안녕하세요. 이번 주 X-Review에서는 23년도 CVPR에 게재된 Moment Retrieval 관련 논문 <DeCo: Decomposition and Reconstruction for Compositional Temporal Grounding via Coarse-to-Fine Contrastive Ranking>을 소개해드리겠습니다. 논문의 제목에서도 알 수 있듯 비디오 분야의 Moment Retrieval(=Temporal Gronuding) task를 수행하며, 이 때 텍스트 쿼리의 Compotisional decomposition & reconstruction을 메인 컨셉으로 잡은 논문입니다.
제가 지금 개인 연구에서 집중하고자 하는 “텍스트 쿼리 내 구성요소(단어, 구 등)와 비디오 간의 관계”를 모델링하는 방법 중 하나가 바로 compositional decomposition이며, 제가 접근하고자 했던 방식과 유사한 방법론이라 자세히 읽고 리뷰 남기게 되었습니다.

1. Introduction
본 논문에서 해결하고자 하는 비디오 분야의 Moment Retrieval이라는 task는 가공되지 않은 비디오와 사용자의 문장을 입력받아, 이에 의미론적으로 상응하는 비디오 일부 구간을 정확히 찾아내는 것입니다. 연구 초기 등장한 데이터셋은 “사람이 문을 연다”, “사람이 간식을 먹는다.” 등과 같이 주어-목적어-동사의 간단한 형태로 구축되었지만, 최근에는 “검은 옷을 입은 여자가 축제에서 광대와 서로 장난을 치며 웃는다.” 등과 같이 사람조차 바로 쉽게 이해하긴 어려운 문장들이 등장하고 있습니다.
Moment Retrieval task도, 여타 인공지능 task의 궁극적 목적과 동일하게 ‘상용화’를 고려한다면 당연히 위 방향으로 나아가야 하기 때문에 저도 사용자로부터 입력받는 문장이 굉장히 복잡하다면, 오타가 있다면, 학습 데이터셋과 말투(일종의 도메인?)가 다르다면 등등 진짜 “free-form” 형태의 문장이 입력되었을 때 모델은 어떻게 해야하는가에 대한 고민을 하는 중입니다.
학계에서도 당연히 이런 고민은 오래 전부터 이어졌고, 좀 더 Real-world에 잘 대응할 수 있는 Moment Retrieval 방법론을 내놓고 평가하자는 의도에서 Compositional Temporal Grounding task가 연구되고 있었습니다. 여기서 compositional이란 구성 요소, 부분부분을 의미합니다. 입력이 문장과 비디오, 출력이 상응 구간이라는 점은 같지만 학습/평가 split을 구성할 때 학습 때 보지 못한 단어를 끼워넣은 문장을 평가 때 사용한다거나, 학습 때 본 단어일지라도 평가 때는 의미는 동일하되 완전히 새로운 조합으로 문장을 구성하는 등등의 방식입니다.
이러한 Compositional Temporal Grounding에 도전하는 여러 방법론들이 한창 연구되고 있었는데요, 대부분은 문장과 비디오의 global feature를 추출하고 이들을 어떻게 합쳐야 새로운 조합에도 대응할 수 있을지를 중점으로 보고 있었다고 합니다. 이 방식은 우선 단어 하나하나의 의미가 중요한 composition 상황에서 각 모달을 global로 합쳐버리는 것부터가 suboptimal하다고 볼 수 있겠죠.
더욱 최근에, VISA라는 방법론이 global feature를 만드는 방법론에서 발전하여 primitive elements를 활용했다고 합니다. Primitive elements라는 어려워보이는 용어를 썼지만 결국 global의 반댓말인 local, 즉 문장을 쪼갠 단어와 비디오를 쪼갠 클립 수준에서 방법론을 고안했다고 생각하시면 됩니다. 저도 자세히는 모르지만 그래프 네트워크를 가져와 각 primitive elements들 간 상응 관계를 모델링하는 방법론이었다고 합니다.
