안녕하세요, 쉰번째 x-review 입니다. 이번 논문은 ECCV 2024년도에 게재된 OV3D 논문인데, 처음으로 3D detection을 위해 제대로 LLM을 활용한 논문인 것 같습니다. 직접적으로 LLM을 3D detection에 처음 적용한 논문이라 굉장히 재밌게 읽었습니다.
그럼 바로 리뷰 시작하겠습니다 !

1. Introduction
object detection(OD) task는 일반적으로 학습에 라벨링된 데이터를 사용하면서 inference 시에도 정해진 클래스 안에서의 물체만을 검출한다는 한계가 있죠. 그래서 ov 방식으로 문제를 해결하려 하지만 이는 아직 2D에서만 활발히 이루어지고 있고 3D 포인트 클라우드를 대상으로는 연구가 비교적 덜 발전한 것은 사실 입니다. 그래서 본 논문에서는 라이다 기반의 OVD를 수행하는데, 이는 inference 단계에서 오로지 포인트만을 사용하게 됩니다.
이미지에 비해 포인트 클라우드에서 OVD을 수행하는데는 아무래도 더 큰 어려움이 있습니다. 먼저 포인트는 굉장히 dense한 이미지에 비해 sparse하다는 특징을 가져 물체의 디테일한 정보, 가령 텍스처 정보나 컬러 정보 등을 놓치기 쉽습니다. 또한 포인트라는 데이터는 취득하는 환경에 따라 매우 영향을 많이 받기 때문에 포인트에 노이즈가 다수 존재할 수 있습니다. 그렇기 때문에 포인트 데이터에서 하나의 물체에 대한 포인트 정보만을 기반으로 물체를 찾는다는 것은 난이도가 높으며, 여기서 저자는 포인트 기반의 OVD에서는 환경적인 정보가 중요하다는 것을 강조하게 됩니다.
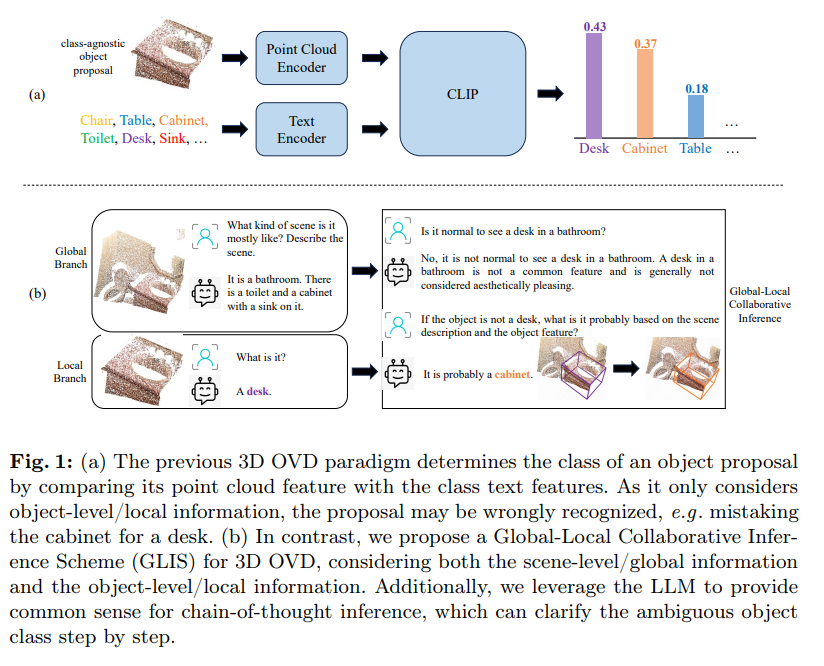
그러나 기존에 포인트 기반 OVD SOTA 모델들은 물체 레벨의 feature를 구성하는데 집중하며 아쉽게도 scene 레벨의 정보를 활용하지는 못하고 있다고 합니다. Fig.1(a)와 같이 물체 레벨의 feature를 추출하고, 그에 맞게 클래스 라벨을 텍스트 feature로 하는 프레임워크가 대부분이죠. 이런 파이프라인이 로컬한 물체 정보만을 집중적으로 고려하면서 앞서 말했던 포인트의 sparse함과 노이즈함에 크게 영향을 받아 물체 검출에 어려움을 겪는다는 것 입니다.
이러한 문제를 해결하기 위해 본 논문에서는 Global-Local Collaborative Inference Scheme(GLIS)라는 글로벌한 전체 scene 정보와 로컬한 물체 레벨의 정보를 모두 고려할 수 있는 OVD 방식을 제안합니다. 여기에 LLM을 CoT inference를 위한 상식을 제공하기 위해 사용하게 된다고 합니다. LLM으로부터 얻는 사전 지식은 로컬한 물체 feature를 명확하게 하는데 도움을 줄 수 있으며 CoT는 모델이 검출 결과에 대해 단계별로 구체화할 수 있도록 도와주게 됩니다. Fig.1를 예시로 보면 캐비넷이라는 물체를 (a)와 (b)의 로컬 브랜치에서는 모두 desk로 잘못 예측한 것을 확인할 수 있습니다. 그러나 여기서 다른 점은 (b), 즉 본 논문의 GLIS는 글로벌한 scene에서 얻은 정보를 통해 이런 로컬 브랜치에서의 오류를 바로잡을 수 있다는 것 입니다. 왜냐하면 장면 레벨로 봤을 때 desk로 잘못 예측한 물체가 존재하는 공간은 욕실일는 것을 알 수 있고, 공간이 욕실인 경우에 LLM이 책상이 욕실에 존재할 가능성이 낮다는 것을 인지함으로써 desk라는 물체 로컬 proposal이 잘못됐다는 것을 알려줄 수 있기 때문입니다. 따라서 GLIS는 inference 프레임워크 안에 글로벌과 로컬 정보를 모두 활용하여 잘못 분류된 desk라는 클래스를 캐비넷이라는 올바른 클래스로 재분류할 수 있습니다.
