1. Introduction
Scene text spotting은 natural image내에 있는 text instance의 위치를 찾고 그 text가 무엇인지 인식하는 task입니다. 지금까지 이 spotting은 fully-supervised 방식으로 발전해오고 있었는데요, 본 논문의 저자는 이런 supervised 방식의 모델들이 좋은 성능을 보이고는 있지만, annotation cost가 많이 들고, data 분포가 다양한 경우에는 잠재적인 한계를 보인다고 언급합니다. 그래서 본 논문에서는 어떻게 하면 fully annotated 상황이 아닌, sparse annotation 상황에서 좋은 성능을 보일 수 있을까? 혹은, 도메인이 바뀌는 상황에서 어떻게 좋은 성능을 보일 수 있을까에 초점을 맞추고 있습니다.
이전 근 십 년간의 spotting 연구에는 ImageNet이나 MSCOCO로 학습한 VGG 혹은 ResNet을 백본으로 주로 사용을 해왔었는데요, CLIP이 등장하고 classification이나 detection, segmentation과 같은 여러 다운스트림에 적용됨에 따라 spotting에도 CLIP을 사용하고자 하는 시도가 있어왔습니다. Spotting을 생각해봤을 때 그 자체로 visual 정보와 character 정보를 갖고 있기 때문에 CLIP을 사용하고자 하는 시도가 자연스러웠죠. 이에 따라 이 visual, semantic, text knowledge간의 cross-modal 정보를 어떻게 잘 다뤄서 성능을 올려볼까에 주목한 연구들도 등장해오고 있었습니다.
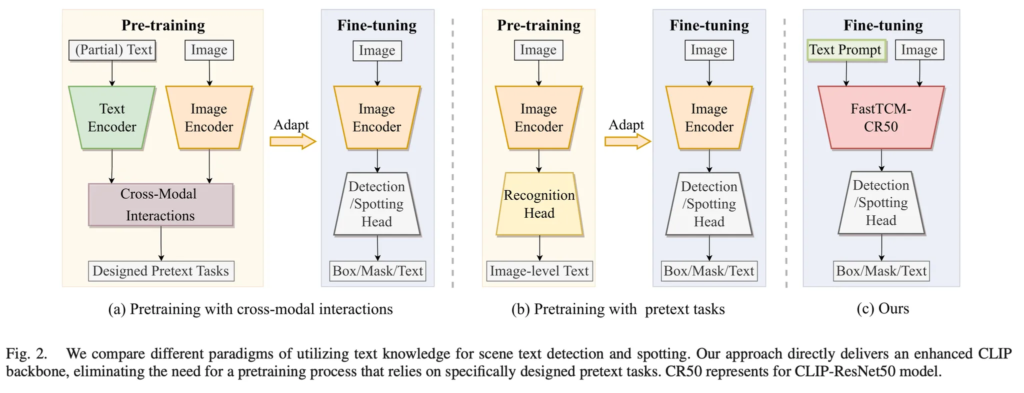
위 그림2에는 이런 연구들의 프레임워크를 도식화한 것인데요, (a)와 (b)를 보시면 pre-training 과정이 존재하고 사전학습한 image encoder를 가져와 fine-tuning하는 식으로 동작합니다. 반면에 본 논문에서는 CLIP 모델을 사용하여 이런 pretext 사전학습 자체를 하지 않고자 하였습니다. 하지만, 단순히 CLIP을 가져다 쓰는 것이 단순한 작업은 아니였다고 하며 그냥 붙였을 때는 굉장히 조금의 성능 향상만을 보이고 특정 task에서는 최악의 결과를 보이기도 했습니다. 즉, 그냥 사용하기보다는 각 image에 맞는 visual, semantic 정보를 사용하는 방식이 필요하다고 볼 수 있겠죠.
따라서 본 논문에서는 text detection spotting을 효과적으로 수행하고자 FastTCM-CR50이라고 하는 백본을 제안합니다. 이 FastTCM-CR50 백본은 현존하는 어떠한 text detection, spotting 모델에 붙일 수 있으며 어떠한 pretask pretraining과정 없이 바로 fine-tuning하는데 사용하도록 설계되었습니다. 단순 framework는 그림 2 (c)에서 확인해 볼 수 있습니다.

추가적으로, 이름에 Fast가 달린 만큼 inference speed를 줄이고자 한 모습을 볼 수 있는데요, 이전에 저자의 선행 논문에서 제안했었던 TCM-CR50과 비교해보았을 때 정확도도 높고 inference speed도 더 빠른 것을 위 fig1에서 확인할 수 있습니다. 이를 위해 저자가 설계한 구체적인 모듈 및 메커니즘은 아래 method 파트에서 자세히 다루도록 하겠습니다.