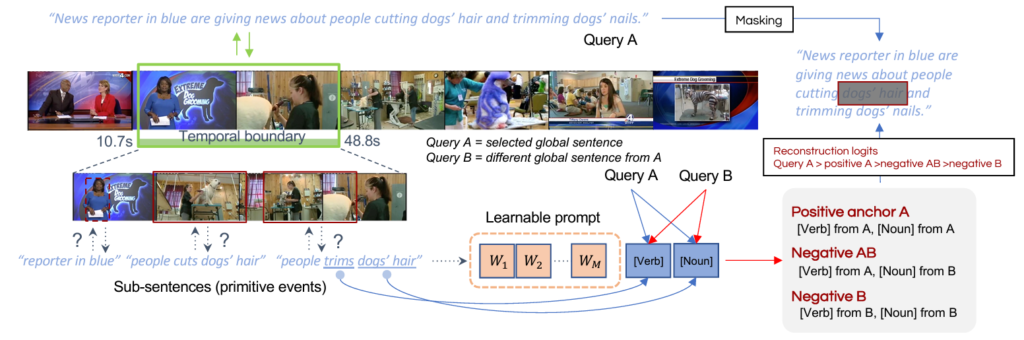
저자들은 VISA와 같이 local한 정보를 활용하는 방향성에는 동의하나, 정말 좋은 composite representation은 거기서 조금 더 나아가 다양한 granularity에서의 local한 차이에 민감하게, 구별력 있게 학습되어야한다고 주장합니다. 즉 기존 방법론에 치명적인 오류가 있어 이를 개선해야한다는 문제 정의는 아니고, 그냥 저자들이 생각했을 때 이런 부분까지 다뤄준다면 Composite Temporal Grounding을 더 잘 할 수 있겠다는 컨셉으로 보입니다. 위 그림 1은 간략하게 저자가 제안하는 방식을 나타낸 것인데, 아직 잘은 모르겠지만 원본 문장으로부터 Sub-sentences도 만들어 내고, Masking-reconstruction 과정도 거치고, Learnable prompt도 보이네요.
자세한 방법론은 밑에서 알아보도록 하겠습니다.
2. Method
우선 notation을 정리해보겠습니다. N개의 비디오 \{v_{1}, \cdots{}, v_{N}\}과 각각의 상응 텍스트 쿼리 \{q_{1}, \cdots{}, q_{N}\}을 입력받습니다. 그리고 task의 목표는 각각의 상응 구간 timestamp \{st_{1}, \cdots{} st_{N}\}, \{ed_{1}, \cdots{} ed_{N}\}를 예측하는 것입니다.
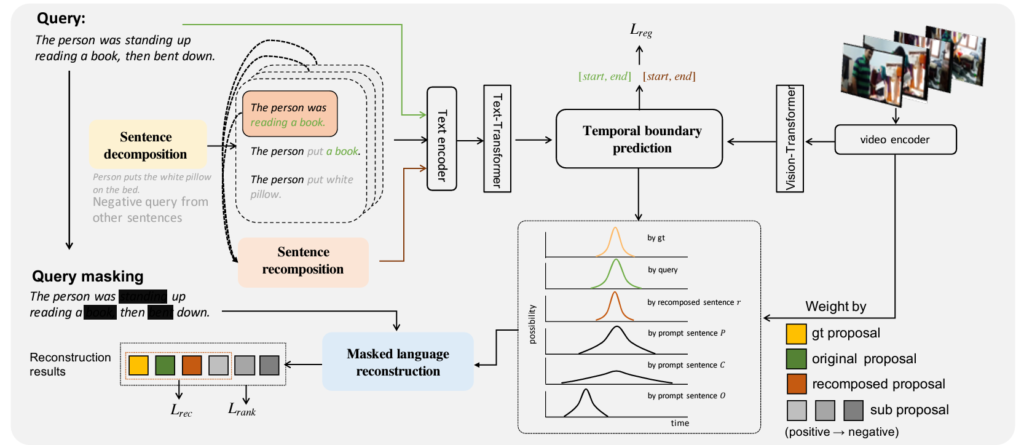
위 그림 2가 저자가 제안하는 방법론의 전체 프레임워크 그림입니다.