GLIS는 글로벌-로컬 정보를 모두 활용한 inference를 가능하게 하기 위해 두 브랜치를 각각 설계하였다고 합니다. 먼저 로컬 브랜치는 학습을 위한 pseudo 라벨을 생성하는 Reflected Pseudo Labels Generation (RPLG)과 로컬 영역 안에서 최대한 정확한 propsal을 생성하기 위해 Background-Aware Object Localization (BAOL)로 구성되어 있습니다. 그리고 글로벌 브랜치는 MiniGPT-v2에 따라 scene에 대한 description을 생성할 수 있도록 모델을 생성하였다고 합니다. 자세한 내용은 방법론에서 살펴보고 여기서 본 논문의 main contribution을 정리하면 다음과 같습니다.
- 글로벌 scene 정보와 로컬한 물체 정보의 상호작용을 처음으로 시도한 최초의 포인트 기반 OVD 방법론인 GLIS 제안
- 포인트 기반 OVD에 LLM을 도입하여 COT를 수행하였으며, LLM에서 얻은 상식 정보를 통해 검출 결과를 개선
- 학습과 테스트에서 포인트의 영향을 완화하기 위한 RPLG, BAOL 모듈 추가적으로 설계
2. Methods
2.1. Overview
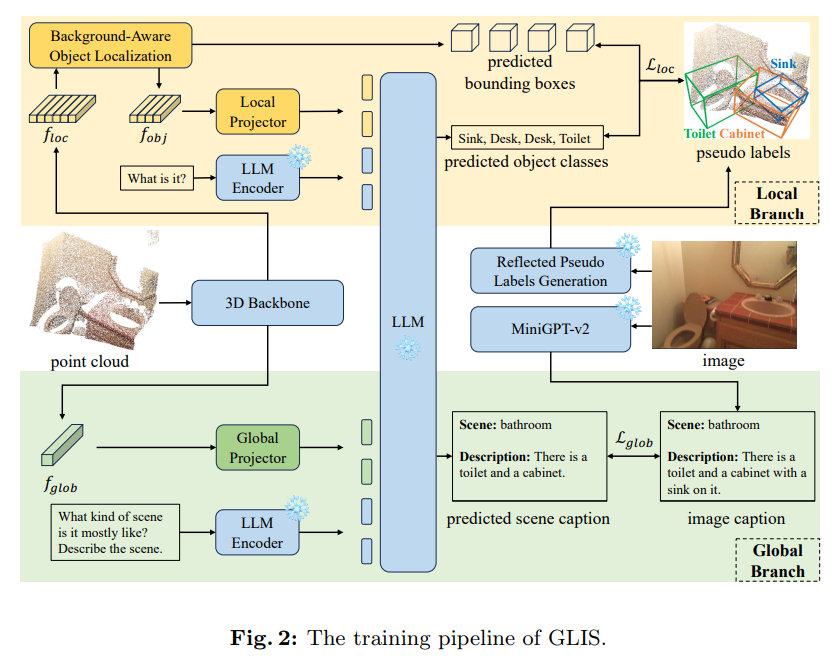
GLIS는 학습과 inference 파이프라인으로 나누어 구성되어 있는데, Fig.2는 그 중 학습 파이프라인을 나타내고 있습니다.
먼저 포인트를 3D 백본의 입력으로 해서 로컬 feature f_{loc}와 클로벌 feature f_{glob}를 추출합니다. unsupervise로 수행하는 OVD task라 모델의 supervision이 부족하기 때문에 두 브랜치는 모두 모델 하습과 pseudo 라벨 생성 과정이 포함되어 있습니다.
로컬 브랜치는 BAOL 모듈을 통해 바운딩 박스를, LLM에 의해 물체 클래스를 예측합니다. RPLG 모듈은 pseudo 라벨을 생성하기 위해 설계한 모듈인데, 생성한 라벨을 loss를 계산하기 위한 supervision으로 사용하는 것이죠. 글로벌 브랜치는 scene에 대한 캡션을 LLM을 통해 생성하는데, 이 캡션은 MiniGPT-v2를 통해 이미지 캡션을 가지고 만들어진다고 합니다.
inference 파이프라인은 간략하게 설명하면, 먼저 LLM이 scene에 대한 설명과 scene의 유형에 대해 예측을 합니다. 그러고 나서 local feature로부터 만들어지는 초기 검출 결과가 있는데, 이를 COT 프롬프트를 사용하여 refine하는 과정을 거치게 됩니다.
아래 섹션에서 학습부터 inference 파이프라인까지 자세하게 살펴보도록 하겠습니다.
