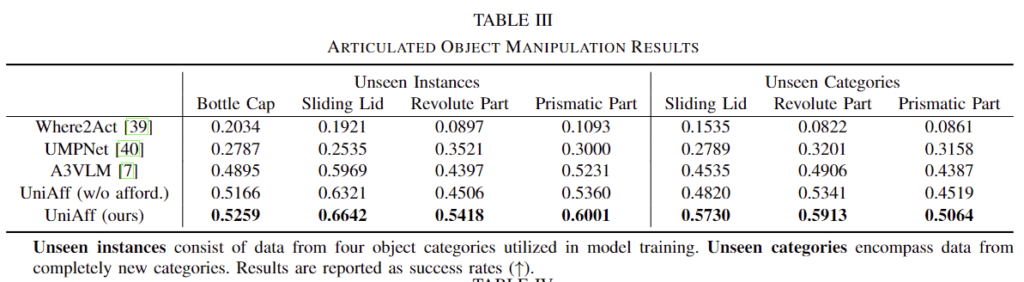
실험결과 articulation 구조를 명시적으로 모델링하는 A3VLM과 UniAff 방식 모두 좋은 성능을 보이는 것을 확인하였으며, A3VLM에 비해 unseen instances에 대해 7.07%, unseen categories에 대해 9.60% 향상된 성능을 보이는 것을 확인하였습니다.
4. Real-World Experiments
7 DoF의 Flexiv 로봇으로 real-world에서 실험을 진행하였으며, 로봇의 손에 RealSense D435를 부착하여 RGB-D 정보를 취득하였으며, UniAff를 통해 물체 중심의 3D motion constraints와 그에 대응되는 affordance를 예측합니다. 실험은 망치로 target을 치는 작업과 서랍./냉장고/전자레인지/냄비 열기와 양동이를 드는 작업 6가지로 구성하였으며, 이에 대한 결과를 아래의 동영상으로 확인하실 수 있습니다. 저자들은 이를 통해 UniAff가 실제 환경으로 일반화가 가능하다는 것을 어필하였습니다.
좋은 리뷰 감사합니다.
간단한 질문 하나 남기고 가겠습니다.
자율성이 보장된 로봇에 있어서 affordance는 진짜 필수인 것 같아요. 근데 affordance란 것이 일반화가 어려운 정보라고 생각이 듭니다. 여기서 말하는 일반화란 category-level object의 다양성 뿐만이 아니라 task에 따라 잡기 적절한 영역이 변경되는 것도 포함한 큰 의미에서의 일반화를 뜻합니다. 해당 기법에서는 해당 문제를 해결하기 위해서 LLM을 활용했는데요.
아쉽게도 affordnace의 영역은 bbox에 국한된 것으로 보입니다.
그래서 드리는 질문인데요. 이상적으로 affordance에 대한 영역을 표시한다면 어떤 형식이 가장 적합할까요?
저는 bbox로는 객체의 형태 정보를 디테일하게 고려하기 어렵기 때문에 affordance에 대한 영역 정보를 표시하기에는 segmentation 형식이 가장 적합하다고 생각합니다.
해당 논문도 bbox를 사용하지만 이를 간단하게 SAM으로 segmentation을 수행할 수 있으며, rotated 정보를 반영하도록 하였는데, 이를 이미지에 대해 살펴보시면 특정 영역에 최대한 타이트하도록 박스를 생성해둔 것을 확인할 수 있습니다. 해당 논문이 bbox 형식을 채택한 것은 다양한 정보를 통합된 structure 형태로 구성하기 위해 파라미터를 줄이고자 한 것으로 보입니다.
안녕하세요 승현님, 좋은 리뷰 감사합니다.
C. MLLMs-based Manipulation and Model Fine-tuning 에서
Mixed visual encoder feature들(local, semantic, global) 간에 단순 채널 축 concat으로 합치고 이후 MLP projection layer를 통해 학습시키는 과정이 있었는데,
혹시 이 부분이 cross-attention 후 MLP projection 등으로 좀 더 유의미하게 고도화될 수도 있을까요? 학습 parameter 가 많이 들어 힘들까요? 너무 막연한 생각인데 단순히 concat 한 것이 과연 local과 global semantic feature가 서로 잘 mixed 혹은 fusion 된 것이 맞는가하는 의문이 들어서 질문드립니다!
질문 감사합니다.
이야기하신대로, local과 global semantic feature에 대한 정보를 더 개선하기 위해 cross-attention 등의 방식을 적용해보는 것도 좋을 것 같습니다. 다만 연산이 너무 복잡해지고, 어찌보면 이 정보들을 융합하는 것을 Llama 2에서 수행하는 것이라는 생각이 들기도 합니다.