2. Methodology
2.1. Prerequisite: CLIP Model
Method 앞 부분에 짧게 CLIP 모델에 대한 설명이 나와있는데, 구체적인 것은 CLIP X-review를 확인해주시면 될 것 같습니다. 앞서 Intro에서 CLIP을 그냥 붙여 사용했을 경우 성능이 좋지 않았다고 했는데, 이런 CLIP의 인사이트를 잘 사용하려면 두 가지의 전제조건이 필요합니다.
첫 번째로, CLIP의 사전 지식에 어떻게 효과적으로 접근할 것인가 하는 것이 있으며,
두 번째로는 원래 clip은 전체 image와 단일 단어 혹은 문장 사이의 similarity를 계산하도록 설계가 되었는데 scene text detection 및 spotting에서는 일반적으로 한 image 당 수많은 text instance가 포함되어 있다는 점을 고려해야 한다는 것입니다. 저자가 이 두 전제 조건에 대해 어떻게 접근했는지 관점에서 아래 FastTCM을 봐주시면 될 것 같습니다.
2.2. FastTCM
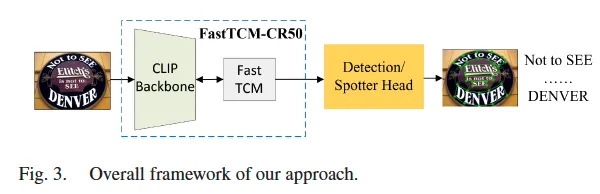
제안된 FastTCM은 text detector, spotter의 robust한 foundation으로 동작하고자 clip을 사용하여 설계된 백본입니다.
백본에서 크게 제안된 것은 CLIP의 image encoder로부터 뽑은 image feature로부터 좀 더 fine-grained한 visual feature를 추출할 수 있도록 하는 visual prompt generator 모듈과, 각 image에 대해 맞춤으로 prompt를 생성하는 language prompt Unit , 그리고 이미지 임베딩과 텍스트 임베딩간의 align을 맞춤으로써 image encoder가 text가 위치한 영역을 명시적으로 학습하도록 하는 instance-language matching방식 입니다. 여기까지는 이전 detector를 위해 CLIP을 사용했던 선행 연구와 동일한데, 추가적으로 더 빠른 추론 능력을 위하여 Bimodal Similarity matching을 제안하였습니다. 이 방식을 통해 clip encoder를 사용한 추론을 offline으로 할 수 있게 하였습니다. 저자가 설계한 모듈 및 FastTCM 동작 과정에 대해 하나씩 아래서 살펴보도록 하겠습니다.
2.2.1. Image Encoder
먼저 image encoder 부분입니다. Image encoder로써는 사전학습된 CLIP의 resnet50을 사용하였습니다. 입력 영상 I’ ∈ R^{H \times W \times 3}이 들어올 때 output 영상 임베딩은 I ∈ R^{H’ \times W’ \times C}가 되며 아래 식1로 나타내볼 수 있습니다.
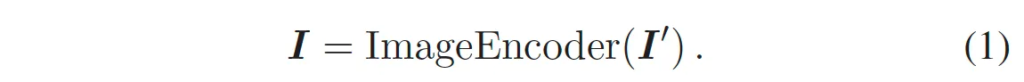
2.2.2. Text Encoder
다음으로 text encoder 부분입니다. 기존 CLIP의 text encoder는 K개의 class prompt를 입력으로 받아 vector space R^C로 임베딩하여 T = {t_1, …, t_k} ∈ R^{K \times C} text embedding을 output으로 내뱉습니다. 여기서는 pre-trained된 CLIP text encoder를 freeze해서 사용하며, text detection task에서는 class가 하나밖에 없기 때문에 K는 1로 설정이 됩니다. 기존 CLIP이 “a photo of a [CLS]”를 템플릿으로 사용하지만, 저자는 “Text”라고 하는 단순한 prompt를 사용하였습니다. Text encoder의 입력중 일부인 t’_{in}는 아래와 같이 나타낼 수 있겠습니다.
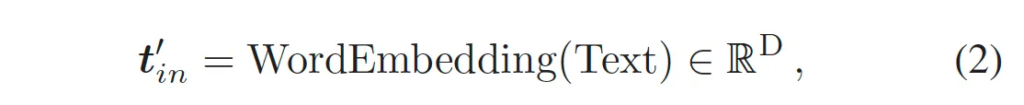
또, 저자는 text embedding의 transferability를 학습시키기 위해 앞선 사전에 정의된 prompt “Text”만 사용하는 것이 아닌, learnable한 prompt {c_1, … c_n)를 추가하였습니다. 이는 CLIP 모델이 zero-shot transfer를 더 잘할 수 있도록 하는 목적이며 이 학습가능한 벡터를 추가한 input prompt는 아래와 같이 나타낼 수 있습니다.