입력받은 텍스트 쿼리 각각을 k개의 subsentences P = \{p^{1}, \cdots{}, p^{k}\}를 만들어냅니다. 이후 k개의 subsentences들을 다시 2개의 negative sample들 \{P^{k1}, \cdots{}, P^{kn}\}을 만듭니다. 여기서 n \in{} \{1, 2\}입니다. 그리고 맨 처음에 만들어낸 P가 원본 텍스트 쿼리와 어느정도 유사한 의미를 갖도록 해주고자 P로부터 recompose한 문장 r을 만들어줍니다. 각각이 무슨 기준으로 만들어지는지는 밑에서 설명드리고, 우선 이런 개수의 문장이 생긴다는 점만 먼저 설명드리겠습니다. 사실 본문과 supplementary 그 어디에도 k가 몇인지 나타나있지가 않습니다.. 제가 생각했을 때 본문을 읽다보면 그냥 k=1인데, 이 변수로 표현하고자 굳이 k를 사용한 것 같습니다.
여기까지 정리하면 주어진 비디오 v, 문장 q에 대 decomposed sentence P \in{} \mathbb{R}^{k}, P_{N} \in{} \mathbb{R}^{2k}, recomposed sentence r이 모델 내 temporal boundary grounding network로 입력되고, 모델이 예측한 temporal proposal T \in{} \mathbb{R}^{3k+2}를 만들어냅니다. 3k+2 중 3k는 P, P_{N}을 합친 개수이고, 2는 원본 문장 하와 recomposed 문장 r 하나를 의미합니다. 각 문장이 상응하는 구간을 예측하는 것이죠.
그러나 실제 GT 구간이 제공되는 문장은 원본 문장밖에 없습니다. 그러면 weak-supervised 상황 속에서 P, P_{N}, r의 구간을 예측해야 추가적인 학습에 활용할 수 있는데, 이를 위해 마스킹된 문장의 reconstruction 기법을 사용합니다. 마지막으로 각 문장 셋 (원본 문장 / P / P_{N} / r / C / O)간의 관계를 고려한 학습 loss를 활용합니다.
그럼 방금 설명드린 (3k+2)개 문장이 각각 어떻게 만들어지는지 이제 알아보겠습니다.
2.1 Sentence decomposition
Compositional generalization 성능 개선을 위한 저자의 의도는, 모델이 최대한 다양한 조합의 문장을 보고, 이에 대한 비디오와의 상응 구간을 weak-supervision으로 예측하고 학습함으로써 추론 시 어떠한 문장에도 대응할 수 있는 일반성을 기르는 것입니다. 이렇게 다양한 문장을 만들어내는 과정 중 첫 번째는 실제 텍스트 쿼리 q를 바탕으로 각 쿼리 당 k개의 positive subsentences P를 만들어내는 것입니다. 아래 그림 3에서 문장을 decompose하는 방식을 볼 수 있습니다.

그림 3에 대해 차근차근 설명드리겠습니다. 가장 먼저 각 문장 q^{i}에 대해 PoS tagging을 수행해 문장 내 단어들의 품사를 모두 얻을 수 있습니다.
- (Verb, Noun)
- (Adjective, Noun)
- (Preposition, Noun)
- (Noun, Noun)
- (Verb, Adverb)
이후 위의 5가지 템플릿 중 하나를 랜덤으로 선택하여 (단어, 단어) 형태를 원소로 갖는 집합 compositional word tuples S=\{s_{1}, \cdots{}, s_{n}\}을 만들어줍니다. 그리고 각 s_{i}를 아래 수식 1의 TAG 위치에 채워줍니다.
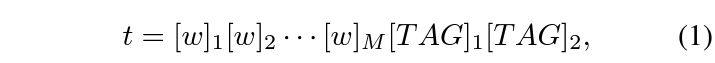
프롬프트 t의 앞에 있는 [w]_{m}은 learnable prompt이고 총 M개가 붙어있는 것을 볼 수 있습니다. 만약 위 5가지 템플릿 중 (Verb, Noun)을 선택했다면, 즉 s^{k} = (Verb, Noun)이라면 각 TAG 위치에 문장 내 동사 하나, 명사 하나가 랜덤으로 선택되어 들어가는 것입니다.