2.2. Local Object Localization and Classification
로컬 브랜치는 초기 검출 결과를 생성하는 역할을 하는데요, 먼저 BAOL 모듈은 물체 proposal \{b_i, f^i_{obj}\}^{N_{obj}}_{i=1}을 f_{loc}로부터 생성합니다.
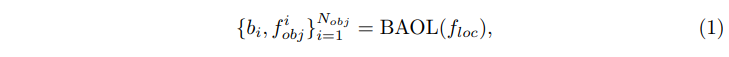
- b_i : i번째 물체 바운딩 박스
- f^i_{obj} : i번째 물체 feature
- N_{obj} : 물체의 수
물체의 localization을 BAOL로 수행했다면, 반대로 classification은 LLM에 의해 식(2)와 같이 예측합니다.
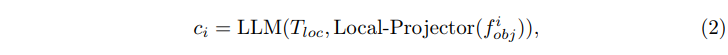
- c_i : i번째 물체의 예측된 클래스
- T_{loc} : LLM 프롬프트 ( 본 논문에서는 “What is it?”을 사용)
- Local Projector : f^i_{obj}를 LLM 임베딩 공간에 align 맞추는 linear layer
RPLG 모듈에서 생성하는 pseudo 라벨을 통해 위의 BAOL과 Local Projector를 학습할 수 있습니다.
Reflected Pseudo Labels Generation (RPLG)
이전 연구에서는 OVD의 pseudo 라벨 생성을 위해 2D OV 검출기로 이미지에서 먼저 2D pseudo 라벨을 생성하였습니다. 그 다음에 그 pseudo 라벨을 3D로 projection하여 변환하는 과정을 거쳤는데요, 본 논문에서는 마냥 2D OV 검출기의 검출 성능을 신뢰하지는 않았나 봅니다. 잘못된 라벨을 만들어 오히려 3D OVD 학습에 혼란을 줄 수도 있을 것이라고 이야기하며, 이를 해결하기 위해 pseudo 라벨의 노이즈를 줄이기 위한 RPLG 모듈을 설계하였습니다.
먼저 Detectron2로 2D 라벨을 먼저 이미지에서 생성하고, CLIP을 생성한 라벨이 옳은지 체크하는 역할로 사용하였다고 합니다. 좀 더 자세하게 설명하면, Detectron2에서 생성하는 라벨을 초기 2D 라벨로 정의하고, 이미지 안에서 물체 바운딩 박스를 크기만큼 crop하여 물체 레벨로 패치를 만듭니다. 그 다음 CLIP으로 라벨이 맞는치 체크하기 위해 아래 두 가지 프롬프트 템플릿을 사용하였는데요,
T^+ (class) : ”This is a {class}.”,
T^- (class) : ”This is not a {class}”.
이 템플릿은 아까 만든 패치와 클래스와 함께 CLIP에 넣어 식(3)과 같이 confidence score를 계산하게 됩니다.
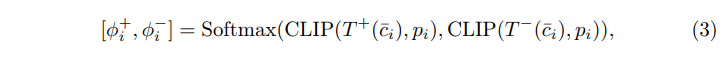
- \phi^+_i : i번째 패치 p_i가 i번째 클래스에 속하는지에 대한 confidence scroe (\phi^-_i도 반대로 동일)
여기서 사전정의된 임계값인 \phi_{CLIP}보다 \phi^+_i가 높은 라벨을 선택하여 새로운 2D 라벨인 \{\tilde{b}^i_{2D}, \tilde{c_i}\}^{\tilde{N}}_{i=1}를 생성하는 것 입니다. 이 2D 라벨이 이제 3D로 projection되면 최종적으로 3D pseudo 라벨인 \{\tilde{b}_i, \tilde{c}_i\}^{\tilde{N}}_{i=1}가 만들어집니다.
Background-Aware Object Loaclization (BAOL)
앞서 BAOL 모듈을 통해 바운딩 박스를 예측한다고 했는데, 포인트에 내재하는 노이즈 때문에 검출기 모델이 물체의 전경과 배경을 구분하지 못하고 잘못된 물체 proposal을 생성할 수가 있습니다. 이를 방지하면서 정확한 proposal을 만들기 위해 제안한 것이 BAOL이죠.
prediction head를 통해 f_{loc}로부터 class agnostic한 물체 proposal \{\hat{b}_i, \hat{o}_i\}^{N_q}_{i=1}이 만들어집니다. 여기서 \hat{o}_i가 i번째 proposal에 대한 confidence인데, 그 중 \phi_{obj}라는 임계값보다 낮다면 그 proposal은 제거되고 남은 proposal들이 검출 결과인 \{b_i, o_i\}^{N_{obj}}_{i=1}로 남게 됩니다.
여기서 만약 보통의 close set detection이라면 confidence 예측이 GT 라벨을 통해 학습될 수 있겠죠. 그러나 지금은 OVD 세팅이기 때문에 supervision을 수동으로 할당해주어야 합니다. 그래서 물체 proposal과 RPLG에서 생성한 pseudo 라벨 사이에 식(4)와 같이 이분 매칭을 수행하여 모든 proposal에 라벨을 할당해줍니다.
