안녕하세요, 마흔 아홉번째 x-review 입니다. 이번 논문은 한 2주 전 arXiv에 게재된 OV3D 논문으로, 지난주와 마찬가지로 monocular ov 3D 논문 입니다. CVPR 포맷으로 작성되어 있긴 한데 .. 제가 바로 이전에 읽은 NeurIPS에 accept된 동일한 task의 논문에 비해 방법론적으로 아쉬움이 많이 남는 논문인 것 같습니다. ?
그럼 바로 리뷰 시작하겠습니다.

1. Introduction
이미지 데이터를 가지고 2D detection에서는 이미 ov가 활발하게 진행되고 있고, 3D에서도 ov는 아니더라도 2D에서의 연구를 확장하여 monocular 3D detection task가 연구되고 있었습니다. 많은 방법론들이 그러하듯 monocular 이미지 데이터 관점에서 ov를 3D로 그대로 확장하고자 하였지만 최근까지 거의 연구가 진행되지 않고 있었습니다. (제가 바로 이전에 리뷰한 논문이 NeurIPS 2024에 게재됐음에도 불구하고 monocular ov 3D로는 처음인걸 보면 이제 막 연구되기 시작한 분야인 것 같습니다.)
여하튼 그래서 본 논문에서는 monocular detection에서도 2D에서의 지식을 최대한 활용하는 것을 목적으로 OVMONO3라는 방법론을 제안합니다. 이를 위해서는 두 가지 문제를 해결해야 하는데요, 먼저 이전 논문 리뷰에서도 언급되었듯이 아직 공공연하게 사용하는 대표적인 실험 세팅과 평가 프로토콜이 없기 때문에 모델의 성능을 증명하는 것이 어렵다는 점이 첫번째 문제점 입니다. 두번째로는 3D 바운딩 박스 어노테이션 하는 것의 cost 때문에 라벨링된 3차원 데이터의 부족을 이야기하고 있네요. 이 두 가지 문제를 해결하기 위해 먼저 task를 평가할 수 있도록 정의하고, 평가할 때 어노테이션 문제의 영향을 완화하기 위한 간단한 프로토콜을 제안한다고 합니다.
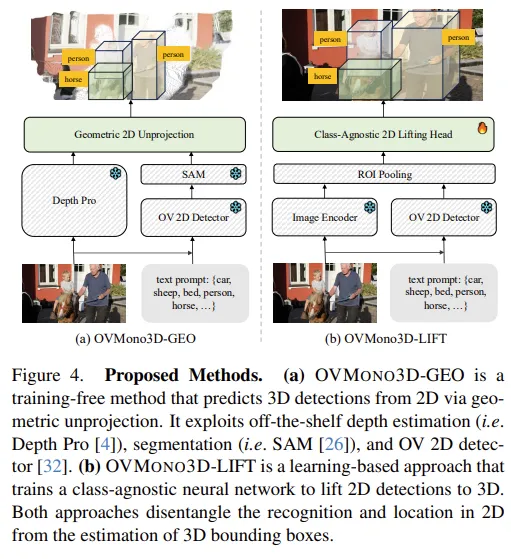
높은 퀄리티의 어노테이션을 제공하는 large scale의 3D 데이터셋이 부족한 것을 우선 해결하기 위해, 본 논문에서는 2D에서 물체를 먼저 인지를 하고 그 다음에 3차원으로 올리는 방식을 선택하였습니다. Fig.4(a)와 같이 기존의 ov 2D 모델을 사용해서 결과를 뽑고, 3D로 투영함으로써 간단하게 학습이 필요하지 않은 방식인 GEO 모델을 우선 설계하였는데요, 이 방식은 일반적으로 쉬운 scene에서는 효과적일 수 있지만 물체가 occlusion이 생기는 scene에 대해서는 강인성이 부족하게 됩니다. 아무래도 복잡한 scene을 단순히 추가적인 학습 없이 3차원으로 올리기만 하는 것은 부족함이 있을테니까요 . .
이를 해결하기 위해 2D 검출 결과를 3D로 올리는 방식을 학습할 수 있도록 하는 방법이 Fig.4(b)에서 얘기하는 LIFT 버전 입니다. 백본 네트워크와 ov 2D 베이스 모델, 그리고 데이터의 크기를 종합적으로 고려하여 설계함으로써 실험에서 novel 클래스를 3차원으로 검출하는데 sota를 달성할 수 있었다고 합니다.