여기서 learnable parameter는 모든 문장에 동일하게 적용됩니다. 문장 마다 새로운 learnable prompt를 초기화하는 것이 아니고 데이터셋에 대해 딱 한 세트 존재한다는 것이죠. 이렇게 하나의 텍스트 쿼리 q^{i}로부터 얻을 수 있는 집합이 P_{i} = \{p_{i}^{1}, \cdots{}, p_{i}^{k}\}이고 각 원소는 위 수식 1의 프롬프트 t 형태를 갖는 것입니다. 사실 본문에 5개의 템플릿 중 k개가 아니라 “하나를 임의로 선택한다”고 명시되어있기 때문에 k=1인 것 같은데.. 우선 넘어가보도록 하겠습니다.
여기서 만든 P는 어떻게 보면 GT 텍스트 쿼리의 일부 정보를 담고있는 positive라고 볼 수 있습니다. 저자는 이에 한 발짝 더 나아가 학습 셋에 존재하지 않는 문장을 만들어내고자 합니다. 학습 중 배치 내 다른 문장 q^{j}도 위 과정을 거치며 s_{j}를 얻었을 텐데요, 배치 내 다른 문장 q^{j}의 구성 요소로 만든 s_{j}를 활용해 현재 비디오에 대해 부분적 negative 문장 C, 완전 negative 문장 O를 각각 k개씩 만들어줍니다.
s_{j}에서 s_{i}와 같은 품사를 갖는 단어를 템플릿 내 두 품사 중 하나에 대해서만 가져와 대체하고, 이를 novel subsentences C = \{c^{1}, \cdots{}, c^{k}\}라 칭합니다. 다른 문장의 주어, 동사, 형용사 중 하나를 가져왔으니 부분적 negative라고 볼 수 있겠죠. 이후 완전한 negative를 구축하기 위해 다른 문장 q^{j}로부터 만든 조합의 두 단어를 모두 대체하고, 이를 O = \{o^{1}, \cdots{}, o^{k}\}라고 칭합니다.
2.2 Recomposition
앞서 만든 subsentences들은 learnable prompt에 의존하고 있습니다. 따라서 이 learnable prompt들이 어떠한 방향으로 학습해야할지에 대한 가이드라인은 줘야겠죠. 이를 위해 \{p^{1}, \cdots{}, p^{k}\}를 N개의 learnable token과 함께 transformer decoder에 입력합니다. N개의 learnable token이 decoder의 query가 되는 것이죠. Decoder의 출력을 길이 N의 recompose된 문장 r이라고 칭합니다. 앞에서 positive라 칭한 P도 결국은 실제 텍스트 쿼리의 일부만을 따온 것이기 때문에 좀 더 명시적으로 학습할 장치를 하나 두는 것 같습니다.
사실 N이 앞서 비디오-텍스트 쌍의 개수로 이미 쓰인 notation인데, 표기는 같지만 의미는 다르다고 생각해주시면 편할 것 같습니다. 저자의 실수인 것 같네요.
2.3 Temporal Proposal/Boundary Prediction
본 절에서는 앞서 추출한 (3k+2)개의 문장으로 구간을 예측하는 방식을 설명합니다. 그림 2에서도 알 수 있듯 비디오는 ViT, 문장은 Transformer를 태운 뒤 cross-attention을 수행하여 각 클립 별 문장에 대한 상응 점수를 추출하는 것이라 자세한 설명은 생략하도록 하겠습니다. 총 (3k+2)개의 예측 timestamp (st, ed)가 나온다고 생각하시면 됩니다. 이 때 예측한 (st, ed)를 통해 구간의 (중심, 너비)를 계산할 수 있는데, 그대로 활용하는 것이 아니라 (중심, 너비)를 갖는 Gaussian curve를 구간이라 두고 뒷 절의 Mask reconstruction에 활용합니다. 실제 추론 시에는 일반적인 (중심, 너비) 형태로 예측됩니다.
아래에서 설명드릴 이 (3k+2)개 문장의 예측 구간 학습 시 이들의 관계를 어떻게 정의하고 활용하는지를 더 중점적으로 살펴보겠습니다.