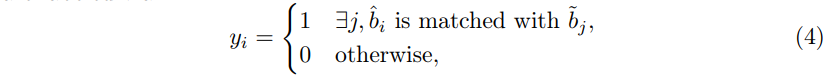
- y_i : 1이라면 i번째 positive가 positive, 0이라면 negative 샘플임을 의미
그런데 이 과정까지에서의 라벨 할당은 두 가지 상황에서 부정확할 수 있는데요, 첫번째는 proposal과 라벨이 매칭되긴 했으나 IoU가 낮은 경우이고 두번째는 서로 다른 두 proposal이 동일한 물체를 나타내는데 그 중 하나만 foreground라고 할당되는 경우라고 합니다. 이렇게 발생할 수 있는 예외 상황들을 해결하기 위해 라벨링을 위한 규칙을 추가적으로 정하였다고 하네요.
먼저 첫번째 예외 사항에 대해서는, 일치하는 proposal이 \phi_{low}보다도 낮으면 매칭되는 라벨이 있다하더라도 negative 샘플로 지정되도록 하였습니다. 두번째 예외 사항을 처리하기 위해서는 두 propoal의 IoU가 \phi_{high}보다 높으면 둘 중 하나만 positive라고 할당되었더라도 두 proposal 모두 다시 positive로 할당되도록 하였습니다. 다시 말해서 추가적인 IoU 임계값을 설정하여 예외 사항을 처리한 것이라고 볼 수 있습니다.
2.3. Global Scene Understanding and Description
로컬 브랜치에 대해서는 모두 살펴보았고, 이제 글로벌 브랜치에 대해 설명드리려고 합니다.
우선 글로벌 브랜치의 역할은 scene에 대한 description을 f_{glob}를 통해 생성하는 것이라고 설명할 수 있습니다. 구체적으로는 아래와 같은 prompt를 통해 LLM을 사용하는 데요,
T_{glob} : ”What kind of scene is it mostly like? Describe the scene.”
여기에 추가적으로 f_{glob}를 LLM 임베딩 공간과 align 맞추기 위해 global projector를 식(5)와 같이 사용합니다.
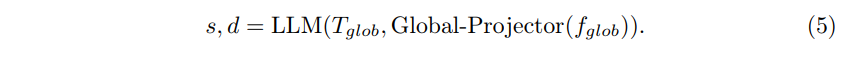
2D 이미지 기반의 MiniGPT-v2를 사용해서 scene의 유형에 대한 라벨인 \tilde{s}과 scene description 라벨인 \tilde{d}를 생성하여 이를 LLM의 대답과의 loss 계산에 사용하게 됩니다.
2.4. Global-Local Collaborative Inference with LLM
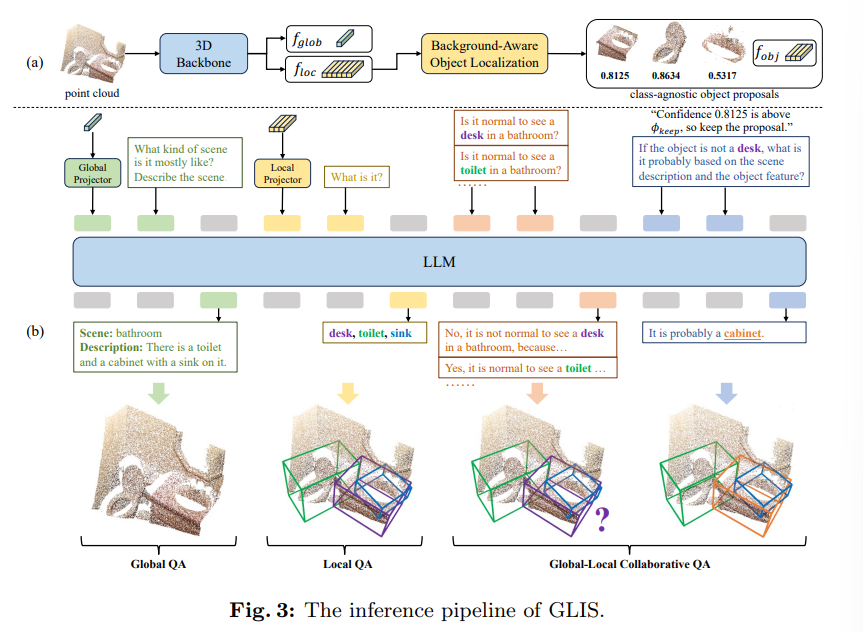
해당 섹션에서는 inference 파이프라인을 살펴보도록 하겠습니다.
먼저 Fig.3(a)와 같이 글로벌 feature와 로컬 feature가 3D 백본으로부터 추출됩니다. 그 다음 class agnostic한 물체 proposal, confidence score, 그리고 그 proposal에 대한 3D feature가 BAOL 모듈을 통해 생성되죠.
추출된 로컬, 글로벌 정보가 있는데, 여기서 검출 결과를 refinement하기 위해 global-local collaborative inference (GLCI)를 LLM과 함께 수행하게 됩니다. 일반적으로 Fig.3(b)와 같이 COT는 LLM의 inference를 가이드하기 위해 많이 사용된다고 하는데요, 본 논문에서 전체 inference 과정은 Global QA, Local QA, 그리고 Global-Local Collaborative QA 이렇게 3단계로 나누어집니다.