이러한 OVMONO3D-LIFT의 main contribution을 정리하면 다음과 같습니다.
- ov monocular 3D detection을 위한 평가 메트릭을 정의하고 처음으로 task를 수행함. (근데 현재 논문이 나온 시기를 봐선 이전에 리뷰한 논문이 가장 처음으로 ov monoulcar 3D를 수행한 논문인거 같긴 합니다 ㅎㅎ .. )
- 2D에서의 detection 결과를 3차원의 공간으로 올릴 수 있는 OVMONO3D-LIFT를 제안
- 구조를 설계하기 위해 수행한 여러가지 실험을 수행하고 zero shot 기반의 monocular 3D detection에서의 효과를 입증
2. Open Vocabulary Monocular 3D Detection
2.1. Task Definition
해당 task의 목적은 입력으로 이미지 I \in \mathbb{R}^{H \times H \times 3}와 텍스트 프롬프트 T = [c_1, c_2, . . . , c_M]이 주어지면 모든 가능한 object set \{(c_i, B_I)\}^N_{i=1}을 예측하는 것이겠죠.
여기서 텍스트 프롬프트는 모든 가능한 open vocabulary \mathcal{C}의 물체 카테고리에 대항하는데, 여기서 \mathcal{C}는 두 개로 나뉘어집니다. 먼저 base 카테고리인 \mathcal{C}_{base}는 학습 동안에 사용이 되고, novel 카테고리인 \mathcal{C}_{novel}은 학습 때는 사용하지 않다가 inference 시에만 평가에 사용됩니다.
2.2. Evaluation Metrics

3D detection에서는 보통 mAP를 사용하는데, 본 논문에서는 그런 일반적인 프로토콜을 그대로 사용하기엔는 데이터셋 관점으로 이슈가 있다고 주장합니다.
먼저 Missing annotation 문제로, 3D 어노테션이 라벨링하는데 cost가 많이 드는 일임에도 불구하고 놓쳐지는 물체들이 존재하여 실용적이지 못하다는 점 입니다. Fig.3(a)를 보면 책장 안에 놓인 책에 대한 라벨링이 없는 것을 확인할 수 있죠.
두번째는 Naming ambiguity인데, 마찬가지로 Fig.3에서 알 수 있듯이 하나의 물체를 두고 테이블인지, 책상인지에 대해 서로 다르게 라벨링이 될 수 있다는 것 입니다. 이렇게 같은 물체임에도 모호하게 정의되는 카테고리가 있을 경우 다른 유사한 클래스로 잘못 예측될 가능성이 커지게 된다고 합니다.
그래서 이런 문제를 해결하기 위해 각 이미지 안에서 GT로 지정된 instance가 존재하는 카테고리에 대해서만 고려하는 target-aware 평가 방식을 제안하였습니다. 2D detecor한테 가능한 모든 카테고리 리스트를 제공하는게 아니라, 이미지 안에서 라벨링이 된 카테고리만 제시하는 것 입니다. 어노테이터는 보통 하나의 이미지 안에서 동일한 카테고리를 가진 모든 instance에 라벨링을 할 것 이기 때문에 GT에 포함된 클래스는 놓쳐진 어노테이션이 없을 것 이라고 판단하였다고 합니다.
이렇게 target aware 평가 방식은 GT 기반의 어노테이션이 있는 클래스에 대해서만 초점을 맞추기 때문에 missing annotation이 평가 메트릭에 미치는 영향을 막을 수 있습니다. Fig.3(c)를 봤을 때, 관련된 카테고리에만 집중함으로써 missing annotation과 모호한 카테고리의 영향을 완화함으로써 모델의 성능을 보다 더 정확하게 평가할 수 있도록 하였습니다.
3. Methodology
본 논문의 방법론에는 두 개의 sota 프레임워크를 사용하였는데요, monocular 3D detector로는 Cube R-CNN을 사용했고 ov 2D detector로는 Grounding DINO를 이용했다고 합니다.
3.1. OVMONO3D-GEO: Geometric 2D Unprojection
먼저 OVMONO3D-GEO는 ov 3D detection을 위해 2D detection 결과를 3차원으로 간단히 역투영 하는 방식을 사용합니다. 입력 이미지 I와 텍스트 프롬프트 T, 그리고 ov 2D detector가 예측한 카테고리 \{(b_i, c_i)\}^N_{i=1}에 대한 2D 박스가 주어집니다. 그럼 검출된 각 물체에 대해 SAM과 같은 segmentation 모델을 사용해서 instance segmentation mask S_i를 생성하고, Depth estimation 모델델로 depth map D \in \mathbb{R}^{H \times W}를 생성합니다.