2.4 Mask Reconstruction
문장 내 일부를 마스킹하고 비디오를 참고해 이를 reconstruction하는 기법은 여러 task에서 그 효과를 입증해왔습니다. 비디오를 보고 비어있는 칸에 채워질 단어를 맞추다보면 그 단어가 문맥적으로, 시각적으로 어떤 의미를 갖는지 알게 될 수 있다는 것이죠. 현재 목적이 각 단어의 문맥 속 의미를 더욱 잘 찾고자하는 것이기에 어떻게 보면 가장 간단하면서 적합한 기법이라고 볼 수 있겠습니다.
이 방법론에서 더더욱이나 Mask Reconstruction을 수행해야 하는 이유가 있습니다. 다들 눈치채셨겠지만 데이터셋에서 기존 텍스트 쿼리 q^{i}를 제외하고는 GT 구간이 제공되어있지 않습니다. 따라서 총 (3k+2)개의 문장 내 단어 일부를 마스킹한 후 Mask Reconstruction 과정을 통해 마스킹된 단어가 무슨 의미를 갖는지 알아볼 필요가 있는 것이죠. 하지만 여기까지만 말씀드리면 또 (3k+2)개 문장 중 reconstruction 해야만 하는 문장도 있고 또 reconstruction이 애초에 가능한가? 싶은 문장들이 있는데요, 이에 대해 자세히 설명드리겠습니다.
가장 먼저 원본 텍스트 쿼리 q의 단어 30%를 마스킹 토큰 <mask>로 가려버립니다. 이후 mask-conditioned transformer는 저희가 알고있는 실제 GT 구간 내 비디오 feature만을 활용하여 복원 feature를 추출합니다. 복원 feature는 이후 mask-conditioned reconstruction completion 모듈(FC layer)에 입력되어 단어 개수 차원으로 project되고, 실제 정답과 예측 간 Cross-entropy loss로 reconstruction quality를 측정하게 됩니다. 위 과정을 통해 우선 reconstruction 모듈이 제대로 reconstruction할 수 있도록 학습하게 됩니다. 여기서 중요한 것은 복원 시 참고하는 비디오 feature가 실제 GT 구간에서 따오는 것이라는 점입니다.
Mask-conditioned transformer의 입력 query는 마스킹된 문장, key와 value는 비디오 feature F_{v}입니다. 앞서 원본 텍스트 쿼리에 상응하는 실제 GT 구간을 참고하여 reconstruction 모듈을 학습시킨다면 이젠 (3k+2)개 문장으로 예측한 구간의 비디오 feature만을 참고해 reconstruction을 수행해야합니다. 똑같이 원본 텍스트 쿼리 q를 masking하고 reconstruction 한다고해도 이젠 GT 구간을 참고하는게 아니라 앞서 2.3절에서 예측한 Gaussian 형태의 구간만을 참고하는 것이죠.
이 방식을 (3k+2)개 문장에 모두 적용하고 cross-entropy loss를 구하면, \mathcal{L}_{gt}, \mathcal{L}_{q}, \mathcal{L}_{p}, \mathcal{L}_{c}, \mathcal{L}_{o}를 얻을 수 있습니다. 여기서 \mathcal{L}_{gt}, \mathcal{L}_{q}, \mathcal{L}_{p}는 모두 positive에 해당하는 문장이기에 실제로 CE loss를 학습합니다. 이들을 엮어 reconstruction loss \mathcal{L}_{rec}라 칭합니다. 그럼 나머지 \mathcal{L}_{c}, \mathcal{L}_{o}는 구해놓고 학습하지 않으면 뭐하러 구한 것인지 의문이 생기는데요, 이는 아래 2.5절에서 활용합니다.
추가로 recompose 문장 r에 대한 loss \mathcal{L}_{r}의 내용은 본문에 없는데, 메인 프레임워크를 나타내는 그림 2를 보시면 아마 \mathcal{L}_{r}도 \mathcal{L}_{reg}에 포함되는데 빠뜨린 것 같습니다.