Global QA는 LLM에게 scene의 유형을 예측하고, 글로벌 feature를 기반으로 scene의 description을 생성하도록 요청합니다. 반대로 Local QA는 object feature를 사용해서 class agnostic한 물체 proposal에 클래스를 예측합니다.
두 QA가 끝나고 나오는 검출 결과가 초기 검출 결과 입니다. 이 결과는 다음 Global-Local collaborative QA를 통해 refinement 되는 것이죠. 각각의 예측된 클래스가 있으면 ”Is it normal to see a {class} in a {scene type}?”라는 프롬프트 템플릿을 가지고 클래스가 합리적인지를 판단합니다.
만약에 클래스 c가 예측된 scene 유형 안에 있을 합리적인 클래스가 아니라면 추가적인 검토를 필요로 합니다. 구체적으로 비합리적인 객체라고 답변을 받았는데, confidence score가 임계값 \phi_{keep}=0.75 미만이라면 제거됩니다. 그러나 만약 Fig.3의 예시와 같이 책상이라는 물체 proposal이 confidence score가 0.75 이상으로 보존되었을 경우에는 올바른 클래스로 정정하기 위해 “If the object is not a desk, what is it probably based on the scene description and the object feature?”라는 추가적인 프롬프트를 LLM에 던집니다. 그러면 LLM은 로컬, 글로벌 정보를 모두 통합하여 욕실 안에는 책상이 있을 확률이 굉장히 적다는 상식이 있기 때문에 책상이 아닌 캐비넷이라는 올바른 클래스를 답변할 수 있게 되어 클래스를 refinement가 가능합니다.
2.5. Training Objectives
마지막으로 학습 loss는 bounding box regression loss \mathcal{L}_{bbox}, confidence 예측 loss \mathcal{L}_{conf}, 물체 classification loss \mathcal{L}_{cls}, 그리고 scene understanding loss \mathcal{L}_{scene}, 이렇게 4개의 loss로 이루어져 있습니다.
그 중 regression loss는 3DETR이라는 3D detection 검출기에서 사용하는 loss를 그대로 식(6)과 같이 사용하였다고 하네요.
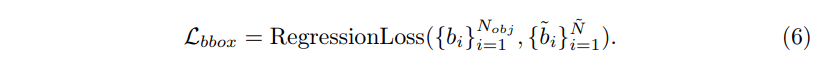
\mathcal{L}_{conf}는 식(7)과 같이 정의되는데,
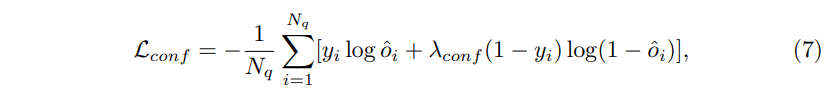
- \lambda_{conf} : balanced factor
물체 클래스가 LLM에 의해 예측되기 때문에 \mathcal{cls}는 라벨 텍스트 토큰의 확률을 최대화하는 방향으로 계산하게 됩니다. 구체적으로, 라벨 텍스트가 t = (w_2, w_2, …, w_l)과 같이 sequence한 토큰이고 각각에 토큰에 대해 예측된 확률이 p(t) = [p(w_1), p(w_2), …, (p(w_l)]이라고 하면 text loss는 식(8)과 같이 정의됩니다.
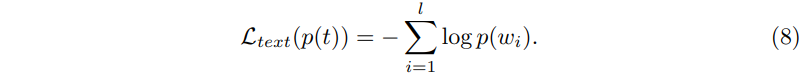
이를 사용해서 \mathcal{L}_{cls}는 식(9)와 같이 정의할 수 있습니다.
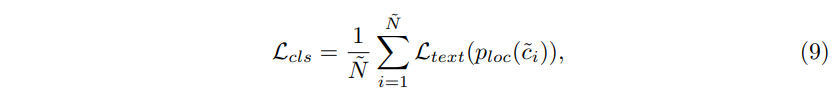
- p_{loc} : 로컬 브랜치에서 LLM이 예측한 토큰 가능성 확률
비슷하게 \mathcal{L}_{scene}도 식(10)과 같이 글로벌 브랜치에 대해 정의할 수 있습니다.
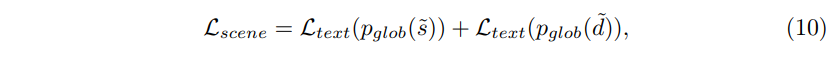
- p_{glob} : 글로벌 브랜치에서 LLM이 예측한 토큰 가능성 확률
classification loss와 다른 점이라고 하면 토큰 확률에 로컬 브랜치에서가 아니라 글로벌 브랜치에서의 가능성이 들어간 것이겠네요.
이렇게 각각의 loss를 합친 전체 loss는 식(11)과 같습니다.
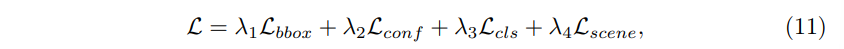
3. Experiments
데이터세은 SUN RGB-D와 ScanNetV2를 사용했으며, 이전 연구들과의 pair comparison을 위해 top 20개의 물체 / top 10개의 물체를 평가하는 방식 모두에 대해 평가(mAP^{20cls}_{25}, mAP^{10cls}_{25})하였다고 하네요.