여기서 S_i안에 포함된 픽셀에 대해 depth map과 카메라 파라미터를 사용해서 3차원 공간으로 올려 포인트 클라우드 P_i를 만드는 것이죠.
그 다음 3차원의 바운딩 박스 파라미터들을 추정하기 위해서 PCA를 가지고 박스의 중심 좌표, 크기, 방향에 대해 각각 계산한다고 합니다. 그 다음 단순하게 DBSCAN으로 outlier을 제거해서 마스크와 depth 예측 결과에 대한 노이즈를 해결하고자 하였습니다.
보셨다시피 GEO 버전에서 사용하는 방법들은 사전학습된 모델들을 사용할 뿐 3차원의 기하학적 계산이나 PCA나 DBSCAN과 같은 연산이 들어가기 때문에 결과의 정확도가 오로지 D와 S_i에 매우 의존적이게 됩니다. 하지만 이미지에서 나오는 마스크와 depth map은 이미지 내의 물체가 occlusion되어 있는 것처럼 기하학적 요소 없이 추정하기 어려운 scene에서는 정확한 예측이 어려워지고, 그런 예측 결과로 만든 포인트 클라우드와 바운딩 박스의 퀄리티 역시 매우 떨어지게 되겠죠.
3.2. OVMONO3D-LIFT: Class-Agnostic 2D Lifting
앞선 3.1.에서의 한계를 해결하기 위해 학습 기반의 모델을 구축하고자 monocular 3D 어노테이션을 활용한 모델인 OVMONO3D-LIFT를 제안합니다. 기존 2D detection으로 prior를 생성해서 3D에서의 성능을 향상시키고자 한 것 입니다. 구체적으로 기존 ov 2D detector를 사용해서 물체를 검출하는 단계와, 2D 바운딩 박스를 3D cuboid로 class agnostic하게 올리는 단계로 분리하여 수행됩니다.
아까와 마찬가지로 I, T, \{(b_i, c_i)\}^N_{i=1}가 주어지면, OVMONO3D-LIFT는 사전학습된 ViT 백본을 이용해서 이미지 feature map을 추출합니다. 그 다음에 Simple Feature Pyramid 모듈을 통해 멀티 스케일의 feature을 생성합니다. 앞서 ov 2D detector를 통해 예측된 2D 바운딩 박스가 RoI pooling의 관심 영역으로 사용되어 로컬한 물체 feature을 추출할 수 있습니다. 그 다음에 Cube R-CNN의 구조를 따라 3차원 특성을 예측하기 위해 3D cube head의 입력으로 feature를 넣게 됩니다. 다른 점이라고 하면 cube head에서 class-agnostic하게 3차원 박스만 예측이 된다고 합니다. 논문에 설명이 여기까지 나와있는데 .. 보통 ov 3D에서는 이렇게 class agnostic한 3차원 박스를 예측하고 나면 클래스와의 매칭과 align을 맞추는 방법까지 제시가 되어 있는데 본 논문에는 그런 부분이 생략이 되어 있네요 .. 아마 예측되는 2D box와 만들어지는 3D box 사이의 IoU 같은걸 계산해서 클래스를 할당하지 않을까 .. 생각해봅니다.
4. Experiments
4.1. Experimental Setup
Datasets
실험에는 monocular 3D detection을 위한 대표적인 데이터셋인 Omni3D를 사용하였다고 합니다. 이 데이터 안에는 indoor/outdoor 데이터셋이 합쳐져 있어 SUN RGB-D, nuScenes, KITTI 등등의 데이터가 모두 포함되어 있습니다.
학습에는 50개의 카테고리로 Cube R-CNN을 학습을 하고, 평가에는 학습 때 사용한 카테고리 이외에 22개의 카테고리를 novel class로 이용하였다고 합니다. 그 중에서도 물체의 visibility를 판단하여 easy와 hard로 기준을 한번 더 나누었다고 하네요.
Baseline Methods
베이스라인을 설정하기 위해 또 다른 데이터 기반의 학습 방식으로 ov 2D detector를 3D로 직접 확장하는 방식을 얘기하고 있습니다. 아까 Grounding DINO를 사용하다고 했던 것이 이 부분을 얘기하는 것 같네요.