이렇게 positive 문장의 예측 구간을 활용해 문장을 잘 reconstruction하려다보면 곧 reconstruction할 때 참고하기 더 좋은 구간, 즉 마스킹된 문장과 더욱 상응하는 구간을 잘 찾아내도록 앞 모듈도 학습된다는 장점을 가질 것입니다.
2.5 Contrastive Ranking
여기에선 앞서 추출해두고 사용하지 않은 \mathcal{L}_{c}, \mathcal{L}_{o} 또한 학습에 사용하는 새로운 loss를 제안합니다. 사실 다른 비디오의 상응 문장으로부터 온 loss이기 때문에 이들에 대해 reconstruction loss를 적용해줄 필요는 없습니다. 대신 아래 수식 (3)과 같이 문장 간 관계를 고려해 랭킹을 강제해주는 학습을 진행합니다.
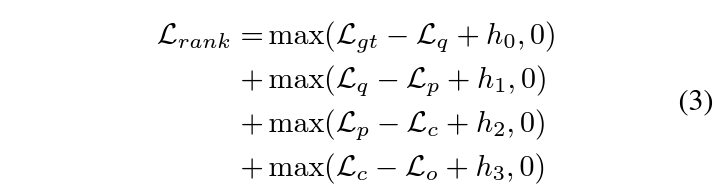
직관적으로 생각해보았을 때 loss 값은 밑에 제가 적은 순서대로 점점 작은 값에서 큰 값으로 향해야 합니다.
- \mathcal{L}_{gt}: 실제 GT 구간 기반 reconstruction
- \mathcal{L}_{q}: 원본 텍스트 쿼리 기반 reconstruction
- \mathcal{L}_{p}: positive에 해당하는 문장 P 기반 reconstruction
- \mathcal{L}_{c}: 텍스트 쿼리와 일부만 관련이 있는 문장 C 기반 reconstruction
- \mathcal{L}_{o}: 현재 텍스트 쿼리와 전혀 무관한 문장 O 기반 reconstruction
2.6 Model training and inference
학습 중 저희는 실제 상응 구간의 GT를 알고있기에 가장 직접적인 regression을 수행해주는 \mathcal{L}_{reg}를 적용할 수 있습니다. 이후 앞서 2.4절에서 본 \mathcal{L}_{rec}, 2.5절에서 본 \mathcal{L}_{rank}를 적용할 수 있습니다. 최종 loss는 아래 수식 (4)와 같습니다.
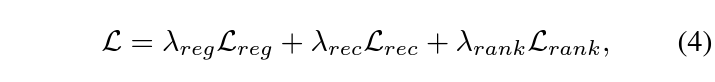
학습을 마친 후 실제 추론 시에는 recomposed sentence r의 예측 구간을 활용한다고 합니다.
이제 방법론에 대한 설명은 끝났고, 실험 결과를 살펴보도록 하겠습니다.
3. Experiments
3.1 Datasets
평가에 사용된 데이터셋 Charades-CG, ActivityNet-CG에 대해 먼저 알아보겠습니다. 여기서 CG는 Compositional Grounding의 준말로 좀 더 일반화된 평가를 위해 당시에 제안되었던 데이터셋입니다. 기존의 Charades-STA와 ActivityNet Caption 데이터셋의 변형이라고 생각하시면 됩니다.
이들은 Novel-Composition, Test-trivial이라는 새로운 평가 split으로 나뉘어있습니다. 먼저 Novel-composition split은, 학습 때 문장 내 각 주어와 동사를 본 적은 있지만 주어-동사로 이루어진 하나의 문장을 평가 때는 처음 보는 상황을 의미합니다. Test-Trivial의 trivial은 ‘쉬운’이라는 뜻으로 기존 테스트셋과 동일한 상황이기에 사실상 Novel-composition 성능에 초점을 맞춰 분석해보면 됩니다.