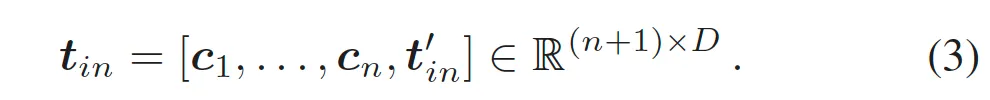
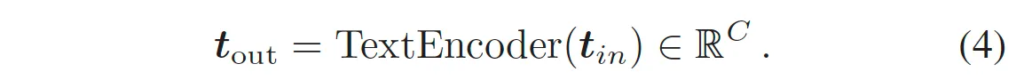
이 t_{in}를 입력으로 받아 clip의 text encoder에 태우면 위 식 4와 같이 text embedding t_{out}을 생성할 수 있습니다.
2.2.3. Language Prompt Unit

다음으로 저자가 제안한 Language Prompt Unit입니다. 앞서 말한 pre-defined prompt (”Text”)와 learnable한 prompt로 CLIP의 text encoder로 임베딩을 잘 뽑아낼 수 있겠지만, train image와 다른 분포를 갖는 test 이미지가 들어오는 경우에서는 few-shot 혹은 일반화 성능이 부족할 수 있다고 합니다. 이를 해결하기 위해 추가로 제안한게 language prompt unit이구요. 이 모듈은 conditional cue 이하 cc로 불리는 feature vector를 생성해내서 각 영상마다 이 cc가 text encoder input t_{in}에 더해져 입력으로 들어가게 됩니다. 위 그림 4를 보았을 때 좌상단 부분에 text encoder로 들어가는 입력 \hat{t}_{in}에 Meta Query를 입력으로 language prompt가 generator를 통과해 들어가는 것을 볼 수 있는데요.
구체적인 것은 아래 식을 참고하면 되겠습니다. \hat{t}_{in}이 최종 text encoder로 들어가는 input prompt가 되는 것입니다.
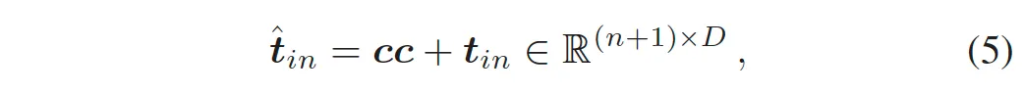
이전 저자의 선행 연구 CLIP into a detector에서는 이 cc를 생성할 때 입력 영상을 사용하여 그에 맞춤된 conditional cue를 생성하도록 하였는데요, 본 논문에서는 그와 다르게 meta query를 가지고 2 layer ffn을 통과하도록 해 conditional cue를 생성하도록 하였다는 차이점이 존재합니다. 추가로, 그림 4를 보면 image encoder와 text encoder의 extraction끼리 상호작용하는 Bimodal Simiarity Matching 모듈 (이하 BSM)이 존재하는데, 이는 이렇게 text encoder로 추출한 embedding에 얼마만큼의 visual modal 정보를 이 text modal embedding에 더해줄건지를 결정하는 일종의 gate라고 보시면 되겠습니다. 이 Meta Query와 BSM에 대해 각각 좀 더 살펴보도록 하겠습니다.
Meta Query
Meta Query는 R^C shape을 갖는 learnable한 query라고 보시면 됩니다. 이전에는 입력 image를 meta query대신에 썼다고 했었는데 Meta query로 바꾼 이유는 추론 시에 clip의 text encoder로부터 embedding을 추출하는 과정을 offline으로 할 수 있게 하기 위함으로 보입니다. 입력 영상 맞춤 cc를 생성해내는 것보다 DETR의 object query에서 아이디어를 착안하여 learnable한 query를 통해 image를 입력으로 하지 않아도 잠재적인 image 맞춤 query가 되도록 학습한 것이죠. 그래서 이 cc는 아래 식6과 같이 생성됩니다.
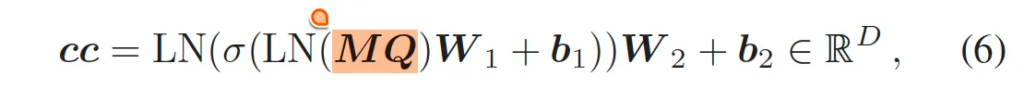
여기서 중요한 것은, 한 번 학습이 완료 됐다면, meta query는 바뀌지 않는다는 것이겠죠. 이로써 CLIP text encoder를 사용한 offline 추론이 가능한 것입니다. 이로써 보다 inference time도 줄일 수 있으며 real-world 측면에 좀 더 적합하겠죠.