3.1. Main Results
ScanNetV2
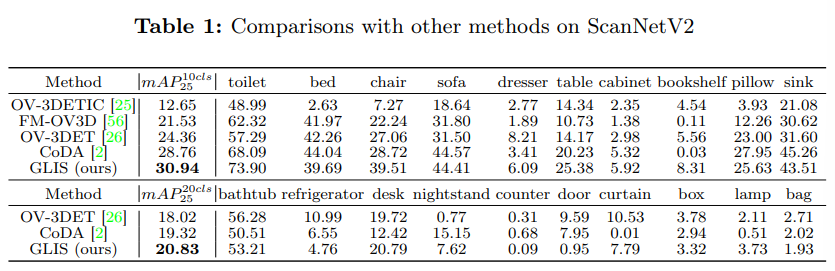
Tab.1을 우선 ScanNetV2에서의 실험 결과로 이전 sota 방법론인 CoDA와 비교했을 때 두 평가 기준에 대해서 모두 가장 높은 성능을 달성한 것을 확인할 수 있습니다. 세부적으로 클래스들에 대해서 봤을 때도 chair, toliet 그리고 table 등등의 주요 물체들에서 큰 성능 향상이 발생한 것을 알 수 있습니다.
SUN RGB-D
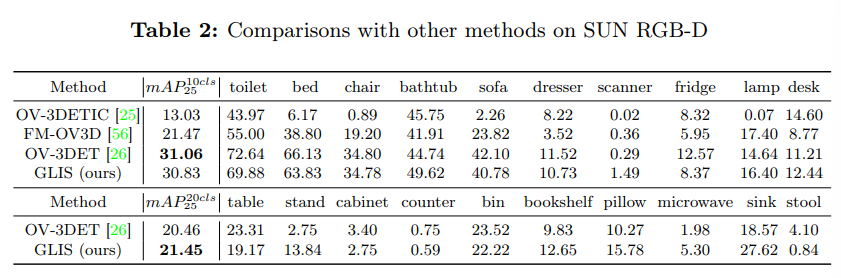
다음으로 SUN RGB-D에 대한 실험 결과로, 10개의 클래스에 대해서 평가했을 때는 이전 방법론인 OV-3DET 성능에 미치지 못하고 있습니다만, 저자는 비록 이전 sota를 넘지는 못했지만 거의 준하는 성능을 달했다고 말하고 있고 실제로도 약 0.2%의 성능 차이만 난다는 것을 확인할 수 있습니다. 또한 stand나 sink와 같이 원래 SUN RGB-D 데이터셋에서 빈번하게 등장하진 않아 메인 클래스는 아니었던 물체들에 대한 성능 향상을 보이며 scene 안에서 나타나는 모든 물체들에 대한 검출 능력을 강조할 수 있습니다.
3.2. Ablation Study
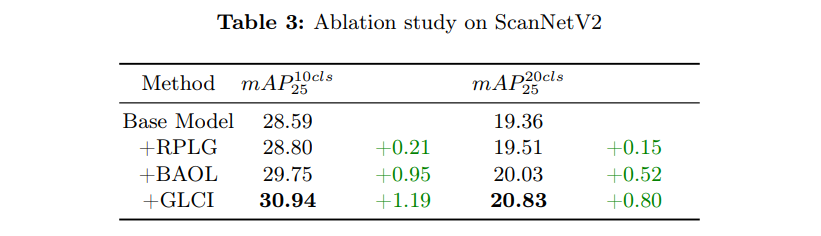
ScanNetV2로 수행한 ablation study 입니다.
pseudo 라벨을 Detectron2의 결과에 의존하며 BAOL에서 모든 로컬 feature가 object feature가 되고, Global inference를 수행하지 않는 Base Model 대비 각각의 모듈이 어떤 효과가 있는지를 비교하고 있습니다.
결과적으로 모두 성능 향상에 기여하고 있는데요, 먼저 RPLG는 MiniGPT-v2를 사용해서 Detectorn2의 잘못 검출된 결과를 찾아 pseudo 라벨의 퀄리티를 향상시킬 수 있습니다. BAOL은 포인트에 내재하는 노이즈를 고려하여 물체 proposal들에 대한 localization 성능을 향상시켰다고 볼 수 있습니다. 마지막으로 GLCI는 가장 큰 성능 향상을 가지고 온 부분인데요, 이러한 결과를 통해 로컬과 글로벌 정보를 모두 사용하여 scene의 유형을 파악하고 해당 scene과 포함되어 있는 물체들 사이의 유기 관계를 파악함으로써 검출 결과를 refinement하는 것의 효과가 크다는 것을 확인할 수 있습니다.