3.2 Quantitative Results
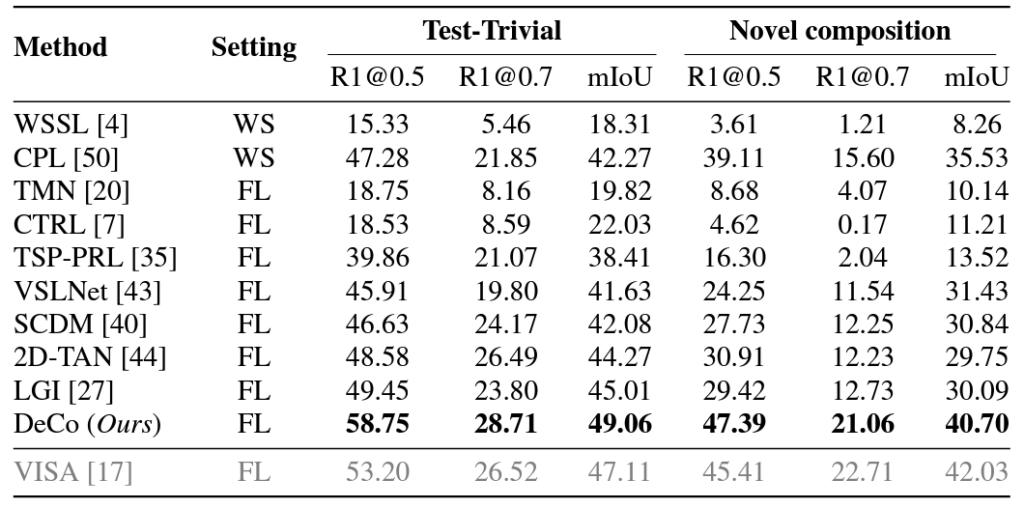
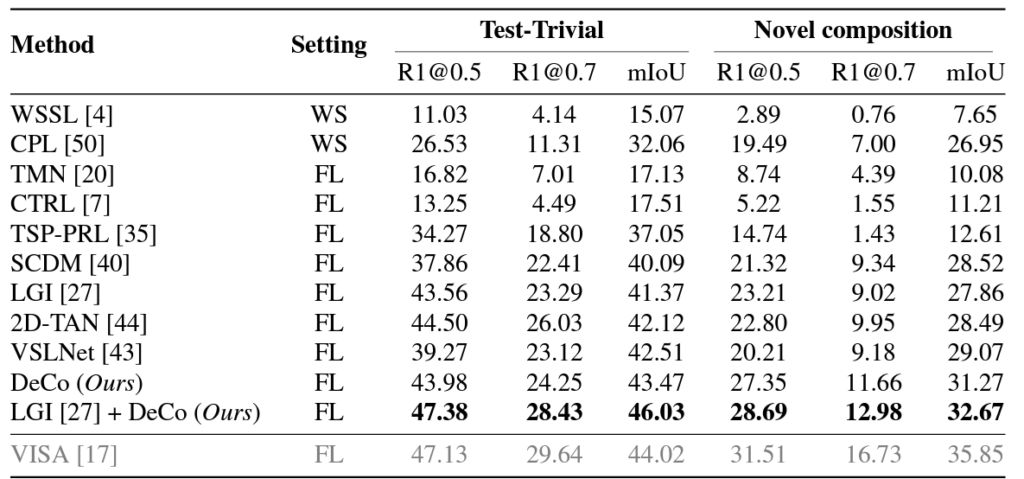
위 표 1, 2는 각각 Charades-CG, ActivityNet-CG 데이터셋에 대한 성능입니다. 우선 Introduction에서부터 유사하다고 말씀드렸던 VISA는 회색으로 표시되어있습니다. 이는 살펴보니 외부 object detector, action detector 지식을 함께 사용했기 때문이라고 하네요. 표 1의 Charades-CG 데이터셋에 대해서는 나름 외부 지식을 함께 활용한 VISA보다 더 높은 성능을 보여주고, 이외 방법론과는 큰 차이로 성능을 압도하는 것을 볼 수 있습니다. VISA에 비하면 R1@0.5를 제외하곤 또 크게 낮긴 하네요.
그러나 표 2의 ANet 성능은 LGI 방법론에 DeCo를 붙여도 VISA보다 훨씬 낮은 성능을 보옂고 있습니다. 저자는 이에 대해 VISA가 활용한 외부 detector의 지식이 이미 decomposition에 대한 정보를 갖추고 있기에 유리하다고 이야기하고, 또 DeCo가 외부 detector 지식 없이 현재 방법론의 visual feature에만 의존하다보니 새로운 샘플에 대해 상대적으로 약할 수 밖에 없다고 이야기하고 있습니다.