Bimodal Similarity Matching
이 BSM 과정은 기존 cc를 생성할 때 image를 사용했었는데, 이를 meta query로 대체함으로써 image 정보와 text embedding에 반영되지 안음을 고려하여 설계된 추가 과정이라고 보면 되겠는데요.
text encoder output t_{out}와 global image-lebel feature \bar{I}가 주어졌을 때 먼저 아래 식7과 같이 코사인 유사도를 계산하게 됩니다.
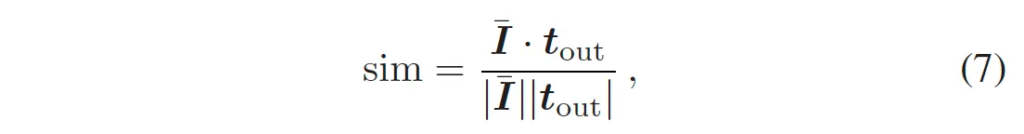
이렇게 계산된 sim은 text embedding에 얼마만큼 양의 visual modal 정보를 합칠건지에 직접적으로 사용되게 되는데요,
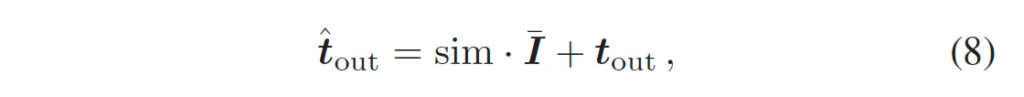
위 식8과 같이 weighted sum하는데 가중치로 사용하였습니다. 이렇게 나오게 된 \hat{t}_{out}은 새로운 text encoder output으로써 입력 영상에 따른 image feature를 암시적으로 담고 있는 feature로 볼 수 있겠죠. 이렇게 뽑아진 output을 가지고 아래 visual prompt generator와 instance-language matching 과정에서 사용하게 됩니다.
2.2.4. Visual Prompt Generator
다음으로 저자가 제안한 visual prompt generator입니다. 이는 CLIP image encoder를 타고 추출한 globality image embeddings으로부터 fine-grained한 embedding을추출해내는 모듈입니다. 구체적으로 text feature로부터 visual feature로 semantic한 정보를 propagate하기 위한 모듈이라고 보면 되겠습니다.
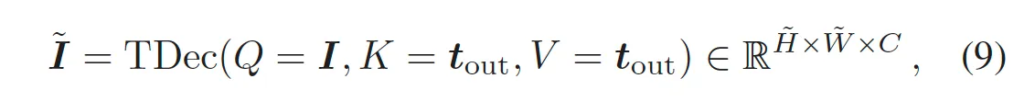
식 9과 같이 image embedding을 쿼리로 두고 text embedding을 key, value로 두어 cross attention하는 것이 그 전부입니다. 즉, 이미지에서 text와 연관된 부분에 좀 더 집중하도록 한 것입니다. 이렇게 생성한 visual prompt \tilde{I}는 원래의 image embedding과 더해져 text-aware locality embedding \hat{I}가 됩니다.
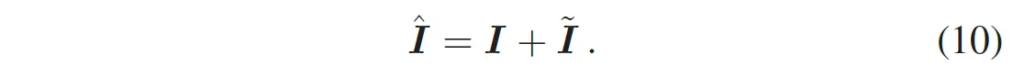
2.2.5. Instance-Language Matching
마지막으로 instance-language matching은 text encoder를 타고 나온 text embedding과 방금 생성한 locality embedding의 text instance를 연결하는 과정이라고 보시면 됩니다. 쉽게 말해 이 최종적으로 나온 image feature에서 text가 있는 특정 영역과 text embedding을 matching하는 것이구요, 이과정을 통해 모델이 이미지 내에 text가 위치한 부분을 더 명확하게 찾도록 학습하는 것입니다. 이 auxilarity task를 통해 clip을 사용하여 text detection, spotting 성능을 높이고자 한 것이죠.
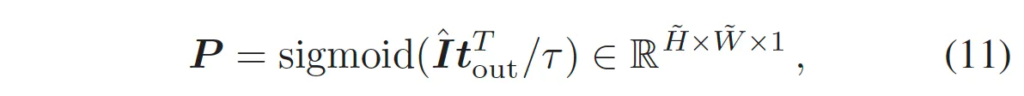
이 matching과정은 식9에서 볼 수 있듯이 우선 두 embedding간의 내적을 한 후 sigmoid 함수를 통해 이 binary score map P을 생성해 내게 됩니다.이렇게 뽑힌 binary score map은 text instance가 존재하는지 나타내는 나타내는 map이겠고, 이후 gt text segmentation map과의 binary cross entropy loss를 통해 학습되게 됩니다.