구체적으로 Grounding DINO의 마지막 디코더 레이어의 출력 feature을 객체의 representation으로 사용하기 위해 MLP를 태워 3차원 특성을 예측합니다. 여기서 사전학습된 이미지 인코더는 사용하지 않으며, 이 구조를 기반으로 본 논문의 방법론과 비교를 위한 두 개의 베이스라인을 설정하였다고 합니다.
(1) 추가적인 MLP만 learnable하게 설정하고, 다른 파라미터를 고정한 G-DINO-3D(FZ)
(2) 모든 학습 파라미터를 fine tuning하는 G-DINO-3D(FT)
4.2. Model Performance
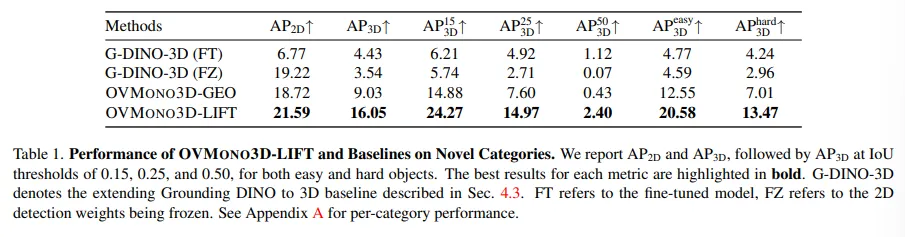
위의 Tab.1을 보면, LIFT가 novel 클래스를 찾는 데서 베이스라인 방식들과 비교하여 큰 차이를 두고 좋은 성능을 보이고 있습니다. GEO 같은 경우에는 LIFT에 미치지 못하는 성능을 보이는데, 이런 차이가 결국 아까 말한 것처럼 occlusion 되어 있는 scene을 처리하지 못하고 마스크와 depth map의 노이즈로 인해 포인트 클라우드와 바운딩 박스의 퀄리티가 낮아지기 때문이라고 볼 수 있습니다.
G-DINO-3D(FZ) 같은 경우에 2D detection 파라미터를 freeze 하는데, 이게 3D detection에 대해서는 적합하지 못하다는 걸 확인할 수 있는게 2D와 3D의 AP 차이가 가장 많이 발생하고 있네요. 반대로 G-DINO-3D(FT)는 파라미터를 모두 fine tuning 하게 되어 기존의 ov 검출 능력을 저하 시켜 3D에서도 마찬가지로 좋지 못한 성능을 보이고 있습니다. 그러나 LIFT는 이제 2D 데이터를 기반으로 학습을 하여 ov 2D detection의 결과를 3D로 올리는데 성공적이었다고 분석하고 있습니다. 이를 통해 이전에 나타나던 예측 결과의 낮은 퀄리티와 3D 데이터의 부족함을 해결할 수 있다고 주장하고 있네요.
4.3. Analysis
Evaluation Protocal
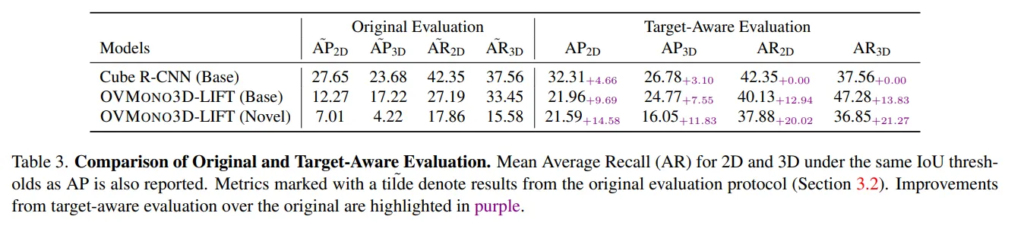
기존의 평가 방식인 AP를 그대로 사용한게 아니라 target aware 평가 프로토콜을 새로 정의한만큼 그에 대한 ablation study를 진행하였습니다. 기존 방법론인 Cube R-CNN에서도 target-aware 평가를 했을 때 더 성능이 개선되는 것을 보여주면서 missing annotation으로 인한 영향을 줄일 수 있었다는 것을 보여주고 있습니다.
novel 클래스를 찾을 때의 성능 향상이 매우 크다는 것을 알 수 있는데요, 이러한 성능 개선을 강조하는 것이, 새로운 클래스는 나타나는 빈도가 적고 매우 넓은 범위의 클래스가 포함이 될 때 모델이 그러한 클래스들까지 모두 검출하는 것이 어려웠는데 이러한 평가 프로토콜을 적용함으로써 모델이 찾은 novel 클래스에 대해 제대로 평가할 수 있게 되었기 때문 입니다.