3.3 Ablation Study
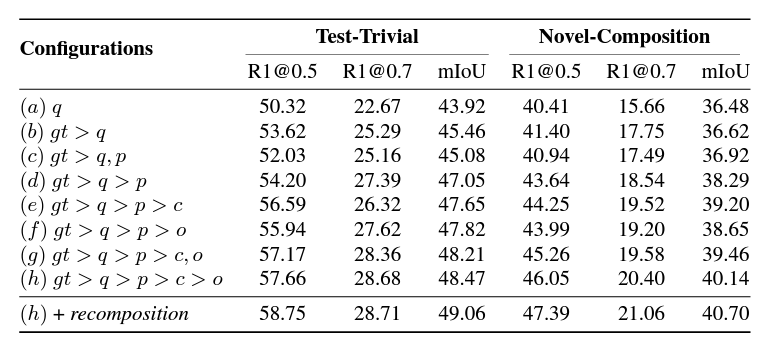
위 표 3은 \mathcal{L}_{rank}에 대한 ablation 성능입니다. 우선 rank 학습의 대상을 늘릴수록 Test-Trivial은 물론 Novel-Composition 성능 또한 함께 올라가는 것을 볼 수 있습니다. 문장 간 계층이 존재하면 계층 간 margin을 주는 것이 확실히 성능 개선에 도움이 되는 것 같습니다. 표 3의 (b), (c), (d)를 함께 보면, 원본 문장으로부터 decompose한 문장을 같은 계층에서 활용하는 것은 오히려 성능 하락을 불러온다는 점을 알 수 있습니다. 확실히 margin을 줌으로써 모델이 문장 간 계층(rank)을 알게 해주는 것이 도움이 되네요.
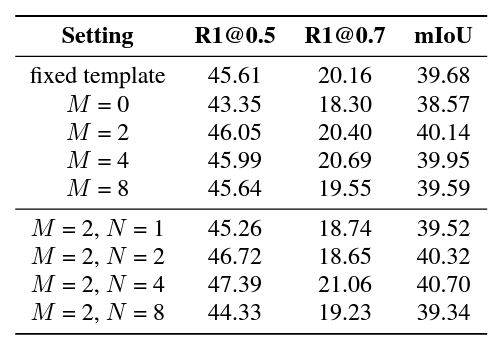
위 표 4는 Learnable prompt에 대한 ablation study 성능입니다. 사실 learnable prompt의 개수 M, N에 따른 성능 차이는 큰 의미 없어보이고, fixed template이라 적힌 hand-crafted prompt의 성능이 볼만한 것 같습니다. 여기서 hand-crafted prompt의 성능도 꽤 나쁘지 않은데, 이를 통해 프롬프트도 중요하긴 하지만 뒷 단에서 각 모달 feature를 어떻게 활용하냐가 더욱 중요함을 알 수 있었습니다. 또 learnable prompt의 개수가 무조건 많다고 좋은 것은 아니기에 어떤 문장에 붙는 것인지에 따라 적절히 설정해줄 필요가 있음을 알 수 있습니다.
4. Conclusion
간단하게 리뷰를 작성하려했는데 굉장히 길어졌네요. 논문을 쭉 읽으며 정리하는 과정에서 사실 notation에 대한 혼란도 있었고, 그림과 본문 내용이 불일치하는 경우도 있고, 동일한 내용을 계속 다른 표현으로 이야기해 읽기에 좀 어려운 감이 있었습니다. 또한 문제 정의가 완벽했던 것도 아니고 성능도 시원하게 다른 방법론을 이긴 것도 아니었음에도 논문이 붙은 것은.. 방법론이 문제를 해결하기 위해 정말 필요한 개념만 정의하고 이를 직관에 맞게 잘 사용했다는 점 때문인 것 같습니다.
유사한 방법론으로 시도중이었는데 결국 성능이 잘 안오른 것 같아 불안함도 있지만 계속 이 방향으로 연구해보도록 하겠습니다. 감사합니다.