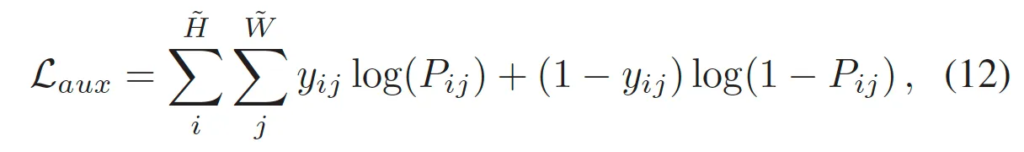
이 과정을 통해서 모델이 영상 내에 위치하고 있는 text 영역을 좀 더 정확하게 구분할 수 있게 되겠죠.
2.3. Optimization
최종적인 loss 함수는 아래 식 13과 같습니다.
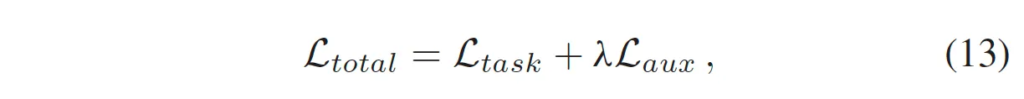
방금 위에서 정의한 aux loss와 기존 detection model(어떤 모델이든 상관 X)의 detection loss를 가져와서 가중합한 것이 되겠습니다.
3. Experiments
3.1. Cooperation With Existing Spotter Methods
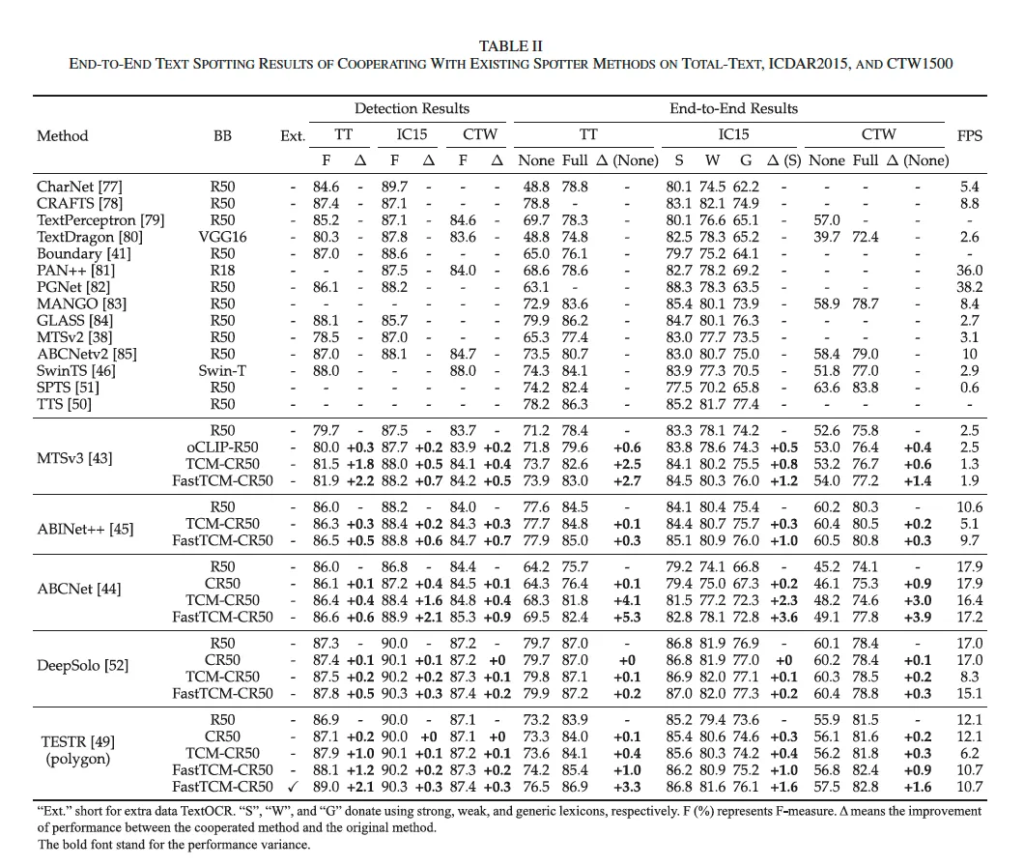
이제 실험 파트입니다. 먼저, 저자가 이전에 제안했언 TCM-CR50과 이번에 제안한 FastTCM-CR50을 붙였을 때 혹은 다른 clip을 사용한 백본 oCLIP-R50을 현존하는 spotter에 붙였을 때의 성능을 비교해볼 수 있겠죠. 결과는 위 표 2에서 확인할 수 있습니다. 구분선 맨 위에 방법론들은 그냥 기존 저자가 제안한 백본을 붙이지 않은 바닐라 방법론들이구요. MTSv3, ABINet++, ABCNet, DeepSOlo, TESTR 이렇게 다섯 개의 방법론에 제안된 백본을 붙인 것을 확인할 수 있습니다. 먼저 detection 성능만을 보았을 때는 이전에 제안되었던 TCM-CR50을 베이스라인 방법론들에 붙였을 때는 TT 데이터셋에서 0.2%에서 1.8% F-measure 범위 내의 성능 향상을 보였었는데요. IC15나 CTW 데이터셋에서도 일관성있는 성능 향상을 보이고 있습니다. 본 논문에서 제안된 FastTCM-CR50을 붙였을 때의 성능은 평균적으로 TCM-CR50과 비교해보았을 때 0.2% 더 높은 성능 향상을 보이며 유사한 속도 향상을 보입니다. 이로써 FastTCM-CR50이 보다 효율성 측면에서 낫다고 볼 수 있겠죠.