2D Bounding Box Input
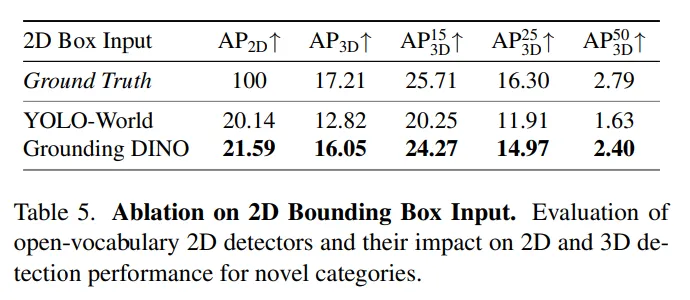
그 다음은 2D와 3D detection에서 새로운 검출을 찾는데 2D detector의 영향을 평가한 실험 입니다. 2개의 sota 모델인 YOLO-World와 Grounding DINO를 사용했는데, 모든 성능 지표에서 Grounding DINO가 더 좋은 성능을 보이는 것을 확인할 수 있습니다. 특히 3D의 AP 성능 관점에서 Grounding DINO는 GT 2D를 사용했을 때와 거의 유사한 성능을 보이면서 최종적으로 Grounding DINO를 사용하였다고 합니다.
Pre-trained Backbone Selection
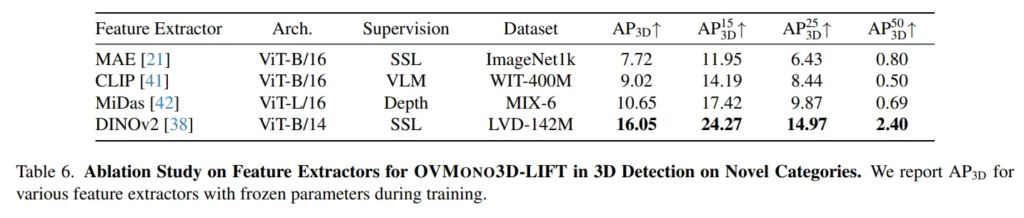
마지막으로 사전학습된 백본 네트워크 종류에 따른 3D detection의 성능 차이에 대한 실험 결과 입니다. DINOv2를 사용했을 때 모든 3D 관련 성능 지표에서 가장 높은 성능을 보이는데, 이러한 결과는 DINOv2가 3차원 task를 수행할 때 가장 효과적이라는 알 수 있습니다. 이전 연구에서도 보여주었듯이 depth estimation이나 multi-view correspondence 등등의 task에서 DINOv2를 가장 활발하게 사용하고 있는 경향과 일치하는 것을 보여주며 DINOv2의 적합성을 보여주고 있습니다.
안녕하세요. 리뷰 잘 읽었습니다.
OVD에 관심을 가지다보니, OV3D 논문들의 흐름이 이제 시작인 것을 느끼게 되네요.
특히, Evaluation Metrics를 제안했지만 현실적으로는 실용성이 다소 떨어지는 방식임에도, 어쩔 수 없음은 아직 연구의 고도화 단계가 깊지는 않은 것 같습니다 (역으로, 논문 쓰기에는 더 편할 수도 있다는 의미이지만).
특히, Lifting이 아닌 (a) GEO의 경우, depth pro와 같은 monocular depth estimation 모델은 가끔 비가 와 영상에 물방울이 많이 맺힌 경우나, 역광이 들어오는 경우 또는 그냥 가끔 metric depth estimation이 제대로 되지 않아 (보통 이 때는 depth scale이 0~1 수준으로 흔히는 Failure Case로 불립니다), 문제가 생기기도 합니다.
그러면서 드는 의문점은 결국 본 논문에서 말하는 Lifting의 핵심이 2D Feature로부터 3차원 특성(class-agnostic 3D bbox)을 추출할 수 있는 Cube R-CNN의 cube head가 가장 핵심으로 보이는데, 이는 동작원리가 자세히 어떻게 되나요?
2D로부터 추가적인 정보 없이 3D를 예측한다, 마치 monocular depth estimation과 같아 보이는데, 이 동작원리가 본 논문의 가장 핵심인데 다소 설명이 빈약하여 자세한 설명을 부탁드립니다.