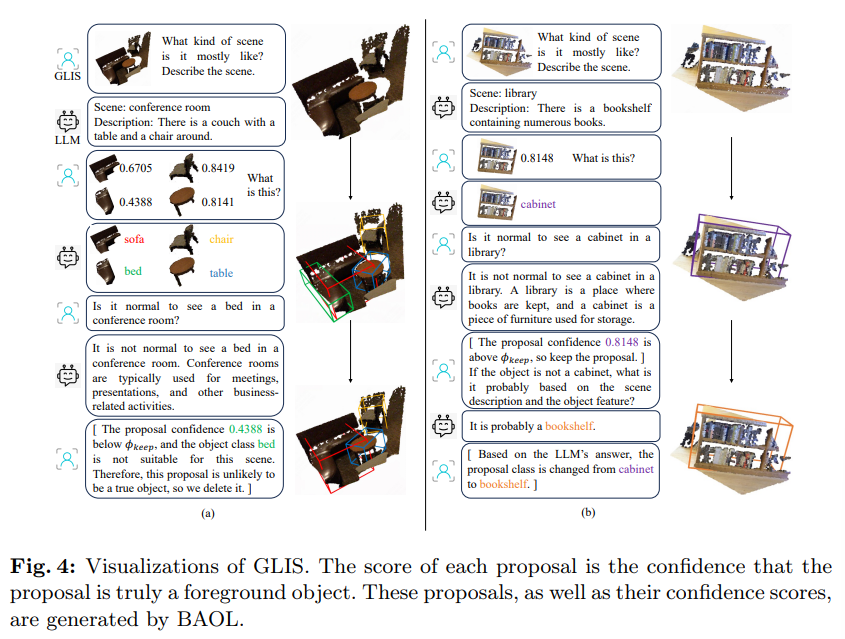
마지막으로 GLIS에 대한 visualization 결과를 보고 리뷰 마치도록 하겠습니다.
Fig.4는 GLIS와 LLM 사이의 대화를 보여주고 있는데요, 먼저 (a)를 보면 LLM은 scene을 global 정보를 통해 회의실로 인지하고 있죠. 그럼 GLIS에서 BAOL을 통해 예측한 4개의 class agnostic한 물체 propsal과 confidence score을 보여주며 LLM에게 물체 클래스를 예측하라고 합니다. 이렇게 하면 Global QA, Local QA까지 거쳐 LLM에 의한 초기 검출 결과를 얻는 것이 됩니다.
다음으로는 refinement하는 과정이 필요하니, global-local collaborative inference를 수행하겠죠. 예를 들어 ”Is it normal to see a bed in a conference room?”라고 LLM에게 물어보면 회의실이 침대가 있는 것은 일반적인 상식으로 옳지 않기 때문에 “It is not normal to see a bed in a conference room.”이라고 답하는 것 뿐만 아니라 그에 합당한 이유까지 답변하게 됩니다.
침대라는 클래스가 옳지 않다고 답변 받았으며 confidence score가 미리 정의한 0.75라는 임계값보다 못 미치는 0.4388이기 때문에 해당 결과는 제거할 수 있습니다. 이 예시를 통해서는 LLM이 잘못 검출된 물체를 상식을 통해 제거하는데 도움을 줄 수 있다는 것을 알 수 있습니다.
(b)는 조금 다른 예시인데요, 초기 검출 결과를 만드는 것 까지는 동일하지만 도서관에 캐비넷이 있다는 다소 비합리적인 검출 결과임에도 confidence score가 임계값을 넘어가는 높은 값을 가진다는 것 입니다. 그래서 (a) 예시와 같이 normal 하지 않다는 답변을 받고 바로 검출 결과를 제거하지 못하고 다시 한 번 추가적인 검토를 하게 되죠. 한번의 추가적인 검토를 통해 LLM은 비로소 캐비넷이 아닌 책장이라는 올바른 클래스를 답변하여 검출 결과를 refinement 할 수 있게 됩니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
local feature와 global feature를 처음 추출할 때 사용하는 3D 백본은 동일한 구조로 활용하는 것인가요 .. ? local과 global이라는 레벨로 feature를 구분할 수 있는 기준이 무엇인지 궁금합니다.
또한 LLM으로 얻은 클래스가 만약 임계값보다 confidence score가 높고 LLM에게 다시 질문하였을 때 scene의 유형과 관련있는 클래스라면 별도의 처리 없이 바로 올바른 클래스라고 여기게 되나요 ?? 관련이 없다고 판단되는 클래스를 처리하는 과정에 비해 비교적 간단한 과정으로 옳은 클래스를 결정하는 것 같아서 이러한 과정에서 발생할 에러에 대해서는 고려하지 않는지, LLM의 대답에 완전히 의존하게 되는 것인지 의문이 들어 질문 드립니다.
감사합니다.
안녕하세요, 리뷰 읽어주셔서 감사합니다.
1. 여기서 3D 백본이라고 하는 것은 단순한 PoinNet과 같은 백본 네트워크가 아니라 3DETR이라는 3D detection 프레임워크를 따랐다고 하는데요, 이를 미루어 보아 아마 전체 포인트에 대해서 추출한 feature를 global feature로 뽑아오고 grouping을 거친 feature을 local feature로 뽑아오지 않았을까 싶습니다.
2. 말씀하신대로 confidence score 자체도 높고 LLM이 scene과의 연관성을 따졌을 때 높은 연관성을 가진다고 판단하면 올바른 클래스라고 정의하게 됩니다. 명확하지 않은 클래스에 비해서는 검열하는 과정이 다소 간단하다고 느끼실 수도 있는데, 그래도 단번에 LLM의 대답을 수용하는 것이 아닌 처음 LLM이 classification한 클래스에 대해서 confidence score와 global scene과의 관계를 파악하는 단계를 거침으로써 신뢰성을 높이기 위한 과정을 거쳤다고 볼 수 있을 것 같습니다.
안녕하세요. 좋은 리뷰 감사합니다.