또, e2e spotting 결과를 보았을 때도 TCM-CR50은 모든 데이터셋에서 일관성있는 성능 향상을 보이고 있습니다. 특히, IC15 데이터셋의 strong lexicon에서, TCM-CR50을 기존 방법론인 MTSv3, ABINet++, ABCNet, DeepSolo, TESTR에 백본으로 사용될 경우 각각 0.8, 0.3, 2.3, 0.1, 0.4의 성능 향상을 보여줍니다. TT와 CTW 데이터셋에서도 유사한 성능 향상이 나타나, TCM-CR50이 기존 scene text detector와 spotter 모두의 성능을 효과적으로 향상시킨다는 점을 시사합니다. 한편, TCM-CR50 대신 FastTCM-CR50을 적용했을 경우, baseline 방법론 대비 평균적으로 1.5%, TCM-CR50 대비 평균적으로 0.55% 정도 더 성능 향상을 보입니다. 또, FastTCM-CR50의 추론 속도는 약 46.4% 향상되어, 성능과 효율성 모두에서 우위를 보이고 있네요. 추론 속도가 거의 50% 향상된 점이 clip text encoder를 offline으로 추론할 수 있음으로써 생긴 것 같은데 이만큼이나 향상됐다는 점이 인상적인 것 같습니다.
3.2. Few-Shot Training Ability
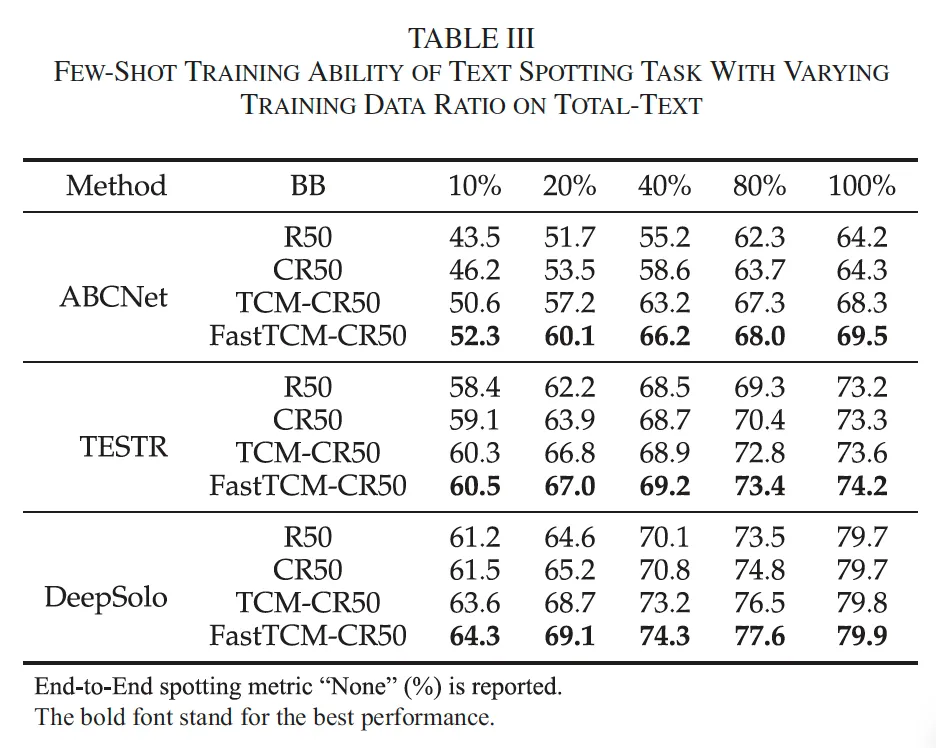
다음으로, text spotting의 few-shot 학습 실험 결과를 살펴보겠습니다. 위 표3에 나와 있듯이, ABCNet, TESTR, DeepSolo를 TT 데이터셋에서 few-shot 학습 실험을 수행했는데요. . 저자가 말하기를 spotting에서 recognition task는 제한된 데이터로 학습하는 경우 성능이 많이 떨어져서 적절한 초기화를 하기 위해 pretraining 단계를 수행했다고 하는데,,, 이는 본 논문에서 pretraining 없이 fine-tuning만 가능함으로써 어필한 간결함과는 좀 모순된 발언인 듯 합니다. 무튼, pre-training을 하고 tt의 학습 데이터셋을 다양한 비율로 나눠서 few-shot 학습을 수행했습니다.
실험 결과, TCM-CR50이랑 FastTCM-CR50은 DB-R50과 DB-CR50 대비 더 좋은 성능을 보이고 있으며 특히 본 논문에서 제안된 FastTCM의 경우 baseline 대비 거의 5% 정도의 성능 향상을 보이고 있다는 점을 주목해볼 만 한 것 같네요.
3.3. Ablation Studies
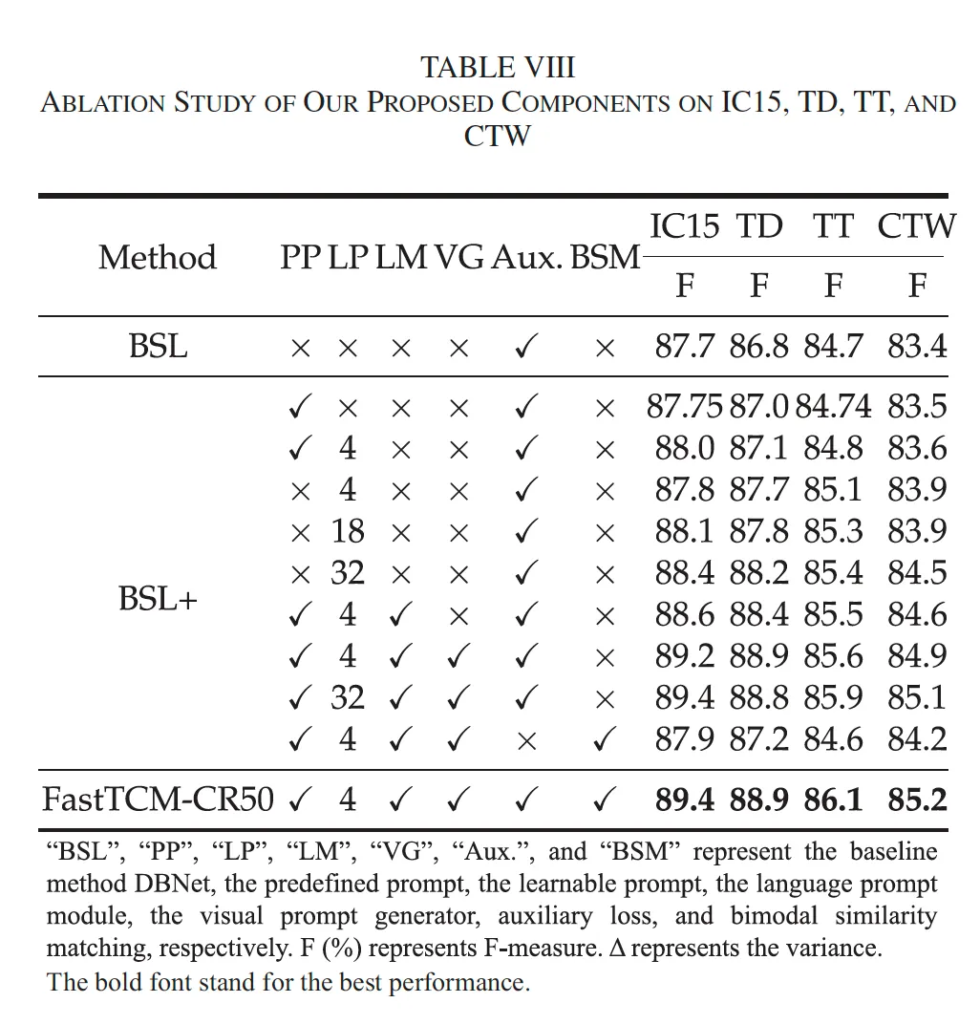
마지막으로 ablation study 살펴보고 마무리하도록 하겠습니다. 물론 제안된 pp나 lp, lm, vg 등을 넣었을 때 대체로 성능이 드라마틱하지는 않지만 조금씩 상승하는 편입니다. 개인적으로 궁금했던 것은 auxilarity loss를 뺐을 때와 넣었을 떄의 성능 차이였는데, 다른 변수들을 완전히 통힐하고 auxilarity loss를 제거했을 경우는 table에 나와있지 않아 아쉬운 것 같습니다. BSL+의 마지막 열이 Aux가 없는 유일한 경우인데 성능이 거의 baseline과 유사, 혹은 TT에서는 0.1%의 성능 하락을 보이고 있는 만큼 auxilarity loss가 없는 경우에는 성능이 많이 떨어지는 것 같긴 합니다만, BSM이 함께 들어가 있어서 정확히 알기는 어려운 것 같네요.