이제는 LLM을 사용하지 않는 Task가 있을 수 있을까?라는 생각이 들게 되는 논문이네요. 본 논문의 메인 contribution은 클래스 refinement인 것 같습니다. 해당 부분에서 질문이 있는데요. LLM을 통해 detect한 물체가 해당 scene에 있을 만한 물체인지 아닌지를 판단하는데, 회의실에 침대가 있는 비상식적인 것에는 “It is not normal to see a bed in a conference room.”와 답변한다고 이해하였습니다. 여기서 궁금한 점이 있는데, LLM의 output이 일정한 형식을 가지고 출력하게 되나요? 질문드리는 의도가 llm의 output이 not normal인지, normal인지 어떻게 판단하는지가 궁금합니다. 일정한 형식으로 나온다면 단순하게 처리해도 될거 같은데 not normal이라는 문장이 여러 형태로 출력해서 나오면 따로 처리해줘야 하지 않을까 싶어 질문드립니다.
감사합니다.
안녕하세요, 리뷰 읽어주셔서 감사합니다.
넵 말씀하신게 맞습니다. LLM의 출력은 딱 정해진 형식을 따르진 않지만, 대부분 응답에서 “not normal” 또는 “not common” 같은 표현이 포함됩니다. 논문에서는 이 출력들을 파싱해서 비정상 여부를 판단하는데, 다양한 표현이 나올 수 있다는 점을 고려해사 특정 키워드를 포함하는지를 찾게 됩니다. 즉, “not normal”, “unusual”, “unlikely” 등을 키워드로 하여 객체가 해당 장면에 적절한지 자동으로 판단하는 과정을 거칩니다.
감사합니다.
손건화 연구원님 좋은 리뷰 감사합니다.
포인트 정보가 놓치는 정보를 LLM을 통해 scene level의 정보를 추론하므로써 예측을 보완해주는 방법론을 제안한 것으로 이해하였습니다.
인트로에서 포인트라는 데이터는 취득하는 환경에 따라 매우 영향을 많이 받기 때문에 환경 정보를 고려하는 게 중요하다고 하였는데, 센서 정보나 데이터 촬영의 환경정보(조도 등의 정보)를 고려하는것은 아닌가요?
또한, CoT를 활용하여 모델의 검출 결과를 단계별로 구체화한다고 하였는데, Global QA와 Local QA를 병렬로 수행한 뒤 Global-Local QA를 수행하는 것으로 이해하였습니다. 해당 과정은 inference 과정에만 사용되는 것일까요?? pseudo lable을 생성할때 CoT 방식을 사용하지 않는 이유가 궁금합니다.
안녕하세요, 리뷰 읽어주셔서 감사합니다.
먼저 포인트 클라우드 데이터가 환경 변화에 민감하다고 언급한 것은 주로 장면의 복잡한 구조나 객체의 분포처럼 장면 자체의 환경을 의미하는 것이고, 센서의 조도, 날씨 같은 환경 정보나 센서 메타데이터는 별도로 고려하지 않습니다.
그리고 말씀하신 CoT 기반의 Global QA, Local QA, Global-Local QA는 모두 inference 단계에서 적용되는 과정이 맞습니다. pseudo label을 생성할 때는 여러 단계의 QA를 수행하지 않고, 직접적인 신뢰도 기반으로 라벨링을 진행합니다. 이는 CoT 방식이 inference 시 reasoning 품질 향상에는 효과적이지만, pseudo label 생성에는연산 복잡도나 일관성 때문에 적용하지 않는 것이라고 생각합니다.
감사합니다.
안녕하세요 건화님 좋은 리뷰 감사합니다.
Ablation study에서 RPLG를 추가한 결과로 기존 모델의 mAP가 28.59%에서 28.80%로 증가했다는 점을 들어 RPLG의 효과를 입증하고 있습니다. 하지만 0.21%의 성능 개선이 유의미한 차이라고 보기 어렵지 않나 생각이 듭니다. 오히려 RPLG가 CLIP과 같은 추가적인 모델을 사용해 라벨을 검증하기 때문에, 추가적인 cost가 든다고 생각되는데, 0.21%의 mAP 향상이 실제 모델의 성능 개선에 성능 향상에 의미가 있다고 생각하는지 건화님의 견해가 궁금합니다.
감사합니다.
안녕하세요, 리뷰 읽어주셔서 감사합니다.
말씀하신 것처럼 RPLG를 추가한 뒤의 결과가 성능 개선 폭이 크다고 보긴 어렵습니다.
다만 논문에서는 RPLG가 단순 성능의 향상 뿐만 아니라 라벨의 신뢰성과 일관성을 향상시키는 데 초점을 맞추고 있습니다.
리뷰에 넣진 않았지만 논문의 정성적 결과를 보면, CLIP 기반의 필터링 과정을 거친 라벨이 더 의미 있는 객체에 집중된다는 걸 확인할 수 있습니다. 즉, 약간의 성능 향상이지만 모델이 보다 고품질 라벨을 활용하도록 돕는 역할을 한다는데 있어 의미를 가지고 있는 것 같습니다. 물론 그에 따른 cost도 발생하기 때문에, 이 부분은 실제로 활용할 때 trade-off를 고려해야 할 것 같습니다.
감사합니다.