안녕하세요. 좋은 리뷰 감사합니다.
리뷰를 읽으면서 CLIP 모델을 spotting task에 적용함으로써 이전에는 pretraining→fine-tuning 투스텝으로 수행되던 task를 단 한 번의 fine-tuning으로 학습할 수 있는 새로운 백본을 제안한 것으로 이해했는데요, 혹시 CLIP 이외의 다른 image-text 모델로 실험한 결과는 없는 것인지 궁금합니다.
또, 인트로에서 언급해주신 다른 pre-training 모델들 가령 fig2의 (a) (b)에 해당하는 모델들과의 직접적인 비교는 없는 것인가요? 제안한 모델 이름이 Fast가 들어가는 것인만큼 기존 clip 모델을 사용한 선행 연구들과의 추론 속도 관점에서 리포팅된 table은 없었는지 궁금합니다 !
감사합니다.
안녕하세요. 댓글 감사합니다.
1. 넵 CLIP 이외의 다른 image-text 모델로 실험한 결과는 없습니다. FastTCM-CR50이라는 이름에서 알 수 있듯이 오로지 CLIP-ResNet50 기반 모델만 실험한 것 같습니다.
2. 넵 다른 pre-training 모델들과의 비교 table이 존재합니다. 제가 따로 본문에서 언급하지는 않았지만 DBNet을 베이스 모델로 삼아 기존 pre-training 방식인 STKM이나 VLPT, oCLIP 모델을 붙였을때의 결과도 함께 비교하고 있는데요. 실험 결과, 별도의 pretext task 없이 백본만 FastTCM-CR50만 변경하기만 하더라도 TT 데이터셋을 제외한 나머지 모든 데이터셋(IC15, TD, CTW)에서 SOTA를 달성하고 있습니다.
3. 넵 추론 속도 관련에 대한 비교는 리뷰의 Fig1에서도 볼 수 있듯이 기존 TCM-CR50에 비해 FastTCM-CR50이 약 50% 더 추론 속도가 빠름을 확인할 수 있습니다. 하지만, 다른 CLIP 기반 모델들과의 직접적인 속도 비교는 따로 테이블이 없네요.
좋은 리뷰 감사합니다.
CLIP으로 scene text spotting을 수행하기 위해 다양한 요소를 뭍인 것 같은데요, clip은 image instance와 text prompt를 활용한 contrastive learning을 통해 학습하다보니 detection에 중요한 local 정보가 부족할 것으로 생각됩니다. text sptting에서는 scene에 있는 러 text를 찾아야 하기에 detection 수행을 sub-region 인식 능력이 중요하다고 생각되는데요, 논문에서 GLIP이나 regionCLIP과 같은 dense prediction task를 염두하여 제안된 방법론들이 아닌 CLIP을 사용한 이유가 있나요??
댓글 감사합니다.
논문에서는 명시적으로 GLIP이나 regionCLIP을 두고 CLIP을 사용한 이유에 대해서는 언급하고 있지 않습니다.
대신 CLIP의 부족한 local 정보 문제는 제안된 Visual Prompt Generator나, Instance-Language Matching, Auxiliary Segmentation Loss를 통해 해결하고자 한 것으로 볼 수 있습니다.
안녕하세요 윤서님 좋은 리뷰 감사합니다.
Spotting 테스크에서 CLIP을 사용하면 대규모의 어휘에서 학습된 모델이기에 특정 데이터셋에 의존하지 않고도 다양한 언어와 단어를 탐지할 수 있을 것 같다는 생각이 들었습니다. 하지만, 단순히 CLIP을 가져다 쓰는 것이 조금의 성능 향상만을 보였고 특정 task에서는 최악의 결과를 보이기도 했다하셨는데 이러한 결과가 나타난 원인은 무엇이라고 생각하시나요? CLIP 모델이 세부적인 정보나 작은 영역을 구분하는 능력이 떨어져서인가요? 윤서님의 개인적인 견해가 궁금합니다.
감사합니다.
안녕하세요. 댓글 감사합니다.
리뷰에서 언급한 특정 task는 aerial object detection과 같은 domain을 말한 것이었는데요. 의철님이 적어주신 것처럼 CLIP은 이미지 전체와 문장 전체 간의 유사도를 잘 판단하도록 학습된 모델이기에, object들이 밀집되어 있고, 크기가 작은데다가, 각각의 위치 및 회전 정보까지 예측해야 하는 aerial od와 같은 task에는 성능이 떨어질 수 있습니다. 이런 task를 수행하기 위해 모델의 region awareness가 요구되는데, CLIP은 구조적으로 지역적인 정보 추출에 한계가 있기 때문인 것 같습니다.